基于spark+机器学习+django的人类肥胖程度分析可视化系统
摘要:本文介绍了一个基于Python、Spark、Hadoop、Django、Vue和ECharts等技术构建的人类肥胖程度分析可视化系统。该系统通过大数据技术整合多维度健康数据(包括人口学特征、饮食习惯、运动行为等),构建肥胖风险评估模型,克服了传统BMI指标的局限性。系统采用Spark处理海量数据,Hadoop实现分布式存储,Vue和ECharts实现前端可视化,MySQL作为数据库支撑。研究
1.开发环境
发语言:python
采用技术:Spark、Hadoop、Django、Vue、Echarts等技术框架
数据库:MySQL
开发环境:PyCharm
2 系统设计
随着经济发展和生活方式的转变,肥胖问题已成为全球性的公共健康挑战。根据世界卫生组织数据显示,全球肥胖人数在过去四十年中增长了近三倍,超过19亿成年人存在超重问题,其中6.5亿人患有肥胖症。传统的肥胖风险评估往往依赖单一的BMI指标,缺乏对个体生活习惯、饮食结构、运动频率等多维度因素的综合考量。面对海量的健康数据,传统分析方法已难以满足精准识别肥胖风险因素和个性化健康管理的需求。大数据技术的快速发展为解决这一问题提供了新的思路,通过对多维度健康数据进行深度挖掘和智能分析,能够更准确地识别肥胖风险模式,为制定科学有效的预防和干预策略提供数据支撑。
本课题具有重要的理论价值和现实意义,从理论层面来看该系统构建了多维度的肥胖风险评估模型,将人口学特征、饮食习惯、生活方式、运动行为等因素进行有机整合,丰富了健康数据分析的理论框架,为相关研究提供了新的分析视角和方法论支撑。从技术角度而言,基于spark+机器学习+django的人类肥胖程度分析可视化系统综合运用Spark、Hadoop等大数据处理技术,结合ECharts可视化展示,实现了海量健康数据的高效处理和直观呈现,推动了大数据技术在健康管理领域的应用实践。从社会价值来说,该系统能够帮助个人更全面地了解自身的肥胖风险状况,通过科学的数据分析结果指导日常生活方式的调整,促进健康行为的养成。对于医疗机构和健康管理部门来说,系统提供的群体性肥胖风险分析结果可以为制定针对性的公共健康政策和干预措施提供重要依据。同时,系统的建设也为相关企业开发智能健康管理产品提供了技术参考和应用模式,具有良好的产业化前景和经济效益潜力。
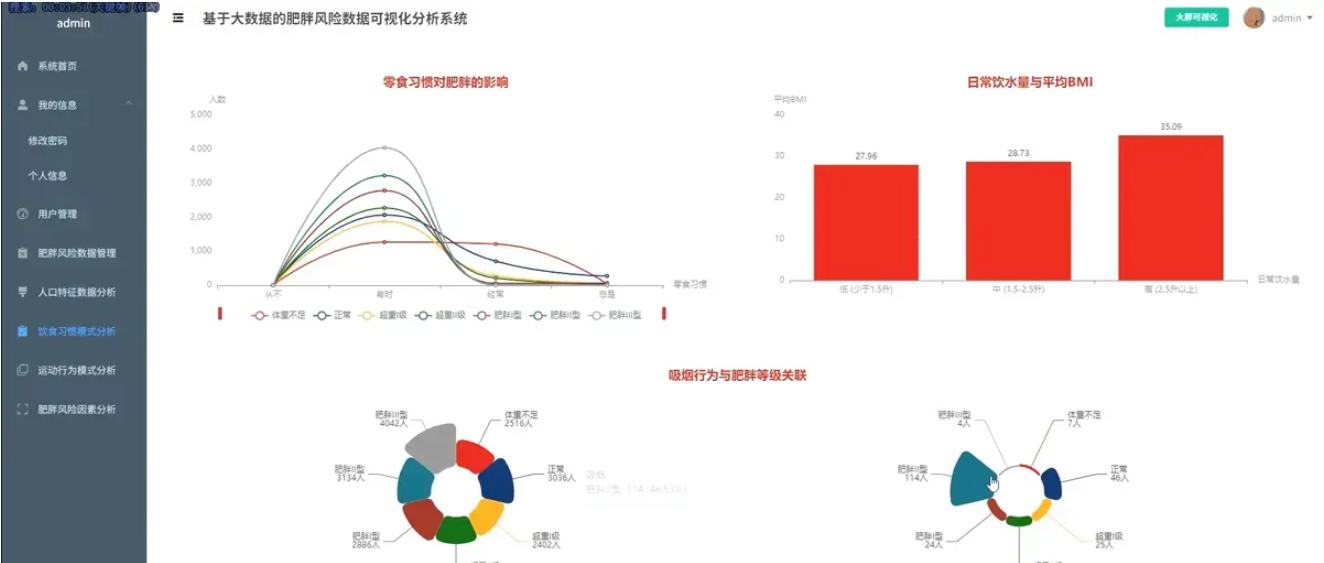
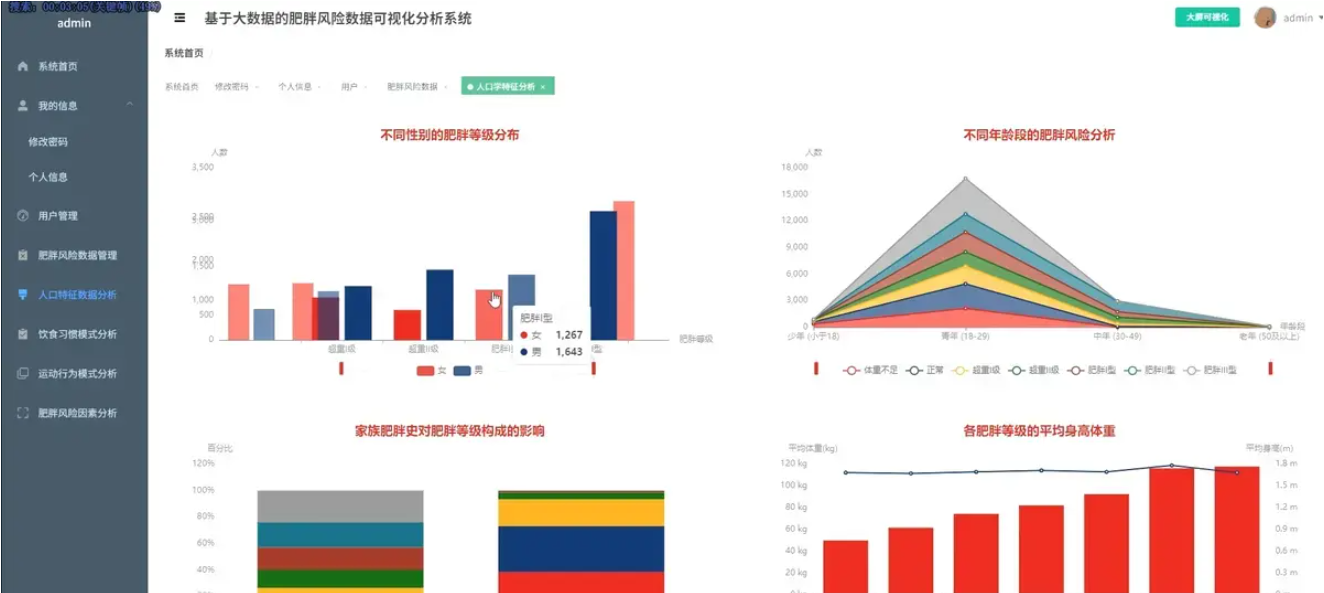
基于spark+机器学习+django的人类肥胖程度分析可视化系统是一个综合运用Python、Spark、Hadoop、Vue、ECharts、MySQL等现代技术栈构建的健康数据分析平台。该系统通过大数据处理技术对海量人群健康数据进行深度挖掘和分析,从人口学特征与肥胖风险、饮食与生活习惯、运动与科技使用行为、关键因素量化与模式探索四个核心维度展开研究。在人口学特征维度,系统分析不同性别的肥胖等级分布、不同年龄段的肥胖风险趋势、家族肥胖史对后代的影响以及体重身高与肥胖等级的交叉验证,并计算不同年龄段的BMI指标;在饮食与生活习惯维度,深入探究高热量食物偏好、蔬菜摄入频率、零食习惯、日常饮水量以及吸烟行为与肥胖水平的关联性;在运动与科技使用行为维度,重点分析体育锻炼频率、电子设备使用时长、日常交通方式以及酒精消费习惯对肥胖风险的影响;在关键因素量化维度,通过相关性分析、群体BMI差异分析、健康生活画像关联分析以及能量平衡模式探索,全面量化各因素的影响力。系统采用Spark进行大数据处理,利用Hadoop进行分布式存储,通过Vue构建前端界面,运用ECharts实现数据的动态可视化展示,MySQL作为数据存储支撑,为用户提供直观、全面的肥胖风险分析结果和科学的健康管理建议。
3 系统展示
3.1 大屏页面
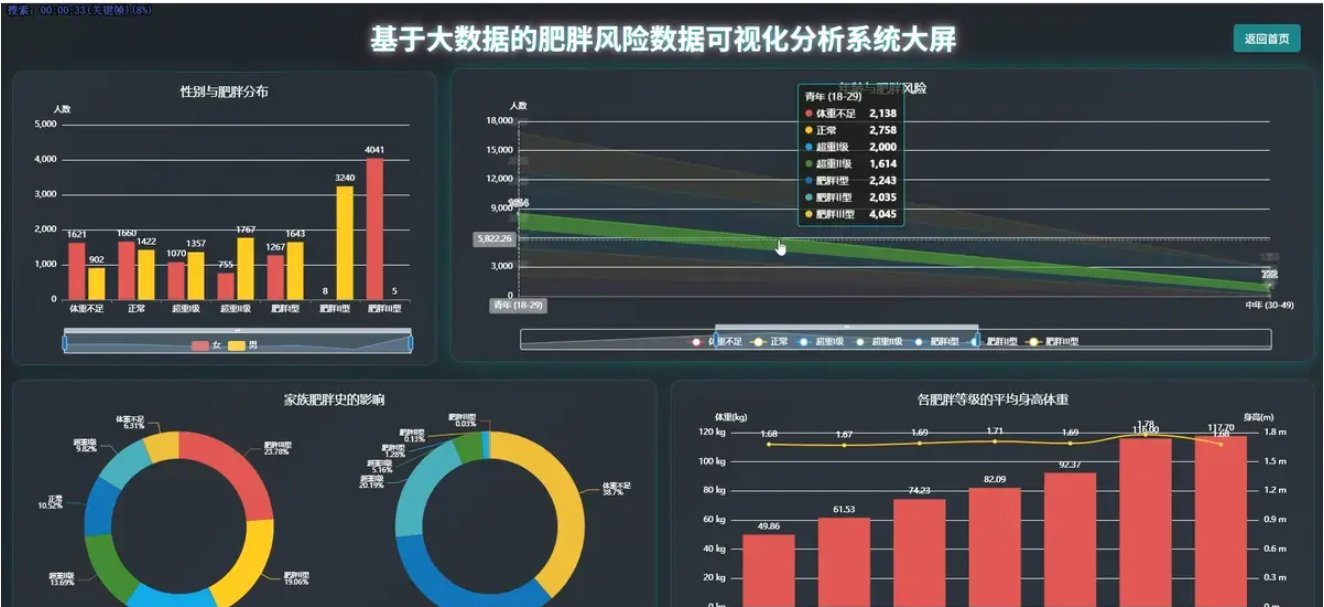
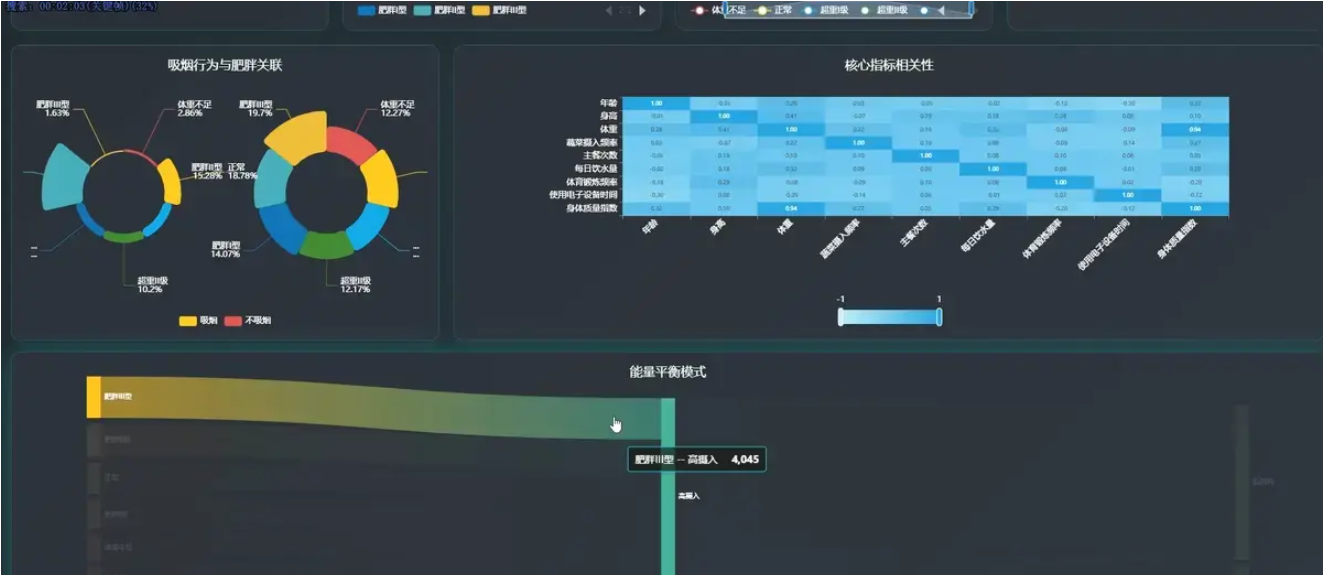
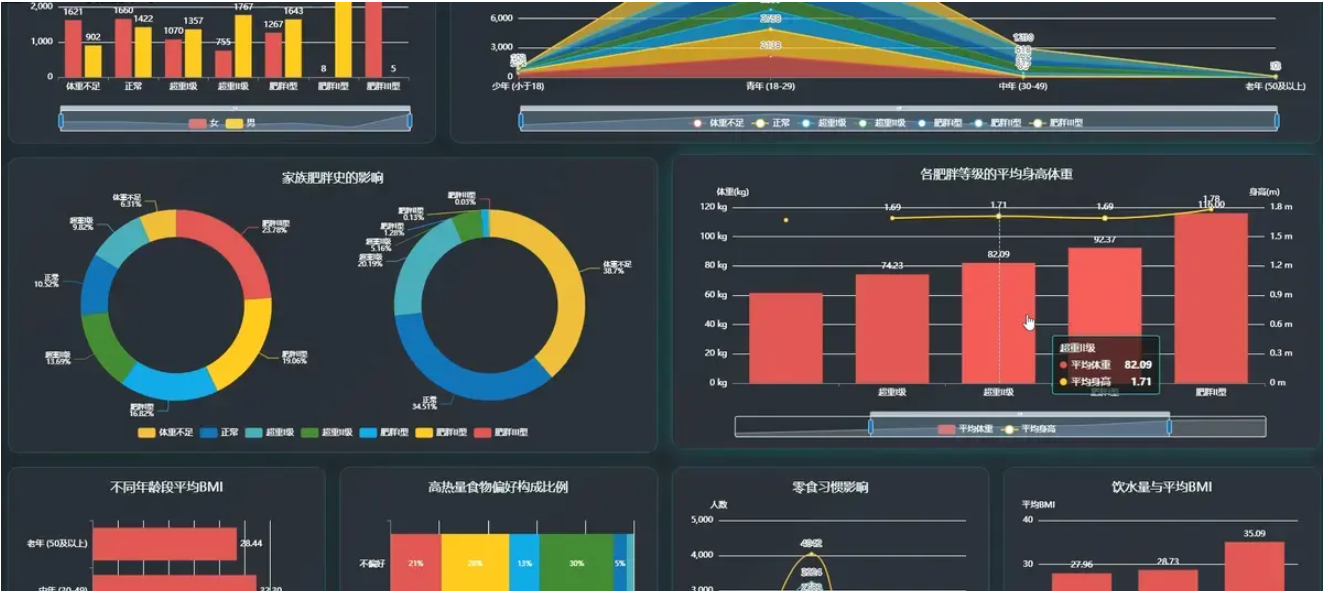
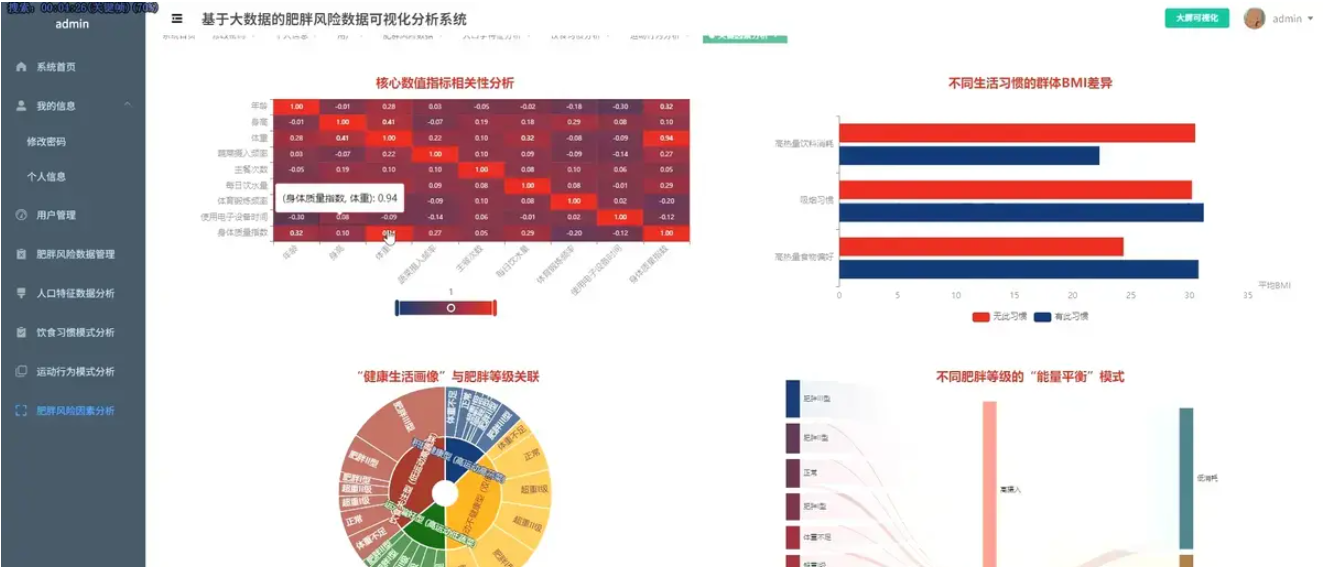


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)