python爬虫实战:一键爬取携程景点评论,讲解完整源代码
·
前言:
你是否想一键获取某携程景点下的评论,收集完之后可以去分析,可以去阅读?
这就来了,我用Python 写了一个携程景点评论爬虫。
我把完整代码放公重浩里了,名称与此号同名哈,有需要可以自取。
话不多说,直接开干!
一:运行结果图(数据)
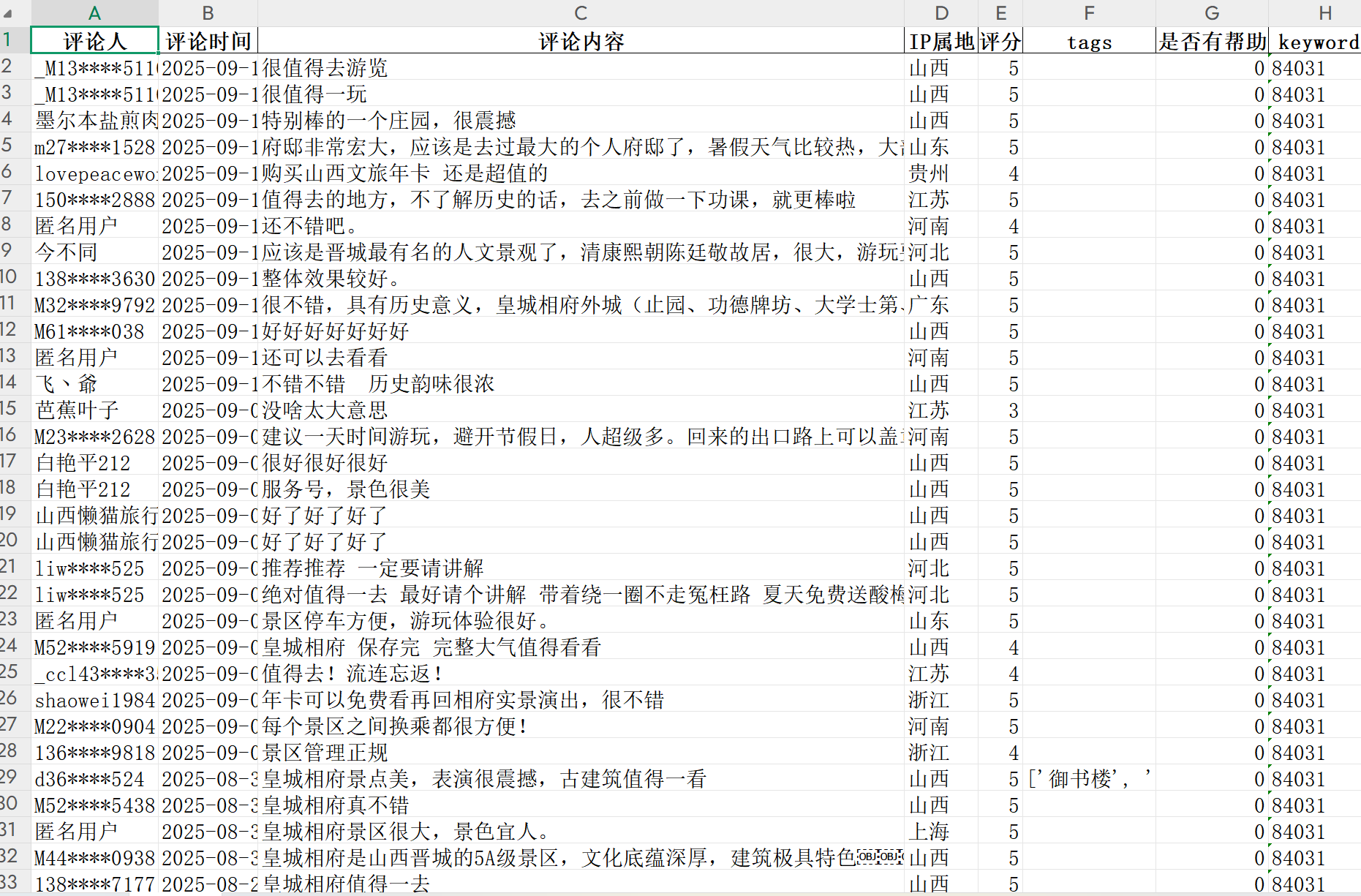
最终的数据结果如图所示,字段详细,内容完整。
二:代码详解
1. 模块导入与初始化
import requests
import pandas as pd
import time
lst = []
ids = ['84031','78481','83868']- 作用:
- 导入网络请求库
requests用于数据获取 - 导入数据处理库
pandas用于数据存储 - 导入
time模块控制请求频率 - 初始化空列表
lst存储评论数据 - 定义景点ID列表,每个ID对应一个目标景点,可以同时爬取多个景点。
- 导入网络请求库
2. 请求头与参数配置
cookies = { ... }
headers = { ... }
params = { ... }
- 作用:
- 设置浏览器指纹信息(Cookies/User-Agent等)
- 模拟真实浏览器访问行为
- 添加必要的API请求参数
- 防止被目标网站反爬机制识别为机器人
3. 分页请求核心逻辑
for id in ids: # 遍历景点
for page in range(1,35): # 分页控制(1-34页)
json_data = {
'arg': {
'channelType': 2,
'collapseType': 0,
'commentTagId': 0,
'pageIndex':page,
'pageSize': 10,
'poiId': id,
'sourceType': 3,
'sortType': 1,
'starType': 0,
},
'head': {
'cid': '09031025312449459187',
'ctok': '',
'cver': '1.0',
'lang': '01',
'sid': '8888',
'syscode': '09',
'auth': '',
'xsid': '',
'extension': [],
},
} # 构造请求体
response = requests.post(
'https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList',
params=params,
# cookies=cookies,
headers=headers,
json=json_data,
) # 发送POST请求
time.sleep(2) # 请求间隔
- 作用:
- 双层循环结构:外层遍历景点,内层遍历评论分页
- 动态构造包含分页参数的JSON请求体
- 使用POST方法请求携程评论接口
- 设置2秒请求间隔避免触发反爬机制
4. 数据解析与提取
try:
sj = response.json()['result']['items'] # 解析JSON响应
for i in sj: # 遍历单页评论
dic={}
try:
dic['评论人'] = i.get("userInfo").get("userNick")
except:
dic['评论人'] = '匿名'
dic['评论时间'] = i.get("publishTypeTag").split(' ')[0]
dic['评论内容'] = i.get("content")
print(i.get("content"))
dic['IP属地'] = i.get("ipLocatedName")
dic['评分'] = i.get("score")
dic['tags'] = i.get("recommendItems")
dic['是否有帮助'] = i.get("usefulCount")
dic['keywords'] = id
lst.append(dic) # 存入列表
- 作用:
- 解析API返回的JSON格式评论数据
- 提取8个关键字段构建结构化数据
- 异常处理保证字段缺失时程序不中断
- 将每条评论转为字典格式存入列表
5. 数据存储与输出
df = pd.DataFrame(lst) # 转为数据框
df.to_excel('data.xlsx',index=None)
- 作用:
- 将列表数据转换为pandas DataFrame
- 导出为Excel文件(含中文文件名)
- 不保留索引列保证数据整洁
整体流程说明
- 初始化配置:设置爬虫基础环境
- 模拟登录:通过请求头伪装浏览器
- 分页抓取:按景点+页码双重遍历
- 数据解析:提取结构化评论信息
- 持久化存储:导出为Excel文件
- 反爬处理:请求间隔+异常捕获机制
三:景点ID如何获取
比如说我们爬取东方明珠的景点评论。

首先:打开开发者工具,点击网络。接着拉到最下边评论,点击下一页,我们会发现出来了许多接口。
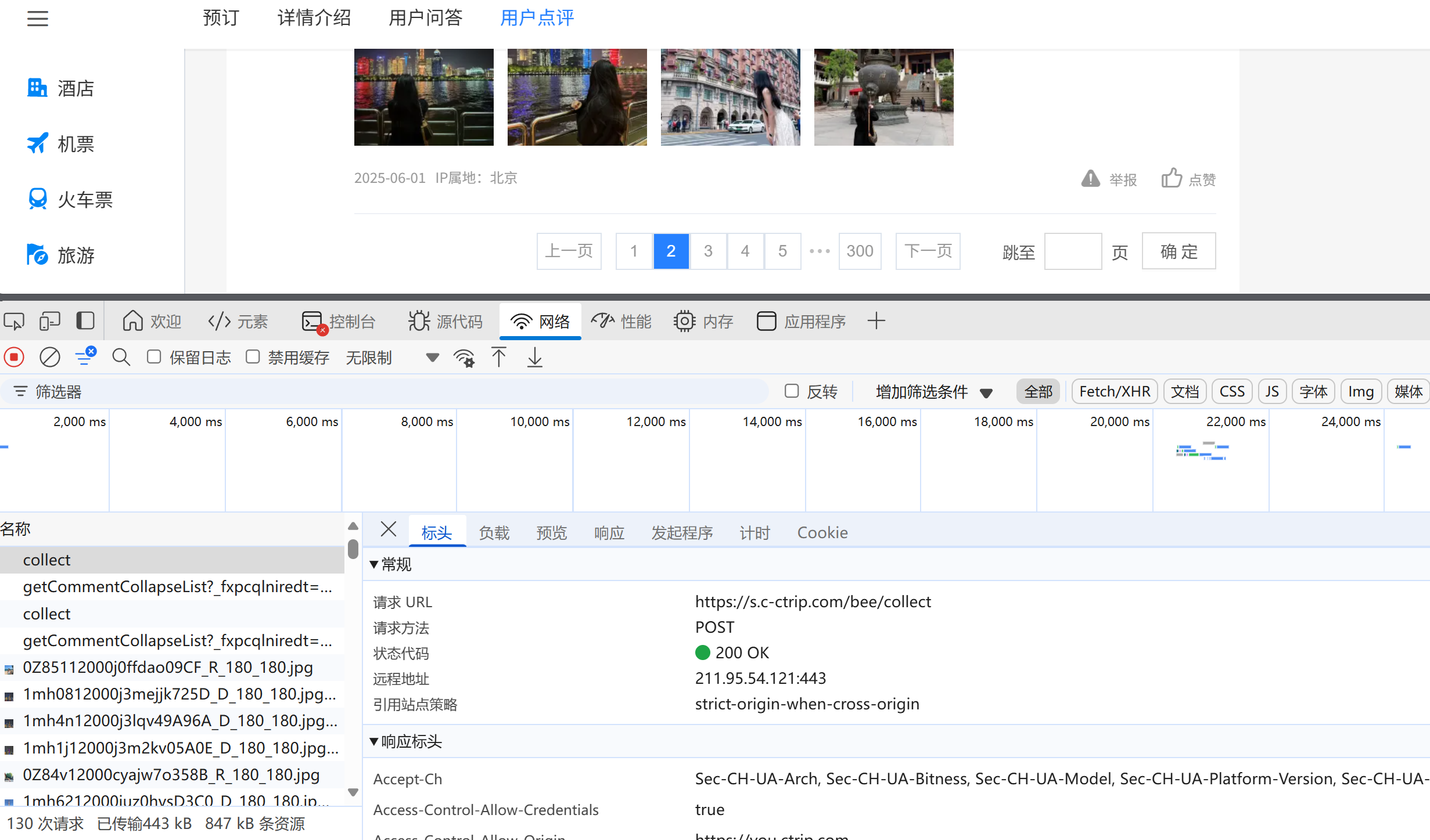
找到getComment...这个接口,点击进去,我们需要的是这个poiID后边的参数,这个就代表东方明珠了。
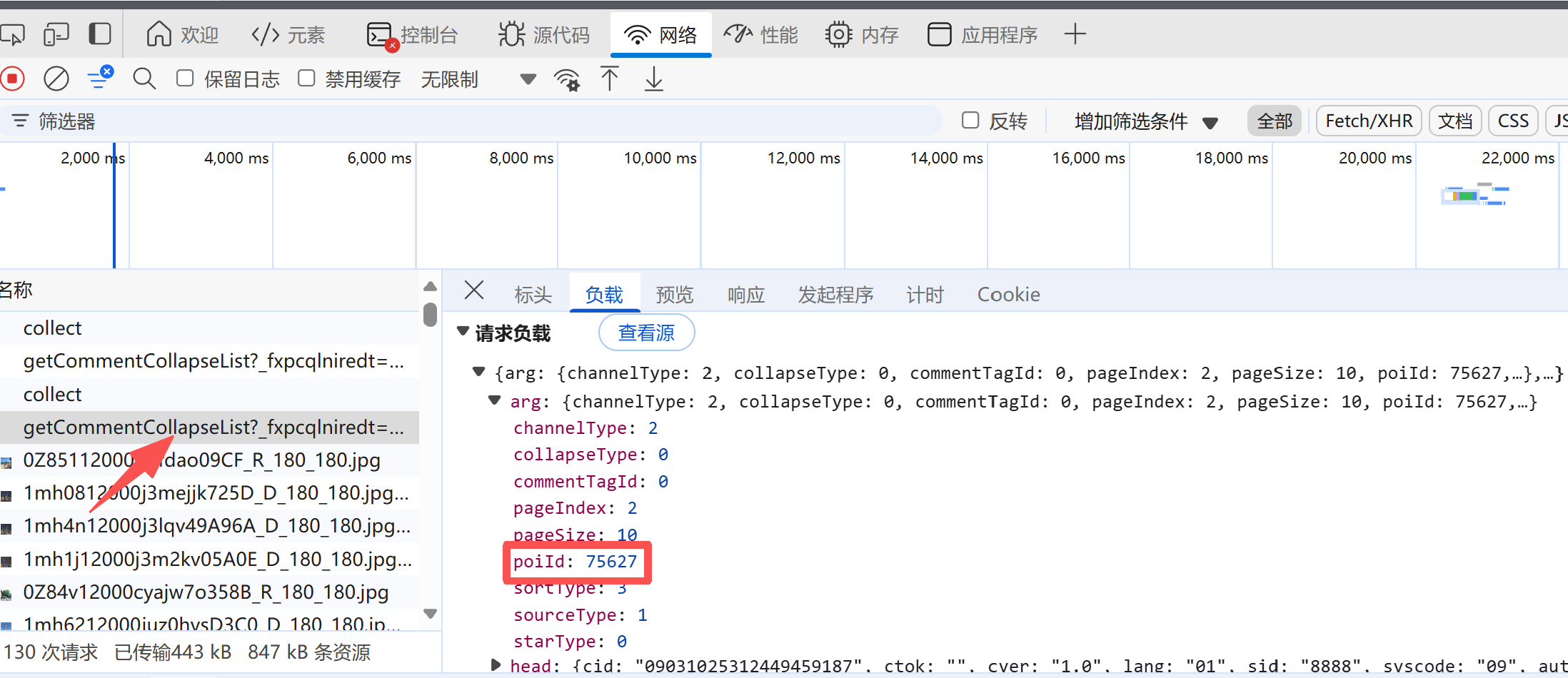
接着把此ID填入代码里即可运行。
注意这个只能爬取网页版可见的3000条,若想要爬取全部的评论数据,就需要app相关的进一步的爬虫了。
谢谢大家观看。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)