Python数据挖掘之数据探索
简要来说,数据探索(Data Exploration)是指在数据分析和数据挖掘的早期阶段,通过多种方法对原始数据进行初步的理解和分析,以掌握数据的基本特征和结构。具体包括以下几个方面:统计描述:计算基本统计指标,如均值、中位数、众数、方差、标准差、最大值、最小值等。查看数据的集中趋势和离散程度。数据分布规律:利用直方图、密度曲线、箱线图等可视化工具,观察数据的分布形态(正态分布、偏态、双峰分布等)
文章目录
简要来说,数据探索(Data Exploration)是指在数据分析和数据挖掘的早期阶段,通过多种方法对原始数据进行初步的理解和分析,以掌握数据的基本特征和结构。
具体包括以下几个方面:
统计描述:
计算基本统计指标,如均值、中位数、众数、方差、标准差、最大值、最小值等。
查看数据的集中趋势和离散程度。
数据分布规律:
利用直方图、密度曲线、箱线图等可视化工具,观察数据的分布形态(正态分布、偏态、双峰分布等)。
异常值检测:
识别数据中的异常点,这些值可能是录入错误、测量误差,或者特殊情况,需进行后续处理。
缺失值分析:
统计缺失数据的比例和位置,判断缺失模式(随机或非随机),以决定合理的数据填补或删除策略。
变量关系分析:
利用散点图、相关系数等方法,探索不同变量之间的关系,为特征选择和模型构建提供依据。
通过全面的探索,不仅可以识别数据中的问题,还能为后续的数据预处理(如清洗、归一化、编码)和模型设计提供有价值的指导,从而提升整个数据分析项目的效果和效率。
数据对象与特征
数据集与数据对象简介
数据集:由多个数据对象组成的集合。
数据对象:代表一个实体,可以称为记录、样本、实例、点、向量或模式。
特征(属性、变量):用来描述数据对象的基本属性。
存储方式:
在数据库中,一行(record或row)对应一个数据对象(元组,tuple)。
一列(column)对应一个特征(属性,attribute或特征变量)。
| 学生编号(ID) | 姓名(Name) | 年龄(Age) | 性别(Gender) | 成绩(Score) |
|---|---|---|---|---|
| 001 | 李华 | 20 | 男 | 85 |
| 002 | 张伟 | 22 | 女 | 90 |
| 003 | 王芳 | 21 | 女 | 88 |
在这个示例中:
每一行(记录)代表一个数据对象(即一个学生实例)。
**列(特征)**描述该对象的属性(ID、姓名、年龄、性别、成绩)。
数据对象特征及其类型
- 标称特征(Nominal Features)
定义:表示类别或名称,没有大小或顺序之分。
示例:性别(男、女)、颜色(红、绿、蓝)、国家(中国、美国、日本)。
特征:只能进行类别之间的相等或不相等比较,不能进行大小比较。
- 二元特征(Binary Features)
定义:只有两个可能取值的特征,通常用0/1或真/假表示。
示例:是否拥有驾照(有/无)、是否通过考试(是/否)。
特征:非常简单,常作为分类变量使用。
- 序数特征(Ordinal Features)
定义:具有明确顺序关系的类别,但类别之间的距离不一定相等。
示例:教育程度(高中、专科、本科、硕士、博士)、满意度(不满意、一般、满意)。
特征:可以比较大小(如更高或更低),但不能量化其间的差距。
- 区间标度特征(Interval Scale Features)
定义:具有数量关系,且相差的意义固定,0点一般为任意定义。
示例:温度(摄氏度、华氏度)、年份(年份差异意义明确)。
特征:可以进行加减操作,但比例关系不成立(如2000年和2020年差20年,但不能说2020年是2000年的两倍)。
- 比率标度特征(Ratio Scale Features)
定义:具有固定的比例关系,0点具有自然意义。
示例:身高、体重、价格、距离、时间。
特征:可以进行加、减、乘、除操作,比例关系有意义(如体重10kg是20kg的一半)。
| 特征类型 | 描述 | 例子 | 操作允许 |
|---|---|---|---|
| 标称特征 | 类别,无顺序 | 性别、颜色、国家 | 相等判断 |
| 二元特征 | 两个可能取值 | 是否拥有驾照(有/无) | 相等、不相等 |
| 序数特征 | 有顺序关系,大小关系有意义 | 教育程度、满意度 | 大小比较 |
| 区间标度特征 | 数值,有固定差距意义 | 温度(摄氏度)、年份 | 加减操作 |
| 比率标度特征 | 数值,有自然零点,比例关系有意义 | 身高、体重、价格、距离 | 加减乘除 |
离散和连续特征
- 离散特征(Discrete Features)
定义:在一定范围内具有有限个可能取值的特征。这些取值可以是整数、符号、布尔值或序数。
特点:
取值有限或可数无穷(例如,整数序列)。
可以用离散的符号或数值表示。
示例:
标称特征:颜色(红、绿、蓝)
二元特征:是否(是/否)、性别(男/女)
序数特征:教育程度(高中、专科、本科、硕士、博士)
整数特征:职工人数、设备台数、年龄(如果用整数表示)
应用场景:
分类变量
构建类别型模型(如决策树)
- 连续特征(Continuous Features)
定义:在一定区间范围内可以取任意值,有无限个可能取值,通常是实数。
特点:
取值是连续的,具有无限的可能性。
可以进行数值运算(加减乘除)。
示例:
区间标度特征:尺寸、温度(摄氏度)、时间
比率标度特征:身高、体重、污染物浓度
应用场景:
数值型特征
适用于回归分析、连续变量建模
| 分类 | 特征类型 | 取值数量 | 典型例子 | 取值说明 |
|---|---|---|---|---|
| 离散特征 | 有限或可数无穷 | 有限或可数 | 性别、颜色、职业、年龄(整数) | 可分为标称、二元、序数、整数 |
| 连续特征 | 无限动值 | 任意实数 | 身高、温度、浓度 | 数值是连续、可无限细分 |
离散特征适合分类、分组和类别分析。
连续特征适合数值计算和回归分析。
理解特征的取值类型,有助于选择适合的特征编码、预处理方法,比如离散特征的独热编码(One-Hot)、连续特征的归一化等。
数据的统计描述
统计描述的两大类指标
- 集中趋势(Measures of Central Tendency)
定义:反映数据的“中心”位置,描述数据在数轴上的典型值或代表性值。
常用指标:
均值(Mean):所有数据点的总和除以数据点数,反映数据的平均水平。
中位数(Median):将数据按大小排序后位于中间位置的值,抗极端值影响强。
众数(Mode):数据中出现频率最高的值。
作用:
描述数据的“平均”状态或典型值。
评估数据是否偏态,判断数据的偏离程度。
- 离中趋势(Measures of Dispersion/Variability)
定义:描述数据在集中趋势附近的分散程度或变异量。
常用指标:
极差(Range):最大值与最小值之差,反映数据的总跨度。
四分位差(Interquartile Range, IQR):第3四分位数(Q3)与第1四分位数(Q1)之差,描述中间50%的数据分散情况。
方差(Variance):每个数据点与均值的偏差的平方的平均值。
标准差(Standard Deviation):方差的平方根,度量数据的波动程度。
作用:
揭示数据的变异性和离散程度。
判断数据是否偏离集中趋势较远,为数据预处理提供依据。
| 指标类型 | 主要指标 | 描述内容 | 作用 |
|---|---|---|---|
| 集中趋势 | 均值、中位数、众数 | 描述数据的“中心”位置 | 了解数据的平均状态或典型值 |
| 离中趋势(分散程度) | 极差、四分位差、方差、标准差 | 描述数据的分散或变异程度 | 评估数据的波动范围和稳定性 |
集中趋势
一般来说,数据在某个特征上的集中趋势主要由其取值的平均水平来度量,使用较为广泛的度量包括:均值(Mean)、中位数(Median)和众数(Mode)
均值
反映在某个特征上平均取值情况。
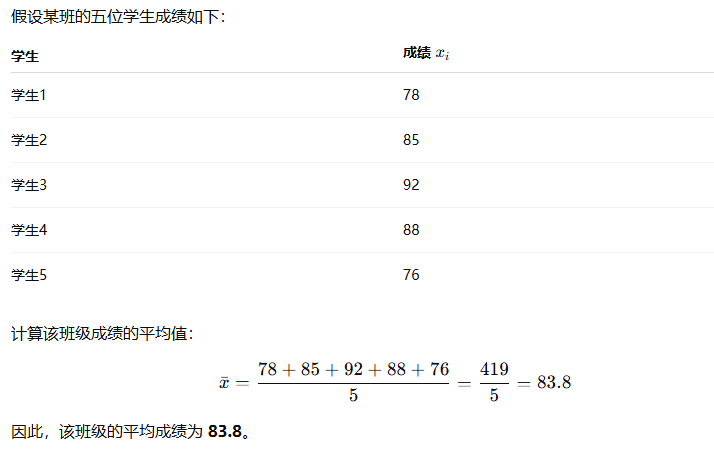
均值是描述数据集中水平的最常用指标,反映了特征的“典型值”。
它受到极端值(离群值)的影响较大,可能不完全代表数据的整体分布。
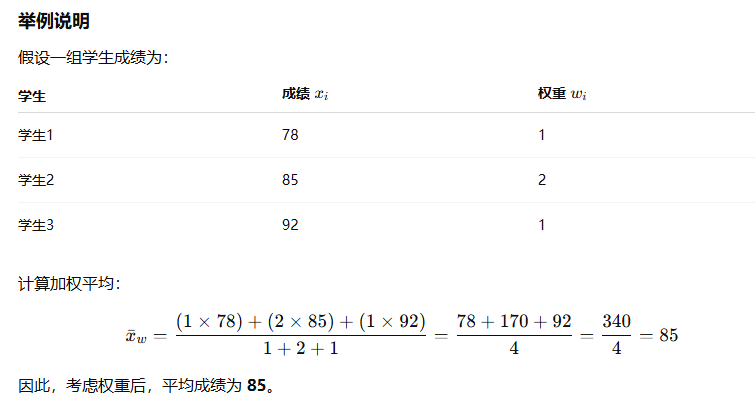
加权均值(Weighted Mean)

中位数
有偏(偏态)数据与中位数
定义:
偏态数据(Skewed Data)指的是数据在某一侧集中较多,形成偏向一端的分布。例如,大部分数据集中在较低值,带有一个长尾指向高值;或反之。
这类数据的特征是其分布非对称。
举例场景:
收入分布通常偏右(长尾在高收入端),平均值偏高,中位数更能代表典型收入水平;
房价也可能偏右,大部分房价集中在较低区间。

偏态数据常常导致平均值偏离数据的“中心”;
中位数是描述偏态数据集中趋势的更稳健指标。
众数
定义:
众数是指在一组数据中,出现频率最高的值。
它是描述离散型数据(类别或有限取值)的集中趋势最常用的指标。
特点:
仅适用于离散特征或类别数据,对连续型数据使用时,通常需要进行区间划分或离散化。
可以有一个众数(单峰),也可以有多个众数(多峰数据)。
多峰数据:当一组数据中有两个或多个值的频数都达到最大,且相等,即存在多个众数。
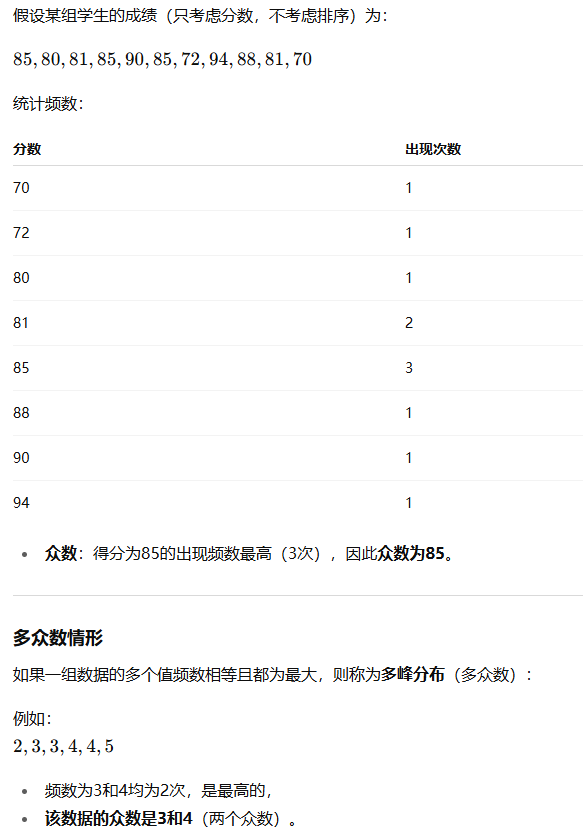
众数适用于离散变量,反映数据中最常出现的值。
在多峰数据中,存在多个众数。
由于对极端值不敏感,尤其适合类别型数据的集中趋势描述。
离中趋势
数据在某个特征上的离中趋势的主要度量指标包括:极差、方差、标准差、四分位极差等。
极差
定义:
极差是描述数据离散程度的最简单指标,表示数据中最大值与最小值之间的差距。
方差和标准差


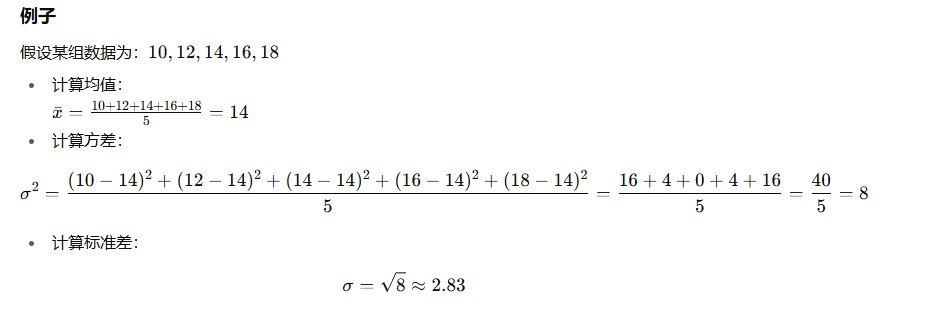
方差衡量数据的整体发散程度,单位是数据的平方单位。
标准差则更为直观,单位与原始数据相同,常用于描述数据的波动。
四分位极差
定义:
四分位数是将已排序的数据集分成四等份的三个值,分别对应百分比分位点,反映数据在不同位置的取值情况。
三个位点:
第1四分位数(Q1):将数据按升序排列后,位于数据下25%的位置点,即第25%的位置值,代表前25%的数据。
第2四分位数(Q2):即中位数,数据的中间值,代表50%的位置。
第3四分位数(Q3):位于数据的75%的位置点,代表前75%的数据。
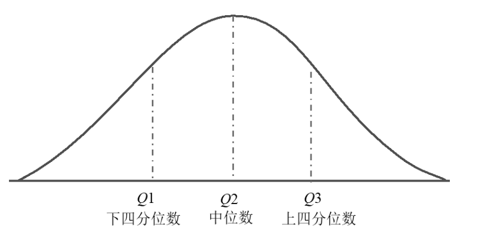

四分位数提供了数据在不同位置的取值,用以描述数据的分布形态。
四分位极差(IQR)衡量中间50%的数据分布宽度,具有抗离群点干扰的优点,是衡量数据离散的重要指标。
数据可视化
相关性与相似性
探索数据有两项非常重要的工作。
其一,观察数据的特征之间是否存在相关性,以便判断是否存在冗余特征,或者观察特征和目标变量之间是否相关性,以便为特征工程提供依据。
其二,许多数据挖掘模型的工作依赖于对数据之间相似性的计算。例如,给定两个数据对象,如何评价它们是否是相似对象等。
数据相关性度量
相关性是数据不同特征之间相关关系的度量,也即一个特征的取值随着另外一个特征取值的变化情况。常用的相关性度量方法包括:协方差、皮尔逊 (Pearson)相关系数、斯皮尔曼(Spearman)相关系数、肯德尔(Kendall)相关系数等




| 相关性指标 | 适用场景 | 特点 | 取值范围 |
|---|---|---|---|
| 协方差 | 两变量的线性关系 | 量纲依赖,容易受到尺度影响 | − ∞ , + ∞ -\infty, +\infty −∞,+∞ |
| 皮尔逊 | 连续变量线性关系 | 易受极端值影响,但直观明了 | [ − 1 , 1 ] [-1,1] [−1,1] |
| 斯皮尔曼 | 单调关系,非线性 | 稳健,基于秩 | [ − 1 , 1 ] [-1,1] [−1,1] |
| 肯德尔 | 小样本或重复值多时 | 稳健,秩相关性 | [ − 1 , 1 ] [-1,1] [−1,1] |
数据相似性度量
相似性是度量数据对象之间相似程度的方法,它是聚类、推荐等数据挖掘模型的核心概念之一。 不同类型的数据有对应的相似性度量指标:针对二元特征的杰卡德相似系数(Jaccard) 针对文档数据的余弦相似度(Cosine) 针对数值特征的各种距离度量(Distance),如:欧式距离(Euclidean distance)、马氏距离(Mahalanobis distance)、曼哈顿距离(Manhattan distance)、切比雪夫距离(Chebyshev distance)等。



| 数据类型 | 相似性/距离指标 | 说明 | 取值范围 |
|---|---|---|---|
| 二元(布尔)特征 | 杰卡德相似系数(Jaccard) | 公共比例 | [0,1] |
| 文档(向量) | 余弦相似度(Cosine) | 夹角余弦 | [-1,1](实际多用[0,1]) |
| 数值型特征 | 欧式距离(Euclidean) | 大小距离 | [0,+\infty) |
| 数值型特征 | 马氏距离(Mahalanobis) | 相关尺度调整距离 | [0,+\infty) |
| 数值型特征 | 曼哈顿距离(Manhattan) | 网格路径距离 | [0,+\infty) |
| 数值型特征 | 切比雪夫距离(Chebyshev) | 最大单维差异 | [0,+\infty) |
练习题
选择题
题1.
在衡量两个二元特征对象相似程度时,常用的指标是:
A. 欧几里得距离
B. 杰卡德相似系数
C. 皮尔逊相关系数
D. 余弦相似度
答案: B. 杰卡德相似系数
题2.
两个文本向量的相似性常用的指标是:
A. 欧几里得距离
B. 马氏距离
C. 余弦相似度
D. 曼哈顿距离
答案: C. 余弦相似度
题3.
以下哪种距离指标适合用于衡量两个高维空间中点的最大单维差异?
A. 欧几里得距离
B. 马氏距离
C. 曼哈顿距离
D. 切比雪夫距离
答案: D. 切比雪夫距离
题4.
在进行特征相关性分析时,若两个连续变量的线性关系紧密,最合适的相关性指标是:
A. 肯德尔相关系数
B. 斯皮尔曼相关系数
C. 皮尔逊相关系数
D. 杰卡德相似系数
答案: C. 皮尔逊相关系数
题5.
在数据对象的相似性度量中,适用于考虑特征之间相关性和尺度多变量调整的距离是:
A. 欧式距离
B. 马氏距离
C. 余弦相似度
D. 杰卡德相似系数
答案: B. 马氏距离
案例集
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
iris = load_iris()
features = iris.data.T
plt.figure(figsize = (8,6), dpi=200)
plt.scatter(features[2], features[3]) #绘制散点图
plt.xlabel(iris.feature_names[2])
plt.ylabel(iris.feature_names[3])
plt.show()
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
iris = load_iris()
features = iris.data.T
plt.figure(figsize = (8,6), dpi = 200)
figure,axes = plt.subplots() #得到画板、轴
axes.boxplot(features[1], patch_artist = True) #描点上色
plt.ylabel(iris.feature_names[1])
plt.show() #图形展示
from sklearn.datasets import load_iris
import numpy as np
import matplotlib.pyplot as plt
iris = load_iris()
species = iris.target
cate_list = iris.target_names
lables, counts = np.unique(species, return_counts = True)
num_list = list(counts)
num_list
plt.bar(range(len(num_list)), num_list)
plt.xlabel("species") # 指定X轴描述信息
plt.ylabel("numbers") # 指定Y轴描述信息
plt.ylim(0,60) # 指定Y轴的高度
idx = np.arange(len(cate_list))
plt.xticks(idx,cate_list)
plt.show()
from sklearn.datasets import load_iris
import numpy as np
import matplotlib.pyplot as plt
iris = load_iris()
species = iris.target
cate_list = iris.target_names
lables, counts = np.unique(species, return_counts = True)
explode = [0, 0.1, 0] # 用于突出显示一个品种
colors = ['#7FFFD4', '#458B74', '#FFE4C4'] #自定义颜色
plt.axes(aspect='equal') # 将X,Y坐标轴标准化处理,设置饼图是正圆
plt.xlim(0, 3.8) # 控制X轴和Y轴的范围
plt.ylim(0, 3.8)
plt.pie(x = counts, # 绘图数据
explode = explode, # 用于突出显示一个品种
labels = cate_list, # 添加鸢尾花品种标签
colors = colors, # 设置饼图的自定义填充色
autopct = '%0.1f%%' ) # 设置显示扇形所占的比例
plt.show() # 显示图形
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris['data'], iris['target'], random_state=0)
iris_dataframe = pd.DataFrame(X_train, columns = iris.feature_names)
grr = pd.plotting.scatter_matrix(iris_dataframe,
c = y_train, # 设置不同品种鸢尾花的颜色
alpha = .8,
figsize = (15,15),
marker = 'o',
hist_kwds = {'bins':20}) # 频率直方图上的箱体数量
plt.show()
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
features = pd.DataFrame(iris.data, columns = iris.feature_names)
print('协方差的结果为:')
print(np.cov(features["petal length (cm)"], features["petal width (cm)"]))
print('pearson相关系数的结果为:')
print(features.iloc[:, [2, 3]].corr(method = "pearson"))
print('spearman相关系数的结果为:')
print(features.iloc[:, [2, 3]].corr(method = "spearman"))
print('kendall相关系数的结果为:')
print(features.iloc[:, [2, 3]].corr(method = "kendall"))

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)