基于Python+Django的毕业设计-图书馆大数据可视化分析系统项目实战(附源码+论文)
大家好!我是岛上程序猿,感谢您阅读本文,欢迎一键三连哦。
精彩专栏推荐👇🏻👇🏻👇🏻
开发环境
开发语言:Python
框架:django
Python版本:python3.7.7
数据库:mysql 5.7
数据库工具:Navicat11
开发软件:PyCharm
浏览器:谷歌浏览器
演示视频
python002图书馆大数据可视化分析系统演示
论文目录
【如需全文请按文末获取联系】


一、项目简介
(1)用户可以在不登录的情况下访问本系统,但是不能进行图书的借阅或管理,也不能对自己的个人信息进行修改。
(2)用户的注册与登录:游客想要在一个网站对自己的信息进行修改的话,需要经过一系列的有验证信息的注册,成为网站的正式用户后,可以编辑或修改自己的个人信息。
(3)图书搜索:用户可以在网站内对图书信息进行搜索。
(4)图书列表:通过图书列表功能可以浏览网站内的所有图书信息,除了显示图书的作者、分类等信息外还可以进行图书的编辑和借阅。
(5)图书编辑:用户可以在网站上编辑本系统内的图书。
(6)用户信息管理:管理员可以查看和维护网站内所有的用户信息,可以通过用户的编号或者用户名进行查找,查找到具体的用户后可以对用户的信息进行修改,也可以直接删除用户的信息。
(7)借书模块:用户可以在图书列表的最后一列进行图书的借阅,提交借书请求后数据库中会增加一条借阅数据。
(8)还书模块:用户可以在网站内将自己借阅的书进行归还。
二、系统设计
2.1软件功能模块设计
经过对各大图书网站(如当当、京东)及生活中对图书馆的研究,我认为基于PYTHON的图书馆分析系统应具有以下几个功能:
(1)网站的页面美观清晰系统的操作流畅便捷。
(2)买家具有查看网站内的图书详情信息的功能。
(3)具有图书对应视频与图片观看、视频与图片下载的功能。
(4)具有在网站中对书籍进行借阅和归还的功能。
(5)具有图书推荐功能。
(6)具有修改自己个人信息的功能。
(7)具有后台管理功能,方便管理员对网站中的图书和借阅信息进行管理。
2.2数据库设计
管理员信息属性有:管理员的账户名、密码以及编号。如下图所示。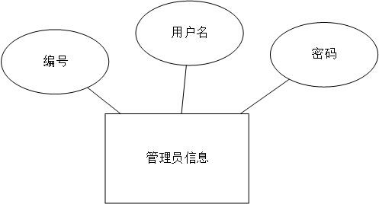
用户实体的属性包括:用户ID,用户真实姓名,用户性别,用户年龄,用户手机号码,用户邮箱,用户家庭地址,用户真实的身份证号等。具体如下图所示。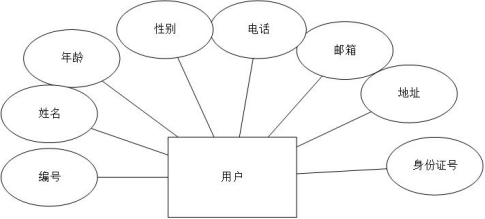
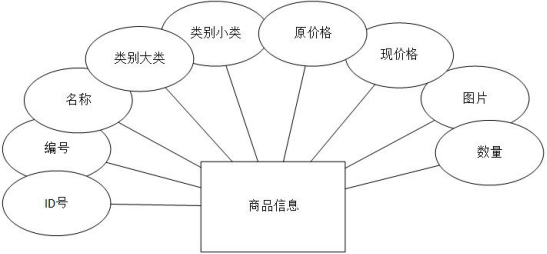
图书实体在这里有两大类,分别是图书信息和图书类别,图书类别的属性包括:分类编号,类别大类,类别小类。图书信息的属性包括:ID号,编号,名称,类别大类,类别小类,原价格,现价格,图片,数量等。具体如下图所示。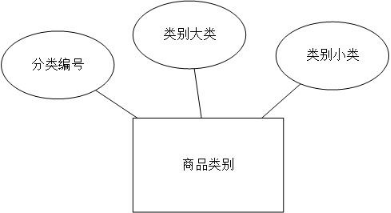
三、系统项目部分截图
3.1图书馆分析系统
本系统是可以允许匿名浏览的,但是在拥有自己的账户之前是不能解锁所有功能的。不管是网站的用户们还是管理员们都要先进行注册,只有注册完成之后才能进行登录。首界面如图所示。
3.2图书列表及查询
(2)用户登录进系统之后可以进行图书列表浏览功能,图书列表中可以查看图书的名称及作者等信息,还能进行图书信息的编辑以及借书等功能。界面如图所示。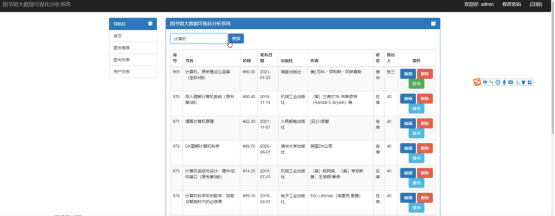
3.3图书推荐功能
用户可以在下拉列表中选择书籍方向,还可以输入具体的需求进行提交,提交后系统即可进行图书的推荐。界面如图所示。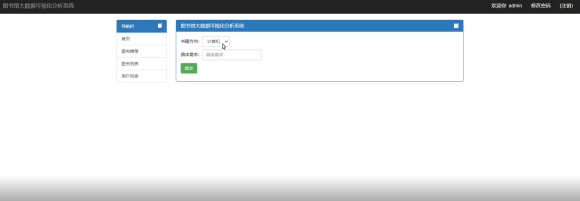
3.4还书功能
如果自己的帐号有过借书记录,在浏览图书信息时最好一列就会显示还书按钮,点击还书之后即可恢复书籍状态。界面如图所示。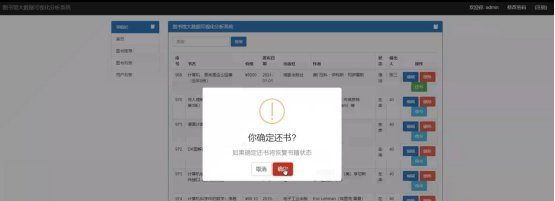
四、部分核心代码
# encoding=utf-8
import requests
import pymysql
import re
import chardet
from lxml import etree
import os
from bs4 import BeautifulSoup
# BeautifulSoup 是HTML解析库
def get_onepage(page):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'}
url = 'http://search.dangdang.com/?key=%D0%C4%C0%ED%D1%A7&act=input&page_index=' + str(page)
res = requests.get(url, headers=headers)
print(url)
res.encoding = chardet.detect(res.content)['encoding'] # 自动编码
return res.text
def parse_onepage(html):
result = etree.HTML(html)
# 解析到数组
x = 1
arr = [[] for i in range(6)]
while (result.xpath('string(//ul[@class="bigimg"]/li[$s])', s=x)):
x += 1
for i in range(1, x):
arr[0].append(result.xpath('string(//ul[@class="bigimg"]/li[$s]/p[@class="name"]/a)', s=i)) # 标题
arr[1].append(result.xpath('string(//ul[@class="bigimg"]/li[$s]/p[@class="price"]/span)', s=i)) # 现价
arr[2].append(
result.xpath('string(//ul[@class="bigimg"]/li[$s]/p[@class="search_book_author"]/span[1])', s=i)) # 作者
arr[3].append(
result.xpath('string(//ul[@class="bigimg"]/li[$s]/p[@class="search_book_author"]/span[2])', s=i)) # 出版时间
arr[4].append(
result.xpath('string(//ul[@class="bigimg"]/li[$s]/p[@class="search_book_author"]/span[3])', s=i)) # 出版社
# 处理图片链接
img_line = str(result.xpath('string(//ul[@class="bigimg"]/li[$s]/a/img/@src)', s=i))
img_comp = "http"
img_flg = re.compile(img_comp, re.S)
result_img = img_flg.findall(img_line)
if result_img:
arr[5].append(result.xpath('string(//ul[@class="bigimg"]/li[$s]/a/img/@src)', s=i))
else:
arr[5].append(result.xpath('string(//ul[@class="bigimg"]/li[$s]/a/img/@data-original)', s=i))
# 数据清理
for i in range(len(arr[3])): # 去除出版时间前的"/"
arr[3][i] = arr[3][i].lstrip(' /')
for i in range(len(arr[4])): # 去除出版社前的"/"
arr[4][i] = arr[4][i].lstrip(' /')
# 封装到字典
item = {}
item['b1'] = arr[0]
item['b2'] = arr[1]
item['b3'] = arr[2]
item['b4'] = arr[3]
item['b5'] = arr[4]
item['b6'] = arr[5]
return item
def write_toMysql(item_z):
#con = pymysql.connect(host='localhost', user='root', passwd='123456', db='dangdang_book', charset='utf8')
#cur = con.cursor()
print(item_z)
for i in range(len(item_z['b1'])):
title = item_z['b1'][i]
price = item_z['b2'][i]
author = item_z['b3'][i]
date = item_z['b4'][i]
company = item_z['b5'][i]
sql_t = "insert into books values(null,%s,%s,%s,%s,%s)"
parm_t = (title, price, author, date, company)
print(parm_t)
def save_img(img_list, page):
# 清洗书名,用以为图片命名:
# 如果有“:”则分开,若没有则按空格分开
img_arr = []
for imagename_i in range(0, len(img_list['b6'])):
imgname_org = img_list['b1'][imagename_i]
imgname_comp = ":"
imgname_maohao = re.compile(imgname_comp, re.S)
imgname_maohao_res = imgname_maohao.findall(imgname_org) # 此时有冒号的被分开
if imgname_maohao_res: # 名字中有“:”
imgname_split = imgname_org.split(":")
else: # 按空格分开
imgname_split = imgname_org.split()
imgname_res = imgname_split[0] # 选取截取后的名字存入数组
img_arr.append(imgname_res)
# 下载到本地文件夹
folder_path = os.path.join(os.path.dirname(os.path.dirname(__file__)),'static','images')
for image_flg in range(0, len(img_list['b6'])):
image_path = folder_path + str(page) + "." + str(image_flg + 1) + "-" + img_arr[image_flg] + ".png"
image_url = requests.get(img_list['b6'][image_flg])
image_url.raise_for_status()
with open(image_path, 'wb') as fd:
fd.write(image_url.content)
fd.close()
def main(page):
# 获取单页HTML
print('第一步')
html = get_onepage(page)
print('第二步:解析html')
item_z = parse_onepage(html)
print('第三步:写进数据库mysql')
write_toMysql(item_z)
# 存储图片到本地
save_img(item_z, page)
if __name__ == '__main__':
for i in range(1, 11): # 分页,爬取前十页的信息
main(i)
获取源码或论文
如需对应的论文或源码,以及其他定制需求,也可以下方微信联系我。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)