半导体数据分析:GPR算法小白入门(四)晶圆测试数据模拟算法详解
各位,前面我们通过三篇文章,介绍了 GPR算法的基本概念和典型应用,以及在这当中,我们还学习了如何通过算法来模拟晶体管的IV曲线。我们的目标其实是使用GPR算法来分析半导体行业的数据,比如晶圆测试数据。
有一个情况是,公司的测试数据是不允许公布到外面的,所以我们在做算法分析的时候,很难获取到产线中的真实数据,不过没关系,我们可以通过算法来模拟这些数据啊!今天我们就一起来尝试:用算法来模拟晶圆测试数据!
摘要:本文详细介绍了一种基于Python的晶圆测试数据模拟算法,该算法能够生成真实的半导体晶圆测试数据,包括空间相关性、工艺变异、异常注入等特征。通过面向对象的设计和科学的数学模型,为半导体测试工程师提供了一个强大的数据生成和分析工具。
1. 引言
在半导体制造过程中,晶圆测试是确保芯片质量的关键环节。每个晶圆上包含数百到数千个芯片单元(die),每个die都需要进行电性能测试。然而,获取大量真实的测试数据用于算法开发和验证往往面临成本高、周期长等挑战。因此,开发一个能够模拟真实晶圆测试数据的算法具有重要的实用价值。
2. 核心Python库介绍
我们的晶圆数据模拟算法基于几个强大的Python科学计算库构建。理解这些库的作用对于掌握算法原理至关重要:

import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
from scipy.ndimage import gaussian_filter
import pandas as pd
# 设置中文字体支持
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False2.1 NumPy - 数值计算基础
NumPy (Numerical Python) 是Python科学计算的基础库,在我们的算法中承担以下关键任务:
- 多维数组操作:晶圆数据本质上是二维数组,NumPy提供高效的数组操作
- 数学运算:距离计算、坐标变换、统计计算等
- 随机数生成:生成符合特定分布的测试数据
- 掩膜操作:处理圆形晶圆边界和无效die区域
典型应用示例:
# 创建晶圆坐标网格
X, Y = np.meshgrid(x, y)
self.coords = np.vstack([X.ravel(), Y.ravel()]).T
# 计算径向距离
distance = np.sqrt((x - center_x)**2 + (y - center_y)**2)
# 生成随机种子确保结果可重现
np.random.seed(seed)2.2 Matplotlib - 数据可视化引擎
Matplotlib 是Python最主要的绘图库,在我们的算法中负责:
- 晶圆图绘制:将二维测试数据以热力图形式展示
- 统计图表:直方图、箱线图、Q-Q图等统计分析图
- 网格线显示:为晶圆图添加die边界线
- 中文字体支持:确保图表中的中文标注正确显示
典型应用示例:
# 绘制晶圆热力图
plt.imshow(wafer_map, cmap='viridis', interpolation='nearest')
# 添加die边界网格线
for x in range(self.wafer_size[0] + 1):
plt.axvline(x - 0.5, color='white', linewidth=0.5, alpha=0.7)
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']2.3 SciPy - 科学计算工具包
SciPy 提供了丰富的科学计算功能,我们主要使用了两个子模块:
- scipy.stats.norm:正态分布相关计算
- 生成符合正态分布的随机数
- 拟合数据的正态分布参数
- 计算概率密度函数和累积分布函数
- 进行正态性检验(Q-Q图)
- scipy.ndimage.gaussian_filter:高斯滤波器
- 实现空间相关性建模
- 模拟相邻die间的测试值相关性
- 平滑处理消除噪声
典型应用示例:
# 生成正态分布随机数
base_values = norm.rvs(loc=mean_current, scale=std_current, size=self.n_dies)
# 拟合正态分布参数
mu, sigma = norm.fit(valid_data)
# 高斯滤波实现空间相关性
smoothed = gaussian_filter(filled_values, sigma=sigma)
# 正态性检验
stats.probplot(valid_data, dist="norm", plot=ax2)2.4 Pandas - 数据处理与分析
Pandas 是Python数据分析的核心库,在我们的算法中用于:
- 数据结构化:将晶圆测试数据组织成DataFrame格式
- 数据筛选:快速筛选有效die、合格die、不合格die
- 统计计算:计算均值、标准差、中位数等统计量
- 数据导出:将生成的数据保存为CSV文件
典型应用示例:
# 创建结构化数据框
data = pd.DataFrame({
'x': self.coords[:, 0],
'y': self.coords[:, 1],
'current_mA': values,
'valid_die': ~np.isnan(values)
})
# 数据筛选和统计
valid_data = data[data['valid_die']]['current_mA']
pass_data = valid_data[(valid_data >= spec_min) & (valid_data <= spec_max)]
# 数据导出
wafer_data.to_csv('improved_wafer_data.csv', index=False)2.5 库之间的协同工作
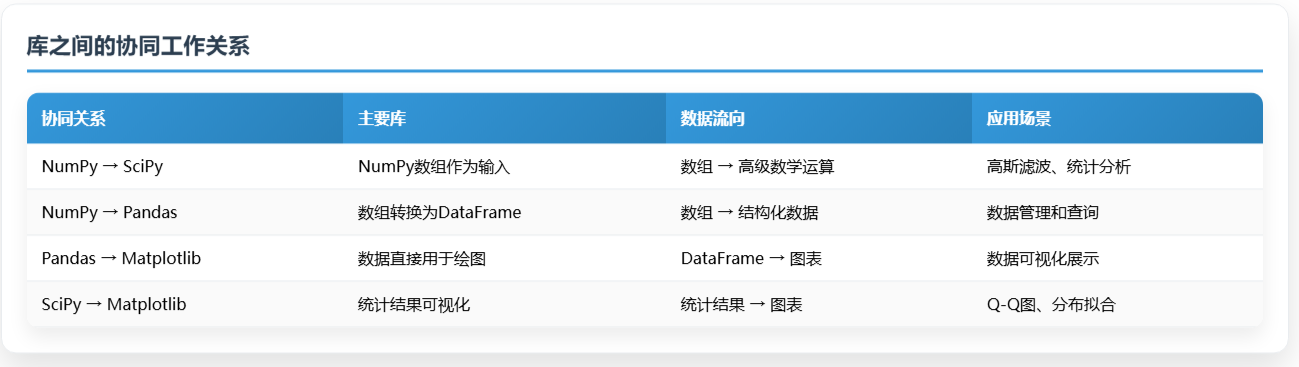
协同优势:这些库并非独立工作,而是形成了一个完整的数据科学生态系统:
- NumPy → SciPy:NumPy数组作为SciPy函数的输入,实现高级数学运算
- NumPy → Pandas:NumPy数组转换为Pandas DataFrame,便于数据管理
- Pandas → Matplotlib:Pandas数据直接用于Matplotlib绘图
- SciPy → Matplotlib:SciPy的统计结果通过Matplotlib可视化展示
3. 设计思路
3.1 核心设计理念
我们的晶圆数据模拟算法基于以下几个核心理念:
- 真实性:模拟数据应尽可能接近真实的晶圆测试结果
- 可控性:用户可以灵活调整各种参数来生成不同特征的数据
- 完整性:涵盖晶圆测试中的各种物理现象和统计特征
- 可扩展性:模块化设计便于功能扩展和维护

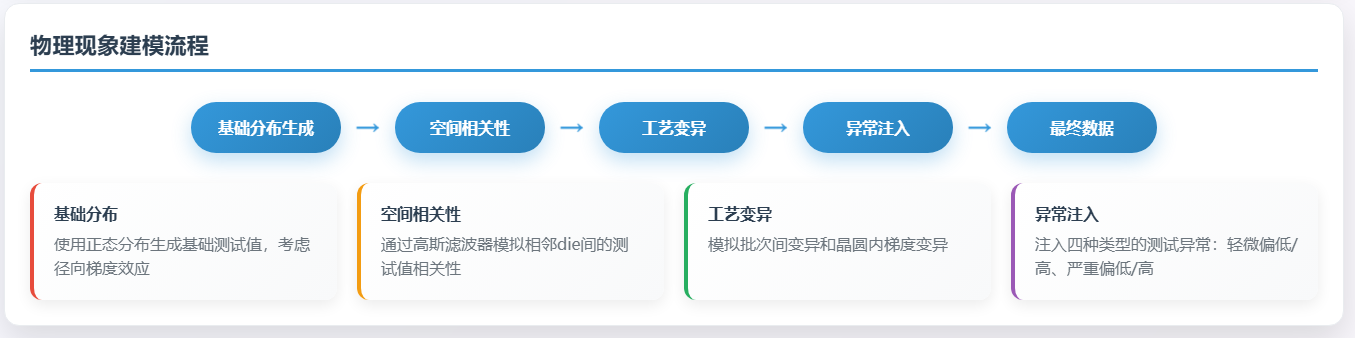
3.2 物理现象建模
真实的晶圆测试数据包含多种物理现象,我们的算法对以下关键因素进行了建模:

4. 模块结构
4.1 整体架构
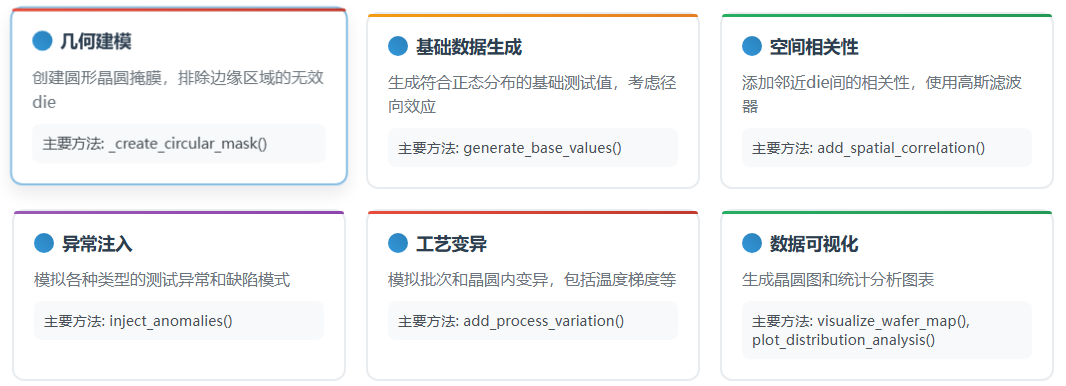
算法采用面向对象的设计模式,主要包含一个核心类 WaferDataGenerator:

class WaferDataGenerator:
"""晶圆测试数据生成器"""
def __init__(self, wafer_size=(50, 50), seed=42):
"""
初始化晶圆数据生成器
Args:
wafer_size: 晶圆尺寸 (width, height)
seed: 随机种子
"""
self.wafer_size = wafer_size
self.n_dies = wafer_size[0] * wafer_size[1]
np.random.seed(seed)
# 生成晶圆die的坐标
x = np.arange(wafer_size[0])
y = np.arange(wafer_size[1])
X, Y = np.meshgrid(x, y)
self.coords = np.vstack([X.ravel(), Y.ravel()]).T
# 创建圆形晶圆掩膜(更真实的晶圆形状)
self.wafer_mask = self._create_circular_mask()4.2 功能模块划分

5. 实现方法
5.1 圆形晶圆掩膜生成
真实的晶圆是圆形的,边缘区域通常不包含有效的芯片。我们通过以下算法创建圆形掩膜:
def _create_circular_mask(self):
"""创建圆形晶圆掩膜,排除边缘die"""
center_x, center_y = self.wafer_size[0] // 2, self.wafer_size[1] // 2
radius = min(center_x, center_y) * 0.9 # 90%的半径
mask = np.zeros(self.wafer_size, dtype=bool)
for i in range(self.wafer_size[0]):
for j in range(self.wafer_size[1]):
distance = np.sqrt((i - center_x)**2 + (j - center_y)**2)
if distance <= radius:
mask[i, j] = True
return mask关键点:通过计算每个die到晶圆中心的距离,只保留半径范围内的die作为有效区域,这样生成的数据更符合真实晶圆的几何特征。这里主要使用了NumPy的数组操作和数学函数。
5.2 基础数据生成与径向效应
基础测试值采用正态分布生成,同时考虑径向梯度效应(晶圆边缘性能通常较差):
def generate_base_values(self, mean_current=0.0065, std_current=0.001,
spec_min=0.003, spec_max=0.010):
# 生成正态分布的基础值
base_values = norm.rvs(loc=mean_current, scale=std_current, size=self.n_dies)
# 添加径向梯度效应(晶圆边缘通常性能较差)
center_x, center_y = self.wafer_size[0] // 2, self.wafer_size[1] // 2
radial_effect = np.zeros(self.n_dies)
for i, (x, y) in enumerate(self.coords):
distance = np.sqrt((x - center_x)**2 + (y - center_y)**2)
max_distance = np.sqrt(center_x**2 + center_y**2)
# 边缘die有轻微的性能下降
radial_factor = 1 - 0.1 * (distance / max_distance)
radial_effect[i] = base_values[i] * radial_factor
return radial_effect, spec_min, spec_max库的作用:这里使用了SciPy的
norm.rvs()函数生成正态分布随机数,NumPy负责数组操作和数学计算。
5.3 空间相关性建模
相邻的die往往具有相似的测试结果,我们使用高斯滤波器来模拟这种空间相关性:
def add_spatial_correlation(self, values, sigma=2.0):
"""添加空间相关性"""
values_2d = values.reshape(self.wafer_size)
# 处理NaN值
valid_mask = ~np.isnan(values_2d)
if np.any(valid_mask):
# 用均值填充NaN进行平滑
filled_values = values_2d.copy()
filled_values[~valid_mask] = np.nanmean(values_2d)
# 高斯平滑
smoothed = gaussian_filter(filled_values, sigma=sigma)
# 恢复NaN值
smoothed[~valid_mask] = np.nan
return smoothed.ravel()
return values技术说明:高斯滤波器通过对每个die及其邻近区域进行加权平均,实现了空间平滑效果。这里使用了SciPy的
gaussian_filter函数实现滤波,NumPy负责数组变形和NaN值处理。sigma参数控制相关性的范围,值越大,相关性影响范围越广。
5.4 异常注入机制
真实的晶圆测试中会出现各种异常情况,我们的算法可以注入四种类型的异常:
def inject_anomalies(self, values, anomaly_rate=0.02, spec_min=0.003, spec_max=0.010):
# 计算异常数量
n_anomalies = int(len(values) * anomaly_rate)
# 随机选择异常位置(只在有效die中选择)
valid_indices = np.where(~np.isnan(values))[0]
anomaly_positions = np.random.choice(valid_indices, size=n_anomalies, replace=False)
# 生成不同类型的异常
anomaly_types = np.random.choice(['low', 'high', 'extreme_low', 'extreme_high'],
size=n_anomalies,
p=[0.3, 0.3, 0.2, 0.2])
for i, pos in enumerate(anomaly_positions):
if anomaly_types[i] == 'low':
# 轻微偏低
values[pos] = np.random.uniform(spec_min * 0.8, spec_min * 0.95)
elif anomaly_types[i] == 'high':
# 轻微偏高
values[pos] = np.random.uniform(spec_max * 1.05, spec_max * 1.2)
elif anomaly_types[i] == 'extreme_low':
# 严重偏低
values[pos] = np.random.uniform(0.0005, spec_min * 0.5)
else: # extreme_high
# 严重偏高
values[pos] = np.random.uniform(spec_max * 1.5, spec_max * 2.0)NumPy随机函数的应用:
np.random.choice():随机选择异常类型和位置np.random.uniform():在指定范围内生成均匀分布的异常值np.where():查找满足条件的数组索引
5.5 工艺变异模拟
制造过程中的工艺变异包括批次间变异和晶圆内梯度变异:
def add_process_variation(self, values, lot_variation=0.05, wafer_variation=0.03):
# 批次偏移
lot_shift = np.random.normal(0, lot_variation)
# 晶圆内梯度(模拟温度梯度等)
wafer_gradient_x = np.random.normal(0, wafer_variation)
wafer_gradient_y = np.random.normal(0, wafer_variation)
for i, (x, y) in enumerate(self.coords):
if not np.isnan(values[i]):
# 应用批次偏移
values[i] *= (1 + lot_shift)
# 应用晶圆内梯度
norm_x = (x - self.wafer_size[0]/2) / (self.wafer_size[0]/2)
norm_y = (y - self.wafer_size[1]/2) / (self.wafer_size[1]/2)
gradient_effect = 1 + wafer_gradient_x * norm_x + wafer_gradient_y * norm_y
values[i] *= gradient_effect6. 数据可视化与分析
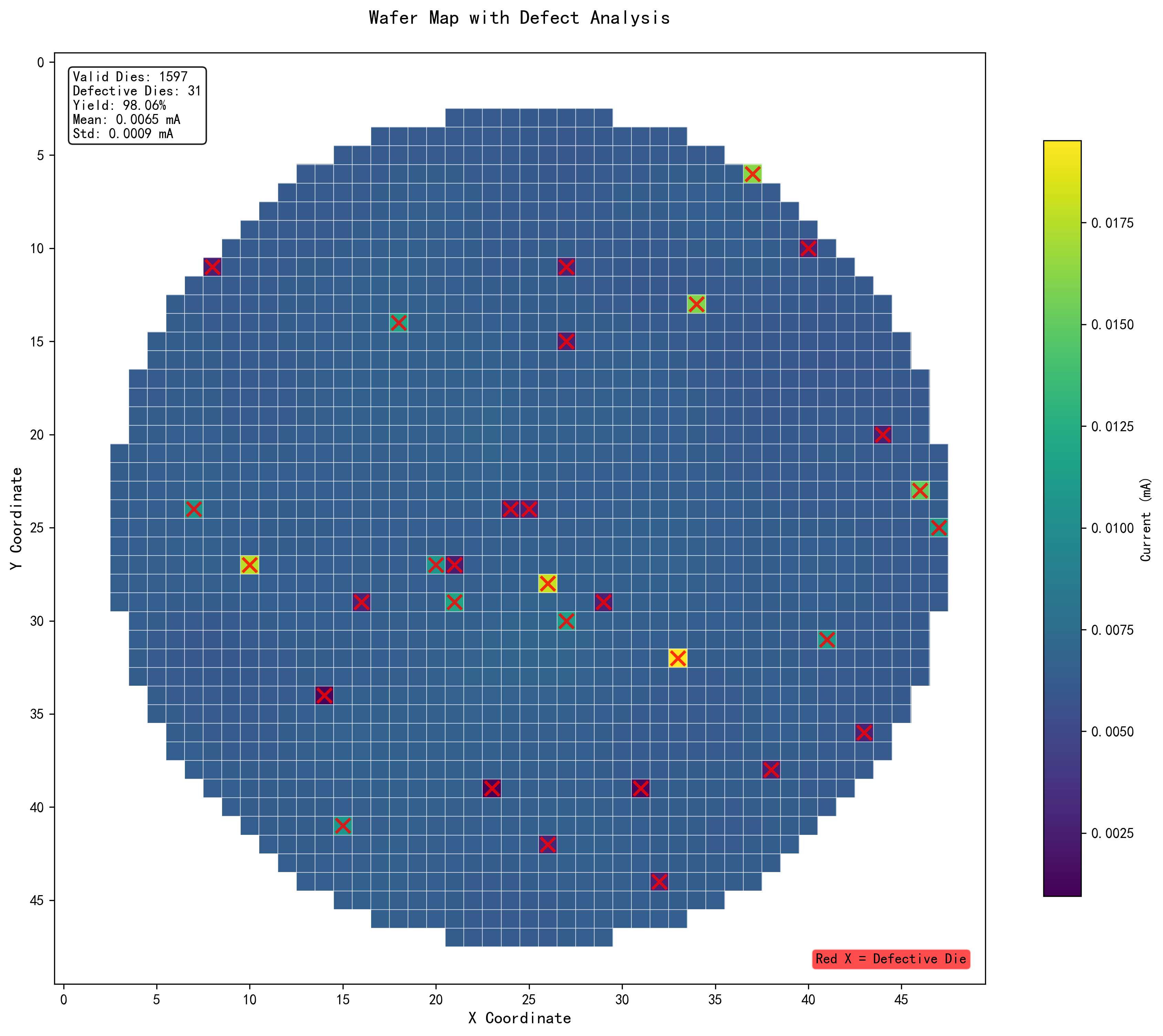
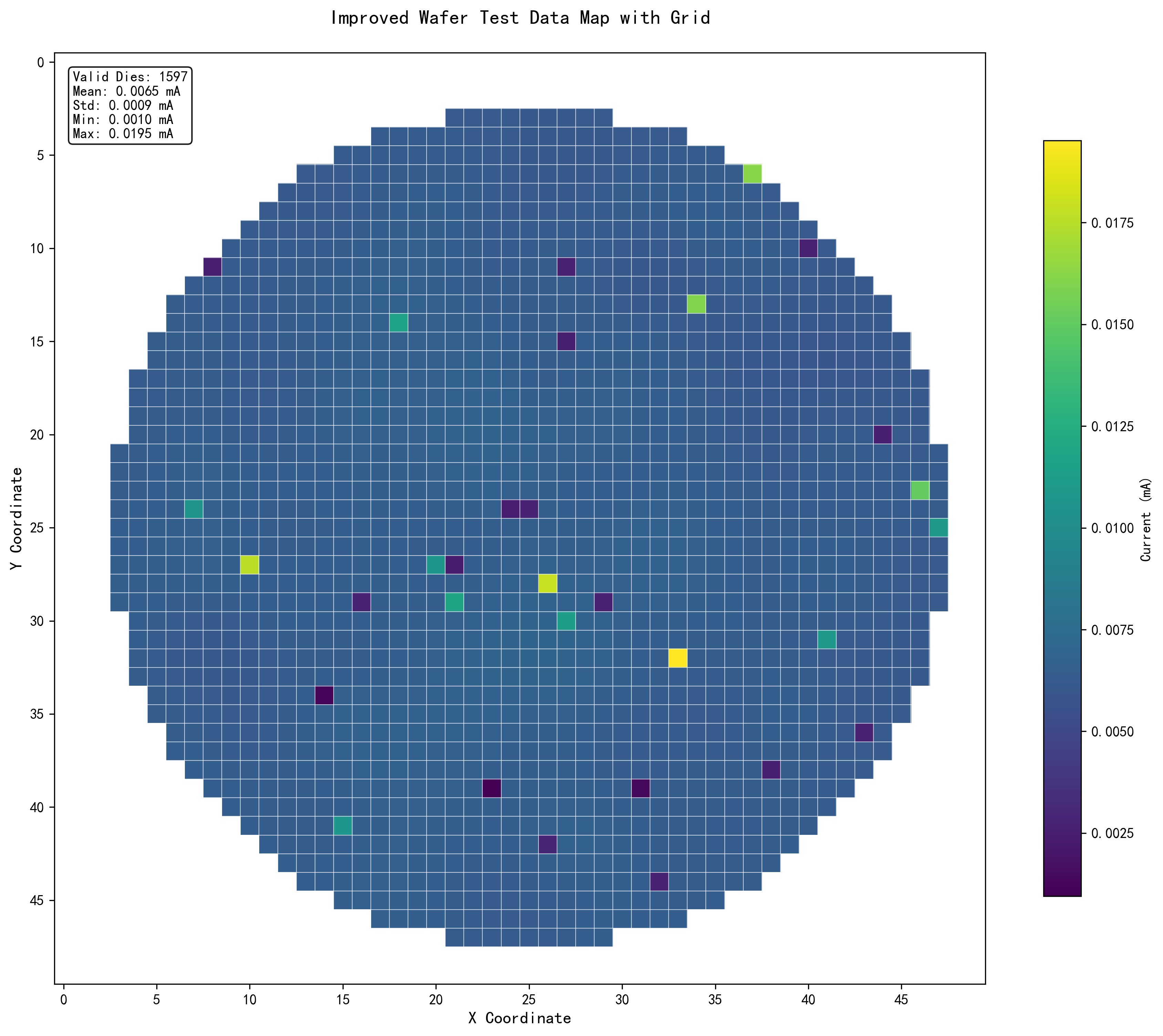
6.1 晶圆图可视化
算法提供了两种晶圆图可视化方式:
- 基础晶圆图:显示所有die的测试值分布,支持网格线显示
- 缺陷标注图:用红色"X"标记超出规格限制的不合格die
Matplotlib在可视化中的关键作用:
plt.imshow():将二维数组显示为热力图plt.axvline(), plt.axhline():添加网格线plt.scatter():标记不合格die位置plt.colorbar():添加颜色条说明plt.text():添加统计信息文本
 |
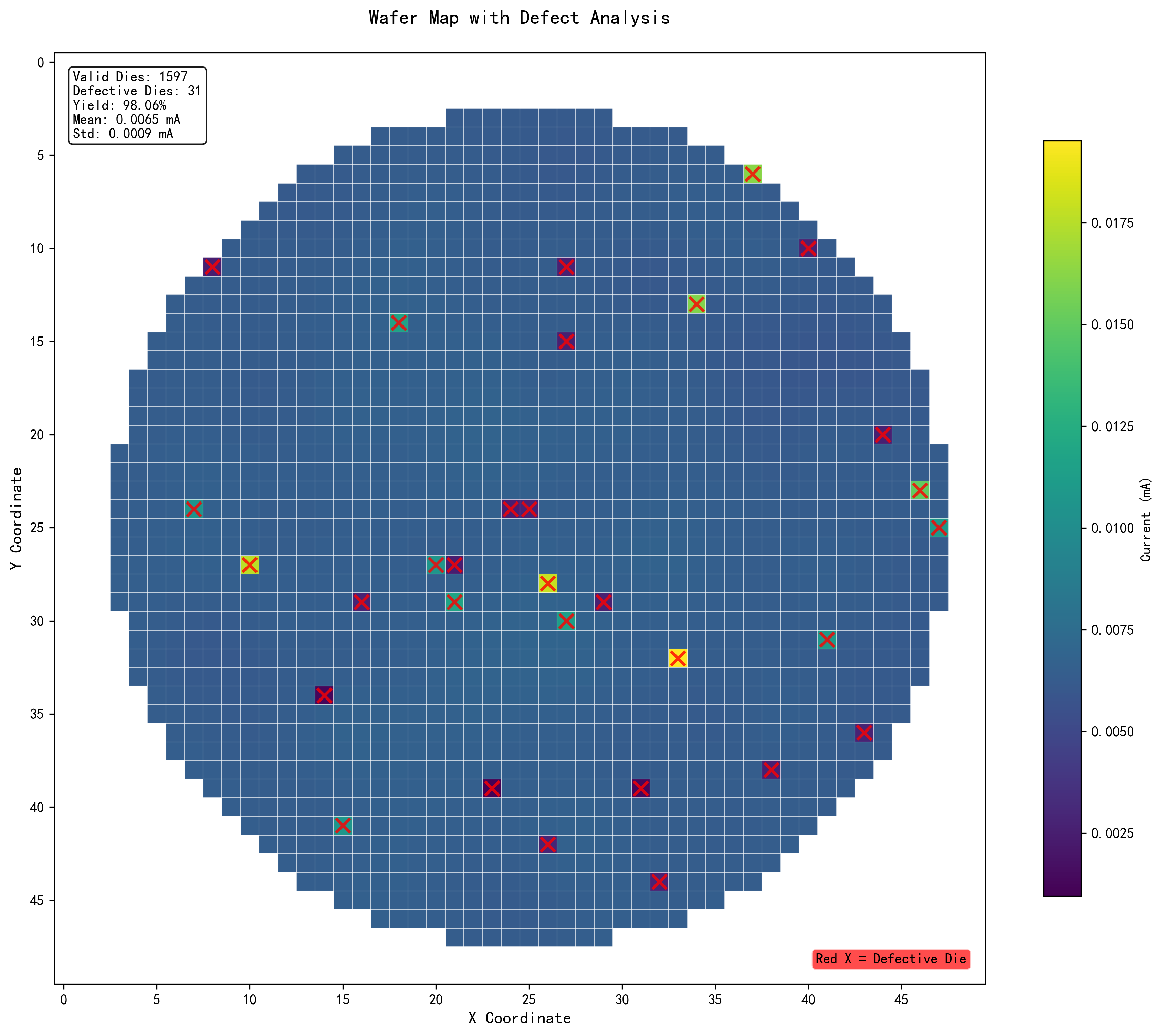 |
晶圆图示例:左图显示整体数据分布,右图标注不合格die位置
6.2 统计分析图表
算法生成四维统计分析图,包括:
def plot_distribution_analysis(self, data, spec_min=0.003, spec_max=0.010,
title="测试数据分布分析", save_path=None):
# 创建子图,增加垂直间距
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(15, 12))
plt.suptitle(title, fontsize=16, y=0.95)
plt.subplots_adjust(hspace=0.35, top=0.90, wspace=0.25)
# 1. 直方图 + 正态分布拟合
# 2. Q-Q图(正态性检验)
# 3. 累积分布函数 (CDF)
# 4. 箱线图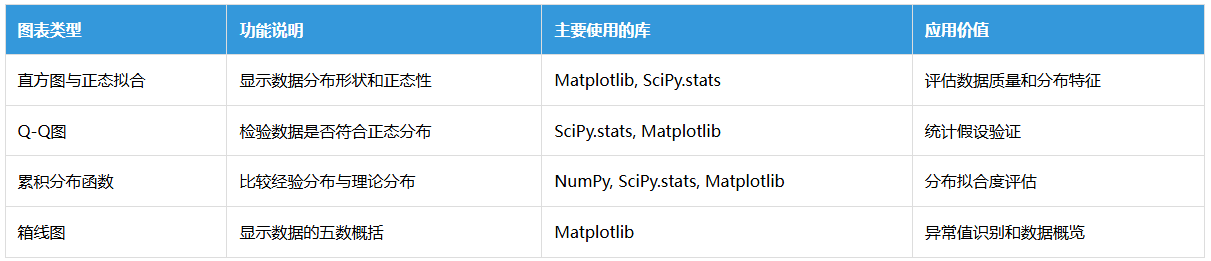
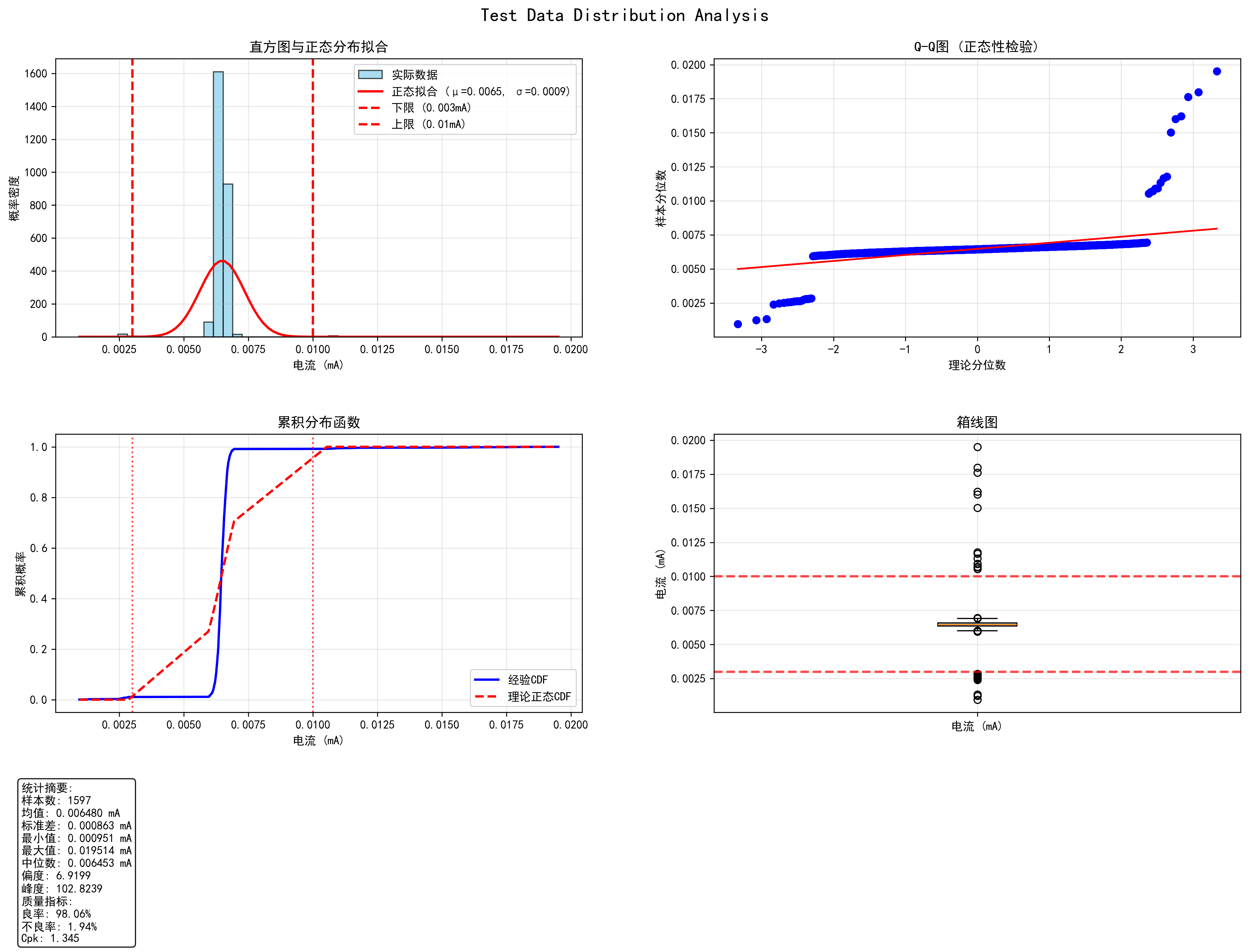
7. 结果分析
7.1 数据质量指标

算法自动计算并输出关键的质量指标:
def analyze_data_quality(self, data, spec_min=0.003, spec_max=0.010):
valid_data = data[data['valid_die']]['current_mA']
pass_data = valid_data[(valid_data >= spec_min) & (valid_data <= spec_max)]
fail_data = valid_data[(valid_data < spec_min) | (valid_data > spec_max)]
print("=== 晶圆数据质量分析 ===")
print(f"总die数量: {len(data)}")
print(f"有效die数量: {len(valid_data)}")
print(f"合格die数量: {len(pass_data)}")
print(f"不合格die数量: {len(fail_data)}")
print(f"良率: {len(pass_data)/len(valid_data)*100:.2f}%")Pandas在数据分析中的优势:
- 条件筛选:
data[data['valid_die']]快速筛选有效数据- 布尔索引:
(valid_data >= spec_min) & (valid_data <= spec_max)复合条件筛选- 统计函数:
.mean(), .std(), .min(), .max(), .median()快速统计- 数据展示:
.to_string()格式化输出
7.2 统计特征分析
生成的数据包含以下统计特征:
- 均值和标准差:反映数据的中心趋势和离散程度
- 偏度和峰度:描述数据分布的形状特征
- Cpk值:工艺能力指数,评估工艺稳定性
- 良率:合格产品的比例
7.3 应用场景
实际应用价值:
- 算法开发:为测试数据分析算法提供标准数据集
- 系统验证:验证测试系统的检测能力和准确性
- 培训教学:为工程师培训提供真实的案例数据
- 研究分析:支持统计分析方法的研究和验证
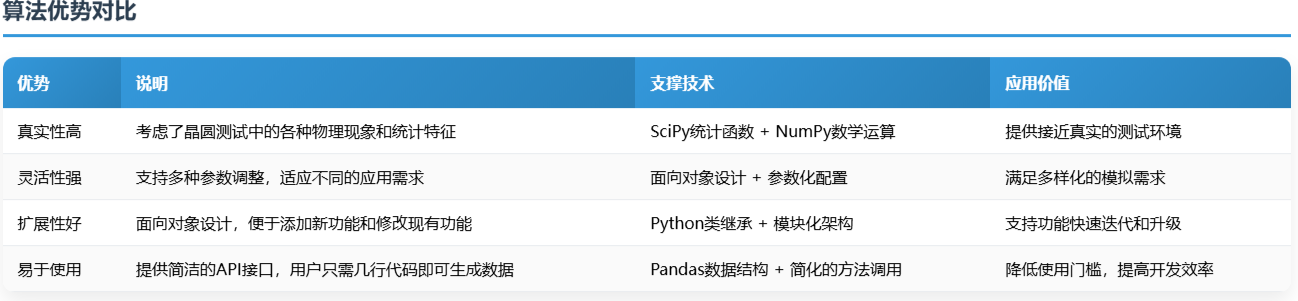
8. 技术特点与优势
- 学的统计模型和物理现象
- 可视化丰富:提供多种图表展示数据特征

8.2 算法优势
9. 总结与展望
本文介绍的晶圆测试数据模拟算法通过科学的数学建模和工程实践相结合,成功实现了对真实晶圆测试数据的高质量模拟。该算法不仅在技术上具有先进性,在实际应用中也展现出了良好的实用价值。
9.1 主要贡献
- 提供了一个完整的晶圆测试数据模拟解决方案
- 实现了多种物理现象的数学建模
- 开发了丰富的数据可视化和分析功能
- 为半导体测试领域提供了有价值的工具
9.2 Python生态系统的价值
本项目充分展示了Python科学计算生态系统的强大优势:
- NumPy:提供了高效的数值计算基础
- SciPy:提供了专业的科学计算工具
- Matplotlib:提供了灵活的数据可视化能力
- Pandas:提供了便捷的数据处理和分析功能
这些库的组合使用,让复杂的科学计算问题变得简单易解,大大提高了开发效率和代码质量。
9.3 未来发展方向
- 模型优化:进一步提高模拟数据的真实性和准确性
- 功能扩展:支持更多类型的测试参数和异常模式
- 性能提升:支持更大规模的数据生成
- 智能化:结合机器学习技术,实现自适应参数调整
结语:随着半导体技术的不断发展,测试数据的复杂性也在增加。本算法为应对这一挑战提供了有力的工具支持,而Python丰富的科学计算库生态系统为这类复杂算法的实现提供了坚实的技术基础。相信在未来的发展中将发挥更大的作用。好了 如果觉得文章对你有帮助,请帮忙:
关注 点赞 收藏

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)