【2026最新原创】基于大数据的海鲜水产品安全信息可视化分析 (hadoop+spark+hive)
摘要 本文介绍了一个基于大数据技术的海鲜水产品安全信息可视化分析系统,采用Hadoop+Spark+Hive框架实现数据采集、处理与分析。系统整合生产、检测、供应链等多源数据,通过Spark进行分布式计算,结合Pandas清洗数据,并利用Vue+ECharts实现交互式可视化,展示安全评估、供应链监控及消费者特征分析。后端采用Django提供API支持,前端通过Vue构建响应式界面。系统显著提升了
🔥作者:雨晨源码🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💕💕文末获取源码
文章目录
本次文章主要是介绍基于大数据的海鲜水产品安全信息可视化分析 (hadoop+spark+hive)
1、海鲜水产品安全信息可视化分析-前言介绍
1.1背景
随着全球海鲜水产品贸易的不断增长,海鲜水产品的质量安全问题逐渐成为消费者、监管部门及生产企业关注的焦点。海鲜作为重要的蛋白质来源之一,其安全性直接关系到公众健康。然而,传统的水产品安全监管模式面临着数据分散、信息滞后、检测不全面等诸多挑战,导致在出现食品安全事件时,追溯性差、响应慢,严重时甚至影响到整个供应链的稳定性。因此,如何利用现代大数据技术,实时、高效地进行海鲜水产品的安全监管、数据分析与可视化,成为亟待解决的问题。尤其是在复杂的供应链管理中,涉及的环节繁多、信息复杂,依靠传统手工监管模式很难进行有效的监控和评估。因此,开发一个基于大数据技术的海鲜水产品安全信息可视化分析系统,不仅能提升监管效率,还能增强消费者的信任,推动行业健康发展。
1.2课题功能、技术
本课题旨在设计并实现一个基于大数据的海鲜水产品安全信息可视化分析系统,借助先进的技术手段提高对水产品安全问题的管控能力。系统主要包括数据采集、数据处理、分析评估和可视化展示等核心功能。数据方面,系统通过集成Hadoop、Spark和Hive等大数据技术,采集来自生产商、供应链管理方、检测机构等多个来源的海鲜水产品检测数据、供应链信息及消费者数据。数据处理层面,采用Spark进行大数据的分布式计算和数据分析,使用Pandas进行数据的进一步清洗与整理。可视化方面,系统前端使用Vue框架,结合ECharts可视化库,将处理后的数据转化为易于理解的图表、地图等形式,帮助用户快速掌握海鲜水产品的安全状况。系统的功能涵盖了安全评估分析、供应链监控、检测体系分析、消费者特征分析等多个维度,能够为各类用户(如监管部门、生产商、供应商、消费者)提供全方位的数据支持与决策依据。
1.3 意义
本课题的实施具有深远的社会意义与行业价值。首先,通过大数据分析和可视化技术的引入,极大提高了水产品安全监控的时效性和精准度,确保公众能够实时了解市场上水产品的安全状况。其次,系统能够有效整合各类安全数据与供应链信息,打破数据孤岛,实现信息共享,为政府监管部门提供高效的监管工具,为企业提供数据支持,促进产业的规范化发展。第三,系统的消费者分析功能帮助商家精准了解市场需求,提升供应链管理效率,并且增强消费者对食品安全的信任,推动透明化和责任化的消费模式。总之,本课题不仅在技术上推动了大数据和可视化技术在食品安全领域的应用,也为海鲜水产品的安全监管提供了一种新的解决方案,对提升行业的整体水平和保障食品安全具有重要意义。
2、海鲜水产品安全信息可视化分析-研究内容
(1)数据采集与清洗:系统通过集成多种数据源,如海鲜水产品生产商、检测机构、供应链管理方等,自动采集相关的检测报告、供应链信息以及消费者数据。利用Pandas进行数据清洗,去除重复、缺失或异常值,确保数据的准确性与完整性,为后续分析提供可靠基础。
(2)数据处理与分析:通过使用Spark对海量数据进行分布式处理,实现数据的快速清洗、转化与聚合分析。应用机器学习算法进行模式识别,利用统计分析方法评估不同水产品的安全性,生成精准的安全评估报告和趋势预测,为决策提供科学依据。
(3)数据可视化:借助ECharts和Vue.js技术,系统将分析结果转化为直观的可视化图表、热力图、趋势图等,展示水产品的安全状况、供应链流动以及消费者行为特征。通过交互式界面,用户可以自由选择时间范围、地区、产品种类等维度,实时查看相关数据。
(4)Web框架搭建:系统后端基于Django框架进行搭建,提供RESTful API供前端与后端数据交互。Django的高效开发支持模块化结构,方便进行业务逻辑扩展。同时,前端采用Vue.js框架实现响应式界面和用户友好的交互设计,确保系统的可用性与可维护性。
(5)系统测试:系统经过单元测试、集成测试以及压力测试,确保各个模块的稳定性与性能。在测试阶段,通过模拟不同的操作场景,验证数据采集、处理、分析和可视化功能的准确性与响应速度。同时进行安全性测试,确保系统的数据传输与存储的安全性。
3、海鲜水产品安全信息可视化分析-开发技术与环境
- 开发语言:Python
- 大数据:Hadoop+Spark+Hive
- 后端框架:Django
- 前端:Vue
- 数据库:MySQL
- 算法:
- 开发工具:Pycharm
4、海鲜水产品安全信息可视化分析-功能介绍
1、数据管理:信息列表展示。
4、词云图:词云图。
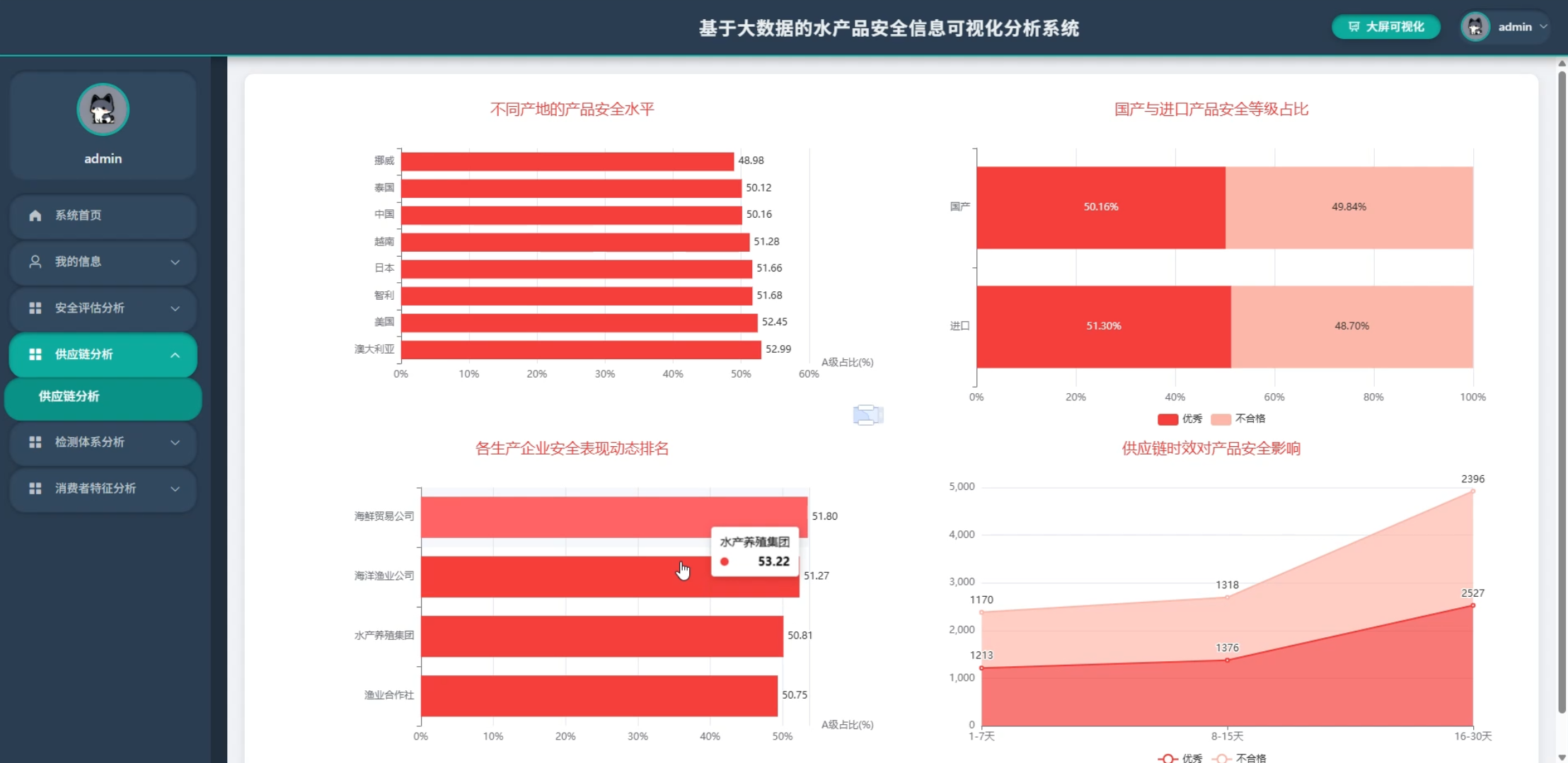
5、可视化分析:安全评估分析、供应链分析、检测体系分析、消费者特征分析
6、系统管理:登录注册、个人信息修改。
5、海鲜水产品安全信息可视化分析-论文参考
6、海鲜水产品安全信息可视化分析-成果展示
6.1演示视频
【2026最新原创】基于大数据的海鲜水产品安全信息可视化分析 (hadoop+spark+hive)
6.2演示图片
☀️首页☀️
☀️登录☀️
☀️可视化分析☀️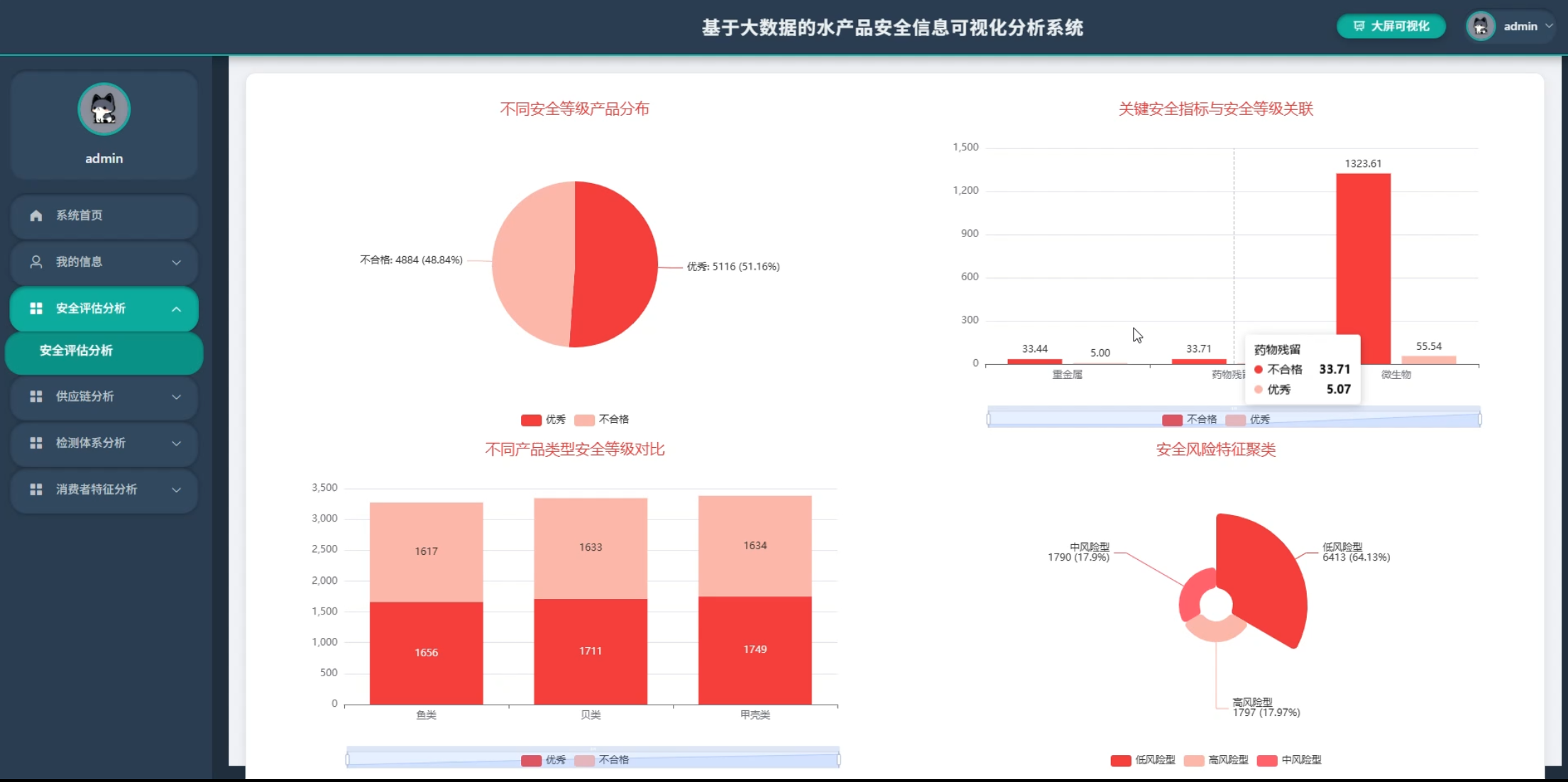
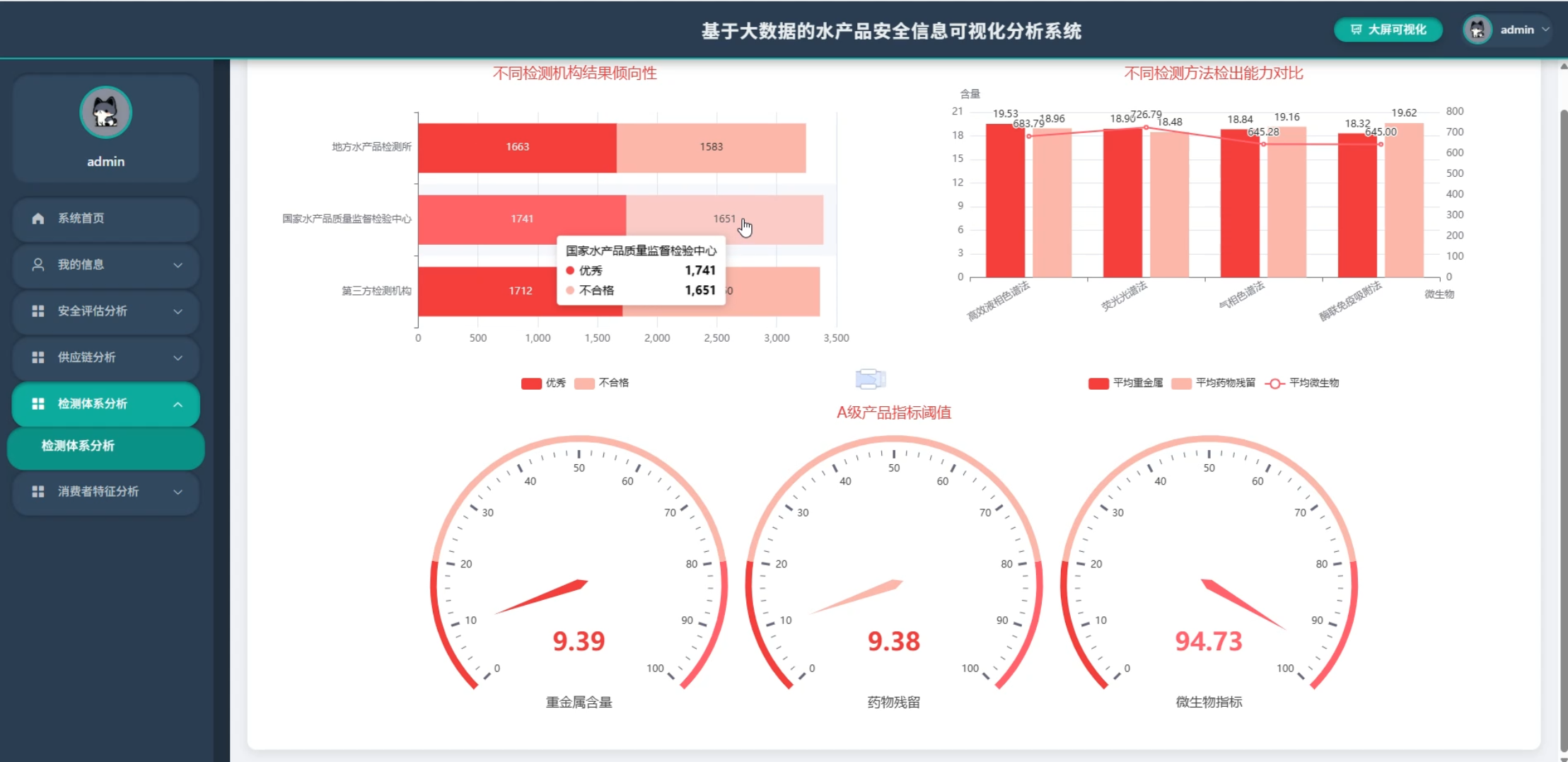
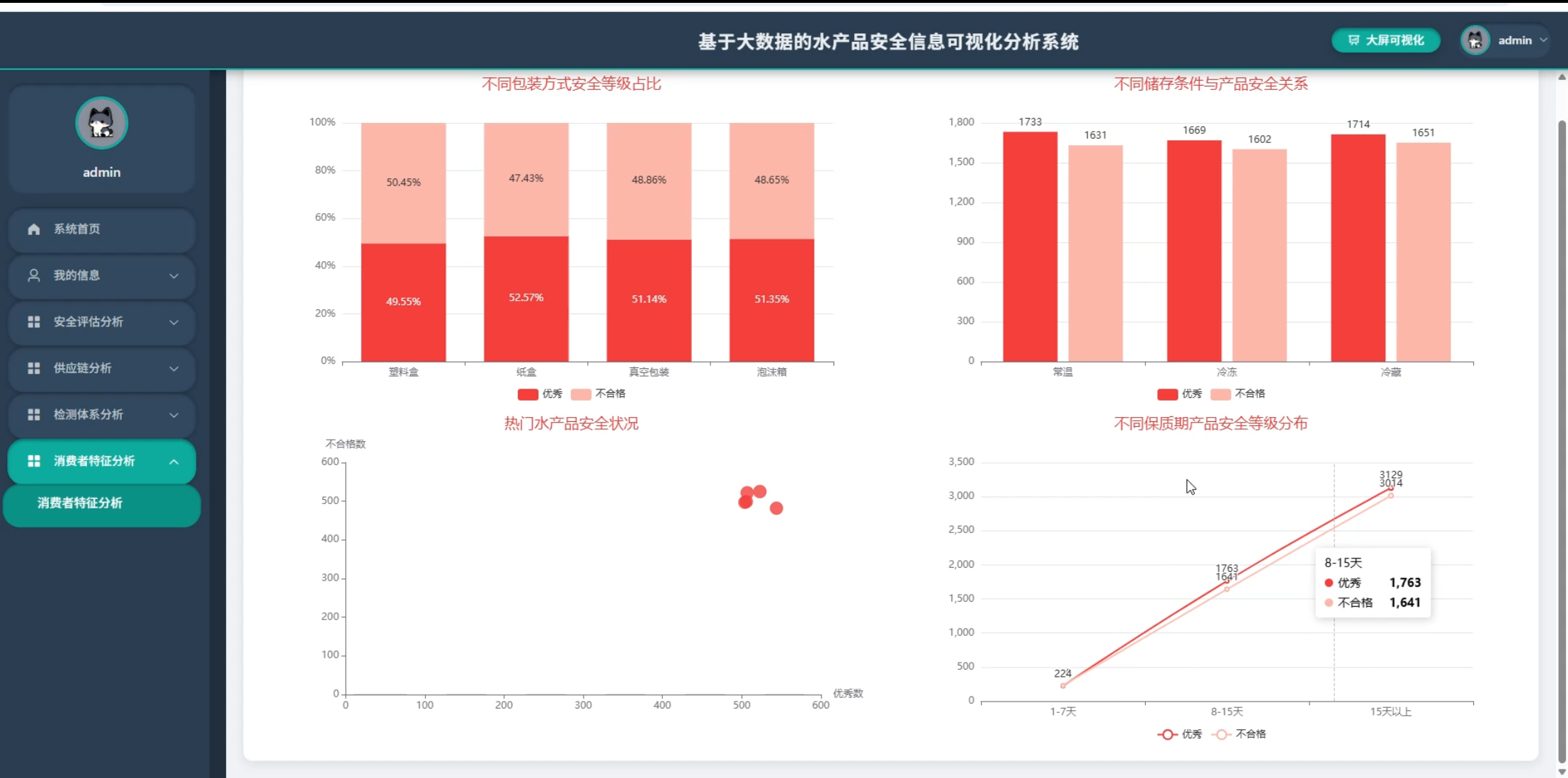
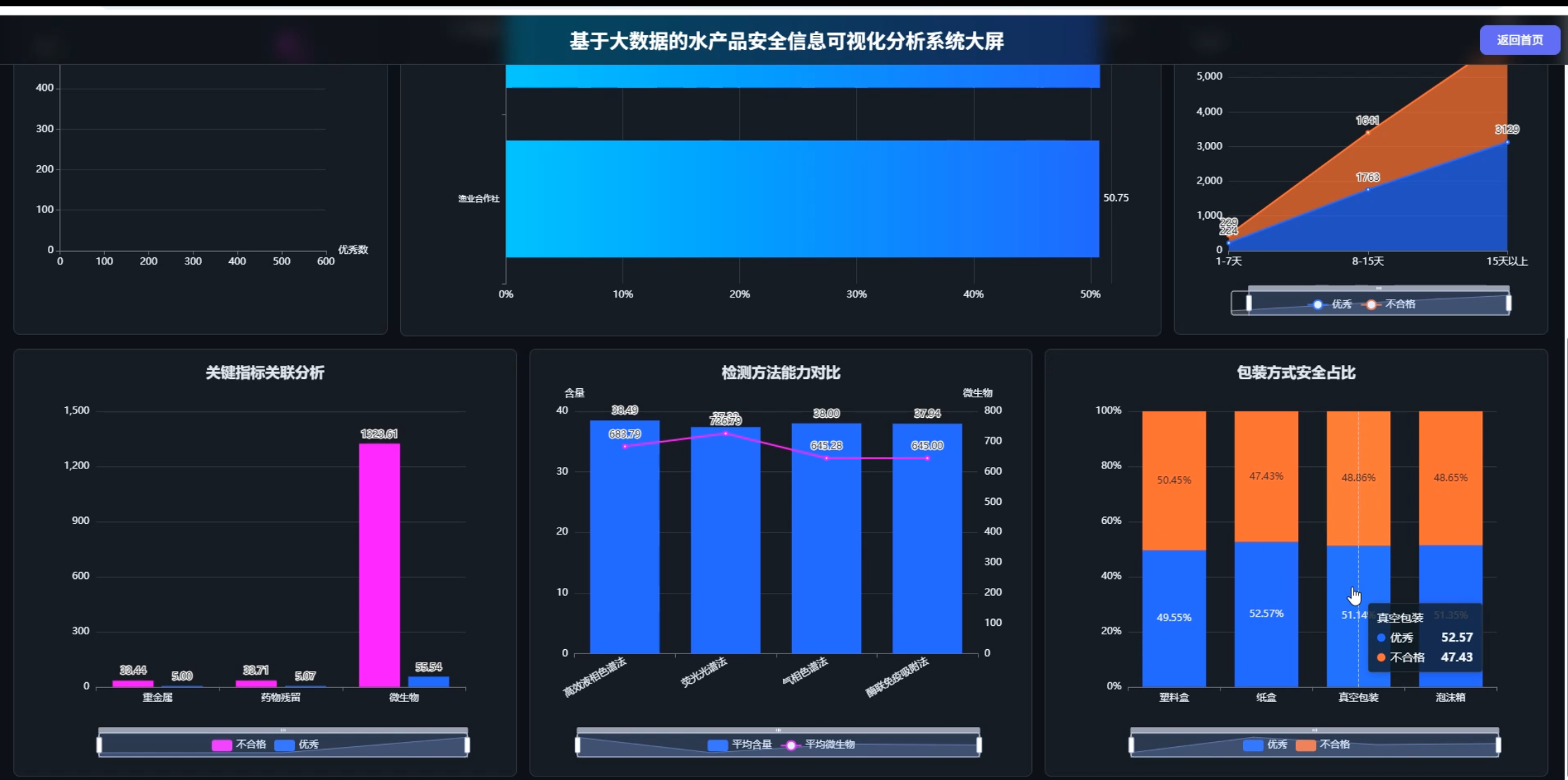
☀️大屏☀️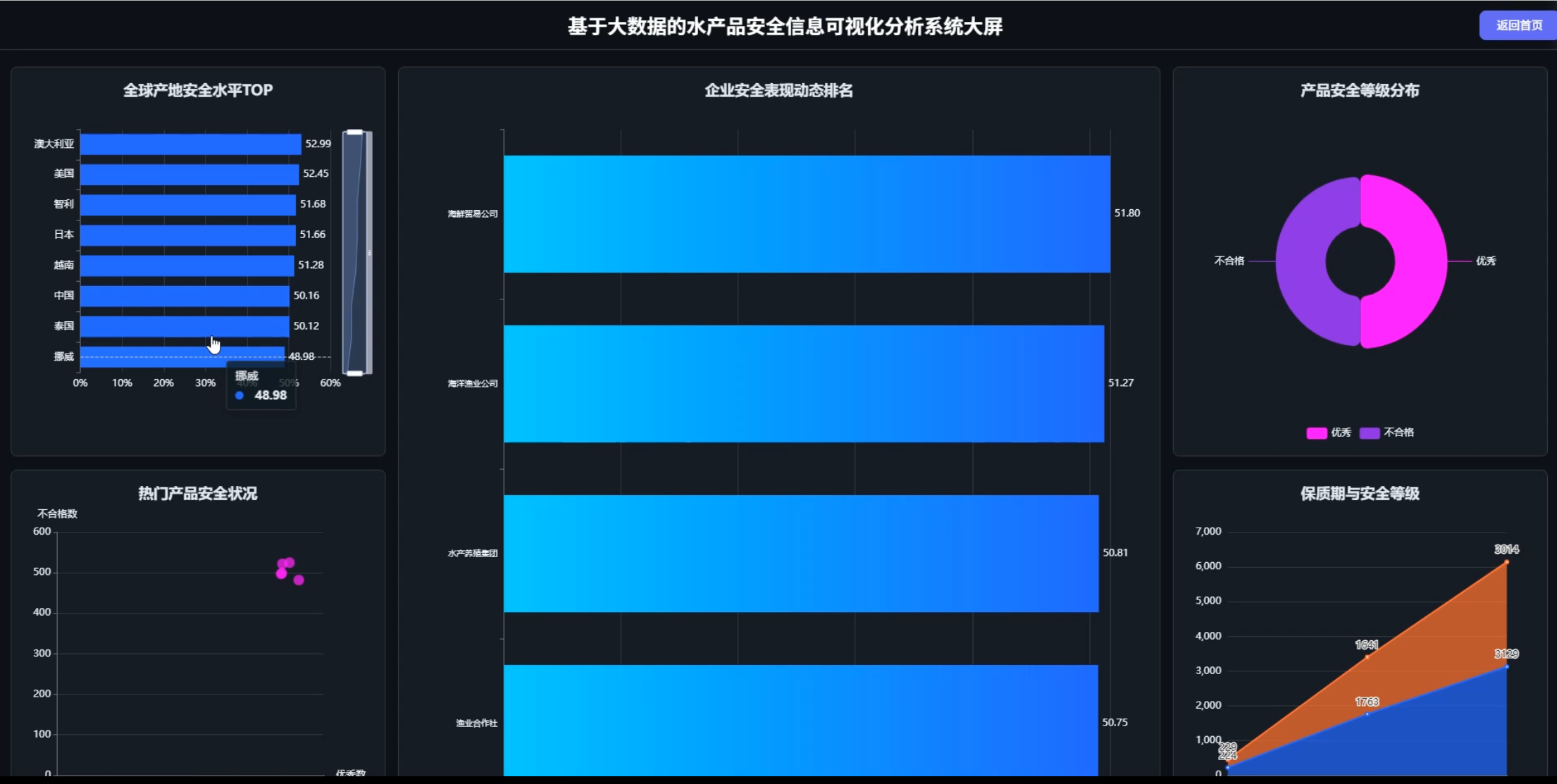
☀️XX数据管理☀️
7、代码展示
1.数据清洗【代码如下(示例):】
import pandas as pd
import numpy as np
# 读取原始数据
data = pd.read_csv("seafood_data.csv")
# 1. 删除重复数据
data.drop_duplicates(inplace=True)
# 2. 处理缺失值
# 方法1:删除包含缺失值的行
data.dropna(inplace=True)
# 方法2:填充缺失值,针对特定列填充均值
data['Detection_Value'].fillna(data['Detection_Value'].mean(), inplace=True)
# 3. 处理异常值(例如,检测值超出正常范围)
# 假设Detection_Value列的正常范围是0到100
data = data[(data['Detection_Value'] >= 0) & (data['Detection_Value'] <= 100)]
# 4. 类型转换:将日期列转换为日期类型
data['Detection_Date'] = pd.to_datetime(data['Detection_Date'])
# 5. 数据标准化:对数值型数据进行标准化处理(例如,将检测值缩放至0-1之间)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data['Detection_Value'] = scaler.fit_transform(data[['Detection_Value']])
# 输出清洗后的数据
data.to_csv("cleaned_seafood_data.csv", index=False)
2.大数据处理【代码如下(示例):】
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, count, when
# 初始化Spark会话
spark = SparkSession.builder.appName("SeafoodSafety").getOrCreate()
# 读取数据文件(假设数据存储在HDFS或S3中)
data = spark.read.csv("hdfs://path/to/seafood_data.csv", header=True, inferSchema=True)
# 1. 数据清洗:删除含有空值的行
data_cleaned = data.na.drop()
# 2. 数据转换:将检测值转换为浮动型数据类型
data_cleaned = data_cleaned.withColumn("Detection_Value", col("Detection_Value").cast("float"))
# 3. 异常值处理:删除检测值小于0或大于100的数据
data_filtered = data_cleaned.filter((col("Detection_Value") >= 0) & (col("Detection_Value") <= 100))
# 4. 数据汇总:计算每个产品的平均检测值和样本数量
product_stats = data_filtered.groupBy("Product_Type").agg(
avg("Detection_Value").alias("Average_Detection_Value"),
count("Detection_Value").alias("Sample_Count")
)
# 5. 标记不合格产品:假设检测值大于50为不合格
product_stats = product_stats.withColumn("Quality_Status",
when(col("Average_Detection_Value") > 50, "Not Safe").otherwise("Safe"))
# 6. 显示结果
product_stats.show()
# 将结果保存到HDFS
product_stats.write.csv("hdfs://path/to/output/product_quality_stats.csv", header=True)
# 关闭Spark会话
spark.stop()
8、结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 23
23 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)