基于卷积神经网络的高光谱图像分类研究
与普通图像相比,高光谱图像处理面临的两个主要问题是:一是光谱分辨率高、光谱曲线近乎连续、数据量大、数据冗余严重、谱间相关性强;另一是空间分辨率有限、存在大量混合像元,“Hughes”现象凸现。“特征学习”从原始的像素出发通过特定的神经网络结构自动发现图像中隐藏的模式以学习出有效特征,近年来获得空前的发展,成为国际上信号处理模式识别等领域的研究热点。深度学习是一种多层的神经网络结构,是自 2012
摘要
与普通图像相比,高光谱图像处理面临的两个主要问题是:一是光谱分辨率高、光谱曲线近乎连续、数据量大、数据冗余严重、谱间相关性强;另一是空间分辨率有限、存在大量混合像元,“Hughes”现象凸现。
“特征学习”从原始的像素出发通过特定的神经网络结构自动发现图像中隐藏的模式以学习出有效特征,近年来获得空前的发展,成为国际上信号处理模式识别等领域的研究热点。深度学习是一种多层的神经网络结构,是自 2012 年来机器学习领域非常热的一个研究方向,它能够从原始的像素出发通过多层结构自动学习有效特征并在输出层实现分类。本文将基于深度学习的特征学习方法引入到高光谱遥感图像处理中,结合像元的空谱联合特征,设计了一种深度学习网络,能够从高光谱数据上百个波段中提取高光谱图像的空谱联合特征进行分类处理,其性能优于国际上最新的RPCA+CNN算法。同时,训练好的网络具有很好的泛化性能,可以直接提取同种传感器获取的其他高光谱图像数据,与传统的SVM、SVM-CK等分类方法比较,正确率得到了显著的提升。
关键词:高光谱图像,特征提取,深度学习,卷积神经网络
Abstract
Hyperspectral classification, which categorizes all image pixels into one of several land cover classes according to their characteristics, has become one of the most popular topics in hyperspectral remote sensing. However, it faces two main problems. First, hyperspectral image is featured with high spectral resolution and its spectral curve is nearly continuous. However, the redundancy in data is serious and the spectral correlation is very strong. Second, there exist a lot of mixed pixels since its space resolution is limited. The "Hughes" phenomenon always happens in classification.
In machine learning, feature learning or representation learning is a set of techniques that learn a feature: a transformation of raw data input to a representation that can be effectively exploited in machine learning tasks. This obviates manual feature engineering, which is otherwise necessary, and allows a machine to both learn at a specific task (using the features) and learn the features themselves: to learn how to learn.
Deep learning (also known as deep structured learning, hierarchical learning or deep machine learning) is a branch of machine learning based on a set of algorithms that attempt to model high-level abstractions in data by using multiple processing layers, with complex structures or otherwise, composed of multiple non-linear transformations. This article will introduce a feature learning method based on deep learning, which combined with the spectral-spatial characteristics of pixels can learn the deep feature from hyperspectral remote sensing image, and be able to extract useful information from hyperspectral data to get lower classification error rate. Compared with other classification method based on deep learning, the accuracy of our method has been significantly improved, and even better than the state of the art algorithms. Meanwhile, the trained network has good generalization performance, and we can use weight which had been trained by one of hyperspectral image to directly extract feature from other hyperspectral image, compared with the origin data, the classification error rate has been significantly lower.
KEY WORDS:hyperspectral image, feature extraction, deep learning,convolutional neural network
目录
2.2.5 Batch normalization批量正则化
3.3.3 Pavia Centre and University
3.3 高光谱图像分类测试数据集
本章使用了四种常用的数据集验证我们提出的卷积神经网络特征学习性能。
3.3.1 Indian Pines


图 32 Indian Pines数据集,左为高光谱图像,右为Ground-truth
Indian Pine数据集,这一场景是由AVIRIS传感器拍摄于印第安纳州西北部的松树林,包括224个波段,图像大小为145

145个像素,波长范围为

米。Indian Pines场景由三分之一的森林三分之二的农耕地以及一些天然草本植被组成,除此以外,还有两条公路,一条火车道,少量居民住宅和一些小路。图像拍摄于六月份,拍摄之后,一些作物如玉米,大豆开始慢慢生长,但覆盖率不超过5%。实际可用数据被分为16大类,剔除被水吸收的波段,图像波段最终降至200,被删减的波段分别为[104-108],[150-163],220。
表 31 16 GROUND-TRUTH CLASSES IN AVIRIS INDIAN PINES
|
# |
Class |
Samples |
|
1 |
Alfalfa |
46 |
|
2 |
Corn-notill |
1428 |
|
3 |
Corn-mintill |
830 |
|
4 |
Corn |
237 |
|
5 |
Grass-pasture |
483 |
|
6 |
Grass-trees |
730 |
|
7 |
Grass-pasture-mowed |
28 |
|
8 |
Hay-windrowed |
478 |
|
9 |
Oats |
20 |
|
10 |
Soybean-notill |
972 |
|
11 |
Soybean-mintill |
2455 |
|
12 |
Soybean-clean |
593 |
|
13 |
Wheat |
205 |
|
14 |
Woods |
1265 |
|
15 |
Buildings-Grass-Trees-Drives |
386 |
|
16 |
Stone-Steel-Towers |
93 |
3.3.2 Salina


图 33 Salinas 数据集,左为高光谱图像,右为Ground-truth
Salina数据集,这一场景由具有224个波段的AVIRIS 传感器收集于萨利纳斯谷和加利福尼亚州,图像以3.7米像素为单位,具有极高的空间分辨率。Salinas scene的图像大小为512

217个像素,波段数为224。与Indian Pines场景类似,这里依然删减水吸收带,波段数分别为[108-112],[154-167] ,224。样本类别有蔬菜、裸露的土地,葡萄园庄园等一共16大类。
表 32 16 GROUND-TRUTH CLASSES IN AVIRIS SALINAS
|
# |
Class |
Samples |
|
1 |
Brocoli_green_weeds_1 |
2009 |
|
2 |
Brocoli_green_weeds_2 |
3726 |
|
3 |
Fallow |
1976 |
|
4 |
Fallow_rough_plow |
1394 |
|
5 |
Fallow_smooth |
2678 |
|
6 |
Stubble |
3959 |
|
7 |
Celery |
3579 |
|
8 |
Grapes_untrained |
11271 |
|
9 |
Soil_vinyard_develop |
6203 |
|
10 |
Corn_senesced_green_weeds |
3278 |
|
11 |
Lettuce_romaine_4wk |
1068 |
|
12 |
Lettuce_romaine_5wk |
1927 |
|
13 |
Lettuce_romaine_6wk |
916 |
|
14 |
Lettuce_romaine_7wk |
1070 |
|
15 |
Vinyard_untrained |
7268 |
|
16 |
Vinyard_vertical_trellis |
1807 |
3.3.3 Pavia Centre and University
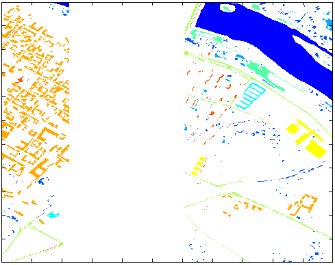
这两个场景是由机载ROSIS传感器在意大利北部的帕维亚飞行的时候拍摄。Pavia Centre场景的光谱波段数为102,Pavia University的光谱波段数为103,二者的图像分别为1096

1096像素和610

610像素,空间分辨率都为1.3米,其中,Pavia University图像中的一些样本不包含任何信息,所以在分析之前这些像素必须被剔除,被剔除的样本在图像中呈黑色条状,剔除后Pavia University图像大小为610

340像素。此外,两个场景都被分为9个类别。


图 34 Pavia University 数据集,左为高光谱图像,右为Ground-truth


图 35 Pavia Centre 数据集,左为高光谱图像,右为 Ground-truth
表 33 9 GROUND-TRUTH CLASSES IN ROSIS PAVIA CENTRE
|
# |
Class |
Samples |
|
1 |
Water |
824 |
|
2 |
Trees |
820 |
|
3 |
Asphalt |
816 |
|
4 |
Self_Blocking Bricks |
808 |
|
5 |
Bitumen |
808 |
|
6 |
Tiles |
1260 |
|
7 |
Shadows |
476 |
|
8 |
Meadows |
824 |
|
9 |
Bare Soil |
820 |
表 34 9 GROUND-TRUTH CLASSES IN ROSIS PAVIA UNIVERSITY
|
# |
Class |
Samples |
|
1 |
Asphalt |
6631 |
|
2 |
Meadows |
18649 |
|
3 |
Gravel |
2099 |
|
4 |
Trees |
3064 |
|
5 |
Painted metal sheets |
1345 |
|
6 |
Bare Soil |
5029 |
|
7 |
Bitumen |
1330 |
|
8 |
Self_Blocking Bricks |
3682 |
|
9 |
Shadows |
947 |
3.4.1 简介
在这一节中,使用本章第一节中提出的卷积神经网络结构进行高光谱图像分类。
3.4.2 实验设计
在这一部分,我们使用四幅高光谱图像验证提出的基于卷积神经网络的高光谱图像分类方法的有效性。作为对比,选择了CNN[52],RPCA+CNN[53],SVM,SVM-CK四种方法。
本小节基于Caffe架构设计并验证了本文提出的卷积神经网络结构。在我们的卷积神经网络中,全连接层的神经元数量,学习率与dropout率被设置为100,0.1和0.1。SGD算法训练网络时不够稳定,本网络使用AdaGrad方法训练权值,mini-batch设为32;使用权重衰减系数为0.0005,模型最终迭代300w次。
对于输入层,计算像元的

或

邻域内的均值与(或)标准差网络输入。
对于卷积层,卷积核尺寸

,对于Indian Pine 和 Salina数据集,设置为24,对于Pavia University数据集,设置为11。
每种网络实验10组,每组实验取每类样本中的200个作为训练集,其余作为测试集。
传统的RBF核SVM分类器与当前最好的基于卷积神经网络的分类方法也被加入到对比之中。最终我们使用分类正确率来验证分类性能。表格 1列举了不同方法在三个数据集上的分类性能,可以看到我们的方法比其他两种只使用了光谱信息的方法有很大优势。
3.4.3 实验结果与分析
- AVIRIS传感器
Indian Pines数据集部分类别样本较少,不足200个。去掉样本较少的8类数据,参与训练的Indian Pines数据集共包含8类数据,列表如下:
表 35 Indian Pines数据集中训练和测试样本的个数
|
Number |
Class |
Training |
Test |
|
1 |
Corn-notill |
200 |
1228 |
|
2 |
Corn-mintill |
200 |
630 |
|
3 |
Grass-pasture |
200 |
283 |
|
4 |
Hay-windrowed |
200 |
278 |
|
5 |
Soybean-notill |
200 |
772 |
|
6 |
Soybean-mintill |
200 |
2255 |
|
7 |
Soybean-clean |
200 |
393 |
|
8 |
Woods |
200 |
1065 |
|
Total |
1600 |
6904 |
Indian Pines:





图 36 Indian Pines 5×5分类结果图,最上为原始标签,中左为CNN[52],中右为RPCA+CNN,下左为3

3均值

方差,下右为5

5均值

方差

图 37 Indian Pines 5

5均值+方差分类混淆矩阵
Salinas数据集样本较多,列表如下:
表 36 Salinas数据集中训练和测试样本的个数
|
Number |
Class |
Training |
Test |
|
1 |
Brocoli_green_weeds_1 |
200 |
1809 |
|
2 |
Brocoli_green_weeds_2 |
200 |
3526 |
|
3 |
Fallow |
200 |
1776 |
|
4 |
Fallow_rough_plow |
200 |
1194 |
|
5 |
Fallow_smooth |
200 |
2478 |
|
6 |
Stubble |
200 |
3759 |
|
7 |
Celery |
200 |
3379 |
|
8 |
Grapes_untrained |
200 |
11071 |
|
9 |
Soil_vinyard_develop |
200 |
6003 |
|
10 |
Corn_senesced_green_weeds |
200 |
3078 |
|
11 |
Lettuce_romaine_4wk |
200 |
868 |
|
12 |
Lettuce_romaine_5wk |
200 |
1727 |
|
13 |
Lettuce_romaine_6wk |
200 |
716 |
|
14 |
Lettuce_romaine_7wk |
200 |
870 |
|
15 |
Vinyard_untrained |
200 |
7068 |
|
16 |
Vinyard_vertical_trellis |
200 |
1607 |
|
Total |
3200 |
50929 |
表 37 AVIRIS传感器数据集错误率总表
|
网络类型 |
Indian Pines |
Salina |
|
均值 |
4.97(4.84±0.60) |
3.43(3.41±0.26) |
|
均值 |
3.03(3.05±0.31) |
2.04(2.09±0.24) |
|
均值
方差 |
5.14(5.27±0.62) |
3.99(3.98±0.28) |
|
均值
方差 |
2.83(2.82±0.17) |
2.37(2.39±0.30) |
|
RPCA+CNN |
22.81(22.53±0.85) |
7.36(7.39±0.35) |






- ROSIS传感器
表 38 ROSIS传感器数据集错误率总表
|
网络类型 |
Pavia University |
Pavia Centre |
|
均值 |
3.86(3.83±0.37) |
0.50(0.51±0.05) |
|
均值 |
2.13(2.14±0.20) |
0.32(0.36±0.11) |
|
均值
方差 |
3.23(3.24±0.19) |
0.44(0.45±0.06) |
|
均值
方差 |
1.77(1.81±0.23) |
0.29(0.31±0.04) |
|
RPCA+CNN |
6.75(6.58±0.84) |
1.35(1.46±0.13) |






实验表明,对于ROSIS传感器的两幅高光谱图像,

均值

方差对应的网络分类正确率最高。Indian Pines数据集包含较多的小样本,相似度高,不好区分,RPCA+CNN的方法对于训练集样本数少,样本相似度高等问题表现稍显不足,在Indian Pines数据集上错误率较高。
3.5 特征学习
3.5.1 特征学习简介
卷积神经网络具有很强的泛化性能,在一种情况下,卷积神经网络被视为端到端网络,网络输入端输入具体的图像或像素时,通过前向运算,网络输出端就可以输出像素的类别。另外一种情况是,卷积神经网络被视为可以逐层学习特征的特征学习方法,我们可以把它用做通用特征提取器,提取中间层的特征另作它用。
传统的特征学习方法依赖于具体的数据,要针对特定的数据设计特定的方法,进行复杂的调优,才能取得不错的结果。而卷积神经网络特征学习方法不同,一处训练,处处使用,可以作为通用的特征学习方法学习特征,不需要针对具体的数据进行具体的调优。
我们设计的卷积神经网络的输入是像元的空谱联合特征,网络可以去除原始数据的冗余信息,保留原始数据的有效信息,提取原始数据的特征。而且,同种传感器获取的信息具有相似性,即使网络并没有针对要分类的数据集进行过训练,依旧可以高效从原始数据中习得特征。
在这个实验中,我们认为同一种传感器获取的高光谱像元具有相似的性质。使用某一数据集训练卷积神经网络,把训练好的卷积神经网络用作特征学习,自动学习同种传感器拍摄的其他数据集的特征。因之,为了衡量特征学习方法提取特征的质量,使用SVM、SVM-CK等经典算法,分别对原始数据与特征学习获得的特征进行分类,实验表明,使用特征学习方法习得的特征做分类,效果要远远优于使用同种算法对原始数据做分类。由此可得,本文提出的特征学习方法对于从未学习过的数据,也具有很好的通用性能,可以从原始数据中习得更加有效的信息。
3.5.2 实验设计
在本节实验中,对于同一种传感器采集的不同数据集,使用其中一个数据集训练网络,获得网络模型作为特征学习网络。其余的数据集输入特征学习网络,获取对应的特征。使用,最终实验组使用SVM与SVM-CK算法分别对特征做分类,对照组直接使用SVM与SVM-CK算法对原始数据分类,以此测试特征质量。
例外的是,使用Indian Pines数据集训练网络时,并没有用到全部的16类样本,而是只用了其中的8类样本。在此基础上,本节增加一组实验,使用部分Indian Pines数据集训练网络,训练完成之后,使用完整的Indian Pines数据集进行特征学习,具体实验结果见AVIRIS传感器实验三。
卷积神经网络具有很好的泛化性能,可以自动从原始数据中习得抽象特征,在实验的训练阶段,用3.3小节中的设置进行训练,之后把同一传感器采集到的其他数据集全部的原始数据归一化至[-1,+1]输入网络,从网络的全连接层中获得对应的特征。特征测试时分两部分进行实验:
测试一:其中每个类别200个特征作为训练集,其余的特征作为测试集。
测试二:其中每个类别10%的特征作为训练集,90%的特征作为测试集。
本节实验在两个传感器(AVIRIS,ROSIS)和传感器捕获的四幅图像(Indian Pines、Salinas、Pavia University、Pavia Centre)中做了实验。
在网络训练阶段,针对同一传感器中的一组数据集,使用3.4.2小节中的

均值+方差的方法训练网络。训练得到10组网络权重。
在特征学习阶段,使用同一传感器的另一组数据集,通过网络前向运算,习得这组数据集的特征,并通过SVM与SVM-CK分类算法,验证学习到的特征的质量,标记为CNN+SVM与CNN+SVM-CK。为了获得更加稳定的实验结果,每组网络权重运行10次分类实验,共计100次实验。实验结果以分类错误率的中位数(均值±标准差)百分比的形式体现。
最后,原始数据归一化至[0,1]区间,使用标准SVM和SVM-CK算法作为对照。
3.5.3 实验结果与分析
- AVIRIS传感器
- 实验一
- 实验内容
在网络训练阶段,使用Indian Pines数据集,在特征学习阶段,使用Salina数据集。
- 实验结果
表 39 Salina数据集特征学习结果测试
|
实验 |
测试一(200) |
测试二(10%) |
|
SVM |
8.321(8.334±0.677) |
6.116(6.119±0.879) |
|
SVM-CK |
4.210(4.234±0.712) |
1.563(1.535±0.879) |
|
CNN+SVM |
3.655(3.661±0.288) |
1.459(1.478±0.133) |
|
CNN+SVM-CK |
2.849(2.866±0.326) |
0.745(0.759±0.112) |
- 实验分析
使用200样本训练的网络提取特征能力并不强,我们认为可以通过使用更多的数据训练网络,来获取质量更好的特征,比如使用 Indian Pines 90%的数据作为训练集,训练完成之后提取Salina特征
- 实验二
- 实验内容
在网络训练阶段,使用Salina数据集,在特征学习阶段,使用Indian Pines数据集。
- 实验结果
表 310 Indian Pines数据集特征学习结果测试
|
实验 |
测试一(200) |
测试二(10%) |
|
SVM |
16.157(16.174±0.385) |
10.649(10.690±0.092) |
|
SVM-CK |
5.381(5.402±0.401) |
5.701(5.693±0.258) |
|
CNN+SVM |
5.156(5.106±0.666) |
6.384(6.459±0.547) |
|
CNN+SVM-CK |
2.296(2.331±0.496) |
3.461(3.437±0.435) |
- 实验三
- 实验内容在网络训练阶段,使用Indian Pines 数据集8类样本,在特征学习阶段,使用Indian Pines 全部16类样本
- 实验结果
表 311 Indian Pines 数据集特征学习结果测试
|
实验 |
测试二(10%) |
|
SVM |
10.649(10.690±0.092) |
|
SVM-CK |
5.701(5.693±0.258) |
|
CNN+SVM |
3.374(3.369±0.317) |
|
CNN+SVM-CK |
1.155(1.203±0.232) |
- ROSIS传感器
- 实验四
- 实验内容
在网络训练阶段,使用Pavia Centre 数据集,在特征学习阶段,使用Pavia University数据集
- 实验结果
表 312 Pavia University 数据集特征学习结果测试
|
实验 |
测试一(200) |
测试二(10%) |
|
SVM |
9.231(9.243±0.477) |
5.714(5.711±0.872) |
|
SVM-CK |
3.175(3.189±0.713) |
1.768(1.765±0.879) |
|
CNN+SVM |
2.615(2.632±0.276) |
1.472(1.477±0.138) |
|
CNN+SVM-CK |
1.191(1.172±0.242) |
0.326(0.335±0.089) |
- 实验五
- 实验内容
在网络训练阶段,使用Pavia University 数据集,在特征学习阶段,使用Pavia Centre数据集
- 实验结果
表 313 Pavia Centre 数据集特征学习结果测试
|
实验 |
测试一(200) |
测试二(10%) |
|
SVM |
1.678(1.713±0.814) |
0.986(0.983±0.964) |
|
SVM-CK |
0.738(0.755±0.881) |
0.288(0.291±0.968) |
|
CNN+SVM |
0.330(0.330±0.042) |
0.131(0.133±0.022) |
|
CNN+SVM-CK |
0.414(0.429±0.087) |
0.057(0.058±0.017) |
- 实验分析
对于ROSIS传感器采集到的两幅图像,较高的空间分辨率使得样本数量较大,实验二获得了比实验一低很多的分类错误率。
Pavia Centre数据集数据量较大,去掉背景之后大约有14万待分类像元,测试一训练集样本有1800个,大约只占总数据集的1.3%,但分类精度依然达到了0.9966,说明本文提出的深度卷积神经网络对于不曾接触过的数据集有良好的特征学习性能,我们的特征学习方法习得的特征具有很好的代表性。
测试二使用10%的训练集,只有76个像元被错分,正确率达到了0.99943,取得了极好的结果。
3.5 本章小结
本章提出了一种基于深度卷积神经网络的空谱联合特征学习与分类方法,结合像元的光谱特征,设计了一种深度学习网络,能够从高光谱数据上百个波段中提取有用的信息并分类,与其他基于深度学习的分类方法相比,正确率得到了显著的提升。同时,训练好的网络具有很好的泛化性能,可以直接提取同种传感器获取的其他高光谱图像数据,与传统的SVM、SVM-CK等分类方法比较,正确率得到了显著的提升。


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)