基于深度学习YOLOv8和YOLOv5的药丸缺陷检测药片缺陷检测药片质量缺陷识别药丸污染破损
摘要:本项目基于YOLOv8/YOLOv5构建了一个高精度视觉检测系统,包含2700+张标注数据集(污染/破损/良好三类),训练模型精确率达98.8%。系统支持图片/视频/摄像头多模态检测,提供模型切换、参数调节(CONF/IOU)、目标统计、结果保存等功能,配备用户登录界面和可视化UI,完整代码及资源已开源。
·
获取完整资源,请查看个人主页的个人简介
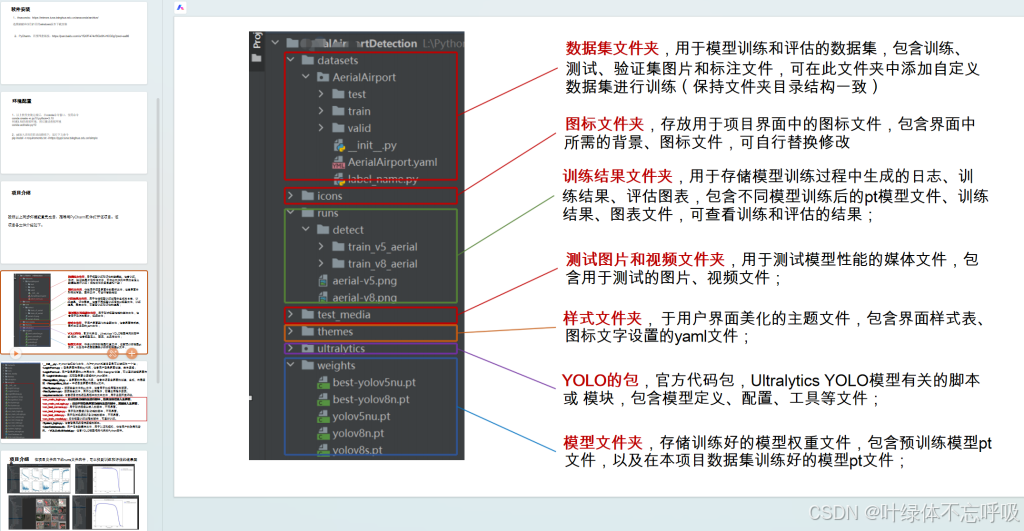
1、数据集(已全部标注)
2、训练好的模型(pt文件和图表)
3、完整系统UI界面、文件目录说明、程序运行说明
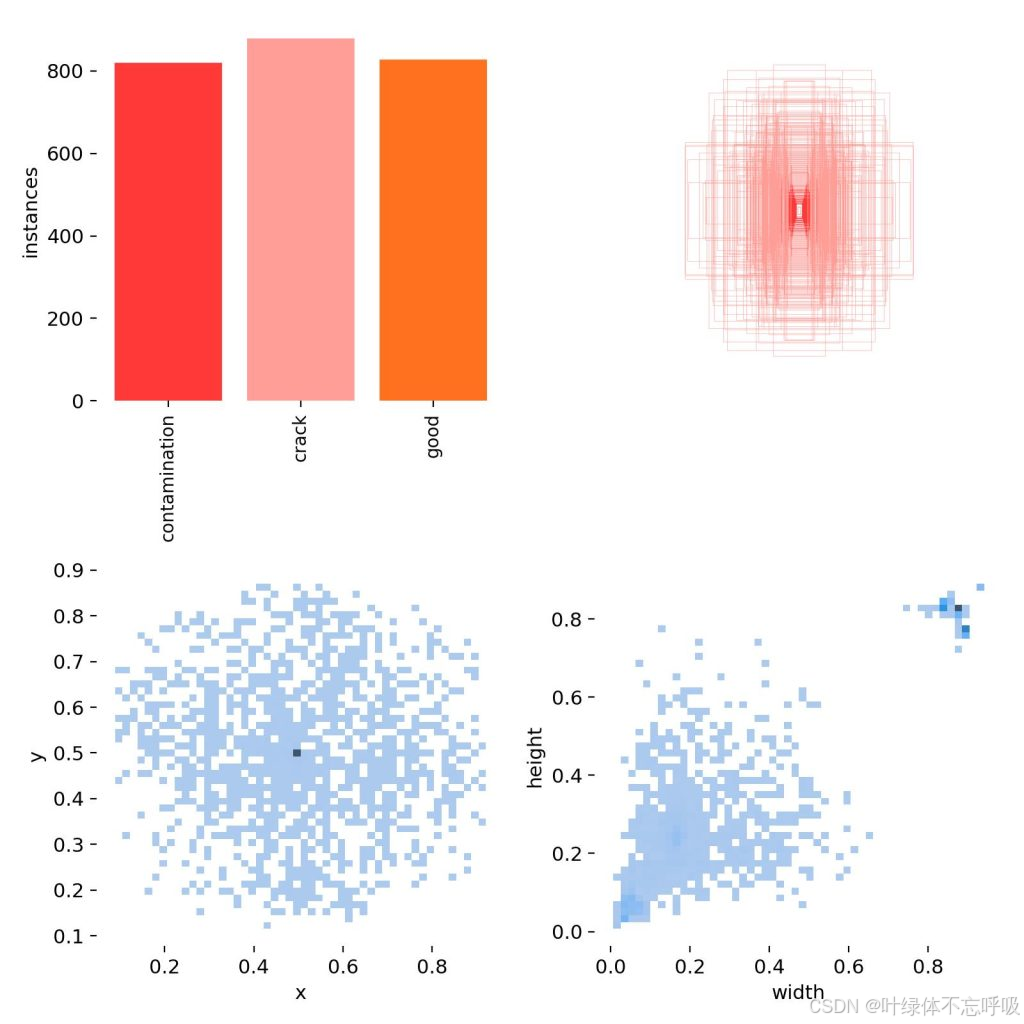
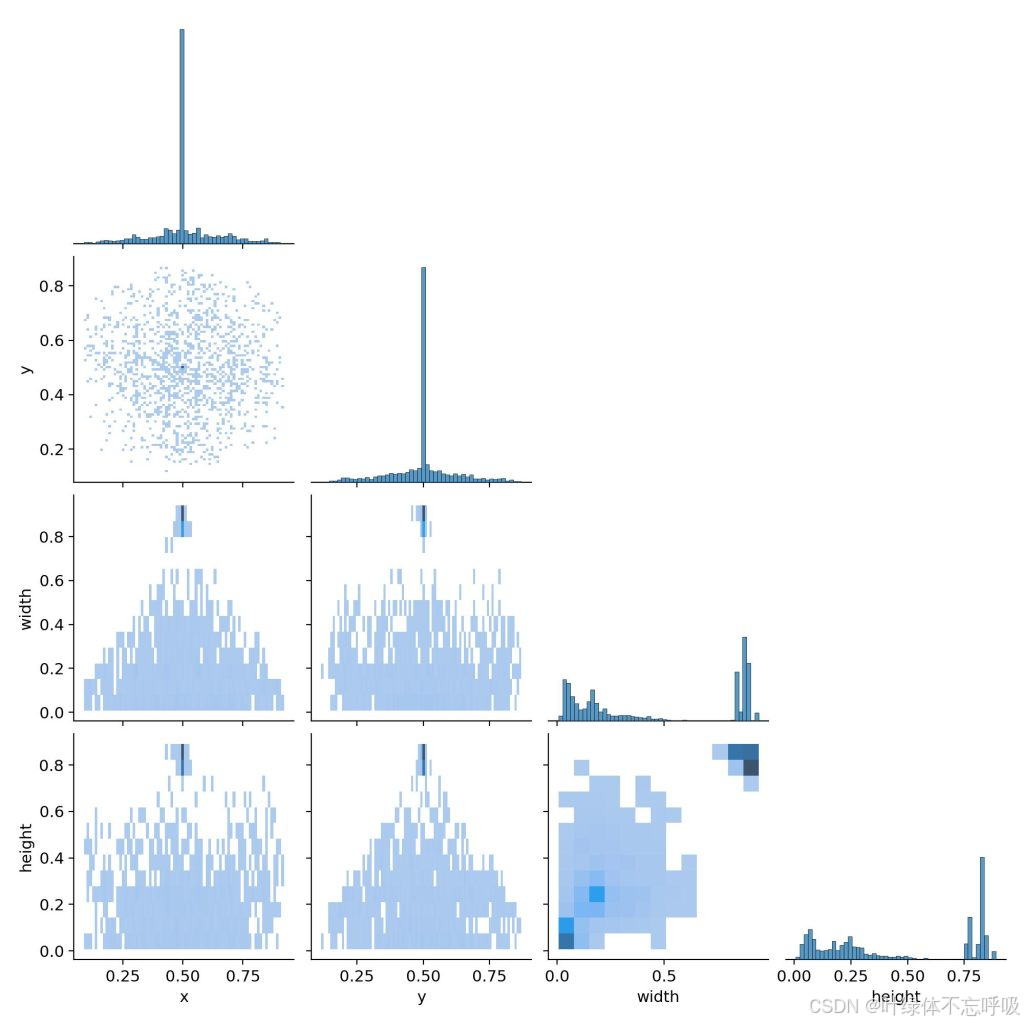
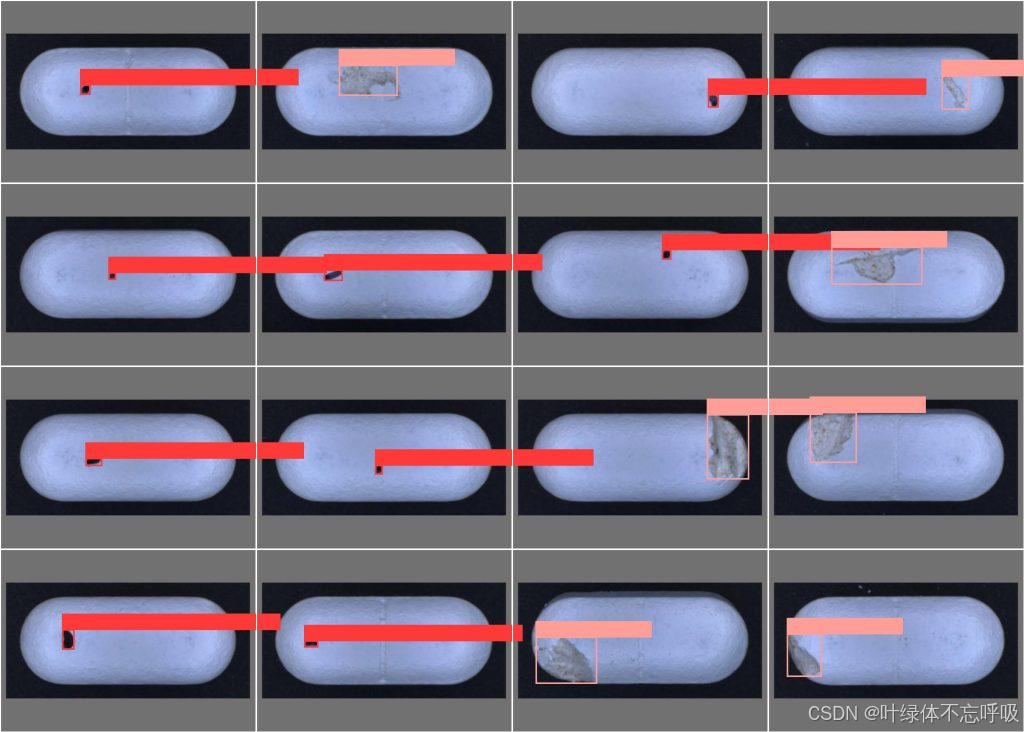
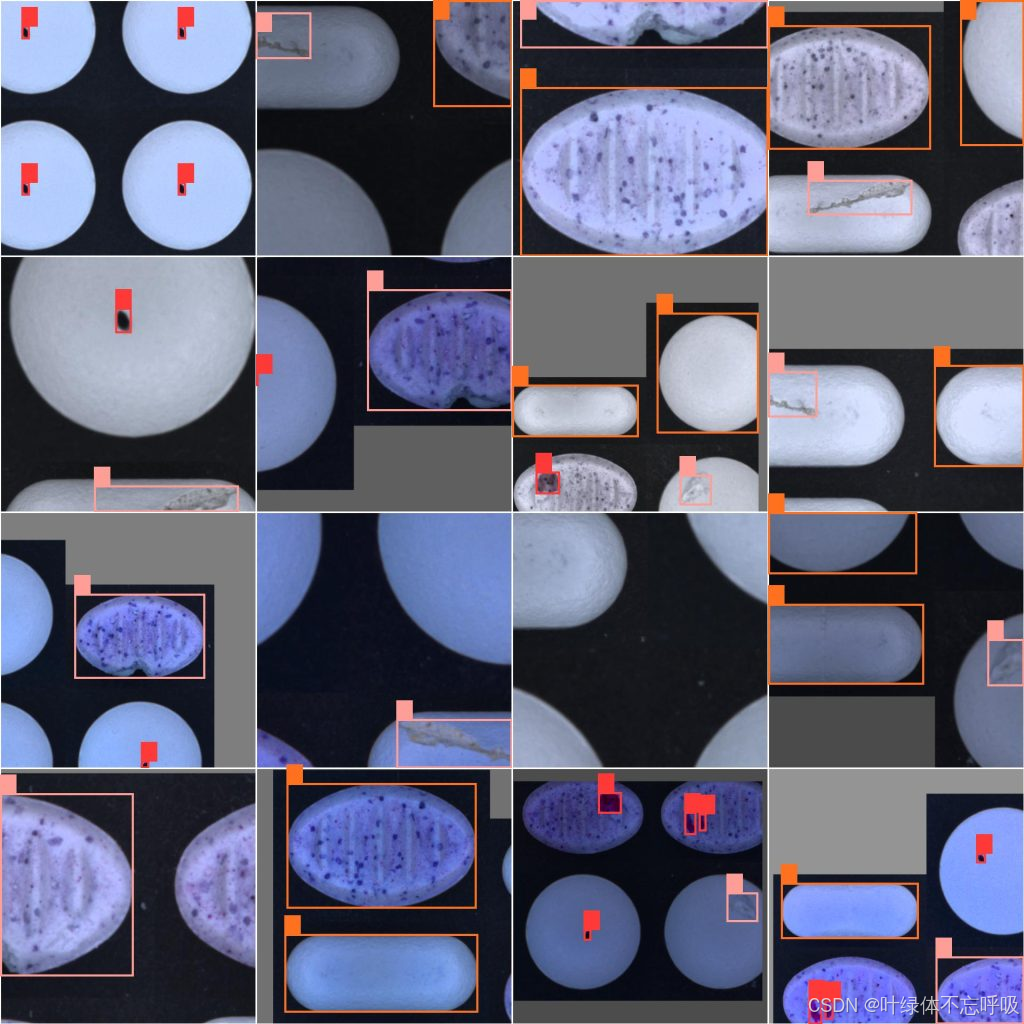
一、数据集介绍
1、数量:2700+张图片和对应标签
2、类别:‘contamination’: “污染”, ‘crack’: “破损”, ‘good’: “良好”
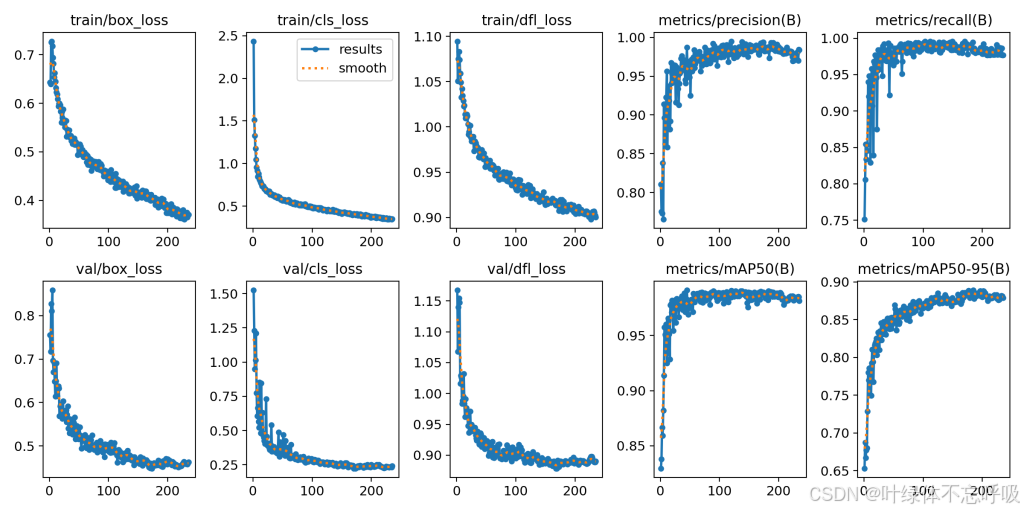
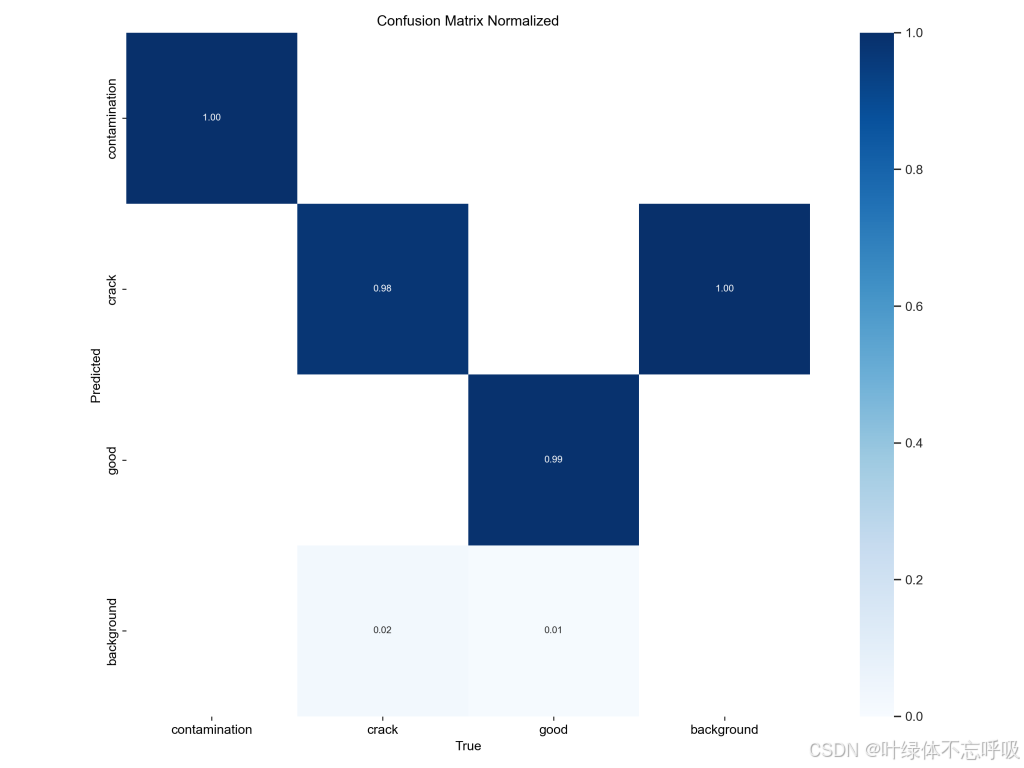
二、训练好的模型介绍
1、基于YOLOv8和YOLOv5训练的2个模型
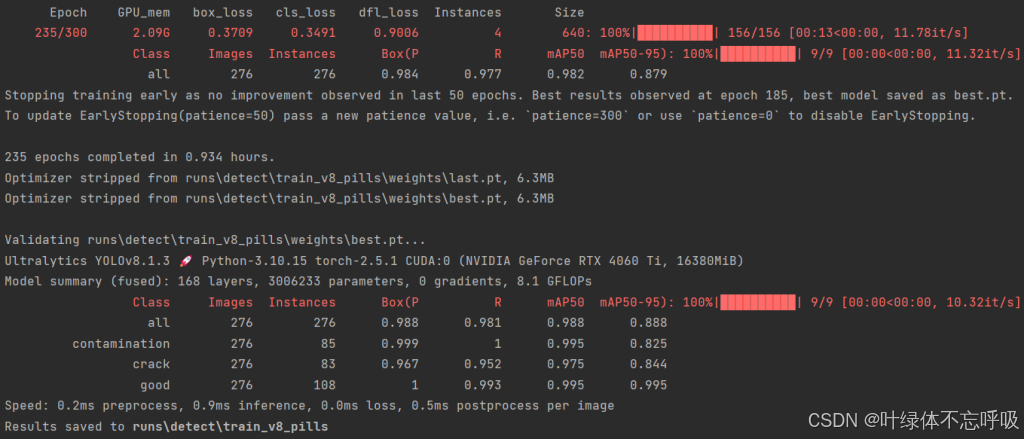
2、训练轮数:235轮
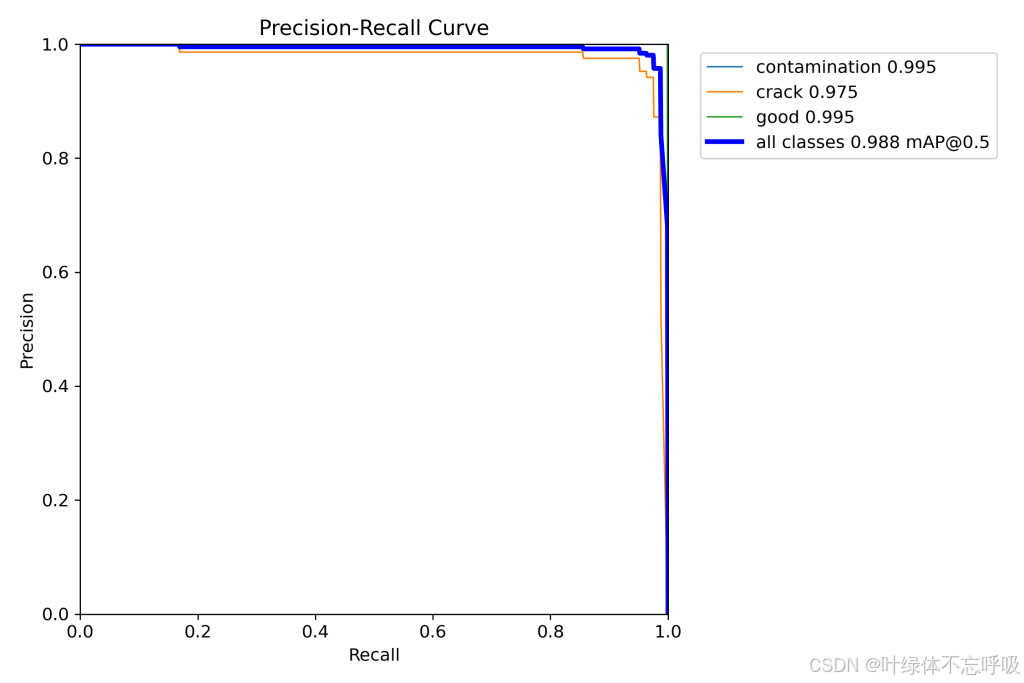
3、精确率:98.8%
三、完整系统介绍
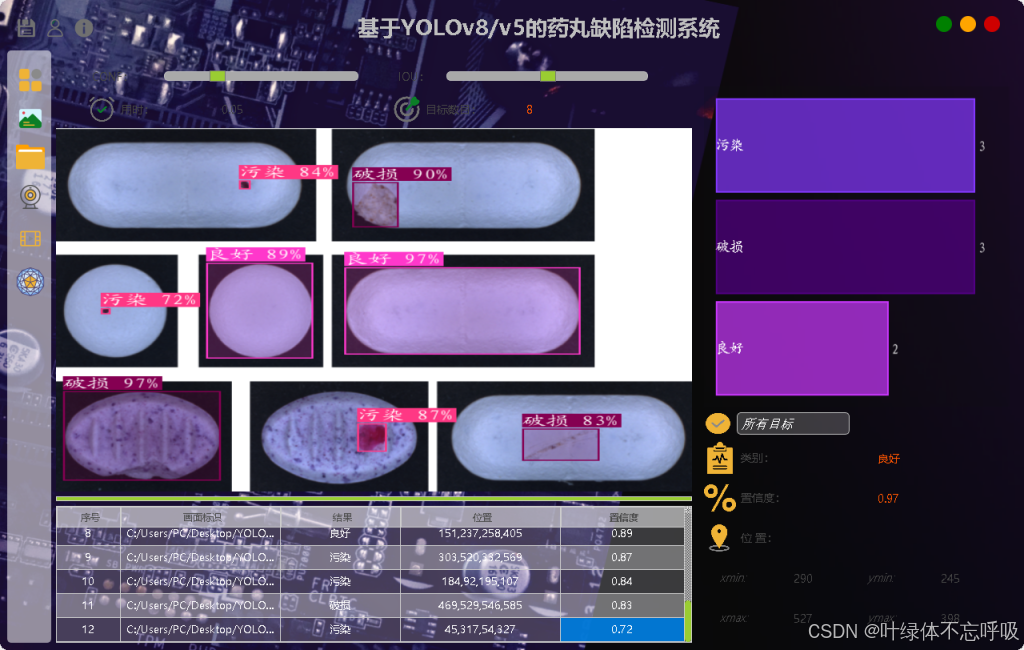
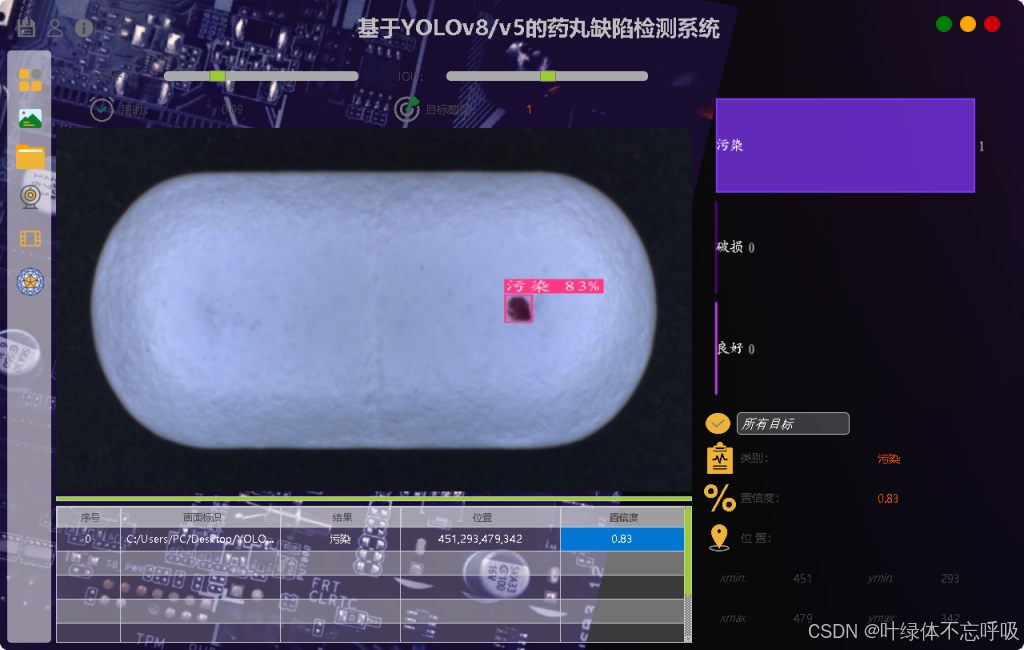
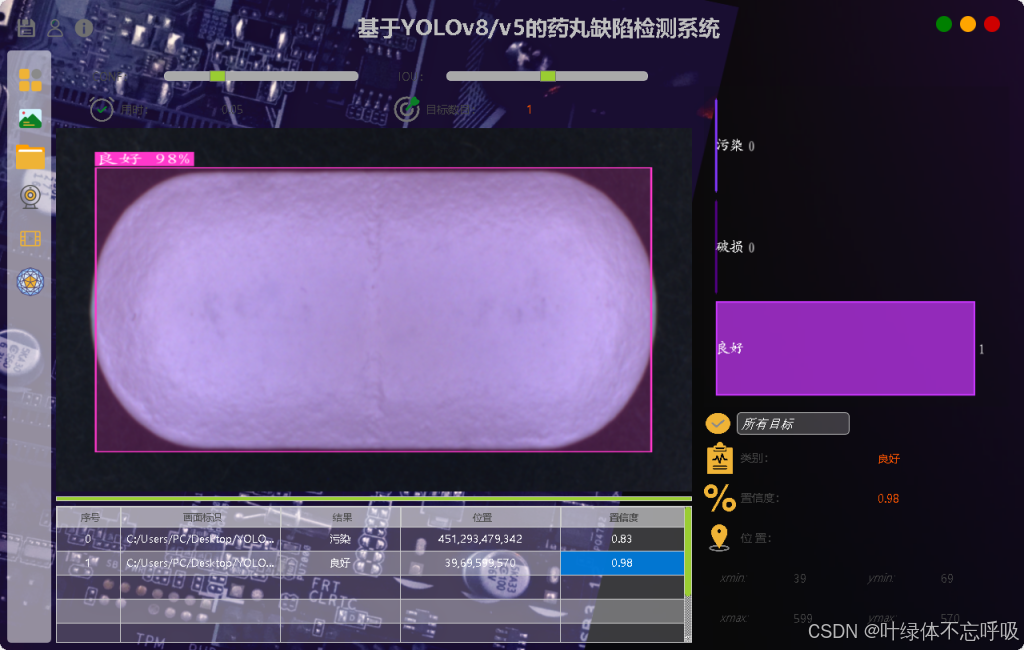
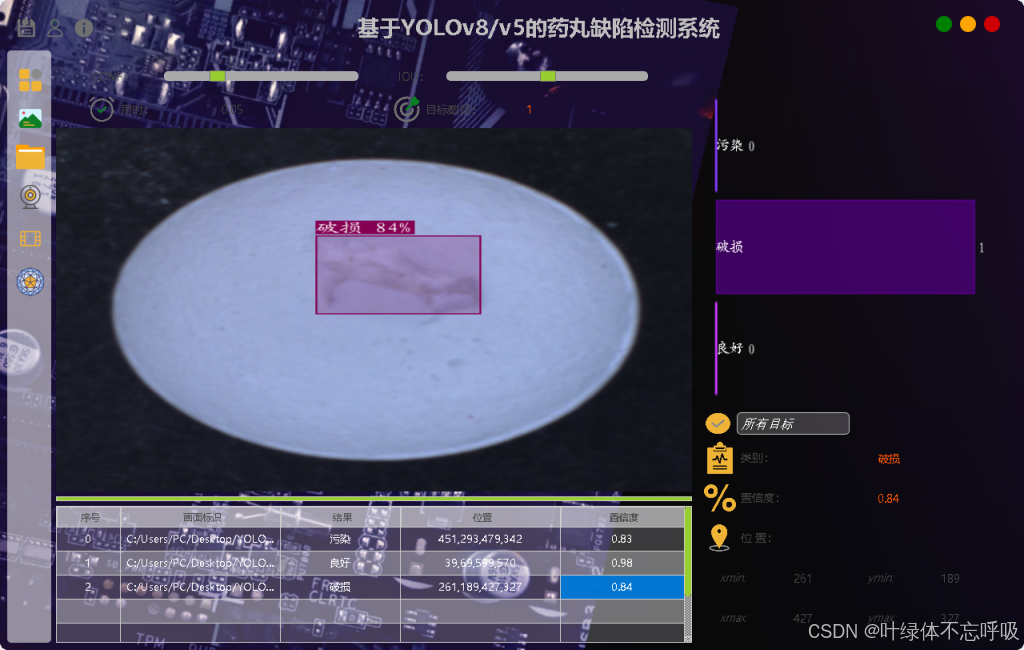
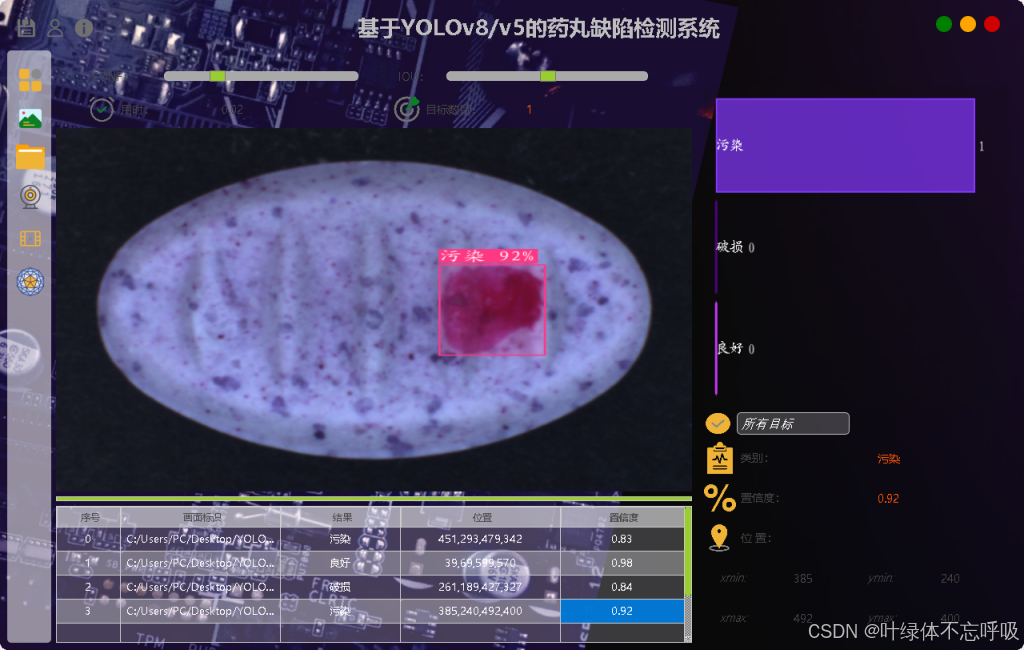
1、检测:‘contamination’: “污染”, ‘crack’: “破损”, ‘good’: “良好”
2、图片检测+视频检测+摄像头检测+自由切换检测模型+自由调整CONF和IOU
3、展示检测目标置信度位置信息,统计数量,自由选择检测结果
4、检测结果保存至本地
5、自定义系统标题
6、自定义系统图标
7、用户登录系统




部分源码
# -*- coding: utf-8 -*-
import cv2 # 导入OpenCV库,用于处理图像和视频
import torch
from QtFusion.models import Detector, HeatmapGenerator # 从QtFusion库中导入Detector抽象基类
from datasets.pills.label_name import Chinese_name # 从datasets库中导入Chinese_name字典,用于获取类别的中文名称
from ultralytics import YOLO # 从ultralytics库中导入YOLO类,用于加载YOLO模型
from ultralytics.utils.torch_utils import select_device # 从ultralytics库中导入select_device函数,用于选择设备
device = "cuda:0" if torch.cuda.is_available() else "cpu"
ini_params = {
'device': device, # 设备类型,这里设置为CPU
'conf': 0.25, # 物体置信度阈值
'iou': 0.5, # 用于非极大值抑制的IOU阈值
'classes': None, # 类别过滤器,这里设置为None表示不过滤任何类别
'verbose': False
}
def count_classes(det_info, class_names):
"""
Count the number of each class in the detection info.
:param det_info: List of detection info, each item is a list like [class_name, bbox, conf, class_id]
:param class_names: List of all possible class names
:return: A list with counts of each class
"""
count_dict = {name: 0 for name in class_names} # 创建一个字典,用于存储每个类别的数量
for info in det_info: # 遍历检测信息
class_name = info['class_name'] # 获取类别名称
if class_name in count_dict: # 如果类别名称在字典中
count_dict[class_name] += 1 # 将该类别的数量加1
# Convert the dictionary to a list in the same order as class_names
count_list = [count_dict[name] for name in class_names] # 将字典转换为列表,列表的顺序与class_names相同
return count_list # 返回列表
class YOLOv8v5Detector(Detector): # 定义YOLOv8Detector类,继承自Detector类
def __init__(self, params=None): # 定义构造函数
super().__init__(params) # 调用父类的构造函数
self.model = None
self.img = None # 初始化图像为None
self.names = list(Chinese_name.values()) # 获取所有类别的中文名称
self.params = params if params else ini_params # 如果提供了参数则使用提供的参数,否则使用默认参数
def load_model(self, model_path): # 定义加载模型的方法
self.device = select_device(self.params['device']) # 选择设备
self.model = YOLO(model_path, )
names_dict = self.model.names # 获取类别名称字典
self.names = [Chinese_name[v] if v in Chinese_name else v for v in names_dict.values()] # 将类别名称转换为中文
self.model(torch.zeros(1, 3, *[self.imgsz] * 2).to(self.device).
type_as(next(self.model.model.parameters()))) # 预热
self.model(torch.rand(1, 3, *[self.imgsz] * 2).to(self.device).
type_as(next(self.model.model.parameters()))) # 预热
def preprocess(self, img): # 定义预处理方法
self.img = img # 保存原始图像
return img # 返回处理后的图像
def predict(self, img): # 定义预测方法
results = self.model(img, **ini_params)
return results
def postprocess(self, pred): # 定义后处理方法
results = [] # 初始化结果列表
for res in pred[0].boxes:
for box in res:
# 提前计算并转换数据类型
class_id = int(box.cls.cpu())
bbox = box.xyxy.cpu().squeeze().tolist()
bbox = [int(coord) for coord in bbox] # 转换边界框坐标为整数
result = {
"class_name": self.names[class_id], # 类别名称
"bbox": bbox, # 边界框
"score": box.conf.cpu().squeeze().item(), # 置信度
"class_id": class_id, # 类别ID
}
results.append(result) # 将结果添加到列表
return results # 返回结果列表
def set_param(self, params):
self.params.update(params)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)