【hadoop+spark】基于大数据的广西医疗机构数据可视化分析系统 疾病预测(2w条数据集)
本文介绍了一个基于大数据的广西医疗机构数据可视化分析系统。该系统针对广西医疗资源分布不均、服务能力差异等问题,通过Python+Django+Vue技术栈开发,结合Hadoop、Spark等大数据技术进行数据处理。系统具备医疗资源可达性分析、机构地理分布展示、医保服务覆盖率统计等功能,采用ECharts实现数据可视化。研究内容包括数据采集清洗、大数据处理分析、可视化展示及系统测试等环节,旨在为医疗
🔥作者:雨晨源码🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💕💕文末获取源码
文章目录
本次文章主要是介绍基于大数据的广西医疗机构数据可视化分析系统 疾病预测
1、广西医疗机构数据可视化分析系统-前言介绍
1.1背景
随着我国经济的快速发展和人民健康意识的提高,医疗行业在社会发展的各个领域中起到了日益重要的作用。然而,广西地区作为一个地理、人口和经济发展不均的省份,医疗资源的分布、医疗服务的质量和可及性问题仍然十分突出。广西不仅面临着医疗机构不均衡分布、医疗资源短缺的困境,而且在不同区域的医疗保障体系建设、医保服务覆盖面等方面也存在一定的差异。因此,如何通过精准的数据分析和科学的决策来改善广西的医疗资源配置,提高医疗服务质量和居民的健康保障水平,成为亟待解决的问题。在这个背景下,开发一款基于大数据的广西医疗机构数据可视化分析系统显得尤为重要。该系统将为政府决策者提供有关医疗资源分布、医保覆盖率、医疗机构规模及服务能力等方面的深入分析,帮助优化医疗资源的配置,提升医疗服务的可达性和效率。
1.2课题功能、技术
本课题旨在开发一个集医疗资源可达性分析、医疗机构地理分布分析、医保服务覆盖率分析、机构规模结构分析以及机构服务能力分析等功能于一体的医疗数据可视化分析系统。系统采用Python编程语言开发,后端使用Django框架,前端使用Vue.js框架和ECharts进行数据可视化展示。为了应对大规模医疗数据的处理,系统结合了Hadoop、Spark和Hive等大数据技术进行数据存储、分布式计算与分析。通过Pandas进行数据清洗与预处理,确保数据的高质量与一致性。用户可以通过系统直观地查看广西医疗机构在不同区域、规模及服务能力方面的分布情况,同时系统能够生成各类统计图表和地图,展示医保服务的覆盖率和医疗资源的可达性。通过这些功能,系统不仅能够帮助用户深入了解医疗资源现状,还能为政府部门制定相关政策提供数据支持。
1.3 意义
本课题的实施意义在于通过数据驱动的方式为广西医疗行业的发展提供决策支持。首先,系统能够准确反映医疗资源的空间分布与服务能力,为政府提供优化医疗资源配置的依据,帮助减少资源过度集中或分散的问题。其次,医保服务覆盖率分析模块将有助于政府评估现行医保政策的实施效果,并制定合理的调整方案,以提高医疗保障的覆盖面和公平性。再次,机构规模结构分析将揭示不同规模医疗机构在提供医疗服务中的作用和优势,帮助实现资源的合理分配与高效利用。最后,通过医疗资源可达性分析,系统能够帮助识别出资源匮乏的区域,为地方政府提供具体的资源投入方向,提升基层医疗水平。综上所述,基于大数据的广西医疗机构数据可视化分析系统能够为广西乃至全国范围内的医疗资源优化和政策制定提供科学、直观的决策支持,推动医疗行业的公平性、普及性和可持续发展。
2、广西医疗机构数据可视化分析系统-研究内容
(1)数据采集与清洗:
数据采集主要通过爬虫技术和API接口,收集广西医疗机构的基础数据,如医院名称、地址、医保覆盖范围、服务项目等。数据清洗步骤包括填充缺失值、去除重复数据、标准化字段格式、异常值检测及处理,确保数据质量符合分析要求
(2)大数据处理与分析:
通过Hadoop和Spark框架,对大规模医疗数据进行高效处理与分析。使用Hive进行数据存储与查询,并对医疗机构的分布、服务能力、医保覆盖率等进行聚合分析。通过数据挖掘算法,识别出医疗资源分布中的关键问题和优化空间。
(3)数据可视化:
数据可视化采用ECharts展示分析结果,通过交互式图表和地图展示医疗机构的地理分布、规模、服务能力等信息。通过热力图、柱状图、饼图等多种图形化形式,帮助用户直观地分析医疗资源的分布情况和发展趋势,支持决策分析。
(4)Web框架搭建:
使用Django框架搭建后端,处理业务逻辑和数据库交互,前端使用Vue.js实现用户界面。通过RESTful API实现前后端数据交互,并结合ECharts进行数据可视化展示,提供用户友好的界面和高效的数据查询及展示功能。
(5)系统测试:
系统测试包括单元测试、集成测试和性能测试。通过模拟不同用户场景,确保系统在高并发情况下的稳定性和响应速度。此外,进行数据准确性验证,确保数据采集、清洗、处理的每个环节符合预期,为用户提供可靠的数据支持和决策依据。
3、广西医疗机构数据可视化分析系统-开发技术与环境
- 开发语言:Python
- 大数据:Hadoop+Spark+Hive
- 数据处理:pandas
- 后端框架:Django
- 前端:Vue
- 数据库:MySQL
- 算法:
- 开发工具:Pycharm
4、广西医疗机构数据可视化分析系统-功能介绍
1、数据管理:广西医疗机构数据信息列表展示。
4、词云图:词云图。
5、可视化分析:医疗资源可达性分析、机构地理分布分析、医保服务覆盖率分析、机构规模结构分析、机构服务能力分析
6、系统管理:登录注册、个人信息修改。
5、广西医疗机构数据可视化分析系统-论文参考
6、广西医疗机构数据可视化分析系统-成果展示
6.1演示视频
【hadoop+spark】基于大数据的广西医疗机构数据可视化分析系统 疾病预测(2w条数据集)
6.2演示图片
☀️首页☀️
☀️登录☀️
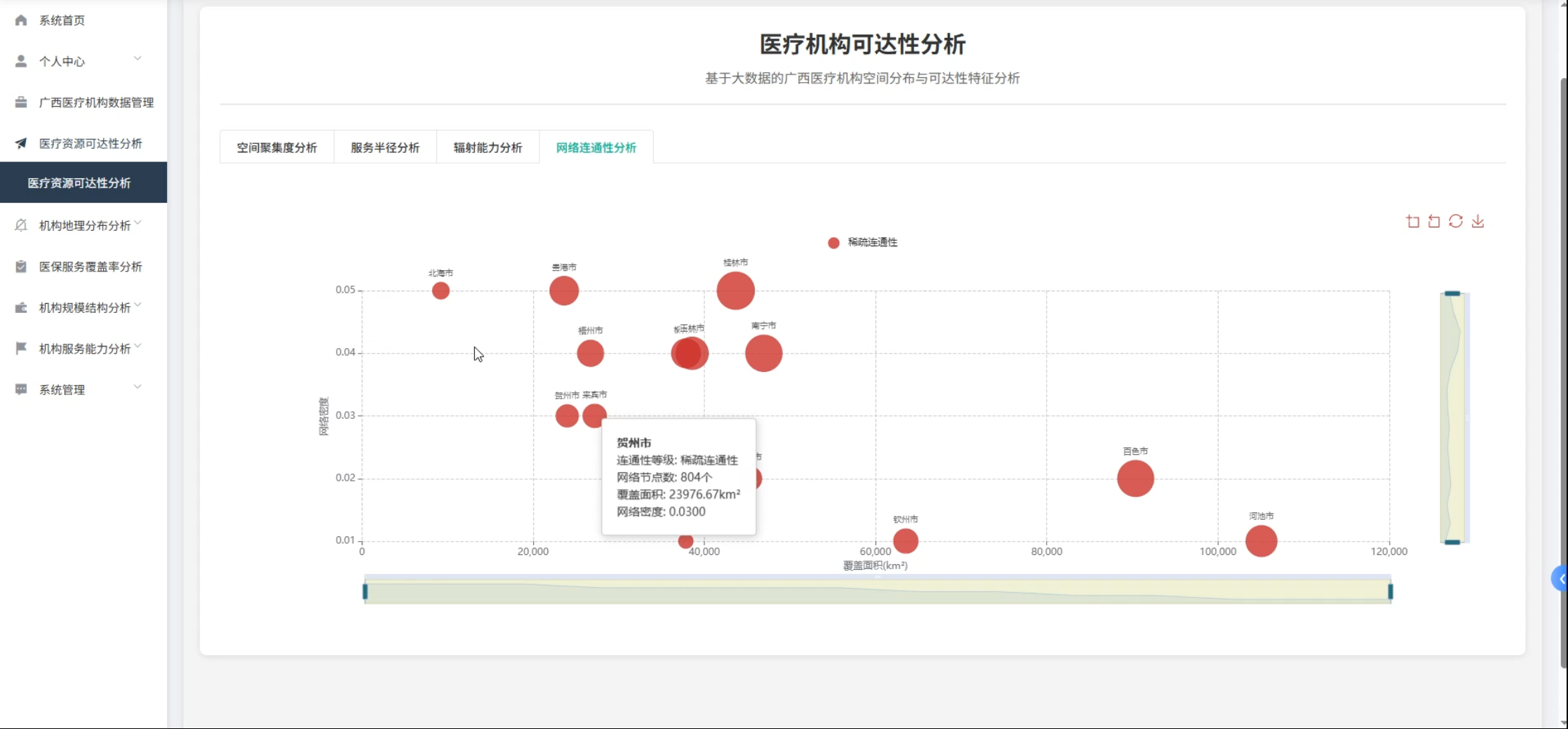
☀️可视化分析☀️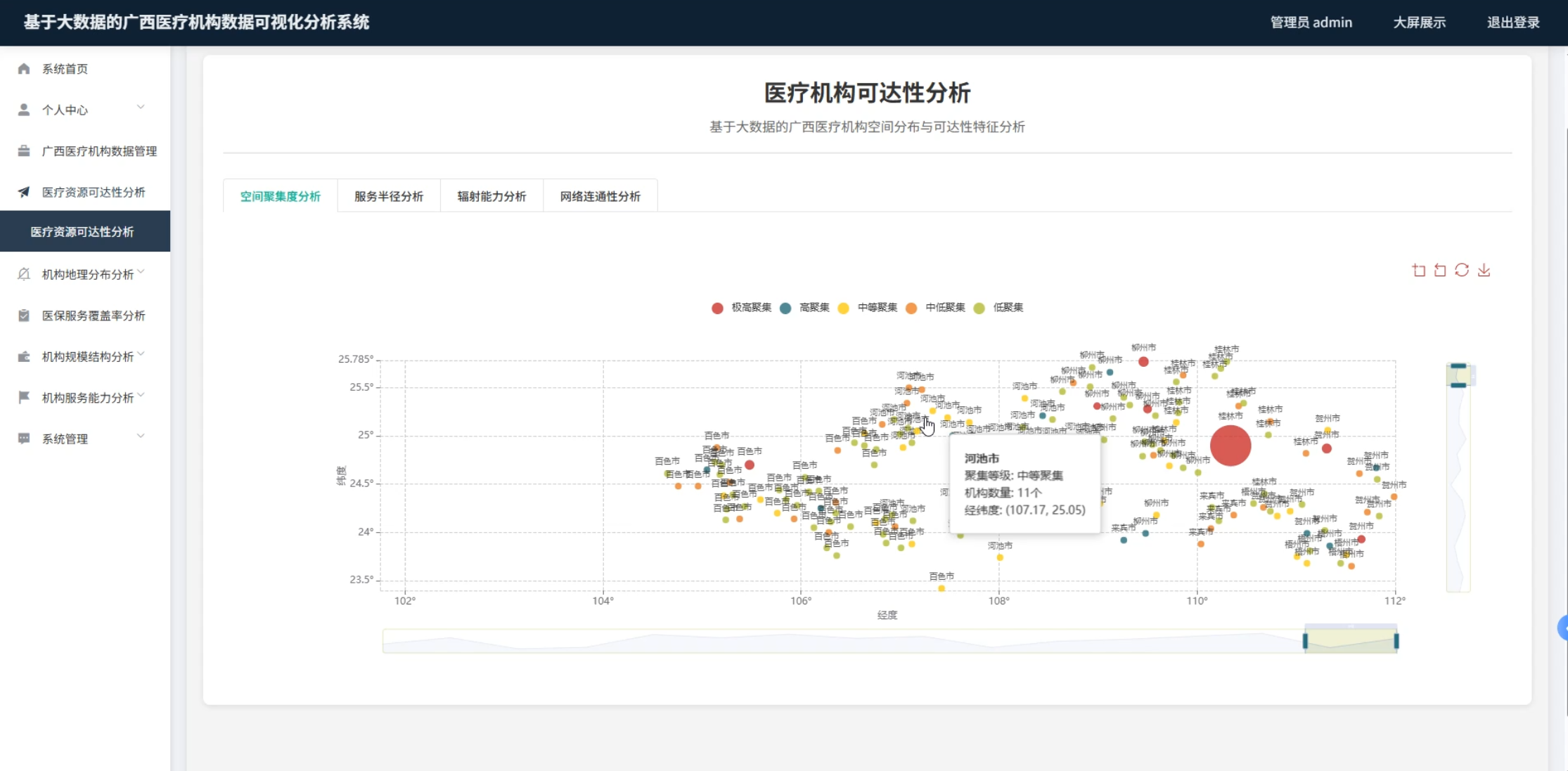
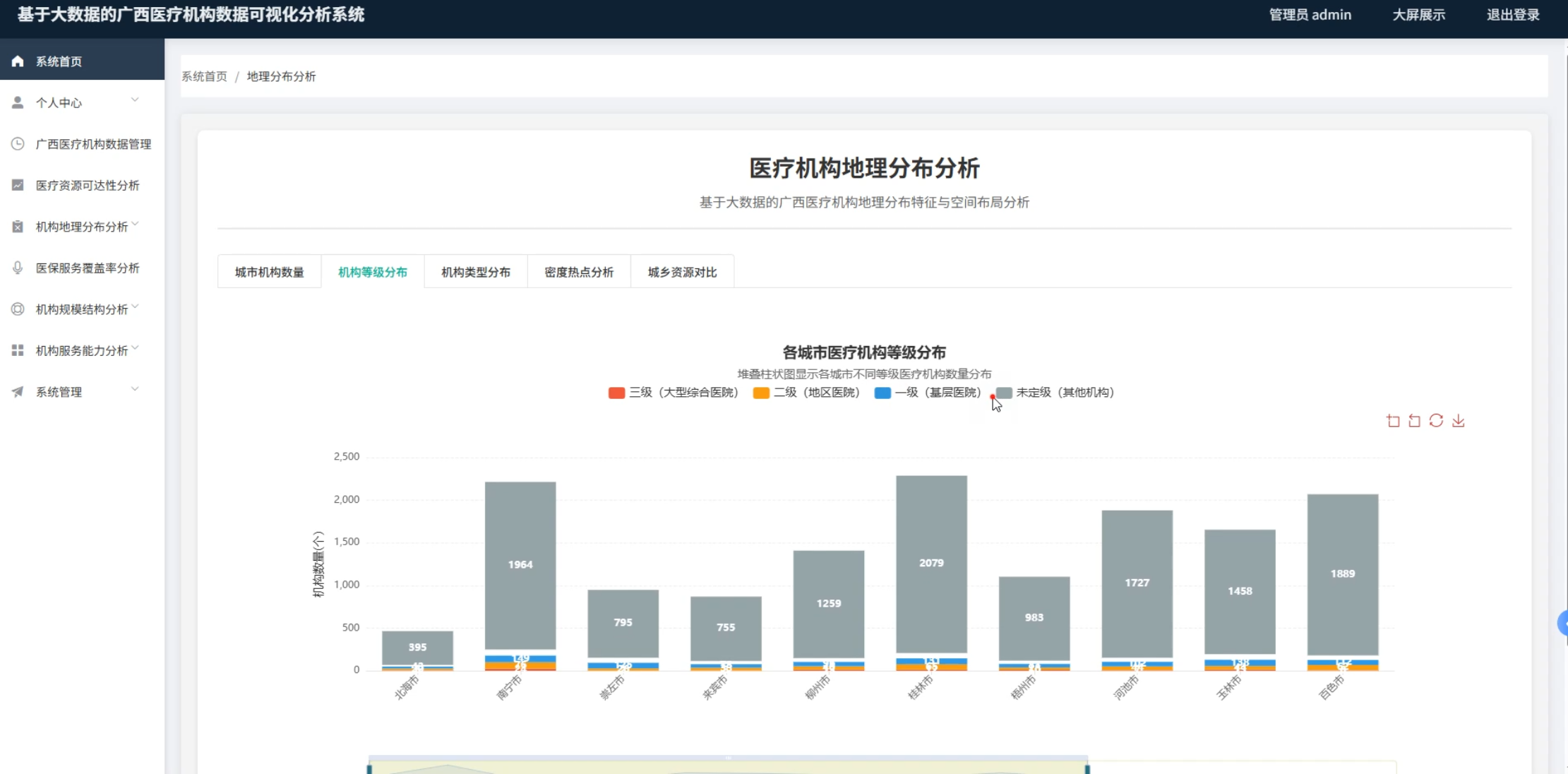
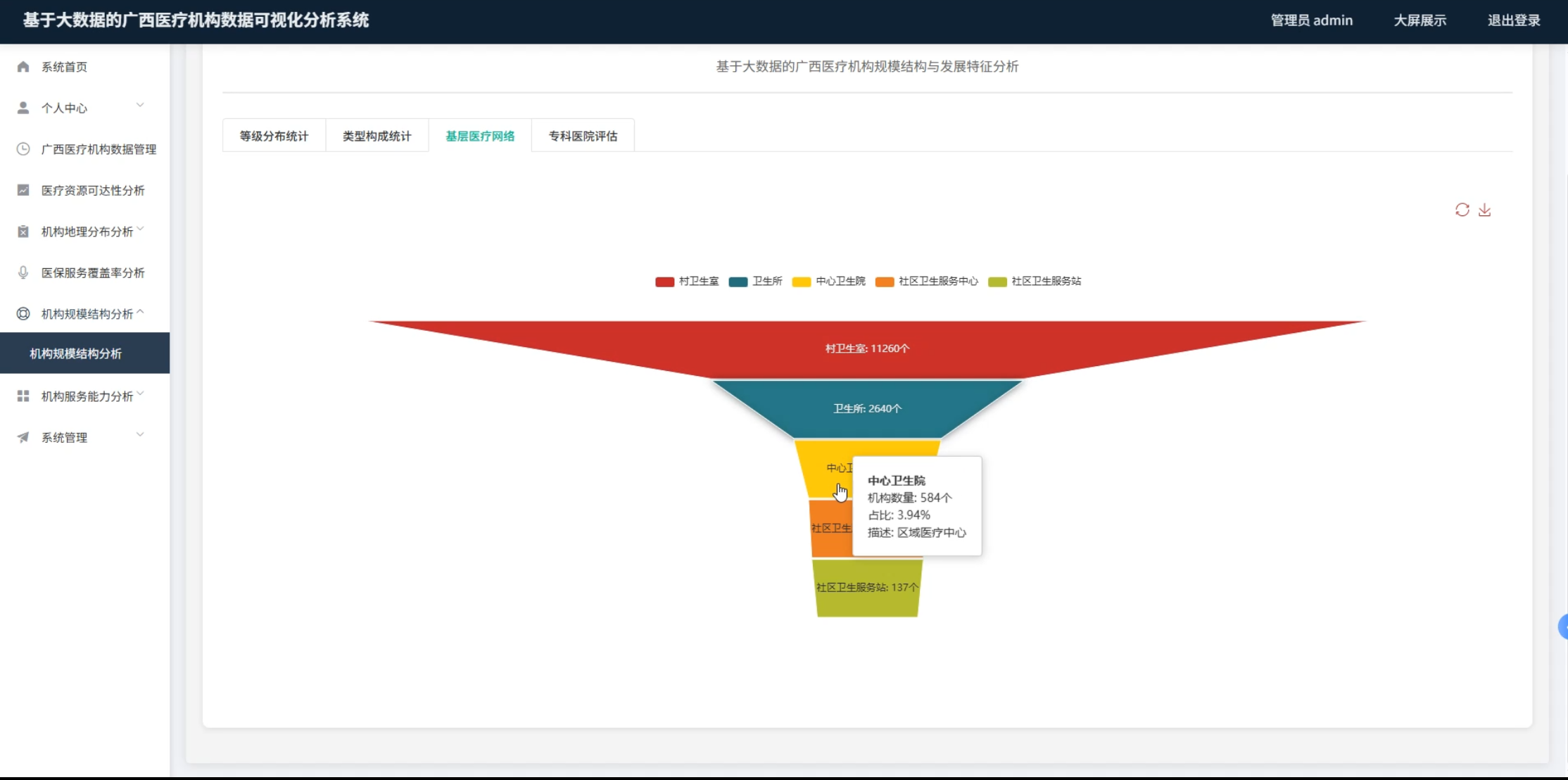
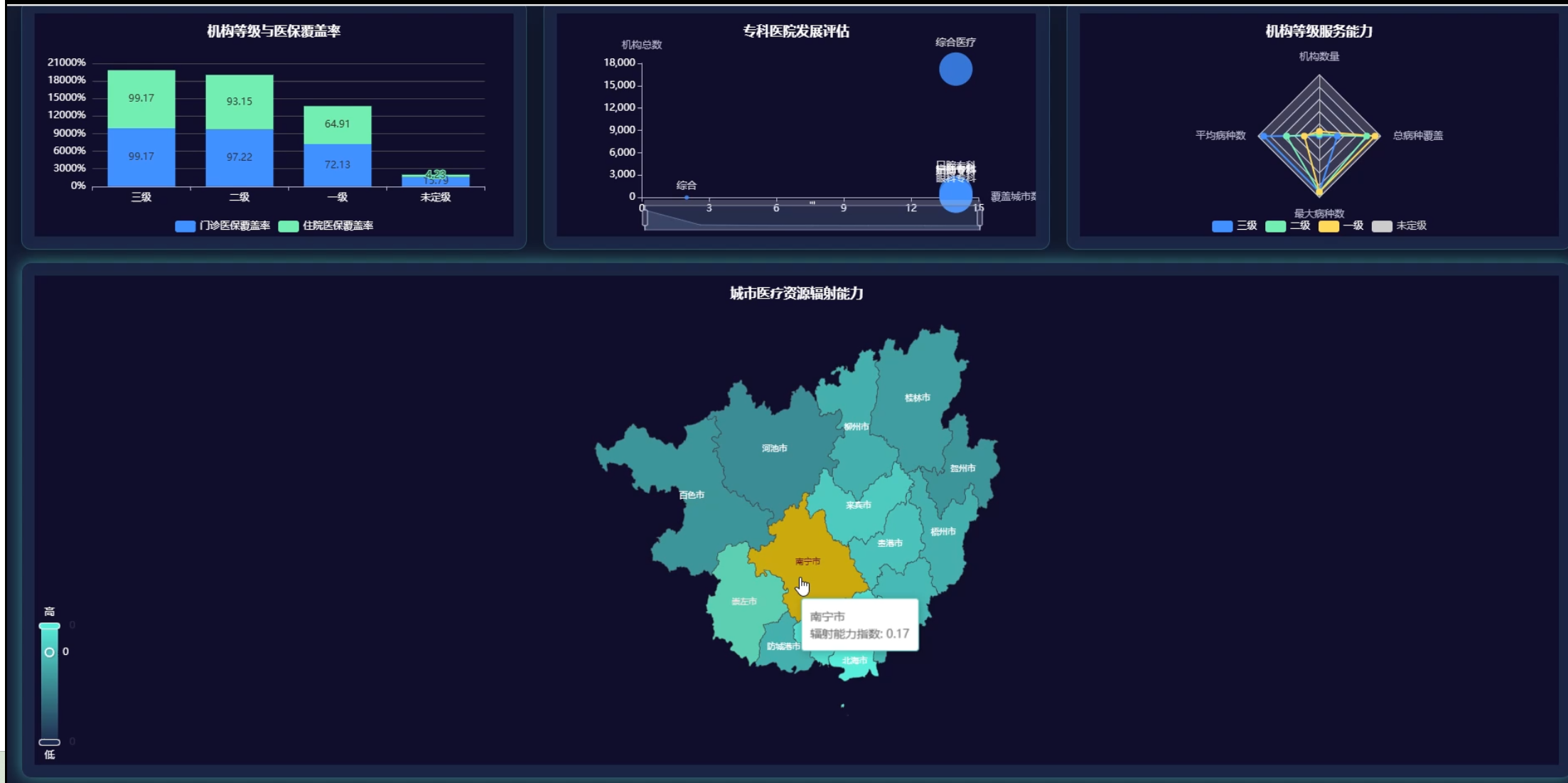
☀️大屏☀️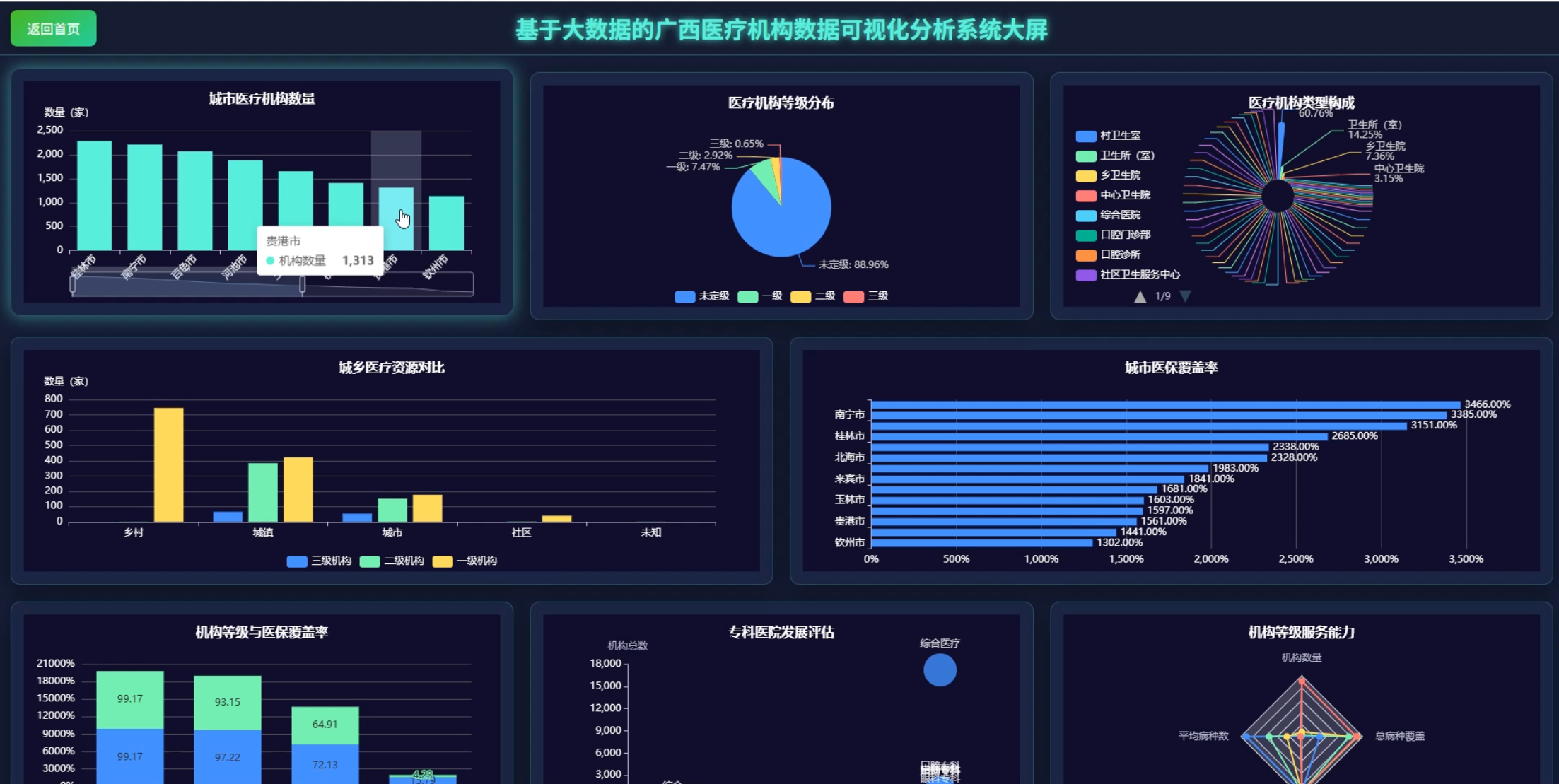
☀️XX数据管理☀️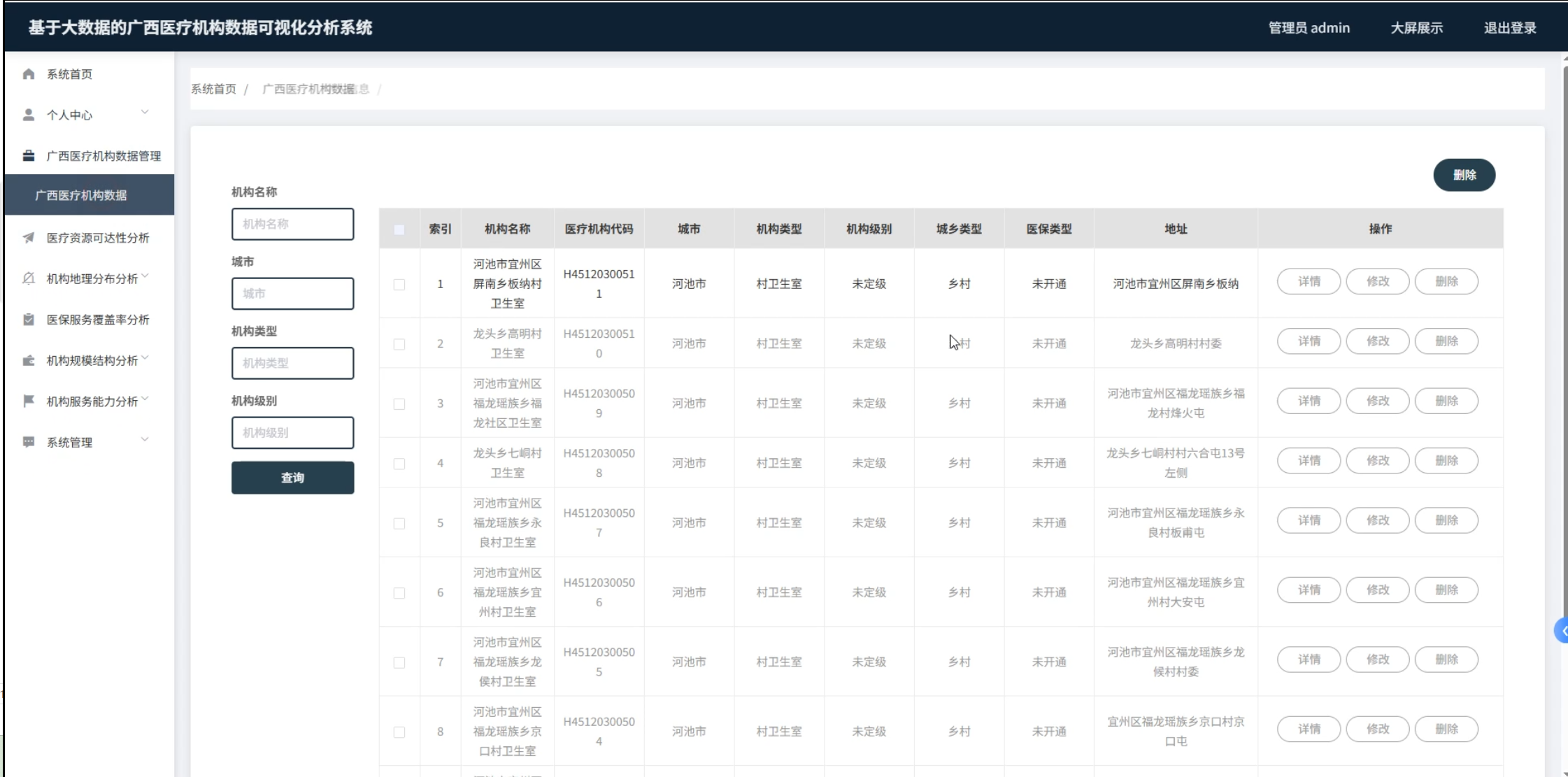
7、代码展示
1.数据清洗【代码如下(示例):】
import pandas as pd
import numpy as np
# 读取原始数据
data = pd.read_csv('hospital_data.csv')
# 查看数据的前几行,了解数据结构
print(data.head())
# 处理缺失值
# 假设有一个'address'列缺失数据,用'unknown'填充
data['address'].fillna('unknown', inplace=True)
# 填充数值型缺失值(如'bed_count'列)用该列的均值填充
data['bed_count'].fillna(data['bed_count'].mean(), inplace=True)
# 去除重复值
data.drop_duplicates(inplace=True)
# 处理异常值,假设'bed_count'列的异常值是小于0的
data = data[data['bed_count'] >= 0]
# 标准化列名,移除列名中的空格或特殊字符
data.columns = data.columns.str.strip().str.replace(' ', '_')
# 检查数据类型,确保每列的数据类型正确
print(data.dtypes)
# 转换'year_established'列为整数类型
data['year_established'] = pd.to_numeric(data['year_established'], errors='coerce')
# 处理时间格式,假设有一个'foundation_date'列
data['foundation_date'] = pd.to_datetime(data['foundation_date'], errors='coerce')
# 进行数据检查,查看是否还有缺失值
missing_values = data.isnull().sum()
print(f"Missing values:\n{missing_values}")
# 保存清洗后的数据到新文件
data.to_csv('cleaned_hospital_data.csv', index=False)
2.大数据处理【代码如下( 示例):】
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, count, max, min
# 初始化Spark会话
spark = SparkSession.builder \
.appName("Hospital Data Analysis") \
.getOrCreate()
# 读取大数据文件(假设为CSV格式)
df = spark.read.csv("hospital_data_large.csv", header=True, inferSchema=True)
# 查看数据的前几行
df.show(5)
# 过滤掉床位数小于0的记录
df_filtered = df.filter(df['bed_count'] >= 0)
# 计算各个医院的平均床位数、最大床位数和最小床位数
bed_stats = df_filtered.groupBy('hospital_name') \
.agg(
avg('bed_count').alias('avg_bed_count'),
max('bed_count').alias('max_bed_count'),
min('bed_count').alias('min_bed_count')
)
bed_stats.show(10)
# 计算不同地区(例如'city'列)医院的平均床位数
city_bed_stats = df_filtered.groupBy('city').agg(
avg('bed_count').alias('avg_bed_count')
)
city_bed_stats.show()
# 计算医保覆盖率:假设有一列'medical_coverage',为0代表未覆盖,1代表已覆盖
coverage_stats = df_filtered.groupBy('city') \
.agg(
count(when(col('medical_coverage') == 1, 1)).alias('covered_count'),
count(when(col('medical_coverage') == 0, 1)).alias('uncovered_count')
)
# 计算每个城市的医保覆盖比例
coverage_stats = coverage_stats.withColumn(
'coverage_ratio', col('covered_count') / (col('covered_count') + col('uncovered_count'))
)
coverage_stats.show()
# 保存分析结果到文件
bed_stats.write.csv('bed_stats_output.csv', header=True)
city_bed_stats.write.csv('city_bed_stats_output.csv', header=True)
coverage_stats.write.csv('coverage_stats_output.csv', header=True)
# 关闭Spark会话
spark.stop()
8、结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 42
42 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)