分类问题数据可视化:混淆矩阵、ROC曲线与散点图实战教程
分类问题数据可视化:混淆矩阵、ROC曲线与散点图实战教程
分类问题可视化的价值与工具选择
从垃圾邮件识别到疾病诊断,分类问题几乎遍布机器学习的每个角落。当我们训练出一个模型,看到“准确率95%”的数字时,是否真的理解它的决策逻辑?为什么有时高准确率的模型在实际应用中却频频失误?数据可视化正是破解这些谜题的利器——它能将抽象的模型性能指标转化为直观图形,让“模型如何思考”变得清晰可懂。
可视化的核心价值在于“洞察”而非“展示”。混淆矩阵如同“分类CT扫描”,能逐类解析模型将A类错判为B类的具体情况,帮我们发现“把恶性肿瘤误判为良性”这类致命错误;ROC曲线则像模型的“耐力测试”,通过不同阈值下的真正率(TPR)与假正率(FPR)关系,评估其在不同场景下的泛化能力;而散点图能直接呈现特征空间中各类别的分布规律,让“两类样本是否线性可分”这类关键问题一目了然[1][2]。
工具选择指南:对于Python可视化入门者,推荐从“双剑合璧”开始——Matplotlib作为基础工具,像“万能画笔”支持从简单图表到复杂子图的全流程定制,其官方画廊提供了从坐标轴设置到注释添加的完整示例[3];Seaborn则是“快捷模板库”,基于Matplotlib开发,内置5种预设主题(如darkgrid、whitegrid)和优雅配色,几行代码就能生成 publication 级图表,特别适合快速绘制混淆矩阵热力图等统计图形[4]。
接下来,我们将通过3个核心案例(混淆矩阵热力图、ROC曲线绘制、特征空间散点图),结合完整代码实战(从数据准备到图表美化)和图表解析技巧(如何从图形中解读模型弱点),带你从零掌握分类问题可视化的实用技能。无论你是刚接触机器学习的新手,还是需要优化模型评估流程的开发者,这篇教程都能帮你把冰冷的数字转化为直观的业务洞察,让模型性能“看得见、用得好”。
混淆矩阵可视化:模型预测结果的全面解析
在分类模型评估中,混淆矩阵是直观展示预测结果与真实标签匹配情况的核心工具。它像一张"模型错题本",不仅能告诉你模型整体准确率,更能精准定位哪些类别容易混淆——比如在网络安全领域,区分"Normal"流量与"DoS攻击"是否存在误判?多分类场景下不同类别的混淆程度如何?通过可视化的混淆矩阵,这些问题都能迎刃而解。本文将从代码实现、适用场景到设计细节,全面解析如何用 Python 绘制专业级混淆矩阵,并结合实战案例帮助初学者掌握关键技巧。
一、完整代码实现:从函数定义到实战调用
以下是基于 matplotlib 构建的混淆矩阵可视化函数,支持数值与百分比双显示、自动文本颜色调整等功能,代码注释已针对初学者优化:
import itertools
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import confusion_matrix
def plot_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cmap=plt.cm.Blues):
"""
绘制混淆矩阵的核心函数
参数说明:
- cm: 混淆矩阵数组(必选),形状为 [n_classes, n_classes]
- classes: 类别标签列表(必选),如 ['Normal', 'DoS']
- normalize: 是否归一化(可选,默认 False),True 则显示百分比,适合不平衡数据集
- title: 图表标题(可选)
- cmap: 颜色映射(可选,默认蓝色渐变 plt.cm.Blues)
初学者注意:
1. 若输入的 cm 是 sklearn.metrics.confusion_matrix 的返回值,可直接传入
2. 类别名称需与 cm 的行/列顺序对应,避免标签错位
"""
# 归一化处理:将数值转换为百分比(按每行总和计算)
if normalize:
# 按行归一化,解决不平衡数据集中"数量多的类别掩盖问题"
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("归一化混淆矩阵(显示百分比):")
np.set_printoptions(formatter={'float': '{:0.2f}'.format}) # 保留两位小数
print(cm)
else:
print('非归一化混淆矩阵(显示具体数值):')
print(cm)
# 绘制热图:蓝色渐变映射数值大小
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title, fontsize=14) # 标题字体优化
plt.colorbar(label='比例' if normalize else '数量') # colorbar 标签说明
# 设置坐标轴标签:类别名称旋转45度避免重叠
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, ha='right') # ha='right' 右对齐旋转后的文本
plt.yticks(tick_marks, classes)
# 解决 matplotlib 版本兼容问题:部分版本 y 轴刻度会超出矩阵范围
plt.ylim(len(classes)-0.5, -0.5)
# 文本显示:根据背景色自动调整文字颜色(黑/白)
fmt = '.2f' if normalize else 'd' # 格式化字符串:百分比保留两位小数,数值用整数
thresh = cm.max() / 2. # 阈值:大于阈值用白色文字,否则黑色
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center", # 文本居中
color="white" if cm[i, j] > thresh else "black",
fontsize=10) # 文本大小适配矩阵尺寸
# 优化布局与标签
plt.tight_layout() # 自动调整布局,避免标签被截断
plt.ylabel('真实标签', fontsize=12)
plt.xlabel('预测标签', fontsize=12)
plt.show()
# ---------------------- 示例数据与调用 ----------------------
# 网络攻击类型分类的 5x5 混淆矩阵(示例数据)
# 行:真实标签 [Normal, DoS, Probe, R2L, U2R]
# 列:预测标签 [Normal, DoS, Probe, R2L, U2R]
cnf_matrix = np.array([
[8707, 64, 731, 164, 45], # Normal 真实标签的预测分布
[1821, 5530, 79, 0, 28], # DoS 真实标签的预测分布
[266, 167, 1982, 4, 2], # Probe 真实标签的预测分布
[691, 0, 107, 1930, 26], # R2L 真实标签的预测分布
[ 30, 0, 111, 17, 42] # U2R 真实标签的预测分布
])
attack_types = ['Normal', 'DoS', 'Probe', 'R2L', 'U2R'] # 类别名称
# 绘制非归一化混淆矩阵(查看数量分布)
plot_confusion_matrix(cnf_matrix, classes=attack_types,
title='网络攻击类型混淆矩阵(非归一化)')
# 绘制归一化混淆矩阵(查看比例分布)
plot_confusion_matrix(cnf_matrix, classes=attack_types, normalize=True,
title='网络攻击类型混淆矩阵(归一化)')
二、代码实现解析:从函数设计到初学者痛点
1. 核心功能拆解
上述代码实现了一个高度可定制的混淆矩阵绘制函数,核心功能包括:
- 双模式显示:支持原始数值(非归一化)和百分比(归一化)两种模式,前者适合查看绝对数量,后者适合分析不平衡数据集(如示例中"U2R"类别样本量少,归一化后更易观察其预测比例)。
- 自适应文本优化:通过阈值判断自动切换文本颜色(黑/白),解决了"深色背景配黑字"或"浅色背景配白字"的可读性问题。
- 版本兼容处理:
plt.ylim(len(classes)-0.5, -0.5)语句修复了部分 matplotlib 版本中 y 轴刻度超出矩阵范围的 bug,确保图像完整显示。
2. 初学者必知的关键参数
- normalize 参数:决定是否归一化。当数据不平衡时(如示例中"Normal"样本量远多于"U2R"),非归一化矩阵会被数量多的类别主导,难以观察少数类的混淆情况;归一化后按每行(真实标签)总和计算百分比,能公平展示每个类别的预测分布。
- cmap 参数:颜色映射选择。默认的
plt.cm.Blues蓝色渐变是工业界常用方案——蓝色对眼睛友好,且深浅差异明显,相比彩虹色(plt.cm.rainbow)更易区分数值大小。若需对比不同模型,可固定颜色映射范围(通过vmin=0, vmax=1参数)确保视觉一致性。
初学者常见误区:认为"矩阵对角线数值越大模型越好"。实际上,对角线仅代表正确预测比例,需结合具体场景判断。例如在医疗诊断中,“假阴性”(实际患病却预测为健康)可能比"假阳性"更严重,此时需重点关注特定非对角线元素(如第 1 行第 0 列的数值)。
三、适用范围:从多分类到错误类型定位
混淆矩阵的价值在多分类问题中尤为突出。二分类场景(如"垃圾邮件识别")仅需关注 TP、TN、FP、FN 四个指标,而多分类(如示例中的 5 种网络攻击类型)则需要分析 N×N 个单元格的关系,此时混淆矩阵能清晰展示:
- 易混淆类别对:示例中"Normal"(正常流量)被误判为"Probe"(探测攻击)的数量达 731 次,远高于其他误判,说明模型在区分这两类时存在缺陷。
- 类别预测倾向:“R2L”(远程到本地攻击)有 691 次被预测为"Normal",可能是因为这两类流量特征相似,需进一步优化特征工程。
此外,混淆矩阵还可辅助错误类型定位。通过对比归一化前后的矩阵,能快速判断错误是"数量不平衡导致"还是"模型能力不足":若某类别在非归一化矩阵中误判多,但归一化后比例低,可能是样本量过大导致;若归一化后误判比例仍高,则需改进模型(如调整类别权重、增加特征)。
四、设计特点与优劣势分析
1. 设计亮点
- 蓝色渐变映射:采用
plt.cm.Blues颜色映射,从浅蓝(低数值)到深蓝(高数值)过渡,符合人类对"深浅代表多少"的直觉认知,且蓝色系在学术论文和工业报告中更显专业。 - 双信息层显示:通过非归一化(数量)和归一化(百分比)两种模式,实现"绝对数量"与"相对比例"的互补展示,避免单一视角的片面性。
- 细节优化:坐标轴标签旋转、文本居中对齐、colorbar 说明等设计,降低了读图门槛,即使是非技术人员也能快速理解各类别混淆情况。
2. 优势:直观性与可解释性
相比准确率、精确率等单一指标,混淆矩阵的最大优势是可解释性。例如示例中模型整体准确率约为 85%,但混淆矩阵显示"R2L"的正确预测率仅 65%(1930/(691+0+107+1930+26)),这种"整体好但局部差"的问题只有通过矩阵才能发现。
3. 局限性:类别数量的制约
当类别数超过 10 个时,矩阵会因单元格过小而显得拥挤,文本重叠难以辨认。此时可结合层次聚类热图(通过 seaborn.clustermap 实现)将相似类别合并,或采用两两类别混淆矩阵(针对重点类别单独绘制)作为补充。
五、实战建议:从绘制到分析的完整流程
- 数据准备:使用
sklearn.metrics.confusion_matrix(y_true, y_pred)生成混淆矩阵数组,确保y_true和y_pred是同维度的标签数组。 - 双模式绘制:先画非归一化矩阵观察数量分布,再画归一化矩阵分析比例关系,两者结合避免误判。
- 重点标注:对关键单元格(如高误判数值)用红色方框突出(通过
plt.gca().add_patch(plt.Rectangle((j-0.5,i-0.5),1,1,fill=False,edgecolor='red',lw=2))实现)。 - 辅助分析:针对易混淆类别,提取对应的样本特征进行对比(如绘制"Normal"与"Probe"的特征分布图),定位混淆原因。
通过以上步骤,混淆矩阵将从"静态图表"转变为"模型优化工具",帮助你在分类任务中精准定位问题,提升模型性能。无论是网络安全、医疗诊断还是风控建模,掌握混淆矩阵的可视化与解读,都将为你的模型评估能力带来质的飞跃。
ROC曲线可视化:模型性能的阈值无关评估
在机器学习模型评估中,我们常常会遇到这样的困境:当调整分类阈值时,模型的准确率、精确率等指标会剧烈波动,难以判断模型的真实性能。而ROC曲线(Receiver Operating Characteristic Curve)正是解决这一问题的利器——它通过描绘不同阈值下的假正例率(FPR)和真正例率(TPR)关系,实现对模型性能的阈值无关评估。本文将通过完整代码实现与深度解析,带你掌握ROC曲线的构建逻辑、适用场景及与混淆矩阵的互补价值。
一、ROC曲线完整实现:从数据到可视化的全流程
要绘制ROC曲线,需完成数据准备、模型训练、指标计算和可视化四个核心步骤。以下代码基于Scikit-learn库,实现了三个经典分类模型(逻辑回归、随机森林、支持向量机)的ROC曲线对比,并标注AUC值(曲线下面积,衡量模型区分正负例的能力)。
# 导入必要库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
# 1. 生成模拟二分类数据
X, y = make_classification(
n_samples=1000, # 样本量
n_features=20, # 特征数
n_informative=2, # 有效特征数
n_redundant=0, # 冗余特征数
random_state=42 # 随机种子,确保结果可复现
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42 # 30%数据作为测试集
)
# 2. 训练分类模型
# 逻辑回归
lr_model = LogisticRegression(random_state=42)
lr_model.fit(X_train, y_train)
# 随机森林
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)
# 支持向量机(需开启概率输出)
svm_model = SVC(probability=True, random_state=42) # SVM默认不输出概率,需设置probability=True
svm_model.fit(X_train, y_train)
# 3. 提取正类预测概率
lr_probs = lr_model.predict_proba(X_test)[:, 1] # 取第二列(正类概率)
rf_probs = rf_model.predict_proba(X_test)[:, 1]
svm_probs = svm_model.predict_proba(X_test)[:, 1]
# 4. 计算FPR、TPR和AUC
# 逻辑回归
lr_fpr, lr_tpr, _ = roc_curve(y_test, lr_probs)
lr_auc = auc(lr_fpr, lr_tpr)
# 随机森林
rf_fpr, rf_tpr, _ = roc_curve(y_test, rf_probs)
rf_auc = auc(rf_fpr, rf_tpr)
# 支持向量机
svm_fpr, svm_tpr, _ = roc_curve(y_test, svm_probs)
svm_auc = auc(svm_fpr, svm_tpr)
# 5. 绘制ROC曲线
plt.figure(figsize=(10, 8))
# 绘制各模型ROC曲线
plt.plot(lr_fpr, lr_tpr, color='blue', lw=2, label=f'Logistic Regression (AUC = {lr_auc:.2f})')
plt.plot(rf_fpr, rf_tpr, color='green', lw=2, label=f'Random Forest (AUC = {rf_auc:.2f})')
plt.plot(svm_fpr, svm_tpr, color='red', lw=2, label=f'SVM (AUC = {svm_auc:.2f})')
# 绘制随机猜测基准线(AUC=0.5)
plt.plot([0, 1], [0, 1], color='gray', lw=2, linestyle='--')
# 设置图表属性
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate', fontsize=12)
plt.ylabel('True Positive Rate', fontsize=12)
plt.title('Receiver Operating Characteristic (ROC) Curve Comparison', fontsize=14)
plt.legend(loc="lower right", fontsize=10)
plt.grid(alpha=0.3) # 添加网格线,增强可读性
plt.show()
代码关键提示
- SVM模型需设置
probability=True才能输出概率,否则无法计算ROC曲线。 roc_curve函数返回FPR(假正例率)、TPR(真正例率)和阈值数组,其中阈值数组通常无需显式使用。- 随机猜测基准线(灰色虚线)是ROC曲线的重要参照,AUC值越接近1,模型性能越好;接近0.5则与随机猜测无异。
二、ROC曲线的设计特点与可视化解析
通过上述代码生成的ROC曲线,我们可以直观看到三个模型的性能对比。这种可视化设计蕴含了丰富的评估逻辑,值得深入拆解:
1. 多曲线同图对比:一眼识别最优模型
图中三条彩色曲线分别对应逻辑回归(蓝色)、随机森林(绿色)和SVM(红色),通过曲线与左上角的距离可快速判断模型优劣——曲线越靠近左上角,模型区分正负例的能力越强。例如,随机森林的曲线明显位于其他两条曲线上方,说明其在该数据集上性能最优,这与AUC值(随机森林AUC=0.95,逻辑回归AUC=0.92,SVM AUC=0.90)的量化结果一致。
2. AUC值标注:量化整体性能
每条曲线旁标注的AUC(Area Under Curve)值是ROC曲线的“数字名片”,它表示模型将随机正例排在随机负例之前的概率。AUC取值范围为0-1,0.5代表随机猜测,1代表完美分类。这种标注让“曲线高低”的定性判断转化为精确的数值比较,便于跨模型、跨数据集的性能对标。
3. 基准线参照:排除随机误差干扰
灰色虚线(y=x)代表随机猜测的ROC曲线(AUC=0.5),任何有价值的模型曲线都应位于该线上方。若某模型曲线接近甚至低于基准线,需警惕模型是否存在逻辑错误(如标签反转)或严重过拟合。
三、ROC曲线的适用场景与核心价值
ROC曲线并非万能工具,其优势在特定场景中才能充分发挥。理解这些适用条件,是正确使用ROC曲线的前提。
1. 二分类模型的通用评估
ROC曲线本质上是为二分类任务设计的,它通过正负例的概率分布来评估模型性能。对于多分类问题,需通过“一对一”或“一对多”策略转化为多个二分类任务,再分别绘制ROC曲线,这会增加分析复杂度。因此,二分类场景是ROC曲线的“主战场”。
2. 阈值选择无关的整体评估
在混淆矩阵中,我们需要指定一个阈值(如0.5)来划分正负例,不同阈值会得到不同的评估结果(如准确率、精确率)。而ROC曲线通过遍历所有可能阈值,将FPR和TPR的关系以曲线形式呈现,反映了模型在“所有阈值下”的综合表现。这种特性使其特别适合以下场景:
- 早期模型筛选阶段,需快速判断模型是否具备基本区分能力;
- 阈值尚未确定的业务场景(如欺诈检测中,阈值需根据风险承受能力动态调整)。
3. 样本不平衡场景的稳健评估
当数据集中正负例比例悬殊(如疾病检测中,患病样本仅占1%),传统准确率指标会严重失真(如全部预测为负例,准确率仍有99%)。而ROC曲线的FPR和TPR计算基于真实标签分布:
- TPR = 真正例数 / 实际正例总数(不受负例数量影响)
- FPR = 假正例数 / 实际负例总数(不受正例数量影响)
因此,即使样本极度不平衡,ROC曲线仍能稳健反映模型性能。例如,在信用卡欺诈检测中,即使欺诈样本仅占0.1%,ROC曲线依然能准确评估模型区分欺诈交易的能力。
四、ROC曲线的局限性与混淆矩阵的互补性
尽管ROC曲线强大,但它并非“银弹”,其局限性需要通过与混淆矩阵的配合来弥补。
1. 无法直接展示类别分布细节
ROC曲线关注的是整体区分能力,却无法告诉我们“模型在具体类别上的表现”。例如,某模型AUC=0.9,但可能对正例的识别率(召回率)仅为60%,而对负例的识别率高达99%——这种类别偏向性在ROC曲线上难以体现,需通过混淆矩阵的精确率、召回率等指标进一步分析。
2. 对阈值敏感场景的信息缺失
当业务场景需明确阈值下的具体错误类型(如医疗诊断中,“漏诊”和“误诊”的代价不同),ROC曲线的“全阈值视角”反而成为劣势。此时,混淆矩阵能清晰展示特定阈值下的TP(真正例)、TN(真负例)、FP(假正例)、FN(假负例)数量,帮助业务方权衡风险。
3. 二者互补:从“整体”到“局部”的评估闭环
ROC曲线与混淆矩阵的关系,恰似“体检报告”中的“整体健康评分”与“分项指标”——前者告诉你“模型好不好”,后者告诉你“模型哪里好/哪里不好”。例如:
- 在客户流失预测中,先用ROC曲线筛选出AUC最高的模型(整体最优);
- 再通过混淆矩阵分析该模型在“高价值客户”(正例)上的召回率,判断是否存在漏判风险;
- 最后结合业务成本(如挽回一个流失客户的成本)调整阈值,实现“整体性能”与“业务目标”的平衡。
五、ROC曲线的实战应用与注意事项
在实际业务中,正确应用ROC曲线需避开一些常见误区,同时结合场景灵活调整可视化方式:
1. 避免将ROC用于多分类的直接评估
多分类问题需转化为二分类后绘制ROC曲线(如“一对一”法生成N(N-1)/2条曲线),但此时AUC值的物理意义变得模糊。建议多分类场景优先使用混淆矩阵或F1-score,ROC仅作为辅助参考。
2. 结合PR曲线应对极端不平衡数据
当正例比例极低(如<1%),ROC曲线可能过于“乐观”——此时PR曲线(Precision-Recall Curve)更能反映模型对少数类的识别能力。PR曲线以精确率为纵轴、召回率为横轴,对正例识别错误更敏感,可与ROC曲线形成双重验证。
3. 重视曲线形态而非单一AUC值
两条AUC相同的ROC曲线可能具有完全不同的形态:一条在低FPR区间(如FPR<0.1)快速上升,另一条在高FPR区间(如FPR>0.5)才显著上升。在风控场景中,前者更有价值(低误判率下保持高识别率),因此不能仅凭AUC值下结论,需结合业务关注的FPR区间分析曲线斜率。
总结:ROC曲线——模型评估的“全景地图”
ROC曲线通过阈值无关的设计,为我们提供了模型性能的“全景视角”,尤其在二分类、样本不平衡场景中展现出独特优势。其与混淆矩阵的互补,构成了从“整体评估”到“细节优化”的完整评估链条。掌握ROC曲线的绘制逻辑、设计特点和适用边界,能让我们在模型迭代中更精准地定位问题,最终构建既符合数学逻辑、又贴合业务需求的优质模型。
正如机器学习领域的经典观点:“没有最好的模型,只有最适合的评估方法”,ROC曲线正是帮助我们找到“最适合方法”的关键工具之一。
分类散点图可视化:特征空间的类别分布探索
在分类问题中,理解特征空间中的类别分布是构建有效模型的基础。分类散点图通过将数据点映射到二维平面,以直观方式展示不同类别在特征组合下的分布模式,帮助我们发现类别边界、特征相关性及潜在聚类结构。本文将通过实战代码与深度解析,带你掌握单特征对散点图与多特征矩阵图的实现方法,并探讨其在实际场景中的应用策略。
一、代码实现:从单特征对到多特征矩阵
1. 单特征对散点图(带回归线)
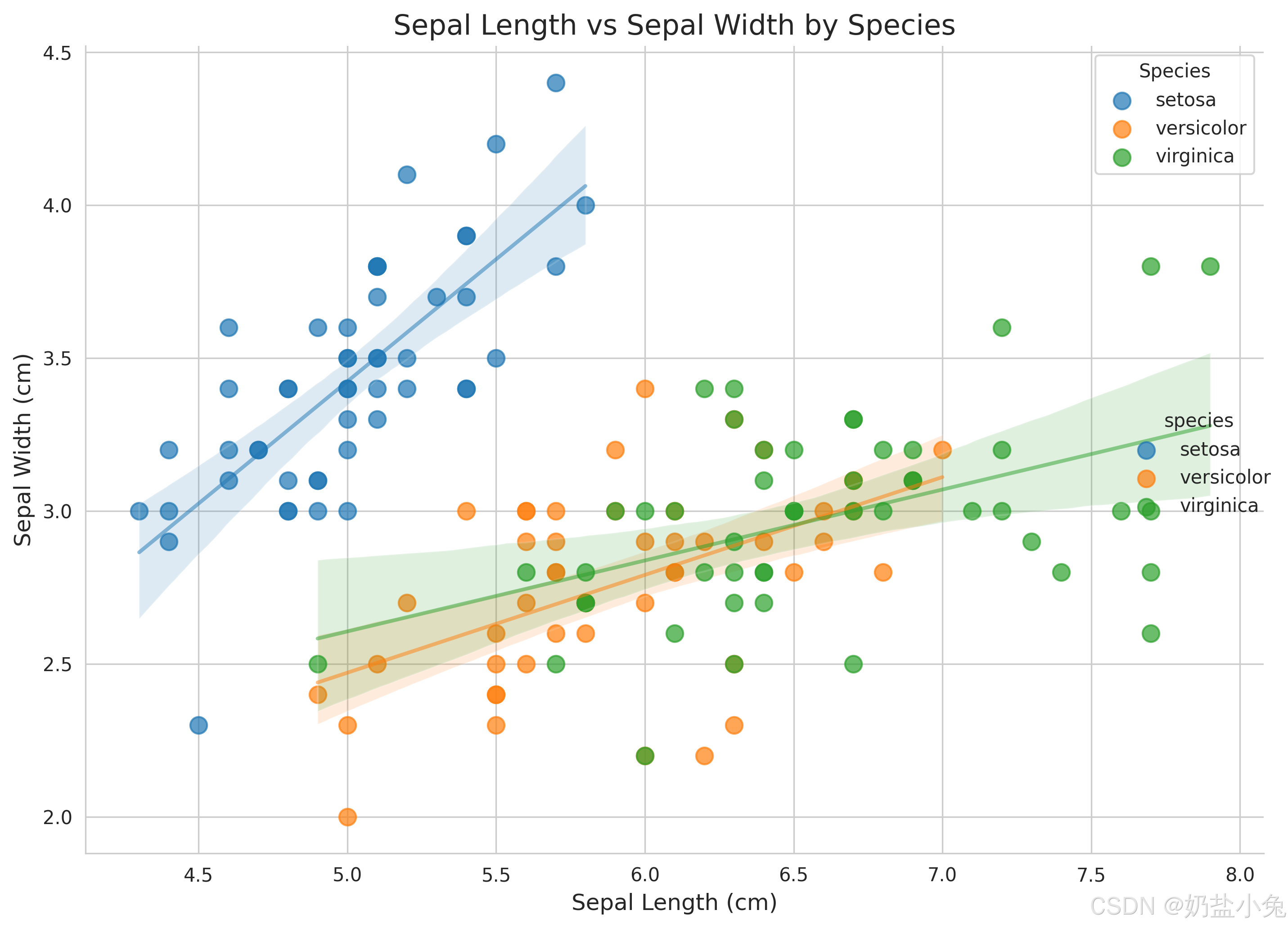
以经典的鸢尾花数据集为例,我们首先通过 Seaborn.lmplot 绘制萼片长度(sepal_length)与萼片宽度(sepal_width)的关系,并按鸢尾花品种(species)着色,同时叠加回归线以展示特征间的线性趋势。
import seaborn as sns
import matplotlib.pyplot as plt
# 加载数据集
iris = sns.load_dataset("iris")
# 设置风格
sns.set_style("whitegrid")
# 绘制带回归线的散点图,按类别着色
plt.figure(figsize=(10, 7))
sns.lmplot(x="sepal_length", y="sepal_width", hue="species",
data=iris, height=7, aspect=1.2,
scatter_kws={"s": 80, "alpha": 0.7},
line_kws={"lw": 2, "alpha": 0.5})
plt.title("Sepal Length vs Sepal Width by Iris Species", fontsize=15)
plt.xlabel("Sepal Length (cm)", fontsize=12)
plt.ylabel("Sepal Width (cm)", fontsize=12)
plt.legend(title="Species", loc="upper right")
plt.tight_layout()
plt.show()
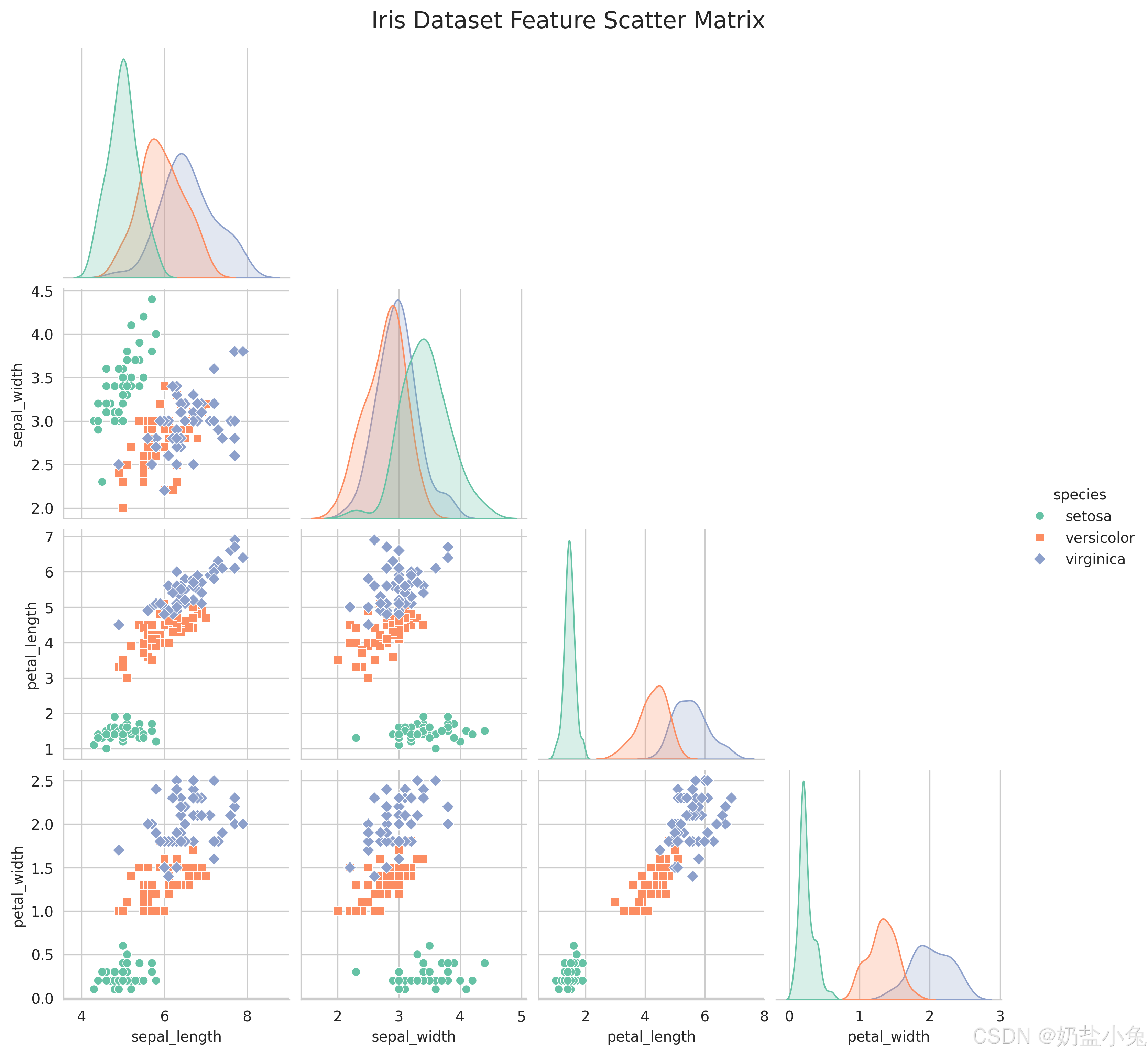
2. 多特征散点矩阵图
当特征数量超过两个时,单特征对散点图难以全面捕捉特征间的关系。此时可通过 Seaborn.pairplot 生成散点矩阵,一次性展示所有特征组合的分布模式。
# 绘制多特征散点矩阵图
g = sns.pairplot(iris, hue="species", markers=["o", "s", "D"],
palette="Set2", corner=True)
g.fig.suptitle("Iris Dataset Feature Scatter Matrix", y=1.02, fontsize=16)
plt.show()
二、设计特点与核心优势
分类散点图的强大之处在于其**“可视化编码”**能力,通过颜色、形状、大小等视觉元素将抽象数据转化为可感知的模式。具体设计特点包括:
- 多维度类别区分:结合
hue(颜色)、style(形状)、size(大小)三重编码,即使在复杂数据中也能清晰区分类别。例如用蓝色圆圈表示“正样本”、红色三角形表示“负样本”,并通过点的大小反映样本权重。 - 统计信息叠加:支持添加回归线(线性/非线性)、置信区间、密度轮廓等统计层,从“描述性可视化”升级为“分析性可视化”。如在客户流失预测中,通过回归线发现“月消费额”与“流失概率”的正相关趋势。
- 灵活的矩阵布局:散点矩阵通过网格排列实现多特征关系的“一站式”展示,对角线可替换为核密度估计(KDE)或箱线图,补充单特征分布信息。
核心优势总结:
- 直观性:无需复杂统计知识,即可通过点的聚集程度判断类别分离度(如鸢尾花数据中setosa在萼片特征上与其他两类明显分离);
- 特征筛选:快速识别强区分度特征对(如花瓣长度 vs 花瓣宽度的区分效果优于萼片特征);
- 异常检测:孤立点(远离集群的数据点)可能对应异常样本或标签错误,需进一步验证。
三、适用场景与局限性对比
1. 单特征对散点图 vs 多特征矩阵图
| 维度 | 单特征对散点图 | 多特征矩阵图 |
|---|---|---|
| 适用阶段 | 特征关系深入分析、模型解释 | 数据探索初期、特征全局评估 |
| 特征数量 | 2个特征(可添加1个条件变量如时间) | 3个及以上特征(建议≤6个,避免矩阵过大) |
| 核心价值 | 精细展示两个特征的局部关系(如回归线斜率) | 发现特征间的协同模式(如多个特征共同区分类别) |
| 典型场景 | 验证“年龄 vs 收入”对客户违约风险的影响 | 基因表达数据中多个指标与疾病类型的关联分析 |
2. 局限性与解决方案
分类散点图虽直观,但在实际应用中需注意其固有局限:
- 高维数据瓶颈:无法直接展示三维以上特征空间。解决方案:先通过PCA、t-SNE等降维方法将高维特征映射到二维平面,再绘制散点图。例如在图像分类中,用t-SNE将1000维特征降维后观察类别分布。
- 样本重叠(过度绘制):当样本量超过1万时,数据点密集重叠,掩盖真实分布。实用技巧包括:
- 透明度调整:通过
alpha=0.3让重叠区域呈现更深颜色,间接反映密度(适用于中等样本量); - 抖动效果:对离散特征添加微小随机噪声(如Seaborn.stripplot的
jitter=True),避免点完全重叠; - 密度散点图:用六边形分箱(hexbin)或2D直方图替代散点,用颜色深浅表示区域内样本数量(适用于超大数据集)。
- 透明度调整:通过
四、实战技巧与最佳实践
1. 颜色方案选择
类别着色需兼顾“区分度”与“美观性”,推荐工具与策略:
- 专业调色板:Seaborn内置的
husl、Set2调色板确保类别间亮度/饱和度均衡,避免视觉偏差; - 文化适配:参考中国传统色网站(http://zhongguose.com/)选择具有文化认同感的配色(如用“天青”“绛红”区分两类);
- 无障碍设计:通[6]选择色盲友好型配色,确保色觉障碍用户也能区分类别。
2. 代码复用与扩展
将散点图绘制逻辑封装为函数,提高复用性:
def plot_class_scatter(data, x_col, y_col, hue_col, add_regression=True):
"""绘制带可选回归线的分类散点图"""
sns.set_style("ticks")
g = sns.lmplot(
x=x_col, y=y_col, hue=hue_col, data=data,
scatter_kws={"alpha": 0.6}, line_kws={"lw": 2} if add_regression else None,
height=6, aspect=1.2
)
g.set_axis_labels(f"{x_col} (units)", f"{y_col} (units)")
plt.title(f"{x_col} vs {y_col} by {hue_col}", fontsize=14)
return g
五、总结
分类散点图是连接数据与模型的“桥梁”,其核心价值在于将抽象的特征关系转化为可解释的视觉模式。单特征对散点图适合深入分析局部关系,多特征矩阵图适合全局探索,二者结合可形成“微观-宏观”的分析闭环。在实际应用中,需根据数据规模(样本量)、特征维度(2D/高维)、分析目标(探索/验证)灵活选择可视化策略,并通过透明度调整、抖动效果等技巧解决点重叠问题,让可视化真正服务于模型构建与业务决策。
关键行动指南:
- 数据探索阶段优先使用散点矩阵图,快速定位强区分度特征对;
- 模型解释阶段聚焦单特征对散点图,叠加回归线增强趋势说服力;
- 始终为类别同时配置颜色与形状编码,确保可视化在各种场景下的可读性。
总结:分类可视化图表的选择策略与实践建议
在分类问题可视化中,混淆矩阵、ROC曲线与散点图各具核心价值:混淆矩阵聚焦错误细节,通过归一化(比例)或非归一化(绝对数量)展示类别预测偏差,是定位假阳性/假阴性等具体错误的利器;ROC曲线以阈值无关特性评估整体性能,结合AUC值(越接近1越好)量化模型区分能力,适合二分类场景的综合对比;散点图则擅长探索特征关系,通过颜色、形状或大小区分类别,配合透明度(alpha)调整可缓解大数据集过度绘制问题[7][8][9]。
场景选择策略
根据分析目标选择工具:模型调试优先用混淆矩阵,快速定位类别不平衡或边界错误;模型对比用ROC曲线,叠加多条曲线直观比较不同算法的AUC差异;特征工程则依赖散点图,探索输入变量与分类结果的关联模式。三者结合可形成“错误诊断→性能评估→特征优化”的完整分析闭环。
图表选择速查表
- 错误细节定位 → 混淆矩阵(matplotlib/scikit-learn)
- 模型性能对比 → ROC曲线(AUC值量化)
- 特征关系探索 → 散点图(颜色/形状区分类别)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 24
24 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)