ICML 2025 | 华南理工提出HyperIMTS:用超图神经网络攻克不规则多元时序预测难题!
为解决不规则多元时间序列(IMTS)“变量内时间间隔不规则”与“变量间观测不对齐”的核心挑战,研究提出超图神经网络模型HyperIMTS。该模型无需数据填充,将IMTS观测值转化为超图节点,通过时间超边与变量超边构建统一关联结构,并借助节点-超边、超边-超边、超边-节点三类消息传递,结合不规则感知相似度融合机制,自适应捕捉时间与变量依赖性。
不规则多元时间序列(IMTS)具有变量内时间间隔不规则和变量间观测不对齐的特点,给学习时间和变量依赖性带来挑战。现有IMTS模型或需对样本进行填充以分别学习时间和变量维度信息,导致处理效率降低并破坏原始采样模式;或通过二分图或集合表示原始样本,难以捕捉不对齐观测间的依赖性。为以统一形式表示并学习原始观测中的两种依赖性,华南理工研究人员提出HyperIMTS,一种用于IMTS预测的超图神经网络。该模型将观测值转化为超图中的节点,通过时间超边和变量超边实现所有观测间的消息传递,并借助不规则感知消息传递,以时间自适应方式捕捉变量依赖性,从而实现精准预测。
另外我整理了ICML 2025时间序列相关论文+源码,感兴趣的dd~
论文这里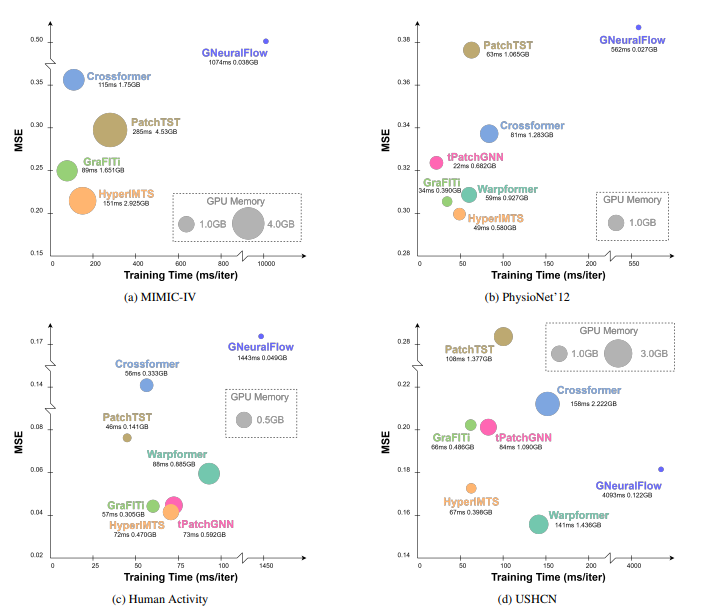
2. 【论文基本信息】

论文标题:HyperIMTS: Hypergraph Neural Network for Irregular Multivariate Time Series Forecasting
作者:Boyuan Li、Yicheng Luo、Zhen Liu、Junhao Zheng、Jianming Lv、Qianli Ma(通讯作者)
作者机构:华南理工大学
论文来源:ICML2025
论文链接:https://arxiv.org/abs/2505.17431v1
项目链接:https://github.com/Ladbaby/PyOmniTS
3.【背景及相关工作】
3.1 研究背景
- MTS的应用与局限:MTS广泛应用于医疗、气象等领域,现有预测方法多假设数据完全观测,未考虑传感器故障等实际问题。
- IMTS的特点与挑战:上述问题导致IMTS产生,其“变量内时间间隔不规则”“变量间观测不对齐”的特征,使精准预测难度大,影响决策。
- 现有IMTS方法不足:
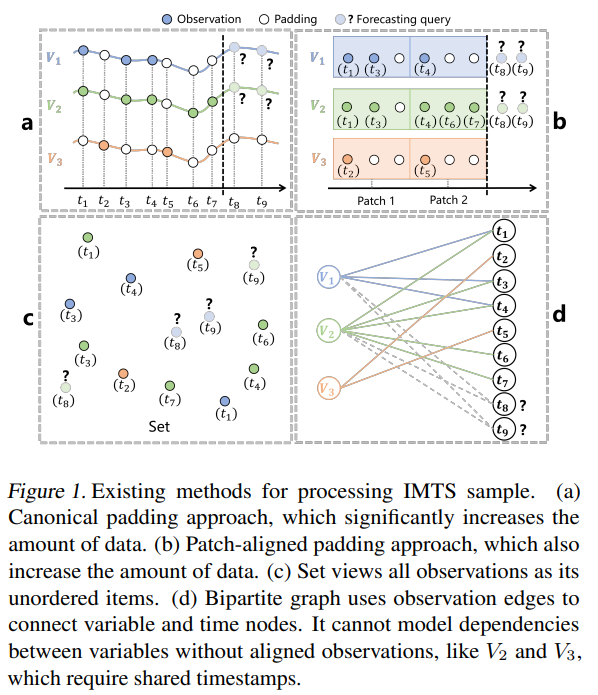
- 填充类:需填充使样本长度一致,虽能捕捉依赖,但增加数据量、降低效率且可能破坏原始采样模式。
- 非填充类:用集合或二分图表示样本,集合无法体现观测相关性,二分图无共享时间戳时难传消息,均难全面捕捉依赖。
3.2 相关工作
- IMTS建模:
- 任务:早期侧重分类与插补,近年预测研究增多。
- 方法:分填充类(依赖RNN、ODE等模型,需处理更多数据)与非填充类(用二分图/集合,无需填充但依赖捕捉受限)。
- 基于图的MTS分析:
- 传统图:将变量作节点、依赖作边,需对齐样本,增加IMTS数据量。
- 超图:超边可连多节点,能体现复杂交互,但超图神经网络在时间序列分析中尚早期,且多假设数据完全观测,不适应IMTS。
4.【研究方法论】
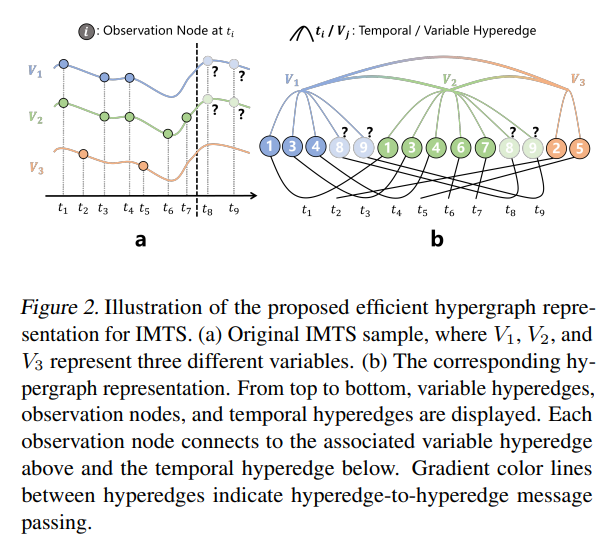
4.1 不规则多元时间序列(IMTS)的高效超图表示
核心是用超图统一建模IMTS的观测与依赖,避免填充带来的问题:
- 超图结构定义:超图 G : = { V , E } G:=\{V, E\} G:={V,E}中, V V V是所有观测对应的节点( M M M个, M M M为观测总数), E E E包含两类超边——时间超边(关联同一时间戳的观测)和变量超边(关联同一变量的观测),实现“一节点连多超边”的灵活关联。
- 关联矩阵量化连接:用 H T H^T HT( M × T M×T M×T)和 H U H^U HU( M × U M×U M×U)两个0-1矩阵,分别标记观测节点与时间超边、变量超边的连接关系,清晰刻画节点与超边的从属关系。
- 嵌入初始化适配特性:
- 观测节点:用 R e L U ( F F o b s ( ⋅ ) ) ReLU(FF_{obs}(\cdot)) ReLU(FFobs(⋅))编码观测值,预测目标初始设为0,确保初始信息贴合数据分布。
- 时间超边:结合线性映射与正弦编码,保留时间戳的周期性与连续性特征。
- 变量超边:用可学习参数初始化,为后续学习变量依赖预留优化空间。
4.2 HyperIMTS的预测流程
通过三类消息传递逐步优化嵌入,最终实现预测,核心是“从节点到超边聚合信息,再从超边到节点传递信息”: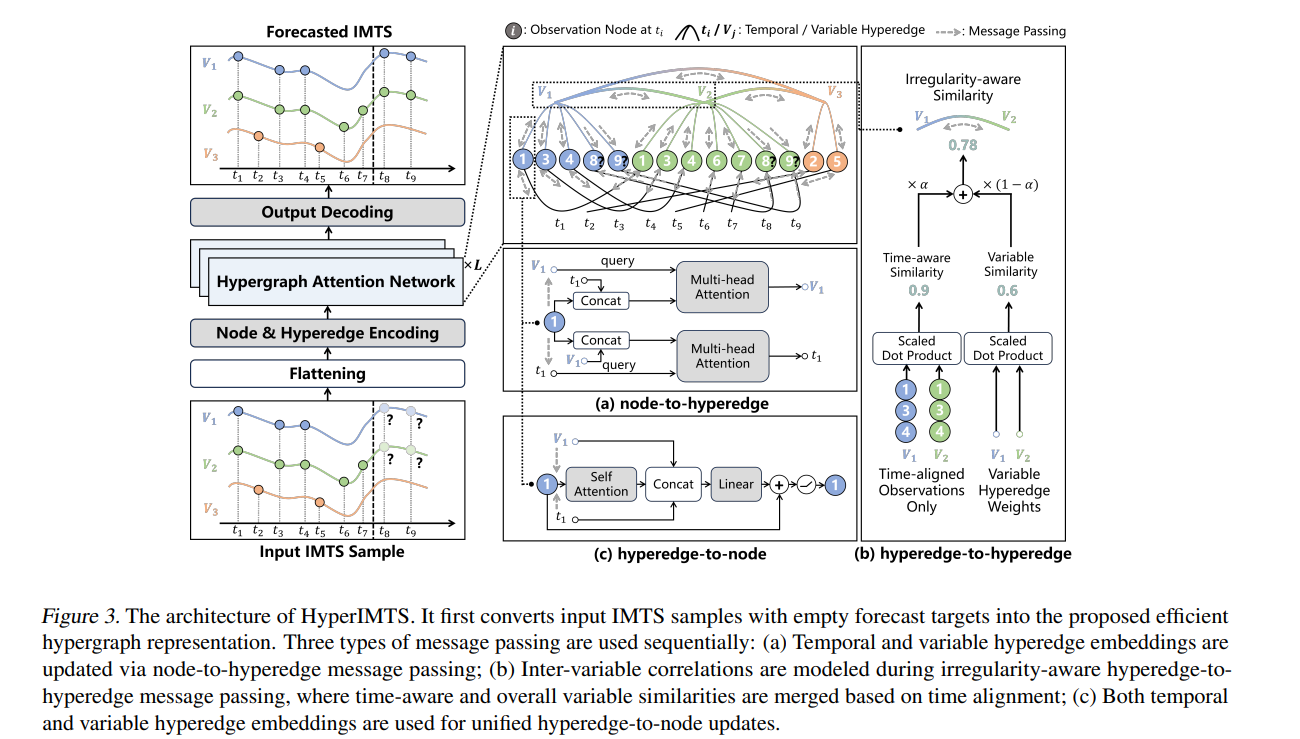
4.2.1 时间与变量超边更新(节点→超边)
- 时间超边更新:以时间超边为查询,观测节点与变量超边的拼接结果为键和值,通过多头注意力(公式 O = ∥ h = 1 H S o f t m a x ( q h k h ⊤ d / H ) v h O=\| _{h=1}^{H} Softmax\left(\frac{q^{h} k^{h^{\top}}}{\sqrt{d / H}}\right) v^{h} O=∥h=1HSoftmax(d/Hqhkh⊤)vh)聚合节点信息,再经残差连接更新超边嵌入,让时间超边捕捉该时间戳下的多变量综合特征。
- 变量超边更新:类似地,以变量超边为查询,结合观测节点与时间超边信息,更新变量超边嵌入,使其包含该变量在不同时间的观测规律。
4.2.2 变量间消息传递(超边→超边)
针对IMTS“观测不对齐”痛点,动态计算变量相似度:
- 双维度相似度计算:先算“整体变量相似度”(基于超边嵌入,体现变量全局关联),再算“时间感知相似度”(仅用对齐观测,避免不对齐数据干扰)。
- 自适应融合:根据共享时间戳占比( T s h a r e d / T t o t a l T_{shared}/T_{total} Tshared/Ttotal)和变量相似度阈值( δ = 0.5 \delta=0.5 δ=0.5),用系数 α \alpha α融合两种相似度(公式 S I M T S = α S o b s + ( 1 − α ) S v a r S_{IMTS }=\alpha S_{obs }+(1-\alpha) S_{var} SIMTS=αSobs+(1−α)Svar),再通过注意力更新变量超边,让变量依赖学习适配不规则性。
4.2.3 节点更新(超边→节点)
分阶段学习不同依赖,提升预测精准度:
- 残差层分工:前 L − 1 L-1 L−1层用未更新的变量超边,专注学习同一变量内的时间依赖;最后一层用更新后的变量超边,融入跨变量依赖。
- 节点优化:先对节点做自注意力,再拼接时间、变量超边信息(公式 V ′ ′ = R e L U ( V + F F n o d e ( V ′ ∥ E t i m e ′ ∥ E v a r ′ ) ) V''=ReLU\left(V+FF_{node }\left(V'\left\| E_{time }' \right\| E_{var }'\right)\right) V′′=ReLU(V+FFnode(V′∥Etime′∥Evar′))),让节点嵌入同时包含时间与变量特征。
4.2.4 训练与解码
- 预测解码:拼接节点与两类超边的最终嵌入,通过线性映射(公式 Z ^ i = F F o u t ( V ′ ′ ∣ ∣ E t i m e ′ ∥ E v a r ′ ′ ) \hat{\mathcal{Z}}_{i}=FF_{out }\left(V''|| E_{time }' \| E_{var }''\right) Z^i=FFout(V′′∣∣Etime′∥Evar′′))输出预测值,确保融合所有学习到的依赖信息。
- 损失优化:用MSE损失最小化预测值与真实值差异,保证预测误差可控。
4.2.5 计算复杂度优势
虽依赖注意力机制,但通过“只处理真实观测”降低数据量:
- 核心复杂度:注意力计算中,查询、键的线性映射及点积操作复杂度与数据规模挂钩,但HyperIMTS无需处理填充数据, M M M(观测数)远小于填充后的样本量。
- 模块效率:各环节的 N q N_q Nq(查询数量)、 N k N_k Nk(键数量)均基于真实数据维度(如变量数 U U U、时间戳数 T T T),相比填充类方法,计算量与内存占用显著降低。
5.【实验结果】
5.1 实验设置
- 数据集:采用5个跨领域IMTS数据集(医疗:MIMIC-III/IV、PhysioNet’12;生物力学:Human Activity;气候:USHCN),涵盖不同时间粒度与变量数量,按8:1:1划分为训练/验证/测试集,部分数据集预处理遵循现有研究方案。
- 基线模型:选取27个基线,涵盖MTS预测(如FEDformer、Autoformer)、时间序列预训练(如MOIRAI)、IMTS专用(如GraFITi、GRU-D)等类型,构建统一评估 pipeline 确保公平性。
- 实现细节:基于PyTorch训练,使用RTX 3090/2080Ti GPU;学习率在epoch>3时按 L n = L 0 × 0.8 n − 3 L_{n}=L_{0}×0.8^{n-3} Ln=L0×0.8n−3调整,最大epoch=300,早停耐心=10;用5个随机种子(2024-2028)控制随机性,以MSE为主要损失函数(部分模型用原论文自定义损失)。
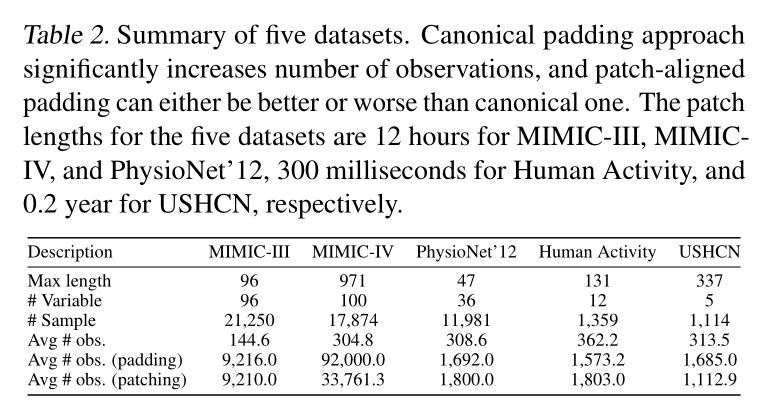
5.2 主要预测性能
- 整体表现:在5个数据集的MSE评估中,HyperIMTS在4个数据集上排名第一,仅USHCN因数据高方差表现稍逊;相比次优模型GraFITi,最高提升11.4%,且平均MSE显著低于最优常规时间序列模型Crossformer。
- 关键发现:部分常规时间序列模型优于部分IMTS模型,说明需同时评估两类模型;时间序列预训练模型(MOIRAI、PrimeNet)表现一般,提示常规与IMTS数据集的预训练适配性需优化。
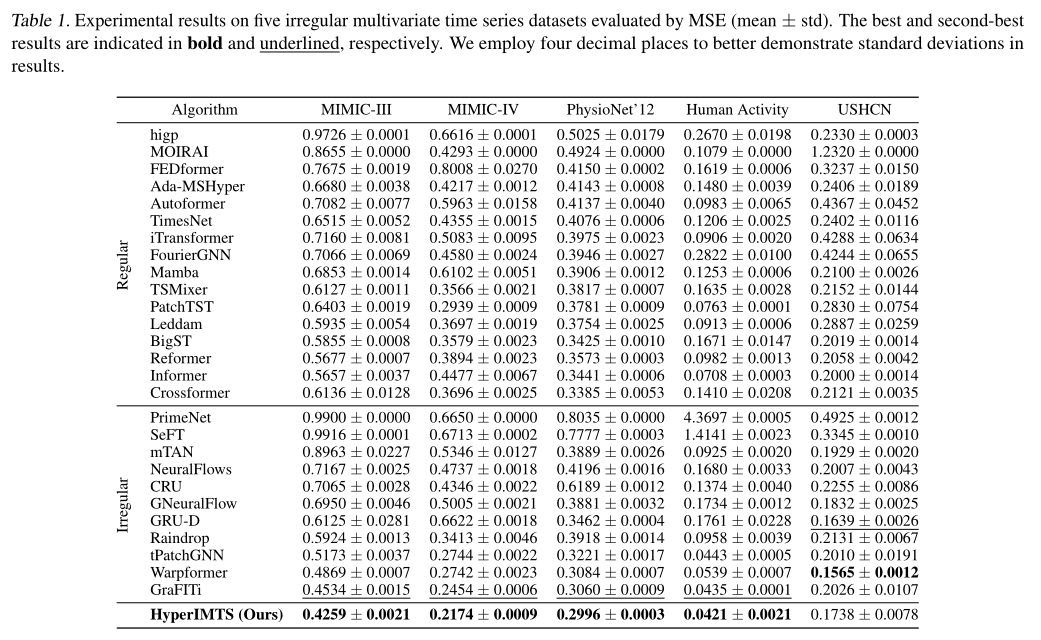
5.3 消融实验
针对HyperIMTS的核心组件设计5种变体,验证各组件必要性(结果基于MSE):
- 变量超边(VE):移除变量超边(w/o VE)后,各数据集MSE大幅上升(如MIMIC-III从0.4259升至0.9556),证明变量超边对捕捉变量依赖的关键作用。
- 不规则感知变量依赖(IAVD):移除(w/o IAVD)或替换(rp IAVD)IAVD后,MSE均高于完整模型,说明不规则感知机制能适配IMTS的观测不对齐特性。
- 时间超边(TE):移除时间超边(w/o TE)或用非可学习正弦嵌入替换(rp TE)后,性能下降,验证可学习时间超边对利用时间信息的重要性。
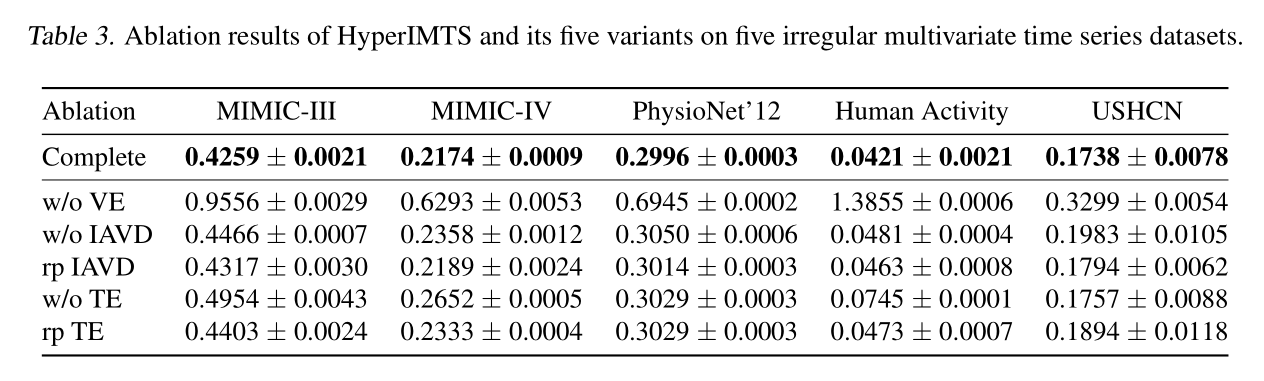
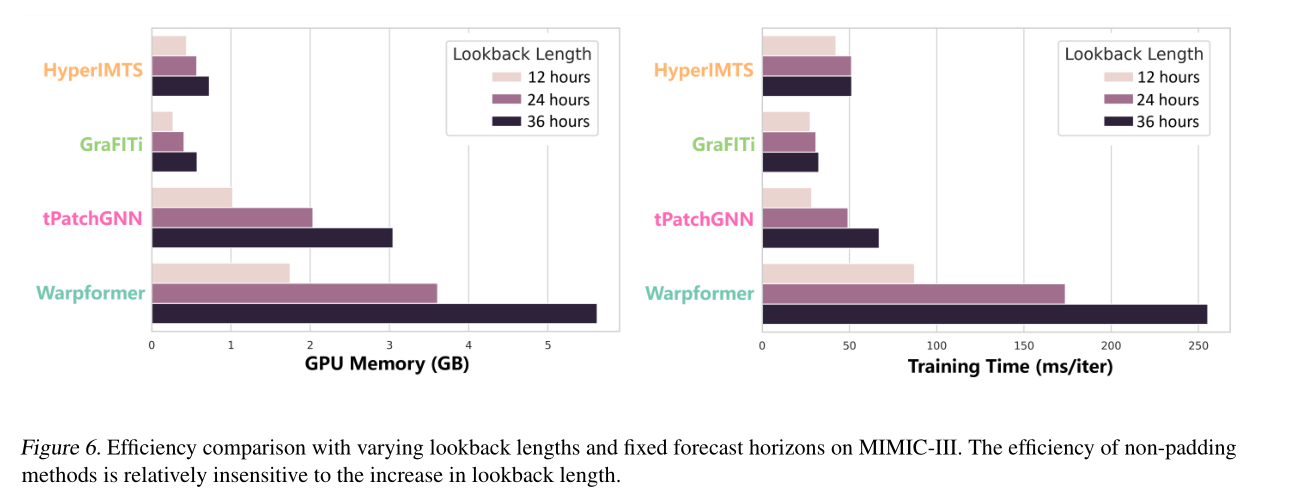
5.4 效率分析
以MIMIC-III为核心案例,从训练时间、GPU内存占用维度对比模型效率:
-
性能与效率平衡:HyperIMTS在取得最低MSE的同时,训练时间与内存占用较低;非填充模型(HyperIMTS、GraFITi)训练速度显著快于填充类模型(如Warpformer、GNeuralFlow)。
-
填充方法局限:块对齐填充模型(tPatchGNN)虽比常规填充快,但内存占用仍较高;Transformer类模型(如Crossformer、PatchTST)因处理填充数据,内存消耗大;ODE类模型(GNeuralFlow)内存低但训练耗时极长。
-
扩展性优势:非填充模型(含HyperIMTS)的效率对回溯长度变化不敏感,而填充类模型效率随回溯长度增加快速下降,更适配长序列IMTS场景。
6.【总结展望】
6.1 总结
为解决不规则多元时间序列(IMTS)“变量内时间间隔不规则”与“变量间观测不对齐”的核心挑战,研究提出超图神经网络模型HyperIMTS。该模型无需数据填充,将IMTS观测值转化为超图节点,通过时间超边与变量超边构建统一关联结构,并借助节点-超边、超边-超边、超边-节点三类消息传递,结合不规则感知相似度融合机制,自适应捕捉时间与变量依赖性。在5个跨领域IMTS数据集(医疗、生物力学、气候)上的实验表明,HyperIMTS在MSE指标上优于27个基线模型,4个数据集排名第一,且具有更低计算成本,验证了其在IMTS预测任务中的有效性与效率。
6.2 展望
当前HyperIMTS仍存在两方面局限有待突破:一是暂不支持文本、图像等多模态数据,而此类数据在医疗等IMTS场景中常见,未来可探索多模态信息融合以提升预测能力;二是模型依赖的注意力计算相较于状态空间等方法资源消耗更高,后续可研究更高效的依赖建模机制以优化性能。此外,针对不同领域IMTS数据集的特性差异,进一步优化模型适配性与泛化能力,也是未来值得深入的方向。
7.【项目复现指南】
7.1 克隆代码仓库
首先进入目标项目路径,通过Git命令克隆PyOmniTS仓库至本地,具体操作如下:
cd /path/to/your/project
git clone https://github.com/Ladbaby/PyOmniTS.git
7.2 配置运行环境
7.2.1 创建并激活虚拟环境
使用Miniconda/Anaconda工具创建Python虚拟环境(推荐Python 3.10~3.11版本,已通过兼容性测试),并激活该环境,命令示例如下:
# 创建虚拟环境
conda create -n pyomnits python=3.11
# 激活虚拟环境
conda activate pyomnits
7.2.2 安装依赖包
通过pip命令安装项目所需依赖,依赖清单记录于requirements.txt文件中。需注意,部分包仅用于特定模型或数据集,为可选依赖,具体可参考requirements.txt中的注释说明,安装命令如下:
pip install -r requirements.txt
7.3 准备数据集
根据数据类型(规则时间序列、不规则时间序列),按以下步骤准备数据集,确保数据路径符合项目预期结构。
7.3.1 规则时间序列数据集
从Time-Series-Library提供的Google Drive获取数据集,包含ECL(电力)、ETTh1/ETTm1(ETT-small)、ILI(疾病)、Traffic(交通)、Weather(气象),将数据集放置于项目的storage/datasets文件夹下(若文件夹不存在需手动创建,或通过符号链接ln -s指向已有的数据集文件)。最终数据结构如下:
storage/datasets/
├── electricity
│ └── electricity.csv
├── ETT-small
│ ├── ETTh1.csv
│ ├── ETTh2.csv
│ ├── ETTm1.csv
│ └── ETTm2.csv
├── illness
│ └── national_illness.csv
├── traffic
│ └── traffic.csv
└── weather
└── weather.csv
7.3.2 不规则时间序列数据集
7.3.2.1 Human Activity数据集
无需提前手动准备,代码在训练时会自动下载并预处理该数据集。预处理完成后,storage/datasets目录下将生成如下结构:
storage/datasets/
└── HumanActivity
├── processed
│ └── data.pt
└── raw
└── ConfLongDemo_JSI.txt
7.3.2.2 MIMIC III数据集
该数据集需授权访问,操作步骤如下:
- 从官方平台申请原始数据;
- 数据预处理(二选一):
- 方案1:使用PyOmniTS中的修订脚本。需创建Python 3.7虚拟环境,安装指定版本依赖后运行预处理脚本:
# 创建并激活Python 3.7虚拟环境 conda create -n python37 python=3.7 conda activate python37 # 安装指定版本依赖 pip install numpy==1.21.6 pandas==1.3.5 # 运行预处理脚本 python data/dependencies/MIMIC_III/preprocess/0_run_all.py - 方案2:使用gru_ode_bayes中的原始脚本。按该项目流程处理得到
complete_tensor.csv,并将其放置于~/.tsdm/rawdata/MIMIC_III_DeBrouwer2019/complete_tensor.csv路径下。
- 方案1:使用PyOmniTS中的修订脚本。需创建Python 3.7虚拟环境,安装指定版本依赖后运行预处理脚本:
预处理完成后,~/.tsdm目录下将生成如下结构:
~/.tsdm/
├── datasets
│ └── MIMIC_III_DeBrouwer2019
│ ├── metadata.parquet
│ └── timeseries.parquet
└── rawdata
└── MIMIC_III_DeBrouwer2019
└── complete_tensor.csv
7.3.2.3 MIMIC IV数据集
该数据集同样需授权访问,操作步骤如下:
- 从官方平台申请原始数据;
- 数据预处理(二选一):
- 方案1:使用PyOmniTS中的修订脚本。创建Python 3.7虚拟环境,安装指定版本依赖后运行脚本:
# 创建并激活Python 3.7虚拟环境 conda create -n python37 python=3.7 conda activate python37 # 安装指定版本依赖 pip install numpy==1.21.6 pandas==1.3.5 # 运行预处理脚本 python data/dependencies/MIMIC_IV/preprocess/0_run_all.py - 方案2:使用NeuralFlows中的原始脚本。按该项目流程处理得到
full_dataset.csv,并将其放置于~/.tsdm/rawdata/MIMIC_IV_Bilos2021/full_dataset.csv路径下。
- 方案1:使用PyOmniTS中的修订脚本。创建Python 3.7虚拟环境,安装指定版本依赖后运行脚本:
预处理完成后,~/.tsdm目录下将生成如下结构:
~/.tsdm/
├── datasets
│ └── MIMIC_IV_Bilos2021
│ └── timeseries.parquet
└── rawdata
└── MIMIC_IV_Bilos2021
└── full_dataset.csv
7.3.2.4 PhysioNet’12数据集
无需提前手动准备,代码在训练时会自动下载并预处理该数据集。预处理完成后,~/.tsdm目录下将生成如下结构:
~/.tsdm/
├── datasets
│ └── Physionet2012
│ ├── Physionet2012-set-A-sparse.tar
│ ├── Physionet2012-set-B-sparse.tar
│ └── Physionet2012-set-C-sparse.tar
└── rawdata
└── Physionet2012
├── set-a.tar.gz
├── set-b.tar.gz
└── set-c.tar.gz
7.3.2.5 USHCN数据集
无需提前手动准备,代码在训练时会自动下载并预处理该数据集。预处理完成后,~/.tsdm目录下将生成如下结构:
~/.tsdm/
├── datasets
│ └── USHCN_DeBrouwer2019
│ └── USHCN_DeBrouwer2019.parquet
└── rawdata
└── USHCN_DeBrouwer2019
└── small_chunked_sporadic.csv
7.4 模型训练
训练脚本存放于项目的scripts文件夹中,不同模型对应不同子目录。以在Human Activity数据集上训练mTAN模型为例,运行如下命令即可启动训练:
sh scripts/mTAN/HumanActivity.sh
训练结果将按storage/results/DATASET_NAME/MODEL_NAME/MODEL_ID_TIME的路径结构自动整理存储。
7.5 模型测试
训练流程结束后,代码会自动执行测试步骤。若仅需单独运行测试,需将训练脚本中的命令行参数--is_training从1修改为0,再运行该脚本。测试完成后,包含测试指标的metric.json文件将保存于storage/results/DATASET_NAME/MODEL_NAME/MODEL_ID_TIME/eval_TIME路径下。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)