0.3 神经网络学习率、激活函数、损失函数
loss_ce2 = tf.nn.softmax_cross_entropy_with_logits(y_, y)//同时softmax并且求交叉熵。首先relu激活函数、输入特征标准化(0为均值,1为标准差)、初始参数以0为均值,以sqrt(2/特征个数)为标准差正态分布。解决了ReLU的“Dead ReLU”问题,因为负区间有一个小的斜率,使得负输入也有梯度。解决了ReLU的“Dead ReL
1.神经元网络的空间复杂度,时间复杂度
以下图为例:
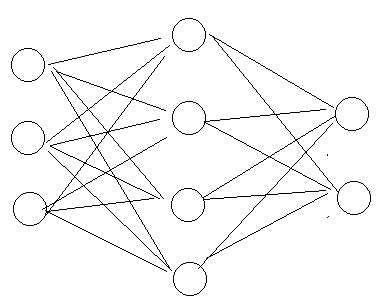
| 空间复杂度 |
层数 = 隐藏层层数 + 1个输出层 = 2 总参数(w,b数量) = 3x4+4 + 4x2+2=26 |
| 时间复杂度 |
乘加运算次数=3x4+4x2=20 |
2.学习率
可以先用较大的学习率,快速得到最优解,然后逐步减小学习率,使得模型在训练后稳定。
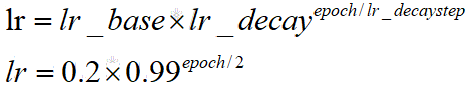
3.激活函数
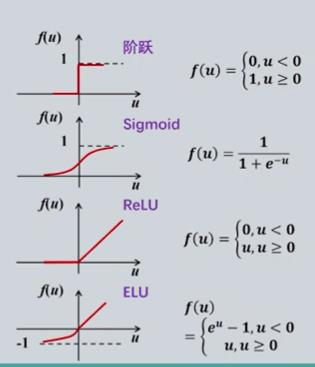
| 优点 | 缺点 | |
| Sigmoid |
输出范围在 (0,1) 之间,适合作为概率输出。 函数平滑,易于求导 |
|
|
Tanh |
|
|
| ReLU |
|
|
| Leaky ReLU |
|
|
| ELU 函数 |
|
|
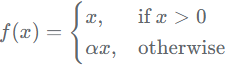
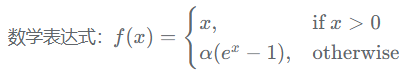
对于初学者:
首先relu激活函数、输入特征标准化(0为均值,1为标准差)、初始参数以0为均值,以sqrt(2/特征个数)为标准差正态分布。
4.损失函数
a).均方误差:tf.reduce_mean(tf.square(y_ - y))
b).交叉熵:![]()
loss_ce1 = tf.losses.categorical_crossentropy([1,0],[0.6,0.4])
loss_ce2 = tf.losses.categorical_crossentropy([1,0],[0.8,0.2])
print(loss_ce1,loss_ce2) //0.5108256, 0.22314353. 可见前一项误差更大,交叉商也更大。
使用前一般需要先用softmax把结果概率化,再使用交叉熵,但是也有函数
y_ = np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1], [1, 0, 0], [0, 1, 0]])
y = np.array([[12, 3, 2], [3, 10, 1], [1, 2, 5], [4, 6.5, 1.2], [3, 6, 1]])
y_pro = tf.nn.softmax(y)
loss_ce1 = tf.losses.categorical_crossentropy(y_,y_pro)
loss_ce2 = tf.nn.softmax_cross_entropy_with_logits(y_, y) //同时softmax并且求交叉熵。
print('分步计算的结果:\n', loss_ce1)
print('结合计算的结果:\n', loss_ce2) //两者结果一致
5.欠拟合和过拟合。
| 表现 | 主要原因 | |
过拟合 (Overfitting) |
|
|
欠拟合 (Underfitting) |
|
|
【代码】
以一个y=2x1+ x2的生成的32对数据,输入模型Y=WX,求出X。
1.方法1:损失函数使用。结果w=【2,1】计算良好
import tensorflow as tf
import numpy as np
SEED = 23455
rdm = np.random.RandomState(seed=SEED) # 生成[0,1)之间的随机数
x = rdm.rand(32, 2)
y_ = [[2*x1 + x2 + (rdm.rand() / 10.0 - 0.05)] for (x1, x2) in x] # 生成噪声[0,1)/10=[0,0.1); [0,0.1)-0.05=[-0.05,0.05)
x = tf.cast(x, dtype=tf.float32)
w1 = tf.Variable(tf.random.normal([2, 1], stddev=1, seed=1))
epoch = 15000
lr = 0.002
for epoch in range(epoch):
with tf.GradientTape() as tape:
y = tf.matmul(x, w1)
loss_mse = tf.reduce_mean(tf.square(y_ - y))
grads = tape.gradient(loss_mse, w1)
w1.assign_sub(lr * grads)
if epoch % 1000 == 0:
print("After %d training steps,w1 is " % (epoch))
print(w1.numpy(), "\n")
print("Final w1 is: ", w1.numpy())

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)