系统中间件与云虚拟化-云数据库与数据库访问中间件ORM框架-Sannic-非实验
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
云数据库就是云上的数据库
这个云数据库既不是本地的数据库,也不是ECS上的数据库,而是类似于阿里云上面的数据库
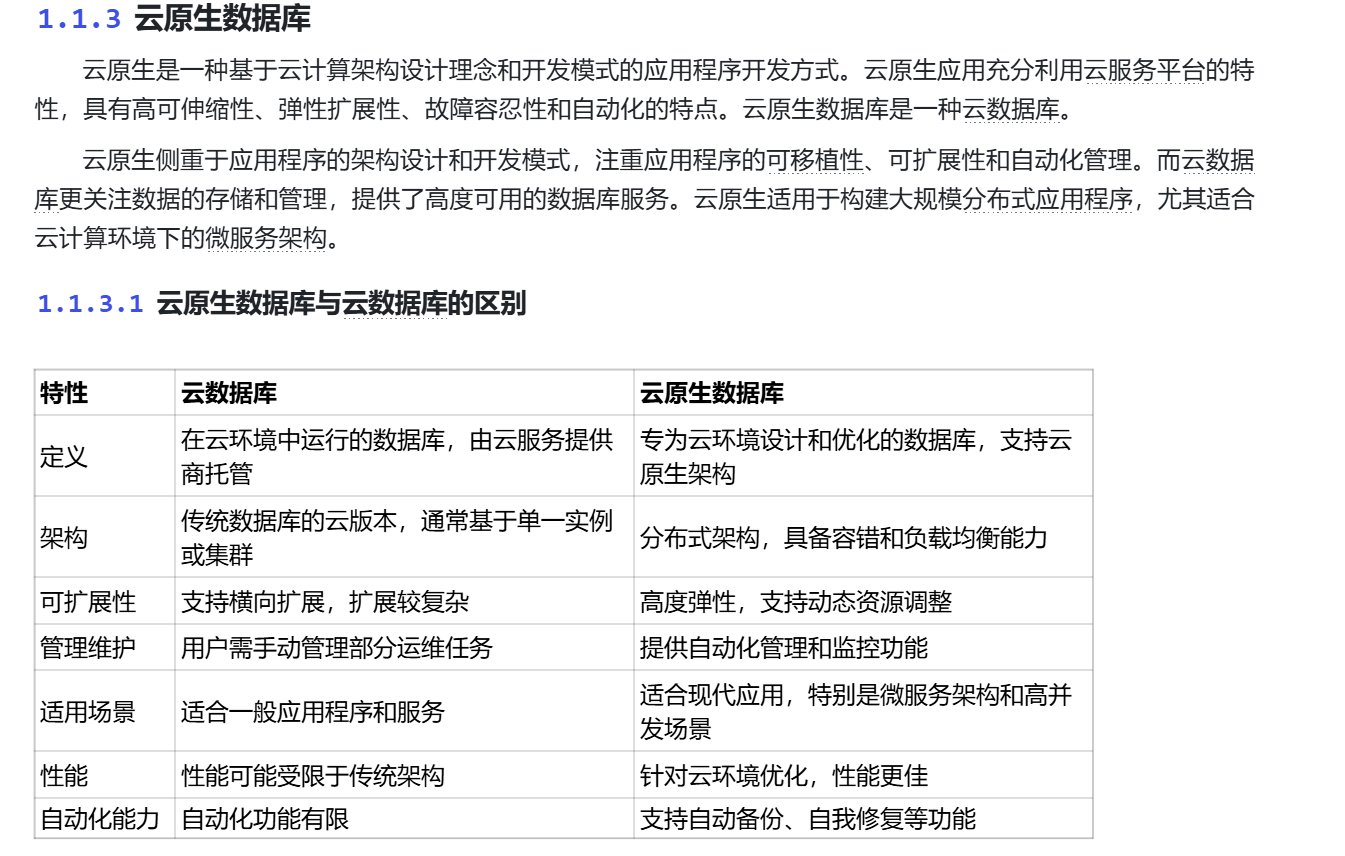
而云原生数据库就更厉害了
而至于ORM就是方便我们来访问数据库的,比如mybatis
create database db_serverless_user;
use db_serverless_user;
create table tbl_user(
id varchar(100) not null primary key comment "用户唯一标识",
name varchar(100) not null comment "用户名称",
age int unsigned null comment "用户年龄"
);
conda install pymysql
pymysql这个是原生sql,每次都需要我们手动连接,所以不用了
pymysql这个就是mysql的驱动
1. ORM框架SQLAlchemy

conda install SQLAlchemy
1.1 Base
在SQLAlchemy中,所有的实体类都需要继承自一个声明基类,这个基类由declarative_base()创建。通过继
承该基类,SQLAlchemy能够将Python类映射到数据库表。
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class ChildClass(Base):
# 继承 Base 类
1.2 Mapping

from sqlalchemy.orm import declarative_base
Base = declarative_base()
from sqlalchemy import Column,Integer,String
class User(Base):
__tablename__= 'tbl_user'
id = Column(String(10),primary_key=True)
name = Column(String(10))
age = Column(Integer)
Base表示这是一个数据库的类,
__tablename__表示表名
其他字段依次映射
1.3 Engine
Engine是SQLAlchemy连接数据库的管理类,它封装了数据库连接池和数据库方言,可以创建Session会话、执
行低级别的SQL语句。SQLAlchemy通过create_engine函数来创建Engine,该函数需要指定数据库的URL,格
式如下:
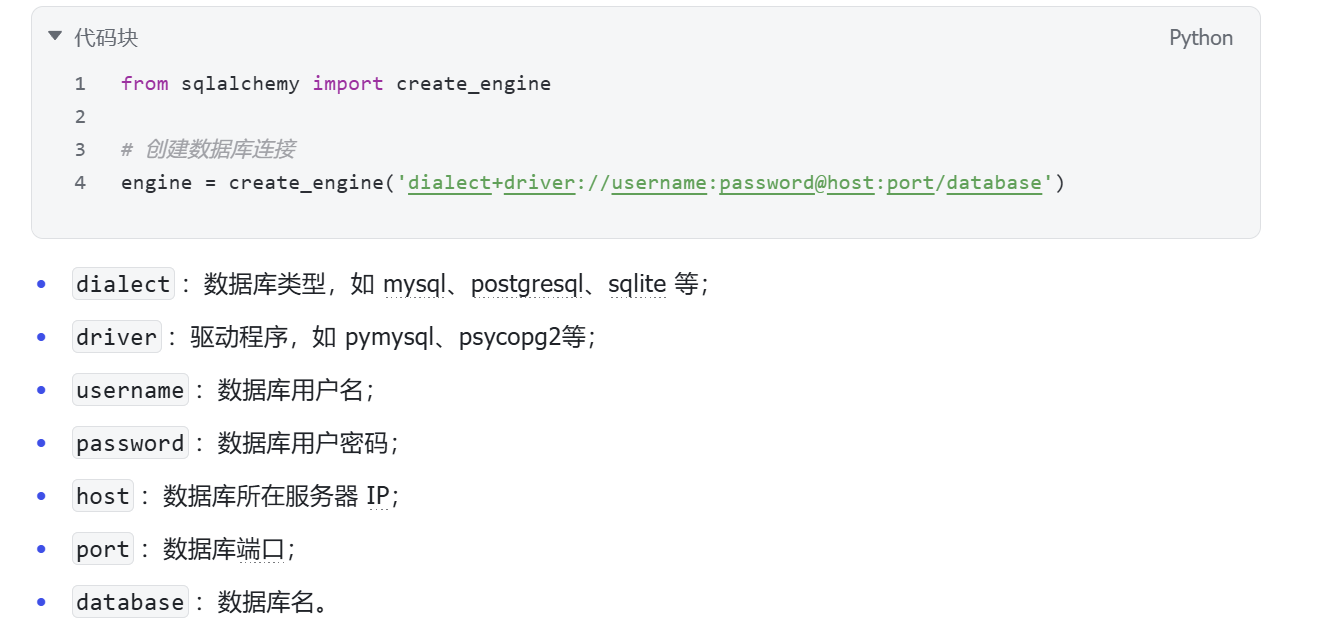
from sqlalchemy import create_engine
#创建与数据库的连接
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/db_serverless_user')
1.4 Session
Session会话实例用于管理对象与数据库的交互,用于处理对象的持久化、查询和事务的提交。通过
sessionmaker方法基于SQL引擎获取Session工厂,再基于Session工厂创建Session实例对象:
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine,autocommit=False, autoflush=False)
#创建Session工厂,当autocommit=True为true的时候,不需要显示执行Session.commit()
session = Session()#创建session实例对象
Session()提供了很多数据库的操作方法
commit:用于提交当前会话中的所有操作,最终将数据持久化到数据库。如果在事务提交前抛出异常,可以
通过rollback()来回滚事务。
session.commit()
rollback:当事务过程发生异常处理时用于回滚当前会话的所有未提交事务。
session.rollback()
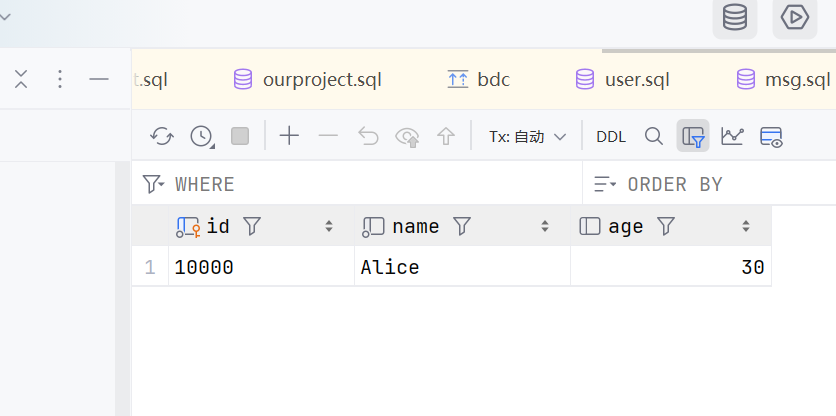
add:将一个新的对象添加到当前Session中,但并不会立即提交到数据库,直到事务被提交;
user = User(id='10000',name='Alice',age=30)
session.add(user)
session.commit()
query:用来查询数据的核心方法,通过类模型或列模型来查询表中的数据。
users = session.query(User).all()
session.commit()
print(users[0].name)

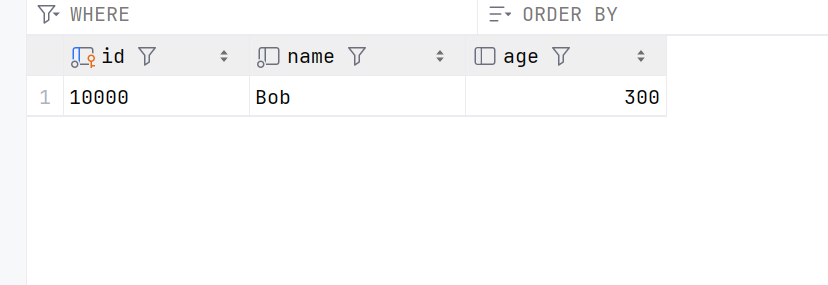
update:更新数据库中的记录。首先需要找到目标对象,修改对象的属性值,然后调用commit()持久化更
改。
from sqlalchemy import update
#生成并执行update语句
session.execute(
update(User).
where(User.id == '10000').
values(name="Bob",age=300)
)
#提交修改
session.commit()
特定条件查询并修改到数据库
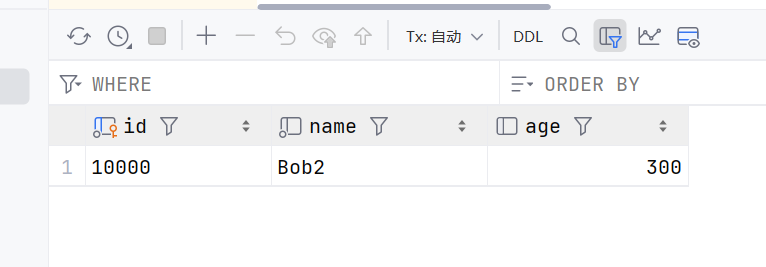
user = session.query(User).filter_by(id = '10000').first()
user.name = 'Bob2'
session.commit()
user = session.query(User).filter_by(id = ‘10000’).first()
这行代码从数据库中查询 User 表中 id 为 ‘10000’ 的用户记录,并将查询到的第一个(也是唯一符合条件的)用户对象赋值给变量 user。
user.name = ‘Bob2’
在内存中修改查询到的用户对象的 name 属性,将其值设置为 ‘Bob2’。此时只是修改了内存中的对象,尚未同步到数据库。
session.commit()
提交事务,将之前在内存中对用户姓名的修改(改为 ‘Bob2’)正式写入数据库,使修改生效。
这个意思就是查询到的对象属性是可以直接更新到数据库的
delete:删除数据库记录,直到事务被提交后真实删除。
user = session.query(User).filter_by(id = '10000').first()
session.delete(user)
session.commit()
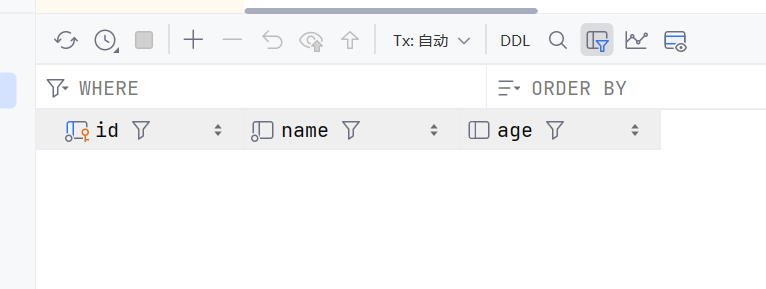
这样就删除了
1.5 Query
在SQLAlchemy中,查询(Query)是ORM中非常重要的部分,它用于从数据库中检索数据。SQLAlchemy提供
了多种灵活的方式来构建和执行查询,包括简单的过滤、排序、聚合、关联等操作。
·filterl|filter_by:用于构建查询条件,分别基于类名.属性名、属性名的方式构建条件。
user = session.query(User).filter(User.age>25).all()
user = session.query(User).filter_by(name = 'Alice').first()
一个是SQL的字段查询,一个类的字段查询
all是返回查询的所有结果
first是返回第一条结果
user = session.query(User).filter(User.age>25).one()
one表示如果插叙出来只有这一条结果,那么就返回这一条结果,如果返回多条就报错
user = session.query(User).filter(User.age>25).count()
count表示返回查询结果的数量
user = session.query(User).filter(User.age>25).order_by(User.age).count()
order_by表示排序
user = session.query(User).filter(User.age>25).limit(5).all()
limit表示限制返回的结果数量
user = session.query(User).filter(User.age>25).offset(5).limit(5).all()
offset表示跳过前面五条记录,获取后面五条记录
2. SQLAlchemy应用流程
from sqlalchemy import create_engine, Column, String, Integer
from sqlalchemy.orm import declarative_base, sessionmaker
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/db_serverless_user')
Base = declarative_base()
class User(Base):
__tablename__= 'tbl_user'
id = Column(String(10),primary_key=True)
name = Column(String(10))
age = Column(Integer)
def __repr__(self):
return f'User(id={self.id}, name={self.name}, age={self.age})'
#创建数据库和表
Base.metadata.create_all(engine)
#创建session
Session = sessionmaker(bind=engine)
session = Session()
#插入数据
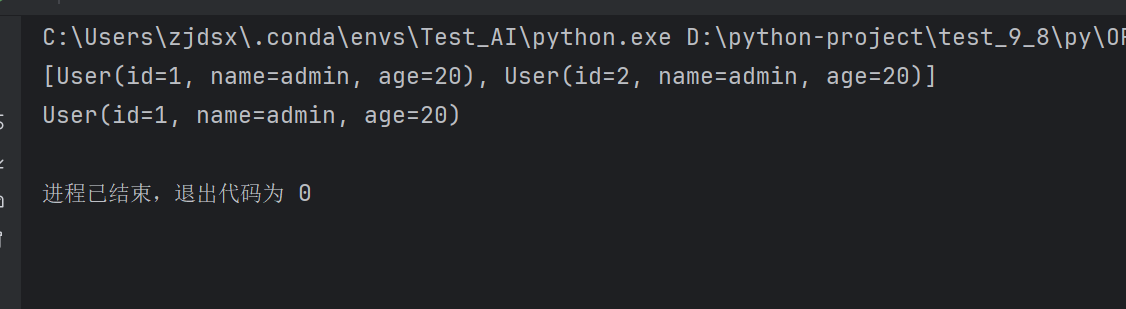
User= User(id='1',name='admin',age=20)
session.add(User)
session.commit()
#查询所有用户
users = session.query(User).all()
print(users)
#根据id查询用户
user = session.query(User).filter_by(id='1').first()
print(user)
#更新数据
user.age=1000
session.commit()
#删除数据
# session.delete(user)
# session.commit()
session.close()

3. SQLAlchemy事务处理
try:
#数据库操作
session.commit()
except:
session.rollback()
raise
finally:
session.close()
在这段代码中,raise 的作用是重新抛出当前捕获到的异常,让异常继续向上传播,而不是在当前的 except 块中被消化掉

4. Sanic简单案例
from sanic import Sanic, Request, HTTPResponse, response
app = Sanic("HelloServer")
@app.get("/hello")
async def hello(request: Request)->HTTPResponse:
return response.text("Hello")
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8000)
async def hello(request: Request)->HTTPResponse:
定义一个异步处理函数 hello,用于处理访问 /hello 路径的请求
request: Request 是类型注解,表示参数 request 是 Request 类型的对象,包含客户端请求的信息
-> HTTPResponse 也是类型注解,表示该函数返回 HTTPResponse 类型的响应
@app.post("/get_device")
async def get_device(request: Request)->HTTPResponse:
device_info = {"status":"success","data":{"id":"00001"}}
return json(device_info)
这个是返回json
@app.route("/get_device/g1",methods=["GET"])
async def get_device(request: Request)->HTTPResponse:
device_info = {"status":"success","data":{"id":"00001"}}
return json(device_info)
这个是对路由的配置注解
4.1 解析Http请求(Request)
·请求体(Body)
通过request.body访问请求体中的原始字节,如果请求体的内容是合法的JSON数据,也可以用
request.json访问。
@app.post("/hello")
async def hello(request: Request)->HTTPResponse:
print(request.body)
return response.text("Hello")
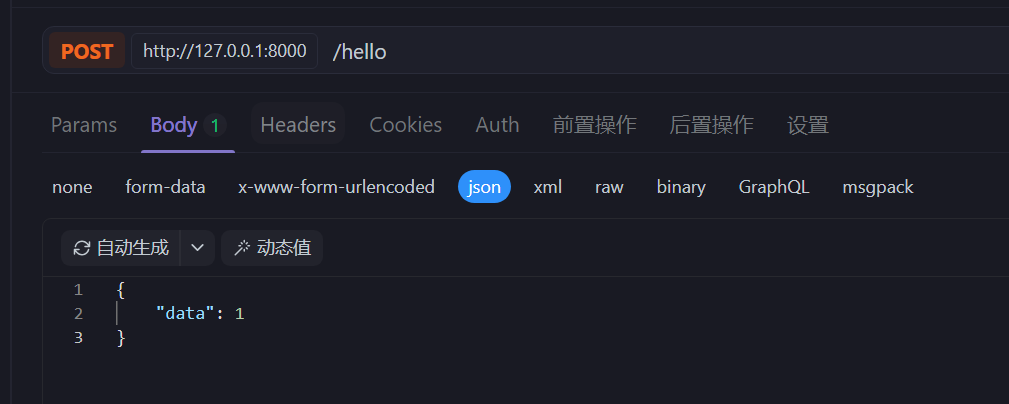

这个可以打印出里面的json


4.2 设置http响应

4.3 Sanic异常处理
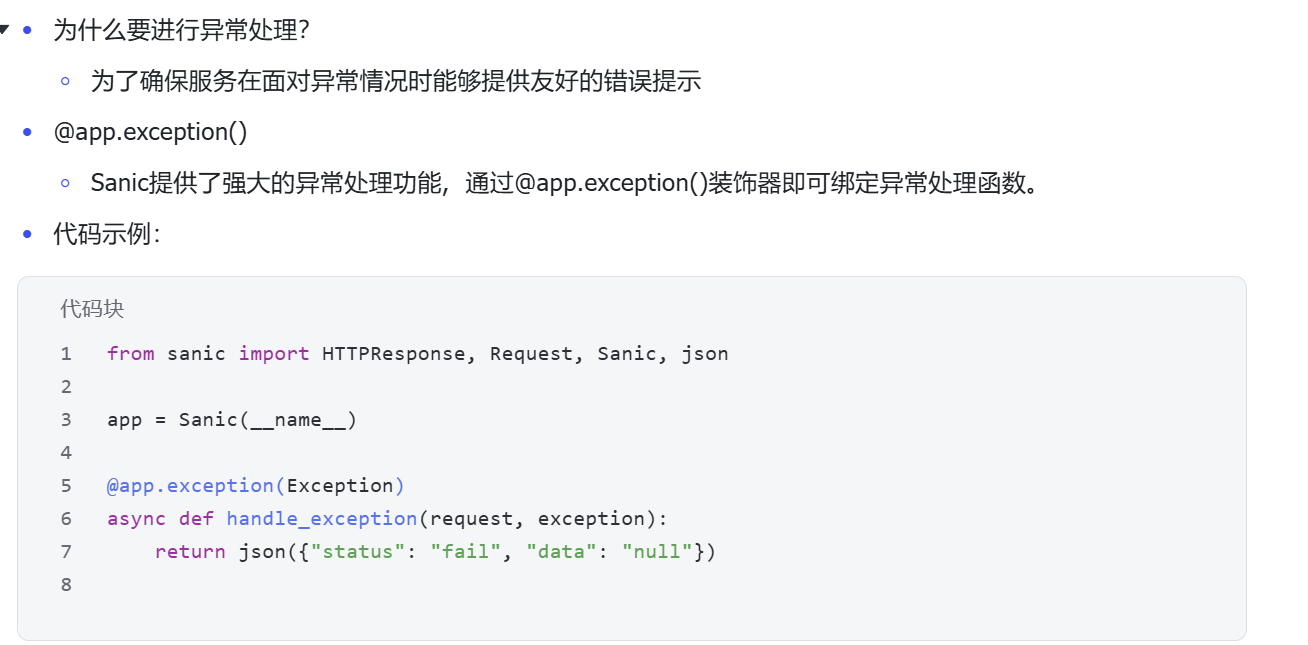
5. Python requests库

conda install requests
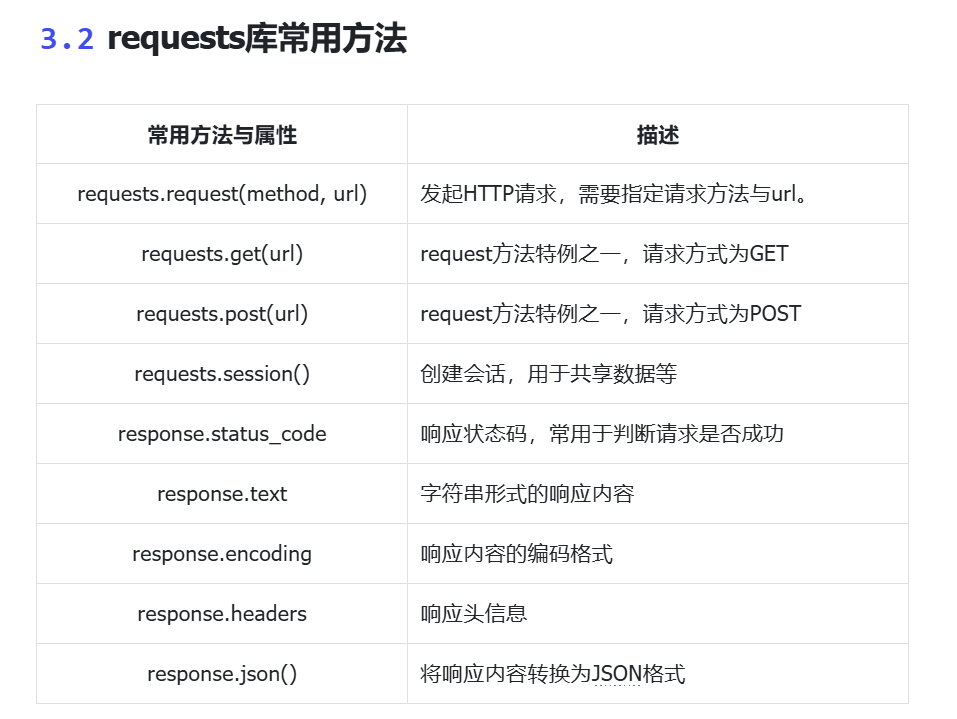
意思就是requests的功能就是相当于apifox,可以直接测试了
@app.route("/get_device",methods=["GET"])
async def get_device(request: Request)->HTTPResponse:
device_info = {"status":"success","data":{"id":"00001"}}
return json(device_info)

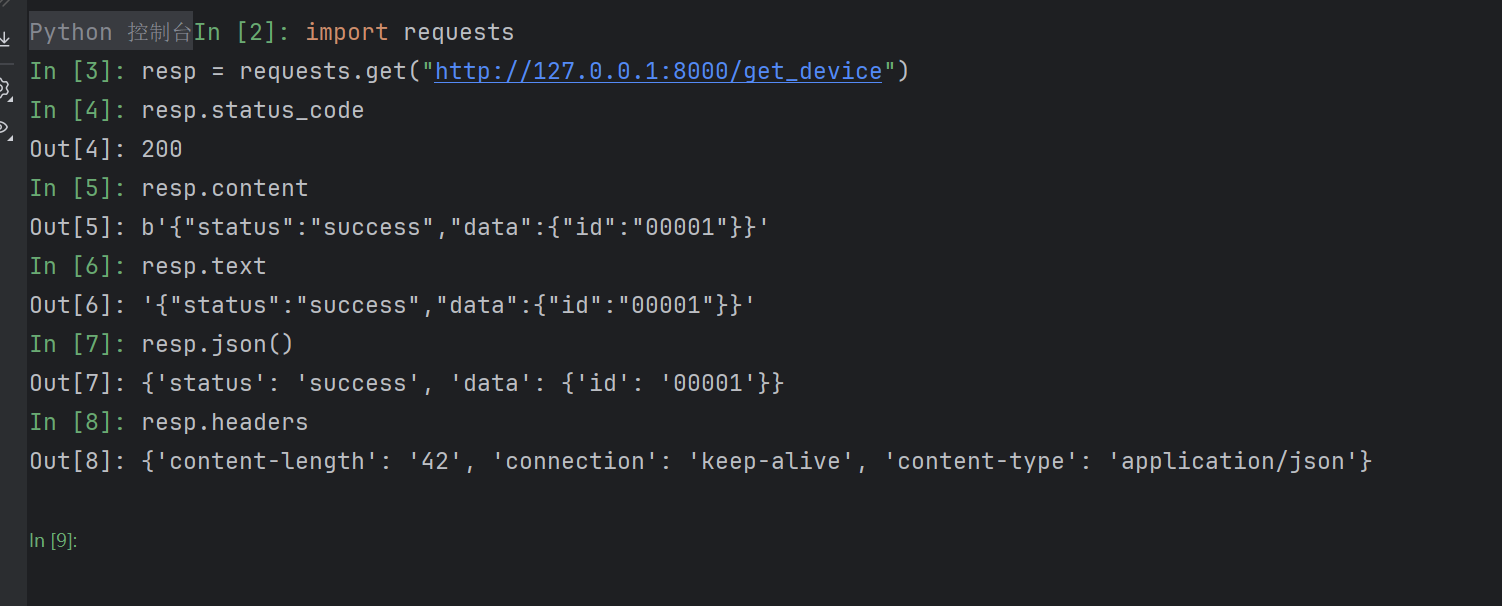
PyDev console: using IPython 9.1.0
Python 3.13.5 | packaged by Anaconda, Inc. | (main, Jun 12 2025, 16:37:03) [MSC v.1929 64 bit (AMD64)] on win32
import requests
resp = requests.get("http://127.0.0.1:8000/get_device")
resp.status_code
Out[4]: 200
resp.content
Out[5]: b'{"status":"success","data":{"id":"00001"}}'
resp.text
Out[6]: '{"status":"success","data":{"id":"00001"}}'
resp.json()
Out[7]: {'status': 'success', 'data': {'id': '00001'}}
resp.headers
Out[8]: {'content-length': '42', 'connection': 'keep-alive', 'content-type': 'application/json'}
总结

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 29
29 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)