Python数据分析与应用
这篇博客是我学习Python数据分析的总结,算是对我学习的一种记录,方便以后回顾和复习。文中所用到的案例资源已上传,欢迎大家下载学习。
Python数据分析与应用
这篇博客是我学习Python数据分析的总结,算是对我学习的一种记录,方便以后回顾和复习。文中所用到的案例资源已上传到我的资源(免费),欢迎大家下载学习。
一. 数据分析基础
1. 数据分析概论
数据分析是结合数学、统计学理论的科学统计分析方法,对Excel数据、数据库中的数据、收集的大量数据、网页抓取的数据进行分析,从中提取有价值的信息并形成结论进行展示的过程。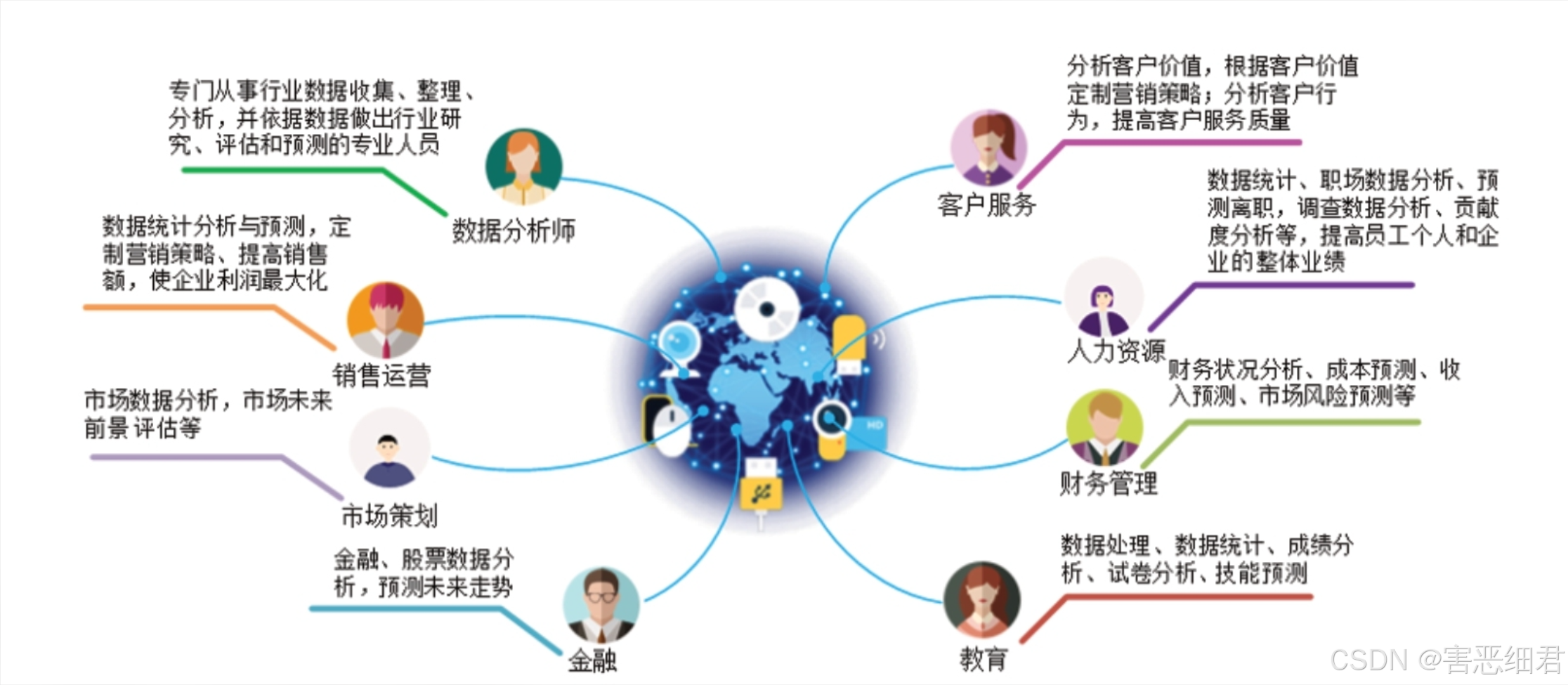
数据分析的基本流程:下图展示了数据分析的基本流程,其中数据分析的重要环节是明确目的,这也是做数据分析最有价值的部分。
2. 搭建Python数据分析环境
Anaconda是适合数据分析的Python开发环境,是一个开源的Python发行版本,其中包含了conda(包管理和环境管理)、Python等180多个科学包及其依赖项。
(1) 下载Anaconda
Anaconda的官网地址为:https://www.anaconda.com/
(2) 安装Anaconda
下载完成后,开始安装Anaconda,具体步骤如下。
如果是Windows操作系统,注意在安装Anaconda软件的时候,通过鼠标右键单击安装文件,然后选择“以管理员身份运行”。然后单击“Next”按钮进入安装协议页面。然后单击“IAgree”按钮接受协议,选择安装类型,等待安装。
安装完成后,系统开始菜单中会新增一个名为Anaconda3(64-bit)的文件夹,在该文件夹下会显示增加的程序,这就表示Anaconda已经安装成功,如下图所示。
在“开始”菜单中单击Anaconda3(64-bit)文件夹中的Jupyter Notebook,会弹出一个黑框,表示准备运行Jupyter Notebook。之后会打开如下图所示的Jupyter Notebook页面,这说明环境已经配置好了。
(3) Jupyter Notebook开发工具
为什么说Jupyter Notebook是文学式开发工具呢?因为Jupyter Notebook将代码、说明文本、数学方程式、可视化数据分析图表等内容全部组合到一起显示在一个共享的文档中,可以实现一边写代码一边记录的功能,而这些功能是Python自带的IDLE和集成开发环境PyCharm无法比拟的。
Jupyter Notebook是一个在线编辑器及Web应用程序,它可以在线编写代码,创建和共享文档,支持实时编写代码、数学方程式、说明文本和可视化数据分析图表。
Jupyter Notebook的用途包括数据清理、数据转换、数值模拟、统计建模等。目前,数据挖掘领域中最热门的比赛Kaggle(举办机器学习竞赛、托管数据库、编写和分享代码的平台)里的资料都是Jupyter格式的。对于机器学习新手来说,学会使用Jupyter Notebook非常重要。
在系统“开始”菜单的搜索框输入Jupyter Notebook(不区分大小写),运行Jupyter Notebook,新建一个Jupyter Notebook文件,单击右上角的“New”按钮,由于我们创建的是Python文件,因此选择Python3。
然后就可以编写代码了
单击“运行”按钮或者使用快捷键<Ctrl+Enter>
最后一步保存Jupyter Notebook文件,也就是保存程序。常用格式有两种,一种是Jupyter Notebook的专属格式,一种是Python格式。Jupyter Notebook的专属格式:单击“File”→“Saveand Checkpoint”选项,将Jupyter Notebook文件保存在默认路径下,文件格式默认为ipynb。如果要保存导出为python文件的格式,单击“File”→“Downloadas”选项,在弹出的子菜单中选择Python(.py)。打开“新建下载任务”窗口,在此处选择文件保存路径,单击“下载”按钮,即可将Jupyter Notebook文件保存为Python格式,并保存在指定路径下。
二. Pandas入门
1. 安装Pandas模块
(1) 使用pip命令安装
在系统“搜索”文本框中输入cmd,打开“命令提示符”窗口,输入如下安装命令:
pip install pandas
(2) 在Pycharm开发环境中安装
单击添加按钮“+”,打开“Available Packages”窗口,在搜索文本框中输入需要安装的模块关键字,例如“pandas”,然后在列表中选择需要安装的模块,如图所示,单击“Install Package”按钮即可实现Pandas模块的安装。
还需要注意一点:Pandas有一些依赖库。
例如,当通过Pandas读取Excel文件时,如果只安装Pandas模块,就会出现错误,意思是缺少依赖库openpyxl。解决办法是:安装openpyxl模块,在“命令提示符”窗口输入pip install openpyxl命令或通过PyCharm开发环境安装openpyxl模块,其方法与安装Pandas模块一样。
(4) 小试牛刀
了解了Pandas模块后,接下来介绍使用Pandas导入Excel数据。
# 导入pandas模块
import pandas as pd
# 读取excel文件
df = pd.read_excel("./data1.xlsx")
# 输出前5条数据
print(df.head())
运行程序,结果如图所示。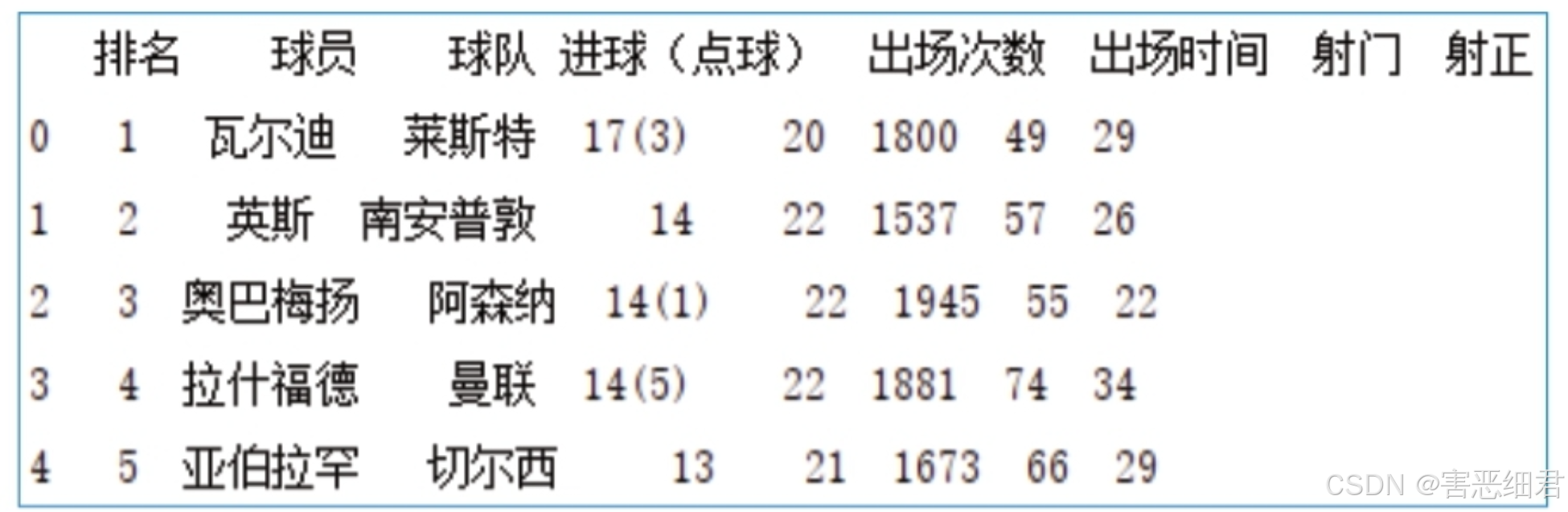
根据运行结果得知,输出的数据出现了列不对齐的现象,这样看上去有些乱,而且影响阅读者对数据的判断,下面来解决这个问题。这里主要使用set_option()函数,将display.unicode.east_asian_width设置为True,使列名对齐,代码如下:
# 导入pandas模块
import pandas as pd
pd.set_option('display.unicode.east_asian_width', True)
# 读取excel文件
df = pd.read_excel("./data1.xlsx")
# 输出前5条数据
print(df.head())
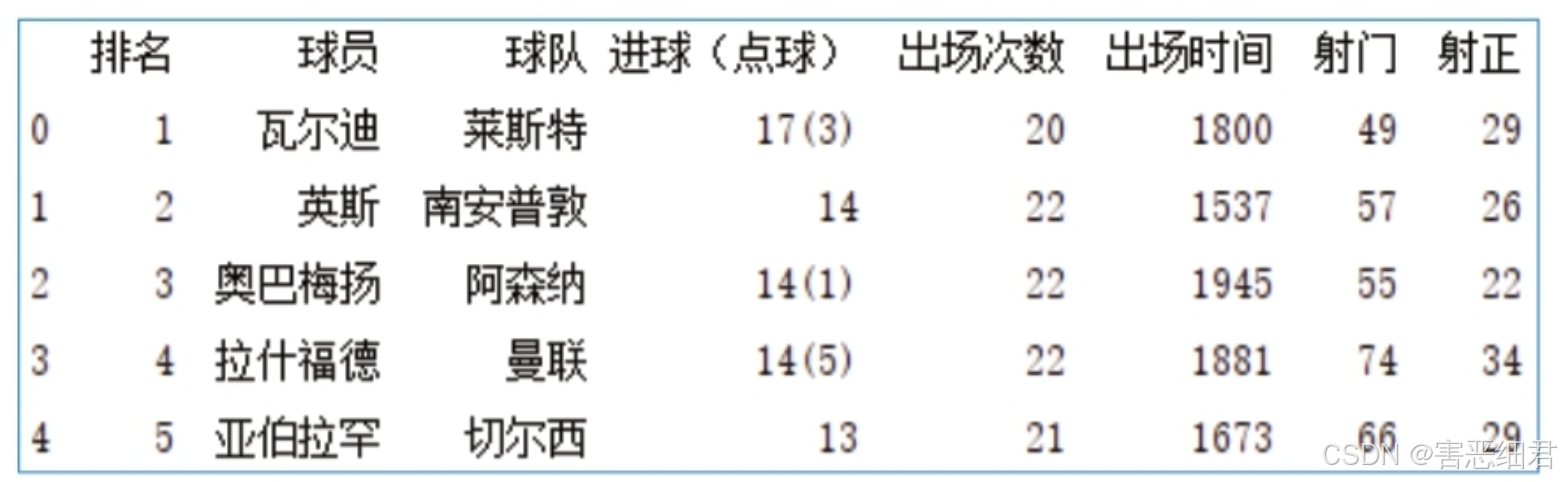
经过上述设置后如果还出现列不对齐的现象,那么可以考虑设置PyCharm控制台字体: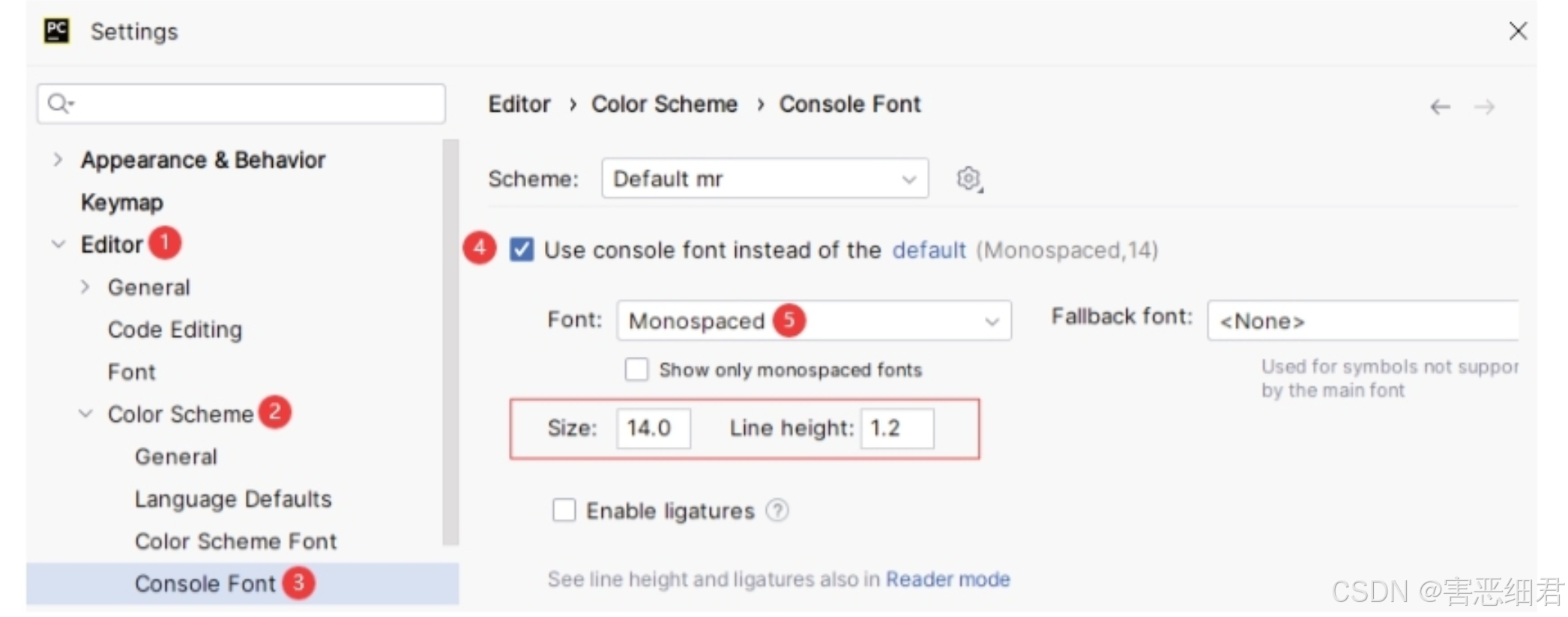
另外,如果数据很多,还可能会出现行列数据显示不全的问题,此时可以通过display.max_rows和display.max_columns修改默认输出数据的最大行数和列数,代码如下:
pd.set_option('display.max_rows', 1000)
pd.set_option('display.max_columns', 1000)
2. Series对象
Pandas是Python数据分析中重要的库,而Series和DataFrame是Pandas库中两个重要的对象,也是Pandas中两个重要的数据结构。
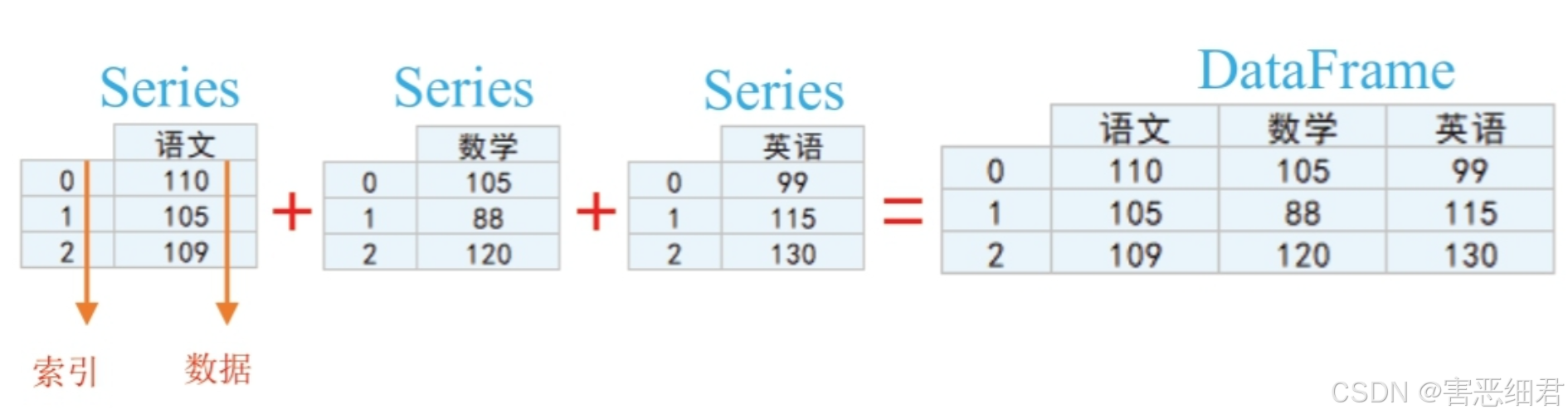
Series是Pandas库中的一种数据结构,它与一维数组类似,由一组数据及与这组数据相关的标签(即索引)组成,仅有一组数据没有索引也可以创建一个简单的Series。Series可以存储整数、浮点数、字符串、Python对象等多种类型的数据。
例如,成绩表中包含了Series对象和DataFrame对象,其中“语文”“数学”“英语”每列都是一个Series对象,而“语文”、“数学”和“英语”三列组成了一个Data Frame对象。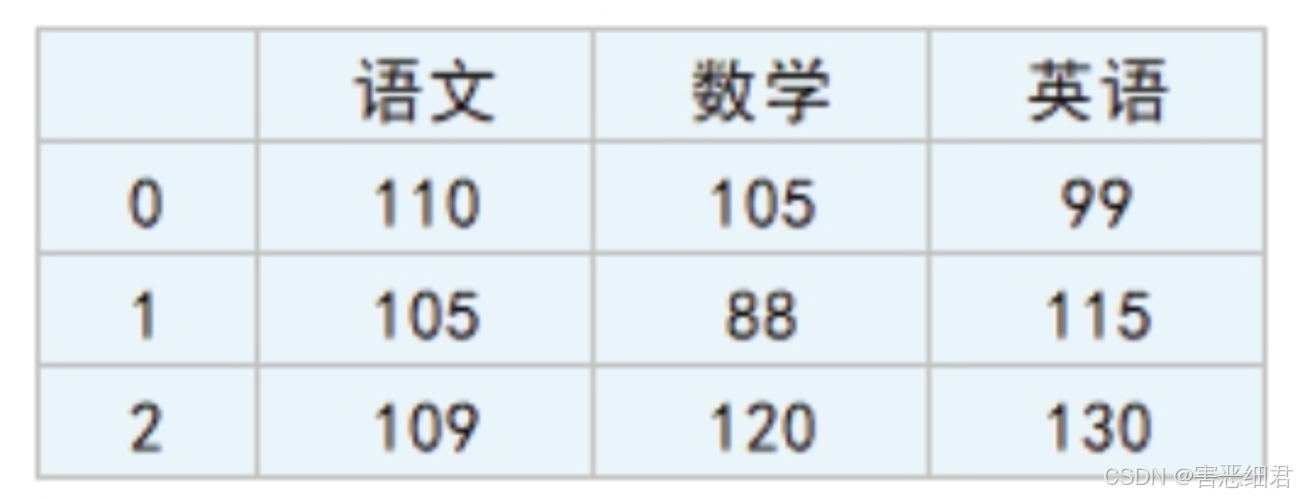
(1) 创建一个Series对象
创建Series对象主要使用Pandas的Series类,语法如下:
s.pd.Series(data,index)
参数说明:data:表示数据,支持Python列表、字典、NumPy数组、标量值(只有大小,没有方向的量,只是一个数值,如s=pd.Series(5))。index:表示行标签(索引)。
返回值:Series对象。
当data参数是多维数组时,index长度必须与data长度一致。如果没有指定index参数,则会自动创建数值型索引(0~data的数据长度-1)。
下面分别使用列表和字典创建Series对象,也就是一列数据。程序代码如下:
# 导入pandas模块
import pandas as pd
# 使用列表创建Series对象
s1=pd.Series([1,2,3])
print(s1)
# 使用字典创建Series对象
s2 = pd.Series({"A":1,"B":2,"C":3})
print(s2)
运行结果:
上述运行结果中的“dtype:int64”是DataFrame对象的数据类型,int为整型,后面的数字64表示位数。
(2) 手动设置Series对象的索引
创建Series对象时会自动生成整数索引,默认值从0开始,至数据长度减1。除了使用默认索引,还可以通过index参数手动设置索引。
下面手动设置索引,将创建的“物理”成绩的索引设置为1、2、3,也可以是“明日同学”“高同学”“七月流火”。程序代码如下:
# 导入pandas模块
import pandas as pd
# 创建Series对象
s1=pd.Series(data=[88,60,75],index=[1,2,3])
s2=pd.Series(data=[88,60,75],index=['明日同学','高同学','七月流火'])
# 输出数据
print(s1)
print(s2)
运行结果:
位置索引默认是从0开始的,[0]是Series的第一个数,[1]是series的第二个数,以此类推。但是要注意:Series不能使用[-1]来定位索引。
首先创建Series对象,即一列物理成绩,然后获取第一个学生的物理成绩。程序代码如下:
# 导入pandas模块
import pandas as pd
# 创建Series对象
s1=pd.Series([88,60,75])
# 通过一个标签索引获取索引值
print(s1[0]) # 88
Series标签索引:标签索引与位置索引方法类似,用[]表示,[] 中是索引名称,注意index的数据类型是字符串。如果要获取多个标签索引值,需用[[]]表示(相当于[]中包含一个列表)。
通过标签索引“明日同学”和“七月流火”获取学生的物理成绩。程序代码如下:
# 导入pandas模块
import pandas as pd
# 创建一列数据并设置索引
s1=pd.Series(data=[88,60,75],index=['明日同学','高同学','七月流火'])
print(s1['明日同学']) # 通过一个标签索引获取索引值
print(s1[['明日同学','七月流火']]) # 通过多个标签索引获取索引值
运行结果:
Series切片索引:通常用标签索引做切片,并包头包尾(既包含索引开始位置的数据,也包含索引结束位置的数据)。
下面通过标签索引切片“明日同学”至“七月流火”获取数据,主要代码如下:
# 导入pandas模块
import pandas as pd
# 创建一列数据并设置索引
s1=pd.Series(data=[88,60,75],index=['明日同学','高同学','七月流火'])
print(s1['明日同学':'七月流火']) #通过切片获取索引值
运行结果:
也可以通过位置索引切片获取数据,下面通过位置索引切片获取数据,主要代码如下:
# 导入pandas模块
import pandas as pd
# 位置索引做切片
s2=pd.Series([88,60,75,34,68])
print(s2[1:4])
运行结果:
用位置索引做切片,其用法和list列表一样,包头不包尾(即包含索引开始位置的数据,不包含索引结束位置的数据)。
(3) 获取Series对象的索引和值
获取Series对象的索引和值主要使用Series的index属性和values属性。
下面使用Series对象的index属性和values属性获取物理成绩的索引和值,程序代码如下:
# 导入pandas模块
import pandas as pd
# 创建一列数据
s1=pd.Series([88,60,75])
# 通过index属性和values属性获取物理成绩的索引和值
print(s1.index)
print(s1.values)
运行结果:
3. DataFrame对象
DataFrame对象是Pandas库中的一种数据结构,它是由多种类型的列组成的二维表数据结构,类似于Excel、SQL或Series对象构成的字典。DataFrame是最常用的Pandas对象,与Series对象一样支持多种类型的数据。
DataFrame对象是一个二维表数据结构,是由行和列数据组成的表格。DataFrame对象既有行索引,又有列索引,可以看作是由Series对象组成的,只不过这些Series对象共用一个索引。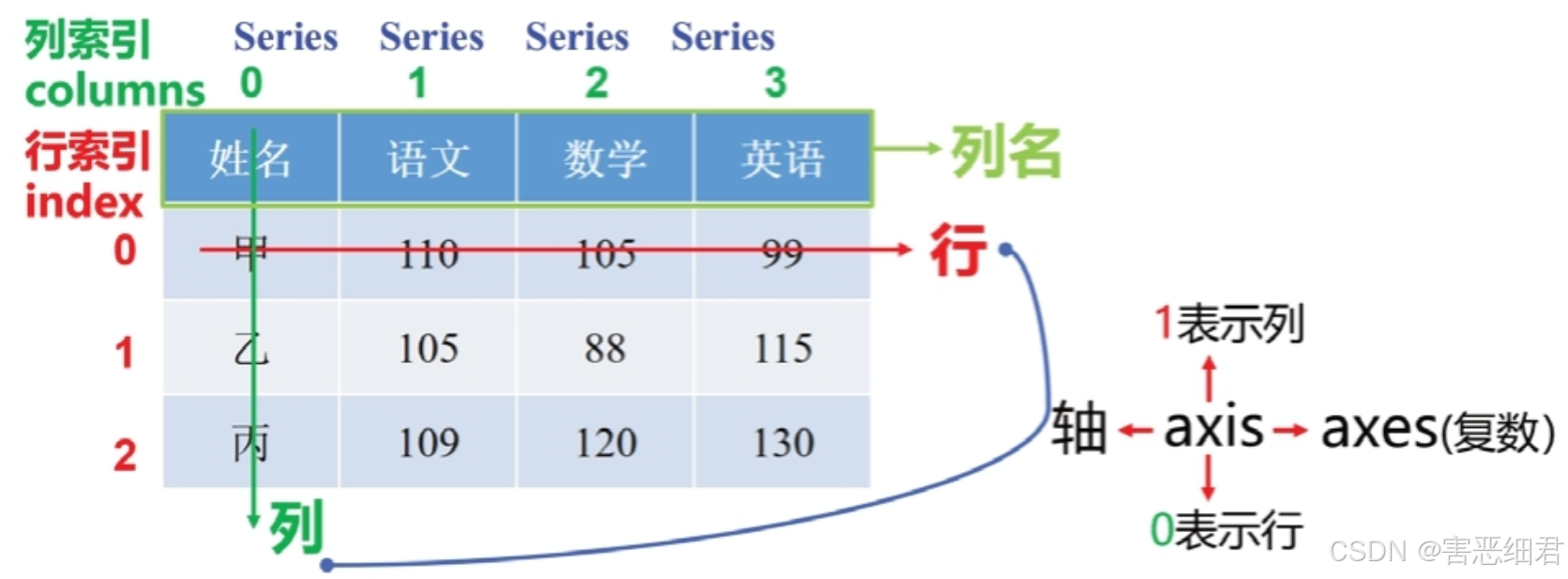
处理DataFrame对象数据时,用index表示行,用columns表示列更直观。用这种方式迭代DataFrame对象的列,代码更易读懂。
首先创建DataFrame对象,然后使用for循环遍历DataFrame对象数据,输出成绩表的每一列数据,程序代码如下:
# 导入pandas对象
import pandas as pd
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
# 创建列表
data = [[110,105,99],[105,88,115],[109,120,130]]
index = [0,1,2]
columns = ['语文','数学','英语']
# 创建DataFrame对象,即表格数据
df = pd.DataFrame(data=data, index=index,columns=columns)
print(df)
# 遍历DataFrame对象的每一列
for col in df.columns:
series = df[col]
print(series)
运行结果:
从运行结果得知:第一组数据为原始数据,即DataFrame对象,其余数据其实是Series对象,这也更进一步说明了DataFrame对象是由Series对象组成的。
(1) 创建一个DataFrame对象
创建DataFrame主要使用Pandas的DataFrame类,语法如下:
df = pd.DataFrame(data, index,columns,dtype,copy)
参数说明:data:表示数据,可以是数组、Series对象、列表、字典等。index:表示行标签(索引)。columns:表示列标签(索引)。dtype:表示每一列数据的数据类型,其与Python数据类型有所不同,如object数据类型对应的是Python的字符型。下表所示是Pandas数据类型与Python数据类型的对应。
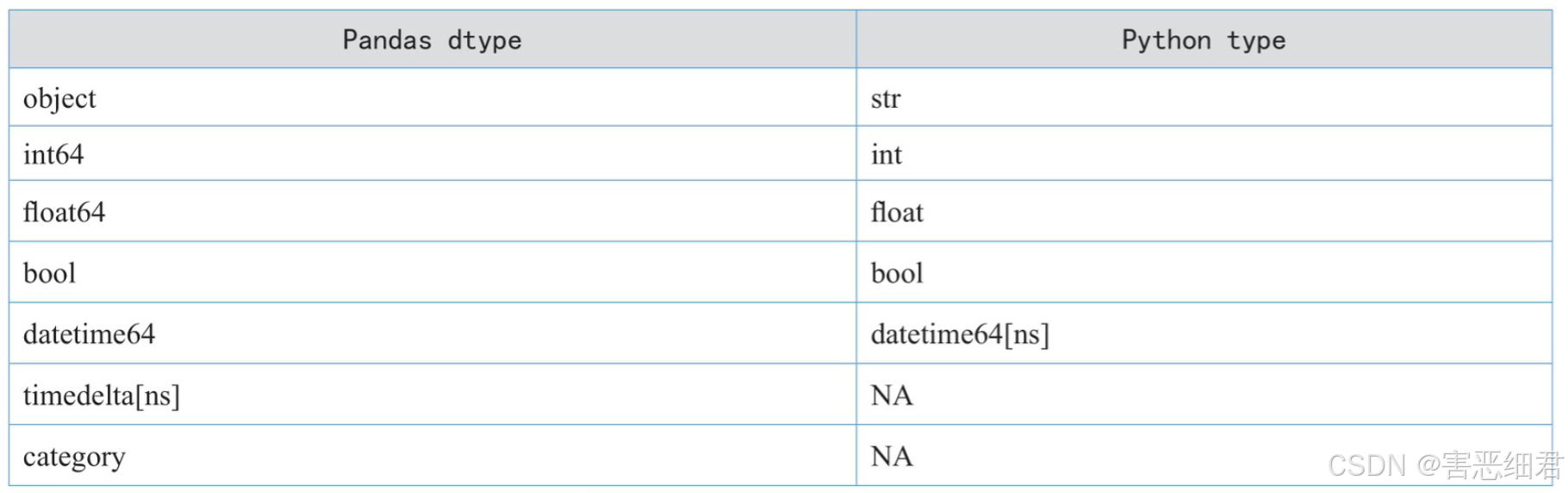
copy:用于复制数据。
返回值:DataFrame对象。
通过列表创建DataFrame对象 ,程序代码如下:
# 导入pandas模块
import pandas as pd
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
# 创建列表
data = [[110,105,99],[105,88,115],[109,120,130]]
columns = ['语文','数学','英语']
# 创建DataFrame对象
df = pd.DataFrame(data=data,columns=columns)
print(df)
运行结果:
通过字典创建DataFrame对象,需要注意,字典中的value值只能是一维数组或简单的单个数据,如果是数组,则要求所有数组的长度一致;如果是单个数据,则每行都要添加相同的数据。示例代码如下:
# 导入pandas模块
import pandas as pd
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
# 通过字典创建DataFrame对象
df = pd.DataFrame({
'语文':[110,105,99],
'数学':[105,88,115],
'英语':[109,120,130],
'班级':'高一7班'})
print(df)
运行结果: 在上述代码中,“班级”的value值是单个数据,所以为每行都添加了相同的数据“高一7班”。
在上述代码中,“班级”的value值是单个数据,所以为每行都添加了相同的数据“高一7班”。
(2) DataFrame对象的重要属性和函数
DataFrame对象是Pandas模块的一个重要对象,它的属性和函数非常之多,下面先简单介绍几个重要且常用的属性和函数。
重要属性: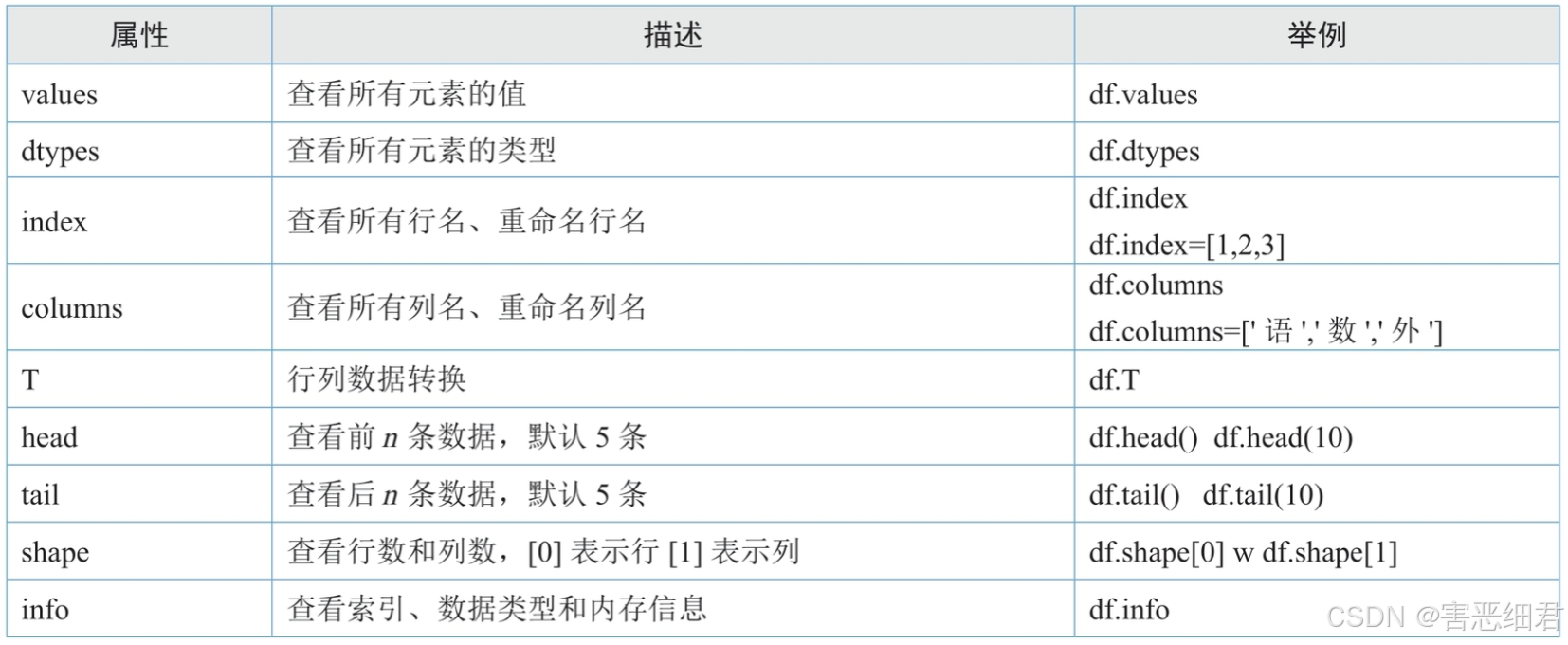
重要函数: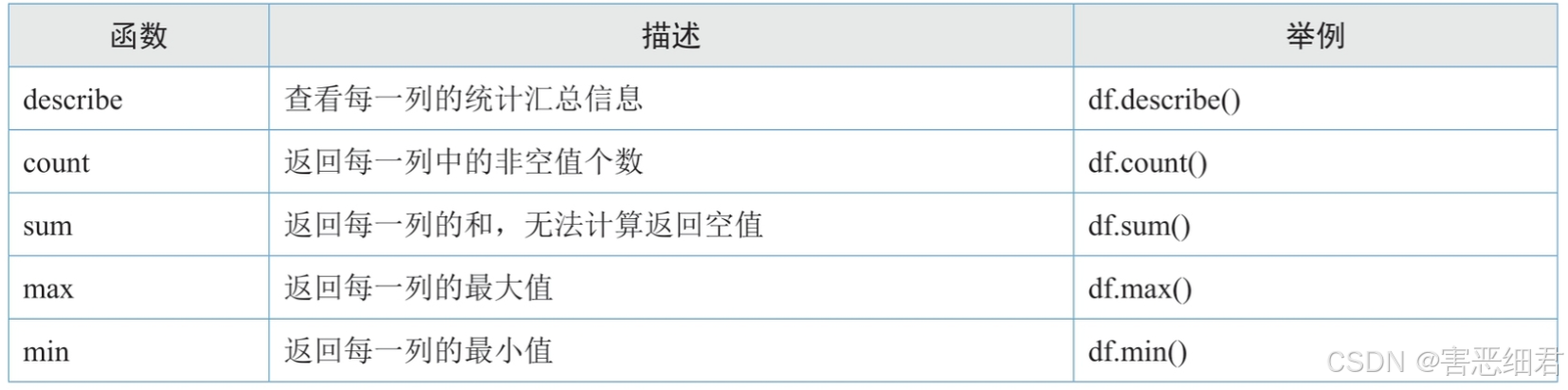
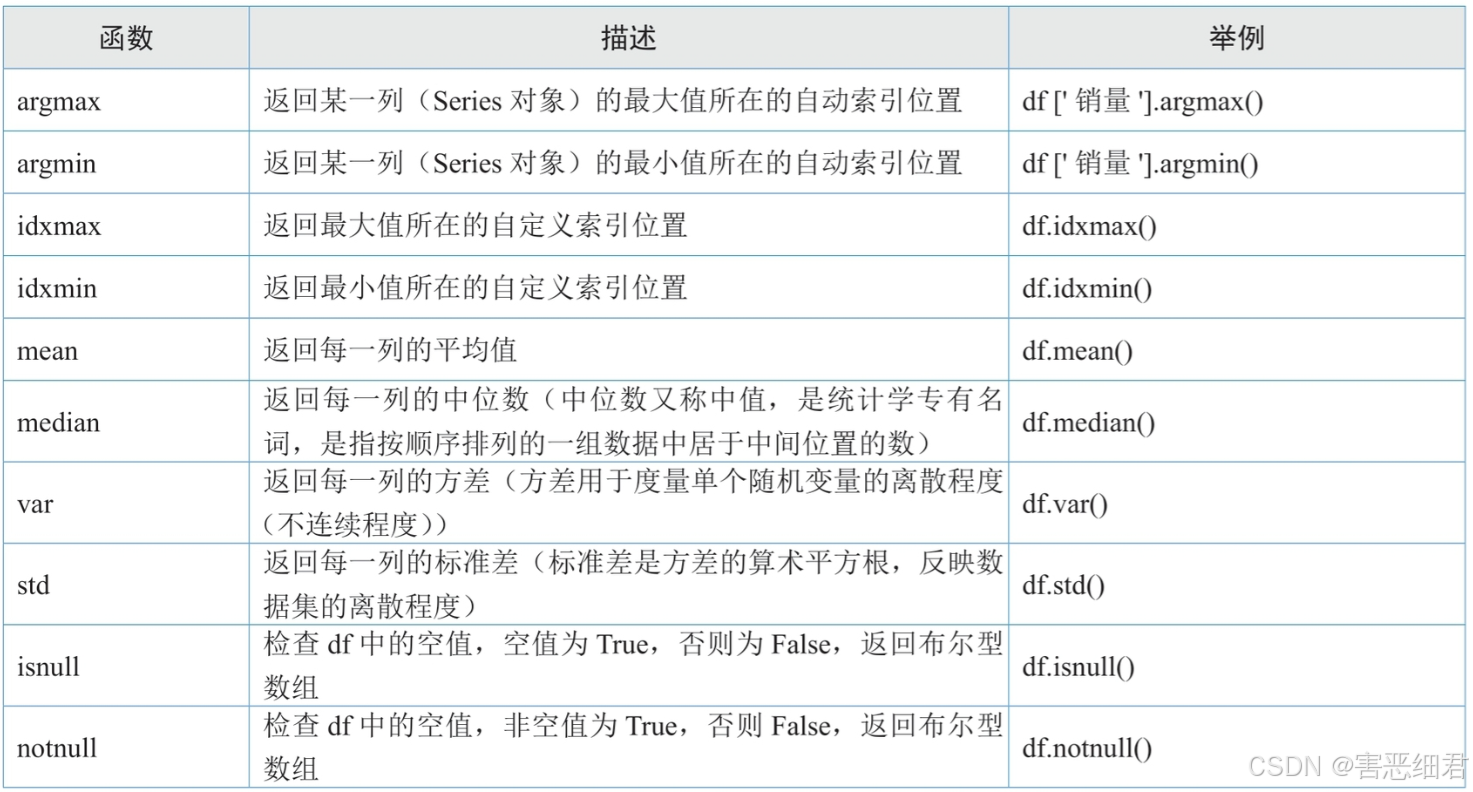
4. 外部数据读取
(1) 读取Excel文件
读取Excel文件主要使用pandas模块的read_excel()方法,语法如下:
pandas.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None,
skiprows=None, nrows=None, dtype=None, parse_dates=False, engine=None, **kwargs)
主要参数说明:io:字符串,xls或xlsx路径文件或类文件对象。sheet_name:None、字符串、整数、字符串列表或整数列表,默认值为0。字符串为Excel工作表的名称;整数为索引,表示工作表的位置;字符串列表或整数列表用于请求多个工作表;为None时表示获取所有的工作表。参数值如下表所示。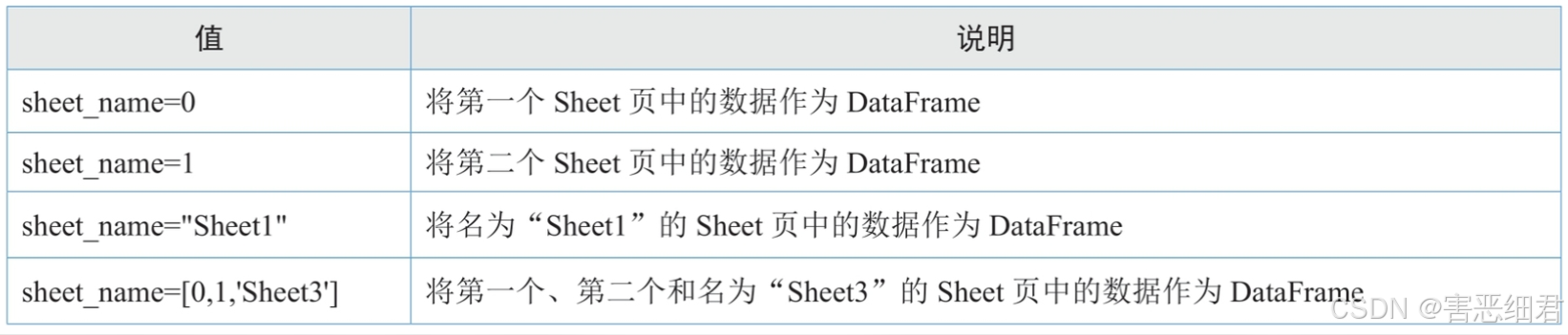
header:指定作为列名的行,默认值为0,即读取第一行的值为列名。数据为除列名以外的数据;若数据不包含列名,则设置header=None。names:默认值为None,表示要使用的列名列表。index_col:指定列为索引列,默认值为None,索引0是DataFrame的行标签。usecols:int、list或字符串,默认值为None。如果为None,则解析所有列。如果为int,则解析最后一列。如果为list,则解析列表中的列。如果为list,则解析列表中的列。其范围包括头和尾。squeeze:布尔值,默认值为False,如果解析的数据只包含一列,则返回一个Series对象。dtype:列的数据类型名称或字典,默认值为None。例如{‘a’:np.float64,‘b’:np.int32}。skiprows:省略指定行数的数据,从第一行开始。skipfooter:省略指定行数的数据,从最后一行开始。
下面通过快速示例,详细介绍如何读取Excel文件。使用read_excel()函数读取文件名为“data2.xlsx”的Excel文件,程序代码如下:
# 导入pandas模块
import pandas as pd
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
# 读取Excel文件
df=pd.read_excel('./data/data2.xlsx')
# 输出前5条数据
print(df.head())
运行结果: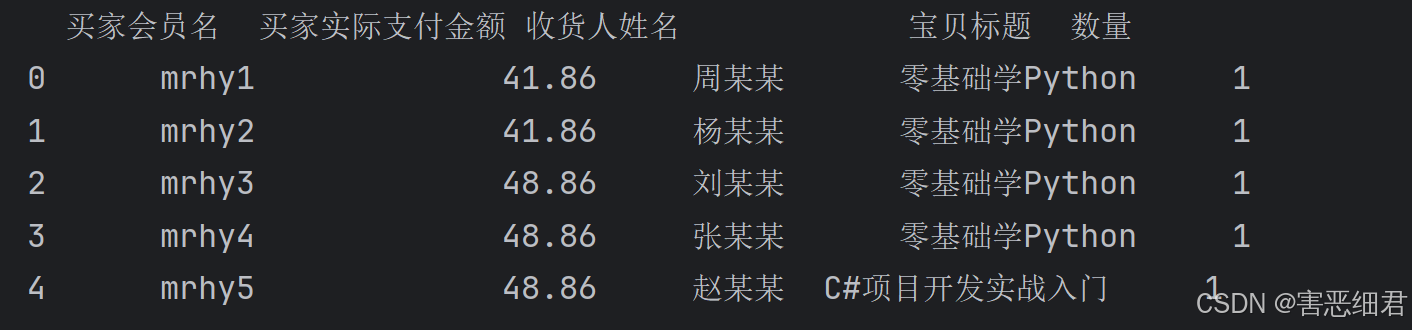
如果读取的Excel文件是.xls类型的,则需要安装 xlrd模块,否则程序会报错。
读取指定的Sheet页:一个Excel文件包含多个Sheet页,通过设置sheet_name参数就可以读取指定Sheet页的数据。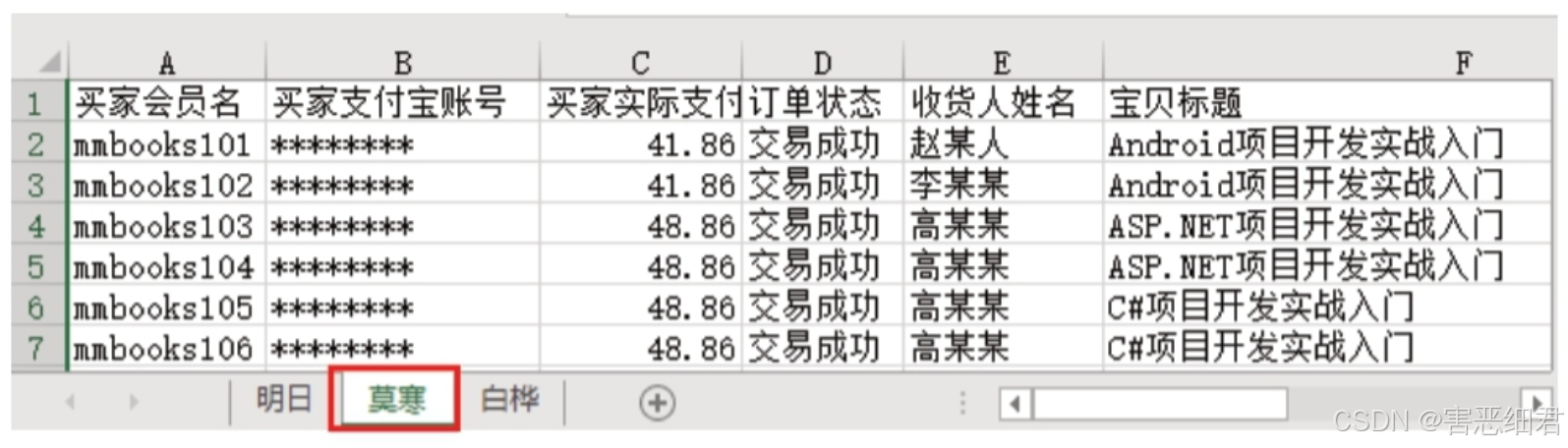
# 导入pandas模块
import pandas as pd
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
# 读取Excel文件
df=pd.read_excel('./data/data2.xlsx',sheet_name="莫寒")
# 输出前5条数据
print(df.head())
运行结果:
除了指定Sheet页的名字,还可以指定Sheet页的顺序,从0开始。例如,sheet_name=0表示第一个Sheet页的数据,sheet_name=1表示第二个Sheet页的数据,以此类推。如果不指定sheet_name参数,则默认读取第一个Sheet页的数据。
通过行列索引读取指定行列数据
DataFrame是二维数据结构,因此它既有行索引,又有列索引。当导入Excel数据时,行索引会自动生成,如0、1、2,而列索引则默认为第0行数据。
如果通过指定行索引读取Excel文件,则需要设置index_col参数。程序代码如下:
# 导入pandas模块
import pandas as pd
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
# 读取Excel文件
df=pd.read_excel('./data/data2.xlsx',index_col=0)
# 输出前5条数据
print(df.head())
运行结果: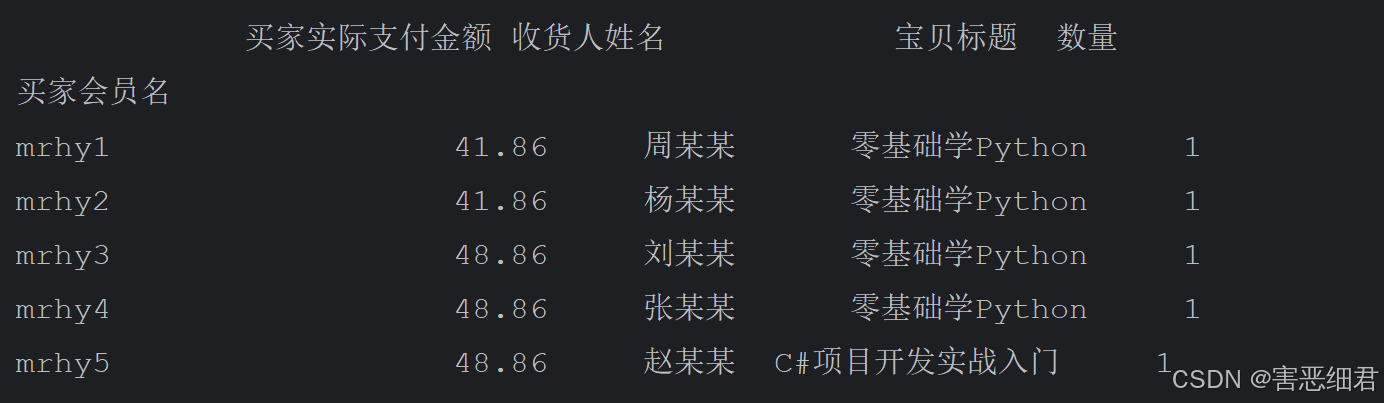
如果将数字指定为列索引,可以设置header参数为None,主要代码如下:
# 导入pandas模块
import pandas as pd
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
# 读取Excel文件
df=pd.read_excel('./data/data2.xlsx',header=None)
# 输出前5条数据
print(df.head())
运行结果: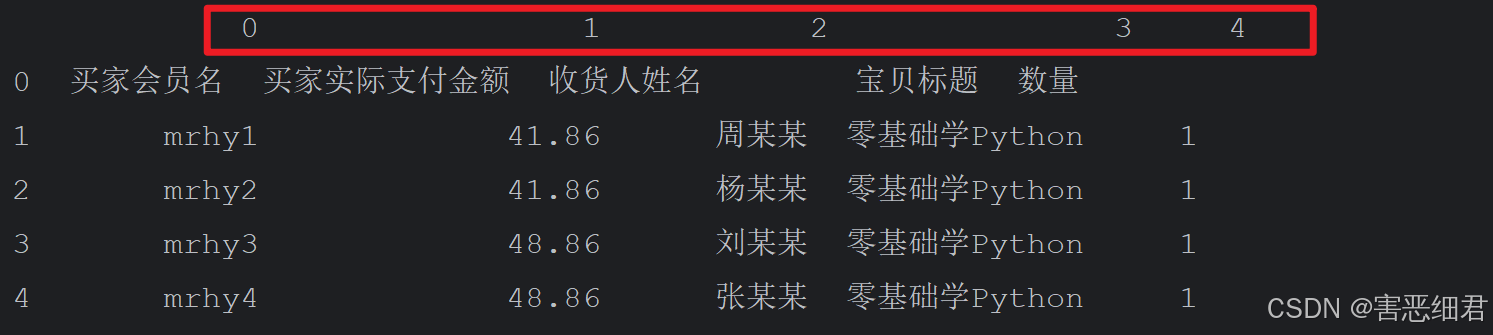
读取指定列数据
一个Excel文件中往往包含多列数据,如果只需要其中的几列,则可以通过usecols参数指定需要的列,从0开始(0表示第1列,以此类推)。
下面读取第1列数据(索引为0),程序代码如下:
# 导入pandas模块
import pandas as pd
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
# 读取Excel文件
df=pd.read_excel('./data/data2.xlsx',usecols=[0])
# 输出前5条数据
print(df.head())

如果要读取多列数据,则可以在列表中指定多个值。例如,读取第1列和第3列数据,主要代码如下:
df=pd.read_excel('./data/data2.xlsx',usecols=[0,3])
也可以指定列名称,主要代码如下:
df=pd.read_excel('./data/data2.xlsx',usecols=['买家会员名','宝贝标题'])
(2) 读取CSV文件
读取CSV文件主要使用pandas模块的read_csv()方法,语法如下:
pandas.read_csv(filepath_or_buffer, sep=',', delimiter=None, header='infer', names=None, index_col=None, usecols=None,
squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None,
false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True,
na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False,
date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None,
decimal='.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None,
dialect=None, error_bad_lines=True, warn_bad_lines=True, delim_whitespace=False, low_memory=True, memory_map=False,
float_precision=None)
这里不做过多的参数说明了,用到去查就好了。
下面使用read_csv()函数读取CSV文件,程序代码如下:
# 导入pandas模块
import pandas as pd
# 设置数据显示的最大列数和宽度
pd.set_option('display.max_columns',500)
pd.set_option('display.width',1000)
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
# 读取CSV文件,并指定编码格式
df1=pd.read_csv(filepath_or_buffer='./data/1月.csv',encoding='gbk')
# 输出前5条数据
print(df1.head())
运行结果: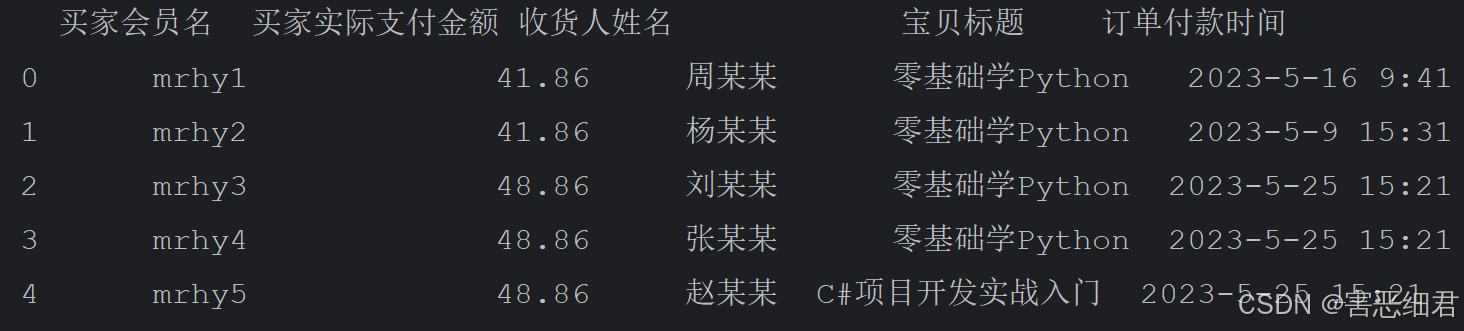
上述代码中指定了编码格式,即encoding=‘gbk’。Python常用的编码格式是UTF-8和gbk,默认编码格式为UTF-8。导入.csv文件时,需要通过encoding参数指定编码格式。当我们将Excel文件另存为.csv文件时,默认编码格式为gbk,此时编写代码导入.csv文件时,就需要设置编码格式为gbk,与原文件的编码格式保持一致,否则会提示错误。
(3) 读取文本文件
读取文本文件同样使用Pandas模块的read_csv()函数,不同的是需要指定sep参数(如制表符/t)。read_csv()函数读取文本文件后返回一个DataFrame对象,是像表格一样的二维数据结构。下面使用read_csv()函数读取“1月.txt”文本文件,主要代码如下:
# 导入pandas模块
import pandas as pd
# 设置数据显示的列数和宽度
pd.set_option('display.max_columns',500)
pd.set_option('display.width',1000)
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
# 读取文本文件
df1=pd.read_csv(filepath_or_buffer='./data/1月.txt',sep='\t',encoding='gbk')
print(df1.head())
(4) 读取HTML网页数据
读取HTML网页数据主要使用Pandas的read_html()函数,该函数用于读取带有table标签的网页表格数据,语法如下:
pandas.read_html(io, match='.+', flavor=None, header=None, index_col=None, skiprows=None, attrs=None, parse_dates=False,
thousands=', ', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)
这里需要说明一点:在使用 read_html()函数前,首先要确定网页表格是否为table类型的,因为只有这种类型的网页表格才能通过read_html()函数获取到其中的数据。
5. 数据抽取
在分析数据的过程中,并不是所有的数据都是我们想要的,此时可以抽取部分数据,主要使用DataFrame对象的loc属性和iloc属性。
loc属性:以列名(columns)和行名(index)作为参数,当只有一个参数时,默认是行名,即抽取整行数据,包括所有列。iloc属性:以行和列位置索引(即0、1、2……)作为参数,0表示第一行,1表示第二行,以此类推。当只有一个参数时,默认是行索引,即抽取整行数据,包括所有列。如抽取第一行数据df.iloc[0]。
(1) 抽取单行数据
抽取一行数据主要使用loc属性。 下面使用loc属性抽取一行名为“明日”的考试成绩数据(包括所有列),程序代码如下:
# 导入pandas模块
import pandas as pd
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
data = [[110,105,99],[105,88,115],[109,120,130],[112,115]]
name = ['明日','七月流火','高袁圆','二月二']
columns = ['语文','数学','英语']
# 创建数据
df = pd.DataFrame(data=data, index=name, columns=columns)
print(df)
# 抽取一行数据
print(df.loc['明日'])
# 使用iloc属性抽取第一行数据时,指定行索引即可,如df.iloc[0]
print(df.iloc[0])
运行结果: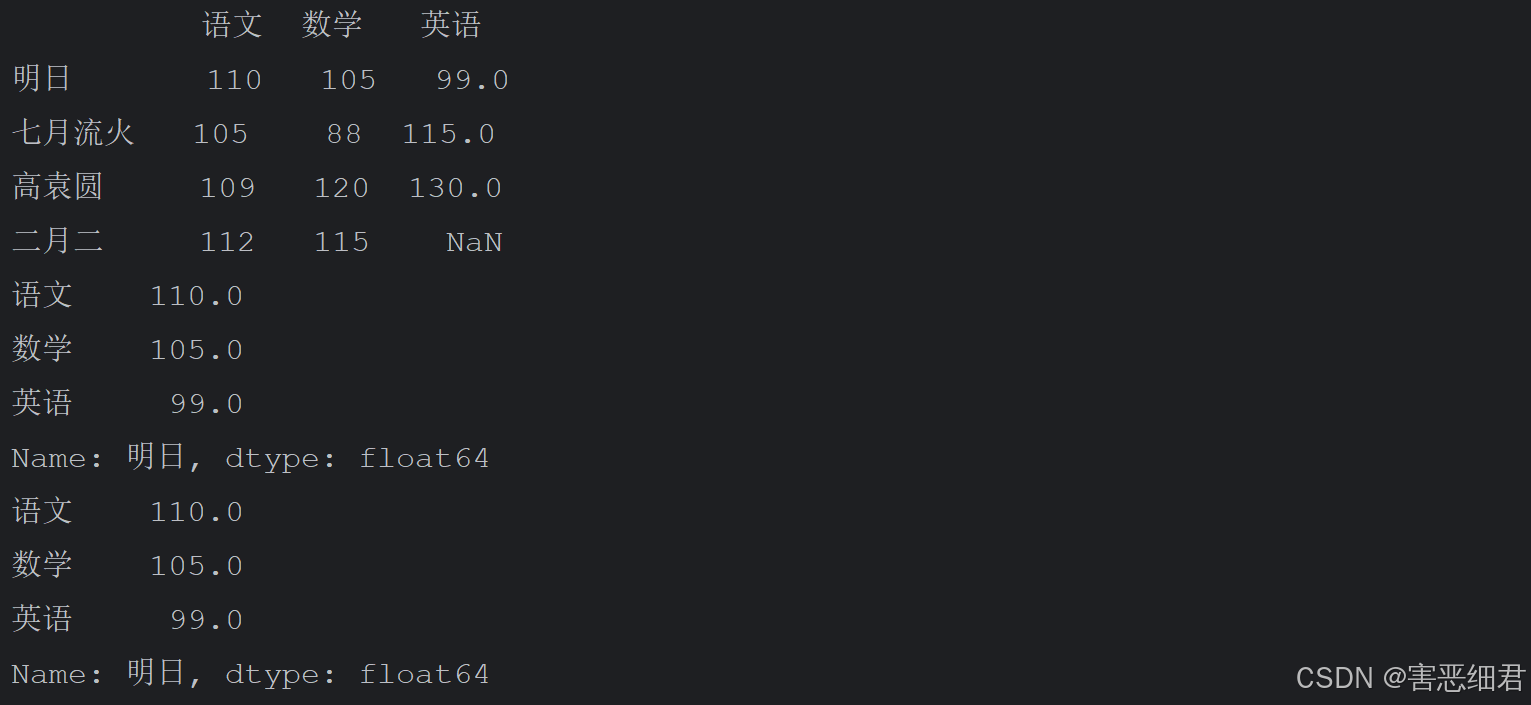
(2) 抽取多行数据
通过DataFrame对象的loc属性和iloc属性指定行名和行索引,即可实现抽取任意多行数据。
抽取行名为“明日”和“高袁圆”(即第1行和第3行数据)的考试成绩数据,主要代码如下:
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
data = [[110,105,99],[105,88,115],[109,120,130],[112,115]]
name = ['明日','七月流火','高袁圆','二月二']
columns = ['语文','数学','英语']
df = pd.DataFrame(data=data, index=name, columns=columns)
print(df.loc[['明日','高袁圆']])
print(df.iloc[[0,2]])
运行结果:
(3) 抽取连续的任意多行数据
在loc属性和iloc属性中合理使用冒号:,即可抽取连续的任意多行数据。
抽取连续几个学生的考试成绩,主要代码如下:
(4) 抽取指定列数据
下面使用loc属性和iloc属性抽取指定列数据,主要代码如下:
import pandas as pd
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
data = [[110, 105, 99], [105, 88, 115], [109, 120, 130], [112, 115]]
name = ['明日', '七月流火', '高袁圆', '二月二']
columns = ['语文', '数学', '英语']
df = pd.DataFrame(data=data, index=name, columns=columns)
# 抽取指定列数据——使用loc方法和iloc方法
print(df.loc[:, ['语文', '数学']]) # 抽取“语文”和“数学”
print(df.iloc[:, [0, 1]]) # 抽取第1列和第2列
print(df.loc[:, '语文':]) # 抽取从“语文”开始到最后一列
print(df.iloc[:, :2]) # 连续抽取从1列开始到第3列
运行结果:
6. 数据的增加、修改和删除
(1) 修改列标题
修改列标题主要使用DataFrame对象的cloumns属性,直接赋值即可。
将列标题“数学”修改为“数学(上)”,主要代码如下:
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
data = [[110,105,99],[105,88,115],[109,120,130],[112,115,140]]
name = ['明日','七月流火','高袁圆','二月二']
columns = ['语文','数学','英语']
df = pd.DataFrame(data=data, index=name, columns=columns)
print('原数据:')
print(df)
df.columns=['语文','数学(上)','英语']
print('修改后:')
print(df)
如果要修改多个学科列的列标题,如:分别将“语文”修改为“语文(上)”,将“数学”修改为“数学(上)”,将“英语”修改为“英语(上)”,主要代码如下:
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
data = [[110,105,99],[105,88,115],[109,120,130],[112,115,140]]
name = ['明日','七月流火','高袁圆','二月二']
columns = ['语文','数学','英语']
df = pd.DataFrame(data=data, index=name, columns=columns)
print('原数据:')
print(df)
print('修改后:')
df.rename(columns = {'语文':'语文(上)','数学':'数学(上)','英语':'英语(上)'},inplace = True)
print(df)
(2) 修改行标题
修改行标题主要使用DataFrame对象的index属性,直接赋值即可。使用DataFrame对象的rename方法也可以修改行标题。
例如,将行标题统一修改为数字编号,主要代码如下:
df.rename(mapper={'明日':1,'七月流火':2,'高袁圆':3,'二月二':4},axis=0,inplace = True)
(3) 修改数据
修改数据主要使用DataFrame对象的loc属性和iloc属性。
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
data = [[110,105,99],[105,88,115],[109,120,130],[112,115,140]]
name = ['明日','七月流火','高袁圆','二月二']
columns = ['语文','数学','英语']
df = pd.DataFrame(data=data, index=name, columns=columns)
print('原数据:')
print(df)
#修改整行数据
df.loc['明日']=[120,115,109]
print('修改后的数据:')
print(df)
#各科成绩均加10分
df.loc['明日']=df.loc['明日']+10
#修改整列数据
df.loc[:,'语文']=[115,108,112,118]
#修改某一数据
df.loc['明日','语文']=115
#使用iloc方法修改数据
df.iloc[0,0]=115 #修改某一数据
df.iloc[:,0]=[115,108,112,118] #修改整列数据
df.iloc[0,:]=[120,115,109] #修改整行数据
(4) 删除行列数据
删除数据主要使用DataFrame对象的drop方法。语法如下:
DataFrame.drop(labels=None, axis=0, index=None, columns=None, inplace=False, errors='raise')
主要参数说明:labels:表示行标签或列标签。axis:axis=0,表示按行删除;axis=1,表示按列删除。默认值为0。index:删除行,默认值为None。columns:删除列,默认值为None。level:针对有两级索引的数据,level=0,表示按第1级索引删除整行,level=1,表示按第2级索引删除整行,默认值为None。inplace:可选参数,对原数组做出修改并返回一个新数组。默认值为False,如果值为True,那么原数组将直接被替换。
以下代码中的方法都可以用于删除指定的行列数据,选择一种就可以。
# 删除行列数据
df.drop(labels=['数学'], axis=1, inplace=True) # 删除某列
df.drop(columns='数学', inplace=True) # 删除columns为“数学”的列
df.drop(labels='数学', axis=1, inplace=True) # 删除列标签为“数学” 的列
df.drop(labels=['明日', '二月二'], inplace=True) # 删除某行
df.drop(index='明日', inplace=True) # 删除index为“明日”的行
df.drop(labels='明日', axis=0, inplace=True) # 删除行标签为“明日”的行
删除特定的行,首先找到满足特定条件的行索引,然后使用drop方法将其删除。
# 删除特定条件的行
df.drop(df[df['数学'].isin([88])].index,inplace=True) #删除“数学”包含88的行
df.drop(df[df['语文']<110].index,inplace=True) #删除“语文”小于110的行
7. 数据清洗
(1) 缺失值查看与处理
缺失值指的是由于某种原因导致为空的数据,这种情况一般有几种处理方式:一是不处理;二是删除;三是填充/替换;四是插值(以均值/中位数/众数等填补)。
缺失值查看:首先需要找到缺失值,主要使用DataFrame对象的info()方法。
以淘宝销售数据为例,首先输出数据,然后使用info()方法查看数据,程序代码如下:
# 导入pandas模块
import pandas as pd
# 设置数据显示的列数和宽度
pd.set_option('display.max_columns',500)
pd.set_option('display.width',1000)
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
# 读取Excel文件
df=pd.read_excel('./data/data3.xlsx')
print(df)
# 缺失值查看
print(df.info())
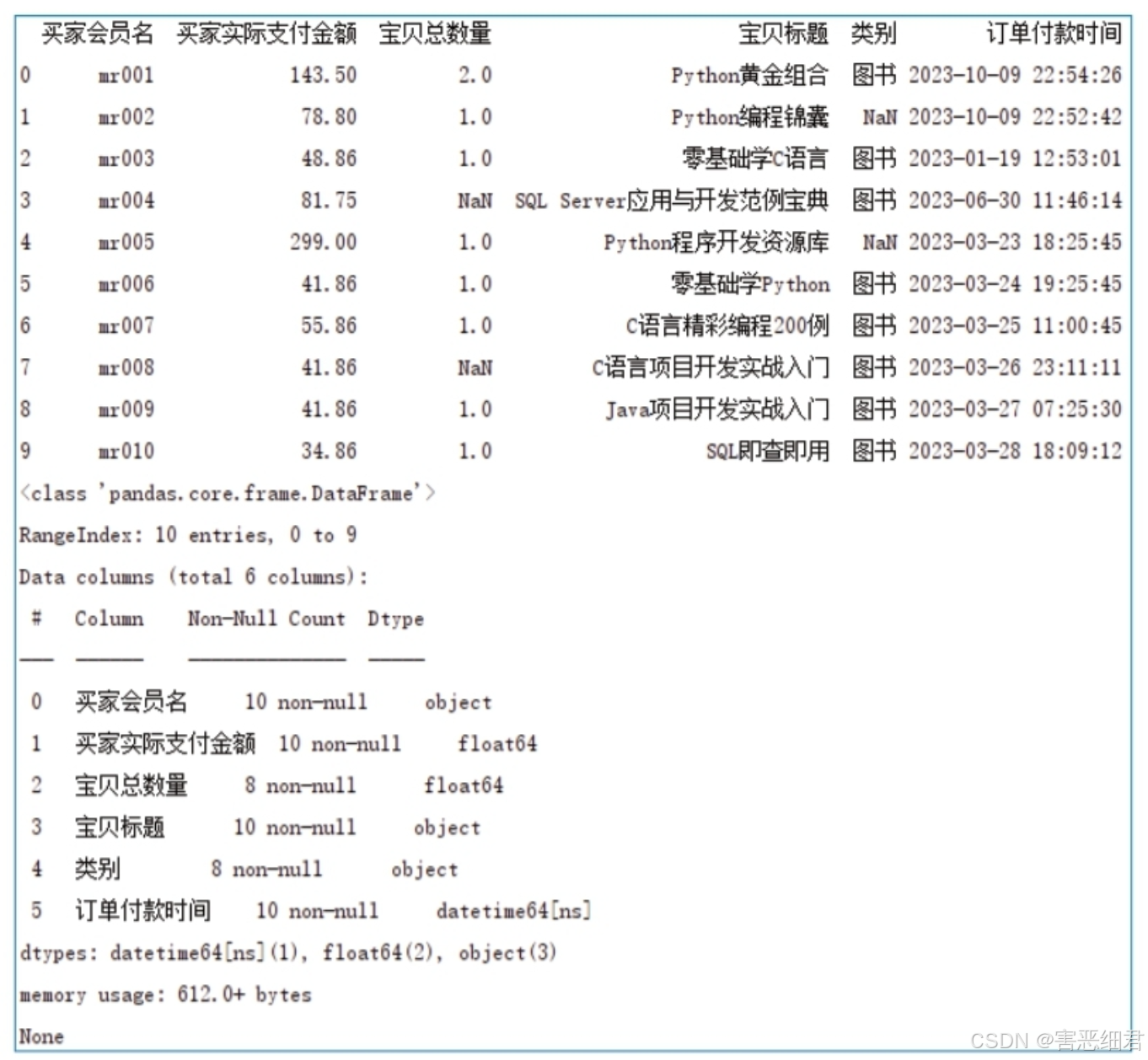
在Python中,缺失值一般用NaN表示,通过info()方法,我们可以看到“买家会员名”、“买家实际支付金额”、“宝贝标题”和“订单付款时间”的非空值数量是10,而“宝贝总数量”和“类别”的非空值数量是8,说明这两列存在缺失值。
判断数据是否存在缺失值可以使用isnull()方法和notnull()方法,主要代码如下:
# 导入pandas模块
import pandas as pd
# 设置数据显示的列数和宽度
pd.set_option('display.max_columns',500)
pd.set_option('display.width',1000)
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
# 读取Excel文件
df=pd.read_excel('./data/data3.xlsx')
print(df.isnull())
print(df.notnull())
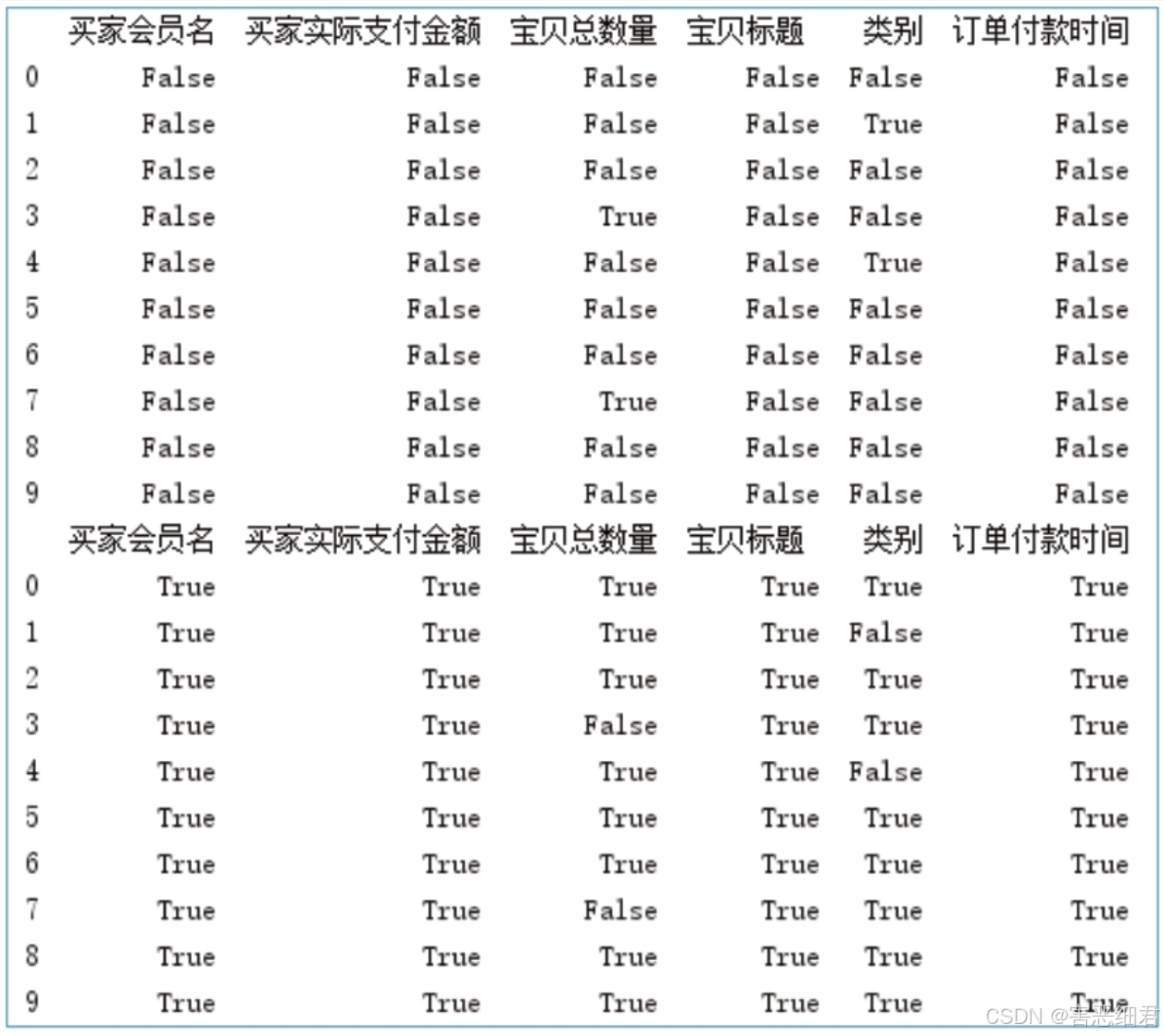
使用isnull()方法时,缺失值将返回True,非缺失值则返回False;notnull()方法与isnull()方法正好相反,缺失值返回False,非缺失值则返回True。
缺失值删除处理:通过前面的判断可得知数据缺失情况,下面将缺失值删除,主要使用dropna()方法,该方法用于删除含有缺失值的行,主要代码如下:
df.dropna(inplace=True)
缺失值填充处理:对于缺失值,如果比例高于30%,可以选择放弃这个指标,做删除处理;低于30%,则尽量不要删除,而是选择将这部分数据填充,一般以0、均值、众数(大多数)填充。DataFrame对象中的fillna()函数可以用于填充缺失值。
对于用于计算的数值型数据,如果为空,则可以选择用“0”填充。例如,将“宝贝总数量”为空的数据填充为“0”,主要代码如下:
df['宝贝总数量'] = df['宝贝总数量'].fillna(0)
(2) 重复值处理
对于数据中存在的重复值(包括重复的行或者几行中某几列的值重复),一般做删除处理,主要使用DataFrame对象的drop_duplicates()方法。
下面以“data4.xlsx”淘宝销售数据为例,对其中的重复值进行处理。
# 导入pandas模块
import pandas as pd
# 读取Excel文件
df=pd.read_excel('./data/data4.xlsx')
# 判断每一行数据是否重复(全部相同),False表示不重复,返回值为True表示重复
print(df.duplicated())
# 去除全部的重复数据
print(df.drop_duplicates())
# 去除指定列的重复数据
print(df.drop_duplicates(['买家会员名']))
# 保留重复行中的最后一行
print(df.drop_duplicates(subset=['买家会员名'],keep='last'))
# inplace=True表示直接在原来的DataFrame上删除重复项,而默认值False表示生成一个副本。
print(df.drop_duplicates(subset=['买家会员名','买家支付宝账号'],inplace=False))
inplace=True,表示直接在原来的DataFrame上删除重复行,而默认值False则表示删除重复行后生成一个副本。
(3) 数据计算
Pandas提供了大量的数据计算方法,可以实现求和、求均值、求最大值、求最小值、求中位数、求众数、求方差、求标准差等,从而使数据统计变得简单高效。
| 类别 | 方法名称 | 功能描述 | 用法示例 | 适用对象 |
|---|---|---|---|---|
| 基础统计 | count() |
计算非缺失值的数量 | df['col1'].count() → 统计列 col1 非空值个数 |
Series/DataFrame |
sum() |
计算数值型数据的总和(非数值列自动忽略) | df.sum(axis=1) → 按行求和(axis=1 行,0 列,默认 0) |
Series/DataFrame | |
mean() |
计算数值型数据的平均值 | df[['col1', 'col2']].mean() → 计算两列的均值 |
Series/DataFrame | |
median() |
计算数值型数据的中位数 | df['col1'].median() → 列 col1 的中位数 |
Series/DataFrame | |
std() |
计算数值型数据的标准差(默认样本标准差,ddof=1) | df['col1'].std(ddof=0) → 计算总体标准差 |
Series/DataFrame | |
var() |
计算数值型数据的方差 | df.var() → 所有数值列的方差 |
Series/DataFrame | |
min() |
计算数据的最小值 | df.min(axis=1) → 按行取最小值 |
Series/DataFrame | |
max() |
计算数据的最大值 | df[['col1', 'col2']].max() → 两列的最大值 |
Series/DataFrame | |
quantile() |
计算分位数(默认 0.5,即中位数) | df['col1'].quantile([0.25, 0.75]) → 计算 25% 和 75% 分位数 |
Series/DataFrame | |
| 聚合计算 | agg() / aggregate() |
对数据应用多个聚合函数(支持自定义函数) | df['col1'].agg(['sum', 'mean', lambda x: x.max()-x.min()]) → 求和、均值、极差 |
Series/DataFrame |
groupby()+ 聚合 |
按指定列分组后执行聚合计算(核心分组方法) | df.groupby('category')['value'].sum() → 按 category 分组,求和 value |
DataFrame | |
pivot_table() |
透视表(按行 / 列分组,计算交叉聚合结果) | df.pivot_table(values='value', index='A', columns='B', aggfunc='mean') |
DataFrame | |
| 窗口计算 | rolling() |
滚动窗口计算(如移动平均、滚动求和) | df['col1'].rolling(window=3).mean() → 3 期移动平均 |
Series/DataFrame |
expanding() |
扩展窗口计算(从第一个元素开始,窗口逐步扩大) | df['col1'].expanding().sum() → 累计求和 |
Series/DataFrame | |
| 元素级计算 | apply() |
对每行 / 每列应用自定义函数(灵活但效率低于向量化) | df['col1'].apply(lambda x: x**2) → 列中每个元素平方 |
Series/DataFrame |
map() |
对 Series 元素执行映射(如替换值、字典匹配) | df['col1'].map({1:'A', 2:'B'}) → 将 1 替换为 A,2 替换为 B |
仅 Series | |
applymap() |
对 DataFrame 每个元素应用函数(Pandas 2.0+ 推荐用 df.map() 替代) |
df.applymap(lambda x: x.strip() if isinstance(x, str) else x) → 清理字符串 |
仅 DataFrame | |
| 向量化运算符 | 直接用 +/-/*// 等执行元素级计算(效率最高) |
df['col1'] * 2 + df['col2'] → 两列元素级运算后相加 |
Series/DataFrame | |
| 缺失值处理 | fillna() |
填充缺失值(支持常数、均值、前向 / 后向填充) | df['col1'].fillna(df['col1'].mean()) → 用均值填充缺失值 |
Series/DataFrame |
dropna() |
删除包含缺失值的行 / 列 | df.dropna(axis=0, how='any') → 删除任何一列有缺失值的行 |
Series/DataFrame | |
interpolate() |
插值填充缺失值(如线性插值、时间序列插值) | df['col1'].interpolate(method='linear') → 线性插值填充 |
Series/DataFrame | |
| 其他常用计算 | cumsum() |
计算累计和 | df['col1'].cumsum() → 列 col1 的累计和 |
Series/DataFrame |
cumprod() |
计算累计积 | df['col1'].cumprod() → 列 col1 的累计积 |
Series/DataFrame | |
diff() |
计算相邻元素的差值(默认 1 阶,即后一个减前一个) | df['col1'].diff(periods=2) → 计算间隔 2 个元素的差值 |
Series/DataFrame | |
corr() |
计算数值列之间的相关系数(默认 Pearson 相关) | df[['col1', 'col2', 'col3']].corr() → 三列间的相关系数矩阵 |
Series/DataFrame | |
cov() |
计算数值列之间的协方差 | df['col1'].cov(df['col2']) → 两列的协方差 |
Series/DataFrame |
(4) 数据导出
数据导出数据到Excel文件,主要使用DataFrame对象的to_excel()方法。导出数据到CSV文件,主要使用DataFrame对象的to_csv()方法。
三. 可视化数据分析图表
1. 图表的基本组成
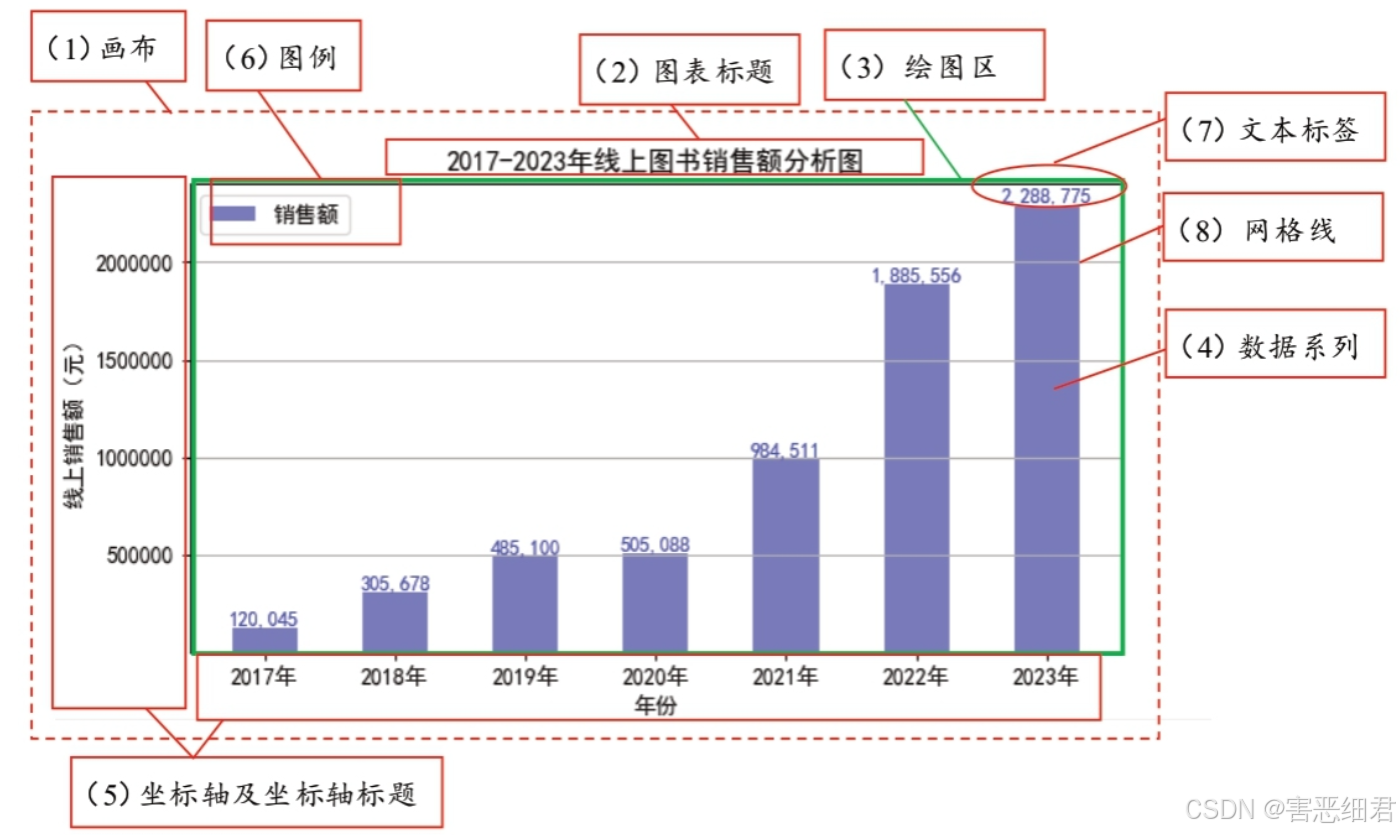
数据分析图表有很多种,但大多数图表的基本组成是相同的,一张完整的图表一般包括画布、图表标题、绘图区、数据系列、坐标轴及坐标轴标题、图例、文本标签、网格线等。
2. Matplotlib的简介和安装
Matplotlib是一个Python2D绘图库,常用于数据可视化。它能够以多种硬拷贝格式在跨平台的交互式环境中生成高质量的图形。Matplotlib非常强大,绘制各种各样的图表游刃有余,只需几行代码就可以绘制折线图、柱形图、直方图、饼形图、散点图等。
使用pip命令安装:
pip install matplotlib
3. 图表的常用设置
主要包括设置线条颜色、设置线条样式、设置标记样式、设置画布、设置坐标轴、添加文本标签、设置标题和图例、添加注释等。
(1) 基本绘图
Matplotlib基本绘图主要使用plot()函数,语法格式如下:
matplotlib.pyplot.plot(*args, scalex=True, scaley=True, data=None, **kwargs)
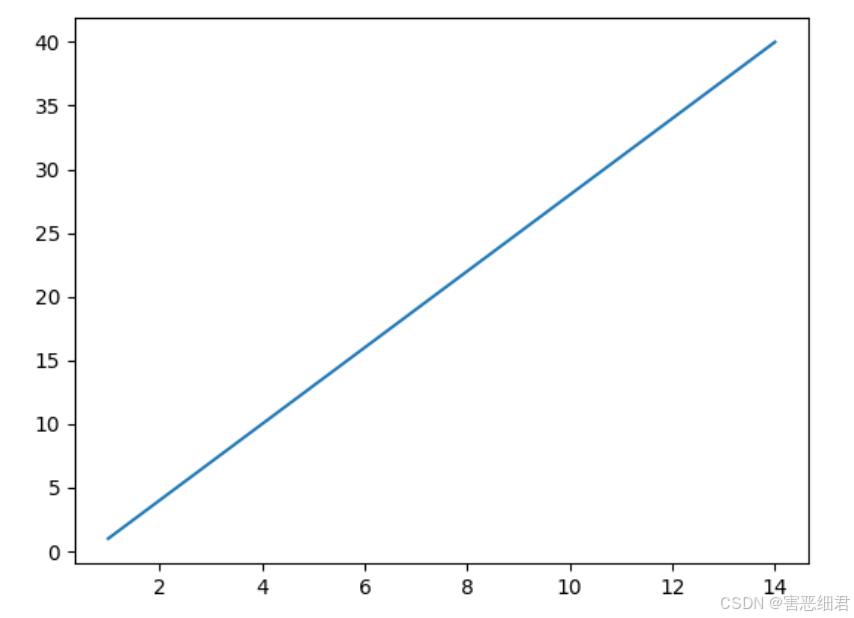
示例1:绘制简单的折线图。
# 导入matplotlib模块
import matplotlib.pyplot as plt
# range()函数创建整数列表
x =range(1,15,1)
y= range(1,42,3)
# 绘制折线图
plt.plot(x,y)
plt.show()
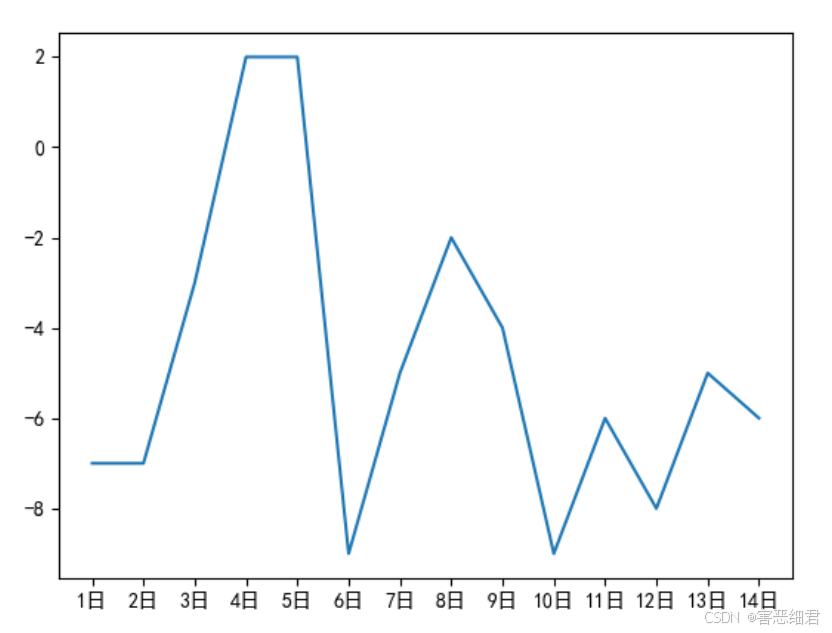
示例2:读取天气Excel表,分析14日天气最高温度情况。
# 导入相关模块
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码
plt.rcParams['axes.unicode_minus'] = False #解决负号不显示
df=pd.read_excel('./data/天气.xlsx') # 读取Excel文件
x =df['日期'] # x轴数据
y=df['最高温度'] # y轴数据
plt.plot(x,y) # 折线图
plt.show() # 显示图表
color参数可以设置线条颜色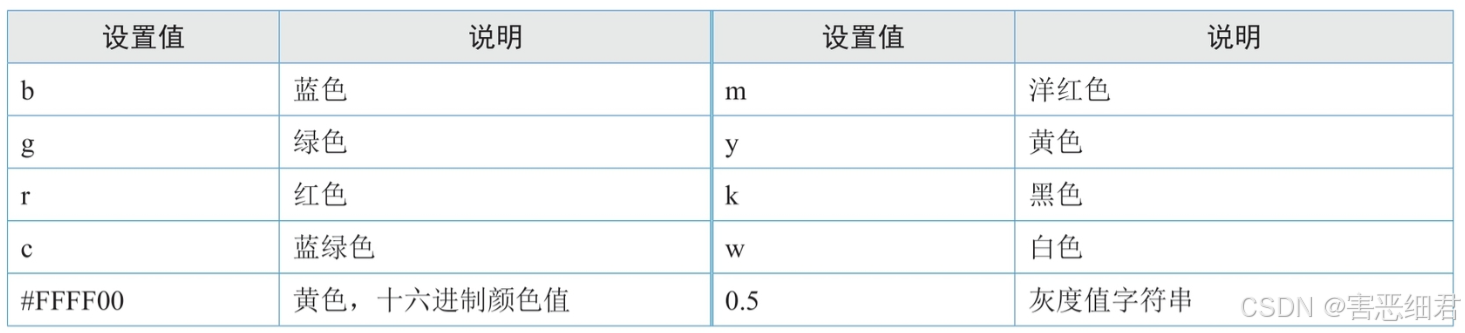
linestyle可选参数可以设置线条样式,设置值如下-:实线,默认值。--:双画线-.:点画线。::虚线。
marker可选参数可以设置标记样式: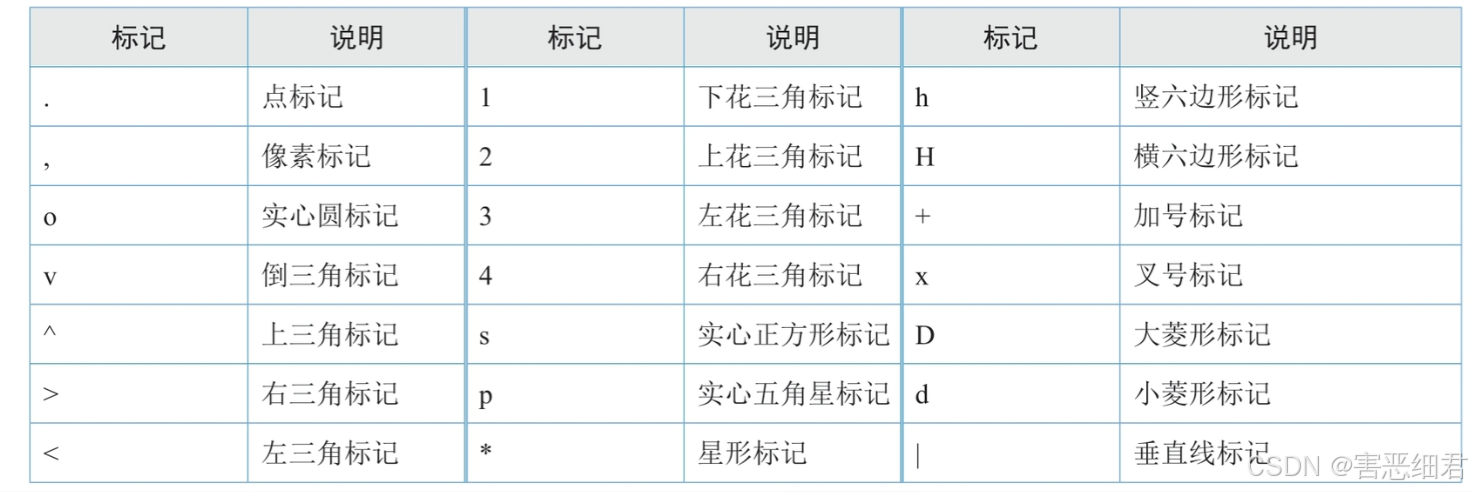
举例:
# 导入相关模块
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码
plt.rcParams['axes.unicode_minus'] = False #解决负号不显示
df=pd.read_excel('./data/天气.xlsx') # 读取Excel文件
x =df['日期'] # x轴数据
y=df['最高温度'] # y轴数据
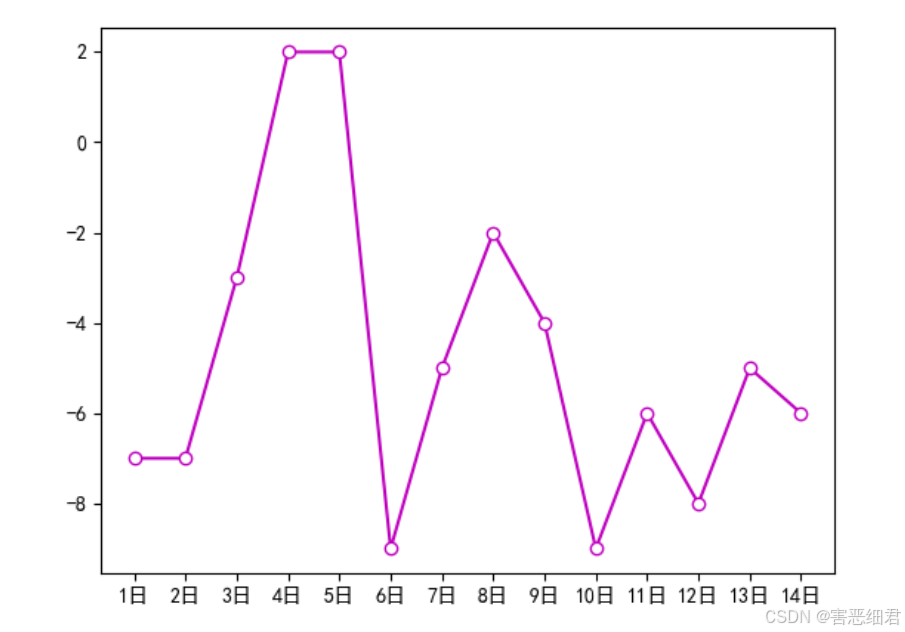
# color为线条颜色,linestyle为线条样式,marker为标记样式,mfc为标记填充颜色
plt.plot(x,y,color='m',linestyle='-',marker='o',mfc='w')
plt.show()
(2) 设置画布
画布就像我们画画用的画板一样,在Matplotlib中可以使用figure()函数设置画布大小、分辨率、颜色和边框等,语法格式如下:
matplotlib.pyplot.figure(num=None, figsize=None, dpi=None, facecolor=None, edgecolor=None, frameon=True,
FigureClass=<class 'matplotlib.figure.Figure'>, clear=False, **kwargs)
num:画布编号或名称,数字为编号,字符串为名称,可以通过该参数激活不同的画布。figsize:指定画布的宽和高,单位为英寸。dpi:指定绘图对象的分辨率,即每英寸包含多少像素,默认值为80。像素越大画布越大。facecolor:背景颜色。edgecolor:边框颜色。frameon:是否绘制边框,默认值为True,表示绘制边框;如果为False,则不绘制边框。
自定义一个5×3的黄色画布,主要代码如下:
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码
plt.rcParams['axes.unicode_minus'] = False #解决负号不显示
fig=plt.figure(figsize=(5,3),facecolor='yellow')
df=pd.read_excel('./data/天气.xlsx') # 读取Excel文件
# 折线图
x=df['日期'] # x轴数据
y=df['最高温度'] # y轴数据
plt.plot(x,y,color='m',linestyle='-',marker='o',mfc='w')
plt.show()
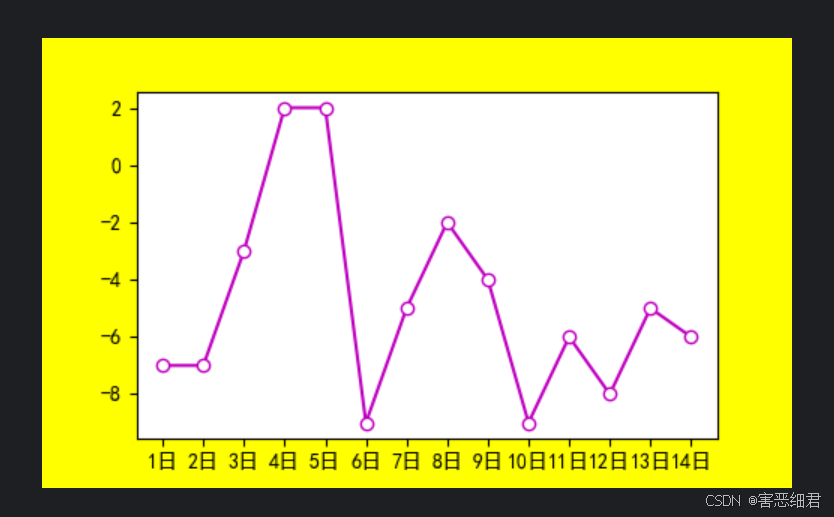
注意:figsize=(5,3),实际画布大小是500×300,所以,这里不要输入太大的数字。
(3) 设置坐标轴
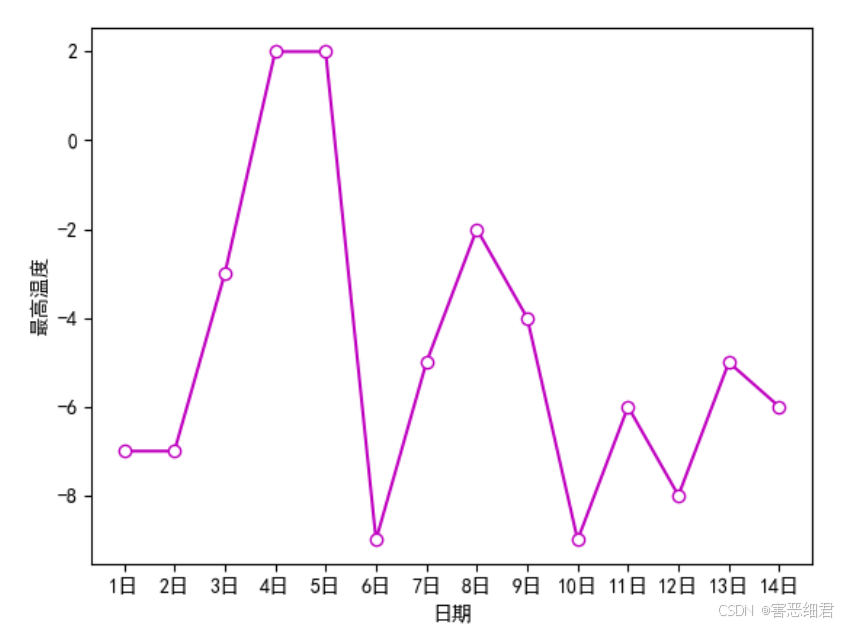
设置x轴和y轴标题主要使用xlabel()和ylabel()函数。
下面设置x轴标题为“日期”,y轴标题为“最高温度”,主要代码如下:
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码
plt.rcParams['axes.unicode_minus'] = False #解决负号不显示
df=pd.read_excel('./data/天气.xlsx') # 读取Excel文件
# 折线图
x=df['日期'] # x轴数据
y=df['最高温度'] # y轴数据
plt.plot(x,y,color='m',linestyle='-',marker='o',mfc='w')
plt.xlabel('日期') #x轴标题
plt.ylabel('最高温度') #y轴标题
plt.show()
用Matplotlib绘制二维图像时,默认情况下的横坐标(x轴)和纵坐标(y轴)显示的值可能达不到我们的要求,这时需要借助xticks()函数和yticks()函数分别对x轴和y轴的值进行设置。
xticks()函数的语法格式如下:
matplotlib.pyplot.xticks(ticks=None, labels=None, **kwargs)
ticks:数组,表示x轴上的刻度。例如,在“学生英语成绩分布图”中,x轴的刻度是2~14的偶数,如果想改变这个值,就可以通过locs参数设置。
在“14日天气最高温度折线图”中,y轴刻度是-8到2之间的偶数,下面使用yticks()函数将y轴的刻度设置为-10到10的连续数字,主要代码如下:
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码
plt.rcParams['axes.unicode_minus'] = False #解决负号不显示
df=pd.read_excel('./data/天气.xlsx') # 读取Excel文件
# 折线图
x=df['日期'] # x轴数据
y=df['最高温度'] # y轴数据
plt.plot(x,y,color='m',linestyle='-',marker='o',mfc='w')
plt.xlabel('日期') # x轴标题
plt.ylabel('最高温度') # y轴标题
# 设置y轴刻度
plt.yticks(range(-10,10,1))
plt.show()
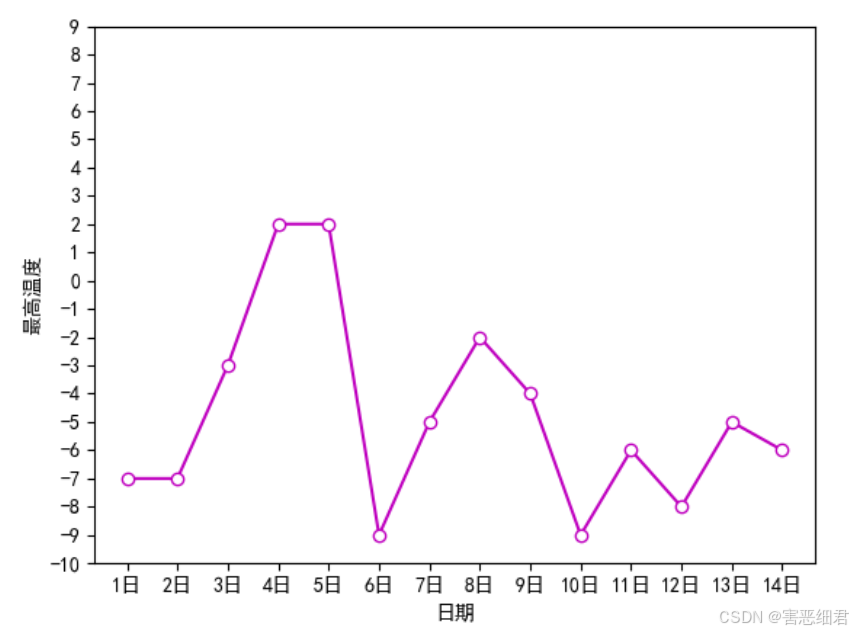
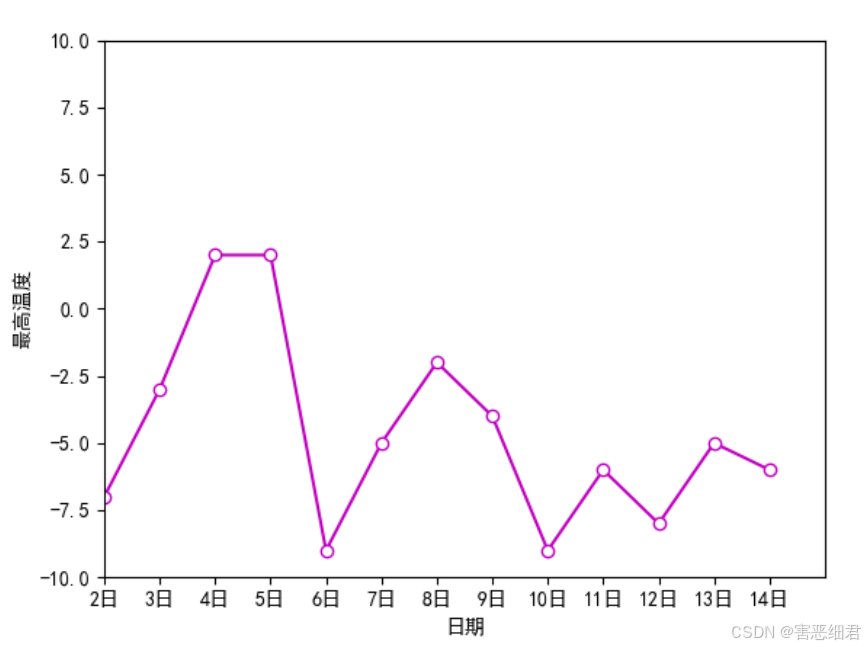
坐标轴范围是指x轴和y轴的取值范围。设置坐标轴范围主要使用xlim()函数和ylim()函数。
例如设置x轴(日期)范围为1~14,y轴(最高温度)范围为-10~10,主要代码如下:
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码
plt.rcParams['axes.unicode_minus'] = False #解决负号不显示
df=pd.read_excel('./data/天气.xlsx') # 读取Excel文件
# 折线图
x=df['日期'] # x轴数据
y=df['最高温度'] # y轴数据
plt.plot(x,y,color='m',linestyle='-',marker='o',mfc='w')
plt.xlabel('日期') # x轴标题
plt.ylabel('最高温度') # y轴标题
# 坐标轴范围
plt.xlim(1,14)
plt.ylim(-10,10)
plt.show()
细节决定成败。很多时候,为了图表的美观,我们不得不考虑细节,下面介绍图表细节之一——网格线。设置网格线主要使用grid()函数,grid()函数也有很多参数,如颜色、网格线方向(参数axis='x'表示隐藏x轴网格线,axis='y'表示隐藏y轴网格线)、网格线样式和网格线宽度等。下面为图表设置网格线,主要代码如下:
plt.grid(color='0.5',linestyle="--",linewidth=1)
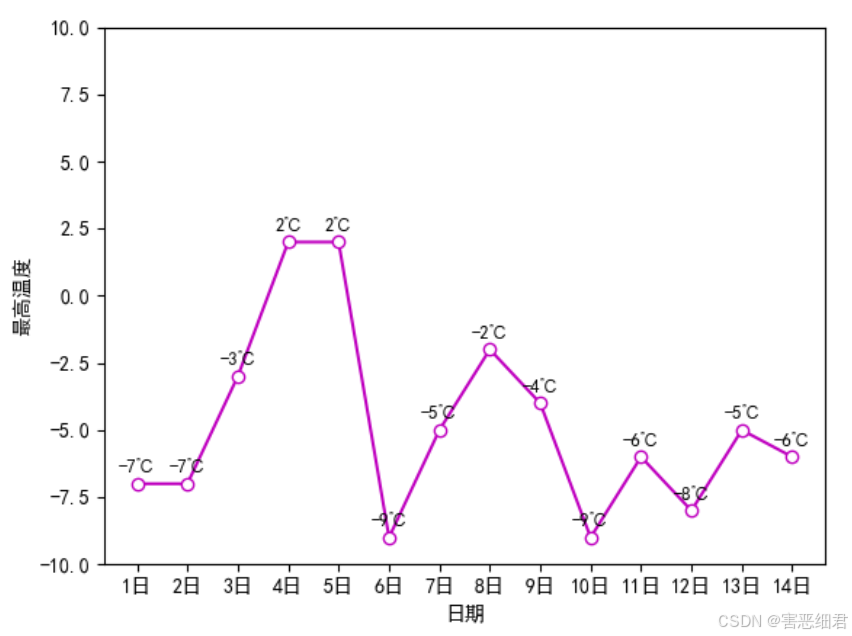
(4)添加文本标签
在绘图过程中,为了能够更清晰、直观地看到数据,有时需要为图表中指定的数据点添加文本标签。下面介绍细节之二——文本标签,主要使用text()函数设置。
下面为图表中各个数据点添加最高温度文本标签,主要代码如下。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码
plt.rcParams['axes.unicode_minus'] = False #解决负号不显示
df=pd.read_excel('./data/天气.xlsx') # 读取Excel文件
# 折线图
x=df['日期'] # x轴数据
y=df['最高温度'] # y轴数据
plt.plot(x,y,color='m',linestyle='-',marker='o',mfc='w')
plt.xlabel('日期') # x轴标题
plt.ylabel('最高温度') # y轴标题
plt.ylim(-10,10)
for a,b in zip(x,y):
plt.text(a,b+0.3,'%.0f'%b+'℃',ha = 'center',va = 'bottom',fontsize=9)
plt.show()
(5) 设置标题和图例
图表标题:为图表设置标题主要使用title()函数。
图表图例:为图表设置图例主要使用legend()函数。
这里需要注意一个问题,当手动添加图例时,有时会出现文本显示不全的问题,解决方法是在文本后面加一个逗号,,主要代码如下:
plt.legend(('最高温度',))
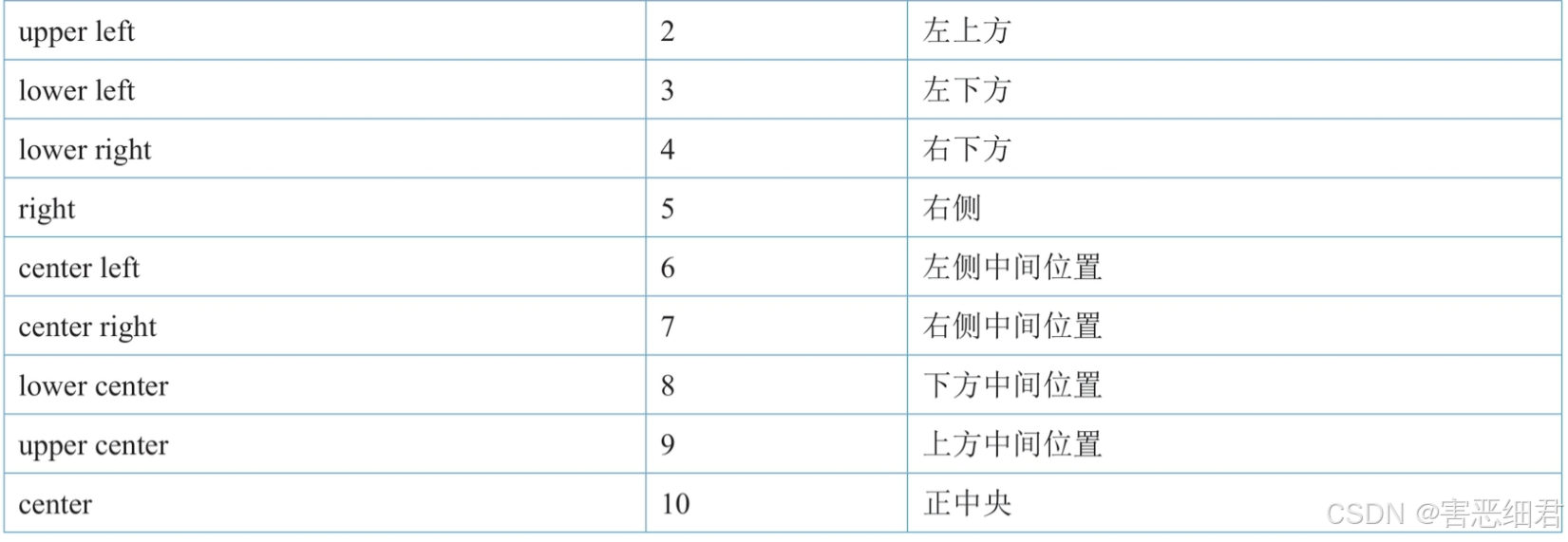
设置图例显示位置通过loc参数可以设置,如在左下方显示,主要代码如下:
plt.legend(('最高温度',),loc='upper right',fontsize=10)
图例显示位置参数设置值:
(6) 添加注释
annotate()函数用于给图表数据添加文本注释,而且支持带箭头的画线工具,方便我们在合适的位置添加描述信息。
在“14日天气最高温度折线图”中用箭头指示最高温度,代码如下:
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码
plt.rcParams['axes.unicode_minus'] = False # 解决负号不显示
df = pd.read_excel('./data/天气.xlsx') # 读取Excel文件
# 折线图
x = df['日期'] # x轴数据
y = df['最高温度'] # y轴数据
plt.plot(x, y, color='m', linestyle='-', marker='o', mfc='w')
plt.xlabel('日期') # x轴标题
plt.ylabel('最高温度') # y轴标题
# 图表标题
plt.title(label='14日天气最高温度折线图', fontsize='18')
plt.ylim(-10, 10)
for a, b in zip(x, y):
plt.text(a, b + 0.3, '%.0f' % b + '℃', ha='center', va='bottom', fontsize=9)
plt.annotate('最高温度', xy=(4,2), xytext=(5.5,2),xycoords='data',arrowprops=dict(facecolor='r', shrink=0.05))
plt.show()
xy:被注释的坐标点,二维元组,如(x,y)。xytext:注释文本的坐标点(上述示例中箭头的位置),也是二维元组,默认与xy相同。xycoords:被注释点的坐标系属性。
xycoords参数设置值: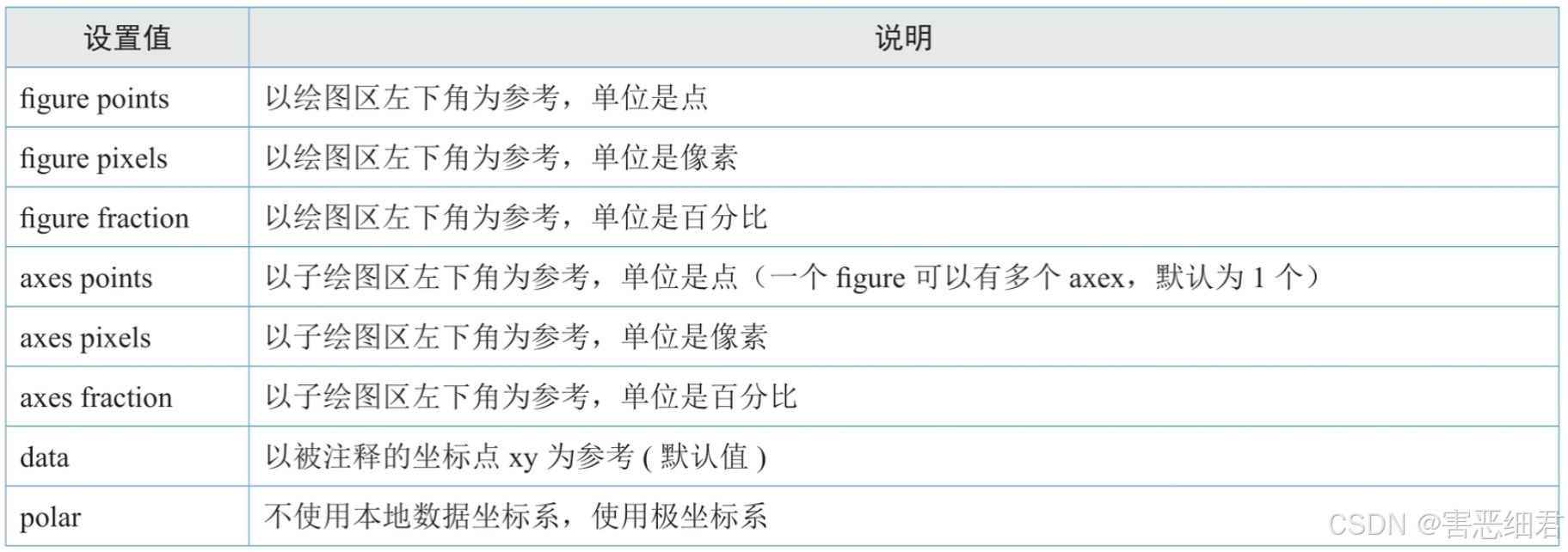
arrowprops:箭头的样式,字典型数据,如果该属性值非空,则会在注释文本和被注释点之间画一个箭头。
arrowprops参数设置值: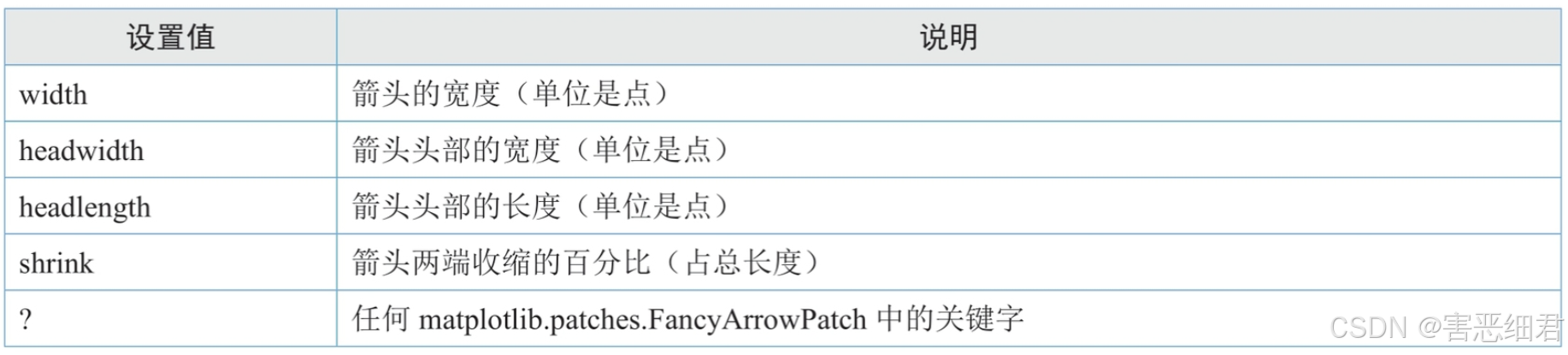
4. 常用图表的绘制
(1) 绘制折线图
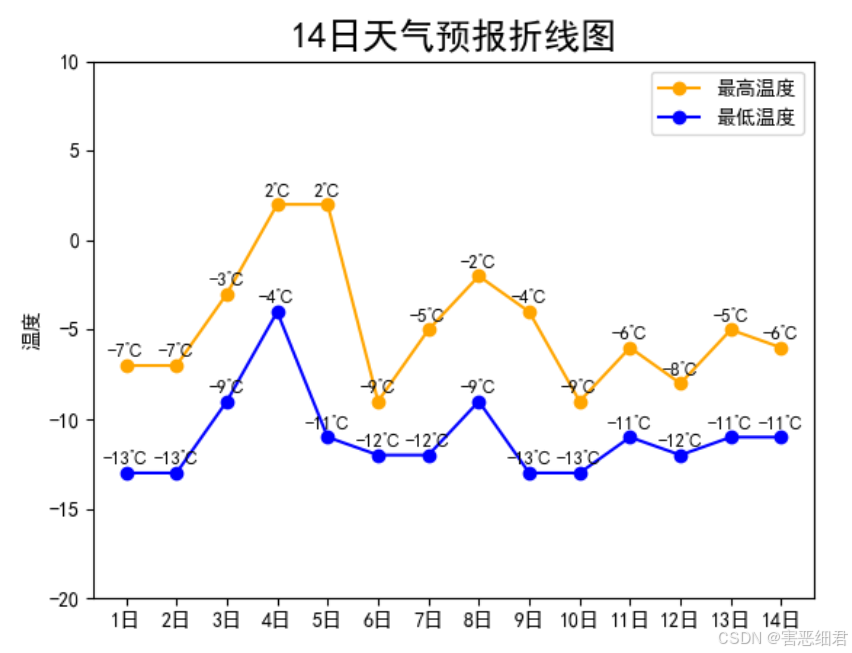
下面使用plot()函数绘制多折线图,例如,绘制14日天气预报折线图,程序代码如下:
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码
plt.rcParams['axes.unicode_minus'] = False #解决负号不显示
df=pd.read_excel('./data/天气.xlsx') # 读取Excel文件
x=df['日期'] # x轴数据
# y轴数据
y1=df['最高温度']
y2=df['最低温度']
# 多折线图
plt.plot(x,y1,label='最高气温',color='orange',marker='o')
plt.plot(x,y2,label='最低气温',color='blue',marker='o')
plt.ylabel('温度') # y轴标题
plt.title(label='14日天气预报折线图',fontsize='18') # 图表标题
plt.ylim(-20,10)
# 添加文本标签
for a,b in zip(x,y1):
plt.text(a,b+0.3,'%.0f'%b+'℃',ha = 'center',va = 'bottom',fontsize=9)
for a,b in zip(x,y2):
plt.text(a,b+0.3,'%.0f'%b+'℃',ha = 'center',va = 'bottom',fontsize=9)
plt.legend(['最高温度', '最低温度']) # 图例
plt.show() # 显示图表
(2) 绘制柱形图
Matplotlib绘制柱形图主要使用bar()函数,下面我们通过5行代码绘制简单的柱形图,程序代码如下:
import matplotlib.pyplot as plt
x=[1,2,3,4,5,6]
height=[10,20,30,40,50,60]
plt.bar(x,height)
plt.show()
(3) 绘制饼形图
Matplotlib绘制饼形图主要使用pie()函数,下面绘制简单饼形图,程序代码如下:
# 导入matplotlib模块
import matplotlib.pyplot as plt
x = [2,5,12,70,2,9] # x轴数据
plt.pie(x,autopct='%1.1f%%') # 绘制饼形图
plt.show() # 显示图表
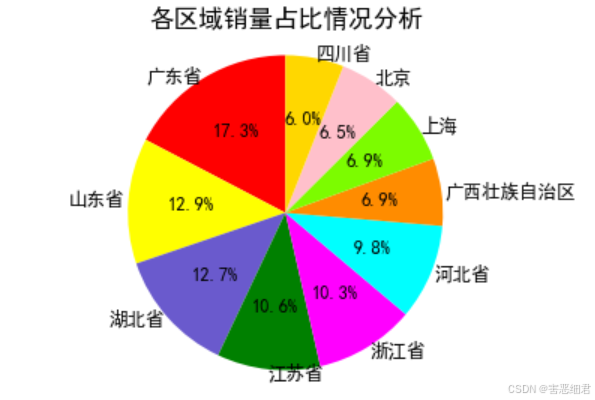
下面通过饼形图分析各区域销量占比情况,程序代码如下:
# 导入相关模块
import pandas as pd
from matplotlib import pyplot as plt
# 读取Excel文件
df1 = pd.read_excel(io='./data/address.xlsx',sheet_name='Sheet2')
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文乱码
plt.figure(figsize=(5,3)) #设置画布大小
labels = df1['省']
sizes = df1['销量']
#设置饼形图每块的颜色
colors = ['red', 'yellow', 'slateblue', 'green','magenta','cyan','darkorange','lawngreen','pink','gold']
plt.pie(sizes, #绘图数据
labels=labels,#添加区域水平标签
colors=colors,# 设置饼图的自定义填充色
labeldistance=1.02,#设置各扇形标签(图例)与圆心的距离
autopct='%.1f%%',# 设置百分比的格式,这里保留一位小数
startangle=90,# 设置饼图的初始角度
radius = 0.5, # 设置饼图的半径
center = (0.2,0.2), # 设置饼图的原点
textprops = {'fontsize':9, 'color':'k'}, # 设置文本标签的属性值
pctdistance=0.6)# 设置百分比标签与圆心的距离
# 设置x,y轴刻度一致,保证饼图为圆形
plt.axis('equal')
plt.title('各区域销量占比情况分析') # 图表标题
plt.show() # 显示图表
(4) 绘制散点图
散点图主要用来查看数据的分布情况或相关性,一般用在线性回归分析中,查看数据点在坐标系平面上的分布情况。散点图表示因变量随自变量变化的大致趋势,据此可以选择合适的函数对数据点进行拟合。
绘制简单散点图,程序代码如下。
# 导入matplotlib模块
import matplotlib.pyplot as plt
x=[1,2,3,4,5,6] # x轴数据
y=[19,24,37,43,55,68] # y轴数据
plt.scatter(x, y) # 绘制散点图
plt.show() # 显示图表
(5) 绘制箱形图
箱形图又称箱线图、盒须图或盒式图,它是一种用来显示一组数据离散情况的统计图因形状像箱子而得名。箱形图最大的优点就是不受异常值的影响(异常值也称为离群值),可以以一种相对稳定的方式描述数据的离散情况,因此在各领域中被广泛使用。另外,箱形图也常用于异常值的识别。Matplotlib绘制箱形图主要使用boxplot()函数。
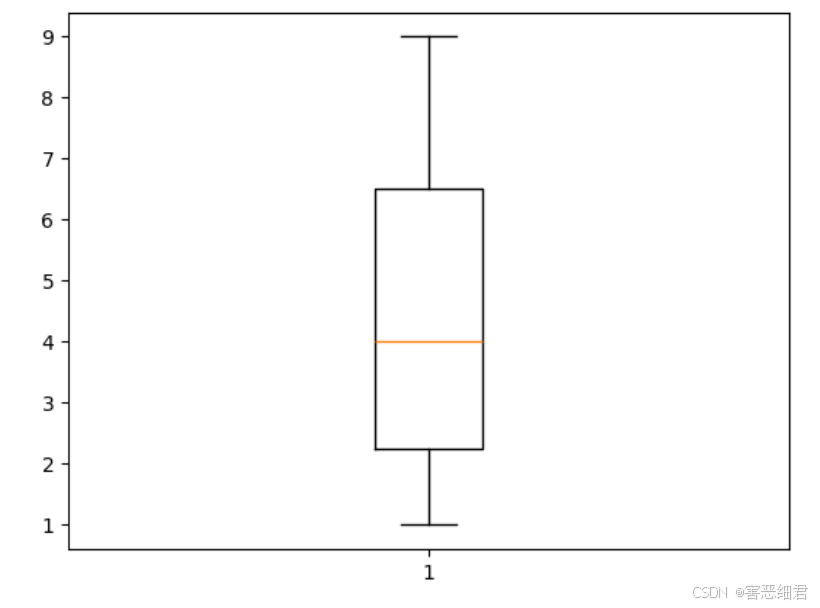
绘制简单箱形图,程序代码如下:
# 导入matplotlib模块
import matplotlib.pyplot as plt
x=[1,2,3,5,7,9] # x轴数据
plt.boxplot(x) # 箱形图
plt.show() # 显示图表
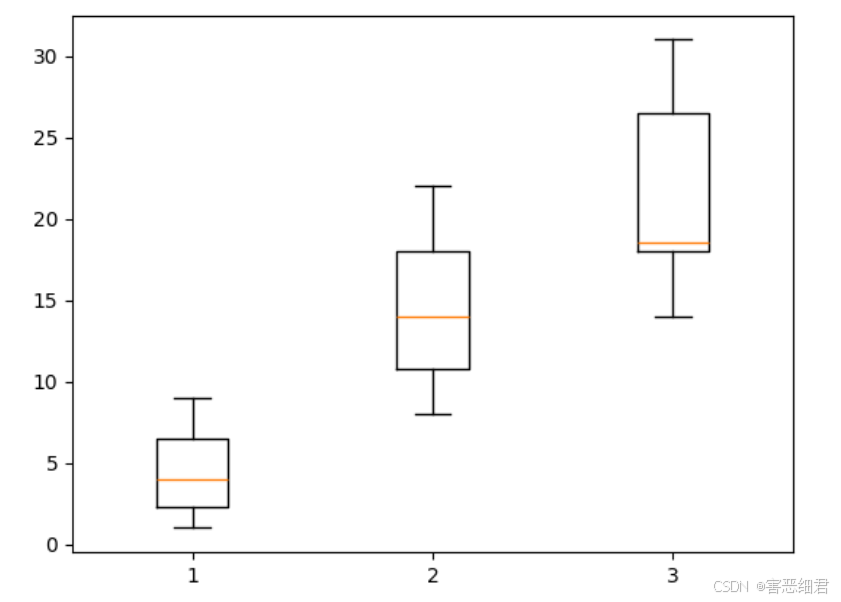
还可以绘制多组数据的箱形图,需要指定多组数据。例如,为三组数据绘制箱形图,主要代码如下:
# 导入matplotlib模块
import matplotlib.pyplot as plt
# 箱形图的数据
x1=[1,2,3,5,7,9];x2=[10,22,13,15,8,19];x3=[18,31,18,19,14,29]
plt.boxplot([x1,x2,x3]) # 箱形图
plt.show() # 显示图表
下面介绍箱形图每部分的具体含义及如何通过箱形图判断异常值。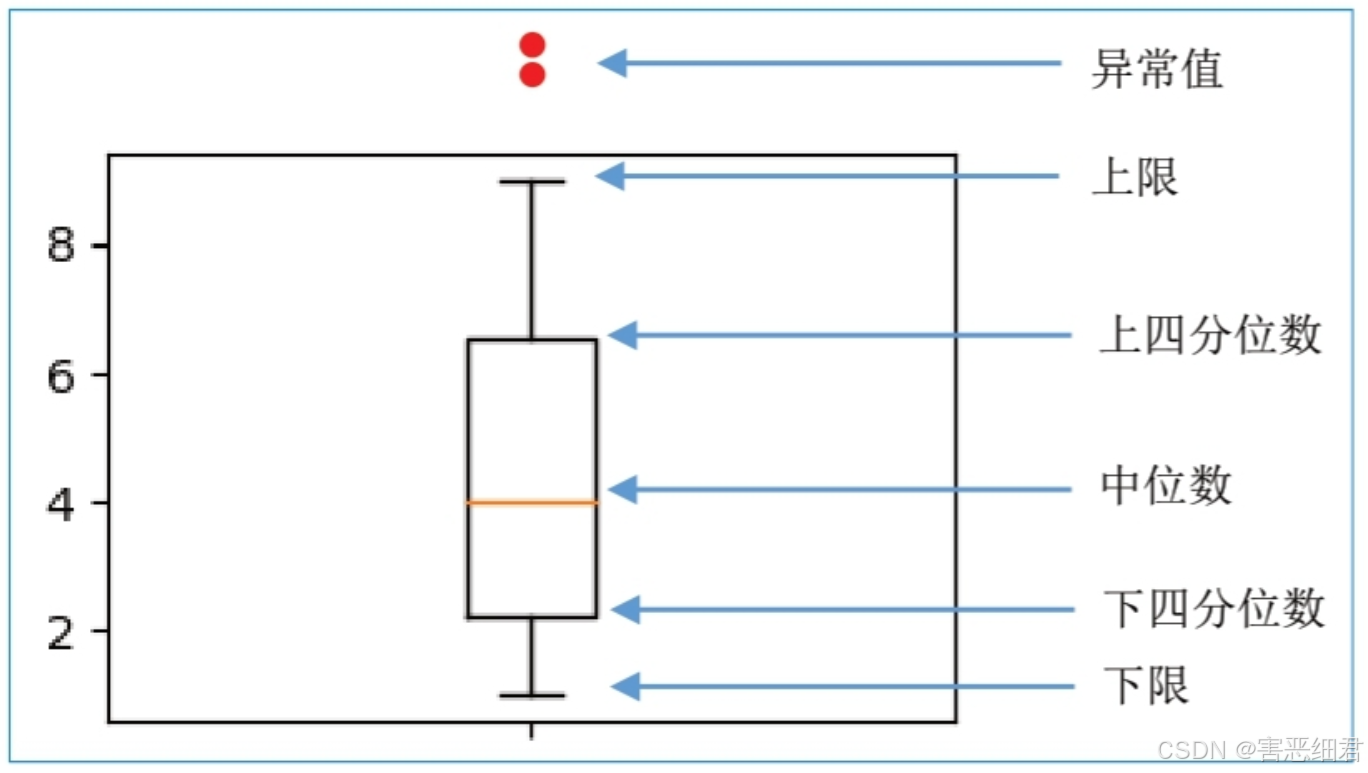
下面介绍箱形图每部分的具体含义及如何通过箱形图判断异常值。
(1)下四分位数
图中的下四分位数指的是数据的25%分位点所对应的值(Q1)。计算分位数可以使用Pandas的quantile()函数。
(2)中位数
中位数即数据的50%分位点所对应的值(Q2)。
(3)上四分位数
上四分位数则为数据的75%分位点所对应的值(Q3)。
(4)上限。
上限的计算公式为:Q3+1.5(Q3-Q1)。
(5)下限
下限的计算公式为:Q1-1.5(Q3-Q1)。
其中,Q3-Q1表示四分位差。如果使用箱形图判断异常值,其判断标准是,当变量的数据值大于箱形图的上限或者小于箱线图的下限时,就可以将这样的数据值判定为异常值。下面介绍判断异常值的标准。
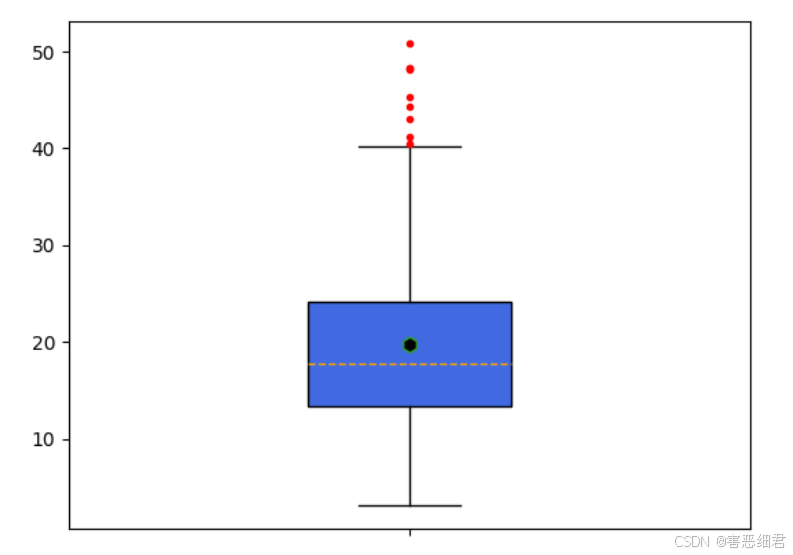
通过箱形图查找客人总消费数据中存在的异常值,程序代码如下:
# 导入相关模块
import matplotlib.pyplot as plt
import pandas as pd
df=pd.read_excel('./data/tips.xlsx')
plt.boxplot(x = df['总消费'], # 指定绘制箱线图的数据
whis = 1.5, # 指定1.5倍的四分位差
widths = 0.3, #指定箱线图中箱子的宽度为0.3
patch_artist = True, #填充箱子颜色
showmeans = True, #显示均值
boxprops = {'facecolor':'RoyalBlue'}, # 指定箱子的填充色为宝蓝色
flierprops = {'markerfacecolor':'red', 'markeredgecolor':'red', 'markersize':3}, # 指定异常值的填充色、边框色和大小
meanprops = {'marker':'h','markerfacecolor':'black', 'markersize':8},# 指定均值点的标记符号(六边形)、填充色和大小
medianprops = {'linestyle':'--','color':'orange'}, # 指定中位数的标记符号(虚线)和颜色
labels = ['']) # 去除x轴刻度值
plt.show() # 显示图表
# 计算下四分位数和上四分位
Q1 = df['总消费'].quantile(q = 0.25)
Q3 = df['总消费'].quantile(q = 0.75)
# 基于1.5倍的四分位差计算上下限对应的值
low_limit = Q1 - 1.5*(Q3 - Q1)
up_limit = Q3 + 1.5*(Q3 - Q1)
# 查找异常值
val=df['总消费'][(df['总消费'] > up_limit) | (df['总消费'] < low_limit)]
print('异常值如下:')
print(val)
(6) 绘制多个子图表
Matplotlib可以实现在一张图上绘制多个子图表。Matplotlib提供了三种方法:subplot()函数、subplots()函数、add_subplot()方法。
绘制一个2行3列包含6个子图的空图表,程序代码如下:
# 导入matplotlib模块
import matplotlib.pyplot as plt
# 绘制一个2×3包含6个子图的空图表
plt.subplot(2,3,1)
plt.subplot(2,3,2)
plt.subplot(2,3,3)
plt.subplot(2,3,4)
plt.subplot(2,3,5)
plt.subplot(2,3,6)
plt.show() # 显示图表
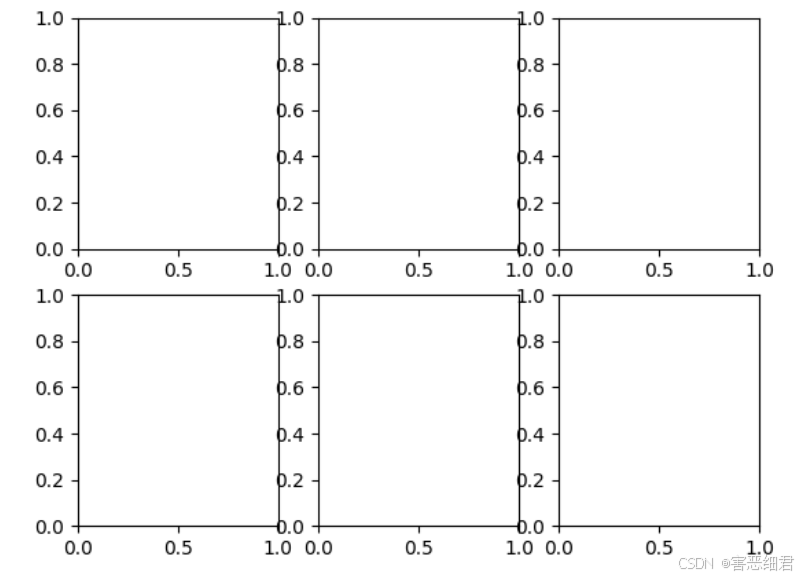
通过上述示例我们了解了subplot()函数的基本用法,接下来将前面所学的简单图表整合到一张图表上,代码如下:
# 导入matplotlib模块
import matplotlib.pyplot as plt
# 第1个子图表-折线图
plt.subplot(2,2,1)
plt.plot([1, 2, 3, 4,5])
# 第2个子图表-散点图
plt.subplot(2,2,2)
plt.plot([1, 2, 3, 4,5], [2, 5, 8, 12,18], 'ro')
# 第3个子图表-柱形图
plt.subplot(2,1,2)
x=[1,2,3,4,5,6]
height=[10,20,30,40,50,60]
plt.bar(x,height)
plt.show() # 显示图表
上述示例中有两个关键点一定要掌握。
(1)每绘制一个子图都要调用一次subplot()函数。
(2)要指定绘图区域的位置编号。subplot()函数的前两个参数指定的是一个画布被分割的行数和列数,最后一个参数则指定的是当前绘制区域的位置编号,编号规则是行优先。
例如,上面案例的第1个子图subplot(2,2,1),即将画布分成2行2列,在第1个子图中绘制折线图;第2个子图subplot(2,2,2),即将画布分成2行2列,在第2个子图中绘制散点图;第3个子图subplot(2,1,2),即将画布分成2行1列,由于第1行已经占用,所以在第2行,也就是第3个子图中绘制柱形图。
四. 数组计算模块NumPy
NumPy是数据分析“三剑客”之一,主要用于数组计算、矩阵运算和科学计算。
1. 初识NumPy
NumPy提供了一个高性能的数组对象,让我们能够轻松创建一维数组、二维数组和多维数组,以及大量的函数和方法,帮助我们轻松地进行数组计算,因此NumPy被广泛地应用于数据分析、机器学习、图像处理、计算机图形学、数学任务等领域。
NumPy是数据分析、机器学习“三剑客”之一,它的用途是以数组的形式对数据进行操作。机器学习中充斥了大量的数组计算,而NumPy使得这些计算变得简单!由于NumPy是用C语言实现的,所以其运算速度非常快。
安装NumPy:
pip install numpy
测试是否安装成功,程序代码如下:
# 导入numpy模块
from numpy import *
# 生成对角矩阵
print(eye(4))

(1) 数组相关概念
学习NumPy前,我们先了解一下数组的相关概念。数组可分为一维数组、二维数组、三维数组。三维数组是常见的多维数组。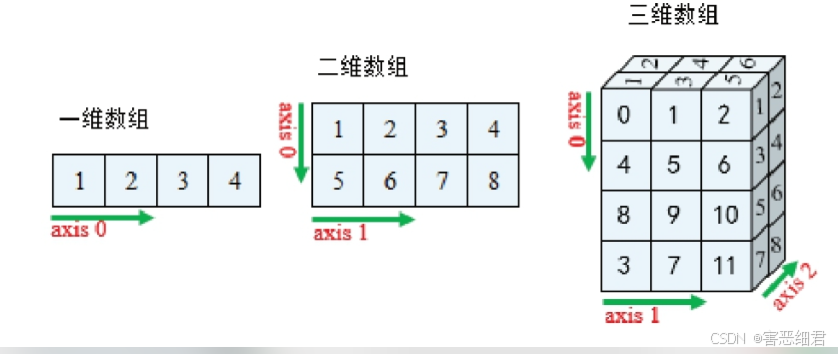
一维数组:一维数组很简单,基本和Python列表一样,区别在于数组切片针对的是原数组(这就意味着,如果对数组进行修改,原数组也会跟着更改)。
二维数组:二维数组本质是以数组作为元素的数组。二维数组包括行和列,形状类似于表格,又称为矩阵。
三维数组:三维数组是指维数为三的数组结构,也称矩阵列表。三维数组是最常见的多维数组,由于其可以用来描述三维空间中的位置或状态,因而被广泛使用。
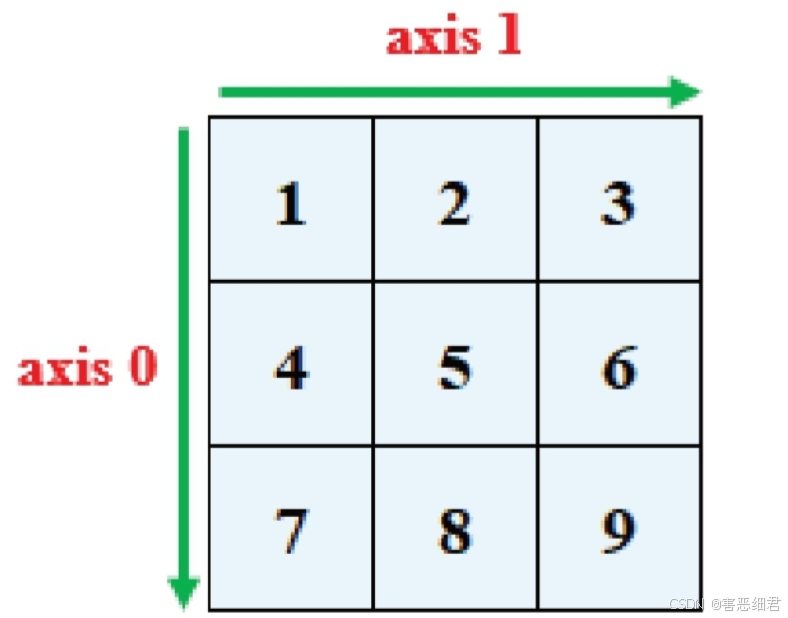
轴的概念
轴是NumPy里的axis,指定某个axis,就是沿着这个axis执行相关操作,其中二维数组中两个轴的指向如图所示。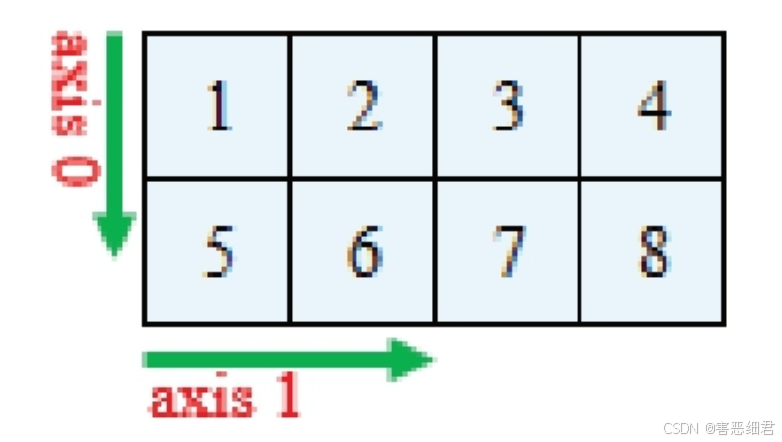
2. 创建数组
NumPy创建简单的数组主要使用array()函数,语法格式如下:
numpy.array(object, dtype=None, copy=True, order='K', subok=False, ndmin=0)
object:任何具有数组接口方法的对象。dtype:数据类型。copy:布尔值,可选参数,默认值为True,表示object对象被复制,生成副本;否则,只有当_array_返回副本,object参数为嵌套序列,或者需要副本满足数据类型和顺序要求时,才会生成副本。order:元素在内存中的出现顺序,值为K、A、C、F。如果object参数不是数组,则新创建的数组将按行排列(C);如果值为F,则按列排列;如果object参数是一个数组,则顺序规则为C(按行排列)、F(按列排列)、A(保持原顺序)、K(遵循元素在内存中的出现顺序)bok:布尔值,如果值为True,则传递子类,否则返回的数组为基类数组(默认值)。ndmin:指定生成数组的最小维数。
创建几个简单的数组,效果如图所示。
程序代码如下:
import numpy as np
n1=np.array([1,2,3])
n2=np.array([0.1,0.2,0.3])
n3=np.array([[1,2],[3,4]])
NumPy支持的数据类型比Python更多,通过dtype参数可以指定数组的数据类型,程序代码如下:
import numpy as np #导入numpy模块
list = [1, 2, 3] #列表
# 创建浮点型数组
n1= np.array(list,dtype=float)
print(n1)
print(n1.dtype)
print(type(n1[0]))

数组的复制
当运算和处理数组时,为了不影响原数组,可以对原数组进行复制,对复制后的数组进行修改、删除等操作。数组的复制可以通过copy参数实现,程序代码如下:
import numpy as np #导入numpy模块
n1 = np.array([1,2,3]) #创建数组
n2 = np.array(n1,copy=True) #复制数组
n2[0]=3 #修改第1行数组为3
n2[2]=1 #修改第2行数组为1
print(n1)
print(n2)

创建指定维数和数据类型未初始化的数组主要使用empty()函数,程序代码如下:
import numpy as np
n = np.empty([2,3],dtype=int)
print(n)

这里,创建的数组元素为随机数,它们未被初始化。
创建指定维数并以0填充的数组,主要使用zeros()函数,程序代码如下:
import numpy as np
n = np.zeros(3)
print(n)
运行程序,结果为:[0.0.0.],输出结果默认是浮点型(float)的。
创建指定维数并以1填充的数组,主要使用ones()函数,程序代码如下:
import numpy as np
n = np.ones(3)
print(n)
运行程序,结果为:[1.1.1.]。
创建指定维数和数据类型的数组并以指定值填充,主要使用full()函数,程序代码如下:
import numpy as np
n = np.full(shape=(3,3), fill_value=8)
print(n)

通过arange()函数创建数组:
arange()函数与Python内置的range()函数相似,区别在于返回值不同,arange()函数的返回值是数组,而range()函数的返回值是列表。arange()函数的语法格式如下:
numpy.arange([start, ]stop, [step, ]dtype=None)
参数说明:start:起始值,默认值为0。stop:终止值(不包含该值)。step:步长,默认值为1。dtype:创建数组的数据类型,如果不设置数据类型,则使用输入数据的数据类型。
下面使用arange()函数按照数值范围创建数组,程序代码如下:
import numpy as np
n=np.arange(1,12,2)
print(n)
运行程序,结果为:[1 3 5 7 9 11]。
创建随机数组
生成随机数组主要使用NumPy的random模块,下面介绍几个常用的生成随机数组的函数。
rand()函数
rand()函数用于生成(0,1)区间的随机数组,输入一个值随机生成一维数组,输入一对值随机生成二维数组,语法格式如下:
numpy.random.rand(d0,d1,d2...,dn)
参数d0,d1,…,dn为整数,表示维数,可以为空值。
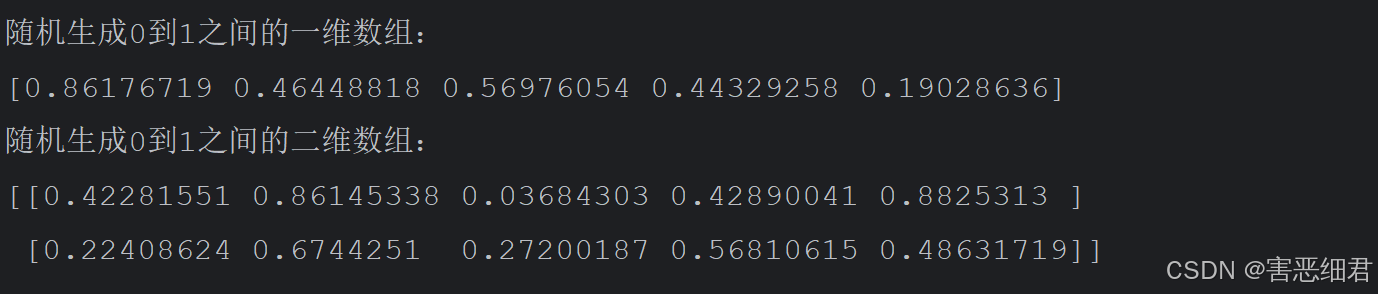
随机生成一维数组和二维数组,程序代码如下:
import numpy as np
n=np.random.rand(5)
print('随机生成0到1之间的一维数组:')
print(n)
n1=np.random.rand(2,5)
print('随机生成0到1之间的二维数组:')
print(n1)
randn()函数
randn()函数用于生成满足正态分布的随机数组,语法格式如下:
numpy.random.randn(d0,d1,d2...,dn)
参数d0,d1,…,dn为整数,表示维数,可以为空值。
生成满足正态分布的随机数组,程序代码如下:
import numpy as np
n1=np.random.randn(5)
print('随机生成满足正态分布的一维数组:')
print(n1)
n2=np.random.randn(2,5)
print('随机生成满足正态分布的二维数组:')
print(n2)

randint()函数
randint()函数与NumPy的arange()函数类似。randint()函数用于生成一定范围内的随机数组,返回值为左闭右开区间,语法格式如下:
numpy.random.randint(low,height=None,size=None)
参数说明:low:低值(起始值),整数,当参数high不为空值时,参数low的值应小值于参数high的值,否则程序会出现错误。high:高值(终止值),整数。size:数组维数,整数或者元组,整数表示一维数组,元组表示多维数组。默认值为空值,仅返回一个整数。
生成一定范围内的随机数组,程序代码如下:
import numpy as np
n1=np.random.randint(1,3,10)
print('随机生成10个1到3之间且不包括3的整数:')
print(n1)
n2=np.random.randint(5,10)
print('size数组大小为空随机返回一个整数:')
print(n2)
n3=np.random.randint(5,size=(2,5))
print('随机生成5以内二维数组')
print(n3)

normal()函数
normal()函数用于生成满足正态分布的随机数组,语法格式如下:
numpy.random.normal(loc,scale,size)
参数说明:loc:正态分布的均值,对应正态分布的中心。loc=0说明是一个以y轴为对称轴的正态分布。scale:正态分布的标准差,对应正态分布的宽度,scale值越大,正态分布的曲线越矮胖,scale值越小,曲线越高瘦。size:表示数组维数。
生成满足正态分布的随机数组,程序代码如下:
import numpy as np
n = np.random.normal(loc=0,scale=0.1,size=10)
print(n)
从已有的数组中创建数组
asarray()函数
asarray()函数用于创建数组,其与array()函数类似,语法格式如下:
numpy.asarray(a, dtype=None, order)
a:可以是列表、列表的元组、元组、元组的元组、元组的列表或多维数组。dtype:数组的数据类型。order:值为“C”和“F”,分别代表按行排列和按列排列,即数组元素在内存中的出现顺序。
使用asarray()函数创建数组,程序代码如下:
import numpy as np #导入numpy模块
n1 = np.asarray([1,2,3]) #通过列表创建数组
n2 = np.asarray([(1,1),(1,2)]) #通过列表的元组创建数组
n3 = np.asarray((1,2,3)) #通过元组创建数组
n4= np.asarray(((1,1),(1,2),(1,3))) #通过元组的元组创建数组
n5 = np.asarray(([1,1],[1,2])) #通过元组的列表创建数组
print(n1)
print(n2)
print(n3)
print(n4)
print(n5)
(3) 数组的基本操作
数据类型:
在对数组进行基本操作前,首先介绍一下NumPy数据类型。NumPy中的数据类型比Python中的数据类型更多。为了区别于Python数据类型,像bool、int、float、complex、str等数据类型名称末尾都加了下画线_。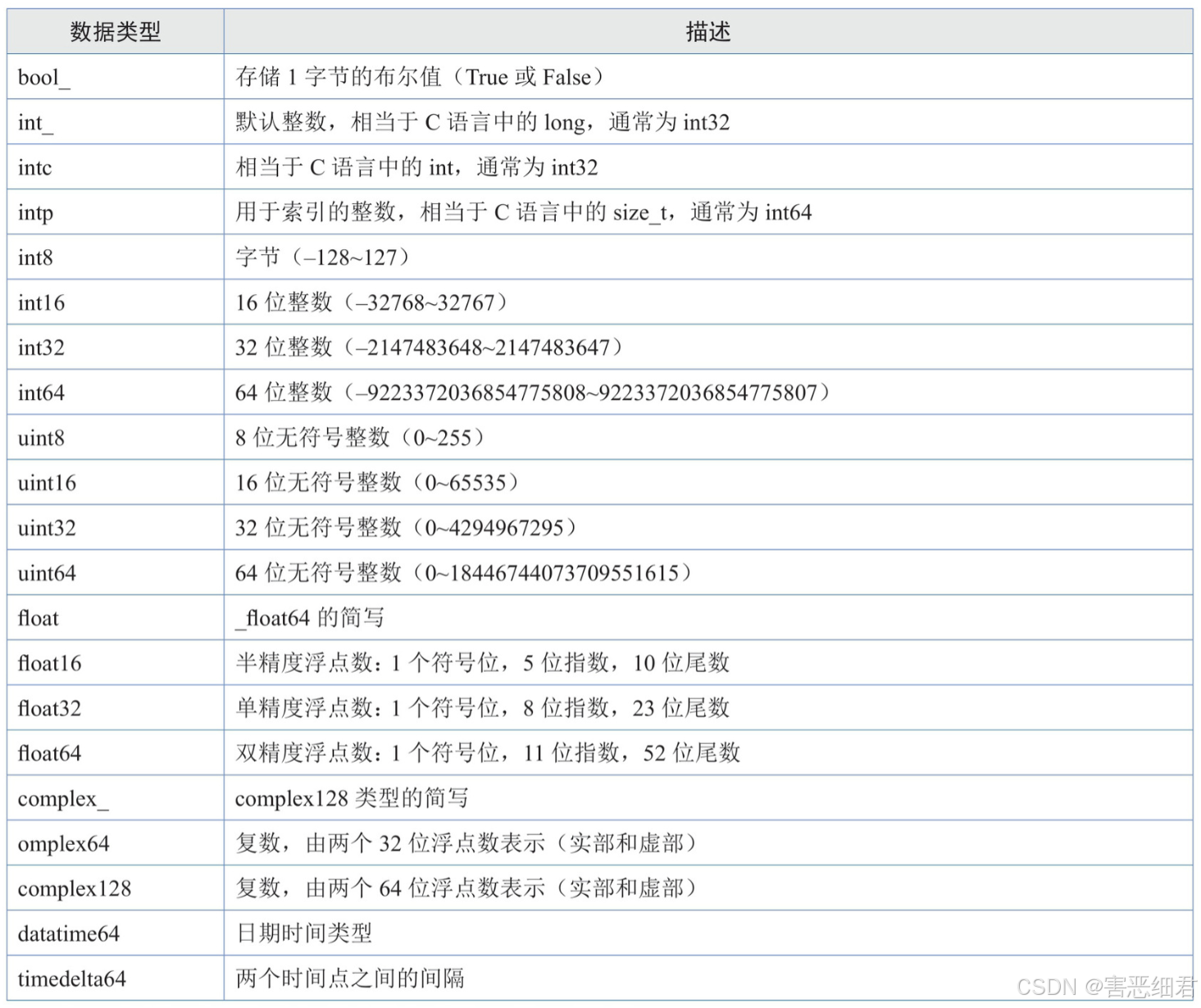
每一种数据类型都有相应的数据转换函数,举例如下:
import numpy as np
x1 = np.int8(3.141)
print(x1) # 3
x2 = np.float64(8)
print(x2) # 8.0
在创建ndarray数组时,可以直接指定数据类型,主要代码如下:
import numpy as np
x1 = np.arange(8,dtype=float)
print(x1) # [0. 1. 2. 3. 4. 5. 6. 7.]
注意:复数不能转换成整数或者浮点数,例如下面的代码会出现错误提示。
数组运算:
不用编写循环即可对数据执行批量运算,这是NumPy数组运算的特点,称为矢量化。大小相等的数组之间的任何算术运算,NumPy都可以实现。本节主要介绍简单的数组运算,如加、减、乘、除、幂运算等。下面创建两个简单的NumPy数组n1和n2,数组n1包括元素1和2,数组n2包括元素3和4,如下图所示。接下来实现这两个数组的运算。
1.加法运算
加法运算的规则是数组中对应位置的元素相加(即每行对应相加),如下图所示。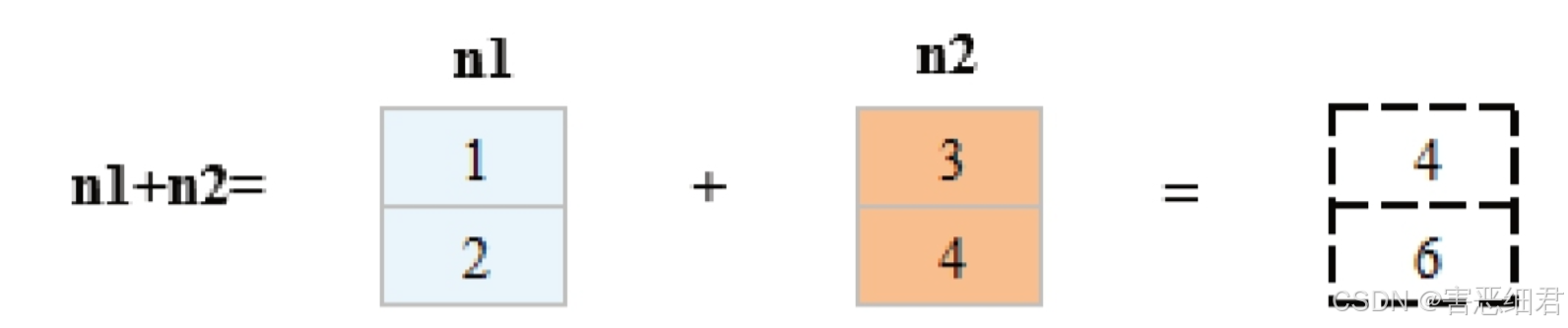
在程序中直接将两个数组相加即可,即n1+n2,程序代码如下:
import numpy as np
n1=np.array([1,2]) #创建一维数组
n2=np.array([3,4])
print(n1+n2) #加法运算
运行结果:[4 6]
2.减法、乘法和除法运算
除了加法运算,还可以实现数组的减法、乘法和除法运算,如下图所示。 同样地,在程序中直接将两个数组相减、相乘或相除即可,程序代码如下:
同样地,在程序中直接将两个数组相减、相乘或相除即可,程序代码如下:
import numpy as np
n1=np.array([1,2]) #创建一维数组
n2=np.array([3,4])
print(n1-n2) #减法运算
print(n1*n2) #乘法运算
print(n1/n2) #除法运算
运算结果如下:
3.幂运算
幂运算的规则是数组中对应位置的元素分别作为底数和指数进行运算,用**表示,如下图所示。
import numpy as np
n1=np.array([1,2]) #创建一维数组
n2=np.array([3,4])
print(n1**n2) #幂运算
输出结果: [ 1 16]
4.比较运算
数组的比较运算规则是对数组中对应位置元素进行大小比较,比较后的结果是布尔值数组,程序代码如下:
import numpy as np
n1=np.array([1,2]) #创建一维数组
n2=np.array([3,4])
print(n1>=n2) #大于等于
print(n1==n2) #等于
print(n1<=n2) #小于等于
print(n1!=n2) #不等于
运行程序,结果如下:
5.数组的标量运算
首先了解两个概念:标量和向量。标量其实就是一个单独的数;而向量是一组数,这组数是按顺序排列的,这里我们理解为数组。数组的标量运算也可以理解为向量与标量之间的运算。
例如,马拉松赛前训练,一周内每天的训练量以“米”为单位,下面将其转换为以“千米”为单位,数组的标量运算示意图如下所示。
在程序中,米转换为千米直接输入n1/1000即可,程序代码如下:
import numpy as np # 导入numpy模块
n1 = np.linspace(start=7500,stop=10000,num=6,dtype='int') # 创建等差数列数组
print(n1)
print(n1/1000) # 米转换为公里
运行程序,结果如下:
上述运算过程在NumPy中叫作“广播机制”,它是一个非常有用的功能。
数组的索引和切片:
NumPy数组元素是通过数组的索引和切片来访问和修改的,因此索引和切片是NumPy中最重要、最常用的概念。
1.索引
所谓数组的索引,是用于标记数组中对应元素的唯一数字,从0开始,即数组中的第一个元素的索引是0,以此类推。NumPy数组可以使用标准Python语法x[obj]来标记索引,其中x是数组,obj是索引。
获取一维数组n1中索引为0的元素,程序代码如下:
import numpy as np
n1=np.array([1,2,3]) #创建一维数组
print(n1[0]) # 1
再举一个例子,通过索引获取二维数组中的元素,程序代码如下:
import numpy as np
n1=np.array([[1,2,3],[4,5,6]]) #创建二维数组
print(n1[1][2]) # 6
2.切片式索引
数组切片可以理解为对数组的分割,按照等分或者不等分原则,将一个数组分割为多个片段,它与Python中列表的切片操作一样。NumPy中用冒号分隔切片参数来进行切片操作,语法格式如下:[start:stop:step]
参数说明:start:起始索引。 stop:终止索引。 step:步长。
实现简单的切片操作,对数组n1进行切片式索引,如下图所示。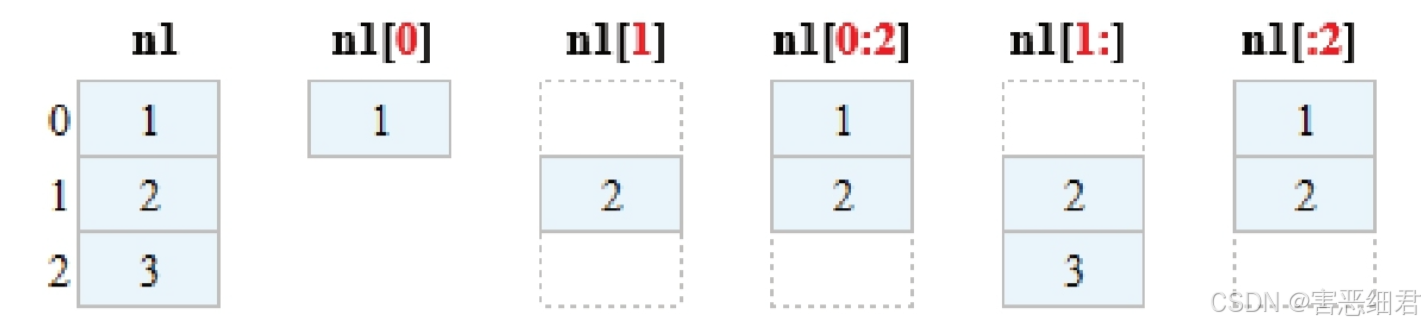
import numpy as np
n1=np.array([1,2,3]) #创建一维数组
print(n1[0])
print(n1[1])
print(n1[0:2])
print(n1[1:])
print(n1[:2])
运行程序,结果如下:
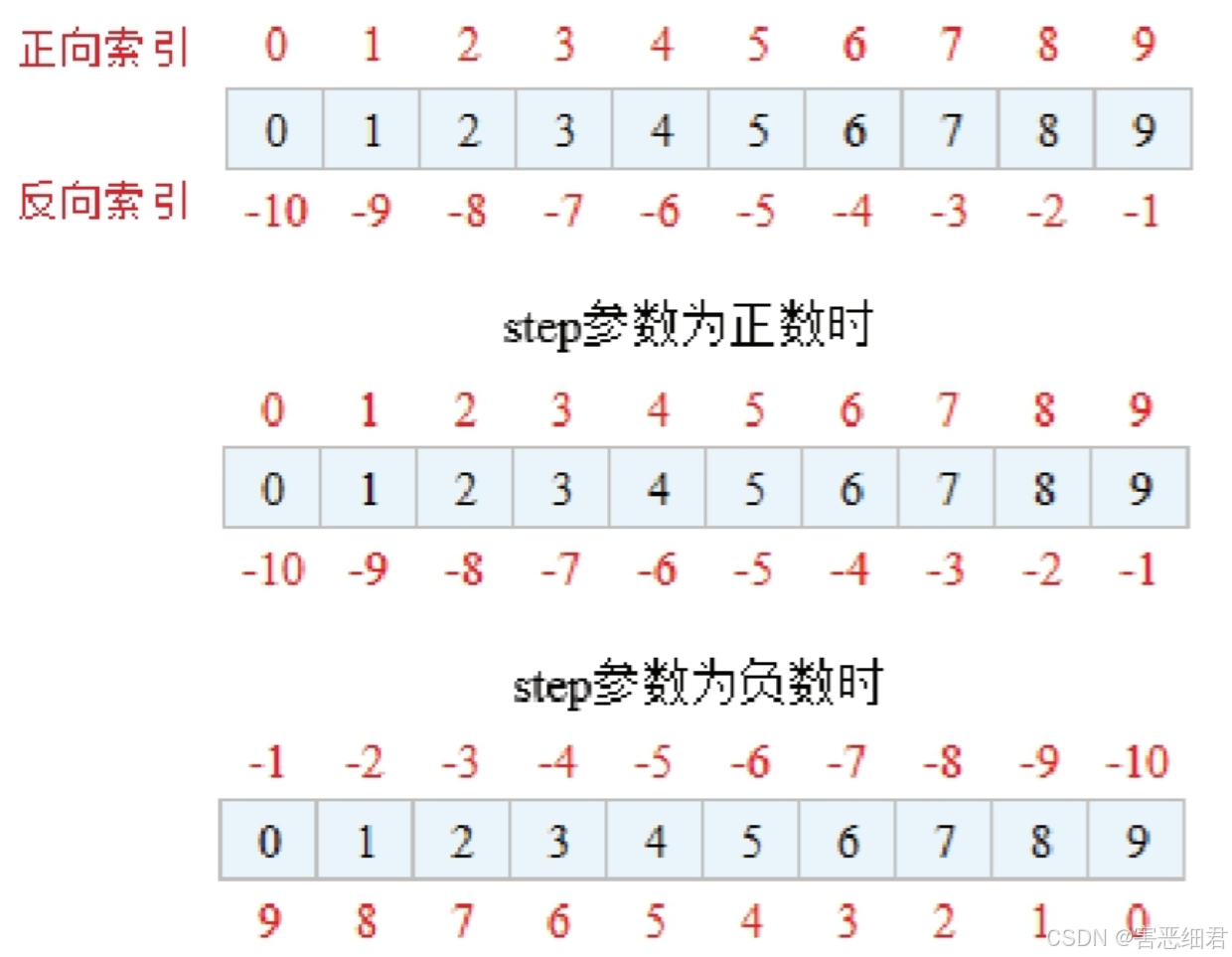
常用的切片式索引操作程序代码如下:
import numpy as np
n = np.arange(10) #使用arange()函数创建一维数组
print(n) #输出一维数组
print(n[:3]) #输出第1个元素(0省略)至第4个元素(不包括第4个元素)
print(n[3:6]) #输出第4个元素至第7个元素(不包括第7个元素)
print(n[6:]) #输出第7个元素至最后一个元素
print(n[::]) #输出所有元素
print(n[:]) #输出第1个元素至最后一个元素
print(n[::2]) #输出步长是2的元素
print(n[1::5]) #输出第2个元素至最后一个元素且步长是5的元素
print(n[2::6]) #输出第3个元素至最后一个元素且步长是6的元素
# start、stop、step为负数时
print(n[::-1]) #输出所有元素且步长是-1的元素
print(n[:-3:-1]) #输出倒数第3个元素至倒数第1个元素(不包括倒数第3个元素)
print(n[-3:-5:-1]) #输出倒数第3个元素至倒数第5个元素且步长是-1的元素
print(n[-5::-1]) #输出倒数第5个元素至最后一个元素且步长是-1的元素
3.二维数组索引
二维数组索引可以使用array[n,m]的方式表示,以逗号分隔,表示第n个数组的第m个元素。
创建一个3行4列的二维数组,实现简单的索引操作,程序代码如下:
import numpy as np # 导入numpy模块
# 创建3行4列的二维数组
n=np.array([[0,1,2,3],[4,5,6,7],[8,9,10,11]])
print(n[1]) # 输出第2行的元素
print(n[1,2]) # 输出第2行第3列的元素
print(n[-1]) # 输出倒数第1行的元素
4.二维数组切片式索引
创建一个二维数组,实现各种切片式索引操作,程序代码如下:
import numpy as np
#创建3行3列的二维数组
n=np.array([[1,2,3],[4,5,6],[7,8,9]])
print(n[:2,1:]) #输出第1行至第3行(不包括第3行)的第2列至最后一列的元素
print(n[1,:2]) #输出第2行的第1列至第3列(不包括第3列)的元素
print(n[:2,2]) #输出第1行至第3行(不包括第3行)的第3列的元素
print(n[:,:1]) #输出所有行的第1列至第2列(不包括第2列)的元素
数组重塑
数组重塑实际是更改数组的形状,例如,将原来2行3列的数组重塑为3行4列的数组。在NumPy中主要使用reshape()方法。
创建一个一维数组,然后通过reshape()方法将其改为2行3列的二维数组,程序代码如下:
import numpy as np
n=np.arange(6) #创建一维数组
print(n)
n1=n.reshape(2,3) #将数组重塑为2行3列的二维数组
print(n1)
运行程序,结果如下:
需要注意的是,数组重塑是基于数组元素不发生改变的情况,重塑后的数组所包含的元素个数必须与原数组的元素个数相同,如果数组元素发生改变,程序就会报错。
将一行古诗(1行20列的数组)转换为4行5列的二维数组形式,效果如图所示。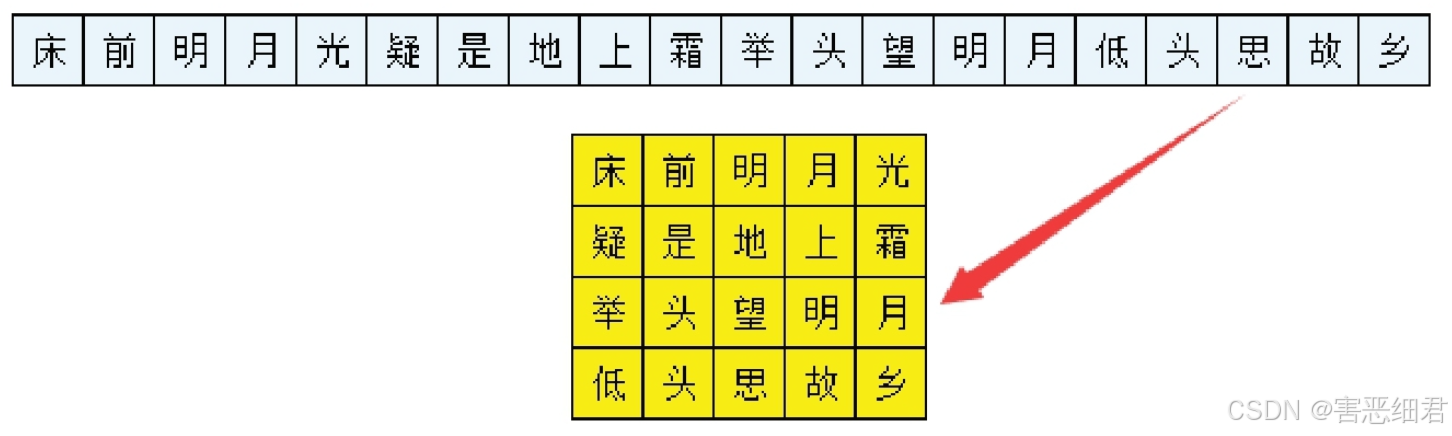
程序代码如下:
import numpy as np # 导入numpy模块
# 创建字符串数组
n=np.array(['床','前','明','月','光','疑','是','地','上','霜','举','头','望','明','月','低','头','思','故','乡'])
n1=n.reshape(4,5) # 将数组重塑为4行5列的二维数组
print(n1)
运行程序,结果如下:
2.多维数组重塑
多维数组重塑同样使用reshape()方法。
将2行3列的二维数组重塑为3行2列的二维数组,程序代码如下:
import numpy as np
n=np.array([[0,1,2],[3,4,5]]) #创建二维数组
print(n)
n1=n.reshape(3,2) #将数组重塑为3行2列的二维数组
print(n1)
运行程序,结果如下:
3.数组转置
数组转置是指数组的行列转换,可以通过数组的T属性和transpose()函数实现。
通过T属性将4行6列的二维数组中的行变成列,列变成行,程序代码如下:
import numpy as np # 导入numpy模块
n = np.arange(24).reshape(4,6) # 创建4行6列的二维数组
print(n)
print(n.T) # T属性行列转置
运行程序,结果如下: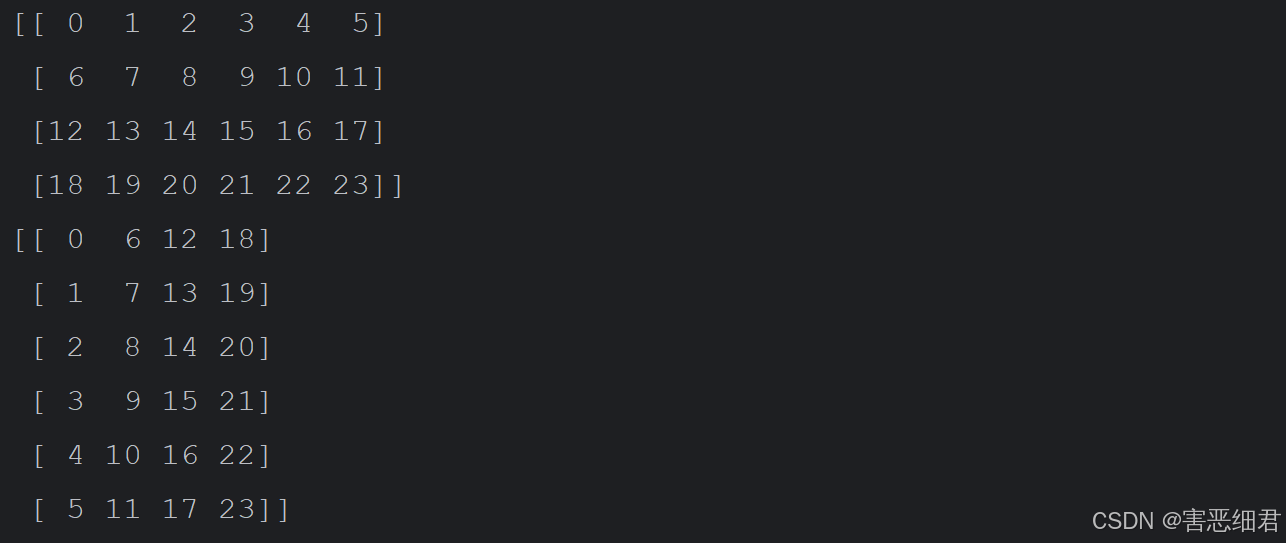
上述示例可能不太直观,下面再举一个例子,转换客户销售数据,对比效果如图: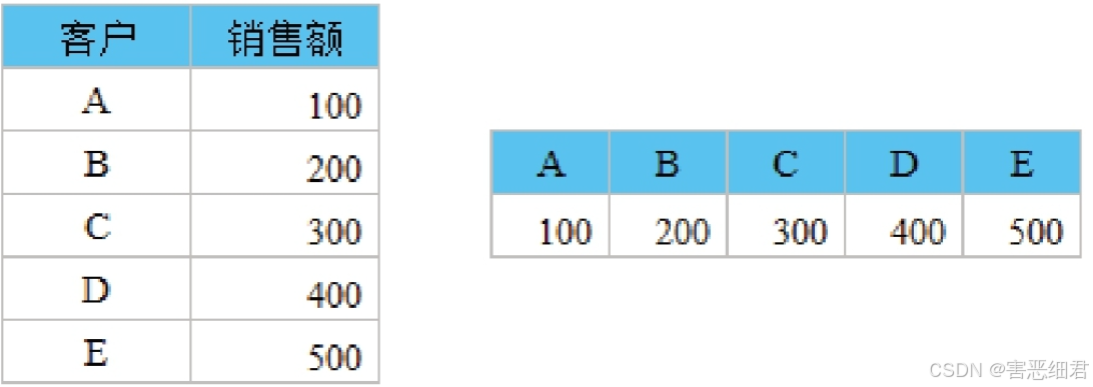
transpose()函数也可以实现数组转置,程序代码如下:
import numpy as np
n = np.array([['A', 100], ['B', 200], ['C', 300], ['D', 400], ['E', 500]])
print(n)
print(n.transpose()) #transpose()函数行列转置
运行程序,结果如下: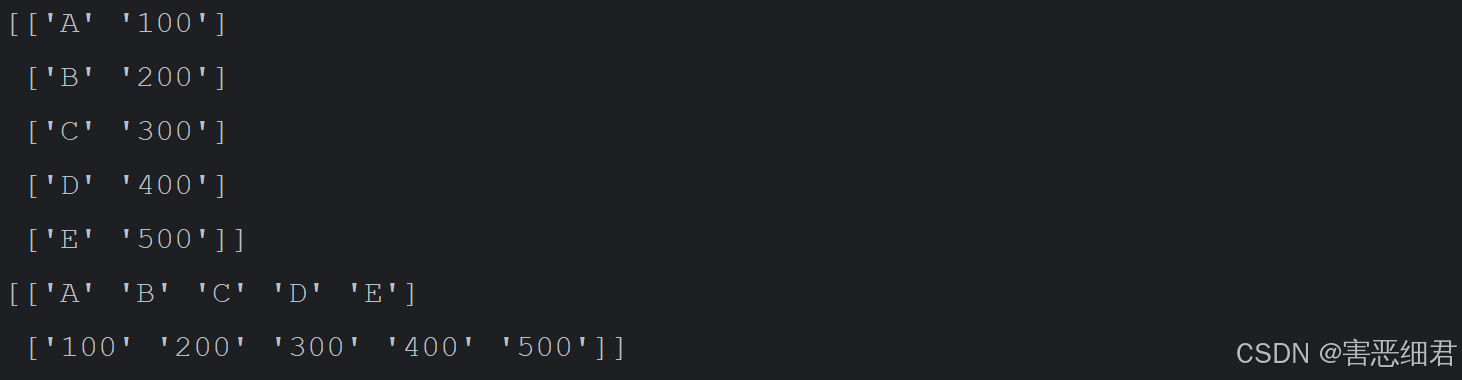
数组的增、删、改、查
数组增、删、改、查的方法有很多,下面介绍几种常用的方法。
1.数组的增加
数组数据的增加可以按照水平方向增加也可以按照垂直方向增加。水平方向增加数据主要使用hstack()函数,垂直方向增加数据主要使用vstack()函数。
创建两个二维数组,实现数组数据的增加,程序代码如下:
import numpy as np
# 创建二维数组
n1=np.array([[1,2],[3,4],[5,6]])
n2=np.array([[10,20],[30,40],[50,60]])
print(np.hstack((n1,n2))) # 水平方向增加数据
print(np.vstack((n1,n2))) # 垂直方向增加数据
运行程序,输出结果如下:
2.数组的删除
数组数据的删除主要使用delete()方法。
通过以下程序删除指定的数组数据,程序代码如下:
import numpy as np # 导入numpy模块
n1=np.array([[1,2],[3,4],[5,6]])# 创建二维数组
print(n1)
n2=np.delete(n1,obj=2,axis=0) # 删除第3行
n3=np.delete(n1,obj=0,axis=1) # 删除第1列
n4=np.delete(n1,obj=(1,2),axis=0) # 删除第2行和第3行
print('删除第3行后的数组:','\n',n2)
print('删除第1列后的数组:','\n',n3)
print('删除第2行和第3行后的数组:','\n',n4)
运行程序,输出结果如下: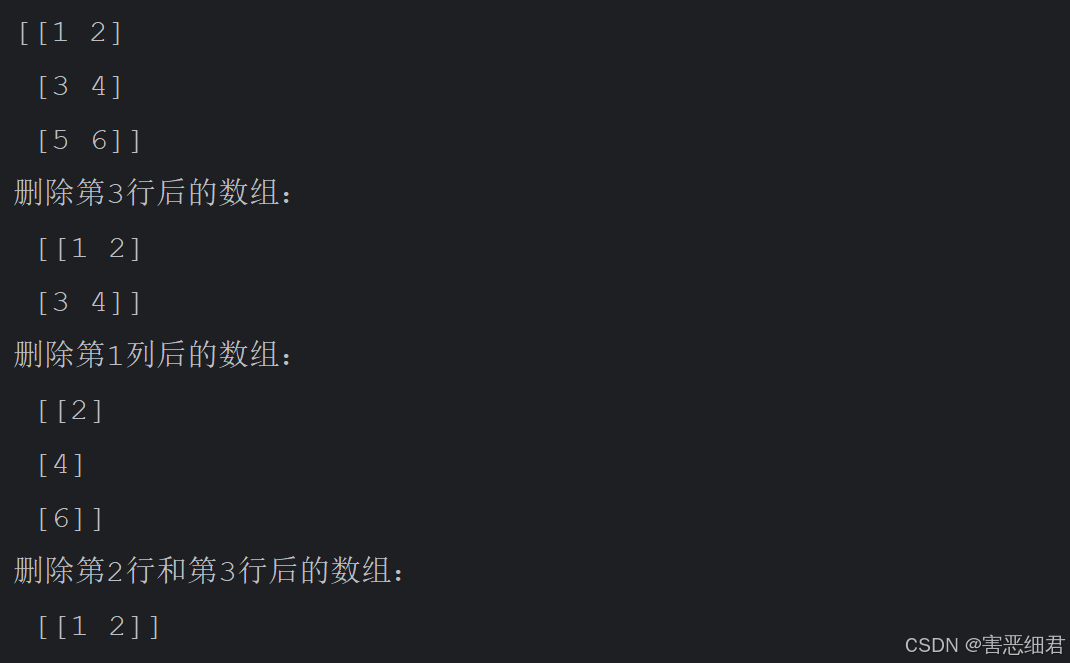
对于删除数组或数组元素的操作,还可以通过索引和切片方法只选取保留的数组或数组元素。
3.数组的修改
修改数组或数组元素时,直接为数组或数组元素赋值即可。
通过以下程序修改指定的数组元素,程序代码如下:
import numpy as np
n1=np.array([[1,2],[3,4],[5,6]]) # 创建二维数组
print(n1)
n1[1]=[30,40] # 修改第2行数组[3,4]为[30,40]
n1[2][1]=88 # 修改第3行第3个元素6为88
print('修改后的数组:','\n',n1)
运行程序,输出结果如下:
4.数组的查询
数组的查询同样可以使用索引和切片方法来获取指定范围的数组或数组元素,还可以通过where()函数查询符合条件的数组或数组元素。where()函数语法格式如:
numpy.where(condition,x,y)
第一个参数为一个布尔数组,第二个参数和第三个参数可以是标量也可以是数组。若满足条件(参数condition),则输出参数x,否则输出参数y。
下面实现数组查询,数组元素大于5则输出2,不大于5则输出0。如果不指定参数x和y,则输出满足条件的数组元素的坐标。程序代码如下:
import numpy as np
n1 = np.arange(10) #创建一个一维数组
print(n1)
print(np.where(n1>5,2,0)) #大于5输出1,不大于5输出0
n2=n1[np.where(n1>5)]
print(n2)
运行程序,结果如下:
3. NumPy矩阵基本操作
在数学中经常会用到矩阵,而在程序中常用的是数组,可以简单理解为,矩阵是数学中的概念,而数组是计算机程序设计领域的概念。在NumPy中,矩阵是数组的分支,数组和矩阵有些时候是通用的,二维数组也称矩阵。下面简单介绍矩阵的基本操作。
创建矩阵
NumPy函数库中存在两种不同的数据类型(矩阵matrix和数组array),它们都可以用于处理用行列表示的数组元素,虽然它们看起来很相似,但是在这两种数据类型上执行相同的数学运算可能得到不同的结果。
在NumPy中,矩阵应用十分广泛。例如,每个图像都可以被看作像素值矩阵。假设像素值仅为0和1,那么5×5像素的图像就是一个5×5的矩阵,如图所示。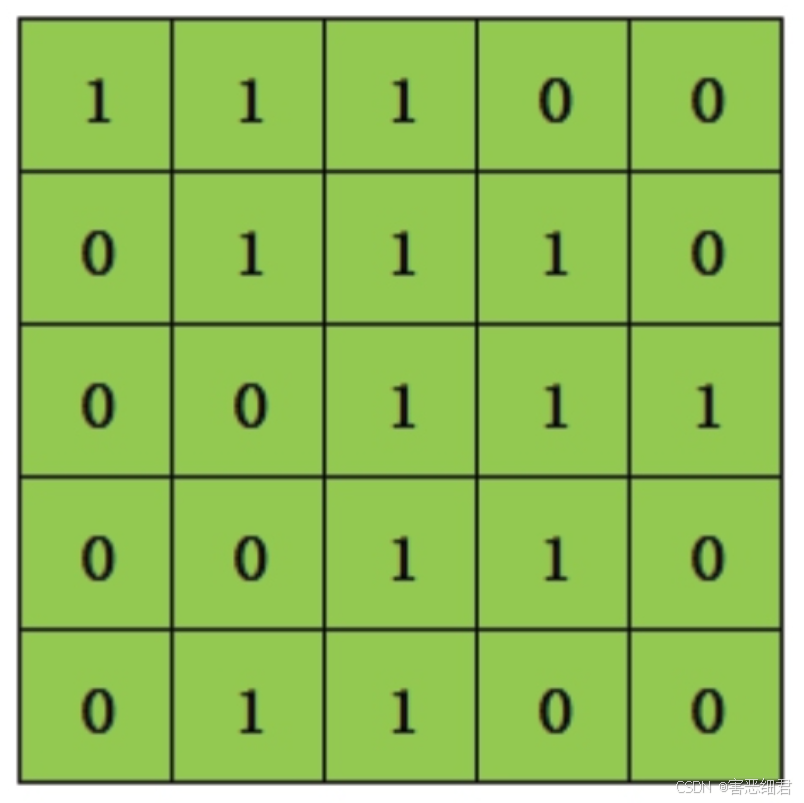
下面使用asmatrix()函数创建矩阵,程序代码如下:
import numpy as np # 导入numpy模块
a = np.asmatrix('5 6;7 8') # 创建矩阵
b = np.asmatrix('1 2; 3 4')
print(a)
print(b)
print(type(a)) # 判断类型
print(type(b))
n1 = np.array([[1, 2], [3, 4]]) # 创建数组
print(n1)
print(type(n1)) # 判断类型
运行程序,结果如下: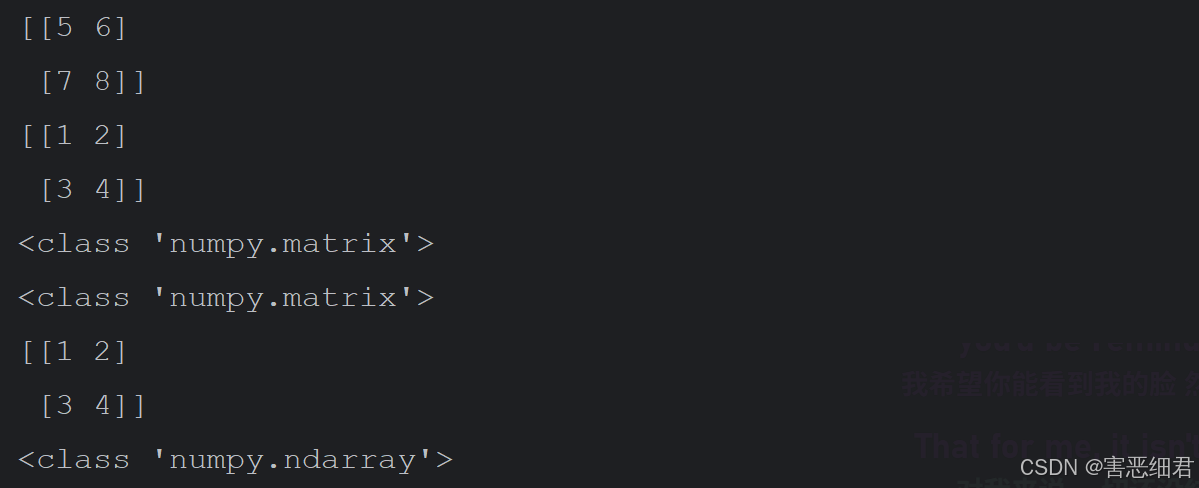
从运行结果得知:asmatrix()函数创建的是矩阵,array()函数创建的是数组,用asmatrix()函数创建的矩阵才能进行线性代数操作。
下面使用asmatrix()函数创建常见的矩阵。
(1) 创建一个3×3的零(0)矩阵,程序代码如下:
import numpy as np
# 创建一个3*3的零矩阵
data1 = np.asmatrix(np.zeros((3, 3)))
print('3*3的零矩阵:')
print(data1)
运行程序,结果如下:
(2)创建一个2×4的以1填充的矩阵,程序代码如下:
import numpy as np
# 创建一个2*4的1矩阵
data1 = np.asmatrix(np.ones((2, 4)))
print('2*4的1矩阵:')
print(data1)
运行程序,结果如下:
(3)使用random模块的rand()函数创建一个3×3的在0至1之间随机产生的二维数组,并将其转换为矩阵,程序代码如下:
import numpy as np
# 使用rand()函数创建一个3*3在0~1之间随机产生的二维数组
data1 = np.asmatrix(np.random.rand(3, 3))
print('3*3在0~1之间随机产生的二维数组:')
print(data1)
运行程序,结果如下:
(4)创建一个1 至8 之间的随机整数矩阵,程序代码如下:
import numpy as np
# 创建一个1~8之间的随机整数矩阵
data1 = np.asmatrix(np.random.randint(1, 8, size=(3, 5)))
print('1~8之间的随机整数矩阵:')
print(data1)
运行程序,结果如下:
(5)创建对角矩阵,程序代码如下:
import numpy as np
# 创建对角矩阵
print('对角矩阵:')
data1 = np.asmatrix(np.eye(N=2, M=2, dtype=int)) # 2*2对角矩阵
print(data1)
data1 = np.asmatrix(np.eye(N=4, M=4, dtype=int)) # 4*4对角矩阵
print(data1)
运行程序,结果如下:
(6)创建指定对角线元素的对角矩阵,程序代码如下:
import numpy as np
# 创建对角线矩阵
print('对角线矩阵:')
a = [1, 2, 3]
data1 = np.asmatrix(np.diag(a)) # 对角线1、2、3矩阵
print(data1)
b = [4, 5, 6]
data1 = np.asmatrix(np.diag(b)) # 对角线4、5、6矩阵
print(data1)
运行程序,结果如下:
说明:asmatrix()函数只适用于创建二维矩阵,维数超过2,asmatrix()就不适用了。从这一点来看,array()函数更具通用性。
矩阵运算
如果两个矩阵大小相同,我们可以使用算术运算符+、-、*和/对矩阵进行加、减、乘、除运算。
创建两个矩阵data1和data2,实现矩阵的加法运算,效果如图所示。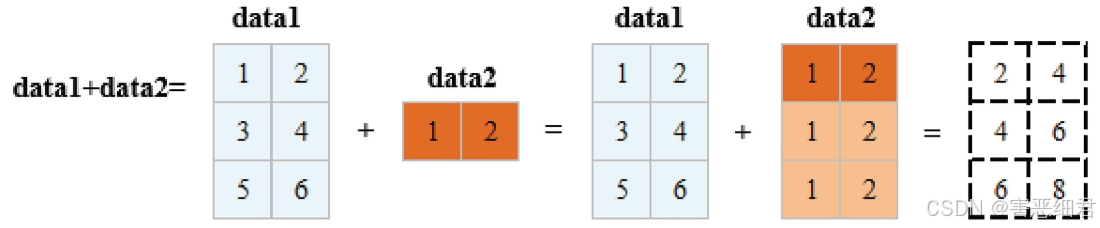
程序代码如下:
import numpy as np # 导入numpy模块
data1= np.asmatrix(('1 2; 3 4; 5 6'))# 创建矩阵
data2=np.asmatrix([1,2])
print(data1+data2) # 矩阵加法运算
运行程序,结果如下:
除了加法运算,还可以实现矩阵的减法、乘法和除法运算。接下来先实现上述矩阵的减法和除法运算,程序代码如下:
import numpy as np # 导入numpy模块
data1= np.asmatrix(('1 2; 3 4; 5 6'))# 创建矩阵
data2=np.asmatrix([1,2])
print(data1-data2) # 矩阵减法法运算
print(data1/data2) # 矩阵除法运算
print(data1*data2) # 报错
当我们对上述矩阵进行乘法运算时,程序出现了错误,原因是矩阵的乘法运算要求左边矩阵的列数和右边矩阵的行数要一致。由于上述矩阵data2只有一行,所以导致程序出错。
将矩阵data2改为2×2的矩阵,再进行矩阵的乘法运算,程序代码如下:
import numpy as np # 导入numpy模块
data1= np.asmatrix(('1 2; 3 4; 5 6'))# 创建矩阵
data2= np.asmatrix(('1 2; 3 4'))
print(data1*data2) # 矩阵乘法运算
运行程序,结果如下:
上述示例是两个矩阵直接相乘,称为矩阵相乘。矩阵相乘的运算过程如下图所示。例如,1×1+2×3=7,是第一个矩阵第1行元素与第二个矩阵第1列元素两两相乘并求和得到的。
数组运算和矩阵运算的一个关键区别是矩阵相乘使用的是点乘。点乘也称点积,是数组中元素对应位置一一相乘之后求和的操作,在NumPy中专门提供了点乘方法,即dot()方法。
数组相乘与数组点乘运算的比较,程序代码如下:
import numpy as np # 导入numpy模块
n1 = np.array([1, 2, 3]) # 创建数组
n2= np.array([[1, 2, 3], [1, 2, 3], [1, 2, 3]])
print('数组相乘结果为:','\n', n1*n2) # 数组相乘
print('数组点乘结果为:','\n', np.dot(n1, n2)) # 数组点乘
运行程序,结果如下:
要实现矩阵对应元素之间相乘可以使用multiply()函数,程序代码如下:
import numpy as np # 导入numpy模块
n1 = np.asmatrix('1 3 3;4 5 6;7 12 9') # # 创建矩阵,使用分号隔开数据
n2 = np.asmatrix('2 6 6;8 10 12;14 24 18')
print('矩阵相乘结果为:\n',n1*n2) # 矩阵相乘
print('矩阵对应元素相乘结果为:\n',np.multiply(n1,n2))
运行程序,结果如下:
矩阵转换
1.矩阵转置
矩阵转置与数组转置一样使用T属性,程序代码如下:
import numpy as np # 导入numpy模块
n1 = np.asmatrix('1 3 3;4 5 6;7 12 9') # 创建矩阵,使用分号隔开数据
print(n1.T) # 矩阵转置
运行程序,结果如下:
2.矩阵求逆
矩阵应该可逆,否则意味着该矩阵为奇异矩阵(即矩阵的行列式的值为0)。求逆矩阵主要使用I属性,程序代码如下:
import numpy as np # 导入numpy模块
n1 = np.asmatrix('1 3 3;4 5 6;7 12 9') # 创建矩阵,使用分号隔开数据
print(n1.I) # 逆矩阵
运行程序,结果如下:
4. NumPy常用统计分析函数
数学运算函数
NumPy中包含大量的数学运算函数,如三角函数、算术运算函数、复数处理函数等,如下表所示。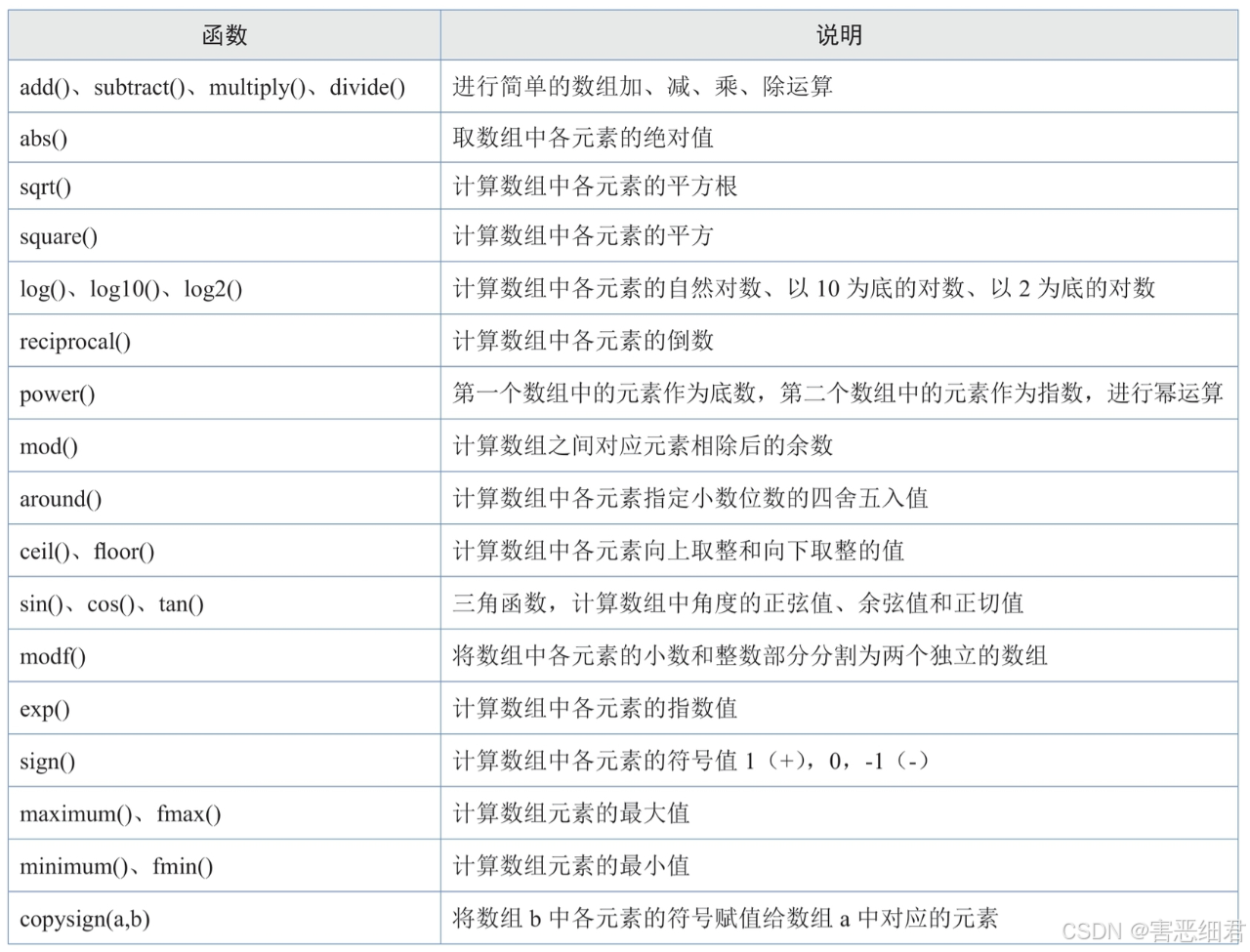
1.算术运算函数
(1)加、减、乘、除
NumPy算术运算函数可实现简单的加、减、乘、除运算,如add()函数、subtract()函数、multiply()函数和divide()函数。这里要注意的是,数组必须具有相同的形状或符合数组广播规则。
数组加、减、乘、除运算的程序代码如下:
import numpy as np # 导入numpy模块
n1 = np.array([[1,2,3],[4,5,6],[7,8,9]]) # 创建数组
n2 = np.array([10, 10, 10])
print('两个数组相加:')
print(np.add(n1, n2))
print('两个数组相减:')
print(np.subtract(n1, n2))
print('两个数组相乘:')
print(np.multiply(n1, n2))
print('两个数组相除:')
print(np.divide(n1, n2))
运行程序,结果如下: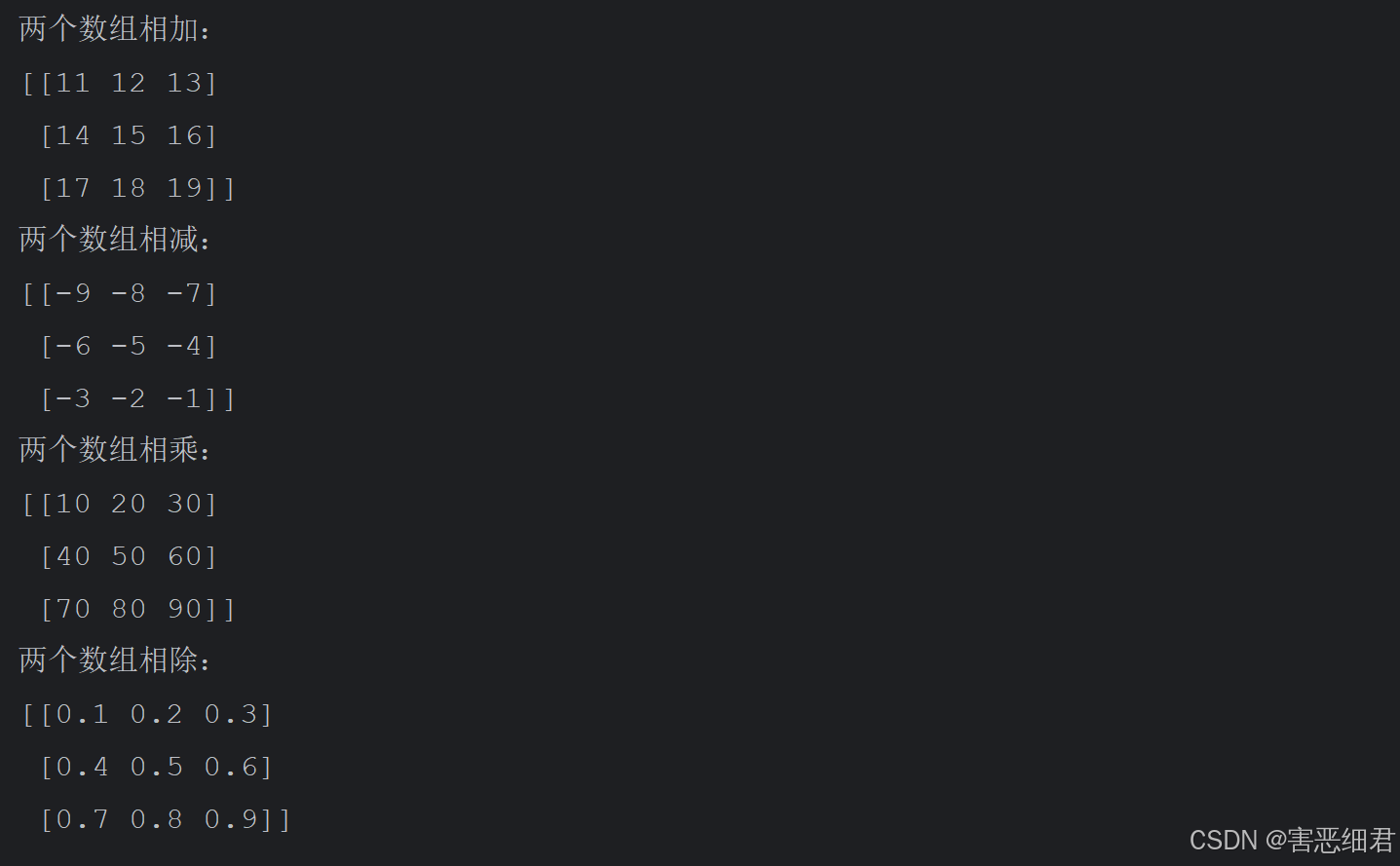
(2)计算倒数reciprocal()函数用于返回数组中各元素的倒数,如4/3的倒数是3/4。
计算数组元素的倒数,程序代码如下:
import numpy as np
a = np.array([0.25, 1.75, 2, 100])
print(np.reciprocal(a))
(3)求幂power()函数将第一个数组中的元素作为底数,将第二个数组中相应的元素作为指数,进行幂运算。
import numpy as np
n1 = np.array([10, 100, 1000])
print(np.power(n1, 3))
n2= np.array([1, 2, 3])
print(np.power(n1, n2))
运行程序,结果如下:
统计分析函数
统计分析函数是对整个NumPy数组或某个轴上的数据进行统计运算的,函数介绍如下表所示。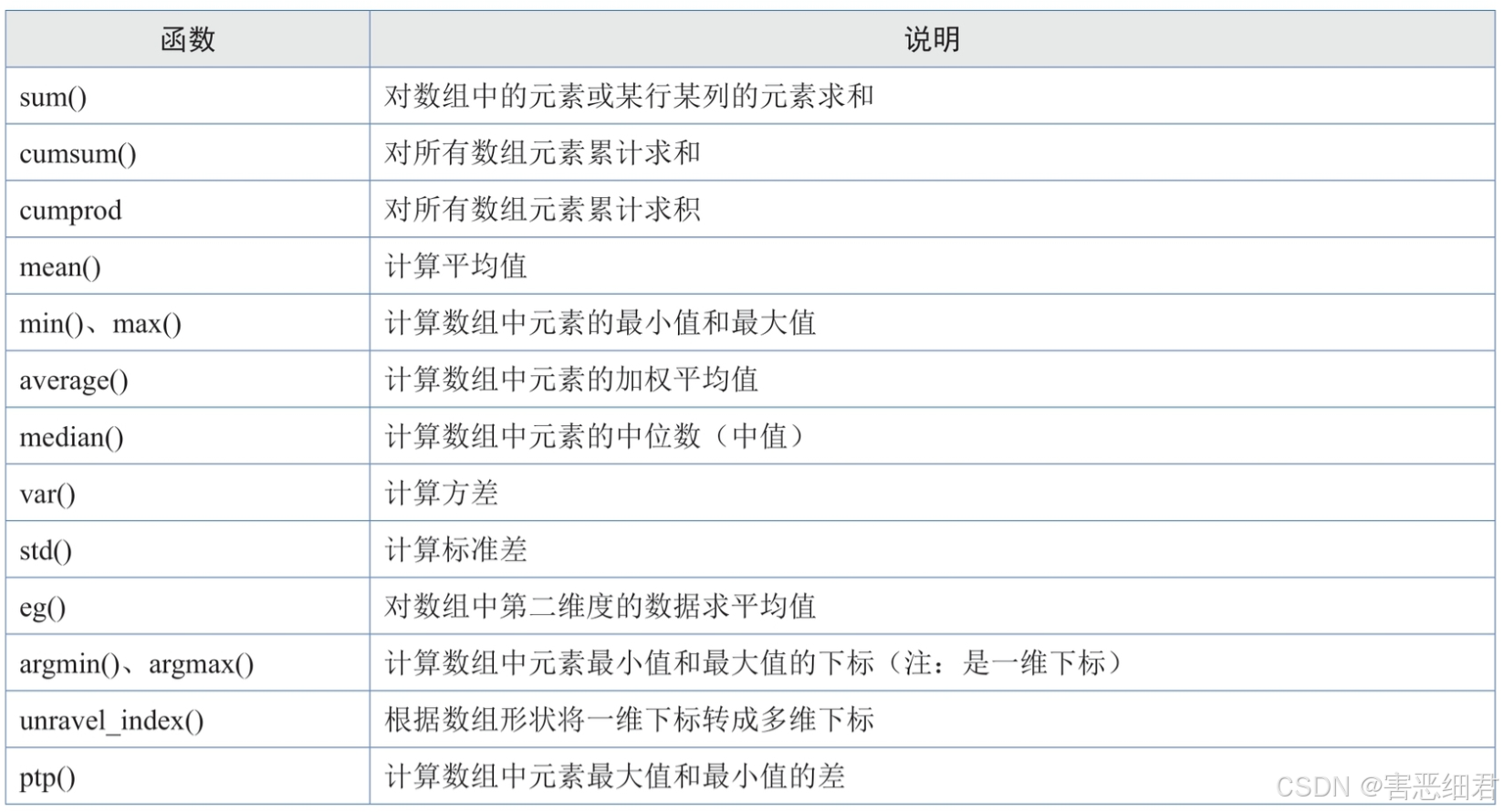
分别对数组元素求和,对数组元素按行和按列求和,程序代码如下:
import numpy as np
n=np.array([[1,2,3],[4,5,6],[7,8,9]])
print('对数组元素求和:')
print(n.sum())
print('对数组元素按行求和:')
print(n.sum(axis=0))
print('对数组元素按列求和:')
print(n.sum(axis=1))
运行程序,结果如下:
五. 数据统计分析案例
本章以案例为主,通过简单的知识讲解,了解数据统计分析中常用的分析方法,如对比分析,同比、定比和环比分析,贡献度分析,差异化分析,相关性分析,时间序列分析。通过典型案例,将数据统计分析方法与前面学习的内容相结合,力求将所学内容应用到实践中。
1. 对比分析
对比分析是指将两个或两个以上的数据进行比较,分析其中的差异,从而揭示事物发展的变化情况和规律。
特点:能非常直观地看出事物在某方面的变化或差距,而且可以准确地量化表示。
对比分析通常是对两个相互联系的指标数据进行比较的,从数量上展示和说明研究对象规模的大小,水平的高低,速度的快慢,以及各种关系是否协调。对比分析一般来说有以下几种方法:纵向对比、横向对比、标准对比、实际与计划对比。
案例:对比分析各品牌销量表现TOP10
对比各国产品牌汽车1月份销量并展示前10名,效果如图所示。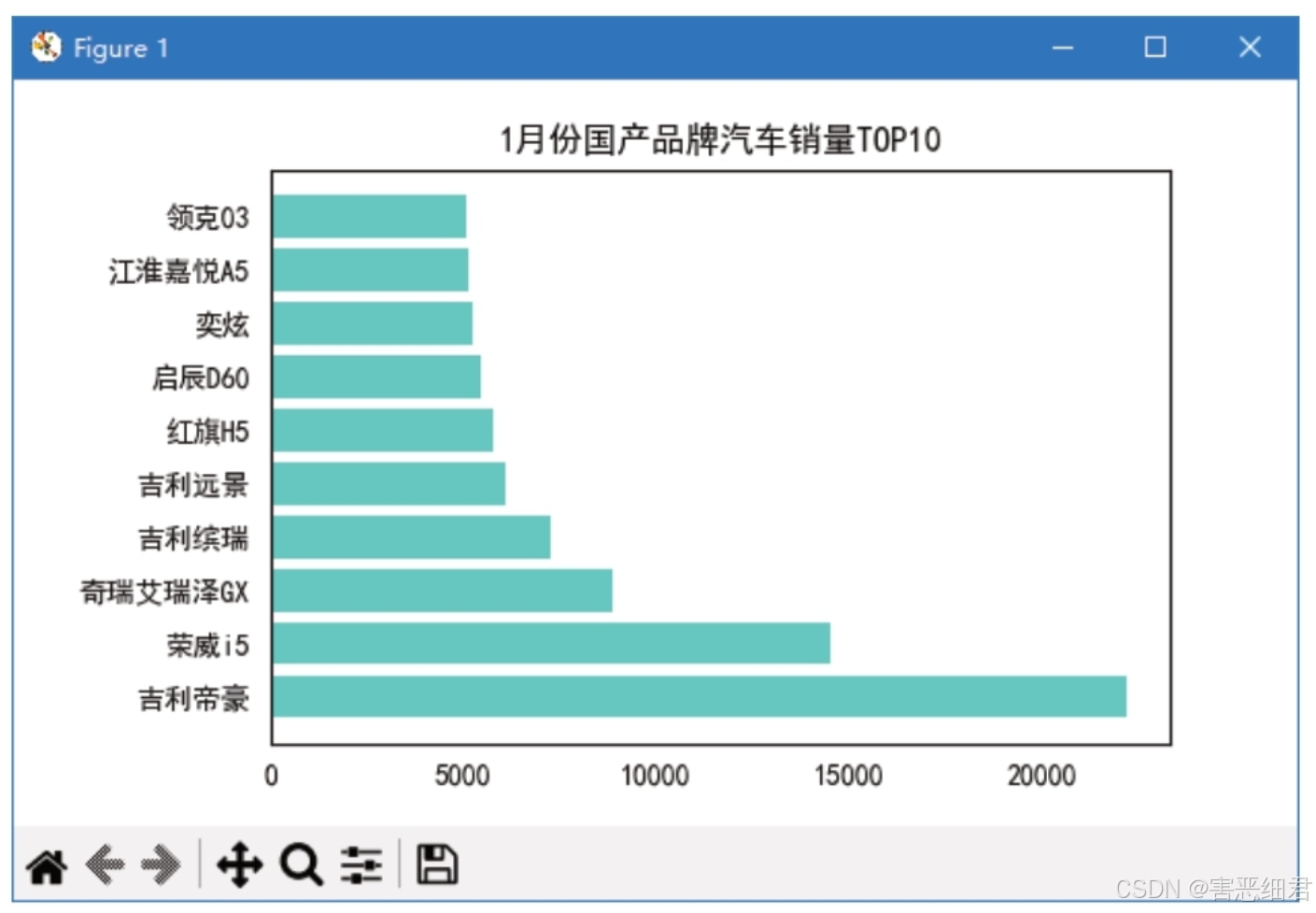
程序代码如下:
# 导入相关模块
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel('./data/car.xlsx') # 读取Excel文件
df1=df.head(10) # 抽取Top数据
plt.rcParams['font.sans-serif']=['SimHei'] # 解决中文乱码
x=df1['车型'];y=df1['1月销量'] # x、y轴数据
plt.subplots_adjust(left=0.2) # 调整图表距左的空白
# 4个方向的坐标轴上的刻度线是否显示
plt.tick_params(bottom=False,left=False)
plt.yticks(range(10)) # y轴刻度
plt.title('1月份国产品牌汽车销量TOP10') # 图表标题
plt.barh(x, y,color='Turquoise') # 柱子蓝绿色
plt.show() # 显示图表
2. 同比、定比和环比分析
同比、定比和环比概述
同比:本期数据与上年同期数据比较。例如,2020年2月数据与2019年2月数据相比较。
定比:本期数据与特定时期的数据(固定期数据)比较。例如,2020年2月数据与2019年12月数据相比较。
环比:本期数据与上期数据比较。例如,2020年2月数据与2020年1月数据相比较。
举一个生活中经常出现的例子来说明。
同比:去年这个这时候我还能穿这条裙子,现在穿不进去啦!定比:与18岁相比,我如今的年龄已经翻倍。环比:我这个月好像比上个月胖了。
同比的好处是可以排除一部分季节因素。环比的好处是可以更直观地表明阶段性的变化,但是会受季节因素的影响。定比则常用于财务数据分析
下面简单介绍一下同比、定比和环比的计算公式。
同比
定比
环比
环比增长率反映本期比上期增长了多少,公式如下:
环比发展速度是本期数据与上期数据之比,反映前后两期的发展变化情况,公式如下:
案例:京东电商单品销量同比增长情况分析
下面分析2024年2月与2023年2月相比,京东电商《零基础学Python》一书在全国各地区的销量同比增长情况,效果如下图所示。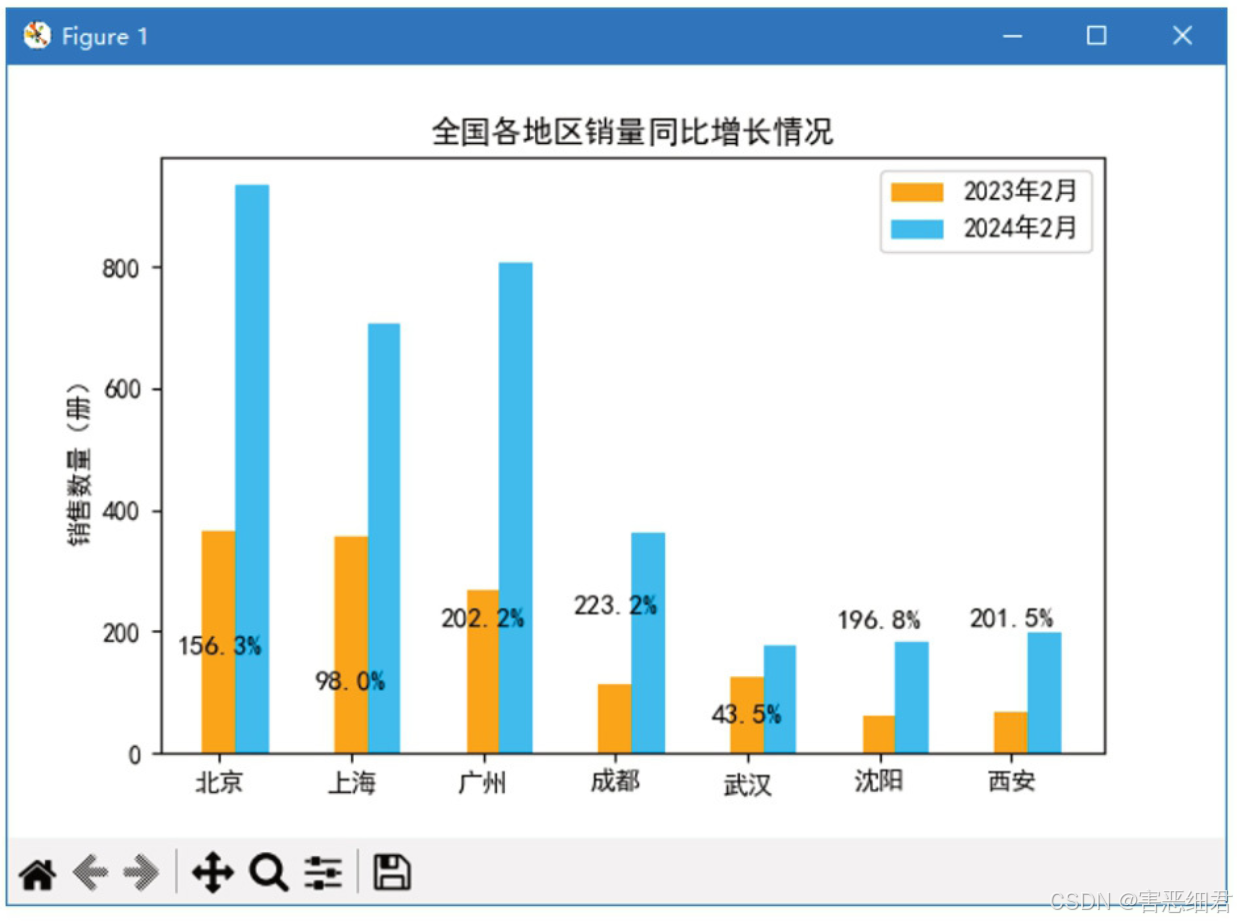
从运行结果得知:上海、武汉地区的销量同比增长率较低。
程序代码如下:
# 导入相关模块
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
df=pd.read_excel('./data/JD2024.xlsx') # 读取Excel文件
df= df.set_index('日期') # 将日期设置为索引
df1=pd.concat([df.loc['2023-02-01'],df.loc['2024-02-01']]) # 抽取数据并合并
df1=df1[df1['商品名称']=='零基础学Python(全彩版)'] # 筛选数据
df1=df1[['北京','上海','广州','成都','武汉','沈阳','西安']]# 抽取数据
df2=df1.T # 行列转置
# x、y轴数据
x=np.array([0,1,2,3,4,5,6])
y1=df2['2023-02-01']
y2=df2['2024-02-01']
# 同比增长率
df2['rate']=((df2['2024-02-01']-df2['2023-02-01'])/df2['2023-02-01'])*100
y=df2['rate']
print(y) # 输出增长率
width =0.25 # 柱子宽度
plt.rcParams['font.sans-serif']=['SimHei'] # 解决中文乱码
plt.title('全国各地区销量及同比增长情况') # 图表标题
plt.ylabel('销售数量(册)') # y轴标签
# x轴刻度及标签
plt.xticks(x,labels=['北京','上海','广州','成都','武汉','沈阳','西安'])
# 双柱形图
plt.bar(x,y1,width=width,color = 'orange',label='2023年2月')
plt.bar(x+width,y2,width=width,color = 'deepskyblue',label='2024年2月')
# 增长率标签
for a, b in zip(x,y):
plt.text(a,b,('%.1f%%' % b), ha='center', va='bottom', fontsize=11)
plt.legend() # 图例
plt.show() # 显示图表
案例:单品销量定比分析
下面实现京东电商《零基础学Python》一书2023年全国销量定比分析,以2023年1月为基期,基点为1,效果如图所示。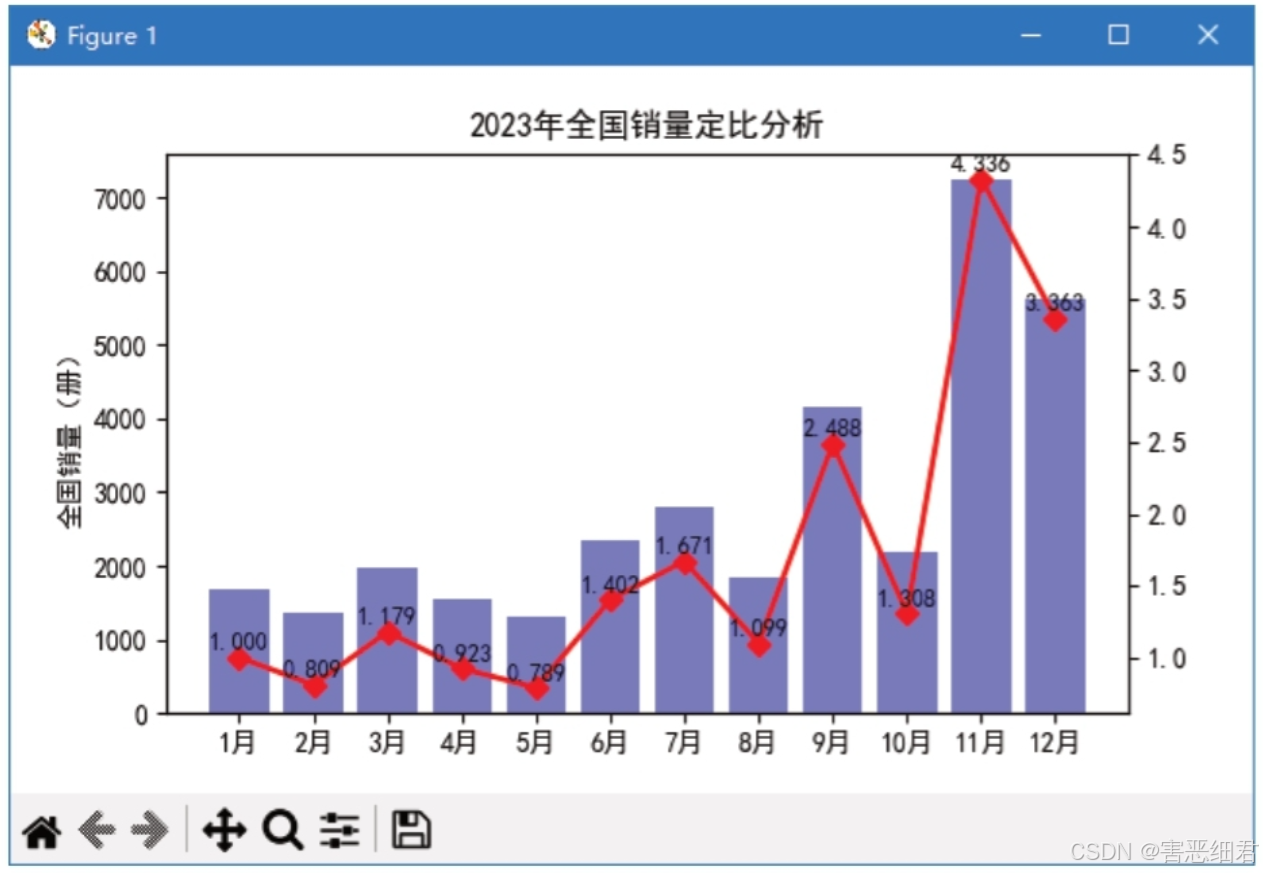
程序代码如下:
# 导入相关模块
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel('./data/JD2024.xlsx') # 读取Excel文件
# 数据筛选并排序
df1=df[df['商品名称']=='零基础学Python(全彩版)'].sort_values('日期')
df1=df1[['北京','上海','广州','成都','武汉','沈阳','西安','日期']] # 数据抽取
df1= df1.set_index('日期') # 将日期设置为索引
df1['全国销量']=df1.sum(axis=1) # 求和运算
df1=df1.loc['2023-01-01':'2023-12-01'] # 抽取2023年数据
# 定比分析(以2023年1月为基期,基点为1)
df1['January']=df1.iloc[0,7]
df1['base']=df1['全国销量']/df1['January']
# x、y轴数据
x=[0,1,2,3,4,5,6,7,8,9,10,11]
y1=df1['全国销量']
y2=df1['base']
fig = plt.figure() # 创建空画布
plt.rcParams['font.sans-serif']=['SimHei'] # 解决中文乱码
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
ax1 = fig.add_subplot(111) # 添加子图
plt.title('2023年全国销量定比分析') # 图表标题
# x轴刻度及标签
plt.xticks(x,labels=['1月','2月','3月','4月','5月','6月','7月','8月','9月','10月','11月','12月'])
ax1.bar(x,y1,color = 'blue',label='left',alpha=0.5) # 柱形图
ax1.set_ylabel('全国销量(册)') # y轴标签
ax2 = ax1.twinx() # 添加一条y轴坐标轴
ax2.plot(x,y2,color='r',linestyle='-',marker='D',linewidth=2)# 折线图
# 添加文本标签
for a,b in zip(x,y2):
plt.text(a, b+0.02, '%.3f' %b, ha='center', va= 'bottom',fontsize=9)
plt.show() # 显示图表
案例:单品销量环比增长情况分析
下面分析京东电商《零基础学Python》一书2023年全国销量环比增长情况,效果如图所示。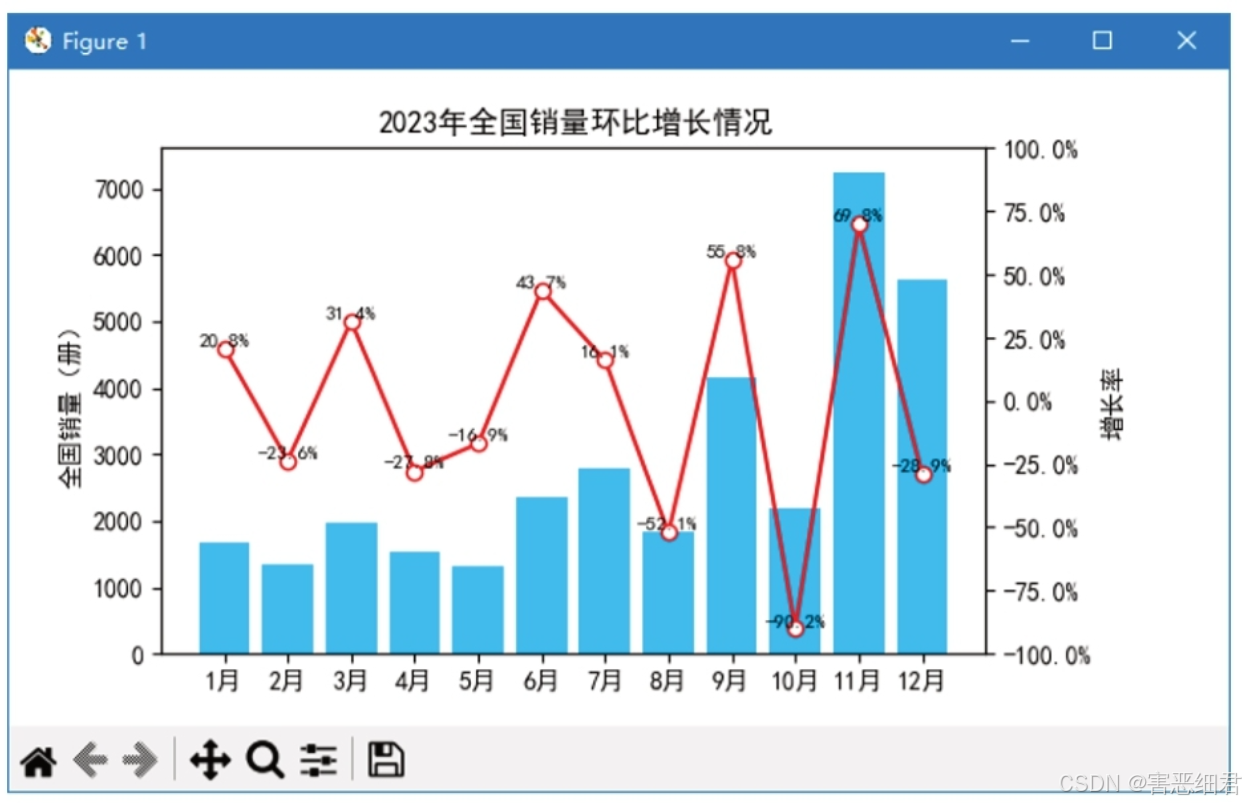
程序代码如下:
# 导入相关模块
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
df=pd.read_excel('./data/JD2024.xlsx') # 读取Excel文件
df1=df[df['商品名称']=='零基础学Python(全彩版)'].sort_values('日期')# 数据筛选并排序
df1=df1[['北京','上海','广州','成都','武汉','沈阳','西安','日期']] # 数据抽取
df1= df1.set_index('日期') # 将日期设置为索引
df1['全国销量']=df1.sum(axis=1) # 求和运算
# 环比增长率
df1['rate']=((df1['全国销量']-df1['全国销量'].shift())/df1['全国销量'])*100
df1=df1['2023-01-01':'2023-12-01'] # 抽取2023年数据
df1.to_excel('aa.xlsx') # 导出Excel文件
# x、y轴数据
x=[0,1,2,3,4,5,6,7,8,9,10,11]
y1=df1['全国销量']
y2=df1['rate']
fig = plt.figure() # 创建空画布
plt.rcParams['font.sans-serif']=['SimHei'] # 解决中文乱码
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
ax1 = fig.add_subplot(111) # 添加子图
plt.title('2023年全国销量及环比增长情况') # 图表标题
# x轴刻度及标签
plt.xticks(x,labels=['1月','2月','3月','4月','5月','6月','7月','8月','9月','10月','11月','12月'])
ax1.bar(x,y1,color = 'deepskyblue',label='left') # 柱形图
ax1.set_ylabel('全国销量(册)') # y轴标签
ax2 = ax1.twinx() # 添加一条y轴坐标轴
ax2.plot(x,y2,color='r',linestyle='-',marker='o',mfc='w',label=u"增长率") # 折线图
# 设置右侧y轴的格式、范围和标签
fmt = '%.1f%%'
yticks = mtick.FormatStrFormatter(fmt)
ax2.yaxis.set_major_formatter(yticks)
ax2.set_ylim(-100,100)
ax2.set_ylabel(u"增长率")
# 添加文本标签
for a,b in zip(x,y2):
plt.text(a, b+0.02, '%.1f%%' % b, ha='center', va= 'bottom',fontsize=8)
plt.subplots_adjust(right=0.8) # 调整图表距右的空白
plt.show() # 显示图表
3. 贡献度分析
贡献度分析又称80/20法则、二八法则、帕累托法则、帕累托定律、最省力法则或不平衡原则。
该法则是由意大利经济学家帕累托提出的。80/20法则认为:原因和结果、投入和产出、努力和报酬之间本来存在着无法解释的不平衡关系。例如,一个公司80%的利润常常来自于20%的产品,使用贡献度分析就可以知道获利最高的20%的产品是什么。
真正的比例不一定正好是80%:20%。80/20法则表明在多数情况下两个指标间的关系很可能是不平衡的,并且数据接近80%:20%。
案例:产品贡献度分析
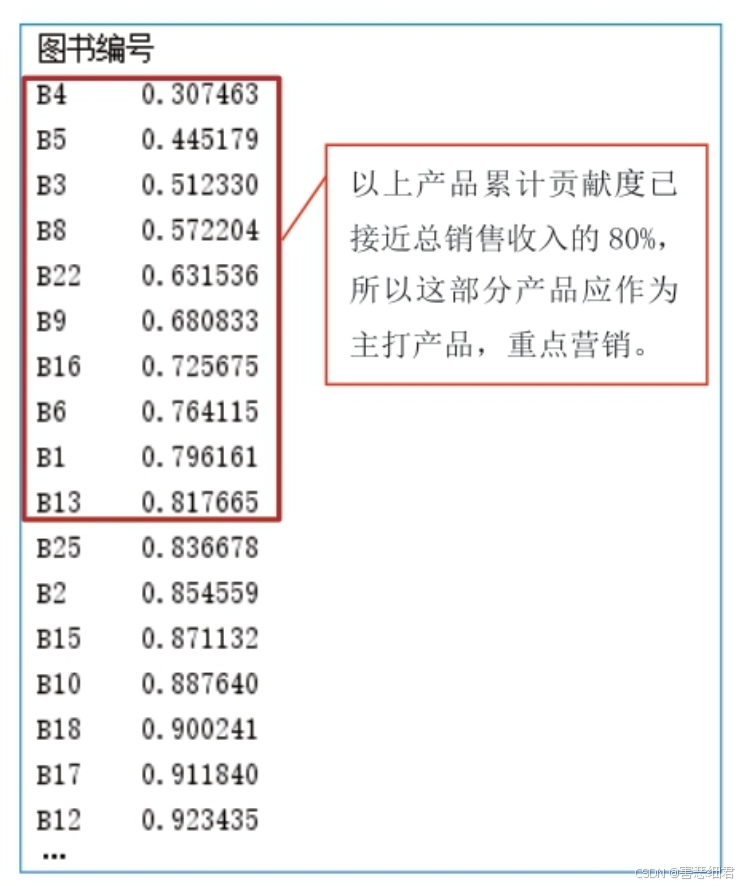
下面分析淘宝电商全彩系列图书上半年销售收入占比80%的产品。首先,计算产品累计贡献度,结果如下图所示。从图中可以看出,到图书编号B13时,累计贡献度就已达到了0.817665(接近总销售收入的80%),其中共有10个产品,接下来在图表中进行标注,如图所示。
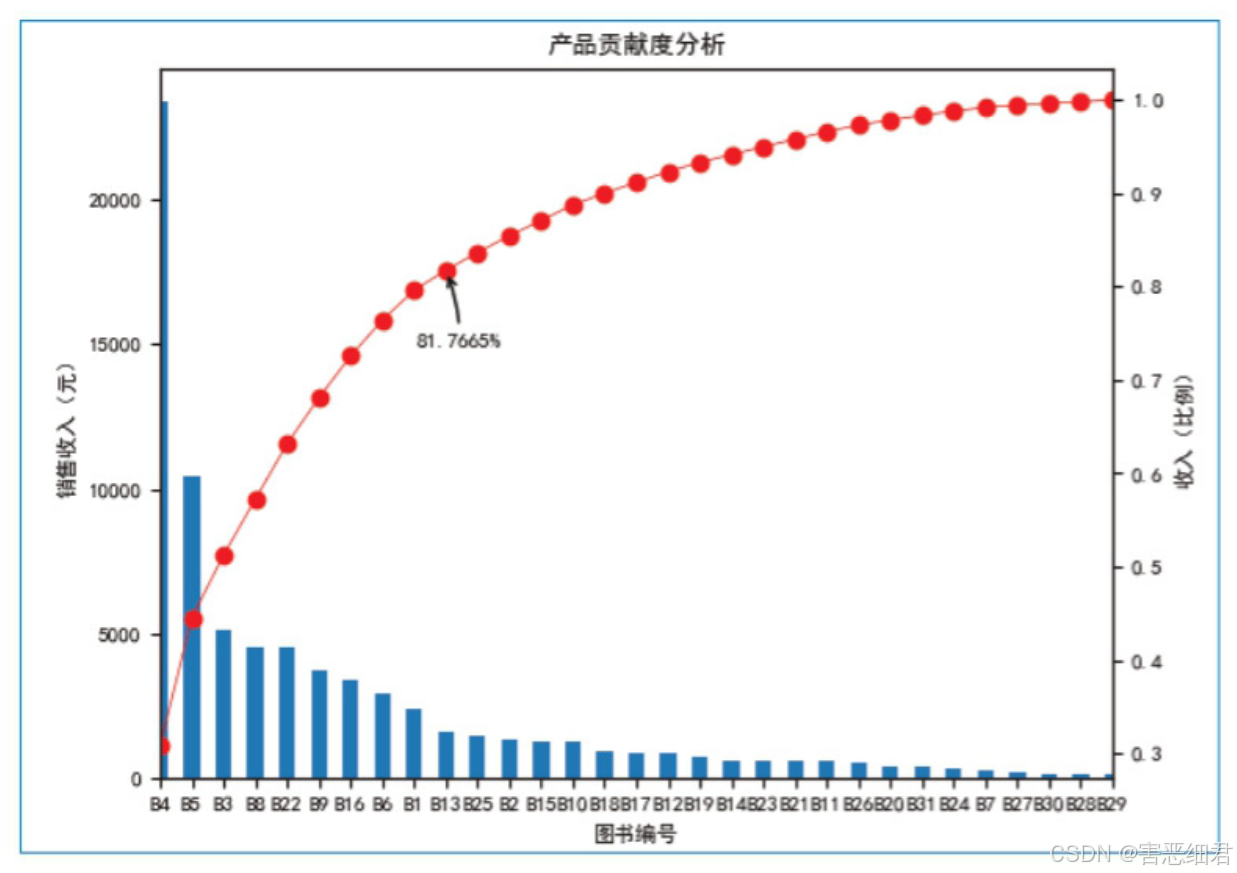
程序代码如下:
# 导入相关模块
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel('./data/data11.xlsx') # 读取Excel文件
# 分组统计排序
# 通过reset_index()函数将groupby()的分组结果重新设置索引
df1 = df.groupby(["图书编号"])["买家实际支付金额"].sum().reset_index()
df1 = df1.set_index('图书编号') # 设置索引
df1 = df1[u'买家实际支付金额'].copy() # 拷贝副本
df2=df1.sort_values(ascending=False) # 降序排序
print(df2) # 输出数据
# 图表字体黑体,字号为8
#plt.rc('font', family='SimHei', size=8)
plt.rcParams['font.sans-serif']=['SimHei'] # 解决中文乱码
df2.plot(kind='bar') # 柱形图
plt.ylabel(u'销售收入(元)') # y轴标签
p = 1.0*df2.cumsum()/df2.sum() # 计算累计贡献率
print(p)
p.plot(color='r', secondary_y=True, style='-o', linewidth=0.5) # 累计贡献率曲线图
plt.title("产品贡献度分析") # 图表标题
plt.annotate(format(p.iloc[9], '.4%'), xy=(9, p.iloc[9]), xytext=(9 * 0.9, p.iloc[9] * 0.9),
arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.1")) # 添加标记,并指定箭头样式
plt.ylabel(u'收入(比例)') # 右侧y轴标签
plt.show() # 显示图表
4. 差异化分析
通过差异化分析,可以比较不同事物之间在某个指标上存在的差异,并根据差异定制不同的策略。对于产品而言,差异化分析是指企业在其提供给顾客的产品上,通过各种方法满足顾客的偏好,使顾客能够把自己的产品同其他竞争企业提供的同类产品有效地区别开来,从而使企业在市场竞争中占据有利的地位。
比较常见的有性别差异、年龄差异。通过差异化分析比较不同性别的人之间在某个指标上存在的差异,通过分析结果为不同性别的人定制不同的方案。例如,分析不同性别的同学在学习成绩上的差异,了解男生和女生之间的差异,因材施教,定制不同的弥补弱项的方案。
年龄差异化分析主要了解不同年龄段用户的需求,投其所好,使企业的利润最大化。例如,网购、自媒体、汽车、旅游等行业,通过年龄差异化分析,找出不同年龄段用户的喜好,从而增加产品销量。
案例:学生成绩性别差异化分析
“女孩喜欢毛绒玩具,男孩喜欢车”,这大概是天生的。
科学研究表明,男孩、女孩的差别在相当程度上是由生理基础决定的。通过高科技扫描就可以发现,男孩、女孩的大脑都会有某些部位比对方相应的部位更发达、更忙碌。
随着成长,这种天生的性别差异就会对孩子的学习产生影响,并且不断强化。而反过来,学习本身也在影响着大脑机能的发育。因为当孩子玩耍和学习的时候,相应的脑细胞就会更加活跃且随时更新,而那些不经常使用的部分将会逐渐萎缩。
下面我们用数据说话,通过雷达图分析男生、女生各科成绩的差异,效果如图所示。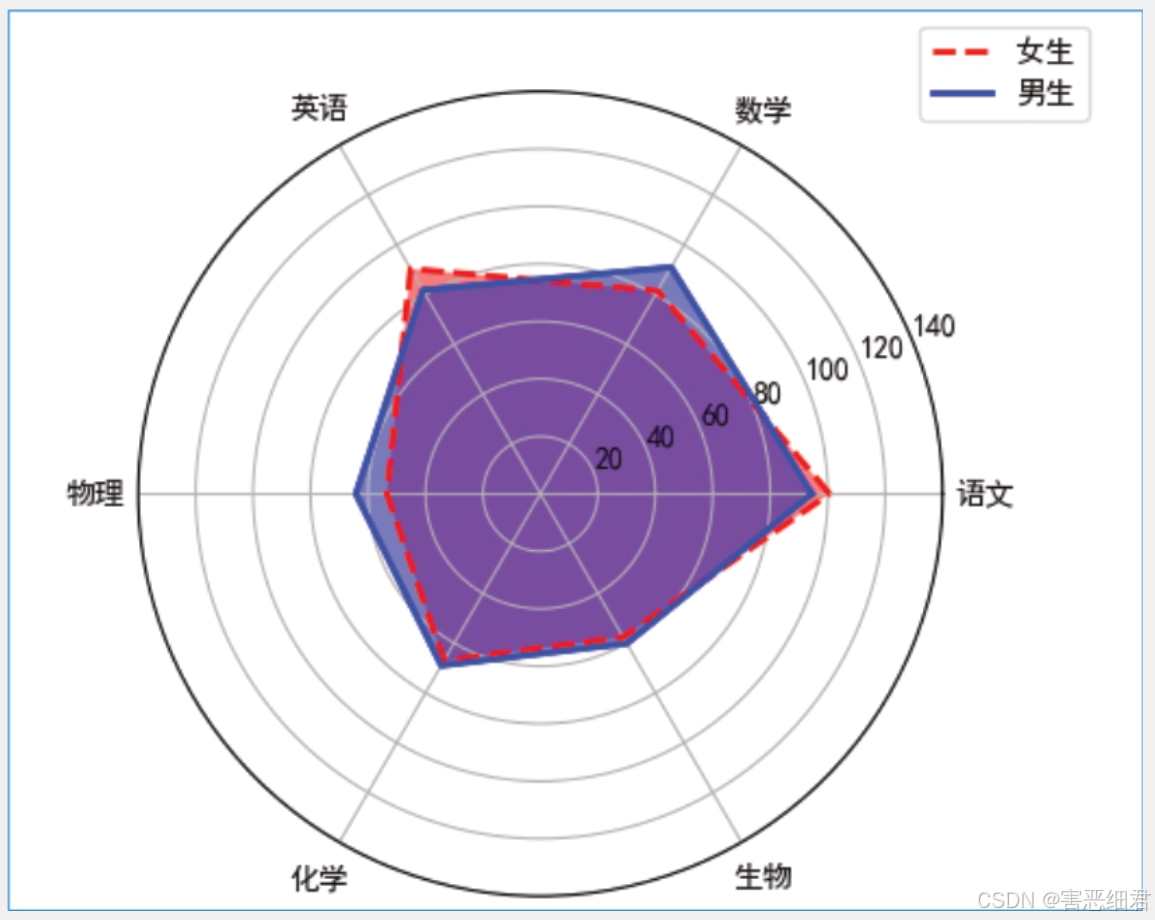
从分析结果得知,男生的数学和物理成绩高于女生,而女生在英语和语文上更占优势。针对性别差异造成学习成绩的差距,应该因材施教,分别提高女生的数学和物理成绩,以及男生的语文和英语成绩。
程序代码如下:
# 导入相关模块
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_excel('./data/成绩表.xlsx') # 读取Excel文件
df=df.iloc[:,1:8] # 抽取数据
df = df.set_index('性别') # 设置性别为索引
plt.rcParams['font.sans-serif']=['SimHei'] # 解决中文乱码
labels = np.array(['语文','数学','英语','物理','化学','生物']) # 标签
dataLenth = 6 # 数据长度
# 计算女生、男生各科平均成绩
df1=df.query('性别==["女"]').mean().round(2)
df2=df.query('性别==["男"]').mean().round(2)
# 设置雷达图的角度,用于平分切开一个平面
angles = np.linspace(0, 2*np.pi, dataLenth, endpoint=False)
plt.polar(angles, df1, 'r--', linewidth=2,label='女生') # 设置极坐标系,r--代表red和虚线
plt.fill(angles, df1,facecolor='r',alpha=0.5) # 填充
plt.polar(angles, df2,'b-', linewidth=2,label='男生') # 设置极坐标系,bo代表blue和实心圆
plt.fill(angles, df2,facecolor='b',alpha=0.5) # 填充
plt.thetagrids(angles * 180/np.pi, labels) # 设置网格、标签
plt.ylim(0,140) # 设置y轴上下限
plt.legend(loc='upper right',bbox_to_anchor=(1.2,1.1)) # 图例及图例位置
plt.show() # 显示图表
5. 相关性分析
任何事物之间都存在一定的联系。例如,夏天温度的高低与空调的销量存在相关性。当温度升高时,空调的销量也会相应提高。
相关性分析是指对多个具备相关关系的数据进行分析,从而衡量数据之间的相关程度或密切程度。相关性分析可以应用到所有的数据分析过程中。如果一组数据的改变会引发另一组数据朝相同方向变化,那么这两组数据存在正相关性。例如,身高与体重,一般个子高的人体重会重一些,个子矮的人体重会轻一些。如果一组数据的改变会引发另一组数据朝相反方向变化,那么这两组数据存在负相关性。例如,运动量与体重。
案例:广告展现量与费用成本相关性分析
为了促进销售,电商平台必然要投入广告,这样就会产生广告展现量和费用成本相关数据。通常情况下我们认为,投入费用高,广告效果就好,它们之间必然存在联系,但仅通过主观判断没有说服力,无法证明数据之间真实存在关系,也无法度量它们之间相关性的强弱。因此我们要通过相关性分析来找出数据之间的关系。
相关性分析方法有很多,简单的相关性分析方法是将数据进行可视化处理,因为单纯从数据的角度很难发现数据之间的变化趋势和联系,而将数据绘制成图表后就可以直观地看出数据之间的变化趋势和联系。
下面通过散点图看一下广告展现量与费用成本的相关性,效果如图所示。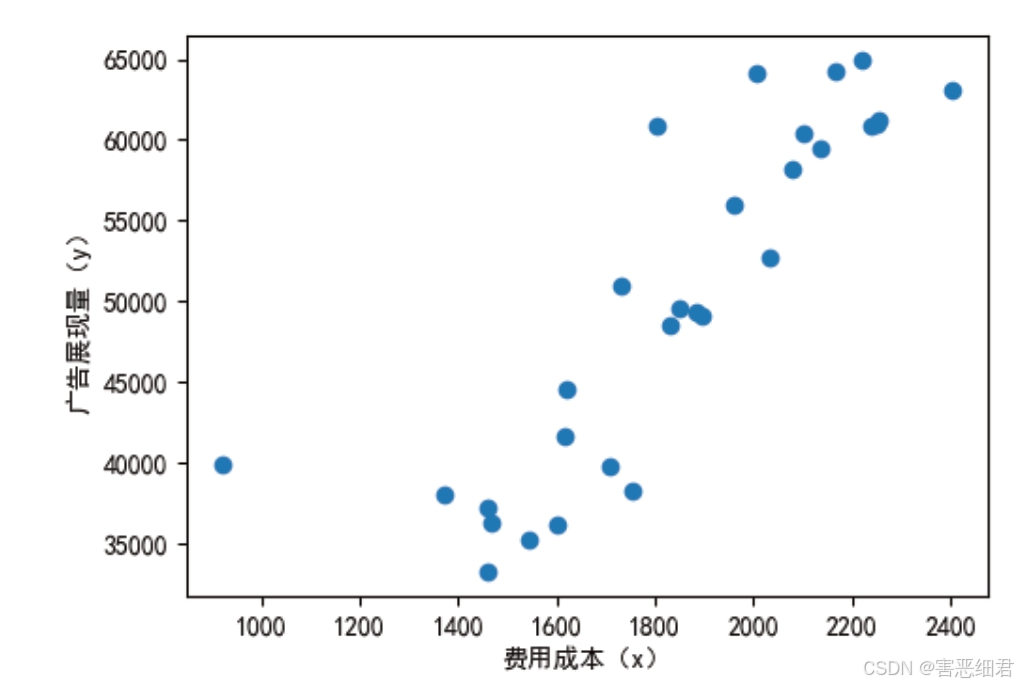
首先对数据进行简单处理,由于“费用.xlsx”表中同一天会产生多个类型的费用,所以需要按天统计费用,然后将“展现量.xlsx”和“费用.xlsx”两个表中的数据合并,最后绘制散点图,程序代码如下:
import pandas as pd
import matplotlib.pyplot as plt
# 解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
# 设置数据显示的列数和宽度
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
df_y = pd.read_excel('./data/展现量.xlsx')
df_x = pd.read_excel('./data/费用.xlsx')
df_x = df_x.set_index('日期') # 将日期设置为索引
df_y = df_y.set_index('日期') # 将日期设置为索引
df_x.index = pd.to_datetime(df_x.index) # 将数据的索引转换为datetime类型
df_x = df_x.resample('D').sum() # 按天统计费用
data = pd.merge(df_x, df_y, on='日期') # 数据合并
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码
plt.xlabel('费用成本(x)')
plt.ylabel('广告展现量(y)')
plt.scatter(data['费用'], data['展现量']) # 绘制散点图,以“费用”和“展现量”作为横纵坐标
plt.show() # 显示图表
# 相关系数
print(data.corr())
虽然图表清晰地展示了广告展现量与费用成本的相关性,但无法判断数据之间有什么关系,相关性也没有被准确地度量,并且数据超过两组时也无法完成对各组数据的相关性分析。
下面再介绍一种方法,相关系数方法。相关系数是反映数据之间关系密切程度的统计指标,相关系数的取值区间在1到-1之间。1表示数据之间完全正相关(线性相关),-1表示数据之间完全负相关,0表示数据之间不相关。越接近0表示数据相关性越弱,越接近1表示数据相关性越强。
计算相关系数需要参考计算公式,而在Python中无须使用烦琐的公式,通过DataFrame对象提供的corr()函数就可以轻松实现。
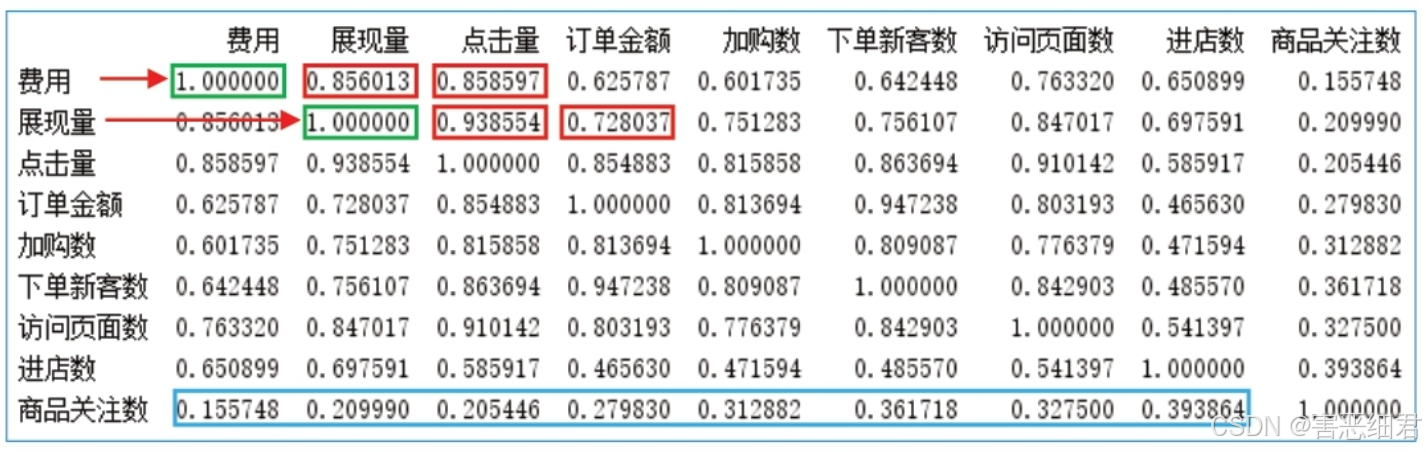
从输出结果得知:“费用”与“费用”自身的相关系数是1,与“展现量”“点击量”的相关系数是0.856013、0.858597;“展现量”与“展现量”自身的相关系数是1,与“点击量”“订单金额”的相关系数是0.938554、0.728037。可以看出“费用”与“展现量”“点击量”等有一定的正相关性,而且相关性很强。
相关系数的优点是可以通过数据对变量间的关系进行度量,并且带有方向性,缺点是无法利用这种关系对数据进行预测。


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)