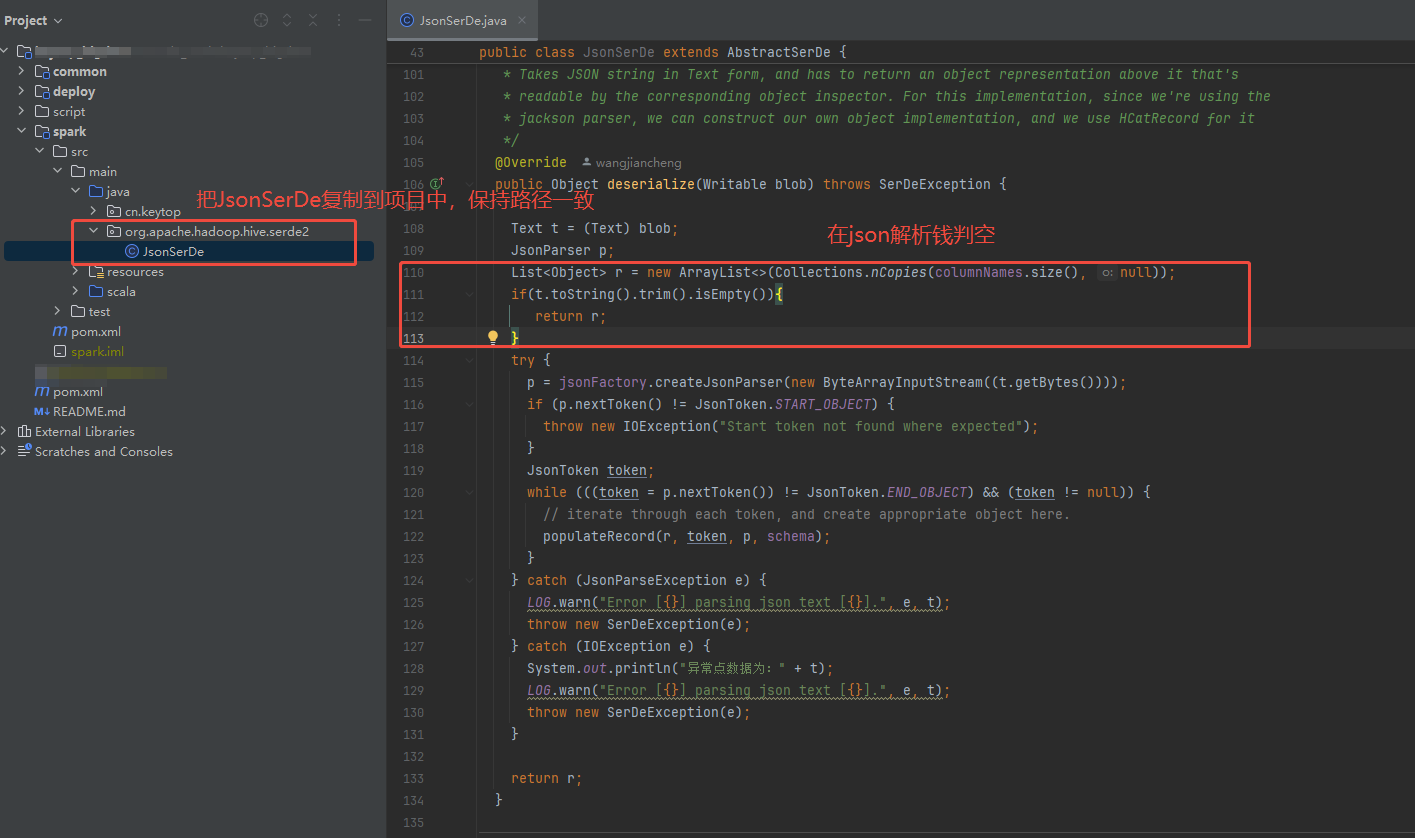
37、org.apache.hadoop.hive.serde2.JsonSerDe的源码修改
·
在spark-measure源码修改用于数据质量笔记中,说到了使用hive外部表读取spark-measure的监测结果json数据。hive外部表ddl使用了 ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.JsonSerDe’ 。但是在spark离线项目中因为hive版本的原因导致spark无法通过hive表读取数据。
主要有以下几个问题:
1.缺少 org.apache.hadoop.hive.serde2.JsonSerDe 包,报错:
2025-07-15 16:47:19,381 ERROR main hive.log.getDeserializer(397) - error in initSerDe: java.lang.ClassNotFoundException Class org.apache.hadoop.hive.serde2.JsonSerDe not found
java.lang.ClassNotFoundException: Class org.apache.hadoop.hive.serde2.JsonSerDe not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2273)
at org.apache.hadoop.hive.metastore.MetaStoreUtils.getDeserializer(MetaStoreUtils.java:385)
at org.apache.hadoop.hive.ql.metadata.Table.getDeserializerFromMetaStore(Table.java:276)
at org.apache.hadoop.hive.ql.metadata.Table.getDeserializer(Table.java:258)
at org.apache.hadoop.hive.ql.metadata.Table.getCols(Table.java:605)
2.文件中存在空行或者存在空文件的情况,导致json解析报错:
org.apache.hadoop.hive.serde2.SerDeException: java.io.IOException: Start token not found where expected
at org.apache.hadoop.hive.serde2.JsonSerDe.deserialize(JsonSerDe.java:127)
at org.apache.spark.sql.hive.HadoopTableReader$$anonfun$fillObject$2.apply(TableReader.scala:452)
at org.apache.spark.sql.hive.HadoopTableReader$$anonfun$fillObject$2.apply(TableReader.scala:451)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
解决思路方案:
在项目中重写 org.apache.hadoop.hive.serde2.JsonSerDe 类,即可解决hive版本冲突问题,又可重新实现空行或者空文件的处理。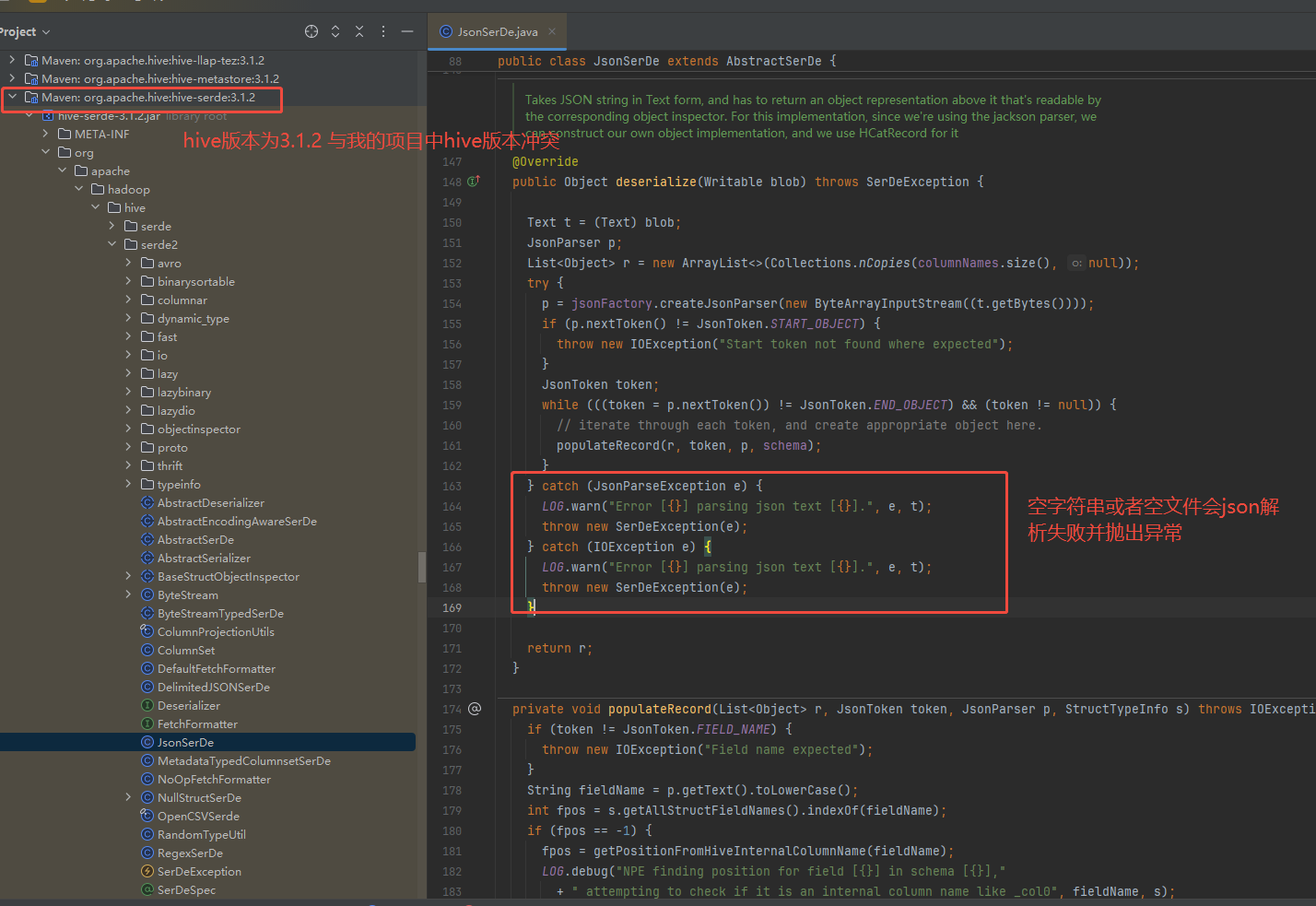

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)