小白也能看懂!!数据库表设计流程,超详细讲解!!!
本文通过奶茶拼团案例,讲解了电商拼团系统的数据库表设计方法。首先从业务场景出发,梳理拼团流程,包括活动配置、用户开团、参团及结果处理等环节。然后详细解析了四张核心表:拼团活动表(记录规则)、折扣表(管理优惠)、用户拼单表(跟踪团状态)和拼单明细表(记录参与者)。文章还介绍了索引优化技巧,并分别从运营和用户视角分析了数据流转过程。最后提供了面试常见问题的解答思路,涵盖业务流程、数据一致性、高并发处理
本文中将以故事的形式让大家简单了解整个流程,再以项目中的库表,对应的功能与作用,从商家与用户两端视角来深入理解库表设计的目的.
以生活中电商的拼团为主要场景,以它为案例来分析讲解.
以及我们以后自己需要设计库表需要怎么样的操作.
让大家在面试问到项目的时候也可以轻松讲出自己的设计理念.
一.数据库表设计简单介绍
1.数据库表设计的用处
(1)在咱们设计数据库表的时候,你需要了解整个业务的执行流程,这些过程,其中哪些部分需要哪些数据作为支撑.合理的数据结构库表设计,会让你的系统逻辑实现容易理解.
(2)库表设计,与代码的逻辑实现息息相关,设计的好,编码会很轻松.熟悉这里的知识大家也可以从编码反推,看看数据库设计的合不合理.
2.一个糟糕的数据库表会导致的问题
(1)后期加字段困难
(2)查询性能差
(3)逻辑混乱
编辑的代码是对数据逻辑的呈现,数据流转调度的好坏来自于数据结构设计的是否合理”
明确本博客价值:通过一个完整案例,展示如何从业务需求推导出合理的库表设计
二.用奶茶拼团场景故事来讲述拼团库表设计流程
1.奶茶小故事背景
周一早9点,运营配置“工作日早鸟奶茶”活动
谢飞机看到活动,点击“开团”,成为团长
张三、李四在微信群看到链接,点击“参团”
系统检测到3人已满,状态变为“拼团成功”
系统回调订单服务,生成3个待支付订单
2.抛开技术,先来理解业务"故事"
先不管什么表,字段这些东西,我们先来讲这个故事
1.故事开场(运营):你,作为老板,决定搞一个活动:"原价15的奶茶,3人成团,团购价10元,活动持续一天."
2.特殊规则(扩展配置): 你觉得还不够,又想:“如果是我的老顾客(比如消费满5次的),可以再减2元!” 看,这里就有了两个折扣:基础折扣(减5元)和专属折扣(再减2元)。
3.故事发展(用户参与): 你的朋友谢飞机(用户)看到了这个活动,他决定发起一个团。系统会记录:“谢飞机开了一个奶茶团,还差2人。”
4.故事高潮(拼团过程): 另外两个朋友看到后,加入了谢飞机的团。系统需要记录谁加入了哪个团。
5.故事结局(成功/失败): 凑够了3个人,拼团成功!系统要标记这个团成功,并通知大家去付款。如果1小时内没凑够人,则拼团失败。
好了现在要把它翻译成数据库的语言
3.用库表来翻译故事
数据库就是很多张excel表格,每一个表记录一件事.
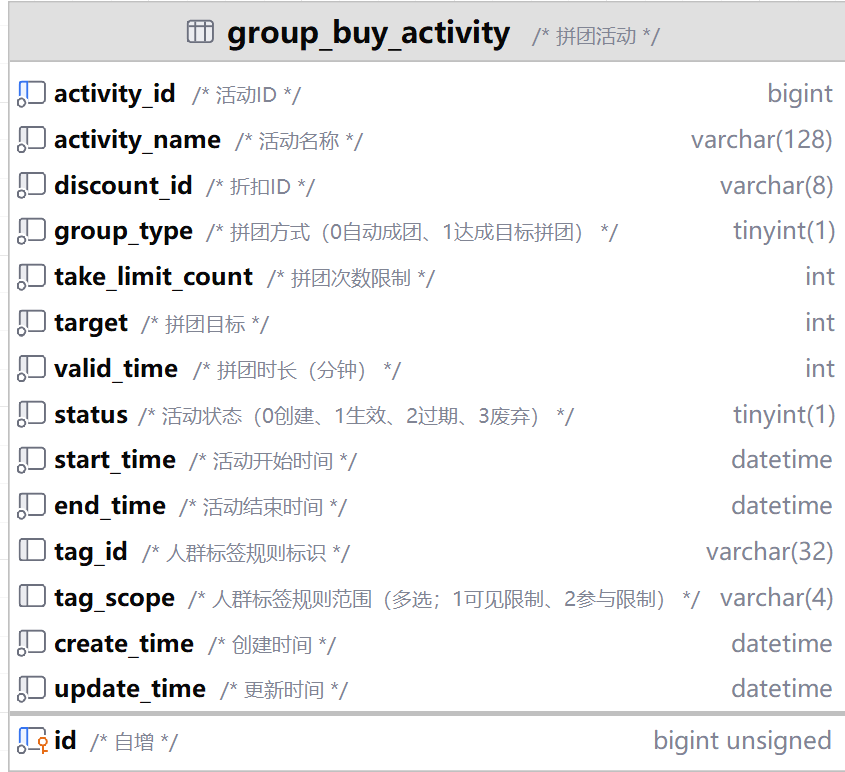
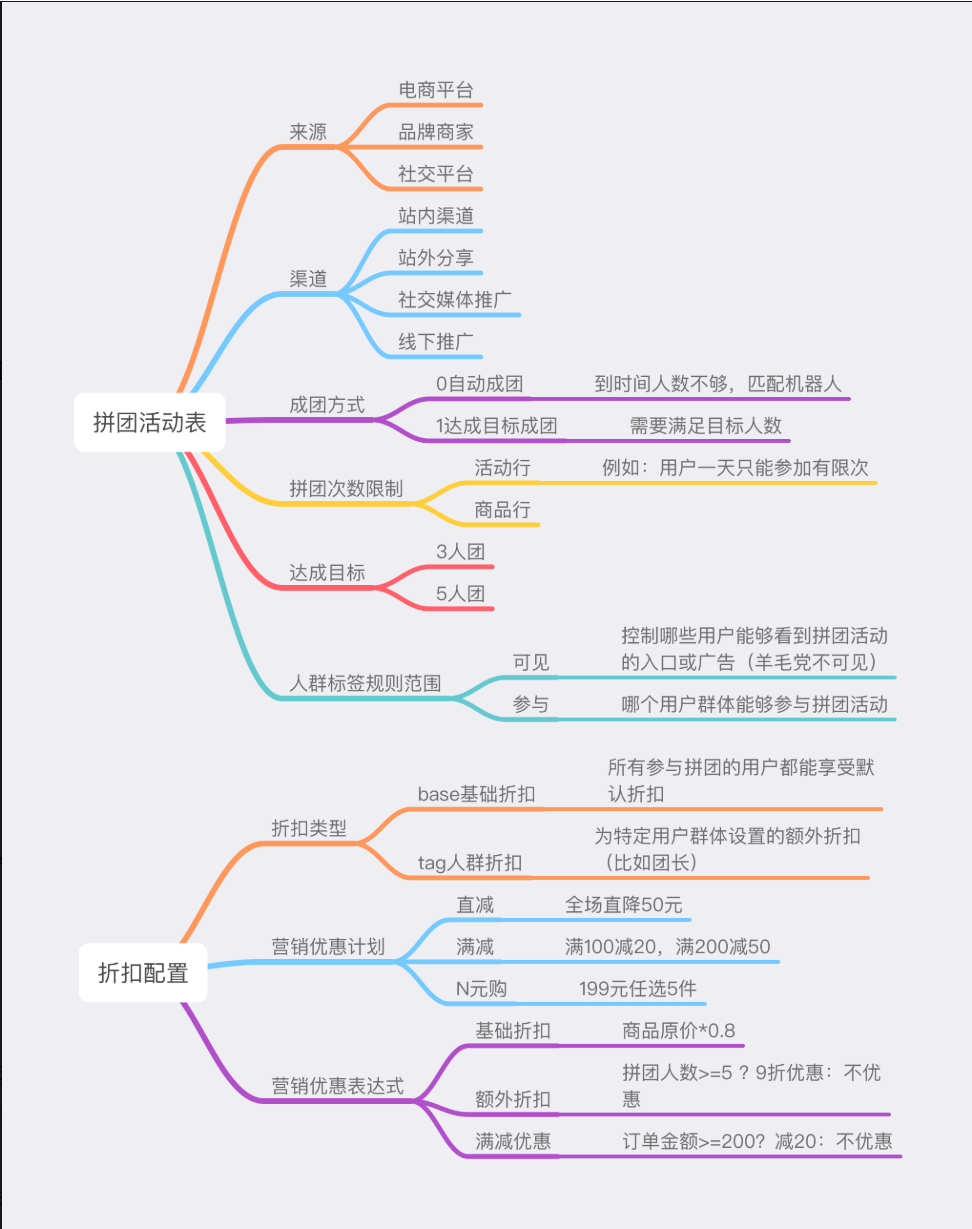
3.1.记录"活动规则"的表->group_buy_acticity(拼团活动表)
~~这张表就是用来写活动公告的~~
它是什么:就是你故事开场里面制定的所有规则.
核心字段:
- activity_id : 给这个活动一个唯一的编号,就像"活动001" .
- goos_id : 那个商品参加的活动?是轻乳茶还是珍珠奶茶?
- target : 目标几个人成团 上面是3个人.
- valid_time :组团时间多长? 这里60分钟.
- start_time/end_time :活动有效期,这里是一天.
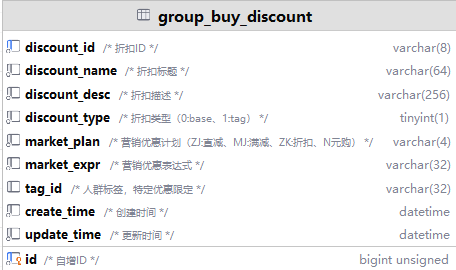
3.2.记录“特殊优惠”的表格 -> group_buy_discount(拼团折扣表)
为什么要把折扣单独放一张表?因为一个活动可能有多条优惠规则(比如基础折扣和专属折扣),如果都挤在活动表里,会非常乱。拆开来更清晰,这就是“数据库范式”的简单理解——让每张表只专心做好一件事。
-
它是什么: 记录了“减5元”和“老顾客再减2元”这些具体的优惠细节。
-
如何关联? 通过
discount_id这个字段,活动表(group_buy_activity)就知道该去折扣表(group_buy_discount)里找哪些优惠规则了。这就是表与表的链接(关联)!
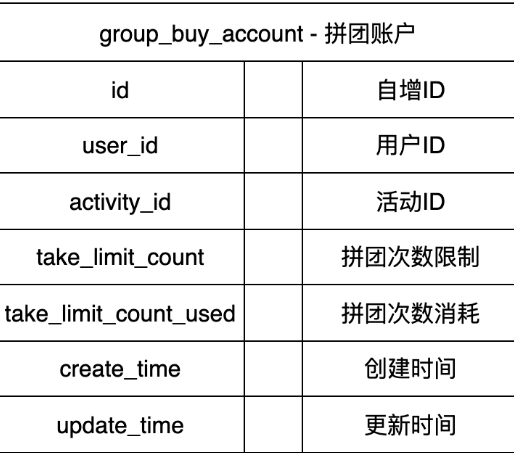
3.3. 记录“谁开了哪个团”的表格 -> group_buy_order(用户拼单表)
用户谢飞机点击“开团”后,就需要一张表来记录这个“团”本身。
-
它是什么: 记录了这个团的整体信息。
-
核心字段:
-
order_id:给这个团一个唯一的编号,比如“团A”。 -
activity_id:这个团参加的是哪个活动?(链接到group_buy_activity表),说明是“经典奶茶3人团”活动。 -
status:这个团的状态是“进行中”、“成功”还是“失败”? -
current_count:当前有几个人了?谢飞机开团时是1,每加入一个人,这个数字就+1。
-
3.4. 记录“团里都有谁”的表格 -> group_buy_order_list(拼单明细表)
光知道团里有3个人不够,我们还得知道具体是哪三个人。
-
它是什么: 记录了每个团(
group_buy_order)和每个参加者(user_id)的对应关系。 -
如何关联? 通过
order_id这个字段,链接到group_buy_order表。比如:-
order_id=“团A”,user_id=“谢飞机” -
order_id=“团A”,user_id=“张三” -
order_id=“团A”,user_id=“李四” -
这样我们就知道“团A”这个团由谢飞机、张三、李四组成。
-
小结: 现在你明白了,所谓的“库表设计”和“表关联”,就是把一个完整的业务故事,拆分成几个部分,分别用不同的本子(表)记录,并通过编号(如
activity_id,order_id)把这些本子里的信息串联起来。
三.简单了解索引
如何快速查询?—— “索引” 就像书的目录
现在数据都记好了。用户谢飞机想看看自己开了哪些团,怎么办?系统需要去 group_buy_order表里,查找所有 user_id= ‘谢飞机’ 的记录。
如果这张表有上百万条数据,一条条找会慢死。索引就是为解决这个问题而生的。
-
索引是什么? 它就是数据库表的“目录”。比如给
user_id字段加了索引,就像给一本按“用户ID”排序的电话簿加了拼音目录,找“谢飞机”时,通过目录能直接翻到“X”开头的页数,而不是从第一页开始翻。 -
怎么加索引? 通常给经常用来查询和链接的字段加索引,比如:
-
user_id(查用户信息) -
activity_id(查活动信息) -
order_id(查拼团信息) -
status(查进行中的团)
-
记住:主键(如 id)自动有索引
四.我的拼团项目
两个视角来描述
运营视角(配置端): 负责创建和管理拼团活动。对应
group_buy_activity(拼团活动表)、group_buy_discount(折扣配置表)等。核心是规则的定义。站在运营的角度,要为这次拼团配置对应的拼团活动。那么就会涉及到;给哪个渠道的什么商品ID配置拼团,这样用户在进入商品页就可以看到带有拼团商品的信息了。之后要考虑,这个拼团的商品所提供的规则信息,包括;折扣、时间、人数等。还要拿到折扣的一个试算金额。这个试算出来的金额,就是告诉用户,通过拼团可以拿到的最低价格.也就是奶茶店老板的工作角度.
用户视角(参与端): 用户发起和参与拼团。对应
group_buy_order(用户拼单表)、group_buy_order_list(拼单明细表)等。核心是行为的记录和状态的流转。站在用户的角度,是参与拼团。首次发起一个拼团与参与已存在的拼团进行数据的记录,达成拼团约定拼团人数后,开始进行通知。这个通知的设计站在平台角度可以提供回调,那么任何的系统也就都可以接入了。
那么由此构建出来两端,再从数据流转的角度分析
拼团状态机:拼单中 → 成功/失败
用户行为:开团 → 参团 → 支付 → 完成
面试可能被问
请描述一下用户从看到拼团商品到拼团成功的整个业务流程,以及数据在这些表里是如何流转的?”
标准回答思路:
活动预热: 运营人员在后台配置一个拼团活动(写入
group_buy_activity),并设置好折扣规则(写入group_buy_discount)。用户可见: 系统根据
activity_id和goods_id,将拼团商品展示给前端用户。发起拼团: 用户A点击“发起拼团”,系统:
检查用户参与次数(查询
group_buy_account)。创建一条新的拼团主记录(插入
group_buy_order,状态为“拼团中”)。将用户A自己作为第一个参团者,写入拼团明细(插入
group_buy_order_list)。更新用户A的参与次数(更新
group_buy_account)。参与拼团: 用户B、C等看到用户A发起的团,点击“参与拼团”,系统:
检查活动是否有效、该团是否已满人等。
将用户B、C的信息写入拼团明细表(
group_buy_order_list)。拼团成功/失败:
成功: 当参团人数达到
target目标时,系统将group_buy_order的状态更新为“成功”。同时,向回调任务表(notify_task)插入一条记录,异步通知其他系统(如订单、优惠券系统)处理后续逻辑。失败: 若在
valid_time内未达成目标,状态更新为“失败”,可能需要进行退款等操作。
拼团相关数据库表结构以及字段设计
1.配置拼团
为什么要把折扣拆分成独立的表?(
group_buy_discount)
设计原则: 符合数据库范式,特别是第二范式(2NF)和第三范式(3NF),目的是减少数据冗余。
业务灵活性: 一个拼团活动(
group_buy_activity)可以配置多个折扣规则(如:基础折扣+人群专属折扣)。如果都塞在活动表里,字段会变得非常臃肿且难以维护。拆开后,通过discount_id关联,结构清晰,扩展性强。面试点: 数据库三大范式是什么?你在设计中如何应用的?什么时候会反范式设计?(答:为了查询性能,可能会做适当的冗余,即空间换时间)。

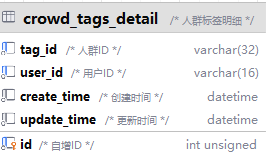
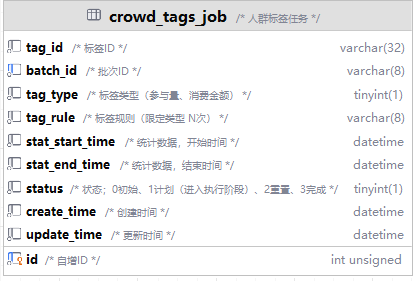
“人群”设计的作用是什么?
技术实现: 文档提到“把符合条件的用户ID写入到特定的Redis记录中”。这是一种高性能的设计。
为什么用Redis? 因为人群判断是高频的读操作。在用户访问拼团页时,需要快速判断他属于哪个人群,能否享受专属优惠。Redis基于内存,速度远快于数据库。
流程: 后台有一个定时任务,根据
group_buy_discount_tag表中的规则,计算符合条件的人群,将用户ID列表存入Redis的Set或ZSet数据结构中。前端查询时,直接使用SISMEMBER命令判断即可。面试点: Redis在你项目里的应用场景?为什么选它?还考虑了其他方案吗?(如布隆过滤器)?如何保证Redis和数据库的数据一致性?
2.参与拼团


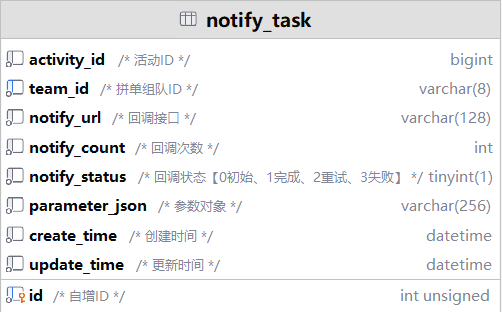
“回调任务表”(
notify_task)的设计体现了什么思想?
设计模式/思想: 体现了异步解耦和最终一致性的思想。
作用: 拼团成功后的通知操作(如发消息、核销优惠券)可能很耗时或可能失败。如果同步处理,会阻塞主流程,影响用户体验。将其放入任务表,由后台任务异步重试,保证了核心流程(改变拼团状态)的敏捷性,并通过重试机制(
notify_count,return_status)保证任务最终能完成。面试点: 如何保证分布式系统的最终一致性?你用过哪些消息队列(MQ)?这个回调表其实就是一个简单的“数据库MQ”,它和RabbitMQ/Kafka相比有什么优缺点?(答:实现简单,但性能和功能不如专业MQ,适用于业务量不大、一致性要求不是极端高的场景)。
五.面试问答
拼团业务核心概念与流程
这类问题考察你对业务本质的理解。
Q1: 简述拼团业务的核心流程和参与角色。
考察点:是否能用简洁的语言说清业务逻辑。
回答思路:
角色:运营人员(配置活动)、用户(团长、团员)。
流程:运营创建活动 → 用户(团长)开团并支付 → 分享邀请 → 用户(团员)参团支付 → 在规定时间和人数内达成目标,则拼团成功,系统处理订单;否则拼团失败,系统自动退款。
加分项:提及拼团模式变体,如阶梯拼团(人越多价越低)、限时拼团、模拟成团(保障商家现金流)等
数据库设计与数据一致性
这是面试官考察基本功的重中之重。
Q2: 拼团系统的核心表有哪些?它们之间的关系是怎样的?
考察点:数据库设计能力、对业务抽象能力。
回答思路:基于你项目中的表展开。
group_buy_activity(拼团活动表):核心配置。
group_buy_order(拼团主表):记录每个“团”的状态。
group_buy_order_list(拼团明细表):记录“团”与“用户”的多对多关系。关系:活动(1)对多个拼团(N);一个拼团(1)对多个参与明细(N)。
Q3: 如何解决高并发下的“超卖”问题?
考察点:并发控制、技术深度。
标准答案(分层递进):
数据库层面:
悲观锁:在查询库存时使用
SELECT ... FOR UPDATE锁定记录。简单但性能开销大,不适用于极高并发。乐观锁:在库存表中增加
version字段,更新时带版本条件:UPDATE stock SET quantity = quantity - 1, version = version + 1 WHERE product_id = ? AND version = ?。轻量,适合并发竞争不极端的场景。缓存层面(最优解):
Redis 原子操作:将库存提前加载到 Redis 中,利用
DECRBY或 Lua 脚本 保证原子性扣减。这是应对高并发秒杀的标准方案。架构层面:
异步化与队列:将下单请求送入消息队列(如 Kafka)进行缓冲,后端异步处理,实现流量削峰
并发控制与幂等性
Q4: 如何防止用户重复参团或重复下单?
考察点:幂等性设计。
回答思路:确保同一操作执行多次的结果与执行一次相同。
数据库唯一索引:在拼团明细表上对
(user_id, activity_id)或(user_id, group_buy_order_id)创建唯一索引,从根源杜绝重复。Token 机制:用户点击参团时,服务端生成一个一次性 Token,参团请求必须携带该 Token,校验后即失效。
分布式锁:在用户参团时,尝试获取一个以用户和活动为 Key 的分布式锁(如 Redis 锁),处理完再释放。
系统架构与性能优化
Q5: 拼团详情页访问量巨大,如何设计以保证高性能和高可用?
考察点:缓存架构、系统设计能力。
回答思路:遵循“尽量减少数据库直接压力”的原则。
多级缓存:
Redis缓存:将活动信息、拼团进度等热点数据存入 Redis,并设置合理过期时间。
本地缓存:在应用层使用 Caffeine 等缓存极少变动的数据(如活动基础规则),作为 Redis 宕机的兜底。
动静分离:将静态资源(图片、CSS/JS)推送到 CDN。
限流与降级:对详情页接口进行限流(如 Sentinel),防止恶意刷接口。在系统压力大时,可降级非核心功能(如实时排名)。
分布式事务与最终一致性
Q6: 拼团成功后,如何保证扣减库存、生成订单等操作的一致性?
考察点:分布式系统下的数据一致性方案。
回答思路:避免使用重量型分布式事务(如两阶段提交),推崇最终一致性。
本地事务+消息队列:创建订单和发送“扣减库存”消息放在一个数据库事务里。只要订单创建成功,消息最终会被发出,由库存服务消费。这是最常用的方案。
补偿机制:要有完善的对账和补偿任务,定期检查是否存在订单成功但库存未扣等异常状态,并自动修复。
故障处理与监控
Q7: 如果拼团失败,自动退款流程是如何设计的?
考察点:系统鲁棒性、业务流程闭环。
回答思路:
状态驱动:有一个定时任务扫描即将过期或已过期的拼团。
判断逻辑:检查当前参团人数是否达标。
执行退款:若未达标,调用支付服务提供的退款接口,并更新订单状态为“已退款”。
可观测性:整个流程的日志、调用链追踪(TraceId)要完备,便于排查问题。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)