基于 python+大数据的农作物产量数据分析与可视化系统
本文介绍了一个基于Python+大数据的农作物产量数据分析与可视化系统。该系统集成了Spark、Hadoop、Django、Vue等技术框架,采用MySQL数据库,旨在解决传统农业依赖经验判断的问题。系统通过五大分析维度(地理环境、农业措施、作物种类、气候条件等)24个具体项目,利用机器学习算法挖掘数据规律,并以Echarts可视化图表直观展示分析结果。系统实现了从数据采集、处理、分析到可视化展示
1.开发环境
发语言:python
采用技术:Spark、Hadoop、Django、Vue、Echarts等技术框架
数据库:MySQL
开发环境:PyCharm
2 系统设计
随着全球人口持续增长和气候变化加剧,农业生产面临着前所未有的挑战,如何提高农作物产量、优化种植结构成为各国政府和农业从业者关注的焦点问题。传统农业生产主要依靠经验判断和简单统计分析,难以准确把握复杂的农业生产规律,特别是在面对多变的气候条件、不同的土壤类型、各种农业投入措施时,缺乏科学有效的数据分析手段。近年来,大数据技术和机器学习算法在各个领域得到广泛应用,为农业数据分析提供了新的技术路径。农业部门积累了大量的生产数据,包括不同区域的作物产量、气候条件、土壤特征、农业措施等信息,这些数据蕴含着丰富的农业生产规律,但由于数据量大、维度复杂,传统分析方法难以有效处理。基于 python+大数据的农作物产量数据分析与可视化系统能够充分挖掘这些数据价值,为农业生产决策提供科学依据,这也是本课题选择农作物产量数据分析作为研究对象的主要背景。
本课题通过构建基于 python+大数据的农作物产量数据分析与可视化系统,能够在一定程度上为农业生产实践提供参考价值。系统通过对历史产量数据的深入分析,可以帮助了解不同地区、不同作物的产量特点和影响因素,为种植户在选择作物品种、制定种植计划时提供一些数据支持。通过分析化肥、灌溉等农业措施的效果,能够为农业投入决策提供量化参考,在一定程度上帮助提高资源利用效率。系统的可视化功能使复杂的数据分析结果更加直观易懂,便于农业管理人员和种植户理解和应用。从技术角度来看,本课题将大数据处理技术与农业领域相结合,为相关专业学生提供了实践机会,有助于加深对Spark、Hadoop、机器学习等技术的理解和应用能力。虽然作为毕业设计项目,系统的规模和功能相对有限,但通过这个实践过程,能够培养运用现代信息技术解决实际问题的能力,为今后从事相关工作积累一定的经验基础。
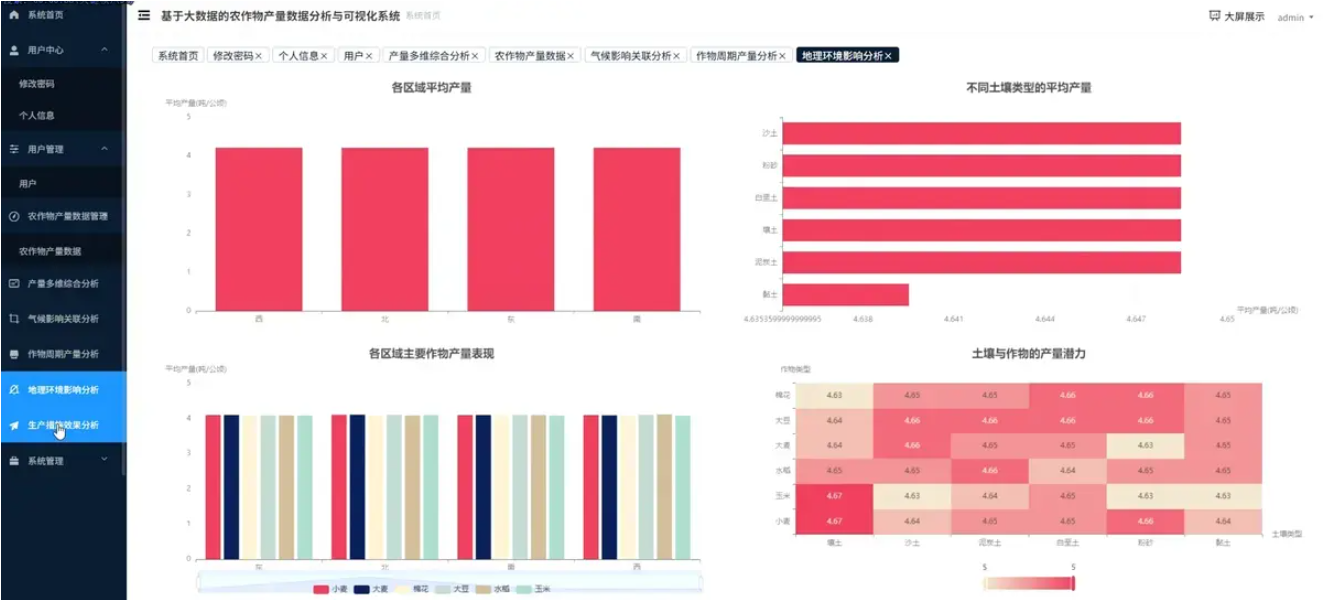
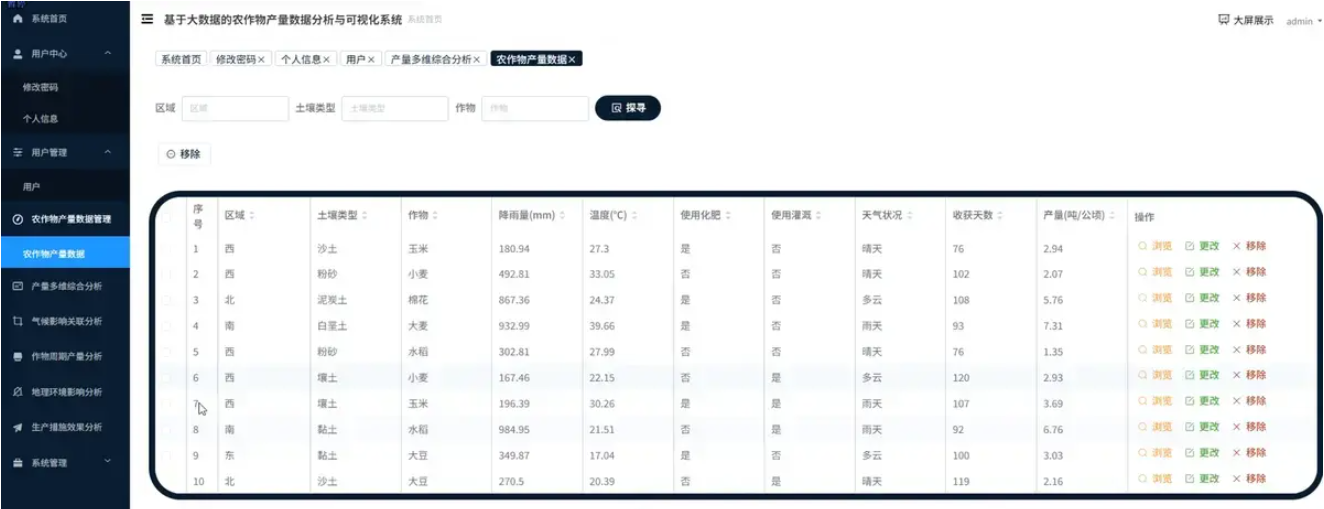
基于 python+大数据的农作物产量数据分析与可视化系统是一套完整的大数据处理与分析解决方案,该系统采用Python作为主要开发语言,集成Spark分布式计算框架和Hadoop生态系统,专门针对农作物产量数据进行深度挖掘与智能分析。系统核心功能涵盖五大分析维度:地理环境因素对产量的影响分析、农业生产措施的效益分析、作物种类与生长周期分析、气候条件影响分析以及多维度综合下探与模式挖掘,通过24个具体分析项目全面解析农作物产量的影响因素和变化规律。在技术架构上,系统利用Hadoop分布式文件系统存储海量农业数据,通过Spark强大的内存计算能力实现快速数据处理,结合机器学习算法挖掘技术挖掘隐藏在数据背后的关联规律。前端采用Vue框架构建用户交互界面,集成Echarts可视化库生成丰富的图表展示,包括区域产量对比图、作物生长周期分析图、气候因素关联热力图等多种可视化形式,直观展现分析结果。数据存储采用MySQL数据库,确保数据的持久化和高效查询,整个系统从数据采集、清洗、分析到可视化展示形成完整的数据处理流水线,为农业决策者提供科学的数据支撑和智能化的分析工具。
3 系统展示
3.1 大屏页面
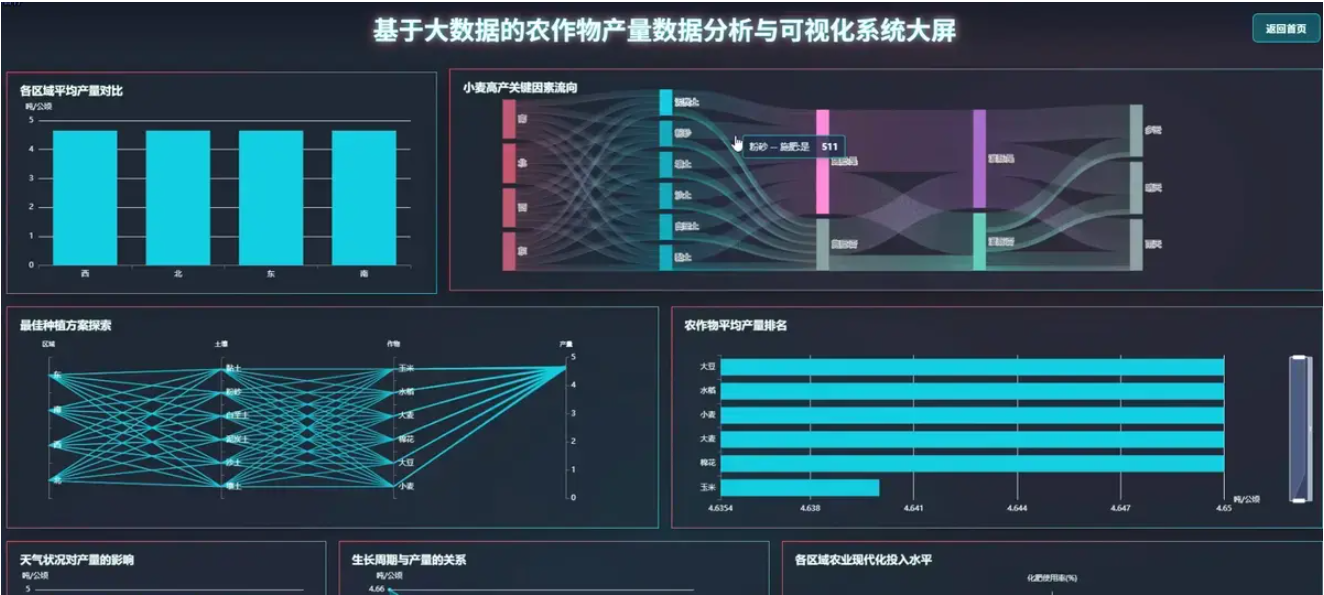
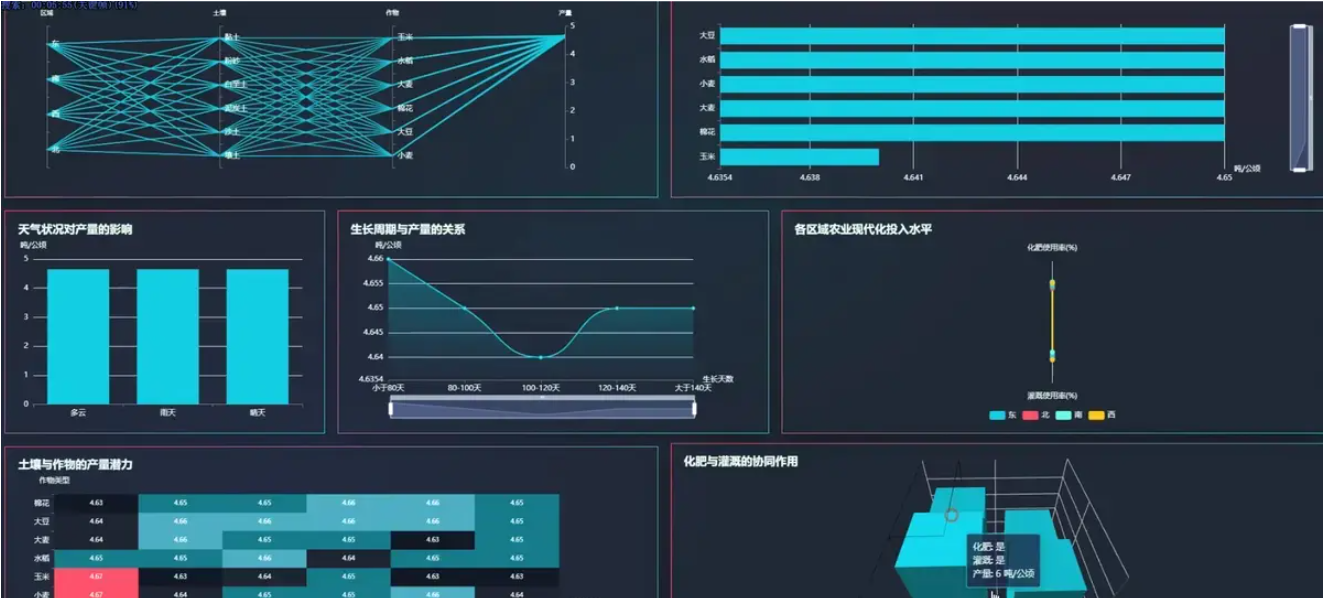
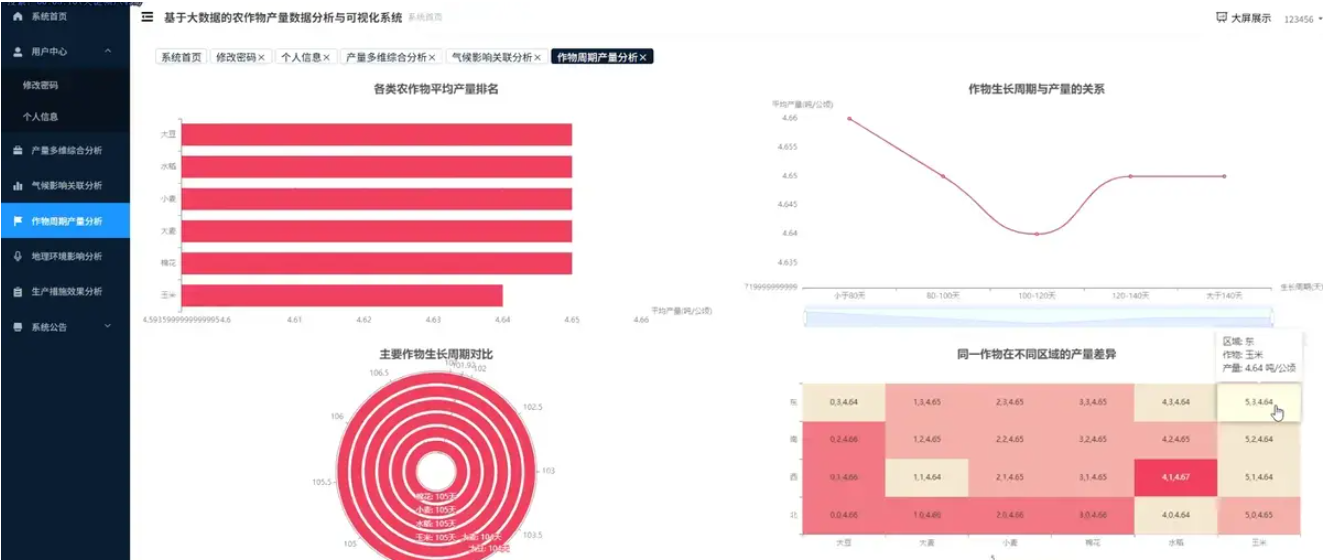
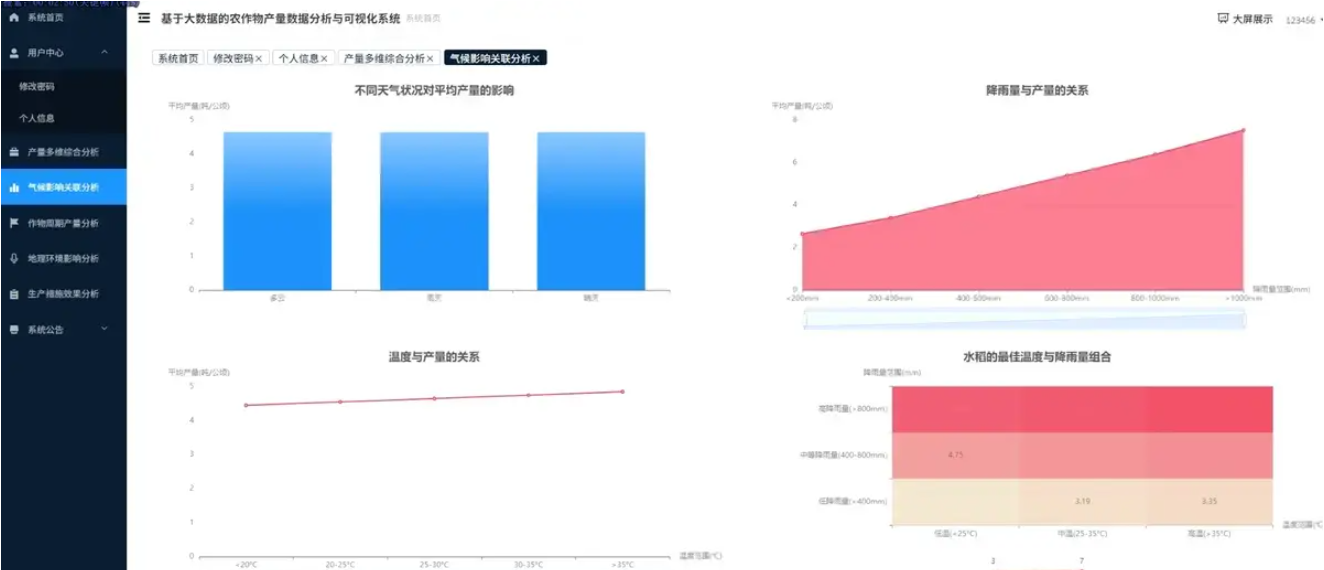

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)