基于机器学习的共享单车轨迹大数据分析
摘要:本文针对共享单车调度不合理问题,提出基于机器学习的轨迹数据分析方法。研究通过采集日期、天气等特征数据,采用线性回归和岭回归算法构建使用量预测模型。实验表明,两种模型预测准确度均达0.71以上,能有效分析用户行为模式和需求热点,为优化单车投放提供决策依据。研究成果对提升共享单车运营效率、促进绿色出行具有重要参考价值。
摘要:随着城市的发展,交通拥堵与环境污染问题逐渐严重,共享单车是我国推出的一种绿色便捷的出行方式,随着共享单车的普及,其也产生了大量的轨迹数据,目前对共享单车轨迹的数据分析应用比较落后,特地地区的共享单车的使用情况不能合理调度,导致共享单车投放区域不合理,影响市民的出行。基于此本文选择机器学习的共享单车轨迹大数据分析课题进行研究。
本文以共享单车轨迹数据为基础进行研究,采用线性回归和岭回归算法建立共享单车使用量预测模型。本文主要实现:(1)通过CDSN等网站收集共享单车数据,对共享单车数据元素进行描述,并统计共享单车数据的缺少值情况并进行阐述,对假期、工作日、天气等数据进行数值化处理;检测并删除重复的共享单车数据,防止共享单车模型训练过拟合;(2)分析共享单车数据特征与用户数量之间关系,并绘制可视化图;(3)以线性回归算法和岭回归算法实现共享单车使用量预测模型,并通过模型的评估报告对共享单车使用量预测模型进行评估;对比选出优秀的共享单车使用量预测模型;最后完成基于线性回归算法和岭回归算法的共享单车使用量预测功能。通过实验数据验证,基于线性回归算法和岭回归算法的共享单车使用量预测模型准确度达到0.71以上,因此两种模型的应用对共享单车合理调度有着重要的参考意义。
关键词:共享单车轨迹数据分析;共享单车使用量预测;线性回归算法;岭回归算法
研究内容
本文以收集的共享单车相关数据为研究对象,基于线性回归算法和岭回归算法进行共享单车使用量预测模型构建,具体研究如下。
(1)收集共享单车相关的数据如日期、季节、年份、月份、假期、工作日、天气、摄氏度、体感温度、湿度、风速、临时用户数、已注册用户数、单车使用量等信息,对共享单车数据集的缺失值进行统计及处理,并验证重复的共享单车数据情况,对重复的共享单车数据进行删除。
(2)绘制共享单车数据分析图,分别进行用户结构统计分析。
(3)划分训练集、测试集,基于线性回归算法的共享单车使用量预测模型训练以及评估,展示共享单车测试集预测和实际的对比情况;
(4)基于岭回归算法的共享单车使用量预测模型构建,完成模型训练、评估的分析、共享单车测试集的预测等。
(5)线性回归算法与岭回归算法的共享单车使用量预测模型比较,选出最佳的共享单车模型,并实现不同算法的共享单车使用量预测功能,同时根据共享单车范围明确其是否在正常范围内。
一、选题的动因(背景或意义)
共享单车轨迹大数据分析的选题背景及意义是通过数据分析和机器学习模型预测共享单车需求、优化单车分布、提升运营效率,并有助于解决“最后一公里”问题,实现与公共交通的无缝连接。而其选题的意义则在于助力智慧城市建设、促进绿色出行和低碳生活、增强城市交通管理。
选题动因:1. 自行车共享系统的兴起:自行车共享系统自动化了从会员注册到租赁、归还的整个过程,用户可以轻松地从特定位置租用并在另一个位置归还自行车。目前全球已有超过500个自行车共享计划,这些系统在交通、环境和健康问题上扮演着重要角色。2. 数据特征与研究吸引力:与其他交通工具不同,自行车共享系统明确记录了旅行的持续时间、出发和到达位置,使其成为研究城市移动性的虚拟传感器网络。监测这些数据可以感知和检测城市中的大多数重要事件,进而优化城市交通管理。3. 大数据与机器学习的应用:利用相关的大数据,如时间、季节、天气、温度、湿度、风速等,构造符合共享单车使用场景的变量,并通过机器学习模型进行需求预测。机器学习和深度学习模型可以通过比较Rsquare、MSE、RMSE等指标来评估预测效果,从而帮助共享单车管理者合理投放单车数量,减少资源浪费。4. 现实问题与改善建议:分析共享单车的使用场景,如“最后一公里”问题,建设绿色城市、低碳城市的主要挑战,并据此提出改善性意见。依据实时收集的环境数据进行建模,精准预测单车需求量,从而实现更高效的共享单车运营管理。5. 需求预测与模型比较:短期内基于小时的共享单车需求预测能够为城市交通管理提供即时决策支持,随机森林和迭代决策树模型在这一方面表现尤为突出。影响共享单车小时需求的主要因素包括特定的位置、时间以及天气条件,这些因素为精准预测提供了基础。
选题的意义:1. 助力智慧城市建设:共享单车的大数据分析可以协助城市规划者更好地理解居民的出行模式和需求,为城市交通建设提供数据支持。通过分析骑行轨迹和高频使用区域,可为城市自行车道的规划和建设提供实证参考。2. 促进绿色出行:研究如何通过共享单车减少机动车使用,从而降低碳排放,推动城市可持续发展。鼓励居民选择环保的出行方式,有助于缓解城市交通拥堵和改善空气质量。3. 增强城市交通管理:共享单车需求预测可以为城市交通管理部门提供决策依据,比如调整公交班次、优化停车设施等。数据驱动的需求分析有助于更加精细化地调配城市交通资源,提高整体交通系统的效率。综上所述,在共享单车轨迹大数据分析中,机器学习方法的选题背景及意义体现在对现代城市交通问题的积极应对上,尤其对于解决“最后一公里”问题和城市交通的优化管理具有重要价值。同时,这一研究课题也展示了大数据分析和机器学习技术在智慧城市建设中的应用潜力。
二、课题拟阐明的主要问题和思路
(一)研究内容或拟阐述的问题:
主要问题:
1. 如何通过分析共享单车轨迹数据来了解用户行为模式?
2. 如何根据轨迹数据进行热点区域分析和需求预测?
3. 如何利用这些数据分析结果来优化共享单车的布局和调度?
4. 如何提升共享单车系统的效率和用户体验?
5. 如何确保数据隐私和安全在分析过程中得到保护?
(二)设计(论文)思路:
思路:
1. 数据收集与预处理:从共享单车系统中收集轨迹数据,包括时间戳、位置坐标、行程时长等,并进行清洗、去噪和格式化处理。
2. 特征工程:提取有助于分析的特征,例如出发地和目的地、行程时间、天气条件、日期和时间等。
3. 用户行为分析:使用聚类算法如k-means或dbscan识别常见的骑行模式和用户群体,并分析不同用户群体的行为特征。
4. 热点区域分析:应用密度估计方法(如核密度估计)来确定骑行的高频区域,从而揭示城市中的热点和冷点区域。
5. 需求预测:构建时间序列模型或机器学习模型(如随机森林、梯度提升树等)预测特定时间段和区域的单车需求量。
6. 资源优化配置:基于需求预测结果,制定动态调度策略,优化车辆分布和调度计划,减少空车率和提高车辆利用率。
7. 效率与体验提升:利用上述分析结果调整运营策略,比如增加高需求区域的车辆供应、设置推荐停车点等,以提高服务效率和用户满意度。
8. 数据隐私与安全:在分析过程中采取数据匿名化、加密传输等措施保护用户隐私和数据安全。
9. 模型评估与迭代:通过实际运营数据来评估模型性能,并根据反馈不断调整和优化模型。
三、设计(论文)提纲
标题:基于机器学习的共享单车轨迹大数据分析
摘要:简要概述研究的背景、主要研究内容、所采用的方法、实验结果以及结论和意义。
关键词:共享单车;轨迹数据;机器学习;大数据分析;城市交通
第一章 引言
1.1 研究背景
介绍共享单车系统的发展,以及轨迹数据在交通领域分析的重要性。
1.2 研究意义
阐述分析共享单车轨迹数据对城市规划、交通管理、环境监测等方面的价值。
1.3 研究目标与任务
明确研究的主要目标、具体任务和预期成果。
1.4 论文结构
说明后续章节的安排和各章节之间的联系。
第二章 相关工作回顾
2.1 共享单车系统分析
回顾共享单车系统的发展历程、运营模式及其在城市交通中的作用。
2.2 轨迹数据的特征与应用
总结轨迹数据的特点,并概述其在各领域的应用现状。
2.3 机器学习在轨迹数据分析中的应用
梳理机器学习方法在轨迹数据分析中的现有研究和成果。
2.4 现有研究的不足与挑战
指出目前研究中存在的问题和面临的挑战。
第三章 研究方法论
3.1 数据收集与预处理
描述如何收集共享单车轨迹数据,并进行清洗、去噪和格式化处理。
3.2 特征工程
阐述如何从轨迹数据中提取有利于分析的特征。
3.3 机器学习模型选择
论述为何选择特定的机器学习模型,如聚类、分类、预测模型等。
3.4 模型训练与验证
细述模型训练过程、交叉验证和参数调优等步骤。
第四章 共享单车轨迹数据分析
4.1 用户行为模式分析
展示通过机器学习模型识别的用户骑行模式和行为特征。
4.2 热点区域分析与需求预测
呈现如何确定骑行热点区域并预测单车需求。
4.3 资源优化配置策略
提出基于数据分析的共享单车优化调度策略。
4.4 效率与体验改善建议
根据分析结果,给出提升效率和用户体验的建议。
第五章 数据分析结果
5.1 用户行为分析结果
展现用户行为模式的分析结果和发现。
5.2 热点区域与需求预测结果
呈现热点区域分析和需求预测的详细结果。
5.3 优化策略效果评估
评价优化策略在实际运营中的效果和影响。
第六章 讨论
6.1 数据分析结果的解释
深入解析数据分析结果背后的原因和意义。
6.2 策略实施的潜在影响
讨论优化策略可能对城市交通和共享单车系统的影响。
6.3 研究局限性与未来工作
承认研究的局限性,并提出未来的研究方向。
第七章 结论与展望
7.1 研究结论
总结研究发现和研究贡献。
7.2 研究展望
提供对未来共享单车轨迹数据分析的展望。
用户结构统计分析
通过df读取共享单车数据,并按照临时用户和已注册用户数量进行统计分析,得到如图
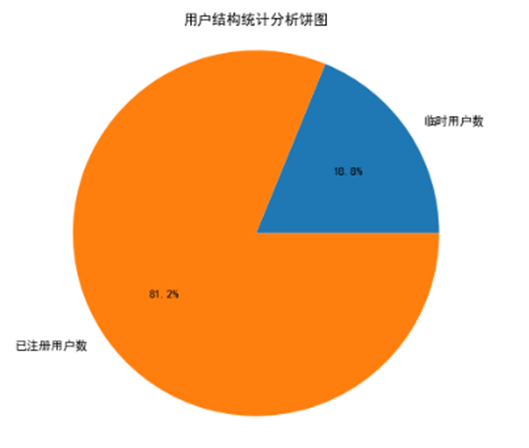
通过用户结构统计分析图可以分析得出, 可以看出某地区共享单车用户中已注册用户数和临时用户数的占比情况:已注册用户数占比 81.2%,在饼图中用橙色表示。这表明该地区大多数共享单车用户是已注册用户,说明很多用户选择长期使用共享单车,可能是因为注册用户能享受更多优惠、服务更便捷等原因。临时用户数:占比18.8%,在饼图中用蓝色表示。临时用户相对较少,可能是一些偶尔使用共享单车的人群,比如游客、只是短时间有出行需求的人等。
按照季节统计用户数量分析
通过df读取共享单车数据,以季节为分类,并按照临时用户和已注册用户数量进行统计分析,得到如图
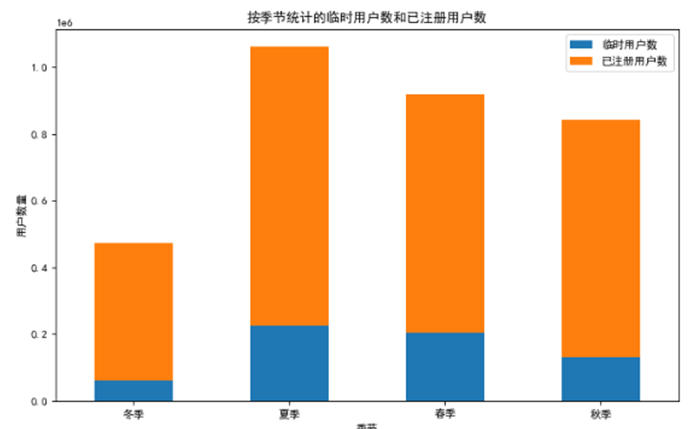
通过按照季节统计用户数量分析图可以分析得出, 冬季临时用户数和已注册用户数相对较少, 临时用户数占比较小,已注册用户数略多于临时用户数,整体的用户数量在四个季节中是最少的。这可能是因为冬季天气寒冷,人们出行更倾向于选择保暖性更好的交通方式,如乘坐室内交通工具或自驾。夏季用户数量达到峰值,尤其是已注册用户数显著增加。临时用户数也有一定增长, 可能是因为夏季天气较为适宜骑行,且可能是旅游旺季,吸引了更多临时用户使用共享单车。春季:用户数量仅次于夏季,已注册用户数和临时用户数都比较可观。春季气候温和,适合户外活动,使得共享单车的使用需求上升。秋季:用户数量有所下降,但仍高于冬季。 秋季天气逐渐转凉,不过仍然比较适合骑行,所以用户数量保持在一定水平。
基于线性回归的共享单车使用量预测模型训练
基于线性回归的共享单车使用量预测模型训练,读取621条共享单车训练集数据作为数据源,TrainZhiFangLin方法用于训练模型,ProZhiFangLin方法用于进行预测。
共享单车使用量预测模型训练(TrainZhiFangLin方法)
(1)初始化
在训练共享单车使用量预测模型之前,先初始化一个线性回归模型对象。这是通过调用LinearRegression()来实现的,它来自于sklearn.linear_model模块。
(2)加载训练数据
这里准备两份数据:一份是特征数据train_ZhiFang,另一份是对应的目标变量数据train_ZhiFangY(即共享单车的真实值)。这两份数据构成了训练集,用于训练线性回归模型。
(3)训练模型
使用训练数据来训练线性回归模型。通过调用linreg.fit(train_ZhiFang, train_ZhiFangY),模型会学习如何根据输入的特征数据来预测共享单车。这个过程涉及到优化算法来最小化预测值与真实值之间的误差。
(4)保存模型
训练完成后,使用joblib.dump()函数将训练好的模型linreg保存到磁盘上。文件名为self._zhiFile + "TrainZhiFangLin.model",其中self._zhiFile是类的一个属性,用于指定模型文件的保存路径。保存模型是为了以后能够加载并直接使用,而无需重新训练。
基于岭回归的共享单车使用量预测模型训练
基于岭回归的共享单车使用量预测模型训练,读取621条共享单车训练集数据作为数据源,TrainZhiFangReg方法用于训练模型,ProZhiFangReg方法用于进行预测。
共享单车使用量预测模型的训练(TrainZhiFangReg方法)
(1)初始化岭回归模型
在TrainZhiFangReg方法中,首先通过Ridge(alpha=100)初始化了一个岭回归模型实例linreg。这里,Ridge是scikit-learn库中的一个类,用于实现岭回归算法。alpha=100是正则化强度的参数,它决定了在损失函数中正则化项的重要性。通过引入正则化项,岭回归能够处理模型过拟合的问题,提高模型的泛化能力。
(2)训练岭回归模型
接下来,使用fit方法将岭回归模型linreg与训练数据train_ZhiFang(特征)和train_ZhiFangY(共享单车使用量标签)进行拟合。在训练过程中,岭回归模型会根据训练数据的分布,通过优化算法(如梯度下降)自动调整模型的参数,使得模型能够尽可能准确地拟合训练数据。这个过程实际上是在最小化预测值与真实值之间的误差,同时受到正则化项的约束。
(3)保存训练好的模型
在训练完成后,我们利用joblib.dump方法将基于岭回归算法训练得到的共享单车使用量预测模型保存为“TrainZhiFangReg.model”文件。这一步骤的目的是为了便于后续在需要时能够快速且准确地调用此模型,从而实现共享单车的预测功能。这里,joblib是Python中用于序列化和反序列化Python对象的库,它非常适合保存和加载机器学习模型。保存模型的好处在于,一旦模型训练完成,我们可以随时加载这个已经训练好的模型,而无需再次进行耗时的训练过程。这对于后续的预测任务或者模型的复用非常有帮助。
共享单车使用量预测功能实现
本文完成共享单车使用量预测功能,在界面设计了季节、月份、假期、工作日、天气、摄氏度、体感温度、湿度、风速的文本框,模型选择框,我们设定了一个预测按钮,用户点击该按钮后,将触发ZhiPre()方法以实现共享单车的预测功能。在ZhiPre()方法的内部,会对用户输入的共享单车数据进行必要的处理,以确保数据的准确性和有效性,从而进行准确的共享单车使用量预测,然后如果选择的是线性回归,则调用训练的基于线性回归的共享单车使用量预测模型来对共享单车进行预测,如果选择的是岭回归,则调用训练的基于岭回归的共享单车使用量预测模型来对共享单车进行预测。其中共享单车使用量预测界面如下图所示。

主要参考文献及相关资料
1. 期刊论文:
焦志伦, 金红, 刘秉镰, 张子豪 (2018). 大数据驱动下的共享单车短期需求预测——基于机器学习模型的比较分析:该文献研究了影响共享单车小时需求的主要因素,并比较了多种机器学习模型在短期需求预测中的效果。研究发现随机森林和迭代决策树模型相较于普通线性回归、套索回归和岭回归模型具有更高精确度。
颜轲越, 王祎萌, 李莹 (2022). 基于机器学习的共享单车需求预测: 此文通过实时收集的时间、季节、天气等数据,构造符合共享单车使用场景的变量,并利用不同机器学习和深度学习模型进行需求预测。结果显示深度学习模型表现更佳,有助于共享单车管理者合理投放单车数量。
2. 会议论文:
马勇 (2019). 基于共享单车轨迹数据的需求预测及智能调度方法研究: 本文探讨了基于北京某区域300万条共享单车出行记录的需求预测分析和需求分配优化,并对智能调度策略进行了研究。文中提出了基于LSTM的线性网络预测模型,以及基于遗传算法的调度模型求解方法和调度路线构建方案。
3. 学位论文:
曹旦旦, 范书瑞 (2017). 基于机器学习的共享单车需求预测研究: 该学位论文通过传统机器学习算法对共享单车短时需求量进行建模预测,为后续研究提供了基础参考。
宋鹏, 黄同愿 (2018). 支持向量机在共享单车需求预测中的应用: 在这篇论文中,作者通过消除原始数据噪声和支持向量机模型对单车需求量进行预测,取得了良好效果。
4. 书籍章节
刘卫东, 仲伟周, 石清 (2016). 2020年中国能源消费总量预测——基于定基能源消费弹性系数法: 虽然本书主要关注能源消费预测,但其方法论部分关于时间序列分析和预测模型构建的内容可为共享单车需求预测提供借鉴。
5. 其他资源
Kaggle共享单车需求数据集: Kaggle网站提供的共享单车需求数据可以作为实验和分析的基础,包含丰富的特征和记录,适用于训练和测试机器学习模型。
Geohash: 一种地理数据编码方式,常用于位置信息的转换和处理,可以在处理共享单车轨迹数据时用于获取位置和距离信息。
Python机器学习库: 包括scikit-learn、TensorFlow等,可用于构建和训练共享单车需求预测模型,是实际操作中不可或缺的工具。
参考文献(近三年刊期):
1. 《基于机器学习的共享单车需求预测》:本文介绍了利用机器学习技术对共享单车需求进行预测的方法,通过分析用户骑行数据,提高了需求预测的准确性。
2. 《共享单车轨迹数据的深度学习分析方法》:研究采用深度学习模型分析共享单车轨迹数据,识别出骑行模式和用户行为特征,为单车的智能调度提供决策支持。
3. 《融合气象数据的共享单车使用量预测模型》:作者探讨了气象因素对共享单车使用量的影响,并结合气象数据和历史使用数据,通过机器学习模型进行使用量预测。
4. 《基于随机森林的共享单车需求实时预测》:该文利用随机森林算法对共享单车需求进行实时预测,重点解决了需求峰值期间的预测问题,以提高系统响应效率。
5. 《城市共享单车出行模式及其影响因素分析》:本文通过对共享单车出行数据的分析,揭示了不同城市和区域的骑行模式,并就城市设计、交通政策等因素对骑行模式的影响进行了研究。
6. 《基于地理信息系统和机器学习的共享单车轨迹分析》:研究集成了地理信息系统和机器学习技术,对共享单车轨迹数据进行了深入分析,旨在优化单车分布和提高服务质量。
7. 《时间序列分析在共享单车需求预测中的应用》:该文探讨了采用时间序列分析方法对共享单车需求进行预测的可行性,实验结果表明,该方法能有效预测短期内的单车需求变化。
8. 《基于聚类分析的共享单车用户行为研究》:通过聚类分析方法,研究了共享单车用户的骑行习惯和偏好,为提供个性化服务和优化单车分布提供了依据。
9. 《共享单车调度优化的机器学习策略》:本文讨论了如何利用机器学习策略优化共享单车的调度计划,以减少空缺和过剩情况,提高用户满意度。
10. 《神经网络模型在共享单车需求预测中的应用》:介绍了神经网络模型在预测共享单车需求中的应用,并与其他传统预测模型进行了性能比较。
11. 《共享单车数据分析的可视化方法》:研究提出了一种针对共享单车数据的可视化分析方法,帮助人们更直观地理解骑行数据和用户需求。
12. 《基于关联规则挖掘的共享单车使用模式分析》:采用了关联规则挖掘技术,分析了共享单车使用数据,发现了骑行行为之间的有趣模式和规律。
13. 《面向共享单车优化调度的强化学习策略》:该文探索了强化学习在共享单车调度优化中的应用,通过自学调度策略,提高了调度效率。
14. 《共享单车轨迹数据的时空分析》:本文围绕共享单车轨迹数据的时空特性进行分析,揭示了城市骑行活动的时空分布特征,为城市交通规划提供参考。
15. 《基于梯度提升机的共享单车需求预测模型》:研究利用梯度提升机算法开发了共享单车需求预测模型,结果显示该模型具有较高的预测准确性和稳定性。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)