基于大数据的智能出行交通数据可视化分析系统 大数据毕业设计 计算机毕业设计 机器学习毕业设计 毕业设计定制开发 大屏可视化 全新UI定制设计
本文介绍了一个基于大数据的智能出行交通数据可视化分析系统。该系统整合了Hadoop、Spark等大数据技术,采用Python+Django框架开发后端,Vue+Echarts构建前端可视化界面,能够对15个关键交通指标进行多维分析。系统主要功能包括:交通流量与拥堵分析、智慧停车与共享出行分析、绿色出行与环境影响分析、交通安全与应急管理分析四大模块。通过Spark SQL进行数据查询,结合Panda
💖💖作者:计算机毕业设计小明哥
💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我!
💛💛想说的话:感谢大家的关注与支持!
💜💜
大数据实战项目
网站实战项目
安卓/小程序实战项目
深度学习实战项目
💕💕文末获取源码
文章目录
智能出行交通数据可视化分析系统-系统功能
基于大数据的智能出行交通数据可视化分析系统是一个集成了Hadoop分布式存储、Spark大数据计算引擎和前端可视化技术的综合性交通数据分析平台。系统采用Python+Django作为后端开发框架,结合Vue+ElementUI+Echarts构建交互式前端界面,通过MySQL数据库存储分析结果,实现对智能出行交通数据的全方位处理与展示。系统核心数据集包含车辆计数、交通速度、道路占用率、交通信号灯状态、天气状况、事故报告、共享出行需求、停车位可用性、排放水平等15个关键字段,能够进行交通流量与拥堵分析、智慧停车与共享出行分析、绿色出行与环境影响分析、交通安全与应急管理分析四大维度的深度数据挖掘。系统运用Spark SQL进行复杂查询,结合Pandas和NumPy进行数据预处理,通过HDFS实现海量数据的可靠存储,最终以热力图、折线图、柱状图等多种可视化形式展现分析结果,为城市交通管理部门提供科学的决策支持工具。
智能出行交通数据可视化分析系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL
智能出行交通数据可视化分析系统-背景意义
选题背景
随着城市化进程的不断加速和机动车保有量的持续增长,城市交通拥堵、停车难、环境污染等问题日益突出,传统的交通管理方式已经难以满足现代城市发展的需要。智慧城市建设成为解决这些问题的重要途径,而交通数据的智能化分析正是智慧交通系统的核心组成部分。当前,各大城市都在积极部署交通感知设备,收集包括车流量、车速、信号灯状态、天气条件等在内的海量交通数据,这些数据蕴含着丰富的交通规律和模式信息。然而,传统的数据处理技术在面对TB级甚至PB级的交通大数据时显得力不从心,迫切需要引入Hadoop、Spark等大数据技术来实现高效的数据存储、计算和分析。同时,如何将复杂的数据分析结果以直观易懂的方式呈现给决策者,也成为交通数据应用中的关键环节,这就需要结合现代化的数据可视化技术来构建用户友好的分析平台。
选题意义
本课题的研究具有重要的实际应用价值和理论探索意义。从实际应用角度来看,系统能够帮助交通管理部门更好地理解城市交通运行规律,通过对不同时间段交通流量变化的分析,可以为交通信号优化和路网调度提供数据依据,虽然作为毕业设计项目规模有限,但这种分析思路和技术方法在实际工程中具有很好的推广价值。系统对停车资源和共享出行需求的分析,能够为智慧停车系统的建设和共享出行平台的运营优化提供参考,这对缓解城市停车难问题和促进绿色出行具有积极作用。环境影响分析功能可以量化评估不同交通状况下的碳排放和能耗水平,为制定环保政策和推广新能源汽车提供数据支撑。从技术层面来说,项目综合运用了大数据存储、计算、分析和可视化的完整技术栈,为学习和掌握大数据技术提供了很好的实践平台,同时探索了交通领域的数据科学应用,对相关专业的学生具有一定的学习和参考价值。当然,作为学术项目,系统在数据规模和功能复杂度方面还比较有限,但其设计理念和实现方法为后续的深入研究奠定了基础。
智能出行交通数据可视化分析系统-演示视频
基于大数据的智能出行交通数据可视化分析系统 大数据毕业设计 计算机毕业设计 机器学习毕业设计 毕业设计定制开发 大屏可视化 全新UI定制设计
智能出行交通数据可视化分析系统-演示图片

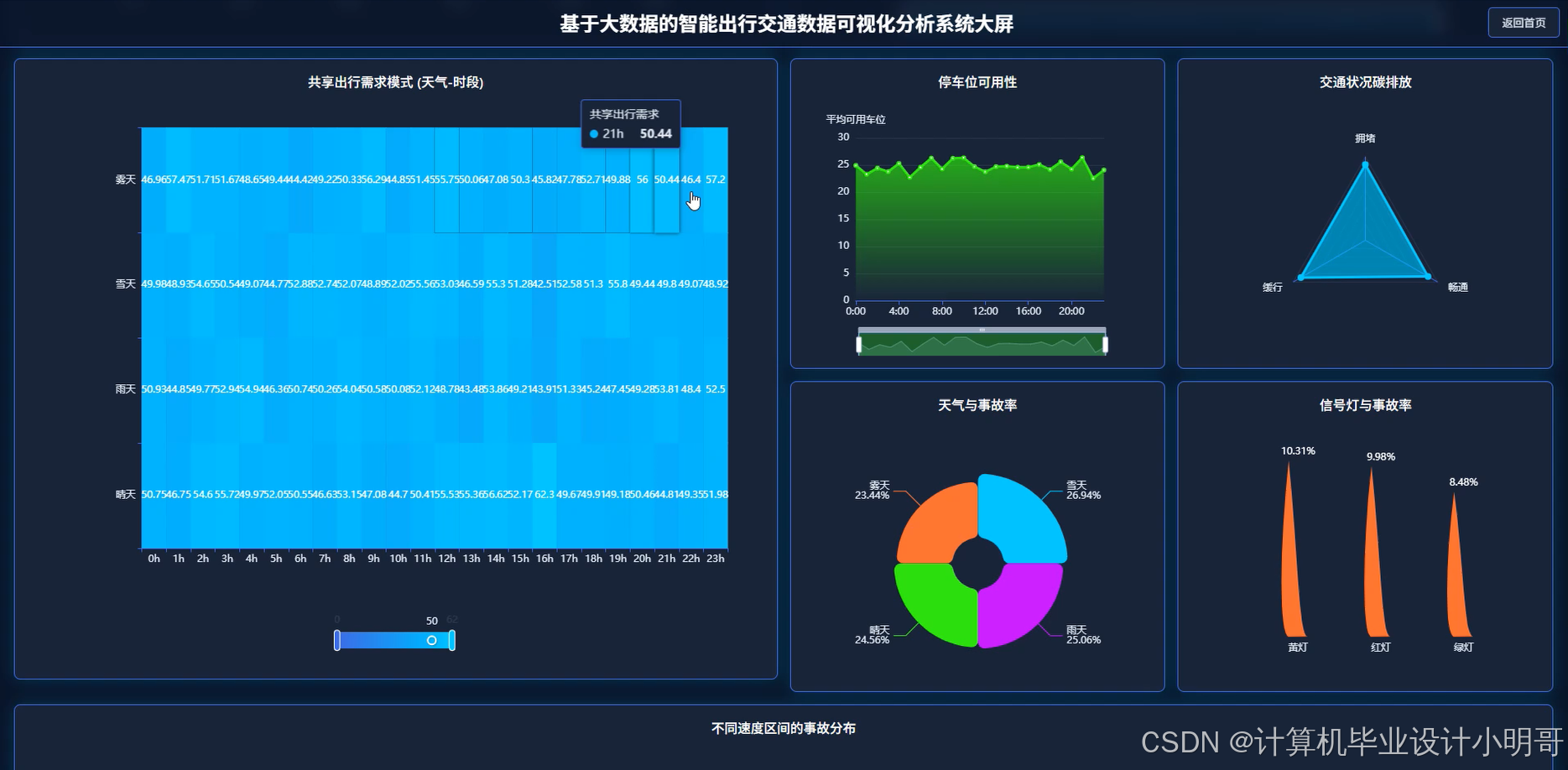
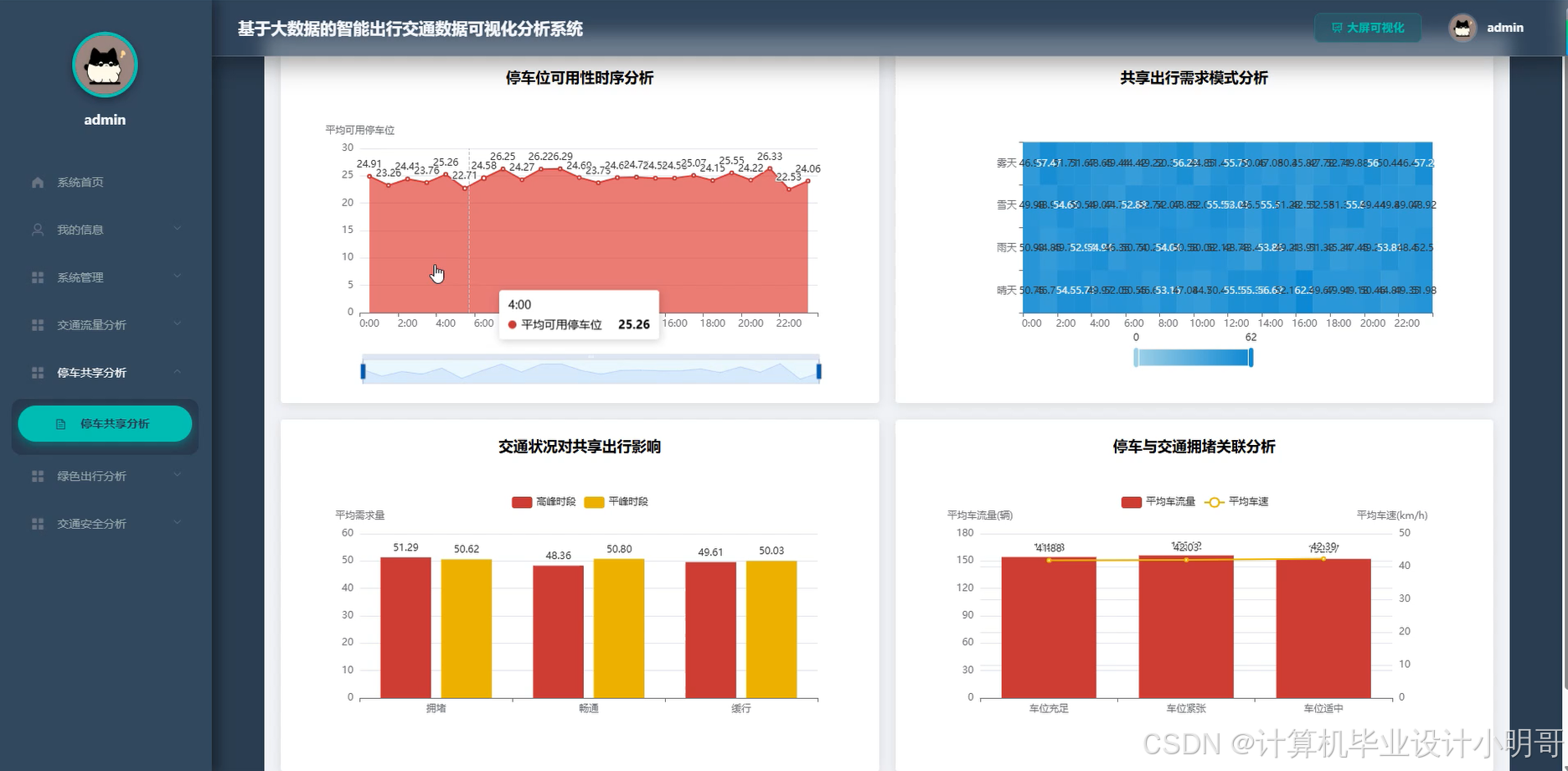
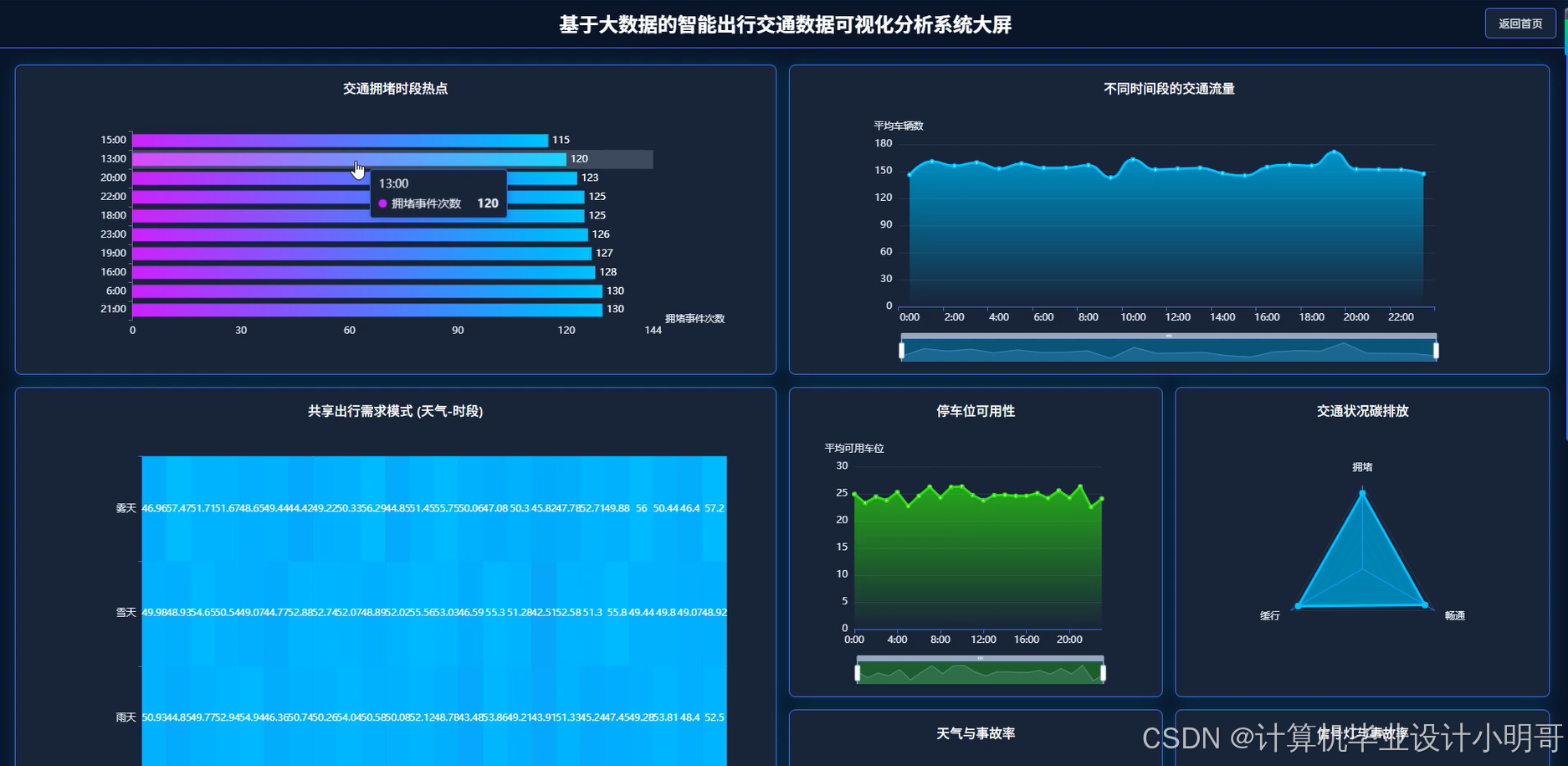
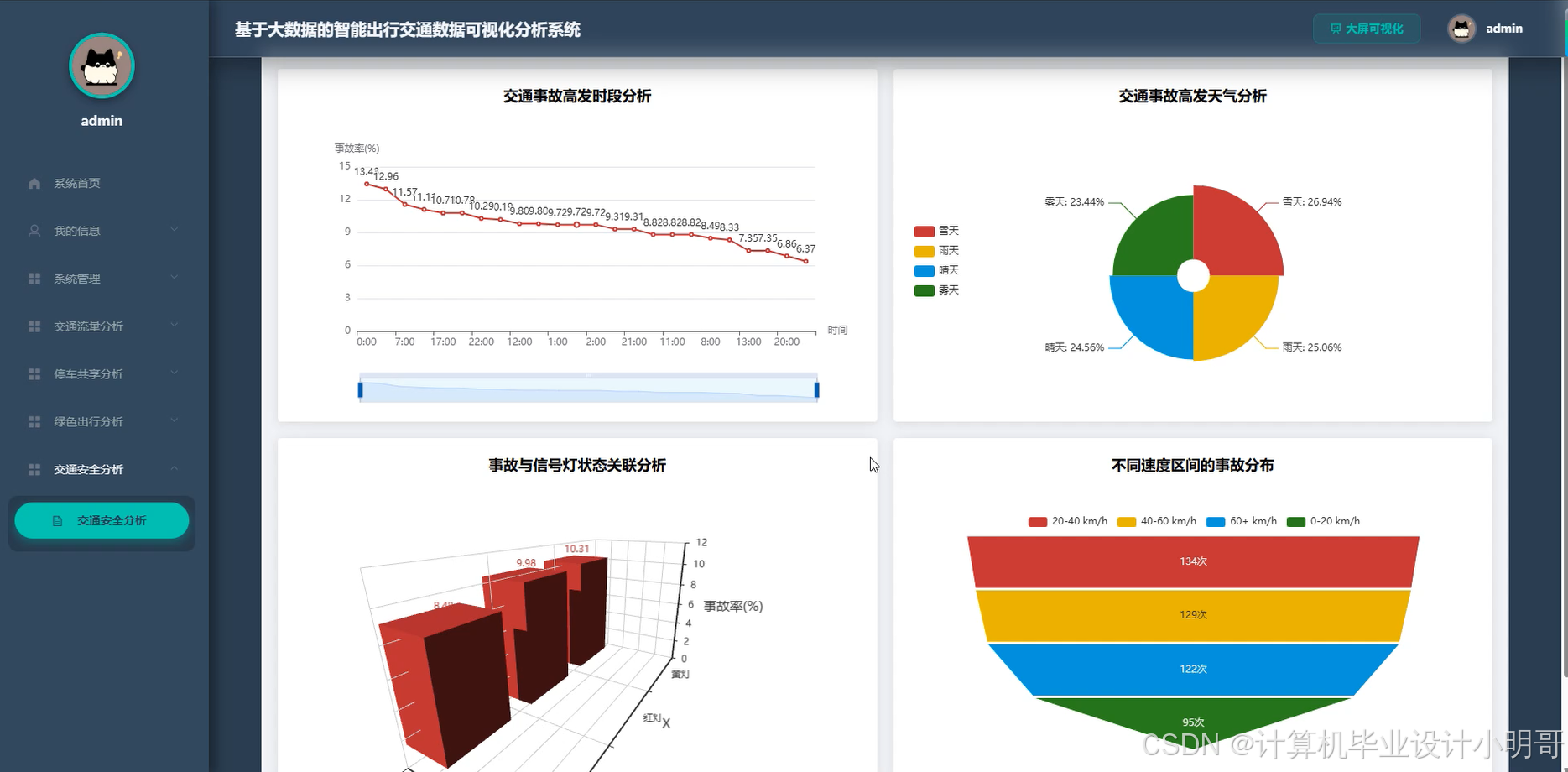
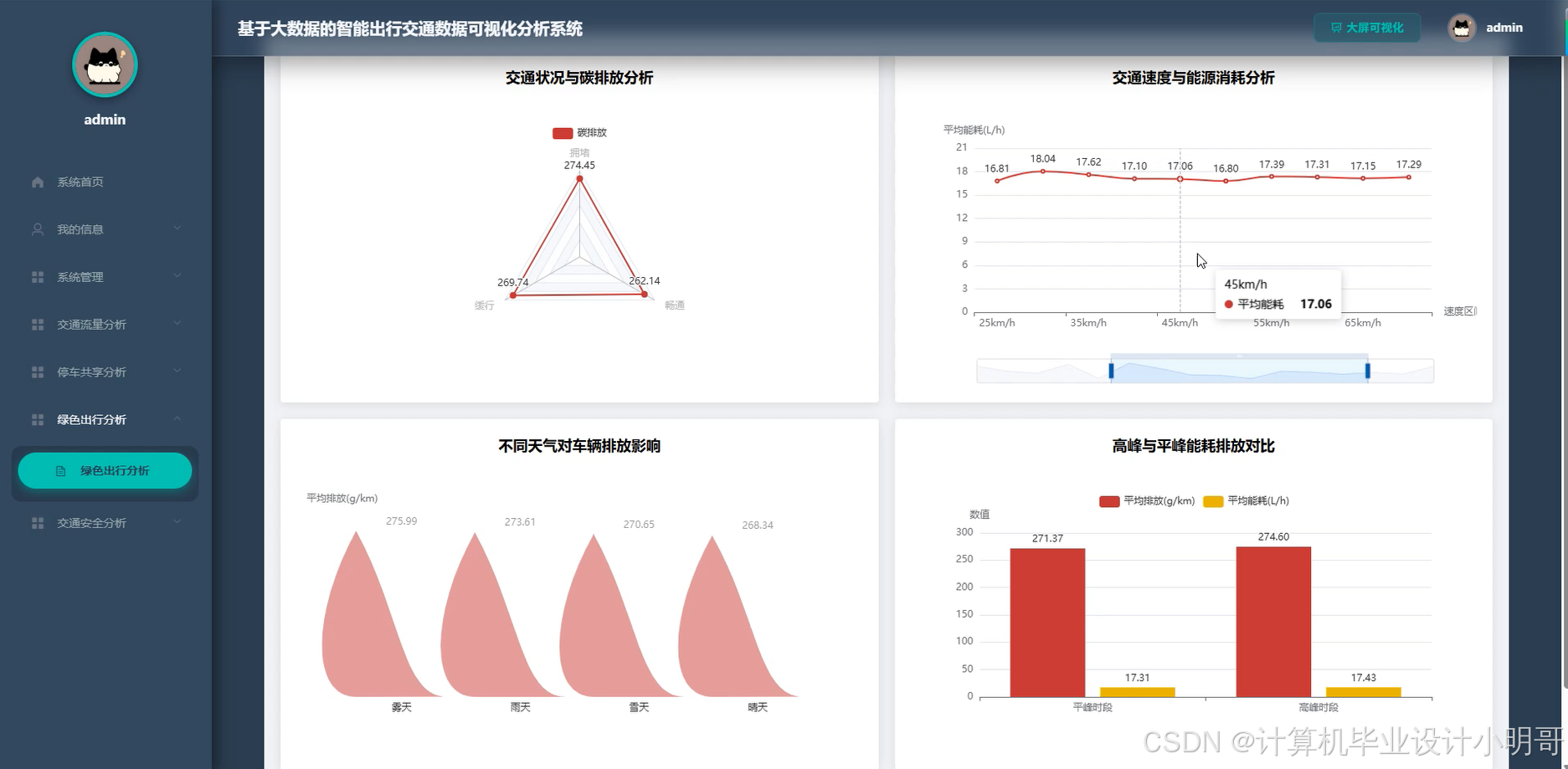
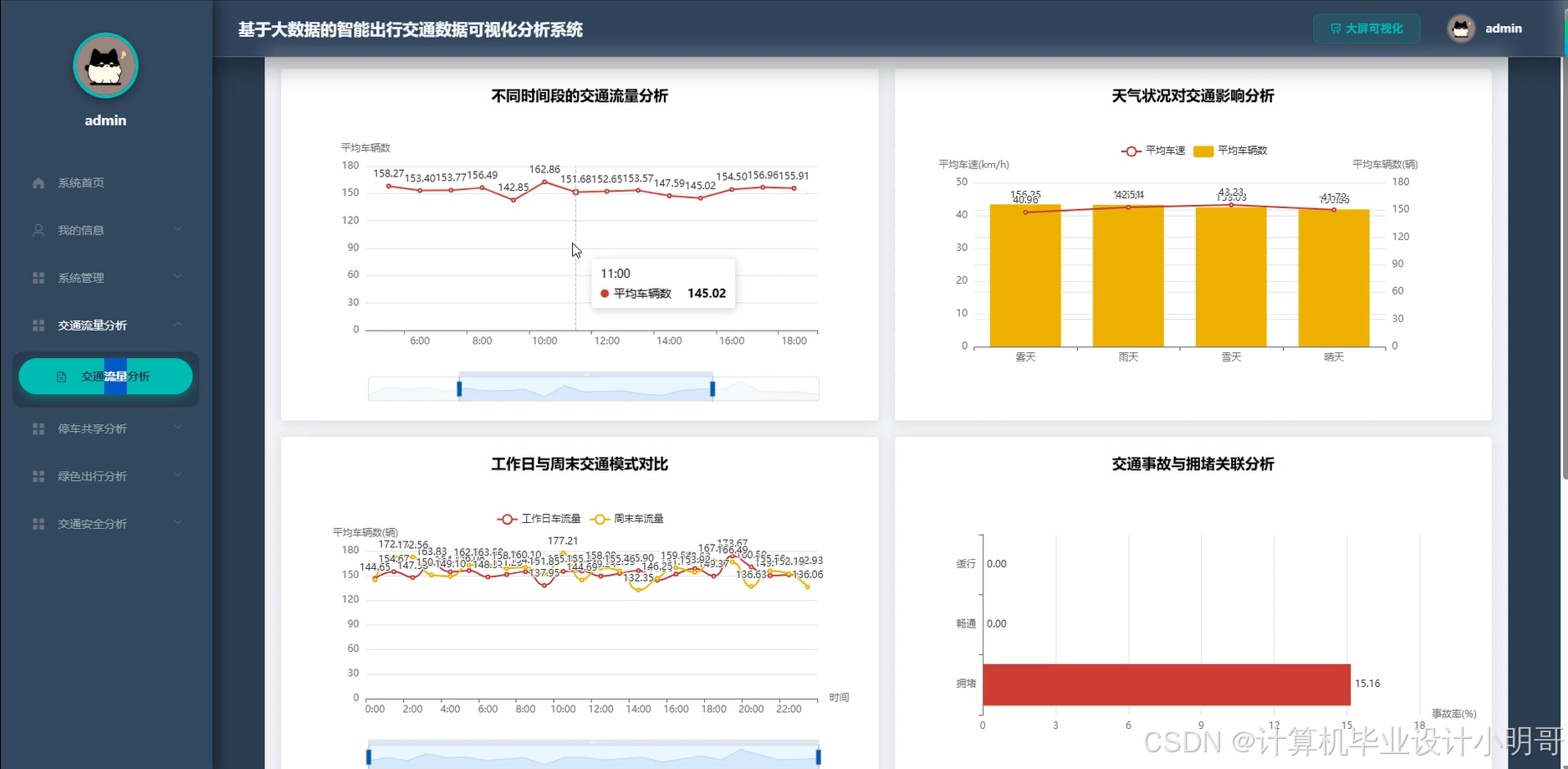
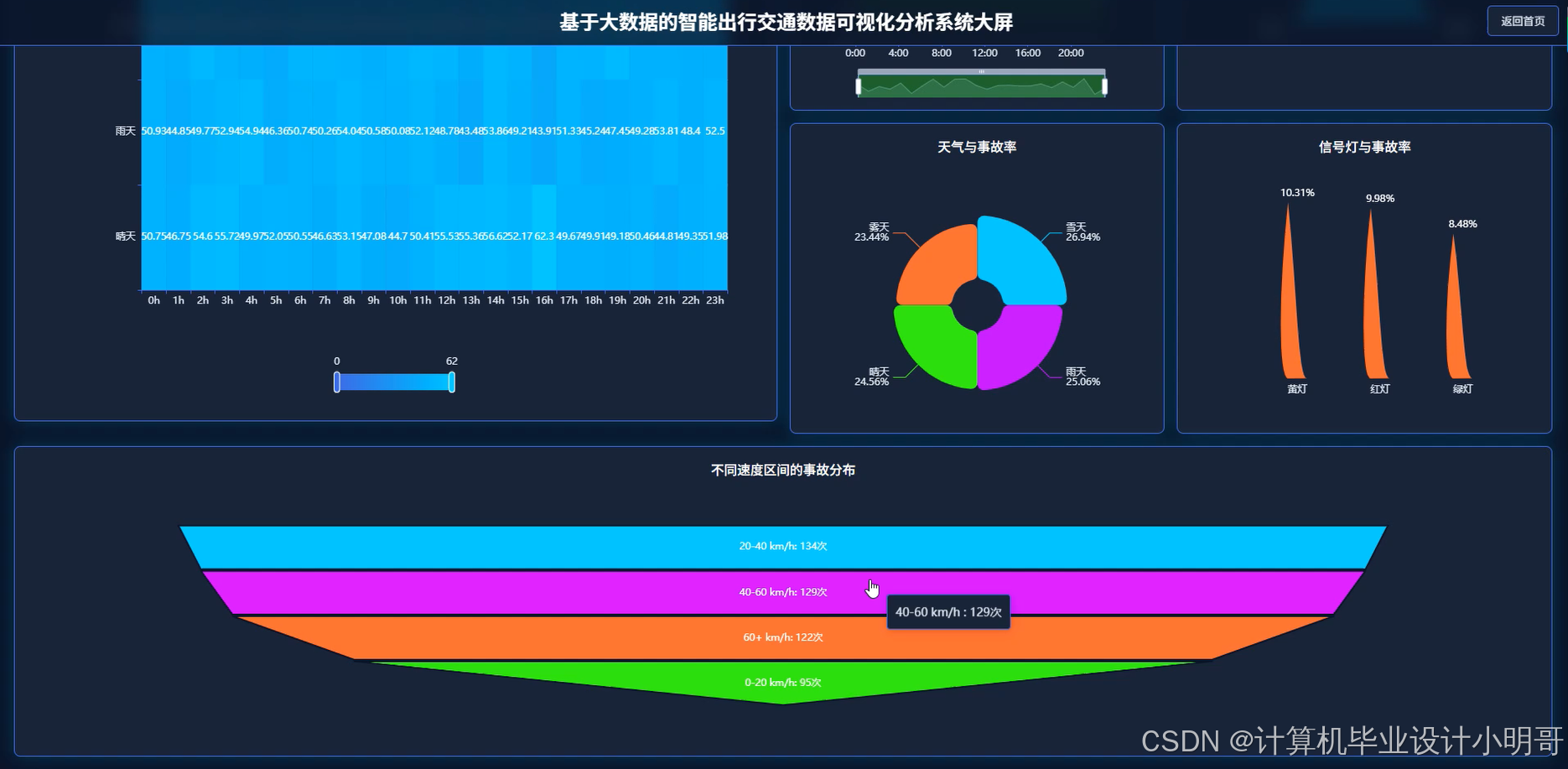
智能出行交通数据可视化分析系统-代码展示
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, count, when, hour, date_format, desc, asc
import pandas as pd
spark = SparkSession.builder.appName("智能交通大数据分析").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.coalescePartitions.enabled", "true").getOrCreate()
df = spark.read.csv("hdfs://localhost:9000/smart_mobility_dataset.csv", header=True, inferSchema=True)
df = df.withColumn("hour", hour(col("Timestamp"))).withColumn("weekday", date_format(col("Timestamp"), "E"))
def traffic_flow_analysis():
hourly_traffic = df.groupBy("hour").agg(avg("Vehicle_Count").alias("avg_vehicle_count"), avg("Traffic_Speed_kmh").alias("avg_speed")).orderBy("hour")
weather_impact = df.groupBy("Weather_Condition").agg(avg("Traffic_Speed_kmh").alias("avg_speed"), count("*").alias("record_count")).orderBy(desc("avg_speed"))
weekday_pattern = df.groupBy("weekday").agg(avg("Vehicle_Count").alias("avg_vehicle_count"), avg("Traffic_Speed_kmh").alias("avg_speed")).orderBy("weekday")
traffic_condition_dist = df.groupBy("Traffic_Condition").agg(count("*").alias("count"), avg("Vehicle_Count").alias("avg_vehicles")).orderBy(desc("count"))
peak_hours = hourly_traffic.filter(col("avg_vehicle_count") > hourly_traffic.select(avg("avg_vehicle_count")).collect()[0][0]).orderBy(desc("avg_vehicle_count"))
congestion_weather = df.filter(col("Traffic_Condition") == "High").groupBy("Weather_Condition").agg(count("*").alias("congestion_count")).orderBy(desc("congestion_count"))
speed_variance = df.groupBy("hour").agg(avg("Traffic_Speed_kmh").alias("avg_speed")).withColumn("speed_category", when(col("avg_speed") > 50, "快速").when(col("avg_speed") > 30, "中速").otherwise("缓慢"))
road_occupancy_analysis = df.groupBy("Traffic_Condition").agg(avg("Road_Occupancy_%").alias("avg_occupancy")).orderBy(desc("avg_occupancy"))
signal_efficiency = df.groupBy("Traffic_Light_State").agg(avg("Traffic_Speed_kmh").alias("avg_speed"), count("*").alias("record_count")).orderBy(desc("avg_speed"))
result_df = hourly_traffic.join(weather_impact, how="cross").join(weekday_pattern, how="cross")
final_analysis = result_df.select("hour", "avg_vehicle_count", "avg_speed").union(weather_impact.select(col("Weather_Condition").alias("hour"), col("record_count").alias("avg_vehicle_count"), col("avg_speed")))
comprehensive_stats = df.groupBy("hour", "Weather_Condition").agg(avg("Vehicle_Count").alias("vehicles"), avg("Traffic_Speed_kmh").alias("speed"), avg("Road_Occupancy_%").alias("occupancy"))
traffic_efficiency = comprehensive_stats.withColumn("efficiency_score", (col("speed") * 100) / (col("occupancy") + 1)).orderBy(desc("efficiency_score"))
morning_rush = df.filter((col("hour") >= 7) & (col("hour") <= 9)).agg(avg("Vehicle_Count").alias("morning_vehicles"), avg("Traffic_Speed_kmh").alias("morning_speed"))
evening_rush = df.filter((col("hour") >= 17) & (col("hour") <= 19)).agg(avg("Vehicle_Count").alias("evening_vehicles"), avg("Traffic_Speed_kmh").alias("evening_speed"))
rush_comparison = morning_rush.crossJoin(evening_rush)
traffic_flow_result = traffic_efficiency.toPandas()
traffic_flow_result.to_csv("traffic_flow_analysis.csv", index=False)
return traffic_flow_result
def traffic_safety_analysis():
accident_by_hour = df.groupBy("hour").agg(avg("Accident_Report").alias("accident_rate"), count("*").alias("total_records")).orderBy(desc("accident_rate"))
accident_weather = df.groupBy("Weather_Condition").agg(avg("Accident_Report").alias("accident_rate"), count(when(col("Accident_Report") == 1, 1)).alias("accident_count")).orderBy(desc("accident_rate"))
signal_accident = df.groupBy("Traffic_Light_State").agg(avg("Accident_Report").alias("accident_rate"), count("*").alias("records")).orderBy(desc("accident_rate"))
speed_accident_relation = df.withColumn("speed_range", when(col("Traffic_Speed_kmh") < 20, "低速").when(col("Traffic_Speed_kmh") < 50, "中速").otherwise("高速")).groupBy("speed_range").agg(avg("Accident_Report").alias("accident_rate"))
high_risk_conditions = df.filter((col("Weather_Condition") == "Rain") | (col("Weather_Condition") == "Fog")).groupBy("hour").agg(avg("Accident_Report").alias("risk_rate")).orderBy(desc("risk_rate"))
accident_traffic_impact = df.filter(col("Accident_Report") == 1).agg(avg("Traffic_Speed_kmh").alias("accident_speed"), avg("Vehicle_Count").alias("accident_vehicles"))
normal_traffic_impact = df.filter(col("Accident_Report") == 0).agg(avg("Traffic_Speed_kmh").alias("normal_speed"), avg("Vehicle_Count").alias("normal_vehicles"))
accident_impact_comparison = accident_traffic_impact.crossJoin(normal_traffic_impact)
weekend_accidents = df.filter(col("weekday").isin(["Sat", "Sun"])).agg(avg("Accident_Report").alias("weekend_accident_rate"))
weekday_accidents = df.filter(~col("weekday").isin(["Sat", "Sun"])).agg(avg("Accident_Report").alias("weekday_accident_rate"))
day_type_comparison = weekend_accidents.crossJoin(weekday_accidents)
occupancy_accident = df.groupBy(when(col("Road_Occupancy_%") > 80, "高占用").when(col("Road_Occupancy_%") > 50, "中占用").otherwise("低占用").alias("occupancy_level")).agg(avg("Accident_Report").alias("accident_rate")).orderBy(desc("accident_rate"))
comprehensive_risk = df.groupBy("Weather_Condition", "Traffic_Light_State").agg(avg("Accident_Report").alias("combined_risk"), count("*").alias("sample_size")).filter(col("sample_size") > 10).orderBy(desc("combined_risk"))
danger_zones = df.groupBy("hour", "Weather_Condition").agg(avg("Accident_Report").alias("danger_level")).filter(col("danger_level") > 0.1).orderBy(desc("danger_level"))
safety_score = df.withColumn("safety_score", 100 - (col("Accident_Report") * 100 + col("Road_Occupancy_%"))).groupBy("hour").agg(avg("safety_score").alias("avg_safety_score")).orderBy(desc("avg_safety_score"))
critical_hours = accident_by_hour.filter(col("accident_rate") > accident_by_hour.select(avg("accident_rate")).collect()[0][0]).orderBy(desc("accident_rate"))
safety_result = comprehensive_risk.toPandas()
safety_result.to_csv("traffic_safety_analysis.csv", index=False)
return safety_result
def environmental_impact_analysis():
emission_by_condition = df.groupBy("Traffic_Condition").agg(avg("Emission_Levels_g_km").alias("avg_emission"), avg("Energy_Consumption_L_h").alias("avg_energy")).orderBy(desc("avg_emission"))
speed_emission_relation = df.withColumn("speed_category", when(col("Traffic_Speed_kmh") < 30, "低速行驶").when(col("Traffic_Speed_kmh") < 60, "正常行驶").otherwise("高速行驶")).groupBy("speed_category").agg(avg("Emission_Levels_g_km").alias("emission"), avg("Energy_Consumption_L_h").alias("energy"))
weather_emission = df.groupBy("Weather_Condition").agg(avg("Emission_Levels_g_km").alias("weather_emission"), avg("Energy_Consumption_L_h").alias("weather_energy")).orderBy(desc("weather_emission"))
peak_off_peak_emission = df.withColumn("time_period", when((col("hour") >= 7) & (col("hour") <= 9), "早高峰").when((col("hour") >= 17) & (col("hour") <= 19), "晚高峰").otherwise("平峰")).groupBy("time_period").agg(avg("Emission_Levels_g_km").alias("period_emission"), avg("Energy_Consumption_L_h").alias("period_energy"))
occupancy_emission = df.withColumn("occupancy_level", when(col("Road_Occupancy_%") > 80, "拥堵").when(col("Road_Occupancy_%") > 50, "缓行").otherwise("畅通")).groupBy("occupancy_level").agg(avg("Emission_Levels_g_km").alias("occupancy_emission"))
daily_emission_trend = df.groupBy("hour").agg(avg("Emission_Levels_g_km").alias("hourly_emission"), avg("Energy_Consumption_L_h").alias("hourly_energy")).orderBy("hour")
vehicle_density_impact = df.withColumn("density_level", when(col("Vehicle_Count") > 100, "高密度").when(col("Vehicle_Count") > 50, "中密度").otherwise("低密度")).groupBy("density_level").agg(avg("Emission_Levels_g_km").alias("density_emission"))
environmental_efficiency = df.withColumn("efficiency_ratio", col("Traffic_Speed_kmh") / (col("Emission_Levels_g_km") + 1)).groupBy("Traffic_Condition").agg(avg("efficiency_ratio").alias("env_efficiency")).orderBy(desc("env_efficiency"))
weather_energy_impact = df.groupBy("Weather_Condition").agg(avg("Energy_Consumption_L_h").alias("weather_energy_avg"), count("*").alias("weather_records")).orderBy(desc("weather_energy_avg"))
signal_emission_relation = df.groupBy("Traffic_Light_State").agg(avg("Emission_Levels_g_km").alias("signal_emission"), avg("Energy_Consumption_L_h").alias("signal_energy")).orderBy(desc("signal_emission"))
comprehensive_env_score = df.withColumn("env_impact_score", (col("Emission_Levels_g_km") * 0.6) + (col("Energy_Consumption_L_h") * 0.4)).groupBy("hour", "Weather_Condition").agg(avg("env_impact_score").alias("impact_score")).orderBy(desc("impact_score"))
emission_reduction_potential = df.filter(col("Traffic_Condition") == "High").agg(avg("Emission_Levels_g_km").alias("current_emission")).crossJoin(df.filter(col("Traffic_Condition") == "Low").agg(avg("Emission_Levels_g_km").alias("optimal_emission")))
reduction_potential = emission_reduction_potential.withColumn("reduction_percentage", ((col("current_emission") - col("optimal_emission")) / col("current_emission")) * 100)
green_travel_metrics = df.withColumn("green_score", 100 - ((col("Emission_Levels_g_km") / 300 * 50) + (col("Energy_Consumption_L_h") / 15 * 50))).groupBy("Traffic_Condition").agg(avg("green_score").alias("green_travel_score"))
environmental_result = comprehensive_env_score.toPandas()
environmental_result.to_csv("environmental_impact_analysis.csv", index=False)
return environmental_result
智能出行交通数据可视化分析系统-结语
💕💕
大数据实战项目
网站实战项目
安卓/小程序实战项目
深度学习实战项目
💟💟如果大家有任何疑虑,欢迎在下方位置详细交流,也可以在主页联系我。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 30
30 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)