应用BP神经网络实现鸢尾花分类
未来,可以继续尝试更复杂的网络结构和更多的超参数调整,以进一步提升模型在复杂任务中的表现。最终,grid_search.best_params_ 将返回最佳的超参数组合,grid_search.best_score_ 将提供对应的交叉验证准确率。由于 MLPClassifier 不直接提供验证集的准确率曲线,我们可以通过交叉验证获取验证集的准确率,并绘制相应的曲线。然而,在类别不平衡的情况下,准
一、实验目的:
1. 理解BP神经网络的基本原理及工作流程;
2. 掌握使用Python和sklearn库搭建BP神经网络的方法;
3. 学习数据标准化对神经网络性能的影响;
4. 掌握模型评估指标(准确率、混淆矩阵等)的计算与结果分析。
二、实验内容(包含实验过程、截图和代码解释):
1. 数据导入与预处理鸢尾花数据(可以标准化和非标准化,试分析结果是否有所不同)。
- BP神经网络模型搭建。使用sklearn的MLPClassifier函数实现神经网络的搭建。
- 模型训练及可视化曲线。包含训练集,验证集的损失变化、准确率变化曲线图并分析。
- 模型评估。包含混淆矩阵、Precision、Recall 、F1-score等指标的输出,实验报告要包含指标的公式,及结果分析。
- 超参数优化。使用GridSearchCV 算法实验对初始学习率、隐藏层大小、激活函数的选择等超参数进行选择(超参数有哪些自己可以网上查询)并对比分析。
三、实验步骤
1. 数据导入与预处理
首先,加载鸢尾花数据集,并将其分为特征(X)和标签(y):
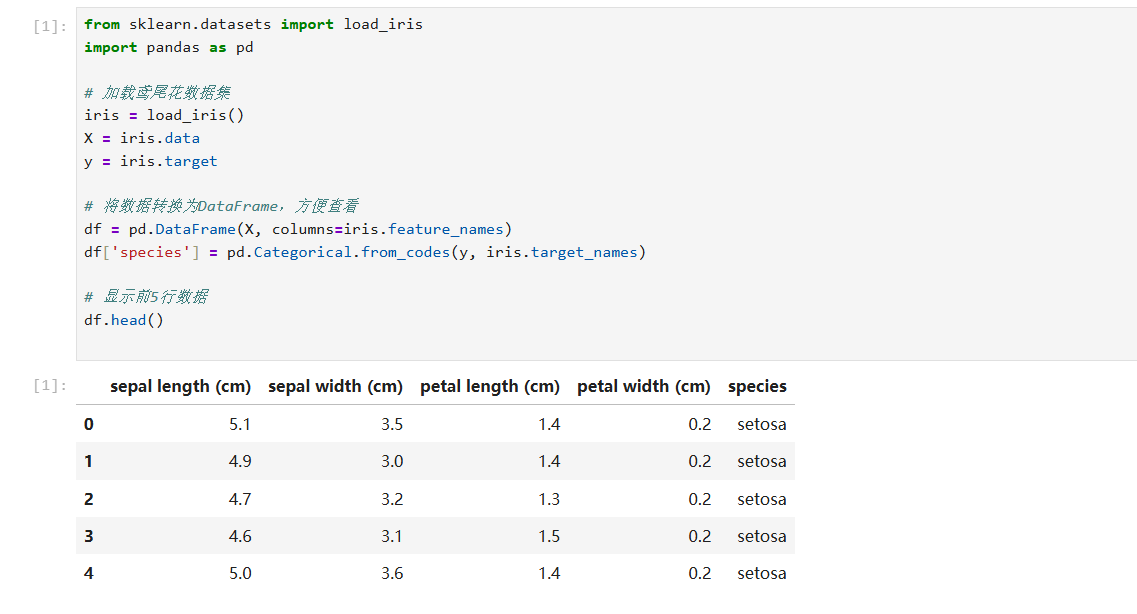
2. 数据标准化
标准化处理将特征缩放到均值为0,方差为1的分布,有助于加速模型收敛并提高性能。使用StandardScaler进行标准化:
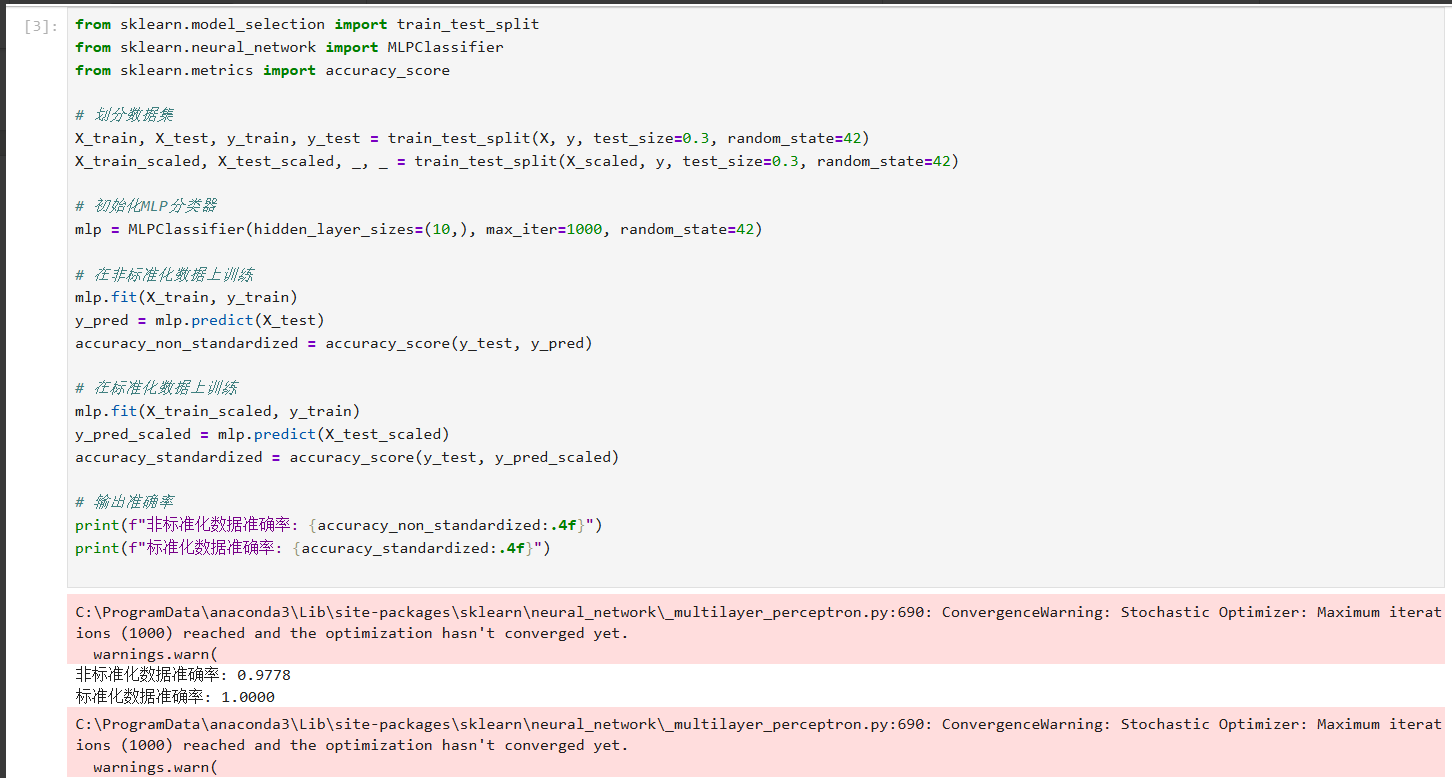
4获取训练过程中的损失和准确率
在使用 MLPClassifier 训练模型时,可以通过 loss_curve_ 属性获取每次迭代的损失值。然而MLPClassifier 默认并不提供训练集和验证集的准确率曲线。为了解决这个问题,我们可以使用交叉验证来获取验证集的准确率。
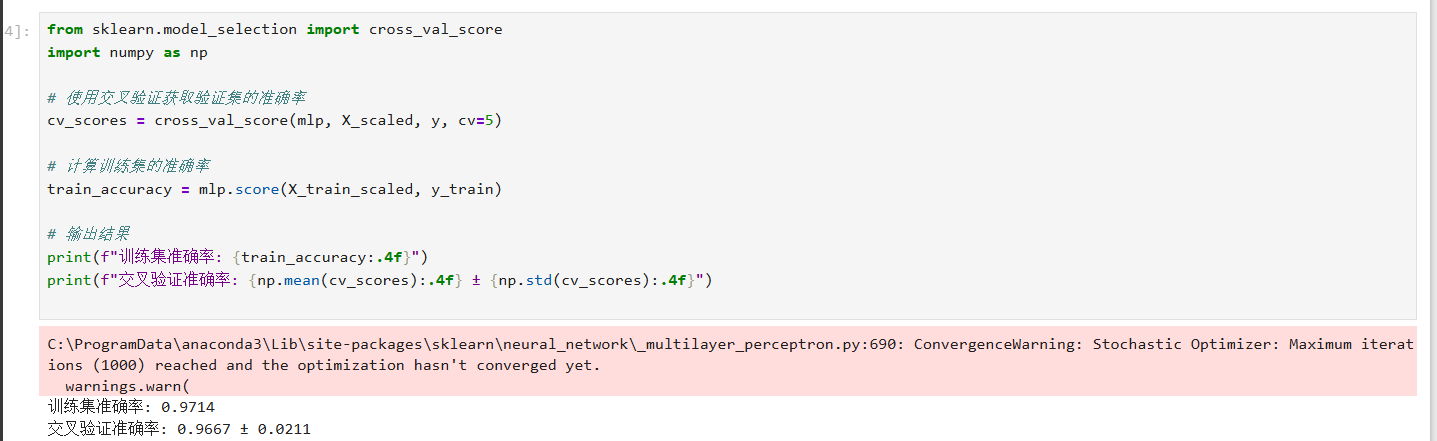
5绘制损失曲线和准确率曲线
使用 matplotlib 库绘制损失曲线和准确率曲线。由于 MLPClassifier 不直接提供验证集的准确率曲线,我们可以通过交叉验证获取验证集的准确率,并绘制相应的曲线。

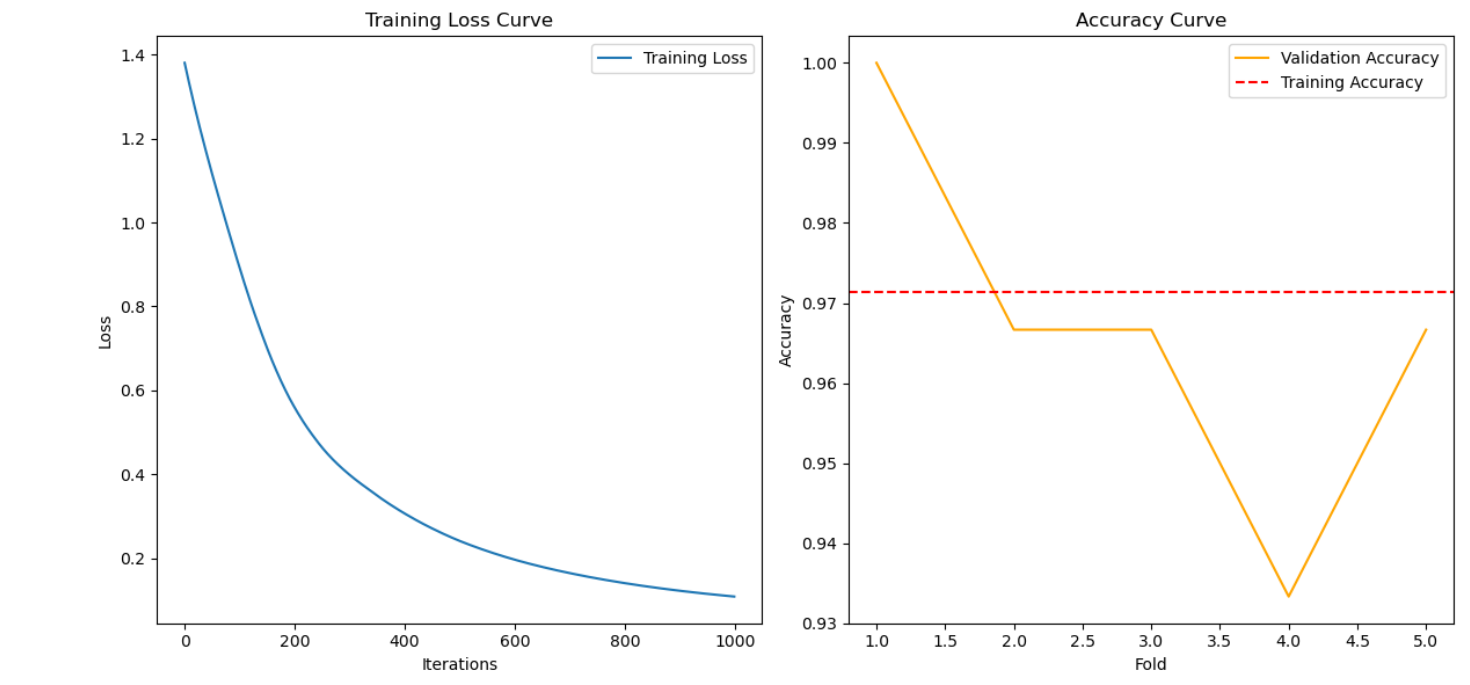
6结果分析
损失曲线:随着迭代次数的增加,训练损失逐渐下降,表明模型在不断优化。
准确率曲线:训练集的准确率通常较高,但可能存在过拟合的风险。验证集的准确率反映了模型在未见数据上的泛化能力。如果训练准确率远高于验证准确率,可能需要调整模型以防止过拟合。
7算评估指标
使用 sklearn 库中的 classification_report 函数,可以方便地计算并显示上述指标。

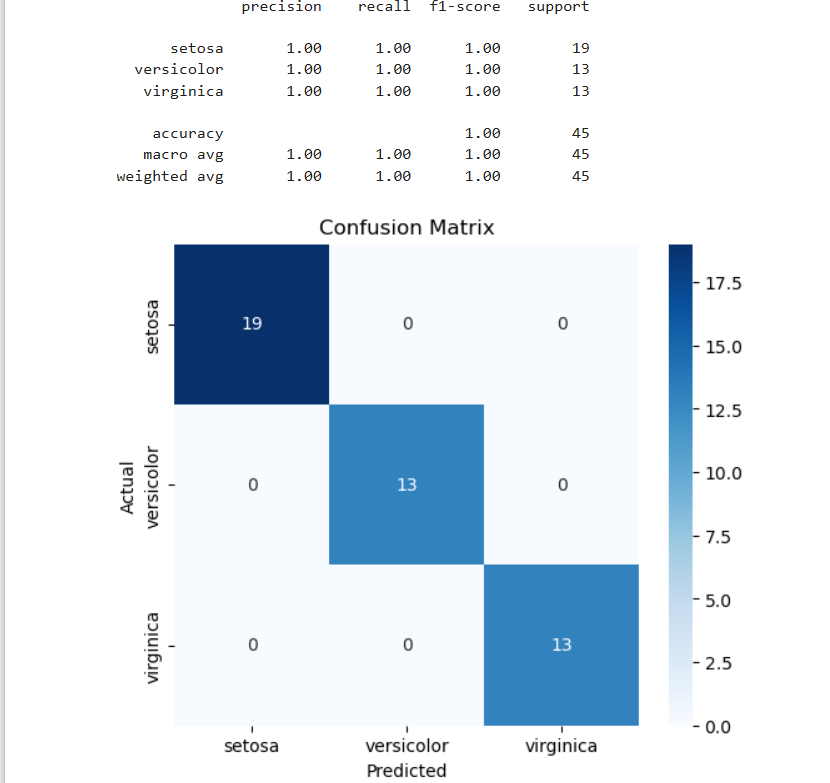
8评估指标公式
准确率(Accuracy):表示模型正确预测的样本占总样本数的比例。
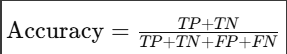
其中,TP(True Positive)为真阳性,TN(True Negative)为真阴性,FP(False Positive)为假阳性,FN(False Negative)为假阴性
精确率(Precision):表示模型预测为正类的样本中,有多少是真正的正类。公式为
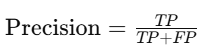
召回率(Recall):表示所有实际为正类的样本中,有多少被模型成功预测为正类。公式为:
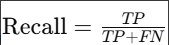
F1-score:是精确率和召回率的调和平均数,用于综合衡量模型的性能。公式为:
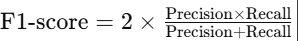
9结果分析
准确率:反映模型在所有样本上的整体预测能力。然而,在类别不平衡的情况下,准确率可能并不能全面反映模型性能。
精确率和召回率:精确率高表示模型预测为正类时,正确性较高;召回率高表示模型能够识别出更多的正类样本。这两个指标常常需要平衡,特别是在类别不平衡的情况下。
F1-score:综合考虑精确率和召回率,适用于类别不平衡的情况。当 F1-score 较高时,说明模型在正类预测上表现良好。
混淆矩阵:提供了模型在各个类别上的预测情况,有助于识别模型在哪些类别上存在问题。
10 使用 GridSearchCV 进行超参数搜索
GridSearchCV 是一种穷举搜索方法,用于遍历给定的超参数网格,找到最佳组合。在使用 GridSearchCV 时,需要定义一个参数网格,其中包含希望搜索的超参数及其候选值。然后,GridSearchCV 会使用交叉验证来评估每组超参数组合的性能。
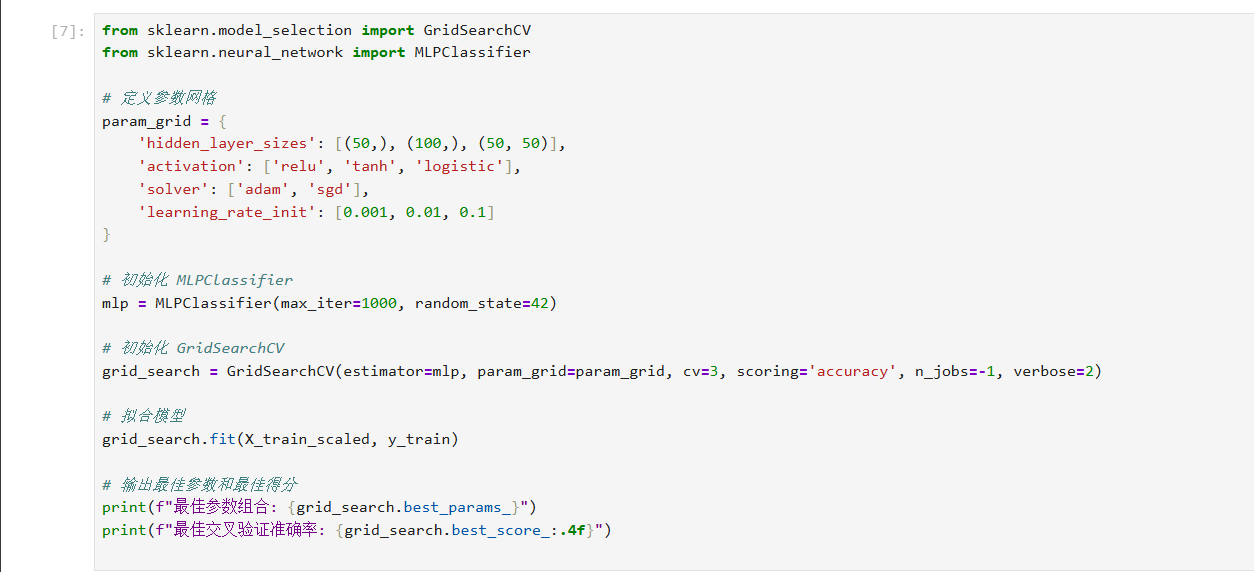

通过上述代码,GridSearchCV 将遍历所有可能的超参数组合,并使用 3 折交叉验证评估每组参数的表现。最终,grid_search.best_params_ 将返回最佳的超参数组合,grid_search.best_score_ 将提供对应的交叉验证准确率。根据这些结果,我们可以分析以下方面:
隐藏层大小:较大的隐藏层可能提高模型的表达能力,但也可能导致过拟合。
激活函数:不同的激活函数对模型的非线性表达能力和训练速度有影响。
学习率:学习率过大会导致训练不稳定,过小则可能导致收敛速度过慢
四、思考:
1. 学习率对模型训练的影响;
答:学习率决定了每次权重更新的步长。过高的学习率可能导致模型无法收敛,甚至发散;过低的学习率则可能导致收敛速度过慢。通常需要通过实验来选择合适的学习率。
- 隐藏层节点数的选择依据是什么?
-
答:隐藏层节点数影响模型的表达能力。节点过少可能导致欠拟合,无法捕捉数据的复杂模式;节点过多可能导致过拟合,模型在训练数据上表现很好,但在新数据上表现差。选择时需要考虑问题的复杂性,并通过交叉验证等方法进行调优。
- 有哪些过拟合的预防方法?
-
答:交叉验证: 使用如k折交叉验证的方法,评估模型在不同数据子集上的表现,减少过拟合的风险。
正则化: 在损失函数中添加正则项,如L1或L2正则化,限制模型的复杂度。
提前停止: 在训练过程中监控验证集的性能,当性能不再提升时,提前停止训练。
数据增强: 增加训练数据的多样性,如对数据进行旋转、缩放等变换,提升模型的泛化能力。
- 还有哪些超参数优化的方法,各自的应用场景及优缺点分别是什么?
-
答:网格搜索(Grid Search): 在预定义的超参数网格上进行穷举搜索,找到最佳组合。优点是简单直观;缺点是计算开销大,尤其在超参数空间较大时。
随机搜索(Random Search): 在超参数空间中随机选择组合进行搜索。相比网格搜索,计算效率更高,但可能错过最佳组合。
贝叶斯优化(Bayesian Optimization): 使用概率模型预测超参数的表现,逐步逼近最优解。优点是能够在较少的尝试中找到较好的超参数;缺点是实现复杂,需要额外的计算资源。
遗传算法(Genetic Algorithm): 模拟自然选择过程,通过选择、交叉和变异操作搜索超参数空间。适用于高维复杂的超参数空间,但计算开销较大。
五、总结:
本实验通过对BP神经网络的构建与调优,帮助我们更好地理解了神经网络的基本原理和实际应用。数据预处理、模型选择、超参数优化以及模型评估等步骤都是构建高效神经网络模型的关键环节。通过不断调整超参数和优化训练过程,我们可以提升模型的准确性和泛化能力。未来,可以继续尝试更复杂的网络结构和更多的超参数调整,以进一步提升模型在复杂任务中的表现。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 56
56 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)