kubernetes(k8s)速通学习笔记
目录
Controller(StatefulSet)部署有状态应用
Controller(Job和CronJob)部署有状态应用
k8s概念和架构
k8s概述:
容器编排系统
k8s是谷歌在2014年开源的容器化集群管理系统,用于管理云平台中多个主机上的容器化应用。
k8s提供了容器化应用部署,规划,更新,维护的一种机制。
k8s目标是让部署容器化应用更加简洁和高效。
k8s特性:
自动装箱:Kubernetes 允许你指定每个容器所需 CPU 和内存(RAM)。 当容器指定了资源请求时,Kubernetes 可以做出更好的决策来管理容器的资源。
自我修复:Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的 运行状况检查的容器,并且在准备好服务之前不将其通告给客户端。
服务发现/负载均衡:Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器,如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
自动部署和版本回退:你可以使用 Kubernetes 描述已部署容器的所需状态,它可以以受控的速率将实际状态 更改为期望状态。
密码和配置管理:Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
存储编排:Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。
k8s集群架构组件:
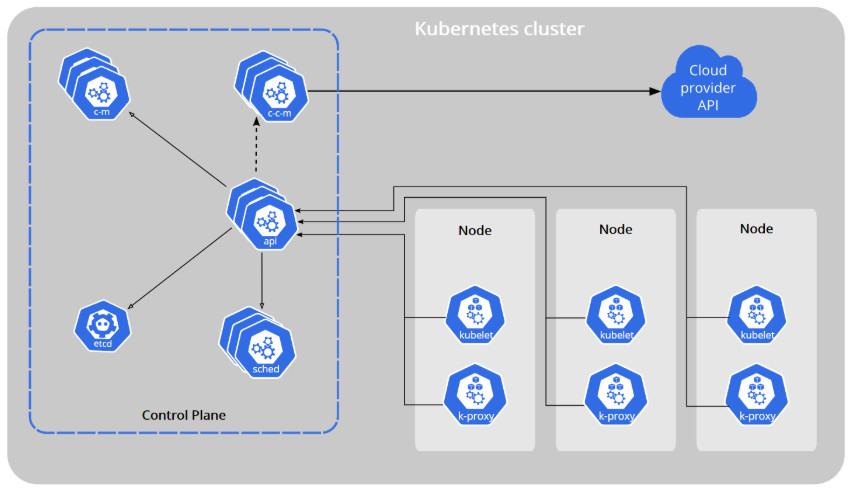
| Master Node (主节点) |
kube-apiserver | 集群的统一入口,以restful方式,交给etcd存储 |
| kube-scheduler | 节点调度,选择worker node节点部署应用 | |
| kube-controller-manager | 处理集群中常规后台任务,一个资源对应一个控制器 | |
| etcd | 存储系统,用于保存集群相关的数据 | |
| Worker Node (工作节点) |
kubelet | 管理当前节点的容器的各种操作(容器的生命周期、创建等) |
| kube-proxy | 提供网络代理,负载均衡等操作 | |
| docker |
容器 |
k8s工作方式:
Kubernetes Cluster = N Master Node + N Worker Node:N主节点+N工作节点; N>=1
k8s核心概念:
pod:最小部署单元(一组容器的集合)
一个pod中的容器共享网络
生命周期是短暂的(服务器重启,重新部署之后,pod就变了)
controller:确保预期的pod副本数量
无状态应用部署
有状态应用部署
确保所有的node运行在同一个pod
一次性任务和定时任务
service:定义一组pod的访问规则
k8s搭建集群方式:
(1)kubeadm方式 k8s部署工具 kubeadm init和kubeadm join 用于快速部署集群
(2)二进制包方式 从github下载发行版的二进制包,手动部署每个组件,组成k8s集群
k8s集群搭建(一主二从)
kubeadm方式:
1、安装3台虚拟机,安装Linux操作系统
2、对3个安装之后的linux系统进行初始化操作
#关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
#关闭selinux
sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config #永久关闭
setenforce 0 #临时关闭
#关闭swap
swapoff -a #临时关闭
sed -i 's/.*swap.*/#&/' /etc/fstab #永久关闭
#根据规划设置主机名
hostnamectl set-hostname <hostname> #分别设置3个节点的hostname
#在master节点添加hosts
cat >>/etc/hosts/ <<EOF
192.168.31.71 k8s-master
192.168.31.72 k8s-node1
192.168.31.73 k8s-noode2
EOF
#将桥接的IPv4流量传递到iptables的链
cat >>/etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system #生效
#时间同步
yum install ntpdate -y
ntpdate time.windows.com
3、在3个节点分别安装docker kubelet kubeadm kubectl
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
exclude=kubelet kubeadm kubectl
EOF
sudo yum install -y kubelet-1.20.9 kubeadm-1.20.9 kubectl-1.20.9 --disableexcludes=kubernetes
sudo systemctl enable --now kubelet4、在master节点执行dockeradm init命令进行初始化操作
#所有机器添加master域名映射,以下需要修改为自己的
echo "172.31.0.4 cluster-endpoint" >> /etc/hosts
#主节点初始化
kubeadm init \
--apiserver-advertise-address=172.31.0.4 \
--control-plane-endpoint=cluster-endpoint \
--image-repository registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images \
--kubernetes-version v1.20.9 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=192.168.0.0/16
#所有网络范围不重叠
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join cluster-endpoint:6443 --token hums8f.vyx71prsg74ofce7 \
--discovery-token-ca-cert-hash sha256:a394d059dd51d68bb007a532a037d0a477131480ae95f75840c461e85e2c6ae3 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join cluster-endpoint:6443 --token hums8f.vyx71prsg74ofce7 \
--discovery-token-ca-cert-hash sha256:a394d059dd51d68bb007a532a037d0a477131480ae95f75840c461e85e2c6ae3#查看集群所有节点
kubectl get nodes
#根据配置文件,给集群创建资源
kubectl apply -f xxxx.yaml
#查看集群部署了哪些应用?
docker ps === kubectl get pods -A
# 运行中的应用在docker里面叫容器,在k8s里面叫Pod
kubectl get pods -A5、配置网络插件 kube-flannel.yml
curl https://docs.projectcalico.org/v3.20/manifests/calico.yaml -O
kubectl apply -f calico.yaml6、在工作节点worker node上执行kubeadm join命令,把node节点添加到当前集群里面
kubeadm join cluster-endpoint:6443 --token x5g4uy.wpjjdbgra92s25pp \
--discovery-token-ca-cert-hash sha256:6255797916eaee52bf9dda9429db616fcd828436708345a308f4b917d3457a227、测试kubernetes集群
二进制包方式:
1、安装3台虚拟机,安装Linux操作系统
2、对3个安装之后的linux系统进行初始化操作(与kubeadm方式一样)
3、为etcd和apiserver制作自签证书 cfssl证书(json文件) openssl证书
为apiserver自签证书的方式
(1)添加可信任的ip列表
修改server.json文件,添加ip
执行generate_k8s_cert.sh文件
(2)携带ca证书发送
4、部署etcd集群
本质:把etcd服务交给systemd管理 复制证书 启动 设置开机启动
5、部署master组件:kube-apiserver,kube-controller-manager,kube-scheduler,etcd,docker
6、部署worker node组件:kubelet,kube-proxy,docker,etcd
7、部署集群网络
k8s集群资源创建方式
命令行工具kubectl
命令语法:kubectl [comand] [TYPE] [NAME] [flags]
kubectl [comand] [TYPE] [NAME] [flags]
##
command:指定要对资源执行的操作 create get desrcibe he delete
TYPE:指定资源的类型 大小写敏感
NAME:指定资源的名称 大小写敏感
flags:可选参数 -s或-server 指定地址或端口
##
kubectl get nodes k8snode1
kubectl --help #获取帮助
kubectl get cs #查看健康状态
kubectl get pod,svc #查看当前命名空间下的所有 Pod 和 Service 资源
kubectl logs pod名字 #查看pod运行日志yaml文件说明
yaml文件:资源清单文件 也可以叫资源编排 一种标记标记语言,以数据为中心
yaml文件组成部分:(1)控制器定义 (2)被控制的对象
yaml语法格式:
通过缩进表示层级关系
不能使用Tab进行缩进,只能使用空格
一般开头缩进2个空格
字符后面缩进1个空格 例如:冒号和逗号等后面都需要使用一个空格缩进
使用---表示新的yaml文件开始
使用#表示注释
#一个yaml文件示例
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-dep
name: my-dep
spec:
replicas: 3
selector:
matchLabels:
app: my-dep
template:
metadata:
labels:
app: my-dep
spec:
containers:
- image: nginx
name: nginxyaml文件中常用字段含义:
| apiVersion | api版本 |
| kind | 资源类型 |
| metadata | 资源元数据 |
| spec | 资源规格 |
| replicas | 副本数量 |
| selector | 标签选择器 |
| template | pod模板 |
| metadata | pod元数据 |
| spec | pod规格 |
| containers | 容器配置 |
如何快速编写一个yaml文件
1、使用kubectl create命令生成yaml文件
kubectl create deployment web --image=nginx -o yaml --dry rum>my1.yaml2、使用kubectl get命令导出yaml文件
kubectl get deploy nginx -o=yaml --export>my2.yamlk8s核心技术-Pod
pod基本概念
pod是最小部署单元,包含对各容器(一组容器的集合),每个pod都有一个"根容器"——Pause容器,一个pod中的容器共享网络命名空间,pod是短暂的
pod存在的意义
①创建容器使用docker,一个docker对应一个容器,一个容器有一个进程,一个容器运行一个应用程序
②pod是多进程设计,运行多个应用程序,一个pod可以有多个容器,可以同时运行多个应用程序
③pod的存在为了亲密性应用(多个应用之间进行交互,也可以提供网络之间调用)
pod实现机制
共享网络:通过Pause容器,把其他业务容器加入到Pause容器里,让所有业务容器在同一个命名空间(namespace)中,可以实现网络共享
共享存储:引入数据卷概念volume,使用数据卷进行持久化存储
pod镜像拉取策略
imagePullPolicy:Always
#IfNotPresent:默认值,镜像在宿主机不存在时进行拉取
#Always:每次创建镜像都会进行镜像拉取
#Never:pod永远不会主动拉取镜像pod资源限制
其实是通过docker实现
resources:
requests:
memory: "64Mi"
cpu: "250M"
limits:
memory: "128Mi"
cpu: "500M"pod重启机制
restartPolicy:Never
#Always:默认策略,当容器停止退出后,总是重启容器
#OnFailure:当容器异常退出(退出状态码非0)时,才重启容器
#Never:当容器终止退出,从不重启容器 (批量任务使用次策略)pod健康检查
livenessProbe(存活检查):如果检查失败,将杀死容器,根据pod的restartPolicy来操作
readinessProbe(就绪检查):如果检查失败,k8s会把pod从service endpoints中剔除
Probe三种检查方法:
httpGet:发送http请求,返回200-400状态码为成功
exec:执行shell命令返回状态0为成功
tcpSocket:发起TCP Socket建立成功
pod调度
创建pod的流程:
master节点:
createPod --apiserver --etcd存储
scheduler --apiserver --etcd --调度算法,把pod调度到某个node节点(工作节点)上
node节点:
kubelet --apiserver --读取etcd数据,拿到分配给当前节点的pod--docker创建容器
影响调度的属性:
1、pod资源限制对pod调度产生影响
2、节点选择器(nodeSelector)标签影响pod调度
spec:
nodeSelector:
env-role: dev
#对节点创建标签
kubectl label node node1 env_role=dev3、节点亲和性影响pod调度
nodeAffinity:硬亲和性------约束条件必须满足
软亲和性------尝试满足,不保证
支持常用操作符:In NotIn Exists Gt Lt DoesNotExists
4、污点和污点容忍
nodeSelector和nodeAffinity:pod调度到某些节点上,是pod的属性,调度时实现
污点Taint:节点不做普通分配调度,是节点的属性
应用场景:专用节点
配置特定硬件的节点
基于Taint驱逐
#查看节点污点情况
kubectl describe node [节点名称] | grep Taint污点值:
NoSchedule:一定不被调度
PreferNoSchedule:尽量不被调度
NoExcute:不会调度,并且还会驱逐节点上已有的pod
#为节点添加污点
kubectl taint node [node] key=value:污点值
kubectl taint node k8smaster name=env_role:NoSchedule
#删除污点
kubectl taint node [node]污点容忍tolerations:即使给吴点设置了NoSchedule的污点值,也可能存在被调度到的情况
在pod中添加容忍规则:
tolerations:
- key: "name"
value: "env_role"
effect: "NoExecute"k8s核心技术-Controller
controller概念
在集群上管理和运行容器的对象
pod和controller的关系
pod是通过controller实现应用的运维,比如伸缩,滚动升级等等
pod和controller之间通过label(pod),selector(controller)建立关系
selector:
app: nginx
labels:
app: nginxdeployment应用场景
部署无状态应用 管理pod和ReplicaSet 部署,滚动升级等功能
主要用于web服务,微服务
yaml文件字段说明
使用deployment部署应用,yaml文件中kind: depolyment
#1.导出yaml文件
kubectl create depolyment web --image=nginx --dry-run -o yaml>web.yaml
#2.使用yaml部署应用
kubectl apply -f web.yaml
#3.对外发布(暴露对外端口)
kubectl expose depolyment web --port=80 --type=NodePort --target.port=80 --name=web1 -o yaml>web1.yaml
kubectl apply -f web1.yaml升级回滚和弹性伸缩
#升级
kubectl set image deployment web nginx=nginx:1.15
#查看升级状态
kubectl rollout status depolyment web
#查看历史版本
kubectl rollout history depolyment web
#回滚到上一个版本
kubectl rollout undo depolyment web
#回滚到指定版本
kubectl rollout undo depolyment web --to-version=2
#弹性伸缩
kubectl scale depolyment --replicas=10k8s核心技术-Service
service存在的意义
1、防止pod失联(服务发现)
2、定义一组pod访问策略(负载均衡)
pod和service的关系
根据label和selector标签建立关联,通过service实现pod的负载均衡
常见service类型
ClusterIP:集群内部使用
NodePort:对外访问应用使用 例如nginx
LoadBalancer:对外访问应用使用
Controller(StatefulSet)部署有状态应用
1、有状态和无状态
| 无状态deployment | 有状态StstefulSet |
| 认为pod都是一样的 | 无状态不需要考虑的要求,有状态都需要考虑到 |
| 没有顺序的要求 | 让每个pod独立,保持pod的启动顺序和唯一性 |
| 不用考虑在哪个node运行 | 需要有唯一的网络标识,持久存储 |
| 可以随意进行伸缩和扩展 | 是有顺序的,比如mysql主从 |
2、部署有状态应用
无头service:即ClusterIP:none
部署有状态应用:kind:StatefulSet
查看pod kubectl get pods 不同pod,每个都有唯一名称 例:nginx-statefulset-0
查看创建的无头service kubectl get svc
depolyment和StatefulSet的主要区别:StatefulSet有唯一标识
每个pod有唯一主机名
根据主机名+按照一定规则生成域名
唯一域名格式:主机名称.Service名称.名称空间.svc.cluster.local
nginx-statefulset-0.nginx.defaultsvc.cluster.localController(DaemontSet)部署守护进程
kind:DaemontSet
在每个node节点上运行同一个pod,新加入的node也同样运行在一个pod里面
Controller(Job和CronJob)部署有状态应用
Job 一次性任务 kind:Job
kubectl get jobsCornJob 定时任务 kind:CronJob
kubectl get cronjobs配置管理
Secret
作用:将加密数据存储到etcd里面,让pod容器以挂载volume方式进访问
应用场景:凭证
1、创建secret加密数据
#base64编码加密
echo -n 'admin' | base64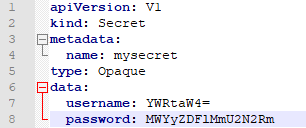
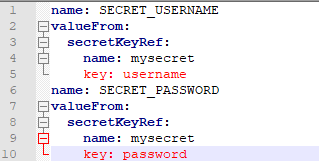
2、以变量形式挂载到pod中
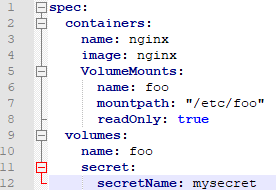
3、以volume形式挂载到pod容器中
ConfigMap
作用:存储不加密数据到etcd,让pod以变量或volume挂载到容器中
应用场景:配置文件
1、创建配置文件redis.properties
#查看configmap
kubectl get cm
kubectl describe cm redis-config2、创建configmap
kubectl create configmap redis-config --from-file=redis.properties3、以volume形式挂载到pod容器中
4、以变量像是挂载到pod容器中
创建yaml,声明变量信息 configmap创建
以变量形式挂载
集群的安全机制
概述
1、访问k8s集群的3个步骤:认证 鉴权(授权) 准入机制
第一步:认证 保证传输安全
传输安全:对外不暴露8080端口,只能内部访问,对外使用端口6443
认证:客户端身份认证方式
https证书认证,基于ca证书
http token认证,通过token识别用户
http基本认证,用户名+密码认证(使用较少)
第二步:鉴权(授权)
基于RBAC进行鉴权操作(RBAC:基于角色的访问控制)
第三步:准入控制
就是准入控制器的列表,如果列表中有请求内容则通过,没有则拒绝
2、进行访问的时候,过程中都需要经过apiserver,apiserver做统一协调。访问过程中需要证书、token,或者用户名+密码,如果访问pod,需要serviceAccount。
RBAC基于角色的访问控制
角色:role:特定命名空间访问权限
ClusterRole:所有命名空间访问权限
角色绑定:roleBinding:角色绑定到主体
ClusterRoleBinding:集群角色绑定到主体
主体:user:用户
group:用户组
serviceAccount:服务账号
RBAC实现鉴权
1、创建命名空间
kubectl create ns roledemo2、在新创建的命名空间创建pod
kubectl run nginx --image=nginx -n roledemo3、创建角色,通过yaml文件创建rbac-role.yaml
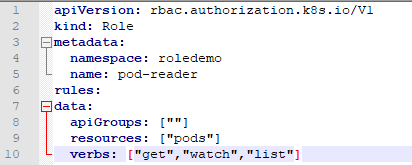
4、创建角色绑定(通过rbac-rolebinding.yaml创建)
5、使用证书识别身份
k8s核心技术-Ingress
1、把端口号对外暴露,通过ip+端口号进行访问(使用Service里面的NodePort实现)
2、NodePort缺陷(在每一个节点都会启动一个端口,在访问时通过任何节点,通过节点ip+暴露端口号都能实现访问)
意味着每个端口号只能访问一次,一个端口对应一个应用
实际访问中都是通过域名访问,根据不同域名跳转到不同端口服务中
3、Ingress和pod的关系
pod和Ingress通过service关联的,Ingress作为统一入口,由service关联一组pod
4、Ingress工作流程
5、使用Ingress
(1)部署Ingress Controller(选择官方维护的nginx控制器实现部署)
(2)创建Ingress规则
6、使用Ingress对外暴露应用
(1)创建nginx应用,对外暴露端口使用NodePort
kubectl create deployment web --image=nginx
kubectl expose deployment web --port=80 --target-port=80 --type=NodePort(2)部署ingress controller
(3)创建ingress规则
(4)在windows系统host文件中添加域名访问规则
k8s核心技术-Helm
引入Helm
之前部署应用的基本过程(编码yaml文件(deployment,service,Ingress)),这种适用于单一,少数服务的应用
使用Helm可以解决哪些问题
(1)使用helm可以把这些yaml文件作为一个整体进行管理
(2)实现yaml文件的高效复用
(3)使用helm应用级别的版本管理
Helm介绍
Helm时k8s中的包管理工具,类似于Linux中的包管理器,如yum/apt等,可以方便的将之前打包好的yaml文件部署到kubernetes上
Helm中的3个重要概念
helm:是一个命令行客户端工具,主要用于Chart创建、打包、发布、管理
Chart:把yaml打包,是yaml集合,一系列用于k8s资源相关文件的集合
Release:基于Chart的部署实体,一个Chart被Helm运行后将会生成一个对应的Release应用级别 的版本管理
Helm V3版本的变化
2019年3月发布Helm V3版本
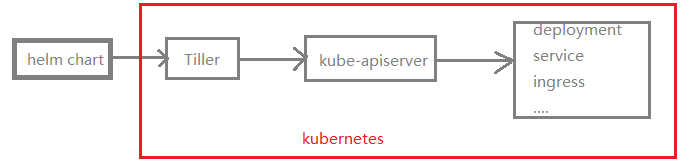
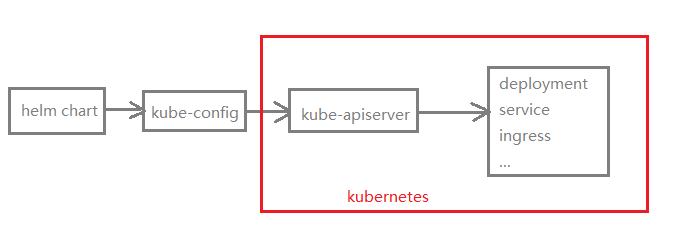
(1)v3版本,删除了Tiller
(2)v3版本,release可以在不同命名空间复用
(3)v3版本,支持将Chart推送到docker仓库中
Helm架构介绍
V3之前版本
V3版本
Helm安装和配置仓库
helm安装
(1)下载helm安装压缩文件,上传到linux系统中,使用tar zxvf命令进行解压
(2)解压helm压缩文件,把解压后的helm目录复制到usr/bin目录下,mv命令
配置helm仓库
(1)添加仓库
helm repo add 仓库名称 仓库地址
#例:helm repo add stable 仓库地址(微软或阿里云等)
helm repo list #查看仓库列表(2)更新
helm repo update(3)删除
helm repo remove stable(仓库名称)Helm快速部署应用
(1)使用命令搜索应用
helm search repo weave #weave是资源名称(2)根据搜索内容选择安装
helm install 安装之后的名称 搜索到的应用名称
#查看安装之后的状态
helm list
helm status 安装之后的名称(3)修改service的yaml文件,type改为NodePort
kubectl get svc #获取service
kubectl edit svc service名称Helm 自定义chart部署
1、使用命令创建chart
helm create chart 名称
#例:helm create mychartChart.yaml:当前chart属性配置信息
templates:编写的yaml文件放到这个目录中
values.yaml:yaml文件可以使用的全局变量
2、在templates文件夹中创建2个yaml文件 deployment.yaml service.yaml
3、安装mychart
helm install web1 mychart4、应用升级
helm upgrade chart名称
helm upgrade web1 mychartHelm chart模板使用
实现高效复用
通过传递参数,动态渲染模板.yaml内容动态传入参数生成
在chart中有values.yaml文件,定义yaml文件全局变量
1、在values.yaml文件中定义变量值
2、在具体yaml文件中,获取定义的变量和值
{{ .Values.变量名称}} {{.Release.Name}}
持久化存储
nfs存储网络
通过数据卷,emptydir本地存储的方式,pod重启后,数据丢失。
而通过nfs网络存储,pod重启后,数据还存在。
1、找一台服务器专门作为nfs服务端,安装nfs,设置挂载路径
(1)安装nfs:
yum install -y nfs-utils(2)挂载路径需要提前创建出来
(3)设置挂载路径
vi /etc/exports
/data/nfs *{rw.no_root_squash}2、在k8s集群的所有node节点上安装nfs
3、在nfs服务器启动nfs服务
systemctl start nfs4、在k8s集群部署应用使用nfs持久网络存储
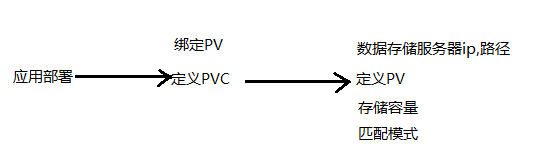
PV和PVC
PV:持久化存储,对存储资源进行抽象,对外提供可以调用的地方(生产者)
PVC:用户调用,不需要关心内部具体实现(消费者)
实现流程:
kubernetes集群资源监控
监控指标
集群监控:节点资源利用率 节点数 运行pods
pod监控:容器指标 应用程序
监控平台搭建
prometheus:
开源的 监控 报警 数据库
以http协议周期性抓取被监控组件状态,不需要复杂的集成过程,使用http接口接入就可以了
Grafana:
开源的数据分析和可视化工具,支持多种数据源
prometheus抓取节点数据进行存储,Grafana读取数据进行分析,通过可视化工具进行展现
搭建步骤:
(1)部署pormetheus
部署守护进程node-exporter.yaml
部署其他yaml文件 rbac-setup.yaml configmap.yaml prometheus-deploy.yaml prometheus-svc.yaml
(2)部署Grafana grafana-deploy.yaml grafana-svc.yaml grafana-ing.yaml
(3)打开Grafana,配置数据源,导入显示模板
通过端口号访问 192.168.44.146:30431/login
默认用户名和密码都是admin
配置数据源,使用prometheus(protheus对应的Cluster-IP) 端口9090
设置显示数据模板(Import Dashboard)
搭建高可用集群
高可用集群需要多master节点
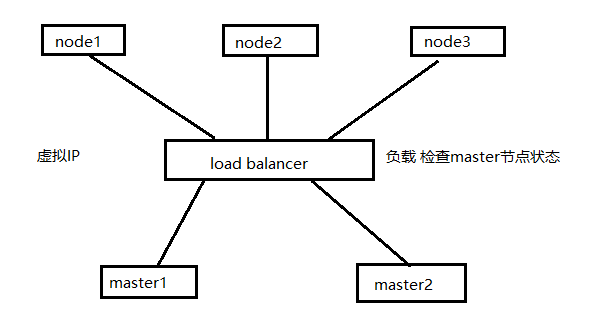
高可用集群技术:
keepalived:配置虚拟IP,检查当前master节点状态,是否正常运行
haproxy:负载均衡的作用
配置高可用集群
master1:部署keepalived 部署haproxy matser节点初始化 安装docker 网络插件
master2:部署keepalived 部署haproxy 添加master2节点到集群 安装docker 网络插件
node1:添加node1节点到集群 安装docker 网络插件
node2:添加node2节点到集群 安装docker 网络插件
node3:添加node3节点到集群 安装docker 网络插件
还需要一个VIP(虚拟IP)节点

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)