K8S(一)—— 云原生与Kubernetes(K8S)从入门到实践:基础概念与操作全解析
本文系统介绍了云原生技术及Kubernetes的核心知识。首先梳理了云原生发展历程,从2004年Google内部使用容器技术到2015年CNCF成立,形成完整技术生态。其次对比了公有云、私有云和混合云三种部署模式的特点及适用场景,并解析了云原生技术栈的组成要素,包括容器化、微服务、服务网格等关键技术。文章重点阐述了Kubernetes作为容器编排平台的核心价值,包括其起源、版本演进以及与Docke
前言
随着云计算技术的飞速发展,云原生已成为企业构建弹性、可扩展、高可用应用的核心技术方向。而Kubernetes(简称K8S)作为容器编排领域的事实标准,更是云原生技术栈的“基石”——它解决了传统部署方式中应用扩展难、运维成本高、容错能力弱等痛点,让开发者能更聚焦于业务逻辑,而非底层基础设施管理。
本文将从云原生基础切入,逐步深入K8S的核心概念、集群架构、操作管理与项目生命周期,覆盖从理论到实操的关键环节。无论你是刚接触云原生的开发者,还是需要系统梳理K8S知识的运维工程师,都能通过本文快速建立完整的知识体系,为后续实践打下基础。
一、云原生基础概述
1.1 云原生的发展历程
云原生技术的演进并非一蹴而就,而是伴随容器化、开源生态的发展逐步成熟,其关键时间节点如下:
| 时间 | 关键事件 | 影响意义 |
|---|---|---|
| 2004年 | Google内部大规模使用容器技术 | 为容器化技术的规模化应用积累了实践经验 |
| 2008年 | Google将Cgroups技术合并进Linux内核 | 解决了容器资源隔离的核心问题,为后续容器引擎(如Docker)奠定底层基础 |
| 2013年 | Docker项目正式发布 | 推动容器技术从企业内部走向开源领域,降低了容器化的使用门槛 |
| 2014年 | Kubernetes项目正式发布 | 填补了容器编排的空白,逐步成为行业标准 |
| 2015年 | Google、RedHat、微软等联合发起成立CNCF(云原生计算基金会) | 构建云原生开源生态,推动技术标准化与产业化 |
| 2017-2018年 | CNCF成员从170个增长至195个,基金项目从14个增至19个 | 云原生生态进入快速扩张期,技术覆盖场景从容器编排延伸至服务网格、Serverless等 |
1.2 云原生的定义与部署模式
云原生技术的核心目标是:帮助企业在公有云、私有云、混合云等动态环境中,构建和运行可弹性扩展的应用。要理解这一目标,需先明确三种主流云部署模式的差异:
1.2.1 公有云
公有云是由云服务提供商(如AWS、微软Azure、谷歌云、阿里云)在互联网上公开提供的云计算服务。其核心特点是“资源共享、按需付费”——用户无需购买或管理底层基础设施(服务器、存储、网络),只需根据业务需求弹性申请资源,按使用量付费。
适用场景:中小企业低成本启动业务、突发流量场景(如电商大促)、非敏感业务部署。
1.2.2 私有云
私有云是企业在自有数据中心内搭建的专属云计算平台,完全由企业自主拥有和控制。其核心优势是“高安全性、高定制性”——可根据企业合规要求(如金融、医疗行业的隐私法规)定制环境,避免敏感数据暴露于外部网络。
适用场景:企业核心业务(如交易系统)、敏感数据存储(如用户隐私数据)、对合规性要求极高的场景。
1.2.3 混合云
混合云是将公有云、私有云、本地IT基础设施有机结合的集成环境。它兼顾了公有云的“弹性与低成本”和私有云的“安全与可控性”——企业可将敏感数据存储在私有云,将非敏感工作负载(如日志分析、测试环境)部署在公有云,实现资源最优配置。
典型案例:某电商平台将用户支付数据存于私有云,将商品展示、营销活动等非敏感服务部署在公有云,大促期间通过公有云弹性扩容应对流量峰值。
1.3 云原生技术栈
云原生技术栈是一个“组合拳”,涵盖容器化、微服务、服务网格等多个核心组件,共同支撑云原生应用的高效运行。
1.3.1 核心技术组件
- 容器化:以Docker、containerd为代表,实现应用的“一次打包,到处运行”——通过轻量级封装(比虚拟机更节省资源)保证开发、测试、生产环境的一致性,解决“开发环境能跑,生产环境报错”的痛点。
- 服务网格(Service Mesh):以Istio为代表,负责管理服务间的通信——包括流量控制(如灰度发布)、安全加密(如mTLS)、监控追踪(如链路追踪),无需修改业务代码即可实现服务治理。
- 微服务架构:将传统单体应用拆分为多个独立的“小服务”,每个服务聚焦单一业务功能(如用户服务、订单服务)。服务间通过RESTful API通信,支持独立部署、更新、扩缩容,降低代码耦合度。
- 不可变基础设施:服务部署后不再直接修改(如不在容器内手动安装软件),而是通过“版本化镜像”更新——每次变更生成新的镜像,确保环境一致性,简化回滚操作。
- 声明式API:用户只需定义“期望的资源状态”(如“我需要3个Nginx副本”),K8S等系统会自动将实际状态调整为期望状态,无需手动执行步骤(如“先启动1个副本,再关闭旧副本”)。
1.3.2 云原生技术栈公式
云原生并非单一技术,而是多技术的协同组合,可简化为以下公式:
云原生 = 容器化(Docker+K8S) + 微服务(Microservices) + 无服务(Serverless) + DevOps + 服务网格(Service Mesh) + 云(Cloud)
各组件的核心定位:
- 容器化(Docker+K8S):微服务的“最佳载体”,解决微服务的部署与编排问题;
- 微服务:业务拆分的“方法论”,支持独立迭代与扩展;
- Serverless:“去基础设施化”,开发者无需关注服务器,只需编写业务逻辑(如AWS Lambda);
- DevOps:“开发+运维协同”,通过持续集成(CI)、持续交付(CD)实现快速迭代;
- 服务网格(Service Mesh):“服务通信管家”,解决微服务间的治理问题;
- 云:云原生的“基础底座”,提供弹性计算、存储等资源。
1.4 云原生的核心特征
云原生系统需具备以下特征,以适应动态、复杂的云环境:
1.4.1 核心特征
- 符合12因素应用:遵循12项开发原则,确保应用可扩展、无状态、易维护;
- 面向微服务架构:应用拆分为松耦合的服务,支持独立部署与扩缩容;
- 自服务敏捷架构:开发者可自主申请、管理云资源(如通过平台一键创建K8S Pod),减少对运维的依赖;
- 基于API的协作:服务间通过标准化API通信,降低跨团队协作成本;
- 抗脆弱性:系统具备“自愈能力”——如K8S会自动重启故障容器、迁移节点离线的Pod,而非仅“抵抗故障”。
1.4.2 12因素应用原则(详解)
12因素应用是云原生应用的“设计指南”,具体原则如下:
- 基准代码:同一应用使用单一代码库(如Git仓库)管理,支持多次部署(开发、测试、生产环境共用代码);
- 依赖管理:显式声明依赖(如Java的pom.xml、Python的requirements.txt),避免依赖“隐式存在于环境中”;
- 配置管理:配置项(如数据库地址、API密钥)存储在环境变量或配置中心,而非硬编码到代码中;
- 后端服务:将外部服务(如数据库、缓存)视为“附加资源”,通过配置动态关联,支持更换服务实例(如从MySQL切换到PostgreSQL);
- 构建、发布、运行分离:清晰区分三个阶段——“构建”生成镜像,“发布”将镜像与配置结合,“运行”启动容器,避免运行时修改构建产物;
- 无状态进程:应用进程不存储状态(如会话数据),状态需存储在外部服务(如Redis),支持水平扩展(多实例共享状态);
- 端口绑定:应用通过端口暴露服务(如Nginx监听80端口),无需依赖外部进程(如Apache反向代理);
- 并发处理:通过多进程/多线程模型扩展并发能力,而非依赖单机硬件升级;
- 快速启动与优雅终止:应用启动时间短(支持快速扩容),终止时能处理完剩余请求(如关闭前保存数据);
- 开发环境与生产环境一致:尽量消除开发、测试、生产环境的差异(如使用Docker镜像保证环境一致);
- 日志管理:日志以“标准输出”形式打印,由外部系统(如ELK)统一收集、分析,支持问题追溯;
- 管理进程:管理任务(如数据备份、数据库迁移)与业务进程使用相同环境,避免“手动执行脚本导致环境不一致”。
二、Kubernetes(K8S)核心认知
2.1 什么是Kubernetes(K8S)?
2.1.1 基本定义与起源
Kubernetes(简称K8S,因“K”与“S”之间有8个字母)是一个开源的容器编排平台,核心功能是自动化部署、扩展和管理容器化应用。它可看作一个“容器集群的操作系统”——负责容器的调度、资源分配、故障恢复、服务发现等运维工作。
K8S的起源与Google密切相关:它受Google内部的Borg系统(用于管理海量容器)启发,2014年由Google开源,后捐赠给CNCF(云原生计算基金会),成为CNCF的首个毕业项目。K8S使用Go语言开发,具备高可用、可扩展、跨平台等特性。
原来最早使用的编排工具:messos 分布式框架 + marathon (马拉松),2019年弃用
2.1.2 版本节奏与官网
- 版本节奏:K8S每年发布约4个版本(如1.24、1.28、1.30),每个版本包含功能增强、bug修复,同时会标注“废弃功能”(如1.24移除dockershim);
- 官方文档:
- 英文官网:https://kubernetes.io
- 中文文档:https://kubernetes.io/zh-cn/docs(适合中文用户快速查阅)。
2.1.3 K8S与Docker的支持变动
K8S早期依赖Docker作为容器运行时,但随着容器标准(OCI)的成熟,K8S逐步推动“去Docker依赖”,关键时间线如下:
- 2016年12月:K8S发布CRI(Container Runtime Interface,容器运行时接口),支持对接多种运行时(如containerd、CRI-O);
- 2020年12月:K8S宣布废弃dockershim(连接Docker与K8S的适配层),鼓励使用CRI兼容运行时;
- 2022年5月(关键变动):K8S v1.24正式移除dockershim,节点必须使用CRI兼容运行时(如containerd、CRI-O);
- 注意:Docker镜像仍可在K8S中使用(因镜像符合OCI标准),只是Docker引擎不再作为K8S的运行时。
2.2 为什么要用K8S?
K8S的设计初衷是解决传统部署方式(如虚拟机部署、手动管理容器)的痛点,其核心价值体现在以下方面:
2.2.1 解决传统部署痛点
传统部署方式存在“扩展难(手动扩容)、运维重(手动重启故障应用)、容错弱(单点故障导致服务中断)”等问题,而K8S通过自动化、自愈能力等特性,彻底改变了这一现状。
2.2.2 K8S核心优势
- 自动化运维:支持“一条命令完成部署/更新/扩缩容”——例如
kubectl scale deployment nginx --replicas=5可快速将Nginx副本扩至5个,无需手动操作每个容器; - 弹性伸缩:基于指标(CPU、内存、自定义指标如“请求量”)自动调整Pod副本数——例如CPU使用率超过80%时自动扩容,低于20%时自动缩容,避免资源浪费;
- 容灾与自愈:具备“故障自动恢复”能力——若某个节点离线,K8S会将该节点上的Pod迁移到其他健康节点;若容器崩溃,K8S会自动重启容器,确保副本数符合期望;
- 服务发现与负载均衡:通过Service资源为Pod提供“稳定访问入口”——即使PodIP动态变化(如重启后IP改变),外部仍可通过Service的ClusterIP或NodePort访问服务,且Service会自动将请求负载均衡到多个Pod;
- 滚动升级与回滚:支持“渐进式更新”——例如更新Nginx版本时,K8S会先启动1个新副本,确认正常后再关闭1个旧副本,依次类推,避免服务中断;若更新出错,可一键回滚到上一版本(
kubectl rollout undo deployment nginx); - 集中配置与密钥管理:通过ConfigMap存储非敏感配置(如数据库地址),通过Secret存储敏感数据(如API密钥、证书)——配置修改后无需重新构建镜像,只需更新ConfigMap/Secret,且Secret会自动加密存储;
- 存储编排:支持对接多种外部存储(NFS、Ceph、云存储如AWS EBS),通过PV(Persistent Volume,持久化卷)和PVC(Persistent Volume Claim,持久化卷声明)实现“存储资源的申请与使用分离”——开发者只需申请PVC,无需关注存储底层细节;
- 批处理与定时任务:支持Job(一次性任务,如数据备份)和CronJob(定时任务,如每天凌晨2点执行日志清理),无需手动编写定时脚本。
三、K8S集群架构与核心组件
K8S采用控制平面(Master)+ 工作节点(Node)的主从架构,两者协同工作,共同管理容器集群。
3.1 架构概述
- 控制平面(Master/Control Plane):集群的“大脑”,负责集群的调度、管理与决策——如接收用户请求(如“部署3个Nginx Pod”)、选择合适的Node节点运行Pod、监控集群状态是否符合期望;
- 工作节点(Node/Worker):集群的“手脚”,负责运行实际的容器化应用——接收控制平面下发的任务,启动/停止容器,汇报节点与Pod状态;
- 通信逻辑:所有资源操作请求(如创建Pod、删除Service)均通过控制平面的API Server接收,控制平面处理后将任务下发给Node节点,Node节点通过kubelet执行任务并反馈状态。
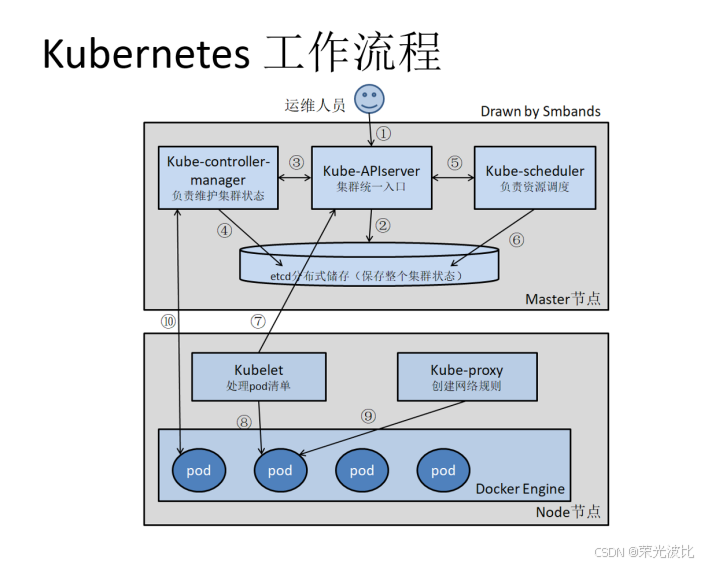
3.2 控制平面(Master / Control Plane)组件
控制平面由4个核心组件组成,每个组件各司其职,共同确保集群正常运行:
| 组件 | 核心职责 |
|---|---|
| kube-apiserver | 集群的“统一API入口”(以restful方式)——接收所有资源操作请求(增删改查、Watch),并校验请求合法性;所有组件(如kube-scheduler、kubelet)均通过API Server交互; |
| kube-controller-manager | 运行“控制器集合”——如Node控制器(监控节点状态,节点离线时标记为不可调度)、ReplicaSet控制器(确保Pod副本数符合期望)、Service控制器(维护Service与Pod的关联);每个控制器负责“纠偏”——将实际状态调整为期望状态; |
| kube-scheduler | 集群的“调度器”——为待调度的Pod选择合适的Node节点;调度逻辑基于“预选策略”(如Node是否有足够CPU/内存)和“优选策略”(如选择负载最低的Node); |
| etcd | 集群的“分布式键值存储”——持久化保存所有K8S资源的状态数据(如Pod配置、Service规则);控制平面组件通过etcd读取/写入数据,etcd是集群的“唯一数据来源”; |
高可用建议:生产环境中,控制平面组件需部署多实例(如3个API Server、3个etcd节点),避免单点故障——例如etcd采用3节点集群,确保数据冗余;API Server通过负载均衡器(如Nginx)暴露入口。
3.3 工作节点(Node / Worker)组件
工作节点是运行容器的“载体”,核心组件如下:
| 组件 | 核心职责 |
|---|---|
| kubelet | 节点的“代理程序”——运行在每个Node节点上,接收API Server下发的Pod任务;监控Pod状态(如容器是否存活),执行容器启动/停止操作;定期向控制平面汇报节点与Pod状态; |
| kube-proxy | 节点的“网络代理”——实现Service的网络规则与负载转发;通过iptables、ipvs等技术,将外部请求(如NodePort端口的请求)转发到后端Pod;确保Service的负载均衡与服务发现功能; |
| Container Runtime | 容器的“运行时”——负责容器镜像拉取、容器启动/停止、资源隔离等底层操作;K8S ≥ 1.24时必须使用CRI兼容运行时,主流选择为containerd(轻量、稳定)、CRI-O; |
示例:当用户创建一个Nginx Pod时,kube-apiserver接收请求并存储到etcd,kube-scheduler选择一个Node节点,kubelet(该Node上)通过Container Runtime拉取Nginx镜像并启动容器,kube-proxy配置网络规则,确保外部能访问该Pod。
3.4 Docker / dockershim 与containerd的过渡说明
随着K8S 1.24 移除dockershim,容器运行时的选择需注意以下要点:
- Docker引擎的角色变化:Docker引擎不再作为K8S的运行时(因不支持CRI),但Docker构建的镜像仍可在K8S中使用(镜像符合OCI标准);
- containerd的优势:containerd是Docker引擎的“核心组件”(负责镜像管理与容器运行),单独剥离后更轻量、性能更好,且原生支持CRI,是当前K8S的主流运行时;
- 版本兼容性:若使用K8S 1.28及以上版本,默认推荐使用containerd或CRI-O,无需再依赖Docker引擎。
四、K8S核心概念与资源对象
K8S通过资源对象描述集群中的各种实体(如Pod、Service、Deployment),掌握这些核心概念是使用K8S的基础。
| 概念/资源 | 含义与用途 |
|---|---|
| Pod | K8S中最小的可调度单位——包含1个或多个容器(如1个Nginx容器+1个Sidecar容器);容器共享网络(同一Pod内容器使用相同IP)、存储(如EmptyDir卷);Pod无法单独扩缩容,需依赖控制器(如Deployment)管理; |
| 控制器(Controller) | 用于“管理Pod的生命周期”——确保Pod按期望状态运行(如副本数、自愈、升级);常见控制器: - Deployment:管理无状态应用(如Web服务),支持滚动更新、回滚; - ReplicaSet:维持Pod副本数(Deployment底层依赖ReplicaSet); - StatefulSet:管理有状态应用(如数据库),确保Pod名称、IP、存储稳定; - DaemonSet:在每个Node节点上运行1个Pod(如日志收集组件、监控代理); - Job/CronJob:Job用于一次性任务(如数据导入),CronJob用于定时任务(如定时备份); |
| Service | 为一组Pod提供稳定的访问入口——PodIP动态变化(如重启后IP改变),Service通过“标签选择器”关联Pod,提供固定的ClusterIP(集群内部访问)或NodePort(外部访问);同时实现负载均衡(将请求分发到多个Pod); |
| Ingress | 在HTTP/HTTPS层面管理外部访问路由——Service的NodePort端口范围固定(30000-32767),且无法直接处理域名、SSL证书;Ingress可通过域名(如www.example.com)将外部流量路由到不同Service,支持SSL终结、路径匹配(如/api路由到API服务); |
| Label/Annotation/Selector | - Label:资源的“键值对标签”(如app=nginx、env=prod),用于标识、分组资源;- Annotation:用于存储“非标识性元数据”(如资源描述、构建信息),不用于资源选择; - Selector:基于Label筛选资源(如Service通过 app=nginx选择Pod); |
| Namespace(命名空间) | 将K8S集群逻辑上划分为多个隔离空间——如“dev”(开发环境)、“test”(测试环境)、“prod”(生产环境);不同Namespace的资源名称可重复,实现资源隔离与权限控制(如限制开发人员仅访问dev Namespace); |
| 资源定义结构 | K8S资源通常以YAML/JSON格式定义,核心字段包括: - apiVersion:资源的API版本(如 apps/v1对应Deployment);- kind:资源类型(如 Deployment、Service);- metadata:资源元数据(如名称、Namespace、Label); - spec:资源的“期望状态”(如Deployment的副本数、Pod模板); - status:资源的“实际状态”(由K8S自动维护,不可手动修改); |
五、K8S核心能力与特性
K8S的核心能力围绕“自动化、高可用、可扩展”设计,覆盖应用全生命周期管理:
-
自动伸缩:
- 水平伸缩(HPA,Horizontal Pod Autoscaler):基于CPU、内存或自定义指标(如请求量)自动调整Pod副本数;
- 垂直伸缩(VPA,Vertical Pod Autoscaler):自动调整Pod的CPU/内存配额(如从1核2G调整为2核4G),适合无法水平扩展的应用(如单机数据库);
-
服务发现与负载均衡:
- 服务发现:通过Service的ClusterIP或域名(如
nginx-service.default.svc.cluster.local)实现Pod的动态发现,无需手动配置IP; - 负载均衡:Service将请求均匀分发到多个Pod,支持会话亲和性(如
sessionAffinity: ClientIP,确保同一客户端请求路由到同一Pod);
- 服务发现:通过Service的ClusterIP或域名(如
-
滚动更新与回滚:
- 滚动更新:Deployment默认采用滚动更新策略,通过控制“最大不可用Pod数”(
maxUnavailable)和“最大额外Pod数”(maxSurge)确保服务不中断; - 回滚:支持查看历史版本(
kubectl rollout history deployment nginx),一键回滚到指定版本(kubectl rollout undo deployment nginx --to-revision=1);
- 滚动更新:Deployment默认采用滚动更新策略,通过控制“最大不可用Pod数”(
-
容错与自愈:
- 节点自愈:Node节点离线时,K8S将该节点上的Pod迁移到其他健康节点;
- Pod自愈:通过“存活探针(livenessProbe)”检测容器是否正常运行,若探针失败,K8S自动重启容器;
- 就绪探针(readinessProbe):确保Pod就绪后才接收请求(如等待数据库连接成功后再对外提供服务);
-
集中配置与密钥管理:
- ConfigMap:存储非敏感配置,支持环境变量注入(如
envFrom: configMapRef: name: nginx-config)或挂载为文件(如volumeMounts: - name: config-volume mountPath: /etc/nginx/conf.d); - Secret:存储敏感数据(如密码、证书),数据会base64编码存储(生产环境需启用加密插件,如etcd加密),支持与ConfigMap类似的注入方式;
- ConfigMap:存储非敏感配置,支持环境变量注入(如
-
存储编排与持久化存储:
- PV(Persistent Volume):集群级别的持久化存储资源,由管理员创建(如“创建100G的NFS PV”);
- PVC(Persistent Volume Claim):开发者向集群申请存储资源(如“申请50G存储”),K8S自动匹配符合条件的PV;
- StorageClass:动态创建PV(无需管理员手动创建),如“请求StorageClass为
fast的PVC时,自动创建云存储卷(如AWS EBS)”;
-
资源隔离与配额:
- ResourceQuota:为Namespace设置资源配额(如“dev Namespace最多使用10核CPU、20G内存”),避免资源滥用;
- LimitRange:为Pod/容器设置默认资源配额(如“默认每个Pod使用0.5核CPU、1G内存”),限制单个资源的最大/最小值;
-
安全管理机制:
- RBAC(基于角色的访问控制):通过“角色(Role)”定义权限(如“允许读取Pod”),通过“角色绑定(RoleBinding)”将角色分配给用户,实现细粒度权限控制;
- NetworkPolicy:定义Pod间的网络访问规则(如“仅允许frontend Pod访问backend Pod的8080端口”),实现网络隔离;
- Pod安全准入:替代旧的PodSecurityPolicy,通过“安全级别(如Privileged、Baseline、Restricted)”限制Pod的权限(如禁止使用特权容器);
六、K8S常见部署方案
不同场景下,K8S的部署方式差异较大,需根据需求选择合适的方案:
| 部署方式 | 适用场景 | 核心特点 |
|---|---|---|
| Minikube | 本地学习、实验、演示(如开发人员验证K8S配置) | - 单节点集群,资源占用低(默认1核2G); - 支持一键启动( minikube start)、停止(minikube stop);- 不支持生产环境,仅用于测试; |
| kubeadm | 中小型集群(如测试环境、企业非核心业务) | - 官方推荐工具,简化部署流程(如kubeadm init初始化控制平面,kubeadm join加入节点);- 自动生成证书、配置文件,支持高可用部署; - 需手动配置网络插件(如Calico、Flannel)、存储等; |
| 二进制/源码部署 | 生产环境(如核心业务集群)、对可控性要求高的场景 | - 手动下载二进制文件(如kube-apiserver、kubelet),手动配置证书、系统服务; - 高度可控,可定制化(如修改组件参数、集成监控); - 部署复杂,需熟悉K8S组件原理; |
| 云托管服务(如GKE/EKS/ACK) | 企业生产环境、追求运维效率的场景 | - 云厂商管理控制平面(如AWS EKS自动维护API Server、etcd),用户只需管理Node节点; - 支持一键扩容、升级、监控集成(如阿里云ACK集成云监控); - 成本较高,依赖云厂商服务; |
推荐选择:若搭建K8S 1.28实验环境,优先选择“kubeadm + containerd”——兼顾部署效率与学习价值;若为生产环境,小型集群可选kubeadm,大型集群推荐云托管服务(如阿里云ACK)或二进制部署。
总结
本文从云原生基础入手,系统梳理了Kubernetes的核心知识——从架构组件、核心概念,到资源对象与特性,覆盖了K8S从入门到实践的关键环节。
K8S的核心价值在于“自动化”与“高可用”:它将开发者从底层基础设施管理中解放出来,聚焦于业务逻辑;同时通过自愈、弹性伸缩、滚动更新等特性,确保应用在动态环境中稳定运行。
然而,K8S的学习并非一蹴而就——建议读者结合实践:
- 用Minikube搭建本地实验环境,熟悉
kubectl命令; - 尝试用kubeadm部署小型集群,理解控制平面与Node节点的协作;
- 用声明式管理部署实际应用(如Spring Boot服务),掌握YAML配置与发布策略;
后续可进一步探索K8S的进阶内容,如网络插件(Calico/Flannel)、持久化存储(Ceph/NFS)、监控告警(Prometheus/Grafana)、日志收集(ELK)、权限控制(RBAC)等,逐步构建企业级K8S集群的运维能力。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 36
36 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)