基于大数据的青光眼数据可视化分析系统
传统毕设vs大数据项目:青光眼数据分析系统如何让导师眼前一亮?
🎓 作者:计算机毕设小月哥 | 软件开发专家
🖥️ 简介:8年计算机软件程序开发经验。精通Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等技术栈。
🛠️ 专业服务 🛠️
- 需求定制化开发
- 源码提供与讲解
- 技术文档撰写(指导计算机毕设选题【新颖+创新】、任务书、开题报告、文献综述、外文翻译等)
- 项目答辩演示PPT制作
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
大数据实战项目
PHP|C#.NET|Golang实战项目
微信小程序|安卓实战项目
Python实战项目
Java实战项目
🍅 ↓↓主页获取源码联系↓↓🍅
这里写目录标题
基于大数据的青光眼数据可视化分析系统-功能介绍
《基于大数据的青光眼数据可视化分析系统》是一套专门针对青光眼医疗数据进行深度挖掘和可视化展示的综合性平台。系统采用Hadoop分布式存储架构作为数据底层支撑,通过Spark大数据计算引擎对海量青光眼患者的临床数据进行高效处理和分析。系统前端基于Vue框架构建,结合ElementUI组件库和Echarts图表库,为用户提供直观友好的数据可视化界面。后端采用SpringBoot框架开发,通过Spark SQL实现对青光眼患者人口学特征、核心临床指标以及疾病风险因素的多维度统计分析。系统能够处理包括患者年龄、眼压、杯盘比、OCT检查结果等在内的多种医疗数据类型,通过Pandas和NumPy进行数据预处理,最终生成包括患者年龄构成分析、眼压与杯盘比相关性分析、家族史关联分析等多个维度的可视化报表,为青光眼的临床诊断和医学研究提供数据支持和决策参考。
基于大数据的青光眼数据可视化分析系统-选题背景意义
选题背景
青光眼作为全球第二大致盲性眼病,其早期诊断和治疗一直是眼科医学领域的重要课题。随着医疗信息化水平的不断提升,各类眼科医院和诊所积累了大量青光眼患者的临床数据,包括眼压测量、杯盘比检查、光学相干断层扫描等多种检查结果。这些数据蕴含着丰富的医学信息和规律,但由于数据量庞大、格式复杂、存储分散,传统的数据处理方式已难以满足深度分析的需求。同时,现有的医疗数据分析工具多为通用型软件,缺乏针对青光眼这一特定疾病的专业化分析功能,无法充分挖掘数据中的潜在价值。医生在临床工作中往往需要花费大量时间进行数据整理和分析,影响了诊疗效率。因此,开发一套专门针对青光眼数据的大数据分析和可视化系统,既能解决数据处理的技术难题,又能为临床医学研究提供有力工具。
选题意义
本课题的研究具有一定的理论价值和实际意义。在技术层面,通过将Hadoop和Spark等大数据技术应用于医疗数据处理,探索了大数据技术在垂直医疗领域的应用模式,为类似的医疗数据分析项目提供了技术参考。系统设计的多维度数据分析框架,包括患者人口学特征、临床指标关联性、风险因素识别等分析模块,在一定程度上丰富了医疗数据挖掘的方法体系。在实际应用方面,系统能够帮助医生更快速地识别患者数据中的关键信息,通过可视化图表直观展示数据规律,提升临床决策的效率和准确性。系统的多维度分析功能可以辅助医生发现不同患者群体的特征差异,为个性化诊疗方案的制定提供数据支撑。对于医学研究人员而言,系统提供的统计分析功能可以帮助他们更好地开展青光眼流行病学研究,挖掘疾病发病规律。虽然作为毕业设计项目,系统在功能完善性和数据规模处理能力方面还有待提升,但其基本架构和核心功能设计为今后的进一步开发奠定了良好基础。
基于大数据的青光眼数据可视化分析系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL
基于大数据的青光眼数据可视化分析系统-视频展示
传统毕设vs大数据项目:青光眼数据分析系统如何让导师眼前一亮?
基于大数据的青光眼数据可视化分析系统-图片展示
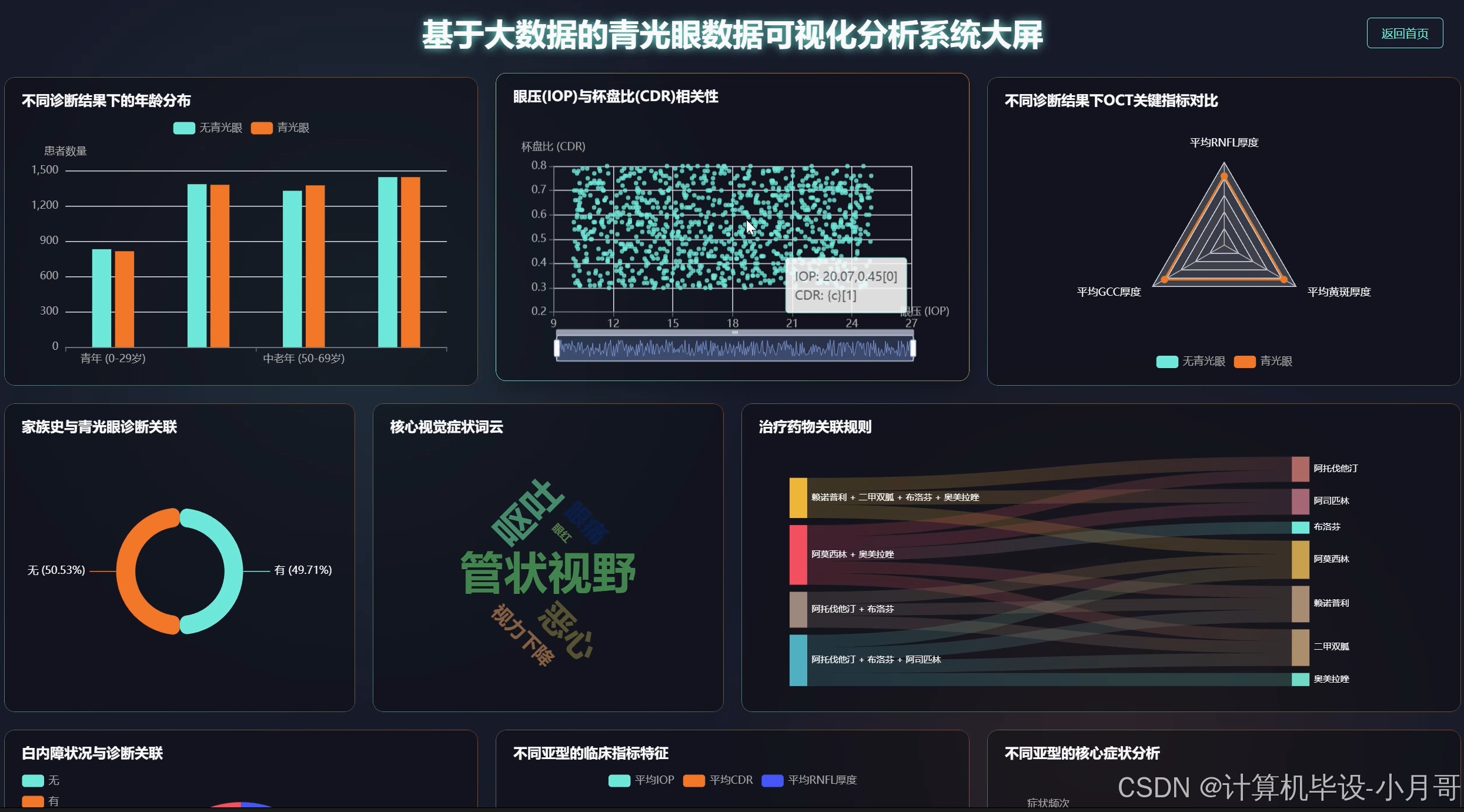
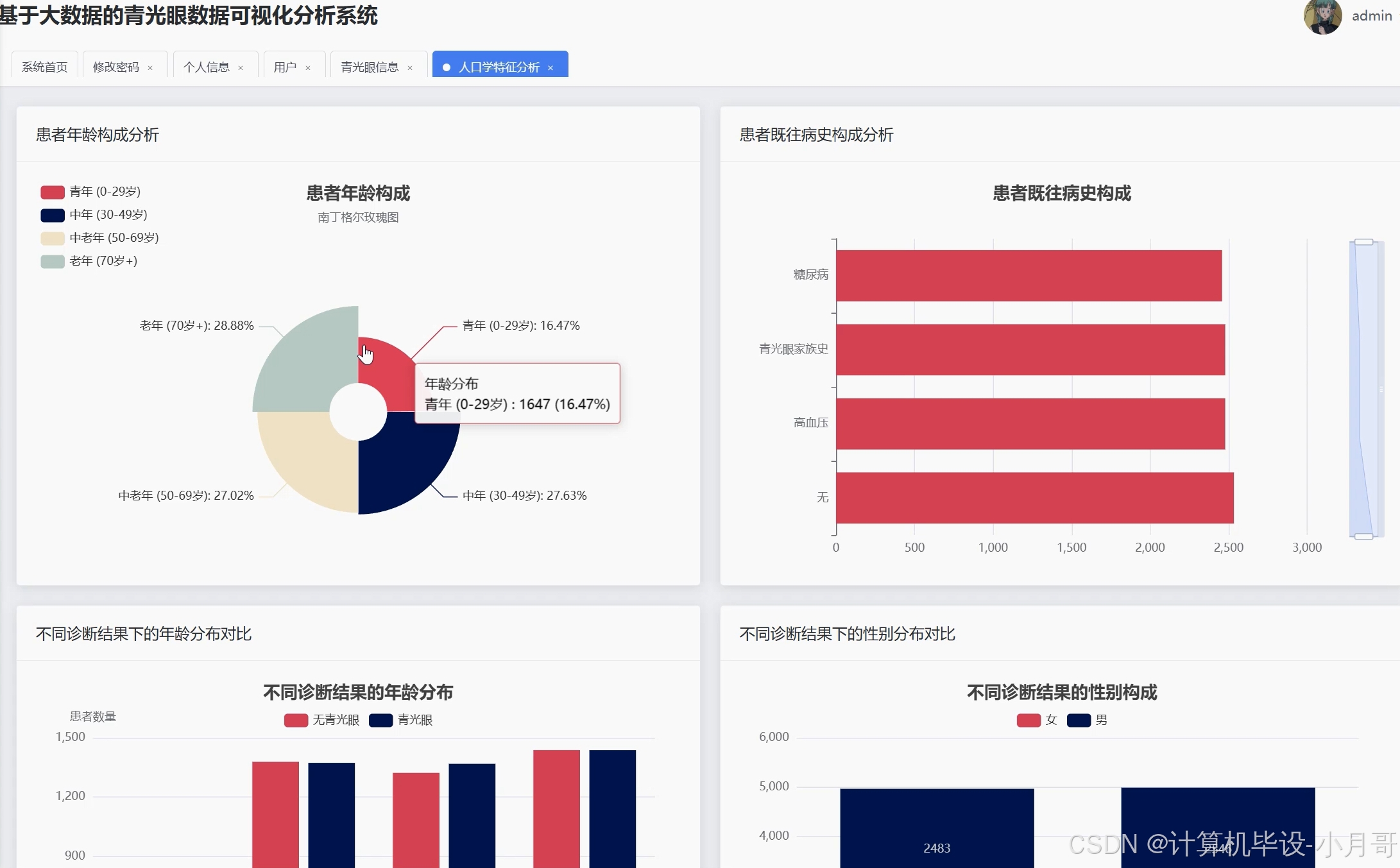
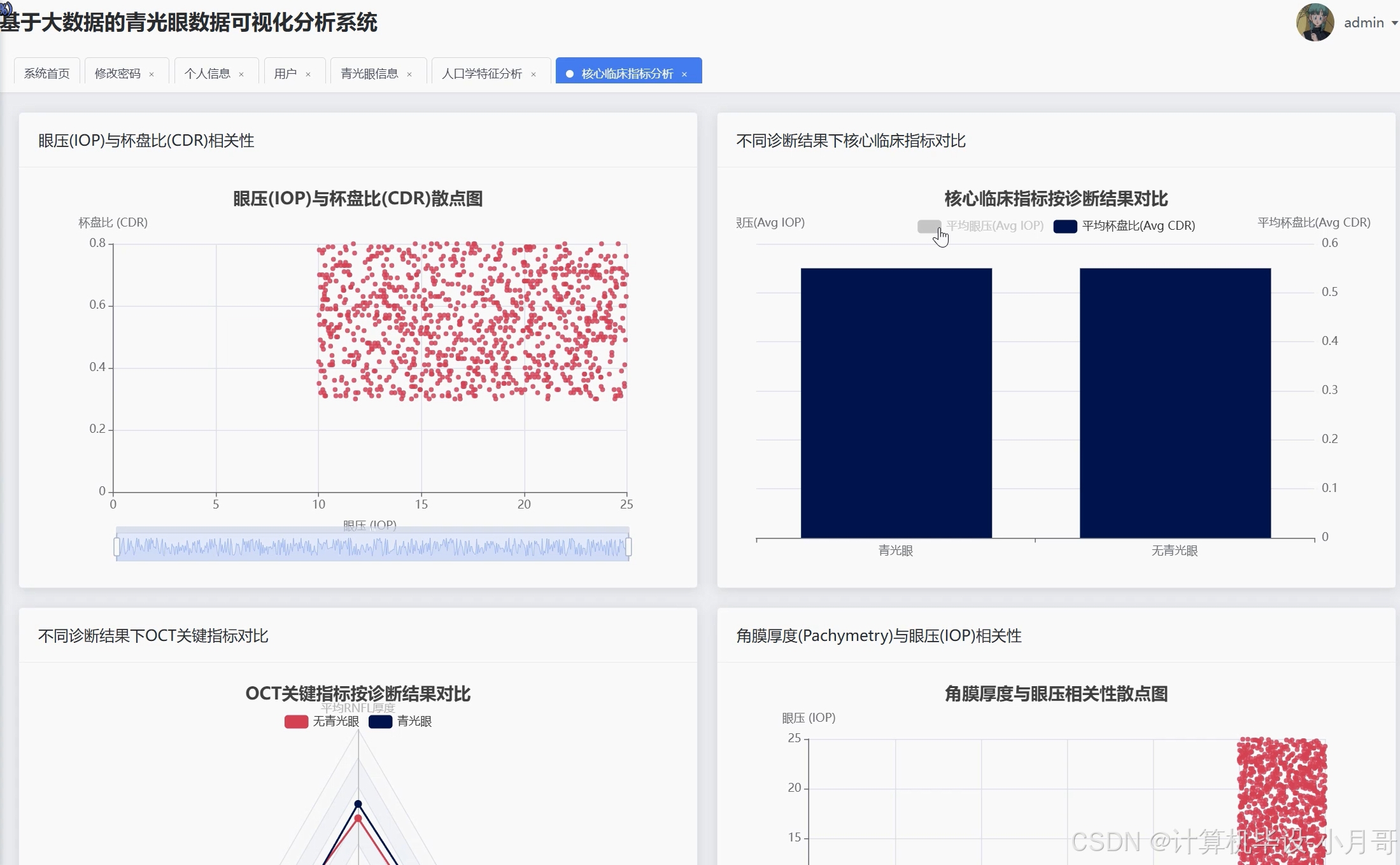

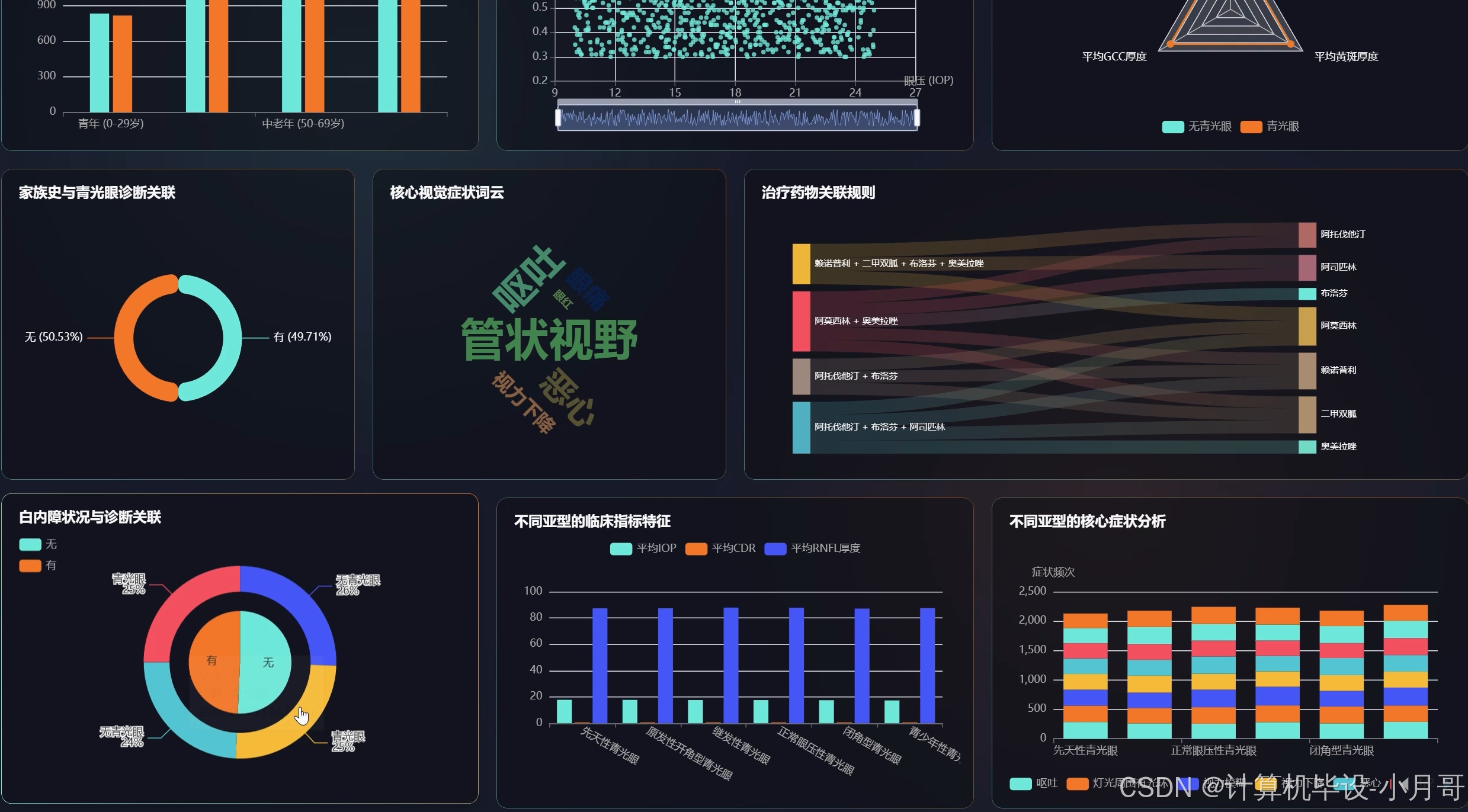
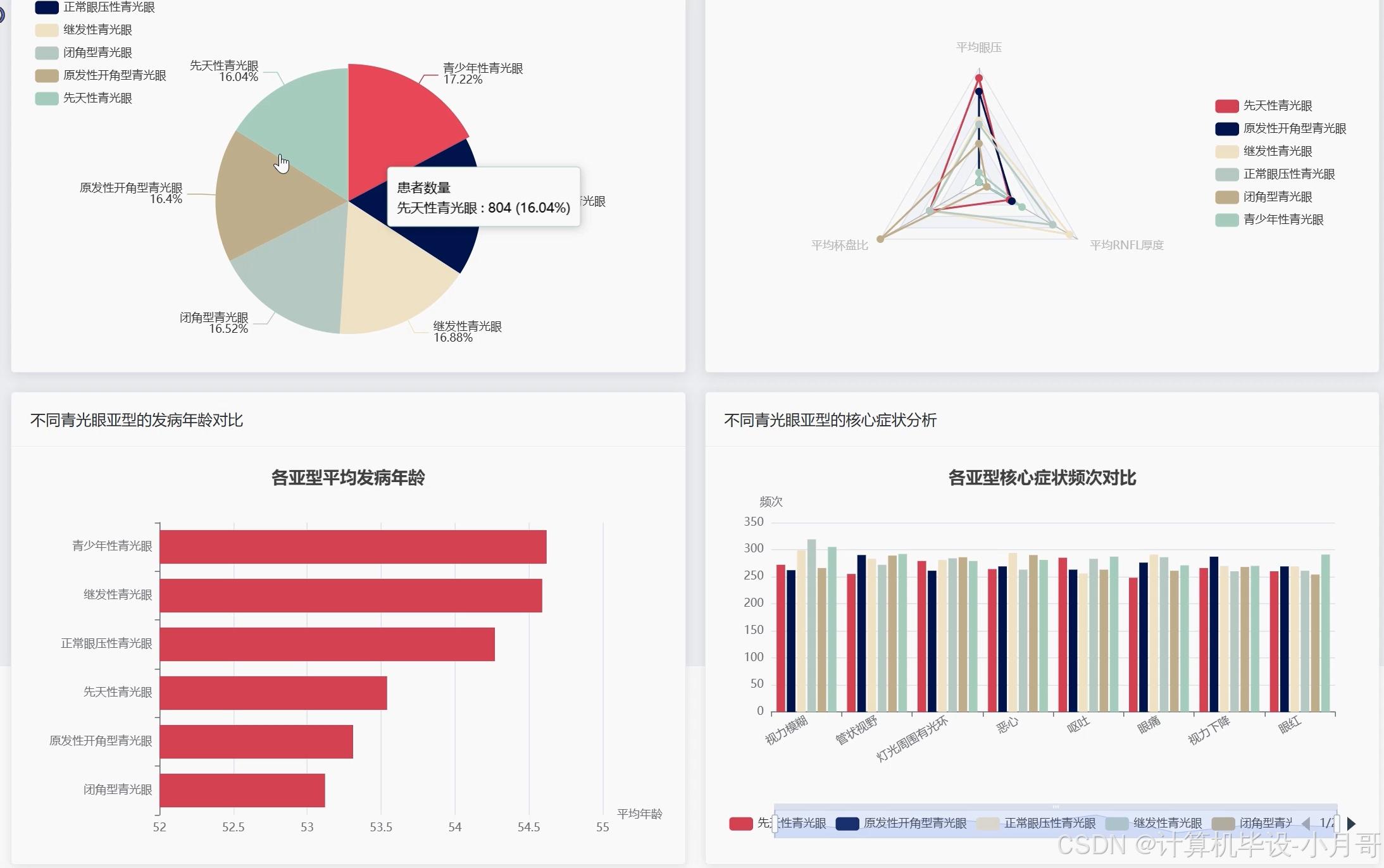
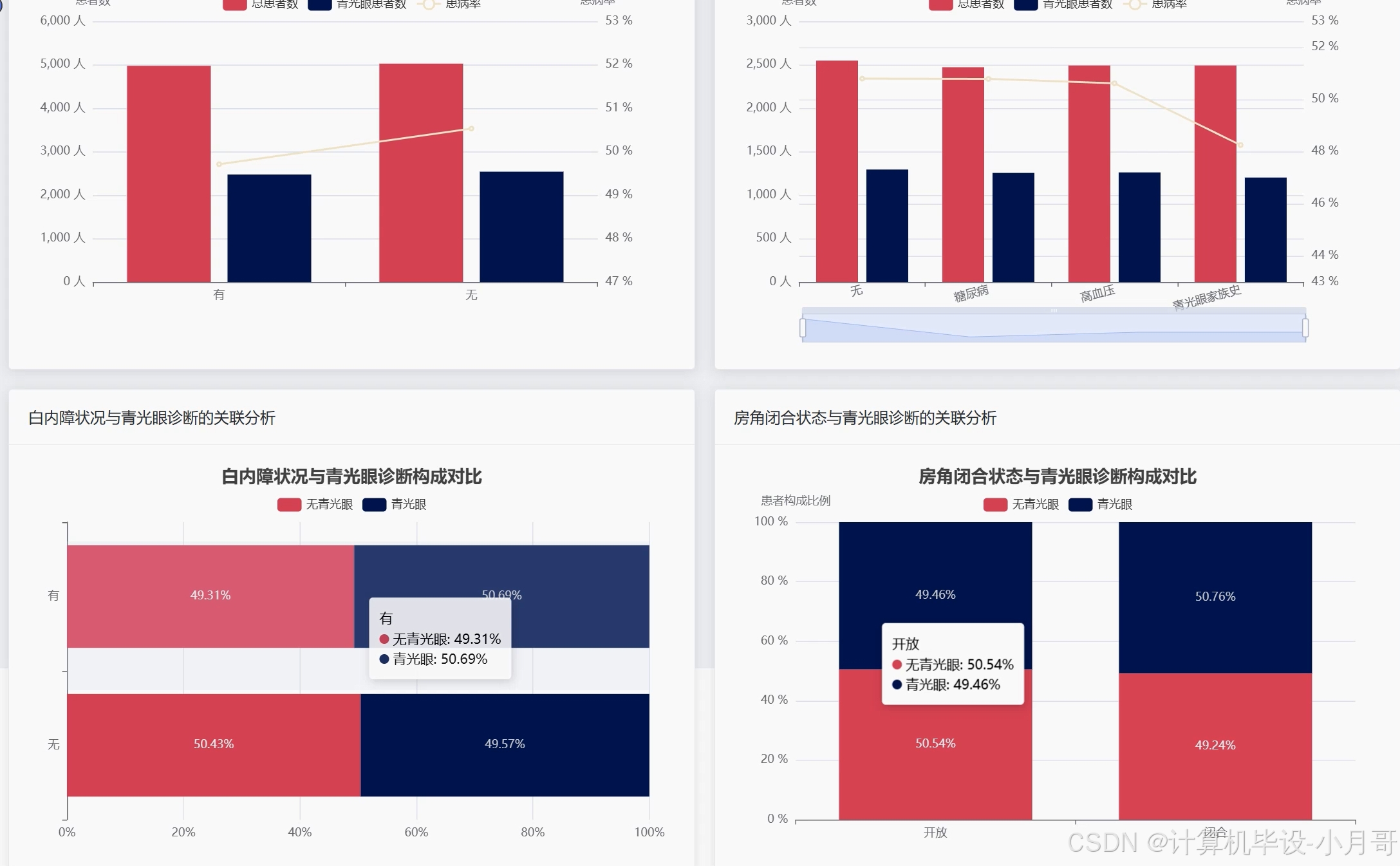
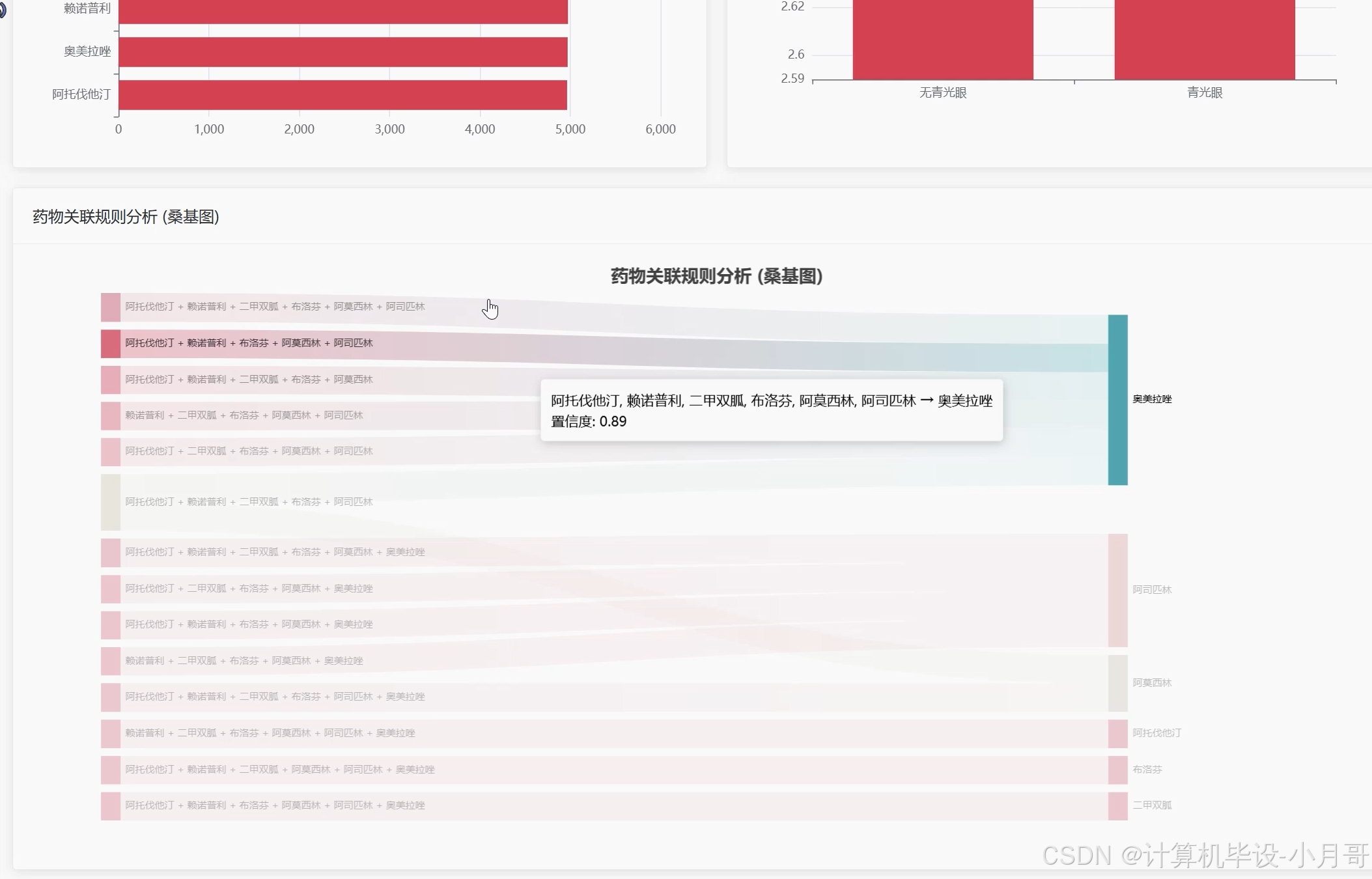
基于大数据的青光眼数据可视化分析系统-代码展示
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.functions;
import static org.apache.spark.sql.functions.*;
import org.springframework.web.bind.annotation.*;
import java.util.*;
@RestController
@RequestMapping("/glaucoma")
public class GlaucomaAnalysisController {
private SparkSession spark = SparkSession.builder()
.appName("GlaucomaDataAnalysis")
.master("local[*]")
.config("spark.sql.adaptive.enabled", "true")
.getOrCreate();
@PostMapping("/patientDemographics")
public Map<String, Object> analyzePatientDemographics() {
Dataset<Row> glaucomaData = spark.read()
.option("header", "true")
.option("inferSchema", "true")
.csv("/data/glaucoma_patients.csv");
Dataset<Row> ageGroups = glaucomaData
.withColumn("age_group",
when(col("Age").lt(30), "青年")
.when(col("Age").between(30, 50), "中年")
.otherwise("老年"))
.groupBy("age_group", "Diagnosis")
.count()
.orderBy("age_group");
Dataset<Row> genderAnalysis = glaucomaData
.groupBy("Gender", "Diagnosis")
.agg(count("*").as("patient_count"),
avg("Age").as("avg_age"),
avg("Intraocular_Pressure").as("avg_iop"))
.orderBy("Gender", "Diagnosis");
Dataset<Row> medicalHistoryStats = glaucomaData
.filter(col("Medical_History").isNotNull())
.groupBy("Medical_History", "Diagnosis")
.count()
.withColumn("percentage",
round(col("count") * 100.0 / sum("count").over(), 2))
.orderBy(desc("count"));
Map<String, Object> result = new HashMap<>();
result.put("ageDistribution", ageGroups.collectAsList());
result.put("genderAnalysis", genderAnalysis.collectAsList());
result.put("medicalHistory", medicalHistoryStats.collectAsList());
return result;
}
@PostMapping("/clinicalIndicators")
public Map<String, Object> analyzeClinicalIndicators() {
Dataset<Row> glaucomaData = spark.read()
.option("header", "true")
.option("inferSchema", "true")
.csv("/data/glaucoma_patients.csv");
Dataset<Row> iopCdrCorrelation = glaucomaData
.select("Intraocular_Pressure", "Cup_to_Disc_Ratio", "Diagnosis")
.filter(col("Intraocular_Pressure").isNotNull()
.and(col("Cup_to_Disc_Ratio").isNotNull()));
double correlationCoeff = iopCdrCorrelation.stat()
.corr("Intraocular_Pressure", "Cup_to_Disc_Ratio");
Dataset<Row> diagnosticComparison = glaucomaData
.groupBy("Diagnosis")
.agg(avg("Intraocular_Pressure").as("avg_iop"),
avg("Cup_to_Disc_Ratio").as("avg_cdr"),
avg("RNFL_Thickness").as("avg_rnfl"),
avg("GCC_Thickness").as("avg_gcc"),
count("*").as("patient_count"))
.orderBy("Diagnosis");
Dataset<Row> iopLevels = glaucomaData
.withColumn("iop_level",
when(col("Intraocular_Pressure").lt(12), "低眼压")
.when(col("Intraocular_Pressure").between(12, 21), "正常眼压")
.otherwise("高眼压"))
.groupBy("iop_level")
.agg(avg("Cup_to_Disc_Ratio").as("avg_cdr"),
count("*").as("count"),
sum(when(col("Diagnosis").equalTo("确诊青光眼"), 1)
.otherwise(0)).as("glaucoma_cases"))
.withColumn("glaucoma_rate",
round(col("glaucoma_cases") * 100.0 / col("count"), 2))
.orderBy("iop_level");
Dataset<Row> pachymetryIopRelation = glaucomaData
.filter(col("Pachymetry").isNotNull()
.and(col("Intraocular_Pressure").isNotNull()))
.withColumn("pachymetry_group",
when(col("Pachymetry").lt(520), "薄角膜")
.when(col("Pachymetry").between(520, 580), "正常角膜")
.otherwise("厚角膜"))
.groupBy("pachymetry_group")
.agg(avg("Intraocular_Pressure").as("avg_iop"),
avg("Pachymetry").as("avg_pachymetry"),
count("*").as("count"))
.orderBy("pachymetry_group");
Map<String, Object> result = new HashMap<>();
result.put("iopCdrCorrelation", correlationCoeff);
result.put("correlationData", iopCdrCorrelation.collectAsList());
result.put("diagnosticStats", diagnosticComparison.collectAsList());
result.put("iopLevelAnalysis", iopLevels.collectAsList());
result.put("pachymetryAnalysis", pachymetryIopRelation.collectAsList());
return result;
}
@PostMapping("/riskFactors")
public Map<String, Object> analyzeRiskFactors() {
Dataset<Row> glaucomaData = spark.read()
.option("header", "true")
.option("inferSchema", "true")
.csv("/data/glaucoma_patients.csv");
Dataset<Row> familyHistoryAnalysis = glaucomaData
.groupBy("Family_History")
.agg(count("*").as("total_patients"),
sum(when(col("Diagnosis").equalTo("确诊青光眼"), 1)
.otherwise(0)).as("glaucoma_cases"))
.withColumn("glaucoma_rate",
round(col("glaucoma_cases") * 100.0 / col("total_patients"), 2))
.orderBy(desc("glaucoma_rate"));
Dataset<Row> medicalHistoryRisk = glaucomaData
.filter(col("Medical_History").isNotNull())
.groupBy("Medical_History")
.agg(count("*").as("total_patients"),
sum(when(col("Diagnosis").equalTo("确诊青光眼"), 1)
.otherwise(0)).as("glaucoma_cases"),
avg("Age").as("avg_age"),
avg("Intraocular_Pressure").as("avg_iop"))
.withColumn("glaucoma_rate",
round(col("glaucoma_cases") * 100.0 / col("total_patients"), 2))
.filter(col("total_patients").geq(10))
.orderBy(desc("glaucoma_rate"));
Dataset<Row> cataractGlaucomaRelation = glaucomaData
.groupBy("Cataract_Status", "Diagnosis")
.count()
.withColumn("percentage",
round(col("count") * 100.0 /
sum("count").over(window().partitionBy("Cataract_Status")), 2))
.orderBy("Cataract_Status", "Diagnosis");
Dataset<Row> angleClosureAnalysis = glaucomaData
.filter(col("Angle_Closure_Status").isNotNull())
.groupBy("Angle_Closure_Status")
.agg(count("*").as("total_patients"),
sum(when(col("Diagnosis").equalTo("确诊青光眼"), 1)
.otherwise(0)).as("glaucoma_cases"),
avg("Intraocular_Pressure").as("avg_iop"),
avg("Cup_to_Disc_Ratio").as("avg_cdr"))
.withColumn("glaucoma_rate",
round(col("glaucoma_cases") * 100.0 / col("total_patients"), 2))
.orderBy(desc("glaucoma_rate"));
Dataset<Row> riskFactorCombination = glaucomaData
.withColumn("risk_score",
when(col("Family_History").equalTo("有"), 1).otherwise(0) +
when(col("Medical_History").contains("糖尿病"), 1).otherwise(0) +
when(col("Medical_History").contains("高血压"), 1).otherwise(0) +
when(col("Age").gt(60), 1).otherwise(0))
.groupBy("risk_score")
.agg(count("*").as("total_patients"),
sum(when(col("Diagnosis").equalTo("确诊青光眼"), 1)
.otherwise(0)).as("glaucoma_cases"))
.withColumn("glaucoma_rate",
round(col("glaucoma_cases") * 100.0 / col("total_patients"), 2))
.orderBy("risk_score");
Map<String, Object> result = new HashMap<>();
result.put("familyHistoryRisk", familyHistoryAnalysis.collectAsList());
result.put("medicalHistoryRisk", medicalHistoryRisk.collectAsList());
result.put("cataractRelation", cataractGlaucomaRelation.collectAsList());
result.put("angleClosureRisk", angleClosureAnalysis.collectAsList());
result.put("riskCombination", riskFactorCombination.collectAsList());
return result;
}
}
基于大数据的青光眼数据可视化分析系统-结语
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
大数据实战项目
PHP|C#.NET|Golang实战项目
微信小程序|安卓实战项目
Python实战项目
Java实战项目
🍅 ↓↓主页获取源码联系↓↓🍅

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 24
24 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)