强化学习1.3 深度学习交叉熵方法
·
在本节中,将交叉熵方法(CEM)实现扩展到神经网络,训练一个多层神经网络,来解决简单的连续状态空间游戏问题。
老规矩,初始化环境。确保在 Google Colab 或远程服务器上也能顺利运行需要图形界面的强化学习环境,不会因为没有显示器而崩溃。
import sys, os
if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):
!wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash
!touch .setup_complete
# This code creates a virtual display to draw game images on.
# It will have no effect if your machine has a monitor.
if type(os.environ.get("DISPLAY")) is not str or len(os.environ.get("DISPLAY")) == 0:
!bash ../xvfb start
os.environ['DISPLAY'] = ':1'
安装依赖库
# Install gymnasium if you didn't
!pip install "gymnasium[toy_text,classic_control]"
确认 CartPole 环境能跑、能画、维度已知,为后续训练代码做准备。
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# if you see "<classname> has no attribute .env", remove .env or update gym
env = gym.make("CartPole-v0", render_mode="rgb_array").env
env.reset()
n_actions = env.action_space.n
state_dim = env.observation_space.shape[0]
plt.imshow(env.render())
print("state vector dim =", state_dim)
print("n_actions =", n_actions)
env.close()
共有四个状态两个动作:
直接用 sklearn 的 MLPClassifier 当策略网络,具体流程如下:
-
训练
把“看到的状态→专家动作”喂进去,一次梯度更新,让网络越来越像专家。 -
推理
输入一批状态,返回每行是该状态下各个动作的概率分布,形状 [batch, n_actions]。
后面用交叉熵方法选动作时,就按这个概率采样。
from sklearn.neural_network import MLPClassifier
# 创建一个小型的前馈网络,还没训练,权重随机。
agent = MLPClassifier(
hidden_layer_sizes=(20, 20),
activation="tanh",
)
# initialize agent to the dimension of state space and number of actions
# 这里用假数据跑一遍,只为了让网络内部把权重矩阵、标签二值化器等结构建好,不指望它学到任何东西。
agent.partial_fit([env.reset()[0]] * n_actions, # X
range(n_actions), # y
classes=range(n_actions)) # 显式告诉模型一共 n_actions 类
让当前神经网络策略完整玩一局游戏,并收集训练数据
对每一步:
- 把当前状态 s 喂给 agent,拿到动作概率向量;
- 按概率随机采样一个动作 a(探索);
- 执行 a,拿到新状态、奖励、是否结束;
- 把 (s, a) 存进列表,累加奖励;
循环直到游戏结束或超时。
def generate_session(env, agent, t_max=1000):
"""
Play a single game using agent neural network.
Terminate when game finishes or after :t_max: steps
"""
states, actions = [], []
total_reward = 0
s, _ = env.reset()
for t in range(t_max):
# use agent to predict a vector of action probabilities for state :s:
# probs = <YOUR CODE>
probs = agent.predict_proba(np.array([s]))[0] # 返回形状 (n_actions,)
assert probs.shape == (env.action_space.n,), "make sure probabilities are a vector (hint: np.reshape)"
# use the probabilities you predicted to pick an action
# sample proportionally to the probabilities, don't just take the most likely action
# a = <YOUR CODE>
a = np.random.choice(env.action_space.n, p=probs)
# ^-- hint: try np.random.choice
new_s, r, terminated, truncated, _ = env.step(a)
# record sessions like you did before
states.append(s)
actions.append(a)
total_reward += r
s = new_s
if terminated or truncated:
break
return states, actions, total_reward
进行测试
dummy_states, dummy_actions, dummy_reward = generate_session(env, agent, t_max=5)
print("states:", np.stack(dummy_states))
print("actions:", dummy_actions)
print("reward:", dummy_reward)

深度交叉熵方法(Deep CEM)的流程和 CEM 一模一样,直接复制代码就行;唯一区别是状态从‘整数索引’变成了‘float32 向量’,所以神经网络输入层要接 state_dim 维实数,而不是 one-hot 或查表。
def select_elites(states_batch, actions_batch, rewards_batch, percentile=50):
"""
Select states and actions from games that have rewards >= percentile
:param states_batch: list of lists of states, states_batch[session_i][t]
:param actions_batch: list of lists of actions, actions_batch[session_i][t]
:param rewards_batch: list of rewards, rewards_batch[session_i]
:returns: elite_states,elite_actions, both 1D lists of states and respective actions from elite sessions
Please return elite states and actions in their original order
[i.e. sorted by session number and timestep within session]
If you are confused, see examples below. Please don't assume that states are integers
(they will become different later).
"""
# <YOUR CODE: copy-paste your implementation from the previous notebook>
reward_threshold = np.percentile(rewards_batch, percentile)
elite_states = []
elite_actions = []
for session_idx, total_r in enumerate(rewards_batch):
if total_r >= reward_threshold:
elite_states.extend(states_batch[session_idx])
elite_actions.extend(actions_batch[session_idx])
return elite_states, elite_actions
开始训练
可视化代码
from IPython.display import clear_output
def show_progress(rewards_batch, log, percentile, reward_range=[-990, +10]):
"""
A convenience function that displays training progress.
No cool math here, just charts.
"""
mean_reward = np.mean(rewards_batch)
threshold = np.percentile(rewards_batch, percentile)
log.append([mean_reward, threshold])
clear_output(True)
print("mean reward = %.3f, threshold=%.3f" % (mean_reward, threshold))
plt.figure(figsize=[8, 4])
plt.subplot(1, 2, 1)
plt.plot(list(zip(*log))[0], label="Mean rewards")
plt.plot(list(zip(*log))[1], label="Reward thresholds")
plt.legend()
plt.grid()
plt.subplot(1, 2, 2)
plt.hist(rewards_batch, range=reward_range)
plt.vlines(
[np.percentile(rewards_batch, percentile)],
[0],
[100],
label="percentile",
color="red",
)
plt.legend()
plt.grid()
plt.show()
训练循环
n_sessions = 100
percentile = 70
log = []
for i in range(100):
# generate new sessions
# sessions = [ <YOUR CODE: generate a list of n_sessions new sessions> ]
sessions = [generate_session(env, agent, t_max=1000) for _ in range(n_sessions)]
# states_batch, actions_batch, rewards_batch = map(np.array, zip(*sessions))
states_batch, actions_batch, rewards_batch = zip(*sessions)
rewards_batch = np.array(rewards_batch) # 只有回报是一维数组
# elite_states, elite_actions = <YOUR CODE: select elite actions just like before>
elite_states, elite_actions = select_elites(states_batch, actions_batch, rewards_batch, percentile)
# <YOUR CODE: partial_fit agent to predict elite_actions(y) from elite_states(X)>
agent.partial_fit(elite_states, elite_actions)
show_progress(
rewards_batch, log, percentile, reward_range=[0, np.max(rewards_batch)]
)
if np.mean(rewards_batch) > 190:
print("You Win! You may stop training now via KeyboardInterrupt.")
结果展示
用 RecordVideo 包装环境,把每一局游戏录成视频并保存到 ./videos 文件夹
# Record sessions
from gymnasium.wrappers import RecordVideo
with RecordVideo(
env=gym.make("CartPole-v0", render_mode="rgb_array"),
video_folder="./videos",
episode_trigger=lambda episode_number: True,
) as env_monitor:
sessions = [generate_session(env_monitor, agent) for _ in range(100)]
把刚刚录好的 .mp4 视频嵌入到 Notebook 里,直接在浏览器里播放。
# Show video. This may not work in some setups. If it doesn't
# work for you, you can download the videos and view them locally.
from pathlib import Path
from base64 import b64encode
from IPython.display import HTML
video_paths = sorted([s for s in Path("videos").iterdir() if s.suffix == ".mp4"])
video_path = video_paths[-1] # You can also try other indices
if "google.colab" in sys.modules:
# https://stackoverflow.com/a/57378660/1214547
with video_path.open("rb") as fp:
mp4 = fp.read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
else:
data_url = str(video_path)
HTML(
"""
<video width="640" height="480" controls>
<source src="{}" type="video/mp4">
</video>
""".format(
data_url
)
)

进阶练习
对于 MountainCar,获得至少 -150 的平均奖励。
以下是一些提示:
- MountainCar 的回合可能持续 超过 10,000 步。请确保 t_max 参数至少为 10,000。
建议使用 “>” 而不是 “>=” 来切割奖励。例如,如果你 90% 的回合奖励是 -10,000,而 10% 更好,那么使用 20% 分位数作为阈值时,R >= threshold 会无法剔除失败的回合,而 R > threshold 则能正常工作。 - 一个只有 20 个神经元的网络可能不足以完成任务,请自由尝试更大的结构或其他参数。
值得注意的是,由于这个任务过于简单,只有最终的奖励,为了让模型能学习到有用的知识,设置了额外的奖励。
import gymnasium as gym
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neural_network import MLPClassifier
# 创建环境(移除时间限制包装器)
env = gym.make("MountainCar-v0").env
n_actions = env.action_space.n # 3个动作:0=左,1=不动,2=右
state_dim = env.observation_space.shape[0] # 2个状态特征:位置和速度
# 初始化神经网络代理
agent = MLPClassifier(
hidden_layer_sizes=(64, 32),
activation='tanh',
solver='adam',
learning_rate_init=1e-3,
warm_start=True, # 允许重复训练
max_iter=1, # 每次partial_fit只进行1次迭代
random_state=42
)
# 初始拟合以设置网络权重
s0, _ = env.reset()
agent.partial_fit(np.tile(s0, (n_actions, 1)), list(range(n_actions)), classes=range(n_actions))
def generate_session(agent, t_max=10000, deterministic=False):
"""生成一个游戏会话并返回状态、动作和总奖励"""
states, actions, total_reward = [], [], 0
s, _ = env.reset()
for _ in range(t_max):
# 根据代理的预测选择动作
if deterministic:
a = agent.predict([s])[0]
else:
probs = agent.predict_proba([s])[0]
a = np.random.choice(n_actions, p=probs)
new_s, r, terminated, truncated, _ = env.step(a)
# 奖励塑造:为前进提供额外奖励
if new_s[0] > s[0]: # 位置改善
r += 0.1
states.append(s)
actions.append(a)
total_reward += r
s = new_s
if terminated or truncated:
break
return states, actions, total_reward
def select_elites(states_batch, actions_batch, rewards_batch, percentile=50):
"""选择表现优异的会话(精英)用于训练"""
# 计算奖励阈值
threshold = np.percentile(rewards_batch, percentile)
# 收集精英样本
elite_states, elite_actions = [], []
for states, actions, reward in zip(states_batch, actions_batch, rewards_batch):
if reward > threshold: # 使用>而非>=以更好地筛选
elite_states.extend(states)
elite_actions.extend(actions)
return np.array(elite_states), np.array(elite_actions)
# 训练参数
n_sessions = 100 # 每次迭代生成的会话数
percentile = 70 # 选择前30%的会话作为精英
log = [] # 记录训练过程中的平均奖励
# 训练循环
for i in range(150):
# 生成会话
sessions = [generate_session(agent) for _ in range(n_sessions)]
states_batch, actions_batch, rewards_batch = zip(*sessions)
# 计算平均奖励并记录
mean_reward = np.mean(rewards_batch)
log.append(mean_reward)
# 选择精英样本
elite_states, elite_actions = select_elites(states_batch, actions_batch, rewards_batch, percentile)
# 如果没有精英样本,跳过本轮
if len(elite_states) == 0:
print(f"迭代 {i}: 没有精英样本,平均奖励: {mean_reward:.1f}")
continue
# 使用精英样本更新代理
agent.partial_fit(elite_states, elite_actions)
# 打印进度
if i % 10 == 0:
print(f"迭代 {i}: 平均奖励: {mean_reward:.1f}, 精英样本数: {len(elite_states)}")
# 检查是否达到目标
if len(log) >= 10 and np.mean(log[-10:]) > -150:
print(f"成功!在迭代 {i} 达到目标,平均奖励: {np.mean(log[-10:]):.1f}")
break
# 绘制训练曲线
plt.figure(figsize=(10, 5))
plt.plot(log)
plt.title('训练过程中的平均奖励')
plt.xlabel('迭代次数')
plt.ylabel('平均奖励')
plt.axhline(y=-150, color='r', linestyle='--', label='目标: -150')
plt.grid(True)
plt.legend()
plt.show()
# 测试训练好的代理
def test_agent(agent, episodes=5):
for episode in range(episodes):
_, _, reward = generate_session(agent, deterministic=True)
print(f"测试回合 {episode+1}: 奖励 = {reward:.1f}")
test_agent(agent)
最终结果如下所示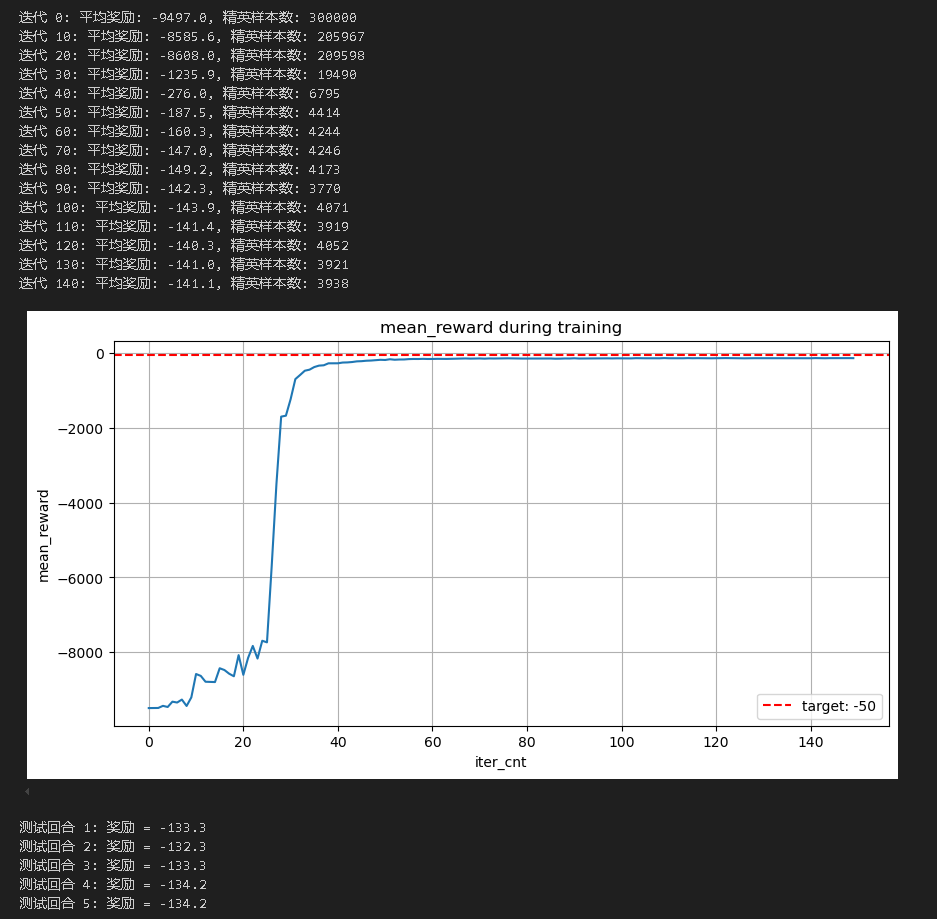

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)