数据分析---数据分析中的统计学基础
🌞欢迎来到数据分析的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
📆首发时间:🌹2025年9月28日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录

描述统计学
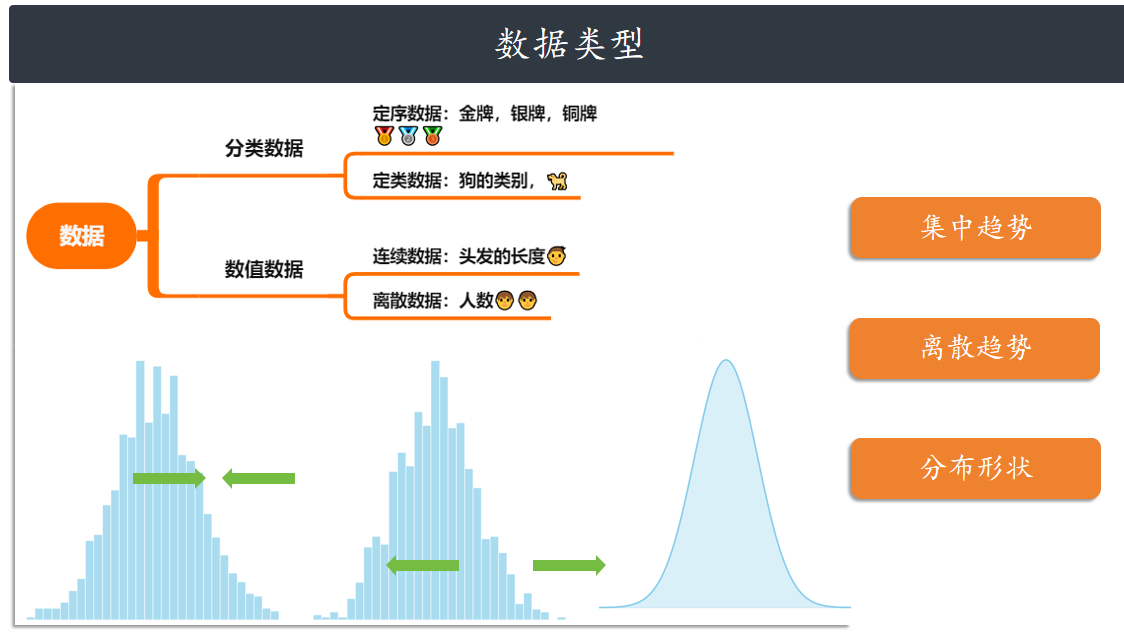
数据的分类和分析点
数据据分析和统计学是紧密关联的学科,统计学的核心功能是对数据进行描述和推断。
数据一般包括两大类,分类数据和数值数据。分类数据有包括定序数据(存在自然顺序(如奖牌的
金>银>铜)和定类数据: 无明确排序(如犬种之间无法客观排序)。数值数据分成连续数据和离散
数据。
数值数据通常是分析的重点,可以有三个分析的维度,集中趋势,离散趋势,分布形状。假设
我们要统计某省的高考人数的话,集中趋势是看数据集中的什么地方。离散趋势看数据偏离中心的
情况。分布形状看的是分布的对称程度。
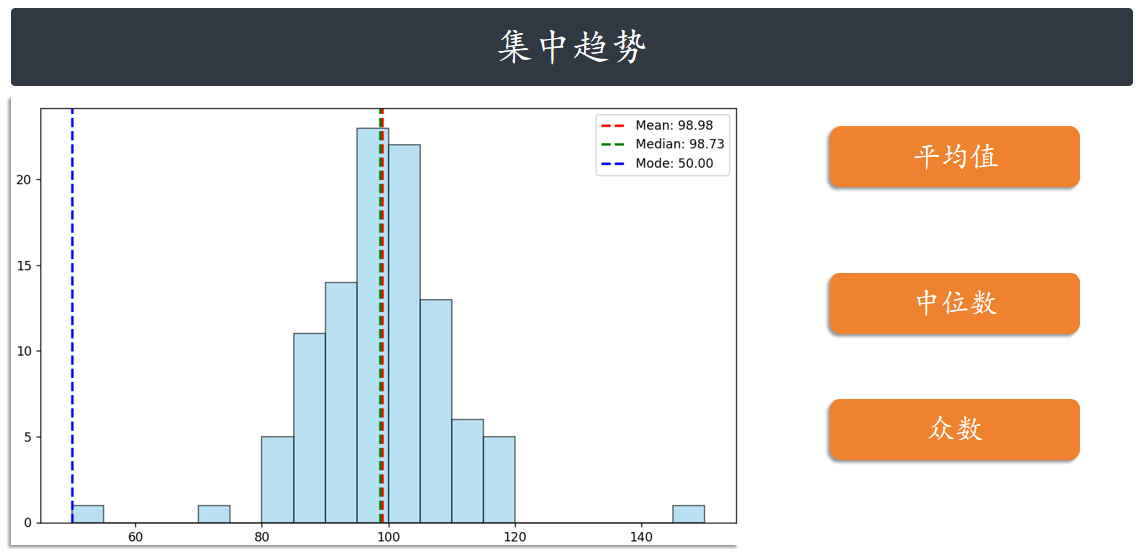
数据的集中趋势
用于度量数据分布的中心位置。直观地说,测量一个属性值的大部分落在何处。描述数据集中
趋势的统计量是:平均值、中位数、众数。
平均值(Mean):指一组数据的算术平均数,描述一组数据的平均水平,是集中趋势中波动最
小、最可靠的指标,但是均值容易受到极端值(极小值或极大值)的影响。
中位数(Median):指当一组数据按照顺序排列后,位于中间位置的数,不受极端值的影响,对
于定序型变量,中位数是最适合的表征集中趋势的指标。
众数(Mode):指一组数据中出现次数最多的观测值,不受极端值的影响,常用于描述定性数据
的集中趋势。
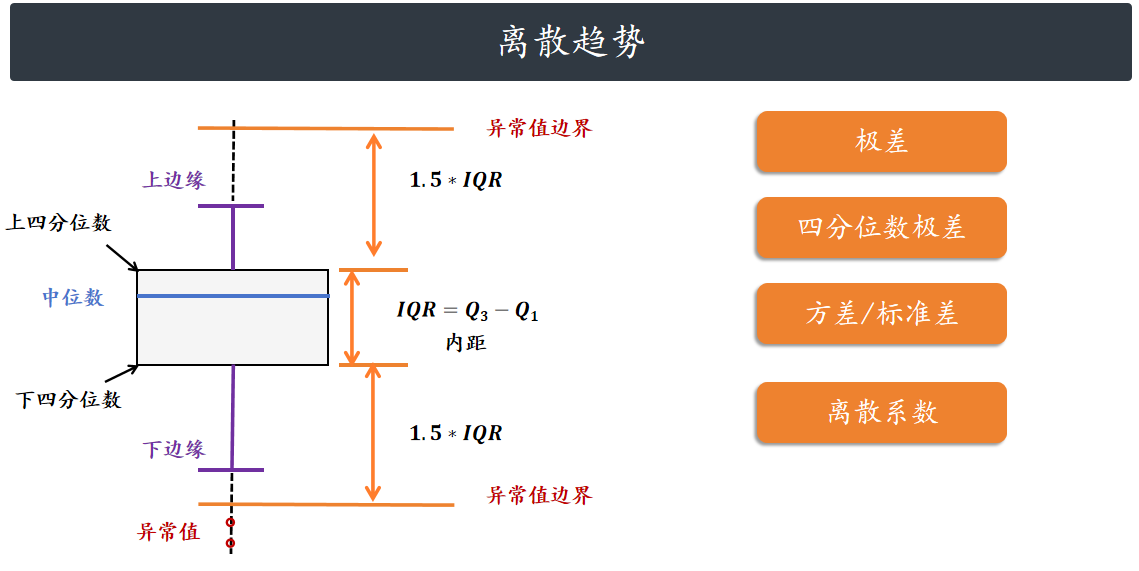
数据的离散趋势
用于描述数据的分散程度,描述离散趋势的统计量是:极差、四分位数极差
(IQR)、标准差、离散系数。
极差(Range):又称全距,记作 ,是一组数据中的最大观测值和最小观测值之差。一般情况
下,极差越大,离散程度越大,其值容易受到极端值的影响。
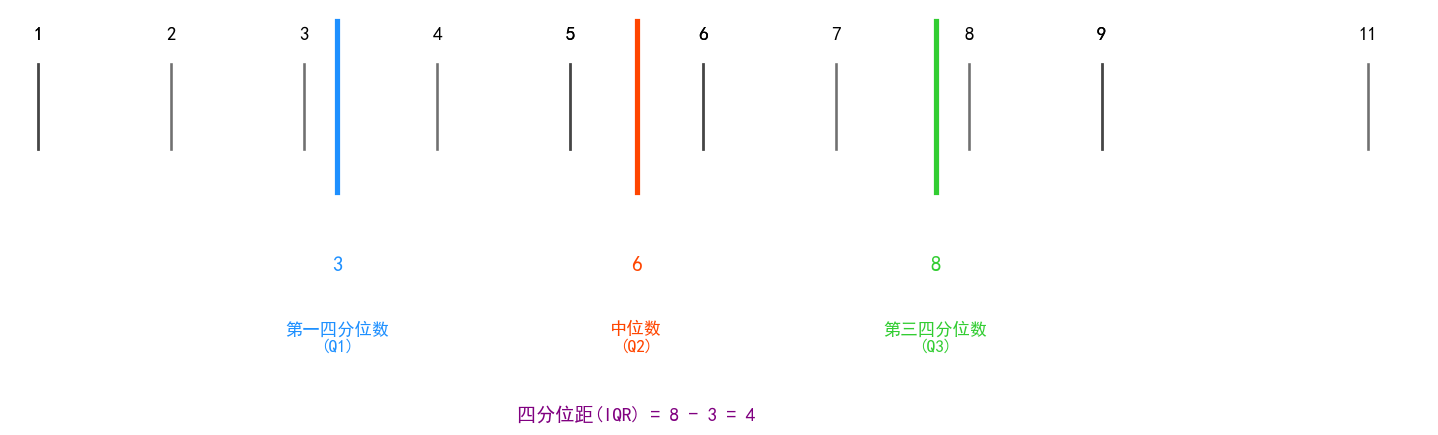
四分位数极差(Inter-Quartile Range, IQR):又称内距,是上四分位数和下四分位数的差值,给
出数据的中间一半所覆盖的范围。是统计分散程度的一个度量,分散程度通过需要借助箱线图
(Box Plot)来观察。
方差(Variance):方差和标准差是度量数据离散程度时,最重要、最常用的指标。方差,是每个
数据值与全体数据值的平均数之差的平方值的平均数。
标准差(Standard Deviation):又称均方差,常用 表示,是方差的算术平方根。计算所有数值相
对均值的偏离量,反映数据在均值附近的波动程度,比方差更方便直观。
离散系数(Coefficient of Variation):又称变异系数,为标准差 与平均值 之比,用于比较不同样
本数据的离散程度。离散系数大,说明数据的离散程度大;离散系数小,说明数据的离散程度也
小。
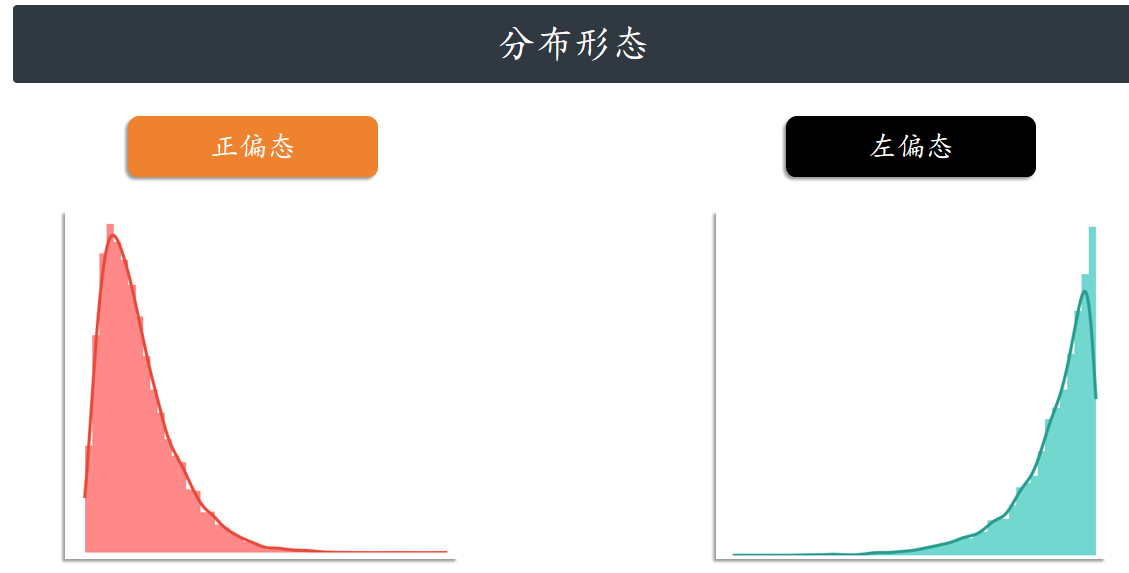
分布形态
偏度(Skewness):用来评估一组数据分布呈现的对称程度。当 偏度系数 =0时,分布是对称的
当 偏度系数 >0时,分布呈正偏态(右偏)当 偏度系数 <0时,分布呈负偏态(左偏)。
峰度(Kurtosis):用来评估一组数据的分布形状的高低程度的指标。当 峰度系数=0时,是正态分
布当 峰度系数 >0时,分布形态陡峭,数据分布更集中当 峰度系数 <0时,分布形态平缓,数据分
布更分散。
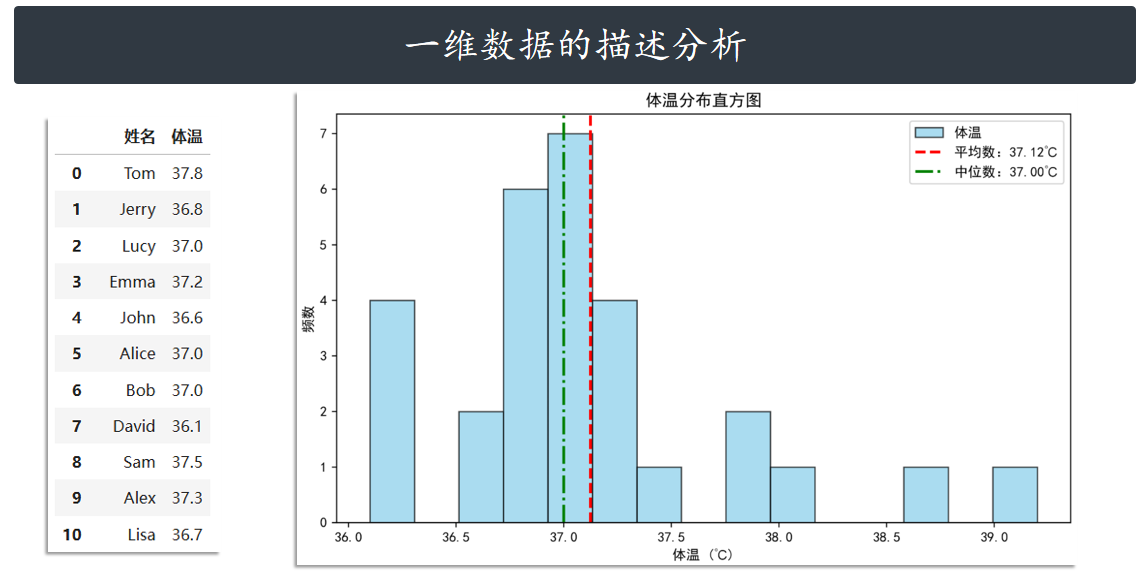
一维数据的描述分析
描述统计学的分析对象很多时候是一维的数据,现在我们有一个数据集,记录了今天每个人的体
温数据。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
# 配置字体以避免中文显示错误和警告
# 使用系统默认 sans-serif 字体族,并优先尝试常见中文字体
matplotlib.rcParams["font.family"] = ["sans-serif"]
matplotlib.rcParams["font.sans-serif"] = [
"SimHei", "WenQuanYi Micro Hei", "Heiti TC", # 常见中文字体
"Microsoft YaHei", "Arial Unicode MS", # 兼容Windows和Mac
"sans-serif" # 回退到系统默认sans-serif
]
matplotlib.rcParams['axes.unicode_minus'] = False # 正确显示负号
# 读取数据集
df1 = pd.read_csv("temperature.csv")
# 计算各项统计指标
mean_temp = df1['体温'].mean()
median_temp = df1['体温'].median()
mode_temp = df1['体温'].mode()
range_temp = np.array(df1['体温']).ptp()
var_temp = df1['体温'].var()
std_temp = df1['体温'].std()
q1 = df1['体温'].quantile(0.25)
q3 = df1['体温'].quantile(0.75)
iqr_temp = q3 - q1
# 打印统计结果
print("体温数据统计分析结果:")
print(f"平均数:{mean_temp:.2f}℃")
print(f"中位数:{median_temp:.2f}℃")
print(f"众数:{mode_temp.values}℃")
print(f"极差:{range_temp:.2f}℃")
print(f"方差:{var_temp:.4f}")
print(f"标准差:{std_temp:.2f}℃")
print(f"四分位距:{iqr_temp:.2f}℃")
# 绘制直方图(无警告版本)
plt.figure(figsize=(8, 5),dpi=500)
ax = plt.gca() # 获取当前轴对象
df1['体温'].plot(kind='hist', bins=15, alpha=0.7, color='skyblue', edgecolor='black', ax=ax)
# 添加参考线和标签
ax.axvline(mean_temp, color='red', linestyle='--', linewidth=2, label=f'平均数:{mean_temp:.2f}℃')
ax.axvline(median_temp, color='green', linestyle='-.', linewidth=2, label=f'中位数:{median_temp:.2f}℃')
ax.set_title('体温分布直方图')
ax.set_xlabel('体温 (℃)')
ax.set_ylabel('频数')
ax.legend()
plt.tight_layout()
plt.show()
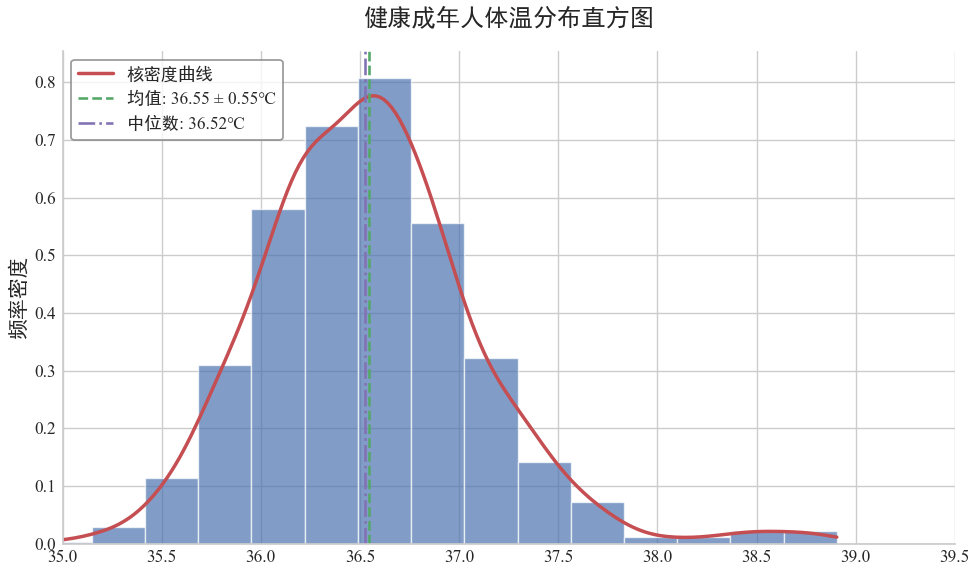
如果我们的数据包含一个数值变量,可以绘制直方图、密度图、箱形图、小提琴图。
直方图是一种用于展示连续型数据分布特征的统计图表,通过将数据划分为若干连续的区间(
bins),用矩形的高度表示每个区间内数据的频数(或频率),直观反映数据的集中趋势、离散程
度和分布形态(如是否对称、是否有偏态等)。
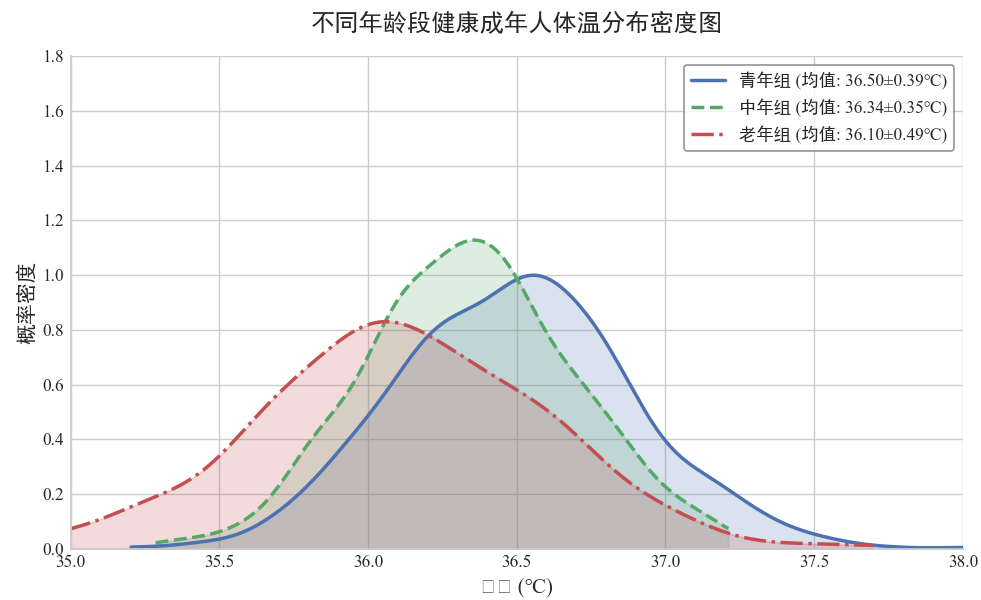
密度图是一种通过平滑曲线展示连续数据分布特征的统计图表,它基于核密度估计(KDE)方
法,能够更清晰地呈现数据的概率分布形态,比直方图更能反映数据的整体分布趋势。
箱形图通过四分位数展示数据的分布特征,能直观呈现数据的集中趋势、离散程度和异常值,
是科研中展示单组或多组数据分布的常用工具。
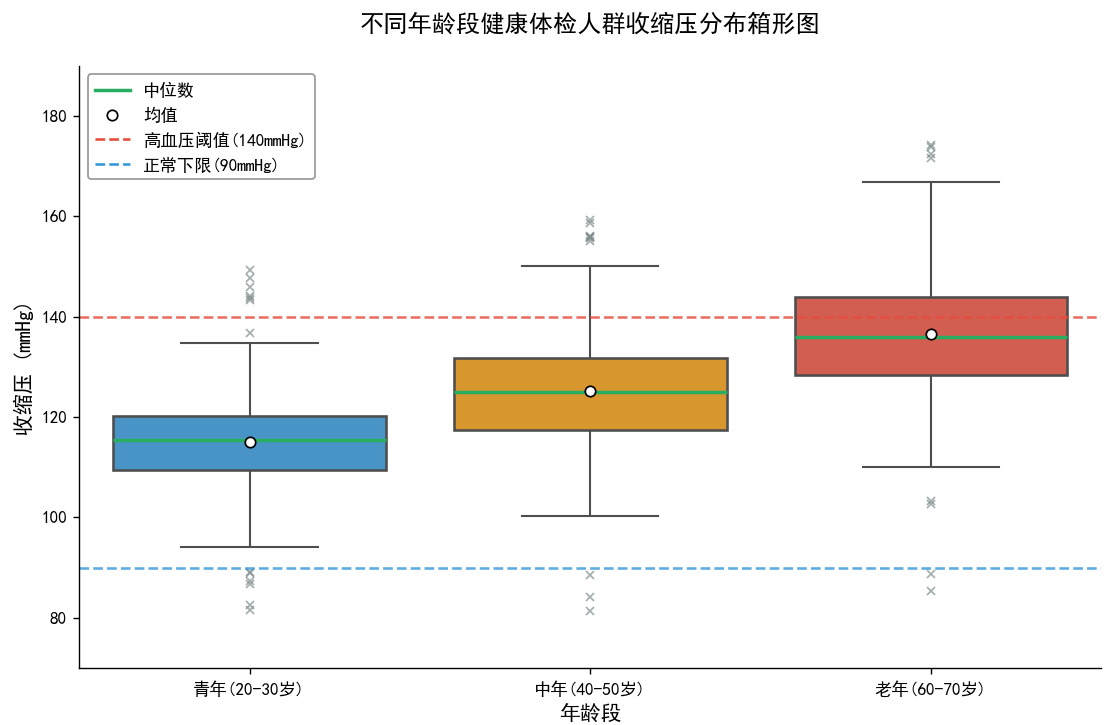
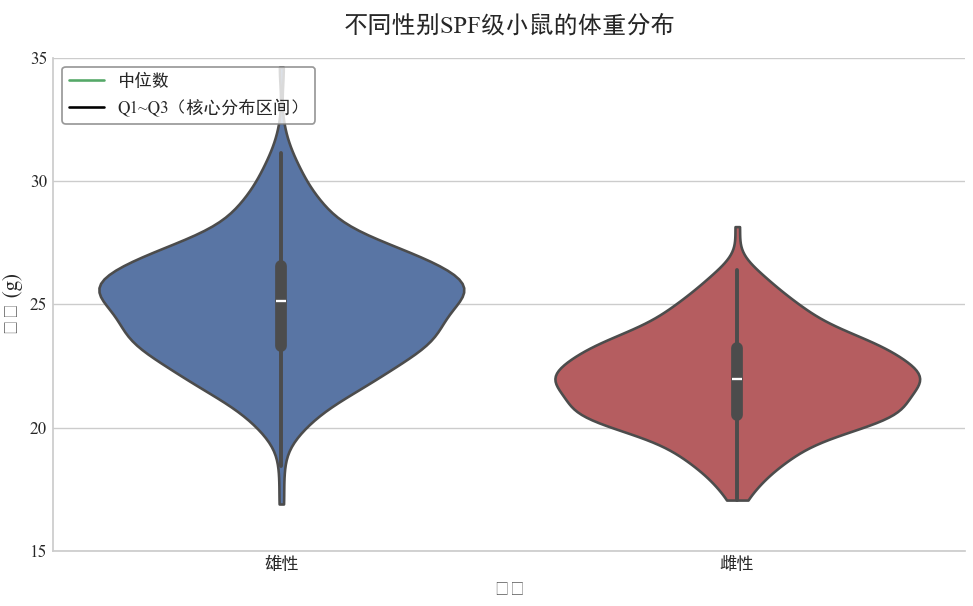
小提琴图(Violin Plot)是一种融合了箱形图的统计分位数信息与密度图的分布形态信息的高级
可视化工具,能同时呈现数据的 “集中趋势、离散程度” 和 “概率密度分布”,在科研数据分析中常
用于多组连续数据的对比分析(如不同实验组、不同人群的指标分布差异)。
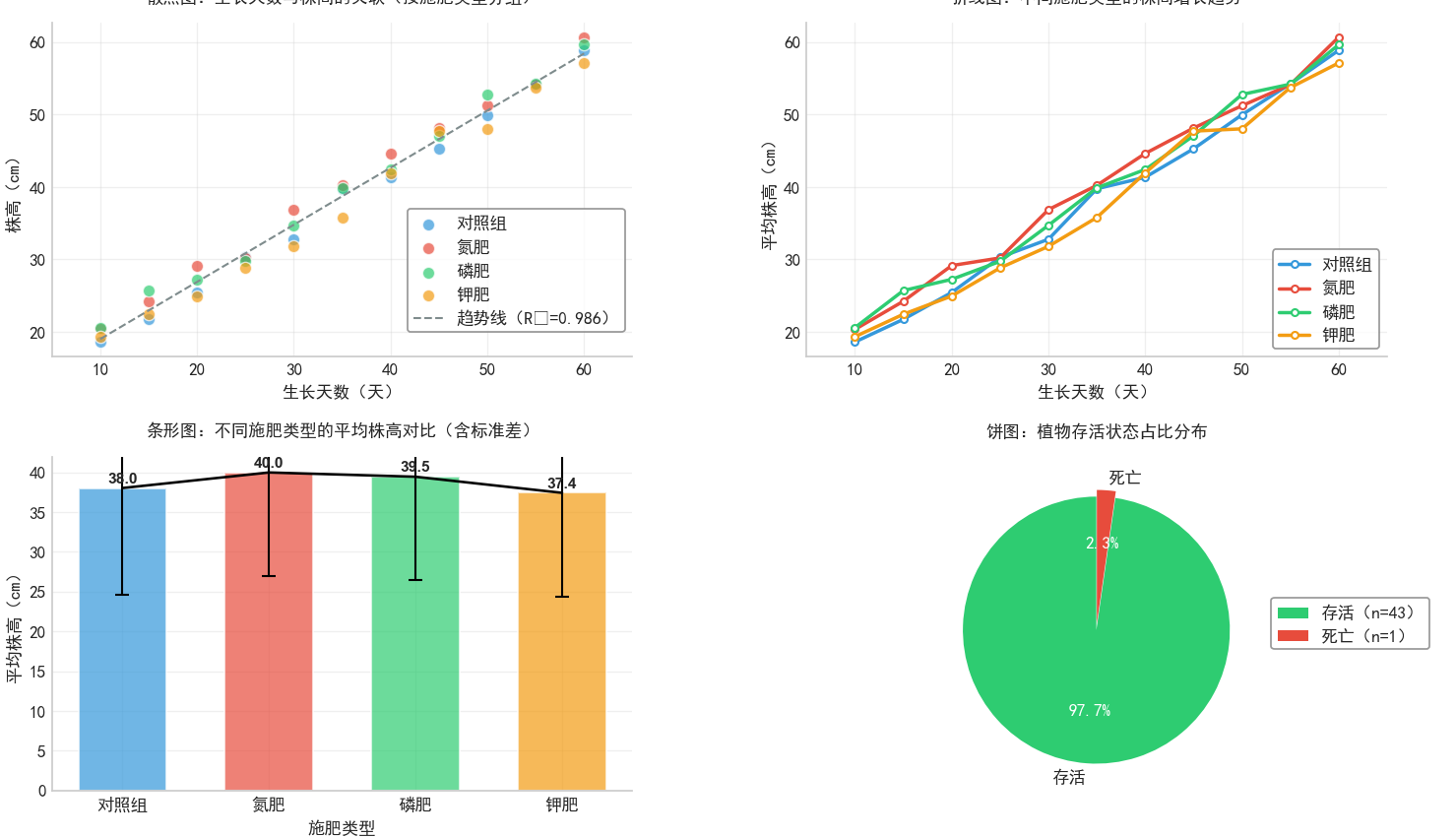
二维数据的描述分析
如果我们的数据中包含两个变量,可以绘制散点图,折线图,条形图,饼图。
| 表类型 | 双变量组合 | 核心用途 | 科研注意事项 |
|---|---|---|---|
| 散点图 | 连续 × 连续 | 展示变量关联(如相关性) | 需分组时用颜色区分,添加趋势线和 R² 值 |
| 折线图 | 连续自变量 × 连续因变量 | 展示变化趋势(如时间序列) | 用均值减少误差,添加标记点,避免线条过多 |
| 条形图 | 离散 × 连续 | 组间均值对比(如不同处理的效果) | 必须添加误差线(标准差 / 标准误),y 轴从 0 开始 |
| 饼图 | 离散 × 占比 | 类别构成比例(如存活 / 死亡占比) | 类别数≤5,标注百分比和样本量,避免 3D 效果 |
多维数据的描述分析
三个变量
(1)可以使用3D 散点图(最常用,展示三变量空间分布)
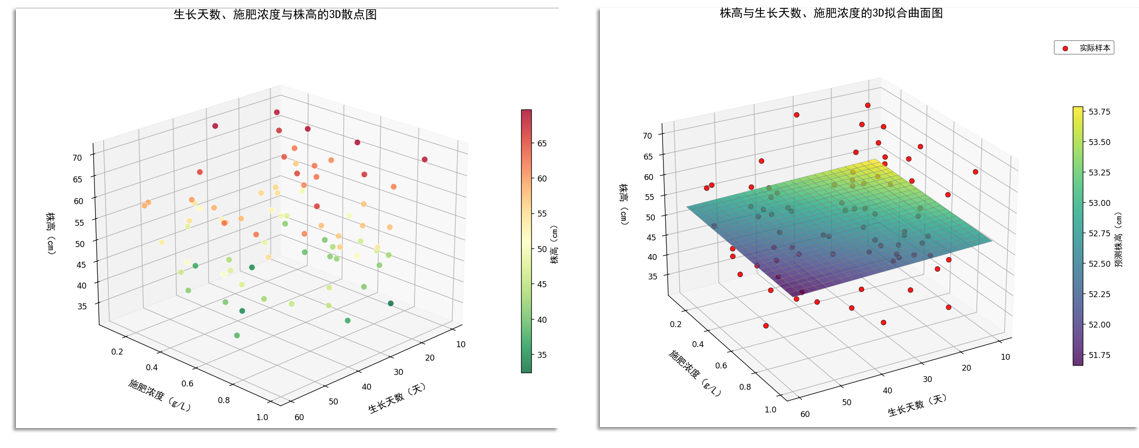
(2)多个简单图的符合
(3)降维+简单图可视化

多个变量
| 变量数量 | 变量类型组合 | 推荐可视化方法 | 核心优势 |
|---|---|---|---|
| 3-4 个 | 2 数值 + 1-2 分类 / 数值 | 散点图(颜色 / 大小映射) | 直观展示变量间关联 |
| 4-6 个 | 混合类型 | 分面网格图 | 按分类变量拆分对比 |
| 6-10 个 | 以数值型为主 | 相关性热力图 + 散点图矩阵 | 展示两两关系和分布 |
| 10 + 个 | 高维数值型 | PCA 降维 + 散点图 | 保留核心信息,简化展示 |
| 10 + 个 | 需保留原始维度 | 平行坐标图 | 展示全维度特征差异 |
推断统计学
引入:
假设你现在想举办一个新活动去增加用户的平均的付费值。在活动开始之前,你随机选择了一小批
的客户,然后分成两组。一组参加新的活动,一组参加老的活动。然后统计数
据。统计之后你发现,新活动的付费平均值比老活动平均值多4.6元。但是付费平均值变化了,不
一定是因为活动变化了,也有可能是因为随机,如何知道是因为活动的变化所以才导致了平均值的
增长?这个时候就需要假设检验。
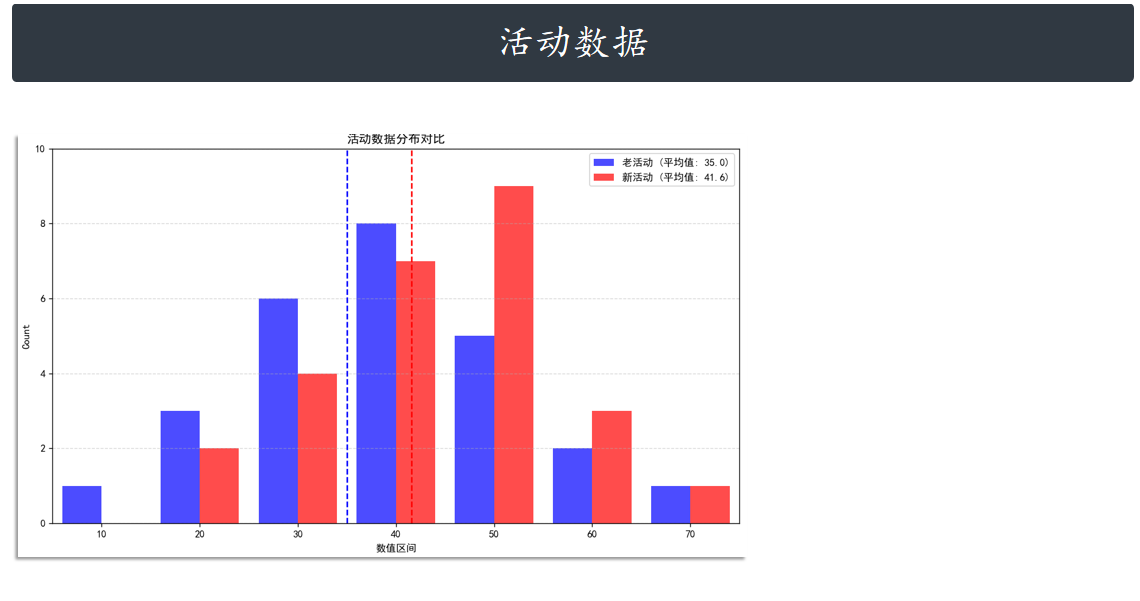
这个时候就可以使用统计学中的独立双样本T检验,来完成这个任务。独立说明样本来自不同的整
体,双样本说明比较的是两个不同样本的数据,T检验是由于确定样本的平均值之间是否存在显著
差异。简单来说T检验是一个统计学的方法用来确定两个样本之间是否存在统计学上的显著差异还
是,差异是来源于随机,使用T 检验的前提是,样本是随机的,且大致呈正态分布。
假设检验(T检验和Z检验)
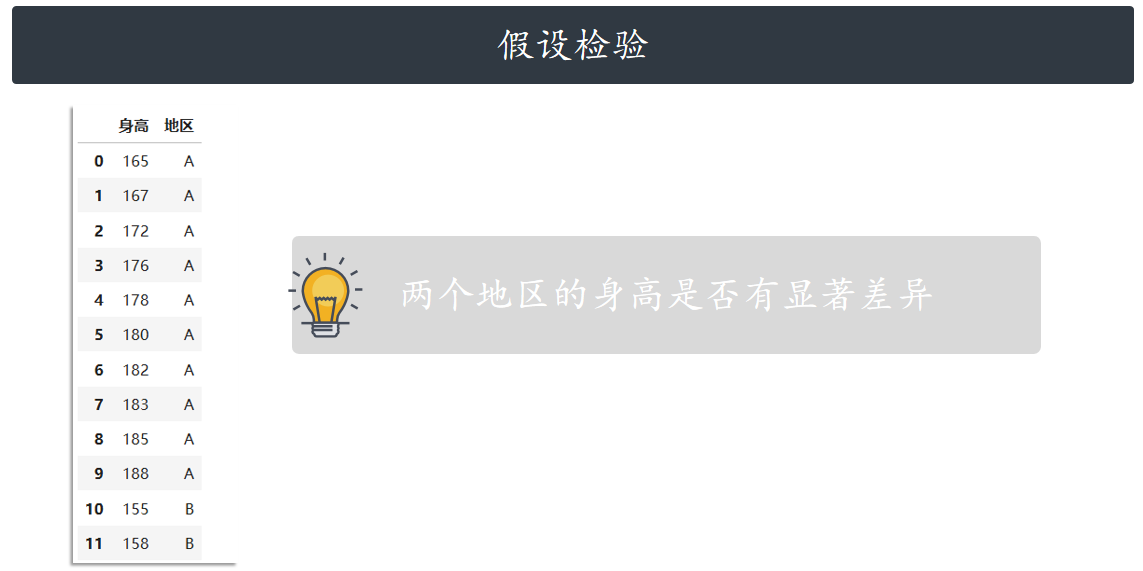
T检验
# 进行t检验
t_stat, p_value = ttest_ind(region_a_height, region_b_height)
print(t_stat, p_value)
# 显著水平为0.05(显著水平一般用alpha字母表示)
alpha = 0.05
# 比较计算出的p值和显著水平
if p_value < alpha:
print('两组数据有显著差异')
else:
print('两组数据无显著差异')Z检验
# 计算z值和p值(双尾)
z_stat, p_value = ztest(region_a_height2, region_b_height2,
alternative='two-sided')
print(z_stat, p_value)
# 显著水平为0.05(显著水平一般用alpha字母表示)
alpha = 0.05
# 比较计算出的p值和显著水平
if p_value < alpha:
print('两组数据有显著差异')
else:
print('两组数据无显著差异')# 计算z值和p值(单尾正差异)
z_stat, p_value = ztest(region_a_height2, region_b_height2,
alternative='larger')
print(z_stat, p_value)
# 显著水平为0.025(显著水平一般用alpha字母表示)
alpha = 0.025
# 比较计算出的p值和显著水平
if p_value < alpha:
print('两组数据有显著差异')
else:
print('两组数据无显著差异')

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 36
36 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)