【Python】标准库imaplib+email:读取邮件
python中的标准库可以实现自动读取邮件的功能。标准库imaplib库完成连接邮箱服务器并读取邮件,标准库email库完成邮件各部分内容的解析。
邮件相关的协议:
- SMAP(Simple Mail Transfer Protocol,简单邮件传输协议)管理发送服务器发送或中转邮件时遵循的协议。
- IMAP(Internet Mail Access Protocol,交互式邮件访问协议)管理从客户端直接访问接收服务器接收并读取邮件时遵循的协议。
- POP3(Post Office Protocol 3,邮局协议的第3个版本)也是从客户端访问接收服务器,但需下载邮件,之后客户端对邮件的操作不会反馈到服务器。
本文读取邮件,以163邮箱(涉及IMAP)为例。
标准库imaplib:
官方文档:imaplib — IMAP4 protocol client — Python 3.13.7 documentation
准备工作:
读取邮件,需开启IMAP/SMTP服务,获取邮箱授权码(不是邮箱登录密码),获取邮箱服务器主机地址和端口。
0、进入163邮箱 --> 点击:设置 --> 点击:POP3/SMTP/IMAP
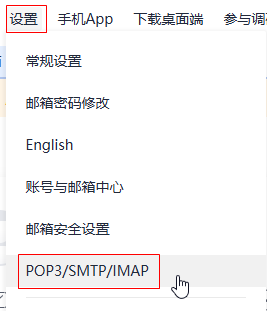
1、开启IMAP/SMTP服务
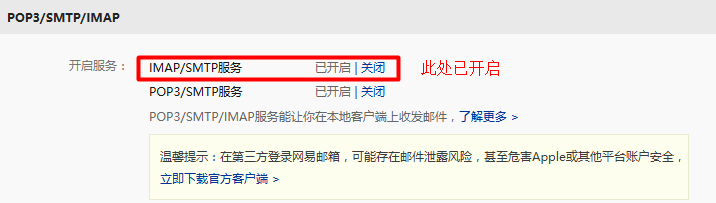
2、获取邮箱授权码
开启IMAP/SMTP服务后,可按提示获取邮箱授权码。若之前已经开启POP3/SMTP服务,则提示使用已给出的授权码,授权码有效期180天。
3、获取邮箱服务器主机地址
设置中POP3/SMTP/IMAP界面最下方提示中就有IMAP服务器地址。

4、服务器端口
163邮箱,接收服务器的端口为143,加密的SSL端口为993。
注:加密端口(SSL)为了增强安全性。使用SSL端口则使用子类imaplib.IMAP4_SSL(...)连接邮件服务器。
涉及类:smtplib.IMAP4(...)
类:imaplib.IMAP4(host='', port=IMAP4_PORT, timeout=None)
管理连接IMAP服务器。
注:host 邮件服务器主机地址,port 邮件服务器端口, timeout 设置超时时间。
子类:imaplib.IMAP4_SSL(...)
子类:imaplib.IMAP4_SSL(host='', port=IMAP4_SSL_PORT, *, ssl_context=None, timeout=None)
管理连接SSL端口的IMAP服务器。
注:host 邮件服务器主机地址,port 邮件服务器端口(SSL加密端口), timeout 设置超时时间。
类的主要方法:
1、登录:IMAP4.login(...)
IMAP4.login(user, password)
参数:user 接收邮箱,password 接收邮箱的授权码(不是登录密码)
2、查看服务器支持的功能:IMAP4.capability()
IMAP4.capability()
返回结果:元组形式,(typ, [data])。
import imaplib
imap_server = "imap.163.com"
conn = imaplib.IMAP4_SSL(imap_server, 993) # 连接IMAP服务器
print('capability: ', conn.capability())
# 返回结果:
capability: ('OK', [b'IMAP4rev1 XLIST SPECIAL-USE ID LITERAL+ STARTTLS APP
ENDLIMIT=71680000 XAPPLEPUSHSERVICE UIDPLUS X-CM-EXT-1 SASL-IR AUTH=XOAUTH2'])3、查看邮箱中所有文件夹:IMAP4.list()
IMAP4.list(directory='""', pattern='*')
查看邮箱中所有文件夹(包括收件箱、已发送等)。
返回结果:元组形式,(typ, [data])。
# 此处conn为连接邮箱服务器并登录成功
print('邮箱所有文件夹: ', conn.list()) # 查看邮箱中所有文件夹
# 返回结果:
邮箱所有文件夹: ('OK', [b'() "/" "INBOX"', b'(\\Drafts) "/" "&g0l6P3ux-"', b'(\\Sent) "/"
"&XfJT0ZAB-"', b'(\\Trash) "/" "&XfJSIJZk-"', b'(\\Junk) "/" "&V4NXPpCuTvY-"', b'() "/" "
&dcVr0mWHTvZZOQ-"', b'() "/" "&Xn9USpCuTvY-"', b'() "/" "&i6KWBZCuTvY-"', b'() "/" "&ZbBl5
VOG-"', b'() "/" "&ZbA-"', b'() "/" "&i6FSEg-"'])4、选择收件箱:IMAP4.select()
IMAP4.select(mailbox='INBOX', readonly=False)
注:没有参数,默认选择收件箱‘INBOX’。
5、搜索邮件:IMAP4.search(...)
IMAP4.search(charset, criterion[, ...])
搜索邮件之前,必须指定mailbox(即必须执行IMAP4.select(...))。
参数:charset 字符集,可以为None。
参数criterion可以'ALL'(搜索所有邮件),也可以‘UNSEEN’(搜索所有未读邮件),等。
6、获取邮件内容:IMAP4.fetch(...)
IMAP4.fetch(message_set, message_parts)
通过邮件序列号或邮件ID获取邮件内容。
例如:IMAP4.fetch(邮件ID,"(RFC822)")
通过邮件ID获取邮件的所有内容(包括头部信息和正文及附件)。"(RFC822)" 相当于'(BODY[])',读取邮件后会自动标记为已读。
注:若不希望标记为已读,则使用'(BODY.PEEK[])'。
| 参数message_parts | 说明与用途 | Python 使用示例 (片段) |
|---|---|---|
BODY[] 或
RFC822 |
获取整个邮件内容,包括头部和正文。自动标识为已读。 |
|
BODY.PEEK[] |
获取整个邮件内容,但不会标识为已读。适用于“无痕”读取。 | fetch('1', '(BODY.PEEK[])') |
BODY[HEADER] |
仅获取邮件的头部信息(头部包含主题、发件人、日期等)。自动标识为已读。 | fetch('1', '(BODY[HEADER])') |
BODY[TEXT] |
仅获取邮件的正文部分(不包含头部)。自动标识为已读。 | fetch('1', '(BODY[TEXT])') |
BODY[section] |
获取邮件的特定部分(如附件、HTML正文等),section 是用于标识部分编号或关键字的字符串。 |
fetch('1', '(BODY[1.2])') (获取第1部分的第2子部分) |
BODY[HEADER.FIELDS (names)] |
获取头部中特定字段(如只获取主题和发件人)。自动标识为已读。 | fetch('1', '(BODY[HEADER.FIELDS (SUBJECT FROM)])') |
BODYSTRUCTURE |
获取邮件的MIME结构详情,常用于分析邮件正文类型、字符集、附件信息(如文件名、类型)等。 | fetch('1', '(BODYSTRUCTURE)') |
ENVELOPE |
获取邮件的信封信息(解析后的头部摘要),如日期、发件人、收件人等地址信息。 | fetch('1', '(ENVELOPE)') |
INTERNALDATE |
获取邮件在服务器上的内部日期。 | fetch('1', '(INTERNALDATE)') |
RFC822.SIZE |
获取邮件的近似大小(字节数)。 | fetch('1', '(RFC822.SIZE)') |
UID |
获取邮件的唯一标识符(UID)。UID在邮箱中长期不变,即使邮件序号变化,UID也保持不变,更可靠。 | fetch('1', '(UID)') |
获取邮件内容之后,邮件解析可由标准库email完成。
7、关闭连接:
IMAP4.close() 关闭指定的mailbox。推荐在IMAP4.logout()之前使用。
IMAP4.logout() 断开服务器的连接。
可能的报错:
报错信息:imaplib.IMAP4.error: command SEARCH illegal in state AUTH, only allowed in states SELECTED
![]()
尝试:
① 使用search(...)方法前必须选择mailbox(即select()方法)。
② 使用select()方法选择了mailbax,但选择失败,失败返回信息:('NO', [b'SELECT Unsafe Login. Please contact kefu@188.com for help'])。
继续尝试:在连接和登录后,以及在选择收件箱之前,向邮箱服务器提发送ID。
IMAP4.xatom(name[, ...])
注:底层方法。可以用于向163邮箱服务器发送ID。
# 连接并登录邮箱服务器
...
# 向邮箱服务器发送ID
imap_id = ("name", "自定义name", "version", "1.0.0", "vendor", "自定义vender")
conn.xatom('ID', '("' + '" "'.join(imap_id) + '")')
# 选择收件箱
...标准库email:
官方文档:email — An email and MIME handling package — Python 3.13.7 documentation
解析邮件。邮件包括header(头部信息)和payload(有效负载或称内容)。
1、解析头部信息
- email.parser:解析器。将字节/字符串/文件对象转为EmailMessage对象树。
- 官方文档:email.parser: Parsing email messages — Python 3.13.7 documentation
-
官方文档:email.message: Representing an email message — Python 3.13.7 documentation
解析整个邮件,也可以只解析头部信息。本文以解析整个邮件(内容为字节对象)为例。
方法一:email.parser.BytesParser(...).parsebytes(...)
类 email.parser.BytesParser(_class=None, *, policy=policy.compat32)
注:默认policy为policy.compat32,可以使用默认policy(policy.default 即更国际化的邮件标准RFC5322 或6532)。
方法:parsebytes(bytes, headersonly=False)
注:bytes为字节对象。headersonly为True则只解析头部,默认为False,则解析整个邮件。
from email import policy
from email.parser import BytesParser
# 使用默认策略, msg_bytes为字节对象(邮件内容为b'...')
msg = BytesParser(policy=policy.default).parsebytes(msg_bytes)方法二:email.message_from_bytes(...)
email.message_from_bytes(s, _class=None, *, policy=policy.compat32)
注:相当于email.parser.BytesParser(...).parsebytes(...)。
import email
from email import policy
# 使用默认策略, msg_bytes为字节对象(邮件内容为b'...')
msg = email.message_from_bytes(msg_bytes, policy=policy.default)header(头部信息)包括主题、收件人、发件人等。
EmailMessage对象树中header结构类似于有序字典。使用获取字典中键对应值的方法即可。
- 获取主题:msg.get("Subject")
- 获取发件人:msg.get("From")
- 获取收件人:msg.get("To")
- 获取日期:msg.get("Date")
注:获取的日期格式:Wed, 17 Sep 2025 12:37:48 +0800 (CST)。若要转为‘年-月-日 时-分-秒’,使用标准库datetime中的strptime(...)。
from datetime import datetime
...
# 此处msg为获取的邮件(并解析为EmailMessage对象树)
date = msg.get("Date") # 返回:'Wed, 17 Sep 2025 12:37:48 +0800 (CST)'
# 转为‘年-月-日 时-分-秒’格式
new_date = datetime.strptime(date[:25], '%a, %d %b %Y %H:%M:%S').strftime('%Y-%m-%d %H:%M:%S')2、 解析邮件正文和附件
payload(有效负载或称内容)包括邮件正文和附件等。
EmailMessage对象树中节点若是multipart(例如multipart/mixed)则payload为列表形式,有子节点。若不是multipart则payload则为该节点内容,没有子节点。
① 判断是否是multipart:
EmailMessage.is_multipart()
判断payload是否是子组件列表(a list of sub-EmailMessage objects)。若是multipart,则为True。
② 遍历EmailMessage对象树中的各节点:
EmailMessage.walk()
迭代器。以深度优先的顺序遍历整个树。
③ 获取节点的内容类型content type:
EmailMessage.get_content_type()
获取EmailMessage对象(各节点)的内容类型。
| content type | 说明 |
|---|---|
| multipart/mixed | 混合内容,包含附件(如文本和图片、文档等) |
| multipart/alternative | 替代内容,同一内容的不同版本(如纯文本和HTML版本,客户端会显示的那个) |
| multipart/related | 相关内容,包含内嵌资源(如HTML正文中引用的图片) |
| text/plain | 纯文本,邮件的基本文本内容 |
| text/html | HTML格式文本 |
| application/octet-stream | 二进制数据流,附件。如Zip压缩包、可执行文件、TXT文件。 |
| application/zip | Zip压缩包,附件。 |
| application/pdf | PDF文档,附件。 |
| image/jpeg,image/png |
静态图片,JPEG或PNG格式的图片附件或内嵌图片。 |
④ 判断是否是附件:
方法一:节点中的Content-Disposition头字段值为attachment则为附件。
获取节点中的Content-Disposition头字段值(字符串类型):str(part.get("Content-Disposition"))
content_disposition = str(part.get("Content-Disposition"))
# 判断是否是附件,此处content_type为获取的节点内容类型
if content_type == "text/plain" and "attachment" not in content_disposition:
...方法二:使用is_attachment()方法(推荐)
是方法一的封装,使用更方便简洁。
# 判断是否是附件,此处content_type为获取的节点内容类型,part为节点(EmailMessage对象)
if content_type == "text/plain" and part.is_attachment():
...⑤ 获取内容
EmailMessage.get_content(*args, content_manager=None, **kw)
获取EmailMessage对象的内容(也可以获取附件内容)。
⑥ 附件
- 获取附件名:part.get_filename()
- 获取附件内容:part.get_content()
- 下载附件:使用正常的文件写入。
- 注:此处part为EmailMessage对象(各节点)。
import os
# part为EmailMessage对象(附件节点)
filename = part.get_filename() # 附件名
if filename:
file_data = part.get_content() # 附件内容
filepath = os.path.join(f'G:/', filename)
with open(filepath, "wb") as f: # 下载附件
f.write(file_data)
print(f"附件 {filename} 已保存到 {filepath}")帮助:
除了文中的官方文档。还可以使用python解释器查看类或函数的使用说明。

举例:
使用imaplib+email连接163邮箱并读取收件箱邮件(包括附件)。
import imaplib
import email
from email import policy
# from email.parser import BytesParser
from datetime import datetime
import os
def read_emails(imap_server, email_user, email_password):
'''连接并登录IMAP服务器,读取所有的未读邮件'''
try:
conn = imaplib.IMAP4_SSL(imap_server, 993) # 连接IMAP服务器
conn.login(email_user, email_password) # 登录邮箱
except Exception as e:
print("--------------------连接或登录IMAP服务器失败。")
print(e)
return
# 向邮箱服务器发送ID(自定义),否则可能报错
imap_id = ("name", "你的名字", "version", "1.0.0", "vendor", "myclient")
conn.xatom('ID', '("' + '" "'.join(imap_id) + '")')
# 选择收件箱,搜索收件箱所有未读邮件
stat, msg = conn.select() # 默认是收件箱"INBOX"
if stat != 'OK':
print(f"-----选择收件箱失败:{stat}, {msg}")
return
# status, datas = conn.search(None, "ALL") # 搜索所有邮件
status, datas = conn.search(None, "UNSEEN") # 搜索未读邮件
if status != 'OK':
print(f"-----搜索邮件失败:{status}, {datas}")
return
# 通过邮件ID获取邮件内容
email_ids = datas[0].split()
print(f"---------------------邮件数:{len(email_ids)}")
for i in email_ids: # 读取所有搜索到的未读邮件
stat, msg_data = conn.fetch(i, '(RFC822)') # 或者BODY[],自动标记为已读
# stat, msg_data = conn.fetch(i, '(BODY.PEEK[])') # 不标记为已读
if stat != 'OK':
print(f"-----获取邮件失败")
continue
# 解析邮件
email_data = parser_email(msg_data)
print('-----------------------email_data: ', email_data)
# 关闭连接
conn.close()
conn.logout()
def parser_email(msg_data):
'''解析邮件,使用字典形式返回各内容并下载附件'''
email_data = {}
# 使用默认策略,解析为EmailMessage对象树
# msg = BytesParser(policy=policy.default).parsebytes(msg_data[0][1])
msg = email.message_from_bytes(msg_data[0][1], policy=policy.default)
email_data["subject"] = msg.get("Subject") # 获取主题
email_data["from"] = msg.get("From") # 获取发件人
email_data["to"] = msg.get("To") # 获取收件人
date = msg.get("Date") # 获取日期,返回格式:'Wed, 17 Sep 2025 12:37:48 +0800 (CST)'
# 日期格式转为'年-月-日 时-分-秒'
email_data["date"] = datetime.strptime(date[:25], '%a, %d %b %Y %H:%M:%S').strftime('%Y-%m-%d %H:%M:%S')
# 解码邮件正文包括附件
attchements = [] # 存放附件信息
if msg.is_multipart():
for part in msg.walk():
content_type = part.get_content_type()
if content_type == "text/plain" and not part.is_attachment():
# email_data["body"] = part.get_payload(decode=True).decode() # 以前的方法
email_data["body"] = part.get_content()
elif content_type == "text/html" and not part.is_attachment():
email_data["body"] = part.get_content()
elif part.is_attachment():
filename = part.get_filename()
if filename:
# file_data = part.get_payload(decode=True) # 以前的方法
file_data = part.get_content()
download_attachment(filename, file_data) # 下载附件
attchements.append({'filename': filename, 'size': len(file_data)})
email_data["attachment"] = attchements
else:
email_data["body"] = msg.get_content()
return email_data
def download_attachment(filename, file_data, download_folder="./"):
'''下载邮件附件'''
filepath = os.path.join(download_folder, filename)
with open(filepath, "wb") as f:
f.write(file_data)
print(f"附件 {filename} 已保存到 {filepath}")
def main():
imap_server = "imap.163.com"
email_user = "邮箱" # 自行修改
email_password = "邮箱授权码" # 自行修改
read_emails(imap_server, email_user, email_password)
if __name__ == "__main__":
main()
腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)