脉冲神经网络的无监督学习规则
训练数据没有人工标注的标签,因此它能够不依赖标签,从这些数据中自动发现规律,结构或模式。,而不仅仅是局部的神经元或突触,因此需要网络中多个部分的信息协同运作,常常依赖优化目标,例如K-means聚类,主成分分析(PCA)。该算法嵌入每一个神经元中,通过神经元的输入和实际输出来修改突触权重,更符合生物神经系统的机制,例如Hebbian学习,STDP。Hebbian学习是最经典的神经网络学习规则之一,
无监督学习
无监督学习指在输入的无标签数据集中尝试确定其结构的问题,是一类机器学习方法,训练数据没有人工标注的标签,因此它能够不依赖标签,从这些数据中自动发现规律,结构或模式。无监督学习方法可通过学习发生的位置或依赖范围分成全局学习算法和局部学习算法。
全局学习算法
权重更新或学习过程中依赖于整个网络的全局信息,而不仅仅是局部的神经元或突触,因此需要网络中多个部分的信息协同运作,常常依赖优化目标,例如K-means聚类,主成分分析(PCA)。
局部学习算法
该算法嵌入每一个神经元中,通过神经元的输入和实际输出来修改突触权重,更符合生物神经系统的机制,例如Hebbian学习,STDP。
无监督学习规则
无监督学习规则是指没有外部标签的情况下,网络内部根据输入数据的统计特性和神经元的局部活动,自动调整权重(或连接强度) 的方法或机制。常见的无监督学习规则有Hebbian学习规则,STDP。
Hebbian学习规则
Hebbian学习是最经典的神经网络学习规则之一,其核心思想是如果神经元A在激活时经常引起另一个神经元B的激活,那么AB之间的突触连接就会加强
:权重的变化;
:学习率;
:输入神经元的激活值;
:输出神经元的激活值;
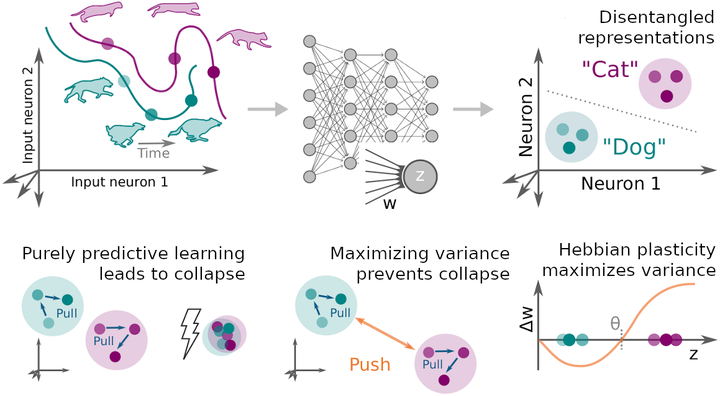
Hebbian学习规则通过强化相关活动、弱化无关活动,使得神经网络在表征上避免坍缩、保持方差,从而自动区分不同类别。
STDP学习规则
STDP 是 Hebbian 学习的时间版,Hebbian学习关心神经是否同时激活,而STDP关心激活的时间先后顺序。即如果前突触神经元 的脉冲比 后突触神经元 提前一点(几毫秒内)则权重 增强(长时程增强,LTP);如果 后突触神经元 先激活,然后前突触才激活 则权重 减弱(长时程抑制,LTD)。
:增强/抑制的幅度
:时间常数
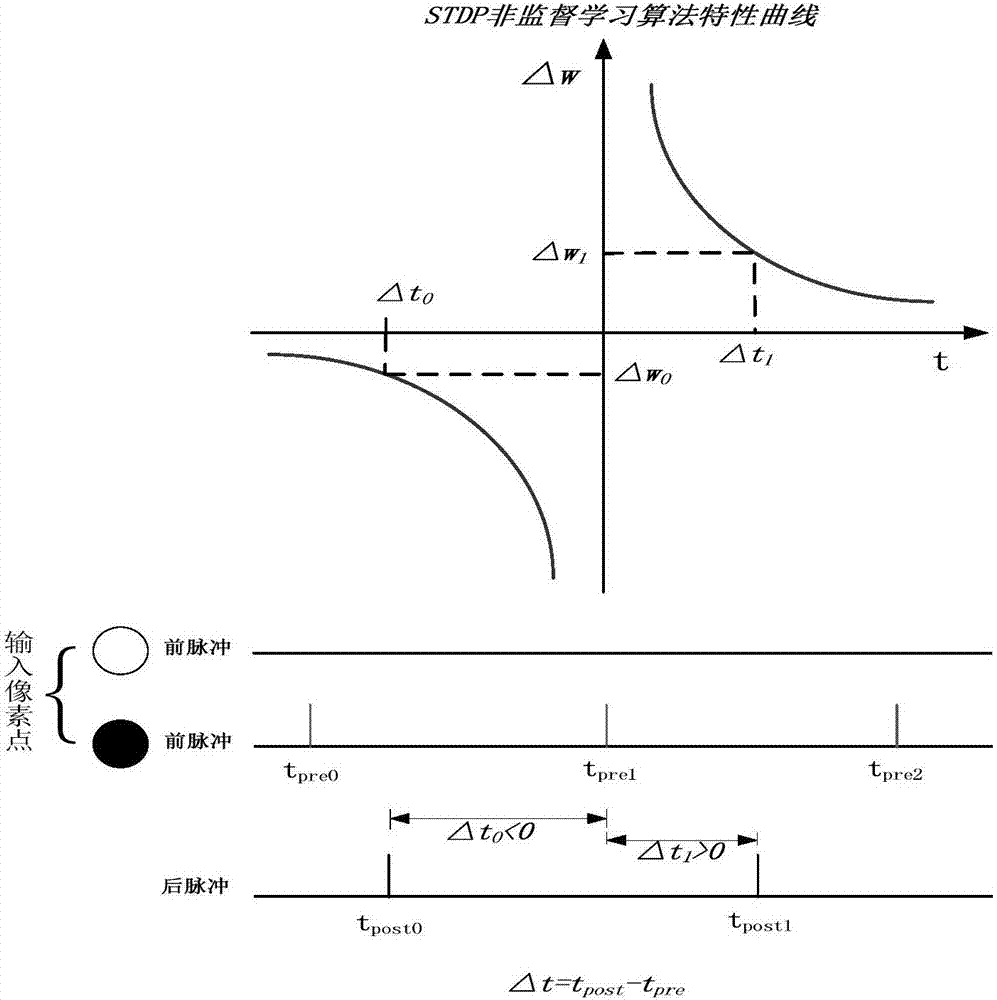
该图示 STDP 学习规则根据前后脉冲的时序差来调整突触:前先后随则增强,后先前随则抑制,效果随时间差指数衰减。
代码实践
利用无监督脉冲神经网络 + STDP 学习机制进行范例代码实践:
1.数据准备
MNIST数据集:28x28的灰度手写数字图像;将[0,255]的像素值转成[0,1]的浮点数(transform.ToTensor()),方便计算;设置了只取前部分的样本(Subset),没有跑全部,为了训练更快;且在训练时打乱顺序,测试时保持顺序(DataLoader)
Poisson编码:将像素值转为脉冲流,与传统的ANN不同点在于输入的不再是固定值而是随时间演化的脉冲流
##数据准备
#加载并处理MNIST数据集
transform = transforms.Compose([transforms.ToTensor()]) # 转换器,把图片转为 [0,1] 浮点Tensor
train_set = datasets.MNIST("./data", train=True, download=True, transform=transform) # 加载训练集
test_set = datasets.MNIST("./data", train=False, download=True, transform=transform) # 加载测试集
#取子集让实验快速可见
train_subset = torch.utils.data.Subset(train_set, list(range(TRAIN_SAMPLES)))# 只取前TRAIN_SAMPLES张图片,跑得更快
test_subset = torch.utils.data.Subset(test_set, list(range(TEST_SAMPLES)))# 只取前TEST_SAMPLES张测试图片
train_loader = torch.utils.data.DataLoader(train_subset, batch_size=BATCH, shuffle=True, drop_last=True)# DataLoader:每次自动生成BATCH张图片,顺序打乱
test_loader = torch.utils.data.DataLoader(test_subset, batch_size=BATCH, shuffle=False, drop_last=False)# 测试集不需要打乱
#Poisson 编码(将图像转换为脉冲序列)原理:像素越亮,发放脉冲的概率越高
def poisson_encode(images, T=TIME_STEPS):
# images: [B,1,28,28], 值 ∈ [0,1]
# 返回脉冲: [T,B,784] 的0/1
B = images.shape[0] # 批次大小
x = images.view(B, -1) # [B,784]
# 在时间上按像素强度产生泊松脉冲
rand = torch.rand(T, B, x.shape[1], device=x.device)
spikes = (rand < x.unsqueeze(0)).float()
return spikes
#越亮的像素越可能在T步内发出更多脉冲,符合感知生物机制。2.网络结构
它把输入图像转成脉冲流,经全连接+LIF神经元逐步积分放电,让不同神经元在 STDP 调整下逐渐对不同输入模式变敏感。
class SingleLayerSNN(nn.Module):
def __init__(self, input_size=28*28, hidden_size=HIDDEN):
super().__init__()
self.fc = nn.Linear(input_size, hidden_size, bias=False) # 全连接层,无偏置,[输入784,输出HIDDEN],用来模拟输入突触权重
self.lif = snn.LIFCell() # LIF 神经元(输出即脉冲)
# 权重初始化为小正数
nn.init.uniform_(self.fc.weight, a=0.0, b=0.05)
def forward_spikes(self, xT):#做25个时间步,每步都按输入决定哪些神经元发脉冲
"""
xT: [T,B,784] 输入脉冲
返回:
zT: [T,B,HIDDEN] 输出脉冲
s_list: 中间状态(这里不需要保存膜电位)
"""
T, B, _ = xT.shape #时间批次,批次大小
s = None #神经元膜电位状态(LIF模型中的状态)
outs = []
for t in range(T):
z = self.fc(xT[t]) # [B,H]
z, s = self.lif(z, s) # 脉冲 0/1
# 轻量 WTA:若该步有多个脉冲,保留每个样本最大者
# 防止全零时 argmax=0 误触发,做个小判断
fired = (z > 0)
if fired.any():
# 对每个样本,若有脉冲,则只保留最大的那个
max_idx = z.argmax(dim=1) # [B]
mask = torch.zeros_like(z)
mask[torch.arange(B), max_idx] = 1.0
z = z * 0.0 + mask * fired.float().max(dim=1, keepdim=True)[0]
outs.append(z)
return torch.stack(outs) # [T,B,H]3.STDP
@torch.no_grad()
def stdp_update(pre_t, post_t, W, a_plus=A_PLUS, a_minus=A_MINUS):
"""
pre_t: [T,B,784] 输入脉冲
post_t: [T,B,H] 输出脉冲
W: [H,784] 注意 PyTorch Linear 的 weight 形状是 [out,in]
这里用相关性累计(近似 Δt>0 的 LTP 和 Δt<0 的 LTD 的混合简化)
"""
# 将 [T,B,·] 合并时间批次维度,做一次性相关统计更快
TB = pre_t.shape[0] * pre_t.shape[1]
pre = pre_t.reshape(TB, pre_t.shape[2]) # [TB,784]
post = post_t.reshape(TB, post_t.shape[2]) # [TB,H]
# 相关性:pre^T @ post -> [784,H],但 W 是 [H,784],所以转置
hebb = pre.T @ post # [784,H]
hebb = hebb.T # [H,784]
# LTP(正向)与 LTD(反向)的简化:同一统计里用不同系数
W += a_plus * hebb
W -= a_minus * (hebb > 0).float() * 0.5 # 轻微抑制,避免爆炸(经验项)
# 归一化/裁剪,保持稳定
W.clamp_(0.0, 0.2)把输入脉冲和输出脉冲的相关性统计出来,根据 Hebbian 规则增强连接,再加点抑制防止爆炸, 最后归一化保持稳定和竞争。
4.无监督训练流程
先用 STDP 在无监督下让突触自组织(形成特征原型),再用少量标注统计给每个神经元贴标签(映射),最后按“最活跃神经元的标签”做分类评估。
def train_unsupervised(model, loader, epochs=1):
model.train()
for ep in range(epochs):
for images, _ in loader:
images = images.to(DEVICE)
xT = poisson_encode(images) # [T,B,784]
zT = model.forward_spikes(xT) # [T,B,H]
# STDP 更新(用 fc.weight.data)
stdp_update(xT, zT, model.fc.weight.data)
@torch.no_grad()
def build_neuron_label_map(model, loader):
"""
统计每个神经元最常响应的数字标签,得到 neuron -> label 的映射
"""
model.eval()
tally = torch.zeros(HIDDEN, 10, dtype=torch.long)
for images, labels in loader:
images = images.to(DEVICE)
xT = poisson_encode(images) # [T,B,784]
zT = model.forward_spikes(xT).cpu() # [T,B,H]
# 以总脉冲数最大的神经元作为“胜者”
winner = zT.sum(dim=0).argmax(dim=1) # [B]
for w, y in zip(winner, labels):
tally[w, y] += 1
# 每个神经元分配到计数最多的标签
mapping = tally.argmax(dim=1) # [H]
return mapping, tally
@torch.no_grad()
def evaluate(model, loader, neuron2label):
model.eval()
correct, total = 0, 0
for images, labels in loader:
images = images.to(DEVICE)
xT = poisson_encode(images)
zT = model.forward_spikes(xT).cpu()
winner = zT.sum(dim=0).argmax(dim=1) # [B]
pred = neuron2label[winner] # [B]
correct += (pred == labels).sum().item()
total += labels.numel()
acc = correct / total
return acc5.评估结果
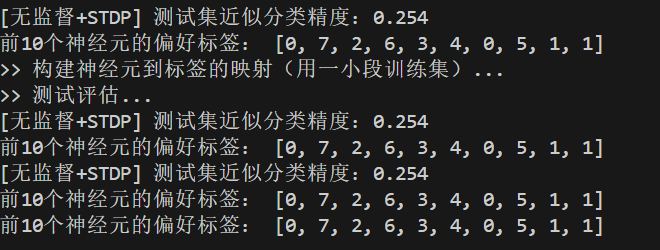
通过简单训练能够得出STDP 可以让神经元自组织成特征探测器,证明了 无监督 STDP + WTA 能在 MNIST 上学出“有意义的特征原型”,而不是完全随机。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)