[智能算法]DARTS-可微的神经网络结构搜索
一、概述
相较于传统方法,DARTS(Differentiable Architecture Search)的结构表述是连续的,允许模型使用随机梯度下降(SGD)的方式高效的进行结构探索。DARTS能在丰富的搜索空间内学习具有复杂图形拓扑的高性能结构体系,其可以用于卷积网络或循环网络,不拘泥于具体的模型形式,同时可以用较少的计算资源来实现与最先进算法媲美的性能。
二、模型
2.1搜索空间
DARTS的搜索空间如下图所示,每个单元的计算过程可以被表述为一个有向无环图。假设一个单元有N个节点,每个节点记作,每条边表述为
,每条边的操作记作
,于是两个节点之间的传递关系可以被写作公式:
,另外这个递归式还包含了一个特殊的零操作。
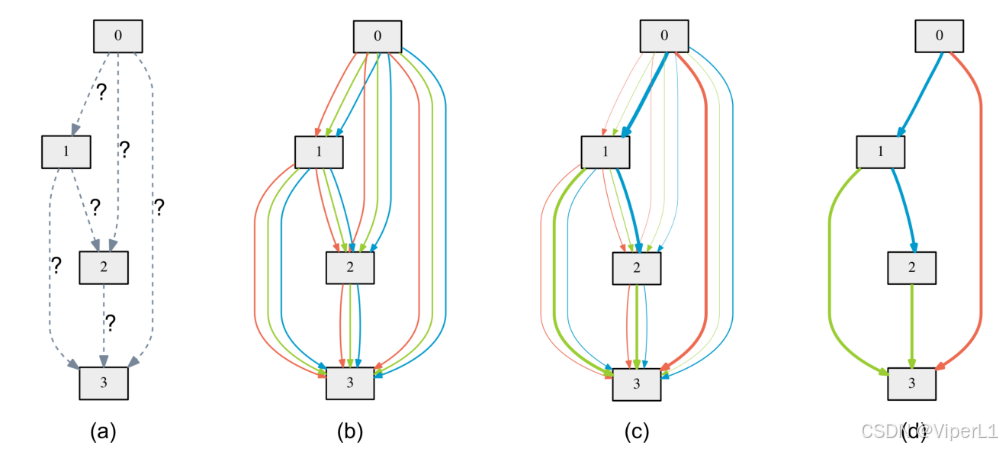
上图为每个单元通路的可视化,图(a)表示单元内每个节点的通路都是位置的;(b)表示这些节点可能的通路,(c)和(d)则表示选择好之后的通路。
2.2连续松弛和优化
将候选运算组记作O(候选运算组包含卷积、池化等运算),每个运算函数表述为
。为了使搜索空间连续,选择操作被设置为Softmax,于是操作(i,j)可以被描述为:
其中,对于节点(i,j)而言有向量,于是可以将一个结构探索任务表述为
,在搜索结束时,将每个混合计算
替换为可能计算
。
模型的目标是联合学习结构和权重
,分别使用
和
来表示训练损失和验证损失,又由于网络中权重
也是不确定的,这两个损失函数分别记作:
和
,所以该问题便变为了一个双层优化问题:
这个嵌套公式同样可以使用基于梯度下降的超参数优化中。其计算流程如下:
创建每条边(i,j)对应的操作o(i,j)和向量a(i,j)
while:
1.通过让L_val下降,更新结构a
2.通过让L_train下降,更新权重w2.3近似梯度优化
由于存在一个嵌套的双层优化问题,模型内部梯度的复杂度极高,作为替代,本文提出了一个近似梯度优化方案。
在上式中,表示当前模型权重,
为学习率;通过训练
来 逼近
可以简化梯度下降的计算复杂度。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)