关系型数据库和非关系型数据的区别和联系
没有最好的数据库,只有最合适的数据库。关系型数据库是精密的瑞士军刀,可靠而精准;非关系型数据库是各种专业工具,各有所长,威力巨大。现代企业的正确做法是:理解业务需求 -> 选择合适的数据存储方案 -> 在需要时,大胆地混合使用它们,让专业的工具做专业的事。
一、关系型数据库
核心概念: 建立在关系模型基础上的数据库。它使用表(Table) 来存储数据,表由行(Row) 和列(Column) 组成。不同表之间通过主键(Primary Key) 和外键(Foreign Key) 建立关联。
核心特性(ACID):
A - 原子性: 事务内的所有操作要么全部完成,要么全部不完成,不存在中间状态。
C - 一致性: 事务必须使数据库从一个一致性状态变换到另一个一致性状态。
I - 隔离性: 并发执行的事务之间不会相互干扰。
D - 持久性: 事务完成后,对数据的修改是永久性的,即使系统故障也不会丢失。
代表产品:
MySQL, PostgreSQL, Oracle Database, Microsoft SQL Server, DB2
优势:
-
结构化数据: 适合存储格式固定、结构严谨的数据。
-
强大的SQL支持: 使用标准化的SQL语言进行复杂查询(如多表关联、聚合、子查询等),功能强大且灵活。
-
数据一致性和完整性: 严格的ACID特性保证了交易数据(如银行转账、订单支付)的绝对可靠。
-
成熟的生态系统: 拥有多年的技术积累,工具、社区和支持都非常完善。
劣势:
-
扩展性限制: 垂直扩展(升级服务器硬件)成本高,水平扩展(分库分表)复杂且对应用侵入性强。
-
** schema 不灵活:** 数据结构需要预先定义(schema-on-write),后期修改表结构比较麻烦,不适合快速迭代的业务。
-
高并发下的性能瓶颈: 在面对海量数据和高并发读写(如社交媒体的点赞、评论)时,性能可能成为瓶颈。
-
不适合非结构化数据: 难以高效存储和处理文档、图片、视频等非结构化数据
二、非关系型数据库
核心概念: 为了克服关系型数据库的不足而设计。它没有固定的表结构,通常不遵循ACID原则,而是在数据模型、扩展性和性能上做了优化。
优势:
-
灵活的数据模型: 支持动态schema(schema-on-read),可以轻松适应数据结构的变化。
-
极高的扩展性: 天生为水平扩展(增加节点)设计,能够轻松应对海量数据和高并发。
-
高性能: 针对特定的数据模型和访问模式进行了高度优化,读写速度极快。
-
高可用性: 很多NoSQL数据库内置了分布式和复制机制,保障服务不中断。
劣势:
-
弱化的事务一致性: 大多数遵循BASE理论(基本可用、软状态、最终一致性),无法提供像关系型数据库那样的强一致性保证。
-
查询功能相对单一: 缺乏像SQL那样统一、强大的查询语言,复杂查询(特别是多表关联)实现困难。
-
学习成本: 不同类型的NoSQL数据库需要学习不同的数据模型和API。
-
成熟度: 相比关系型数据库,部分NoSQL产品在生态系统和工具支持上稍显年轻。
三、如何选择:什么场景使用什么?
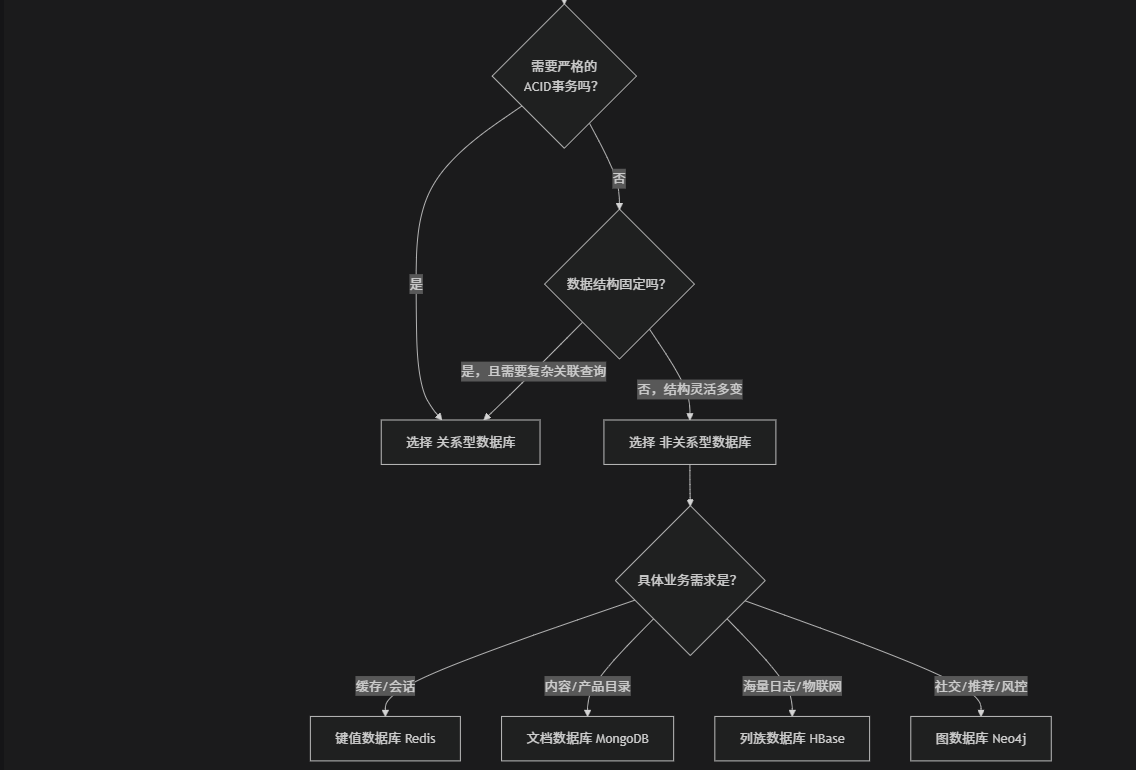
简单总结:
用关系型数据库当你的核心业务需要“铁一般的纪律”:金融交易、会计系统、核心订单系统等。
用非关系型数据库当你的业务需要“海纳百川的规模和弹性”:用户画像、社交APP、物联网数据平台、实时推荐等。
四、如何结合使用:混合持久化
在现代微服务架构中,一个企业系统通常会同时使用多种数据库,让每种数据库做自己最擅长的事,这被称为 “混合持久化”。
一个经典的电商平台例子:
-
核心业务数据(关系型数据库 - MySQL/PostgreSQL)
-
用途: 存储用户账户、商品信息、订单、支付记录。
-
原因: 这些数据关系复杂,需要严格的ACID事务来确保“下单减库存”、“支付更新状态”等操作的绝对准确。
-
-
会话和缓存(键值数据库 - Redis)
-
用途: 存储用户的登录会话(Session)、热门商品信息、首页页面缓存。
-
原因: 读写性能要求极高,数据可以丢失(会话可重建),Redis的内存特性完美契合。
-
-
商品评论和用户动态(文档数据库 - MongoDB)
-
用途: 存储用户发布的商品评论、晒图、问答。
-
原因: 这些内容结构多变,不同商品的评论字段可能不同,文档模型的灵活性非常适合。
-
-
用户行为日志(列族数据库 - HBase)
-
用途: 记录用户的点击、浏览、搜索历史。
-
原因: 数据量巨大(每天TB级),写多读少,后期用于大数据分析(如用户行为分析、个性化推荐)。
-
-
社交关系和推荐(图数据库 - Neo4j)
-
用途: 存储“好友关系”、“购买此商品的人还买了...”、“关注了该品牌的用户”。
-
原因: 这些是典型的图关系数据,使用图数据库可以高效地进行多度关系查询和路径分析。
-
结合使用的关键点:
-
服务解耦: 每个微服务可以选择最适合自己数据需求的数据库类型。
-
数据同步: 需要通过ETL工具(如DataX)、CDC工具(如Debezium)或消息队列(如Kafka)在不同数据库间同步数据,例如将MySQL中的订单数据同步到HBase中做分析。
-
最终一致性: 在跨数据库的场景下,强一致性很难保证,系统需要接受最终一致性。
总结
没有最好的数据库,只有最合适的数据库。关系型数据库是精密的瑞士军刀,可靠而精准;非关系型数据库是各种专业工具,各有所长,威力巨大。
现代企业的正确做法是:
理解业务需求 -> 选择合适的数据存储方案 -> 在需要时,大胆地混合使用它们,让专业的工具做专业的事。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)