【卷积神经网络详解与实例】9——经典CNN之NiN(网络中的网络)
1 提出背景与设计动机
提出论文:[1312.4400] Network In Network
论文详解:(51 封私信 / 62 条消息) NIN一个即使放到现在也不会过时的网络 - 知乎
NiN(Network in Network)是由Min Lin等人于2014年提出的一种卷积神经网络结构。在NiN提出之前,卷积神经网络(CNN)已经取得了显著的成功,特别是AlexNet在2012年ImageNet竞赛中的突破性表现。然而,传统的CNN结构存在一些局限性:
-
传统卷积层的局限性:传统卷积层使用线性滤波器(卷积核) followed by 非线性激活函数(如ReLU)。这种结构被认为是一个广义线性模型(GLM),其抽象能力有限,对于同一特征图的不同区域,使用相同的滤波器可能无法捕捉到更复杂的模式。
-
全连接层的问题:传统的CNN在最后几层通常使用全连接层进行分类,这种方式容易导致过拟合,并且参数量巨大。
-
特征表示的不足:传统卷积层的感受野虽然可以通过堆叠来增大,但每个卷积核只能学习到一种特定的模式,对于复杂的数据分布,可能需要更多的卷积核来捕获足够的特征。
NiN的设计动机主要基于以下几点:
-
增强特征提取能力:通过在卷积层内部引入微型的多层感知机(MLP),增强网络对局部特征的抽象能力。
-
减少参数数量:使用全局平均池化(Global Average Pooling)替代传统的全连接层,大幅减少参数数量,降低过拟合风险。
-
提高模型泛化能力:通过更精细的特征提取和更简洁的分类层设计,提高模型在不同数据集上的泛化性能。
NiN的核心思想是"网络中的网络"(Network in Network),即在传统的卷积网络结构中嵌入更小的神经网络,以增强模型的表达能力。
2 网络结构
2.1 网络结构中的核心创新点
2.1.1 MLP卷积层(mlpconv)
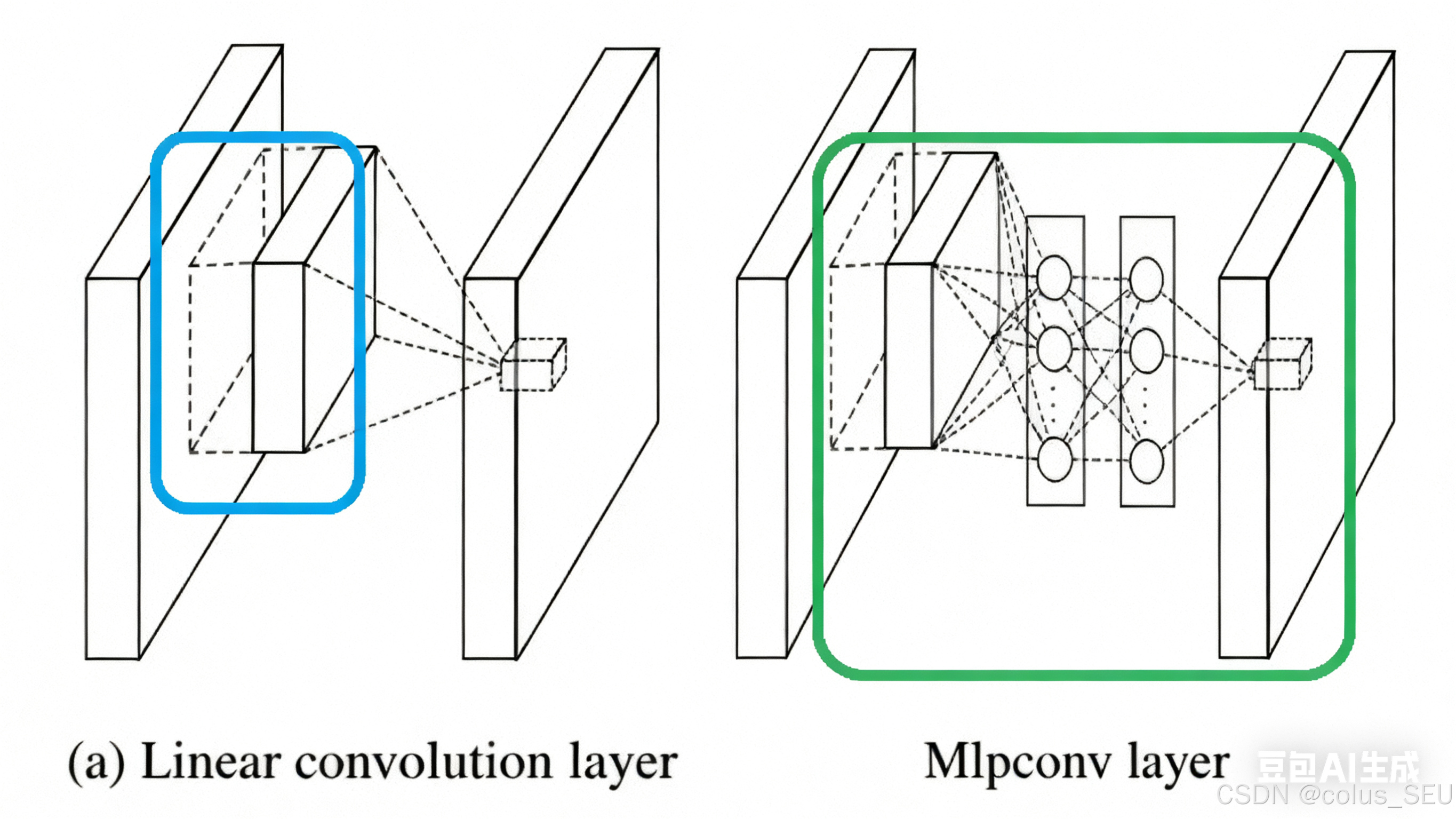
左图为简单的卷积层网络,右图为mlpconv(卷积层 + 1x1 卷积 + ReLu函数组成)。
传统的卷积层可以看作是一个线性滤波器 followed by 非线性激活函数。而NiN提出的MLP卷积层在传统卷积的基础上,增加了额外的1×1卷积层,相当于在每个局部感受野上应用了一个微型的多层感知机。
MLP卷积层的数学表示:
-
传统卷积:
-
MLP卷积:
其中, 是输入的局部块,
和
是第一层和第二层的权重,
是非线性激活函数(如ReLU)。
MLP卷积层的优势:
-
能够学习更复杂的特征表示
-
通过1×1卷积实现跨通道的信息整合
-
增加了网络的非线性,提高了模型的表达能力
2.1.2 全局平均池化(Global Average Pooling)
传统的CNN在最后几层通常使用全连接层进行分类,这种方式存在以下问题:
-
参数量巨大,容易导致过拟合
-
破坏了特征图的空间结构信息
-
对输入尺寸敏感
NiN提出了全局平均池化来替代全连接层:
-
对每个特征图取平均值,得到一个数值
-
将这些数值直接作为对应类别的置信度
-
大幅减少参数数量,降低过拟合风险
2.2 与 LeNet/AlexNet 的对比
NiN与早期的经典CNN结构(如LeNet和AlexNet)在设计理念上有显著差异:
| 特性 | LeNet | AlexNet | NiN |
|---|---|---|---|
| 提出年份 | 1998 | 2012 | 2014 |
| 核心创新 | 首次提出CNN架构 | 使用ReLU、Dropout、GPU加速 | MLP卷积层、全局平均池化 |
| 卷积层类型 | 传统卷积 | 传统卷积 | MLP卷积层 |
| 分类层 | 全连接层 | 全连接层 | 全局平均池化 |
| 参数数量 | 约60K | 约60M | 显著减少 |
| 感受野控制 | 通过堆叠卷积层 | 通过堆叠卷积层 | 通过MLP卷积层增强 |
| 特征整合 | 仅在通道维度 | 仅在通道维度 | 空间和通道维度同时整合 |
具体差异:
-
卷积层设计:
-
LeNet和AlexNet使用传统的卷积层,每个卷积核只学习一种特征模式。
-
NiN使用MLP卷积层,每个局部感受野通过微型网络进行更复杂的特征提取。
-
-
分类层设计:
-
LeNet和AlexNet使用全连接层作为分类器,参数量大。
-
NiN使用全局平均池化,将每个特征图映射到一个类别的置信度,参数量极少。
-
-
网络深度:
-
LeNet相对较浅(5层)。
-
AlexNet较深(8层)。
-
NiN通过MLP卷积层在增加网络深度的同时控制参数数量。
-
-
参数效率:
-
NiN通过1×1卷积和全局平均池化大幅减少了参数数量,提高了参数利用率。
-
2.3 具体网络结构和参数
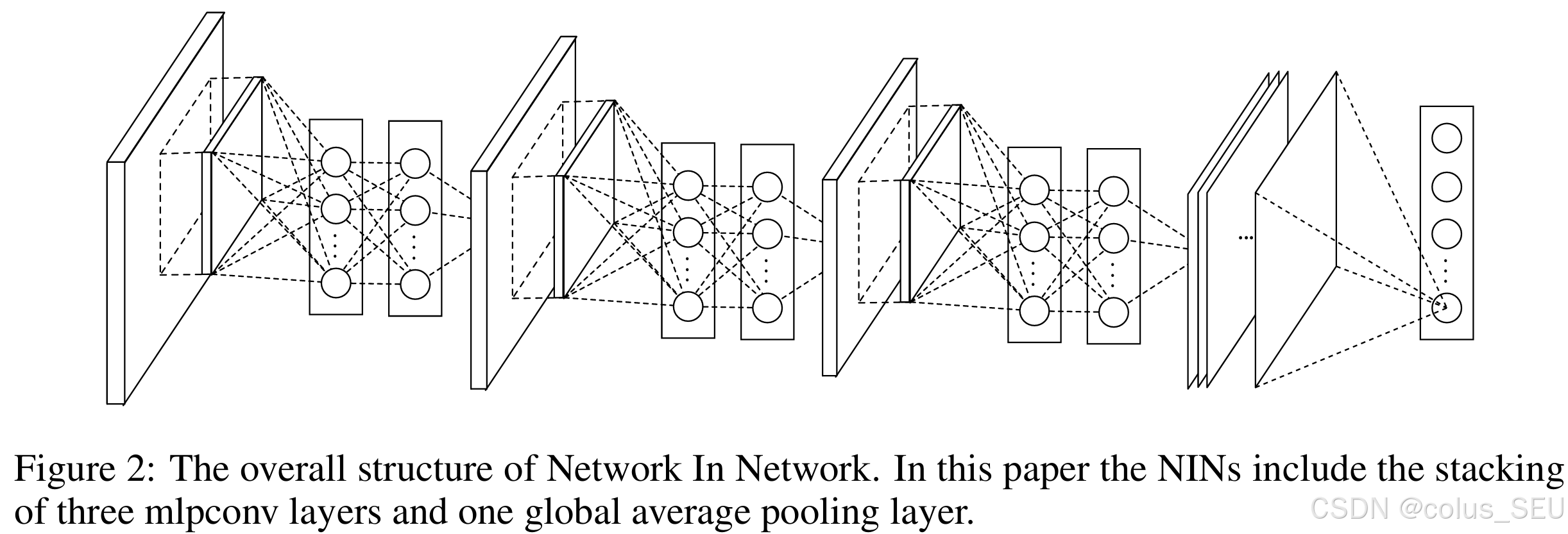
此网络结构总计4层: 3mlpconv + 1global_average_pooling
NiN的原始论文中提出了针对CIFAR-10和CIFAR-100数据集的网络结构,以及针对ImageNet的更深层次结构。下面我们以CIFAR-10版本为例,详细说明其网络结构和参数:
CIFAR-10版本的NiN结构:
-
输入层:32×32×3(RGB图像)
-
第一个MLP卷积层:
-
卷积:5×5卷积,192个滤波器,步长1,填充2
-
ReLU激活
-
1×1卷积,160个滤波器
-
ReLU激活
-
1×1卷积,96个滤波器
-
ReLU激活
-
最大池化:3×3,步长2
-
Dropout:50%
-
-
第二个MLP卷积层:
-
卷积:5×5卷积,192个滤波器,步长1,填充2
-
ReLU激活
-
1×1卷积,192个滤波器
-
ReLU激活
-
1×1卷积,192个滤波器
-
ReLU激活
-
平均池化:3×3,步长2
-
Dropout:50%
-
-
第三个MLP卷积层:
-
卷积:3×3卷积,192个滤波器,步长1,填充1
-
ReLU激活
-
1×1卷积,192个滤波器
-
ReLU激活
-
1×1卷积,10个滤波器
-
ReLU激活
-
-
全局平均池化层:
-
对每个10个特征图取平均值
-
-
输出层:10个类别的概率分布
参数计算:
以第一个MLP卷积层为例:
-
5×5卷积:5×5×3×192 = 14,400参数
-
第一个1×1卷积:1×1×192×160 = 30,720参数
-
第二个1×1卷积:1×1×160×96 = 15,360参数
-
总计:60,480参数
相比传统CNN,NiN通过1×1卷积增加了参数,但通过全局平均池化大幅减少了最后的参数量,整体参数效率更高。
特征图尺寸变化:
-
输入:32×32×3
-
第一个MLP卷积层后:16×16×96
-
第二个MLP卷积层后:8×8×192
-
第三个MLP卷积层后:8×8×10
-
全局平均池化后:1×1×10
这种设计使得NiN能够在保持较高表达能力的同时,有效控制参数数量,减少过拟合风险。
总结:
NiN网络通过引入MLP卷积层和全局平均池化,在保持较高表达能力的同时,有效控制了参数数量,减少了过拟合风险。这种设计思想对后来的深度学习模型产生了深远影响,如GoogLeNet中的Inception模块和ResNet中的残差连接都受到了NiN的启发。
3 基于Pytorch实现
通过PyTorch实现NiN并在CIFAR-10上进行训练,我们可以看到NiN虽然结构相对简单,但在图像分类任务上仍然能够取得不错的性能。这证明了好的网络设计思想比单纯增加网络深度和宽度更为重要。
项目目录如下:
NIN_CIFAR10/
│
├── data/ # 数据目录
│ └── cifar-10-batches-py/ # CIFAR-10数据集(代码中自动下载)
│
├── model/ # 模型目录
│ └── nin.py # NiN模型定义
│
├── utils/ # 工具函数目录
│ └── data_utils.py # 数据处理工具
│
├── train.py # 训练脚本
└── test.py # 测试脚本模型定义
# nin.py
import torch.nn as nn
class NiN(nn.Module):
def __init__(self, num_classes=10):
super(NiN, self).__init__()
# 第一个mlpconv层
self.mlpconv1 = nn.Sequential(
nn.Conv2d(3, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.Conv2d(192, 160, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(160, 96, kernel_size=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Dropout(0.5)
)
# 第二个mlpconv层
self.mlpconv2 = nn.Sequential(
nn.Conv2d(96, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Dropout(0.5)
)
# 第三个mlpconv层
self.mlpconv3 = nn.Sequential(
nn.Conv2d(192, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, num_classes, kernel_size=1),
)
# 全局平均池化
self.global_avg_pool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
x = self.mlpconv1(x)
x = self.mlpconv2(x)
x = self.mlpconv3(x)
x = self.global_avg_pool(x)
x = x.view(x.size(0), -1)
return x数据集加载辅助
# data_utils.py
import torch
import torchvision
import torchvision.transforms as transforms
def get_cifar10_data_loaders(data_dir='./data', batch_size=128, num_workers=4):
"""
获取CIFAR-10数据集的加载器
参数:
data_dir: 数据存储目录
batch_size: 批次大小
num_workers: 数据加载的工作进程数
返回:
train_loader: 训练数据加载器
test_loader: 测试数据加载器
"""
# 定义数据预处理
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
# 加载CIFAR-10数据集
train_set = torchvision.datasets.CIFAR10(
root=data_dir, train=True, download=True, transform=transform_train)
test_set = torchvision.datasets.CIFAR10(
root=data_dir, train=False, download=True, transform=transform_test)
# 创建数据加载器
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(
test_set, batch_size=batch_size, shuffle=False, num_workers=num_workers)
return train_loader, test_loader
def get_classes():
"""获取CIFAR-10的类别名称"""
return ('plane', 'car', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck')模型训练
import os
import argparse
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm
from model.nin import NiN
from utils.data_utils import get_cifar10_data_loaders, get_classes
def train(args):
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
# 创建模型保存目录
if not os.path.exists(args.save_dir):
os.makedirs(args.save_dir)
# 获取数据加载器
train_loader, test_loader = get_cifar10_data_loaders(
data_dir=args.data_dir, batch_size=args.batch_size, num_workers=args.num_workers)
# 创建模型
model = NiN(num_classes=10).to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=0.9, weight_decay=5e-4)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[60, 120, 160], gamma=0.1)
# 创建TensorBoard writer
writer = SummaryWriter(log_dir=os.path.join(args.save_dir, 'logs'))
# 训练循环
best_acc = 0.0
for epoch in range(args.epochs):
# 训练阶段
model.train()
train_loss = 0.0
correct = 0
total = 0
pbar = tqdm(train_loader, desc=f'Epoch {epoch + 1}/{args.epochs}')
for inputs, targets in pbar:
inputs, targets = inputs.to(device), targets.to(device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计信息
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
# 更新进度条
pbar.set_postfix({
'Loss': train_loss / (pbar.n + 1),
'Acc': 100. * correct / total
})
# 更新学习率
scheduler.step()
# 计算训练集准确率
train_acc = 100. * correct / total
train_loss = train_loss / len(train_loader)
# 测试阶段
test_acc = test(model, test_loader, device, criterion)
# 记录到TensorBoard
writer.add_scalar('Loss/train', train_loss, epoch)
writer.add_scalar('Accuracy/train', train_acc, epoch)
writer.add_scalar('Accuracy/test', test_acc, epoch)
writer.add_scalar('Learning rate', optimizer.param_groups[0]['lr'], epoch)
# 打印信息
print(f'Epoch {epoch + 1}/{args.epochs}: '
f'Train Loss: {train_loss:.4f}, '
f'Train Acc: {train_acc:.2f}%, '
f'Test Acc: {test_acc:.2f}%')
# 保存最佳模型
if test_acc > best_acc:
best_acc = test_acc
torch.save(model.state_dict(), os.path.join(args.save_dir, 'best_model.pth'))
print(f'Best model saved with accuracy: {best_acc:.2f}%')
# 定期保存模型
if (epoch + 1) % args.save_interval == 0:
torch.save({
'epoch': epoch + 1,
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict(),
'best_acc': best_acc,
}, os.path.join(args.save_dir, f'checkpoint_epoch_{epoch + 1}.pth'))
print(f'Training completed. Best test accuracy: {best_acc:.2f}%')
writer.close()
def test(model, test_loader, device, criterion):
"""测试模型"""
model.eval()
test_loss = 0
correct = 0
total = 0
with torch.no_grad():
for inputs, targets in test_loader:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
test_loss = test_loss / len(test_loader)
test_acc = 100. * correct / total
return test_acc
def main():
parser = argparse.ArgumentParser(description='Train NiN on CIFAR-10')
parser.add_argument('--data_dir', type=str, default='./data', help='data directory')
# 保存训练好的模型文件
parser.add_argument('--save_dir', type=str, default='./checkpoints', help='model save directory')
parser.add_argument('--batch_size', type=int, default=128, help='batch size')
parser.add_argument('--num_workers', type=int, default=4, help='number of data loading workers')
parser.add_argument('--lr', type=float, default=0.01, help='learning rate')
parser.add_argument('--epochs', type=int, default=100, help='number of epochs to train')
parser.add_argument('--save_interval', type=int, default=20, help='save model every N epochs')
args = parser.parse_args()
train(args)
if __name__ == '__main__':
main()模型测试
# test.py
import os
import argparse
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from tqdm import tqdm
from model.nin import NiN
from utils.data_utils import get_classes
def test(args):
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
# 获取类别名称
classes = get_classes()
# 定义数据预处理
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
# 加载测试数据集
test_set = torchvision.datasets.CIFAR10(
root=args.data_dir, train=False, download=True, transform=transform_test)
test_loader = torch.utils.data.DataLoader(
test_set, batch_size=args.batch_size, shuffle=False, num_workers=args.num_workers)
# 创建模型
model = NiN(num_classes=10).to(device)
# 加载模型权重
if os.path.isfile(args.model_path):
print(f"Loading model from {args.model_path}")
model.load_state_dict(torch.load(args.model_path))
else:
print(f"No model found at {args.model_path}")
return
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 测试模型
model.eval()
test_loss = 0
correct = 0
total = 0
# 用于计算每个类别的准确率
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
pbar = tqdm(test_loader, desc='Testing')
for inputs, targets in pbar:
inputs, targets = inputs.to(device), targets.to(device)
outputs = model(inputs)
loss = criterion(outputs, targets)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
# 计算每个类别的准确率
c = (predicted == targets).squeeze()
for i in range(targets.size(0)):
label = targets[i]
class_correct[label] += c[i].item()
class_total[label] += 1
# 更新进度条
pbar.set_postfix({
'Loss': test_loss / (pbar.n + 1),
'Acc': 100. * correct / total
})
# 计算总体准确率
test_loss = test_loss / len(test_loader)
test_acc = 100. * correct / total
print(f'Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.2f}%')
# 打印每个类别的准确率
for i in range(10):
print(f'Accuracy of {classes[i]:5s} : {100 * class_correct[i] / class_total[i]:.2f}%')
def main():
parser = argparse.ArgumentParser(description='Test NiN on CIFAR-10')
parser.add_argument('--data_dir', type=str, default='./data', help='data directory')
parser.add_argument('--model_path', type=str, required=True, help='path to the trained model')
parser.add_argument('--batch_size', type=int, default=128, help='batch size')
parser.add_argument('--num_workers', type=int, default=4, help='number of data loading workers')
args = parser.parse_args()
test(args)
if __name__ == '__main__':
main()
腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)