论文笔记:SimpleVLA-RL: Scaling VLA Training viaReinforcement Learning
SimpleVLA-RL一个具身智能训练框架
论文连接:https://arxiv.org/pdf/2509.09674
github: https://github.com/PRIME-RL/SimpleVLA-RL
参考介绍文章:https://mp.weixin.qq.com/s/oMiwVh2gKSO58DYE3QpKvA?poc_token=HMD2x2ijXMo8NhmAdD3SrZruFHgiXIiPsnO2MNlj
SimpleVLA-RL一个专为 VLA 模型量身定制的高效 RL 框架,基于veRL构建,引入了 VLA 特定的轨迹采样、可扩展并行化、多环境渲染和优化的损失计算。
应用在OpenVLA-OFT(使用正交微调技术构建的开源视觉语言动作模型)上,表现超过Pi0(RoboTwin 1.0&2.0),不仅减少了对于大规模数据的依赖,也表现出更稳健的泛化性能,在真实世界任务中的表现也显著超过了SFT。
在强化学习训练过程中还发现了一个新奇的现象“Pushcut”(我理解是机器人的行为突破已有的行为边界),策略发现了原有训练过程没有见过的模式。
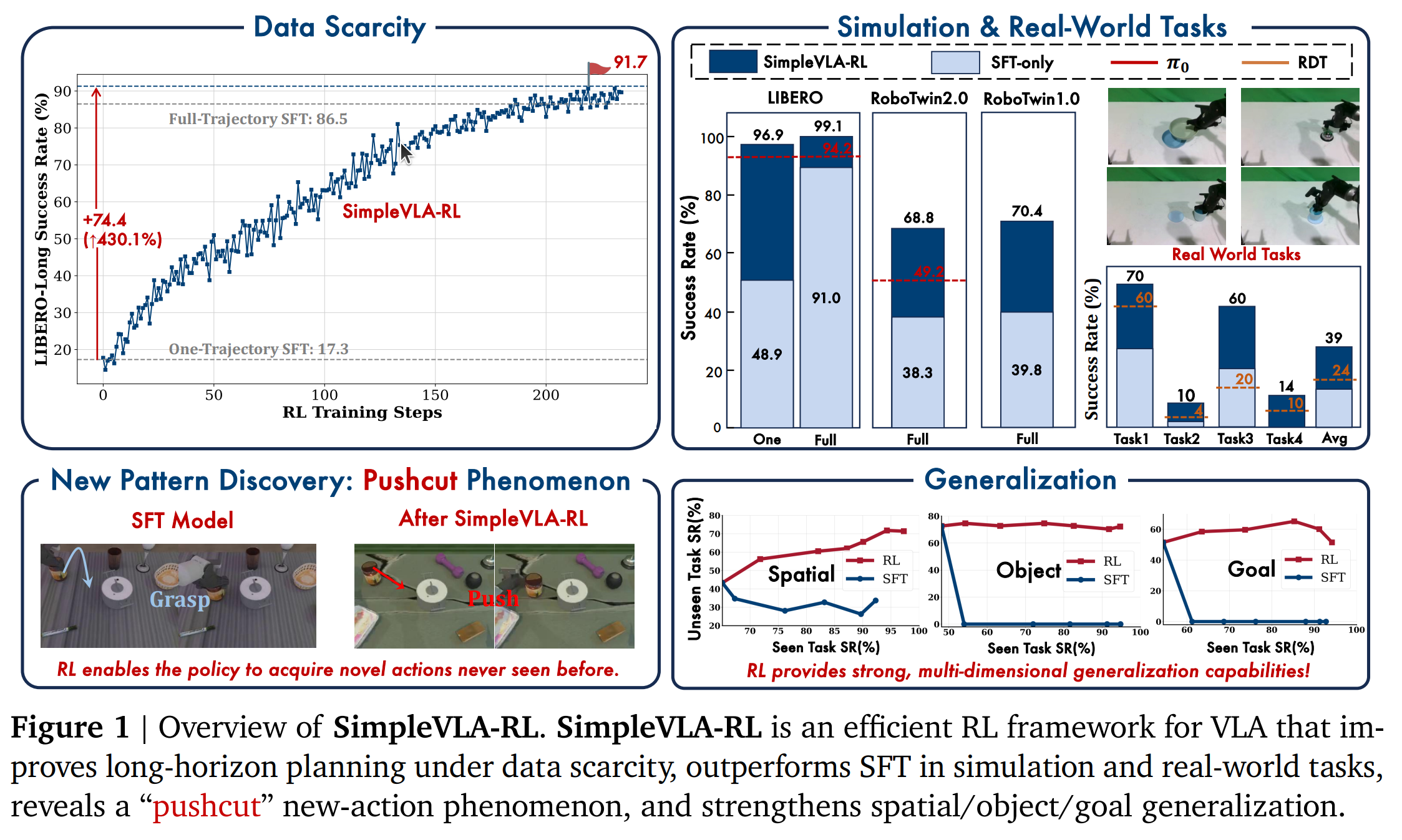
对于论文中提到的“Pushcut”下面这张小图应该可以帮助理解:

比如训练数据都是把物体O从A点抓取再放置到B点,但是模型学会了新的没有见过的行为方式就是把物体O 从A点推到B点。
作为一个研究具身智能算法从业的人读到这篇论文,看到模型的这个行为突破也甚是觉得有趣和鼓舞。
目前VLA+SFT存在的两个挑战:
1.数据稀疏性
2.泛化性能弱
下面要介绍论文里提到的公式,因为我本身就研究强化学习,所以先简单介绍一下强化学习的原理
强化学习的核心思想:一个智能体(Agent)在一个环境(Environment)中通过尝试不同的动作(Action),根据环境反馈的奖励(Reward)来学习一套最佳策略(Policy),以最大化长期累积奖励。
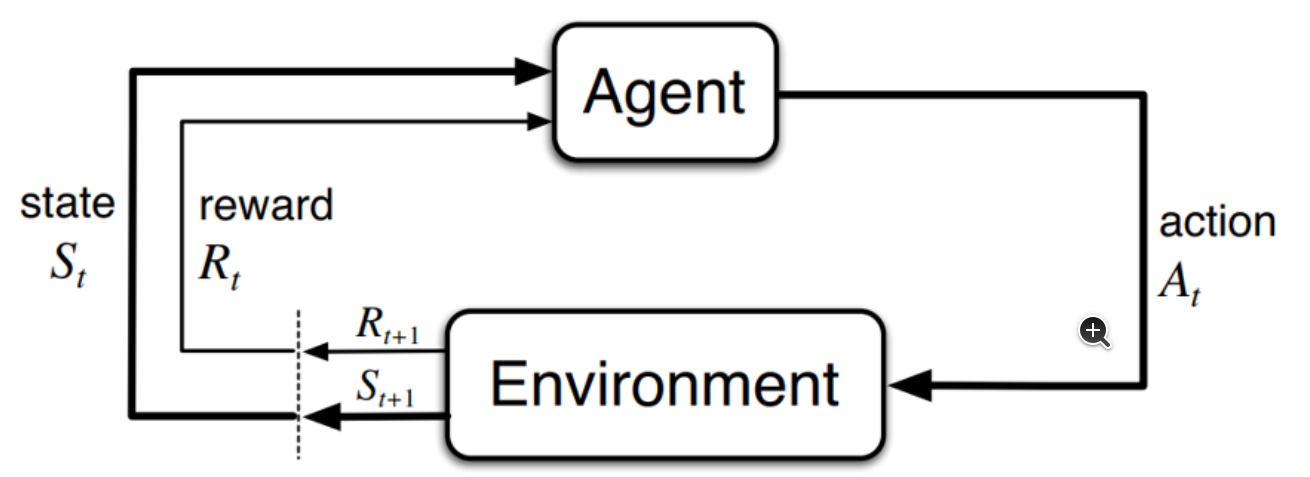
强化学习里面最核心和重要的公式 贝尔曼方程,请自行查阅。
以下是论文中用到的公式
RL 用于llms的公式:
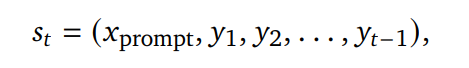
St: t时间步的状态,强化学习的核心概念State
xprompt: 最初给的prompt
yi: t生成的token,我理解是将action token化生成的token
分析了一下以上公式,个人理解用人话说就是t-step的状态由最初的prompt任务指导,和t-step之前每一步的action决定。
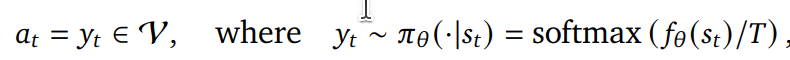
at: t时间步的动作 action,强化学习中一个重要的概念
![]() 为LLm的原始输出,大概是LLM模型计算后每一个输出的原始分数(有更好的理解请指正)
为LLm的原始输出,大概是LLM模型计算后每一个输出的原始分数(有更好的理解请指正)
V:yi token的集合
T: 温度参数
个人理解at由![]() 策略决定,策略的结果由当前的状态和温度参数决定,这倒是强化学习的思路
策略决定,策略的结果由当前的状态和温度参数决定,这倒是强化学习的思路

奖励函数
r: reward 奖励,强化学习中一个重要的概念
![]() : 一组轨迹
: 一组轨迹
![]() :学习到的奖励模型
:学习到的奖励模型
RL用于VLAs的公式:
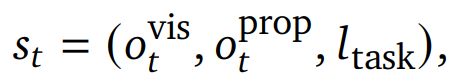
St: state 环境状态
右边三个变量分别是 t-step的视觉观测、本体感知信息(关节角、末端位姿、抓夹状态)、该任务的语言指导/指令

at: action t-step的动作,由6D位姿和抓夹状态组成
Decoder: 动作解码器
![]() : St在VLA模型中的隐藏状态
: St在VLA模型中的隐藏状态
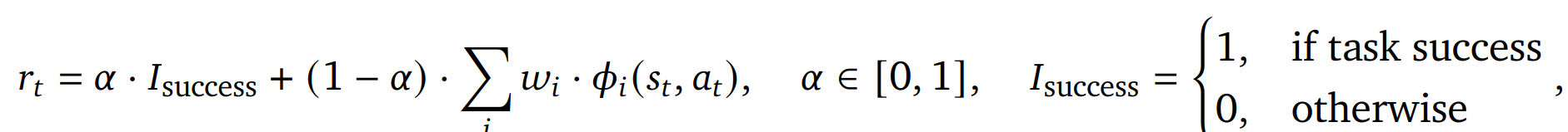
奖励函数
rt: 累计奖励
![]() : 过程中的奖励(例如到目标的距离)
: 过程中的奖励(例如到目标的距离)
![]() :调整最终奖励和过程中奖励比例的参数
:调整最终奖励和过程中奖励比例的参数
Isuccess: 最终成功或者失败
Wi: 权重参数,这个应该是模型自己学习到的
总的来说奖励分两部分一部分是最终的成功还是失败,另一部分是过程中的奖励
实际运行过程
当前状态St作为输入给到策略![]() ,生成一组长度为k的动作块序列(𝑎𝑡 , 𝑎𝑡+1, . . . , 𝑎𝑡+𝑘−1),执行完这一组动作之后,再将当前状态St+k输入给策略
,生成一组长度为k的动作块序列(𝑎𝑡 , 𝑎𝑡+1, . . . , 𝑎𝑡+𝑘−1),执行完这一组动作之后,再将当前状态St+k输入给策略![]() ,继续生成下一组动作块,直到完成任务或者设置的最大步长,通过交互生成一组完整的轨迹𝜏 = ( (𝑠0, 𝑎0), (𝑠1, 𝑎1), . . . , (𝑠𝑇 , 𝑎𝑇 ))
,继续生成下一组动作块,直到完成任务或者设置的最大步长,通过交互生成一组完整的轨迹𝜏 = ( (𝑠0, 𝑎0), (𝑠1, 𝑎1), . . . , (𝑠𝑇 , 𝑎𝑇 ))
分组相对策略优化Group Relative Policy Optimization (GRPO)
对于GRPO算法的介绍参考:https://www.jianshu.com/p/be855a10abe8
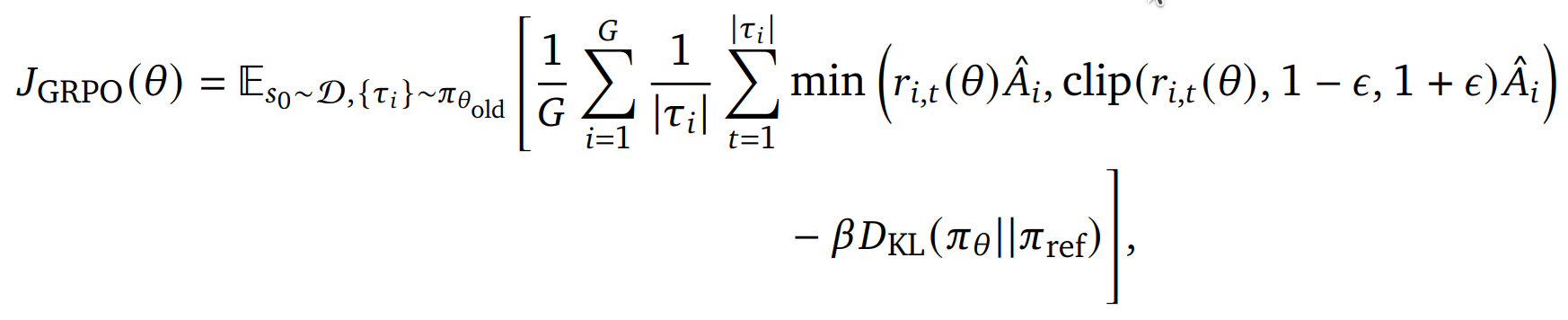
S0: 初始状态
![]() :行为策略
:行为策略
![]() : 通过行为策略生成的轨迹
: 通过行为策略生成的轨迹
clip函数限制更新幅度,防止策略突变
![]() : 新旧策略概率比,定义如下
: 新旧策略概率比,定义如下
![]() :标准化优势函数,定义如下
:标准化优势函数,定义如下
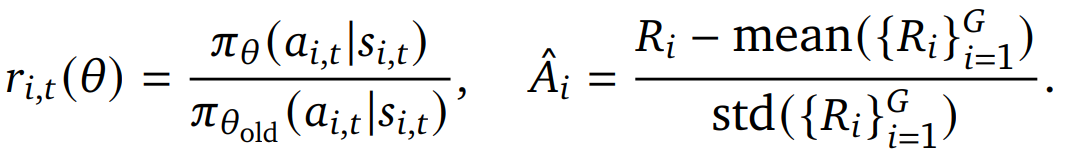
𝑅i: 第i个轨迹的整体奖励
𝜖 > 0 是PPO算法的裁剪参数,用于限制策略比例的变化幅度
𝛽 > 0 是控制相对于参考策略𝜋ref的KL正则化强度的系数
SFT与SimpleVLA-RL训练框架的对比:
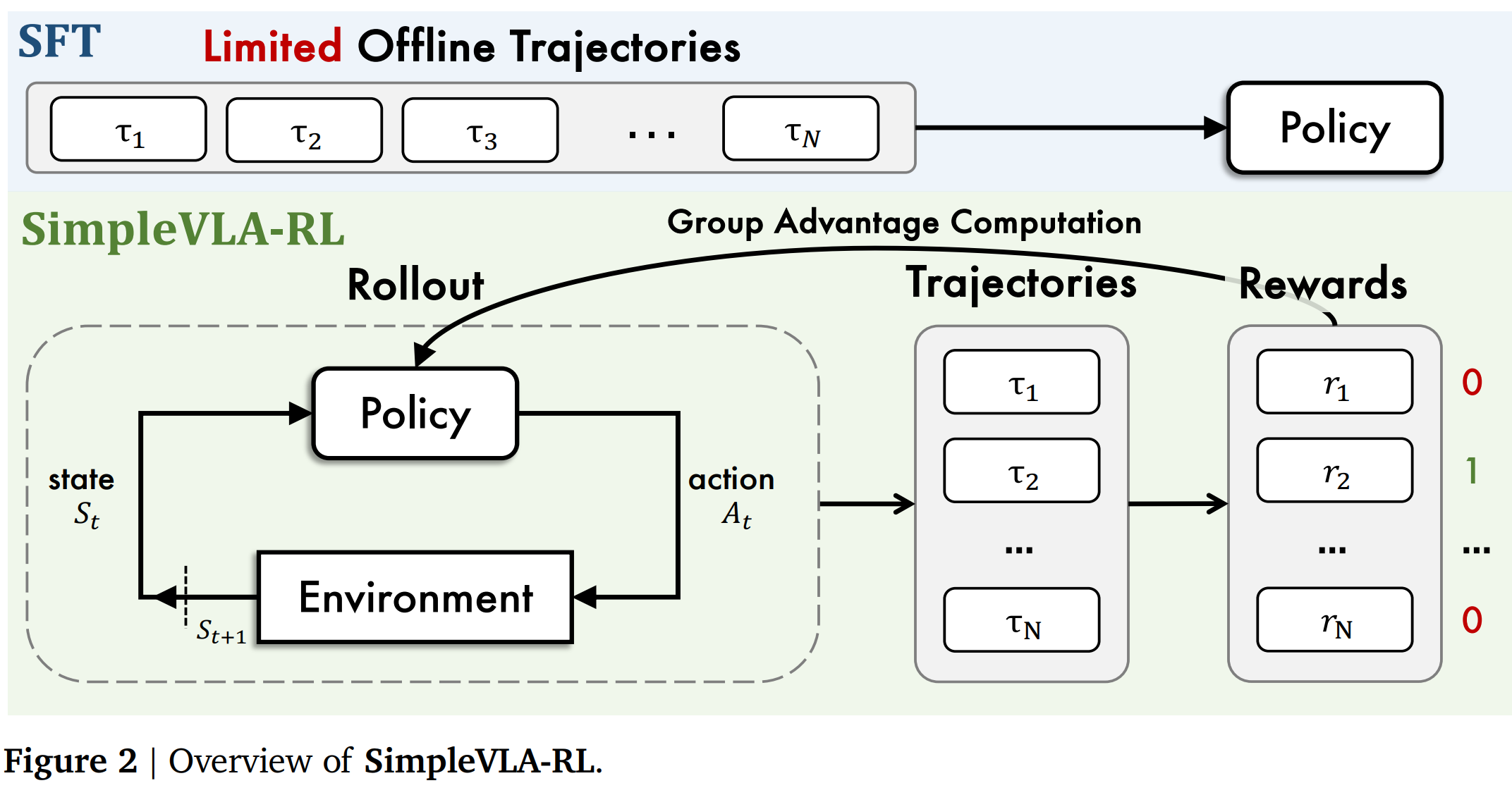
可以看到是在策略更新这一步用到了GRPO
SimpleVLA-RL
该研究将这套基于规则的在线强化学习框架扩展至视觉-语言-动作(VLA)模型,用于实现具身操纵任务(如图2所示)。具体而言,训练框架按以下流程推进:首先通过随机采样为每个输入生成多条轨迹;随后根据环境反馈为每条轨迹分配简单的结果奖励(成功为1,失败为0);最后结合这些奖励与相应的动作标记概率,计算GRPO损失以更新策略模型。
为了实现在线强化学习,策略模型需要从同一个输入生成多样化的轨迹,以提高探索效率。
VLA与LLM不同,需要面临一个独特的关于action行为解码策略的挑战。
目前的VLA模型通常使用三种策略:
1.生成类似于LLM的行为token分布;
2.基于扩散的潜在状态去噪;
3.通过多层感知机的确定性回归。
这里采用的是第一种策略。
结果奖励建模
当VLA模型成功完成一项任务时,整个轨迹被分配奖励值1;否则,奖励值为0。为了进行梯度计算,这些轨迹级别的奖励被均匀地传播到各个动作令牌(token)。因此,成功轨迹中的所有令牌都被分配奖励值1,而不成功轨迹中的所有令牌则被分配奖励值0。
看到这里我有一个疑问,强化学习是计算累计奖励,如果只要成功那么每一步的Token都给到奖励值为1,那么是否会鼓励模型一个可以用简单轨迹完成的动作,选择更复杂的轨迹去完成。应该是整个轨迹的奖励是1,把这个奖励1再均分到每一步,这样高效完成任务的轨迹每一步的奖励更高。
探索增强
为了增加强化学习的探索采用了以下三个关键改进:
1.在轨迹采样期间采用动态采样;
2. 调整 GRPO 训练目标中的裁剪范围;
3. 在采样期间提高采样温度.
动态采样解决梯度消失的问题,在采样过程中,我们会排除所有轨迹均成功或均失败的组。采样会持续进行,直到批次中仅包含具有混合结果的组。。
增大裁剪范围:PPO 和 GRPO 均采用重要性采样比率裁剪技术,旨在限制信任区域并增强强化学习的稳定性。然而,上界裁剪阈值会限制低概率标记的概率提升,从而可能制约探索能力。遵循 DAPO 的方法,我们将 GRPO 训练目标中的裁剪范围从 [0.8, 1.2] 调整为 [0.8, 1.28]。
更高的采样温度:近期关于大语言模型(LLM)强化学习(RL)调整采样温度以促进探索的研究已被广泛证明是有效的,尤其是在较高温度下采样带来了显著的改进。为了鼓励视觉-语言-动作(VLA)模型在采样阶段生成更多样化的轨迹,我们将采样温度从1.0提高到1.6。这些修改带来了显著的改进。
Training Objective
使用上面介绍的改进后的GRPO算法对VLA模型进行在线强化学习(RL)训练。此外参考DAPO移除了KL散度正则化。消除了训练过程中对参考模型的需求,降低了内存消耗并加速了训练。KL惩罚会限制策略偏离固定参考模型,可能限制新行为的探索。策略通过以下目标进行优化:
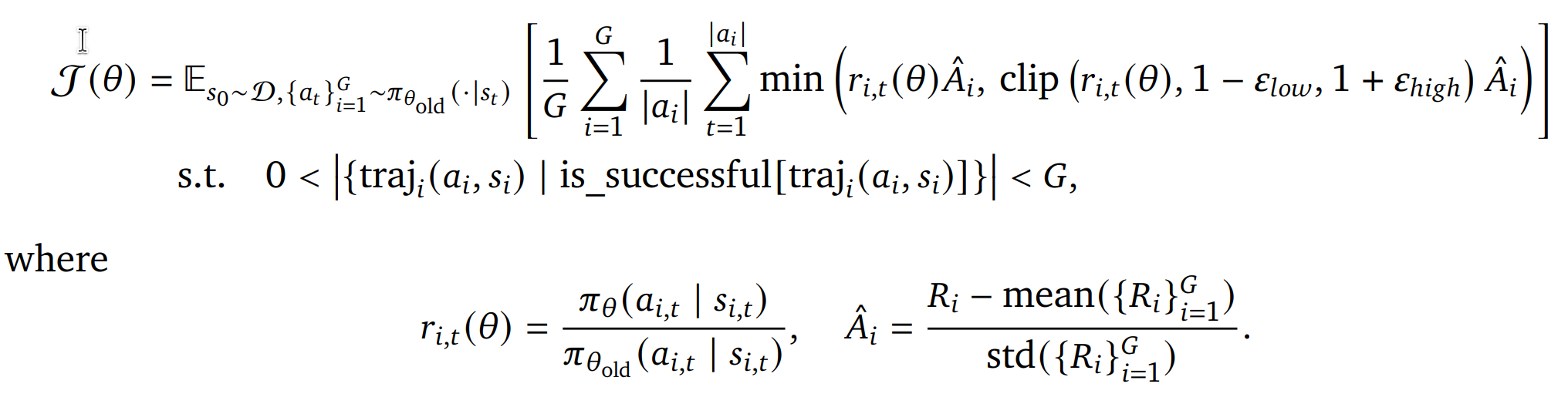
论文笔记是为了帮助自己更仔细和深入的理解论文的内容,以及记录自己读论文时的一些想法和粗浅的见解,如果大家看到发现理解有出入请指正,欢迎同行互相交流见解。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)