容器大王Docker——玩转docker(下)
六 Docker网络
docker的镜像是令人称道的地方,但网络功能还是相对薄弱的部分
6.1 Docker三种自带网络
#查看docker自动创建的3种网络
[root@docker-node2 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
e8be5527bb0f bridge bridge local
6bb4e020dfca host host local
23942a02987a none null local
6.1.1 bridge
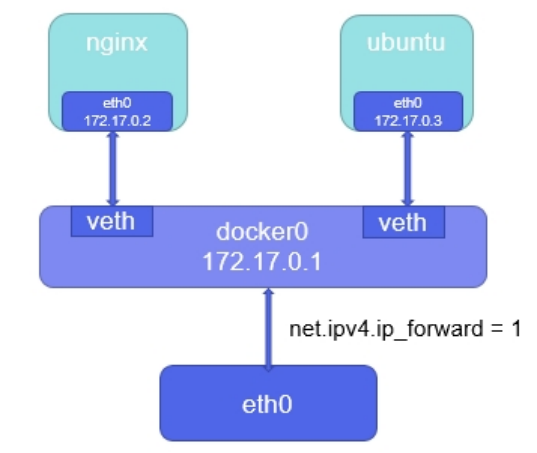
-
docker安装时会创建一个名为 docker0 的Linux bridge,新建的容器会自动桥接到这个接口
-
bridge通信原理是创建容器时增加一个veth网卡,容器通过veth网卡桥接到docker0上,docker0通过路由功能net.ipv4.ip_forward=1连接到eth0访问外网
-
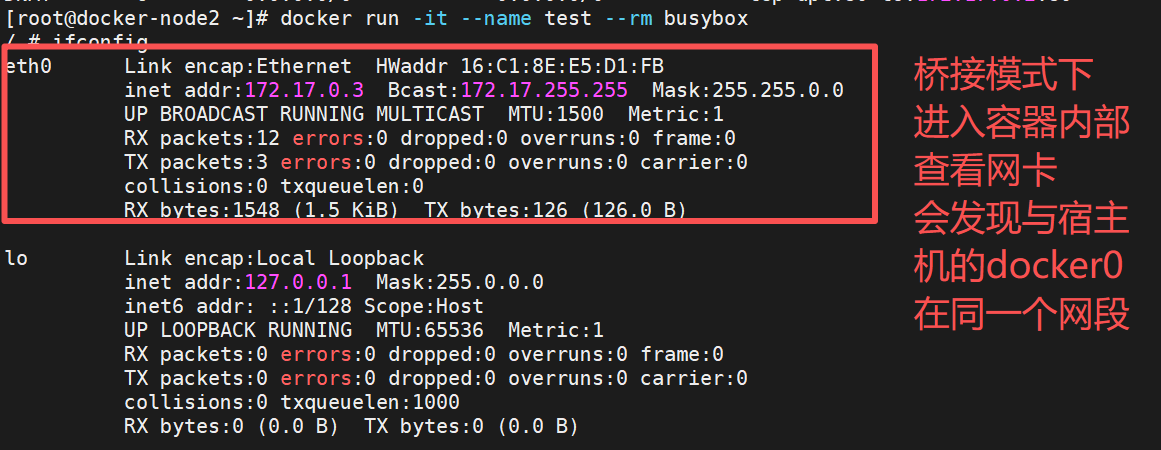
bridge模式下容器没有一个公有ip,只有宿主机可以直接访问,外部主机是不可见的。
-
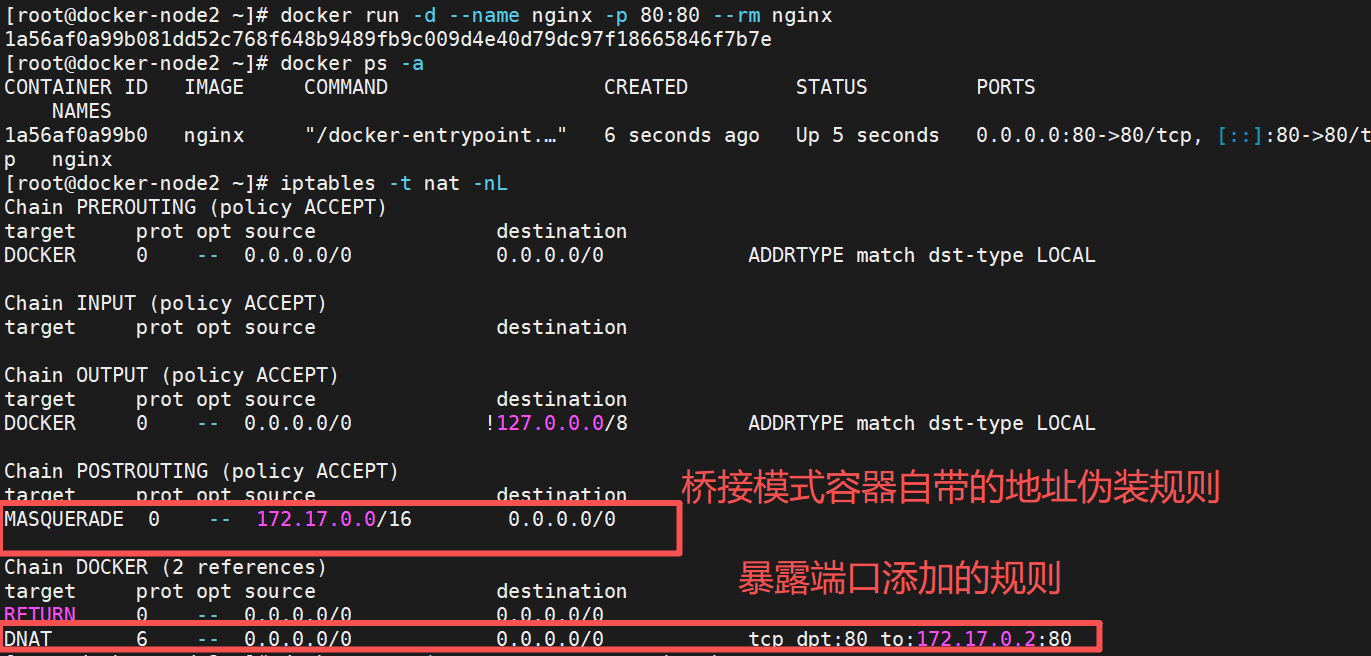
容器通过宿主机的NAT规则后可以访问外网,地址伪装,外网想要访问容器的服务就要创建容器时暴露端口进行端口映射
实验验证
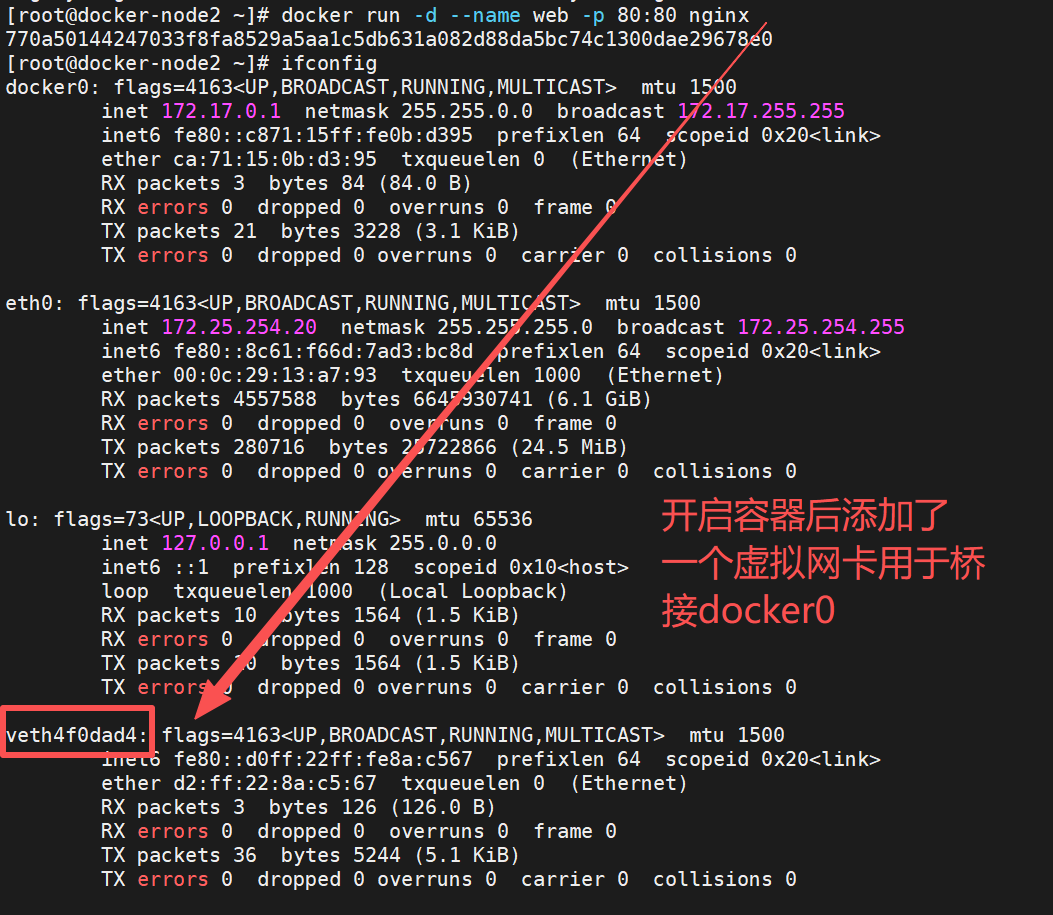
拓展工具brctl
brctl show 是 Linux 系统中用于管理和查看 Linux 桥接(bridge)网络设备的命令,通常需要安装 bridge-utils 工具包才能使用。它主要用于查看当前系统中的桥接设备、关联的网络接口以及相关信息。
dnf install bridge-utils

与 Docker 的关联
在 Docker 中,当使用 bridge 网络模式时,Docker 会自动创建桥接设备(如默认的 docker0 或自定义网络的 br-xxx),并通过 veth 虚拟接口将容器连接到桥接上。使用 brctl show 可以直观地看到这些桥接与容器接口的关联关系,帮助排查容器网络连接问题。
6.1.2 host
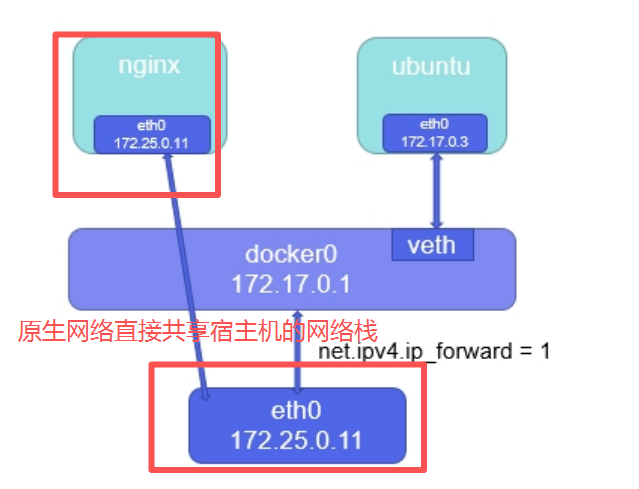
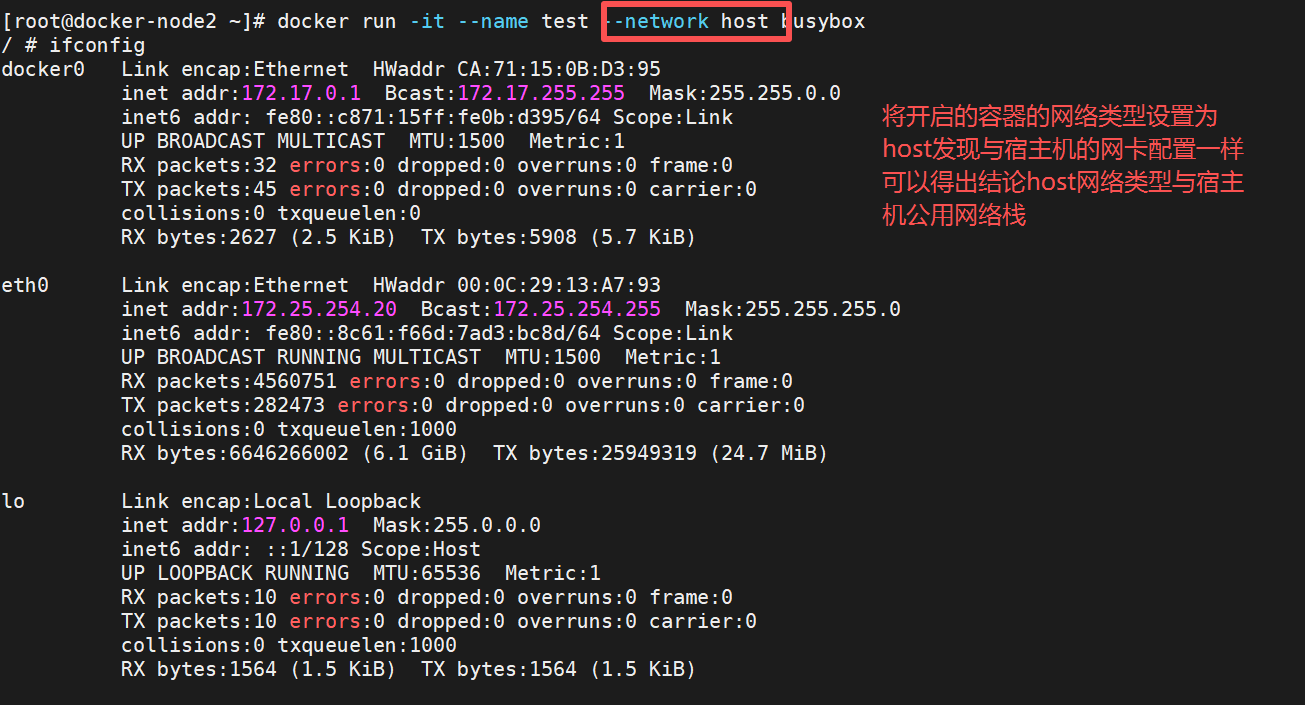
- host网络模式需要在容器创建时指定 --network=host
- host模式可以让容器共享宿主机网络栈,这样的好处是外部主机与容器直接通信,但是容器的网络缺少 隔离性
[!NOTE]
如果公用一个网络,那么所有的网络资源都是公用的,比如启动了nginx容器那么真实主机的80端口被占用,在启动第二个nginx容器就会失败
6.1.3 none
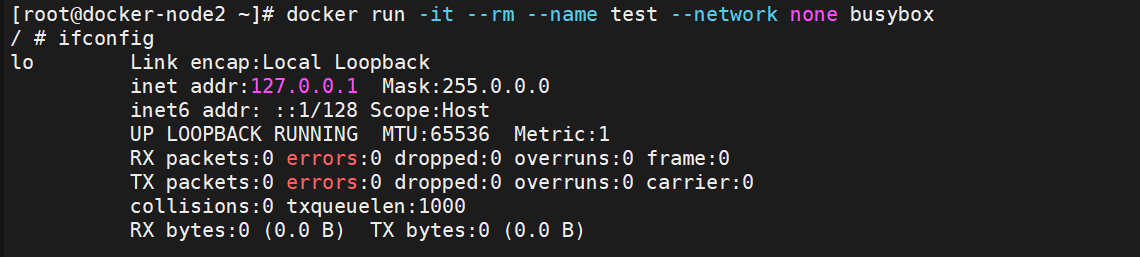
- none网络模式需要在容器创建时指定 --network=none
- 推荐使用情况为个别容器存放重要数据只允许在容器内互相访问
6.2 Docker自定义网络
自定义网络模式,docker提供了三种自定义网络驱动:
- bridge
- overlay
- macvlan
bridge驱动类似默认的bridge网络模式,但增加了一些新的功能,
overlay和macvlan是用于创建跨主机网络
建议使用自定义的网络来控制哪些容器可以相互通信,还可以自动DNS解析容器名称到IP地址。
6.2.1 自定义bridge
在建立自定以网络时,默认使用桥接模式
[root@docker ~]# docker network create my_net1
f2aae5ce8ce43e8d1ca80c2324d38483c2512d9fb17b6ba60d05561d6093f4c4
[root@docker ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
2a93d6859680 bridge bridge local
4d81ddd9ed10 host host local
f2aae5ce8ce4 my_net1 bridge local
8c8c95f16b68 none null local
桥接默认是单调递增,与原生桥接模式几乎一样只添加了新的功能
桥接也支持自定义子网和网关
[root@docker ~]# docker network create my_net2 --subnet 192.168.0.0/24 --gateway 192.168.0.100
7e77cd2e44c64ff3121a1f1e0395849453f8d524d24b915672da265615e0e4f9
[root@docker ~]# docker network inspect my_net2
[
{
"Name": "my_net2",
"Id": "7e77cd2e44c64ff3121a1f1e0395849453f8d524d24b915672da265615e0e4f9",
"Created": "2024-08-17T17:05:19.167808342+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "192.168.0.0/24",
"Gateway": "192.168.0.100"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {},
"Options": {},
"Labels": {}
}
]
6.2.2 为什么要自定义桥接
多容器之间如何互访?通过ip可以,但是有什么问题?
[root@docker ~]# docker run -d --name web1 nginx
d5da7eaa913fa6cdd2aa9a50561042084eca078c114424cb118c57eeac473424
[root@docker ~]# docker run -d --name web2 nginx
0457a156b02256915d4b42f6cc52ea71b18cf9074ce550c886f206fef60dfae5
[root@docker ~]# docker inspect web1
"Networks": {
"bridge": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"MacAddress": "02:42:ac:11:00:03",
"DriverOpts": null,
"NetworkID": "2a93d6859680b45eae97e5f6232c3b8e070b1ec3d01852b147d2e1385034bce5",
"EndpointID": "4d54b12aeb2d857a6e025ee220741cbb3ef1022848d58057b2aab544bd3a4685",
"Gateway": "172.17.0.1",
"IPAddress": "172.17.0.2", #注意ip信息
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"DNSNames": null
[root@docker ~]# docker inspect web1
"Networks": {
"bridge": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"MacAddress": "02:42:ac:11:00:03",
"DriverOpts": null,
"NetworkID": "2a93d6859680b45eae97e5f6232c3b8e070b1ec3d01852b147d2e1385034bce5",
"EndpointID": "4d54b12aeb2d857a6e025ee220741cbb3ef1022848d58057b2aab544bd3a4685",
"Gateway": "172.17.0.1",
"IPAddress": "172.17.0.3", #注意ip信息
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"DNSNames": null
#关闭容器后重启容器,启动顺序调换
[root@docker ~]# docker stop web1 web2
web1
web2
[root@docker ~]# docker start web2
web2
[root@docker ~]# docker start web1
web1
#我们会发容器ip颠倒
docker引擎在分配ip时时根据容器启动顺序分配到,谁先启动谁用,是动态变更的
多容器互访用ip很显然不是很靠谱,那么多容器访问一般使用容器的名字访问更加稳定
docker原生网络是不支持dns解析的,自定义网络中内嵌了dns
[root@docker ~]# docker run -d --network my_net1 --name web nginx
d9ed01850f7aae35eb1ca3e2c73ff2f83d13c255d4f68416a39949ebb8ec699f
[root@docker ~]# docker run -it --network my_net1 --name test busybox
/ # ping web
PING web (172.18.0.2): 56 data bytes
64 bytes from 172.18.0.2: seq=0 ttl=64 time=0.197 ms
64 bytes from 172.18.0.2: seq=1 ttl=64 time=0.096 ms
64 bytes from 172.18.0.2: seq=2 ttl=64 time=0.087 ms
注意:不同的自定义网络是不能通讯的
[!NOTE]
在rhel7中使用的是iptables进行网络隔离,而在rhel9中使用nftpables,所以在部署docker时把火墙管理方式改为了iptables
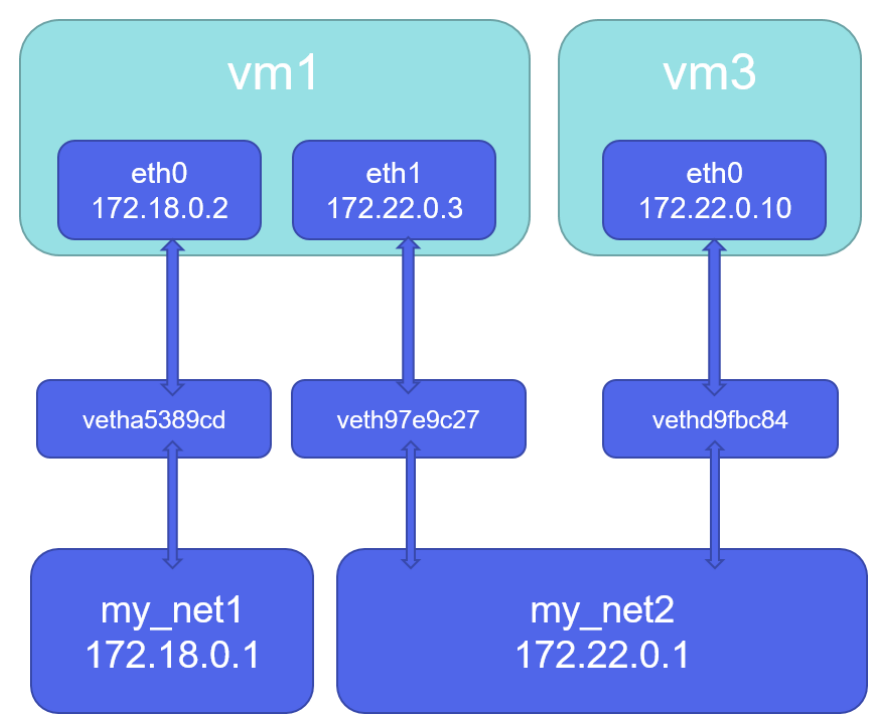
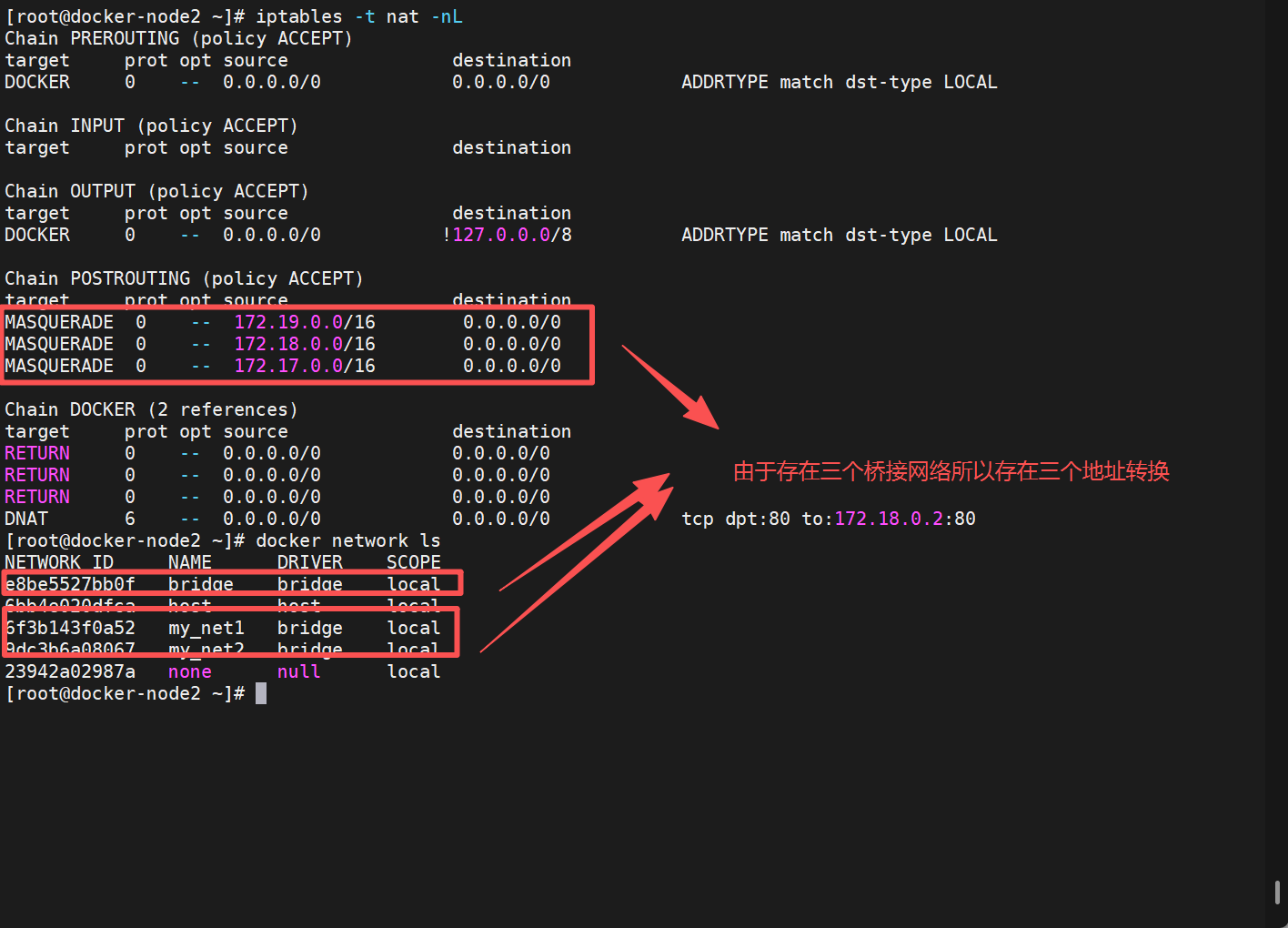
6.2.3 如何让不同的自定义网络互通?
[root@docker-node2 ~]# docker network create my_net1 -d brdige #-d 指定自定义网络类型
[root@docker-node2 ~]# docker network create my_net2 #默认是自定义bridge
[root@docker-node2 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
e8be5527bb0f bridge bridge local
6bb4e020dfca host host local
6f3b143f0a52 my_net1 bridge local
9dc3b6a08067 my_net2 bridge local
23942a02987a none null local
[root@docker-node2 ~]# docker run -d --name web --network my_net1 nginx
[root@docker-node2 ~]# docker run -it --name test --network my_net2 busybox
/ # ping 172.18.0.2
PING 172.18.0.2 (172.18.0.2): 56 data bytes #由于是不同自定义网络不互通
把test加入到my_net1网卡中
[root@docker-node2 ~]# docker network connect my_net1 test
[root@docker-node2 ~]# docker exec -it test sh
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 0E:85:B1:6F:55:74
inet addr:172.19.0.2 Bcast:172.19.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:43 errors:0 dropped:0 overruns:0 frame:0
TX packets:6 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:5706 (5.5 KiB) TX bytes:364 (364.0 B)
eth1 Link encap:Ethernet HWaddr 76:D1:B4:94:AE:BF
inet addr:172.18.0.3 Bcast:172.18.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:24 errors:0 dropped:0 overruns:0 frame:0
TX packets:3 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:2562 (2.5 KiB) TX bytes:126 (126.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:4 errors:0 dropped:0 overruns:0 frame:0
TX packets:4 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:346 (346.0 B) TX bytes:346 (346.0 B)
#通过把容器添加到另一个网卡中,实现双网卡来进行不同自定义网络的互通
6.2.4 joined容器网络
Joined容器一种较为特别的网络模式,在容器创建时使用–network=container:vm1指定。(vm1指定 的是运行的容器名)
处于这个模式下的 Docker 容器会共享一个网络栈,这样两个容器之间可以使用localhost高效快速通 信。
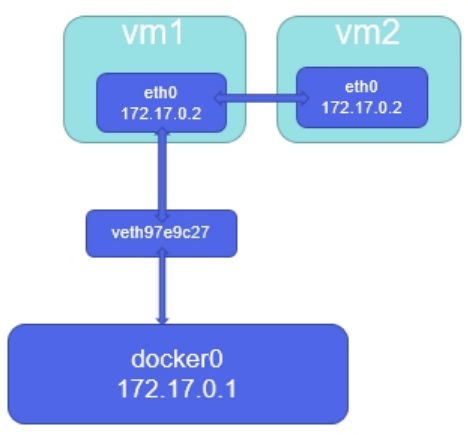
[root@docker-node2 ~]# docker run -it --rm --network container:web busybox
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 6E:42:1E:EC:88:A0
inet addr:172.18.0.2 Bcast:172.18.255.255 Mask:255.255.0.0 #与web共用同一个网络栈
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:21 errors:0 dropped:0 overruns:0 frame:0
TX packets:3 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:2436 (2.3 KiB) TX bytes:126 (126.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # [root@docker-node2 ~]# docker run -it --rm --network container:web centos:7
[root@e4d8fc99e4cc /]# curl localhost #由于与web共用同一个网络栈所以访问的是web部署的nginx
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
[root@e4d8fc99e4cc /]#
6.2.5 joined网络示例演示
实验目的:利用容器部署phpmyadmin管理mysql
[root@docker-node2 ~]# docker run -d --name mysqladmin --network my_net1 \
> -e PMA_ARBITRARY=1 \ #指定服务器栏
> -p 80:80 phpmyadmin:latest
[root@docker-node2 ~]# docker run -d --name mysql5.7 \
> -e MYSQL_ROOT_PASSWORD='yyy' \ #设置root密码
> --network container:mysqladmin \ #joined与mysqladmin的网络
> mysql:5.7
访问宿主机
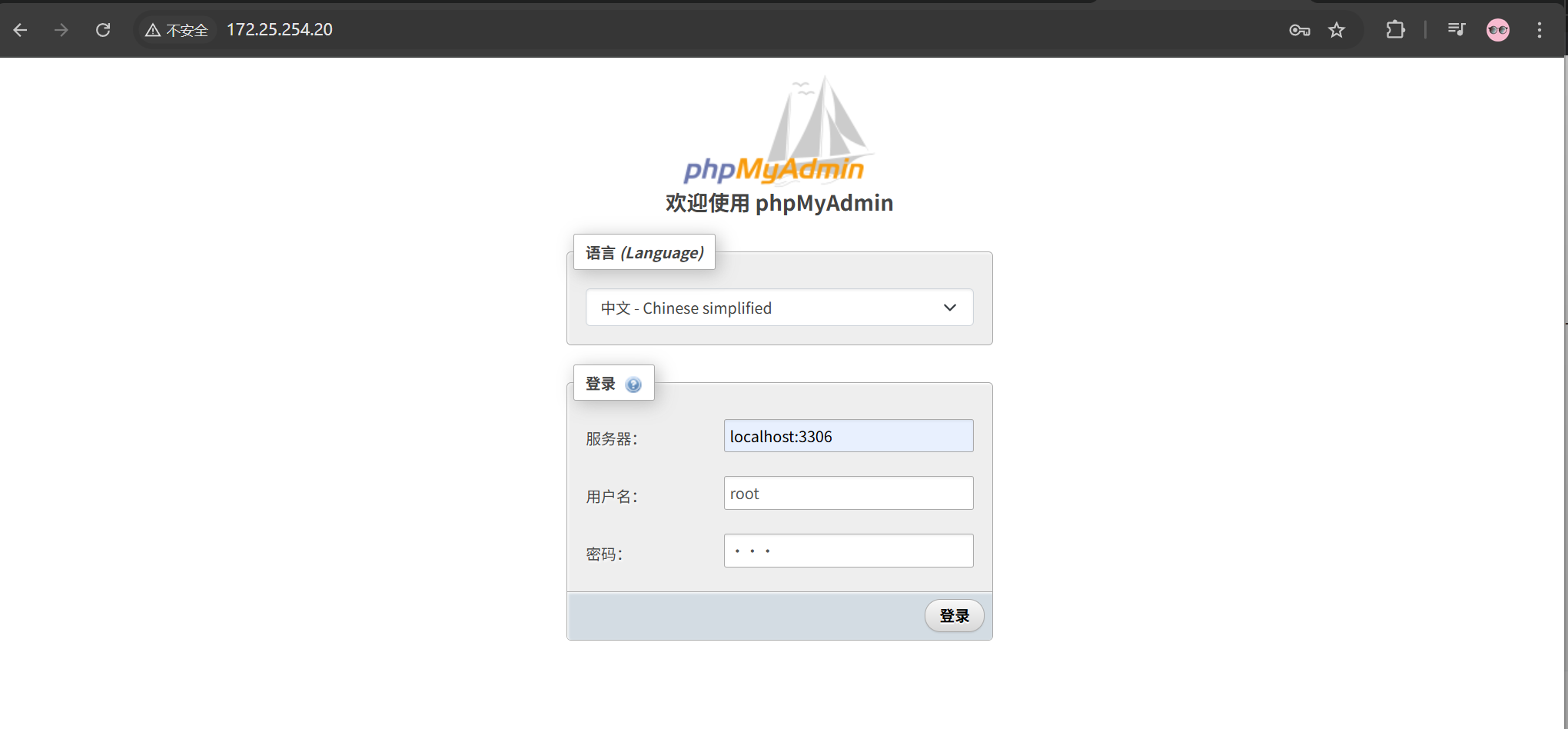
[!NOTE]
开启的phpmyadmin容器中是没有数据库的
这里填写的localhost:3306是因为mysql容器和phpmyadmin容器公用一个网络栈
6.3 容器内外网的访问
6.3.1 容器访问外网
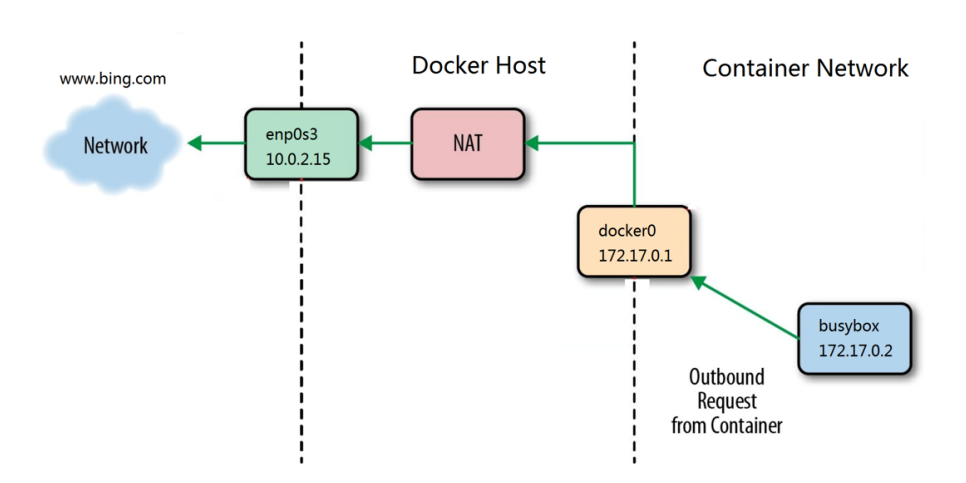
- 在rhel7中,docker访问外网是通过iptables添加地址伪装策略来完成容器访问外网
- 在rhel7之后的版本中通过nftables添加地址伪装来访问外网,可以在安装docker后把管理方式改为iptables
容器访问外网的原理:容器通过桥接网络的虚拟出来的veh网卡桥接到docker0,docker0通过路由功能ip_ipv4_forward=1转到eth0上eth0通过iptables策略的地址伪装来访问外网
6.3.2 外网访问容器
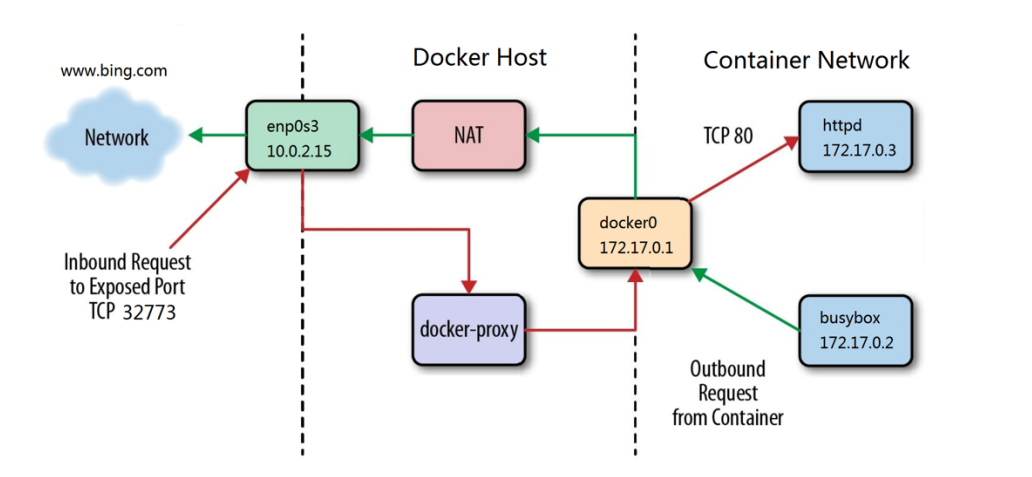
外网访问容器有两种方式:
- 端口映射,在创建容器时通过-p参数来暴露端口
- docker-proxy对数据包进行内转
通过端口映射内转
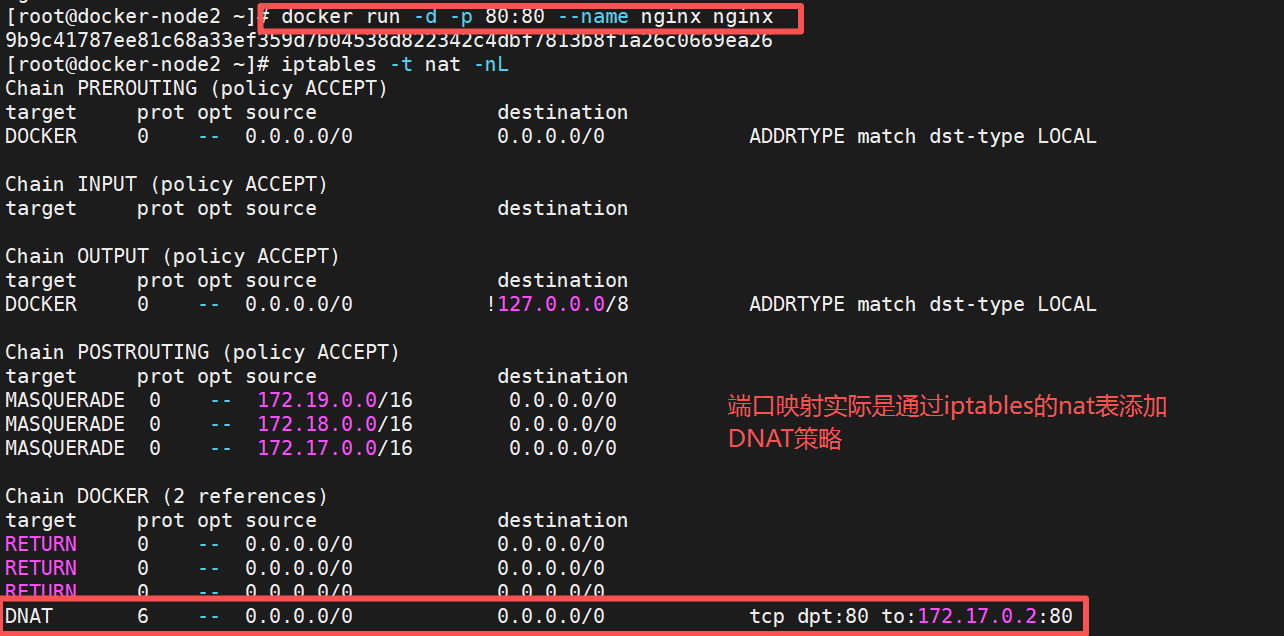
通过docker-proxy内转

[!NOTE]
docker-proxy和dnat在容器建立端口映射后都会开启,哪个传输速率高走那个
6.4 docker跨主机网络
在生产环境中,我们的容器不可能都在同一个系统中,所以需要容器具备跨主机通信的能力
- 跨主机网络解决方案
- docker原生的overlay和macvlan
- 第三方的flannel、weave、calico
- 众多网络方案是如何与docker集成在一起的
- libnetwork docker容器网络库
- CNM (Container Network Model)这个模型对容器网络进行了抽象
6.4.1 CNM(Container Network Model)
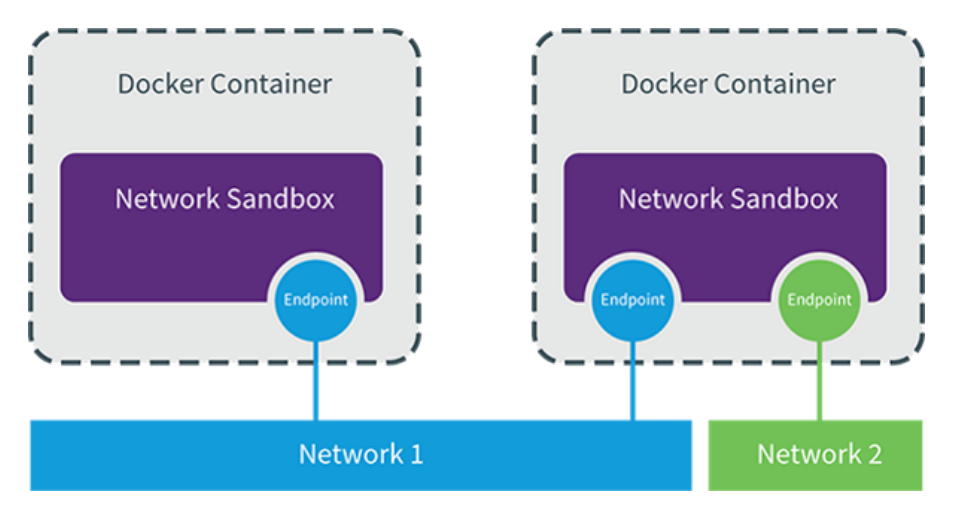
CNM分三类组件
Sandbox:容器网络栈,包含容器接口、dns、路由表。(namespace)
Endpoint:作用是将sandbox接入network (veth pair)
Network:包含一组endpoint,同一network的endpoint可以通信
6.4.2 macvlan网络方式实现跨主机通信
macvlan网络方式
- Linux kernel提供的一种网卡虚拟化技术。
- 无需Linux bridge,直接使用物理接口,性能极好
- 容器的接口直接与主机网卡连接,无需NAT或端口映射。
- macvlan会独占主机网卡,但可以使用vlan子接口实现多macvlan网络
- vlan可以将物理二层网络划分为4094个逻辑网络,彼此隔离,vlan id取值为1~4094
macvlan网络间的隔离和连通
- macvlan网络在二层上是隔离的,所以不同macvlan网络的容器是不能通信的
- 可以在三层上通过网关将macvlan网络连通起来
- docker本身不做任何限制,像传统vlan网络那样管理即可
实现方法如下:
1.在两台docker主机上各添加一块网卡(要为vmware的仅主机),打开网卡混杂模式:
[root@docker ~]# ip link set eth1 promisc on
[root@docker ~]# ip link set up eth1
[root@docker ~]# ifconfig eth1
eth1: flags=4419<UP,BROADCAST,RUNNING,PROMISC,MULTICAST> mtu 1500
ether 00:0c:29:ec:fc:dd txqueuelen 1000 (Ethernet)
RX packets 83 bytes 8696 (8.4 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[!NOTE]
eth1这款网卡在vmware中要设定为仅主机模式
为了取消虚拟的误差
2.添加macvlan网路
[root@docker ~]# docker network create \
-d macvlan \
--subnet 1.1.1.0/24 \
--gateway 1.1.1.1 \
-o parent=eth1 macvlan1
3.测试
#在docker-node1中
[root@docker ~]# docker run -it --name busybox --network macvlan1 --ip 1.1.1.100 --rm busybox
/ # ping 1.1.1.200
[root@docker-node2 ~]# docker run -it --name busybox --network macvlan1 --ip 1.1.1.200 --rm busybox
/ #
七 Docker数据卷管理及优化
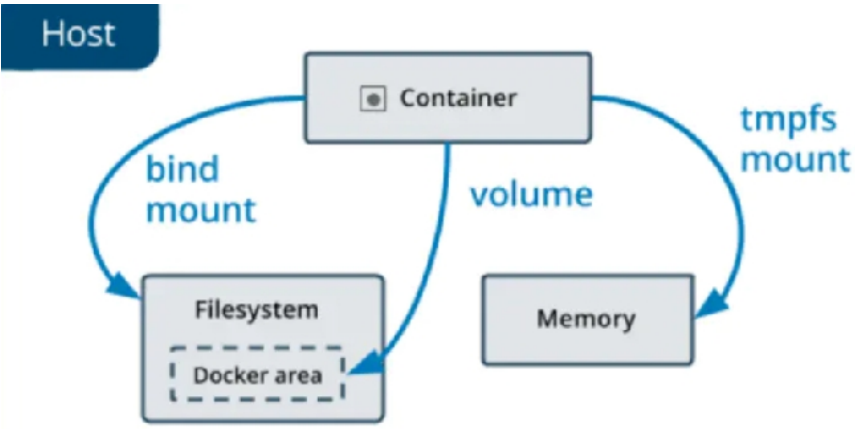
Docker 数据卷是一个可供容器使用的特殊目录,它绕过了容器的文件系统,直接将数据存储在宿主机上。
这样可以实现以下几个重要的目的:
- 数据持久化:即使容器被删除或重新创建,数据卷中的数据仍然存在,不会丢失,实现永久化。
- 数据共享:多个容器可以同时挂载同一个数据卷,实现数据的共享和交互。
- 独立于容器生命周期:数据卷的生命周期独立于容器,不受容器的启动、停止和删除的影响。
7.1 为什么要用数据卷
docker分层文件系统
- 性能差
- 生命周期与容器相同
docker数据卷
- mount到主机中,绕开分层文件系统
- 和主机磁盘性能相同,容器删除后依然保留
- 仅限本地磁盘,不能随容器迁移
综合以上,使用数据卷会比仅使用docker分层文件系统好
docker提供了两种卷:
- bind mount
- docker managed volume
7.2 bind mount 数据卷
- 是将主机上的目录或文件mount到容器里。
- 使用直观高效,易于理解。
- 使用 -v 选项指定路径,格式 :
- -v选项指定的路径,如果不存在,挂载时会自动创建
实验示例
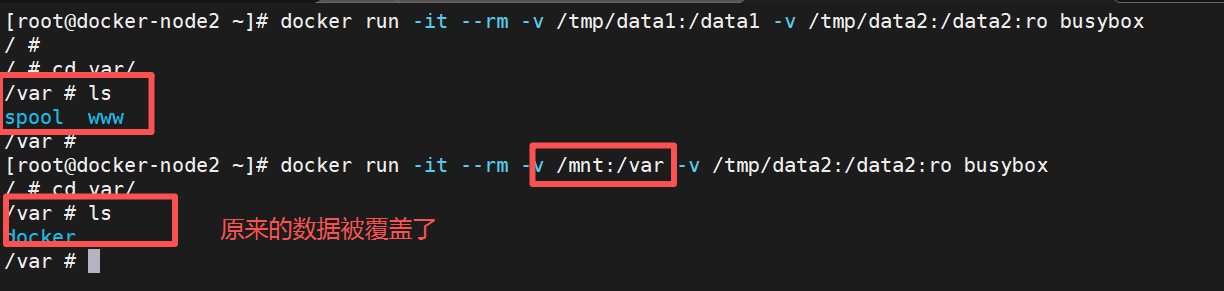
[root@docker ~]# docker run -it --rm \
-v /tmp/data1:/data1 \ #把宿主机的任意目录或主机挂载到容器中
-v /tmp/data1:/data2:ro \
-v /etc/passwd:/data/passwd:ro busybox
/ # tail -n 3 /data/passwd
lee:x:1000:1000:lee:/home/lee:/bin/bash
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
nginx:x:1001:1001::/home/nginx:/sbin/nologin
/ # touch /data1/leefile1
/ # touch /data2/leefile1
touch: /data2/leefile1: Read-only file system
bind mount会覆盖原数据
7.3 docker managed 数据卷
- bind mount必须指定host文件系统路径,限制了移植性
- docker managed volume 不需要指定mount源,docker在构建镜像时添加了volumes参数会自动为容器创建数据卷目录,也可以使用docker volume create xx创建数据卷在启动容器时直接挂载与bind mount方式一样但docker managed统一管理目录
- 默认创建的数据卷目录都在 /var/lib/docker/volumes 中
- 如果挂载时指向容器内已有的目录,原有数据会被复制到volume中
示例
#在构建镜像时添加volumes参数
#在构建镜像时添加volumes参数
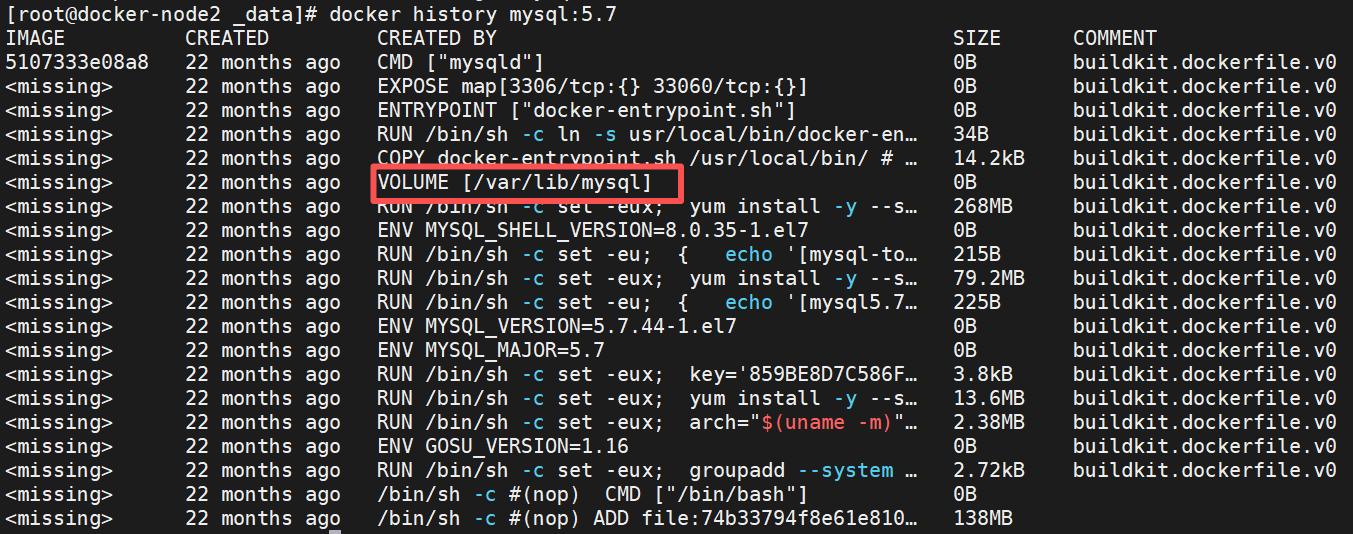
[root@docker-node2 _data]# docker run -d --name mysql -e MYSQL_ROOT_PASSWORD='fjw' mysql:5.7
#启动mysql容器后会自动创建数据卷,因为在构建这个镜像的时候指定了volumes
[root@docker-node2 _data]# docker volume ls
DRIVER VOLUME NAME
local 2803bc9fd74ccb65cf21c8d7e3357ae25291f8f8640428b9ed0414b46916e5a8
[root@docker-node2 _data]# ls
auto.cnf client-cert.pem ibdata1 ibtmp1 performance_schema server-cert.pem
ca-key.pem client-key.pem ib_logfile0 mysql private_key.pem server-key.pem
ca.pem ib_buffer_pool ib_logfile1 mysql.sock public_key.pem sys
[root@docker-node2 _data]# docker exec -it mysql bash
bash-4.2# ls
bin dev entrypoint.sh home lib64 mnt proc run srv tmp var
boot docker-entrypoint-initdb.d etc lib media opt root sbin sys usr
bash-4.2# cd var/lib/mysql
bash-4.2# ls
auto.cnf client-cert.pem ib_logfile0 ibtmp1 performance_schema server-cert.pem
ca-key.pem client-key.pem ib_logfile1 mysql private_key.pem server-key.pem
ca.pem ib_buffer_pool ibdata1 mysql.sock public_key.pem sys
#手动建立数据卷
[root@docker-node2 _data]# docker volume create myvol1
[root@docker-node2 _data]# ls -l /var/lib/docker/volumes/leevol1/_data/
查看卷
[root@docker-node2 volumes]# docker volume ls
DRIVER VOLUME NAME
local myvol1
使用建立的数据卷
#新建立的数据卷是没有数据的,在启动容器挂载时会被指向挂载的容器目录给覆盖
[root@docker-node2 volumes]# docker run -d --name web -p 80:80 -v myvol1:/usr/share/nginx/html nginx
36c62ea1898b00306cc53a1f08184cba71204d232d2c95770acec4d8b33ba2d4
[root@docker-node2 volumes]# cd myvol1/
[root@docker-node2 myvol1]# cd _data/
[root@docker-node2 _data]# ls
50x.html index.html #覆盖后的内容时指向的容器目录
[root@docker-node2 _data]# echo myvol1 > index.html #可以在宿主机管理,也可以进入容器管理
[root@docker-node2 _data]# curl 172.25.254.20
myvol1
#清理未使用的docker数据卷
[root@docker-node2 ~]# docker volume prune
#只能清理由镜像自动创建的未使用的数据卷,手动创建的数据卷不能被清理
[root@docker-node2 _data]# docker rm -f web
[[root@docker-node2 ~]# docker volume prune
WARNING! This will remove anonymous local volumes not used by at least one container.
Are you sure you want to continue? [y/N] y
Total reclaimed space: 0B
[root@docker-node2 ~]# docker volume ls
DRIVER VOLUME NAME
local myvol1 #还是存在手动创建的数据卷
#只能使用rm来删除手动创建的数据卷
[root@docker-node2 ~]# docker volume rm myvol1
myvol1
[root@docker-node2 ~]# docker volume ls
DRIVER VOLUME NAME
[!NOTE]
- 在执行
docker volume prune命令之前,请确保你确实不再需要这些数据卷中的数据,因为该操作是不可逆的,一旦删除数据将无法恢复。- 如果有重要的数据存储在数据卷中,建议先进行备份,或者确保数据已经被妥善保存到其他地方。
7.4 两种数据卷的对比
| docker managed | bind mount | |
|---|---|---|
| volume位置 | /var/lib/docker/volumes/… | 可任意指定 |
| 对已有mount point影响 | 容器数据复制到volume覆盖 | 容器数据会被替换为volume |
| 是否支持单个文件 | 不支持,只能时目录 | 支持 |
| 权限控制 | 两者都支持只读 | 两者默认都为读写 |
| 移植性 | 移植性弱,与host path绑定 | 移植性强,无需指定host目录 |
7.5 数据卷容器
数据卷容器(Data Volume Container)是 Docker 中一种特殊的容器,主要用于方便地在多个容器之间共享数据卷。
示例
1.建立数据卷容器
#就是建立一个挂载数据卷的容器来作为模板
[root@docker ~]# docker run -d --name datavol \
-v /tmp/data1:/data1:rw \
-v /tmp/data2:/data2:ro \
-v /etc/resolv.conf:/etc/hosts busybox
2.使用数据卷容器
# --volumes-from datavol 来指定创建容器的挂载模板来创建新的容器
[root@docker ~]# docker run -it --name test --rm --volumes-from datavol busybox
from datavol busybox
/ # ls
bin data1 data2 dev etc home lib lib64 proc root sys tmp usr var
/ # cat /etc/resolv.conf
# Generated by Docker Engine.
# This file can be edited; Docker Engine will not make further changes once it
# has been modified.
nameserver 114.114.114.114
search fjwyyy.org
# Based on host file: '/etc/resolv.conf' (legacy)
# Overrides: []
/ # touch data1/leefile1
/ # touch /data2/leefile1
touch: /data2/leefile1: Read-only file system
/ #
7.6 备份与迁移数据卷
备份数据卷
#`pwd`优先执行pwd获取当前路径再挂载进去
[root@docker-node2 ~]# docker run -it --name backup --volumes-from web -v `pwd`:/backup busybox:latest
/ # ls
backup bin dev etc home lib lib64 proc root sys tmp usr var
/ # tar zcf /backup/nginx.tar.gz etc/nginx/ usr/share/nginx/html/
/ # exit
[root@docker-node2 ~]# ls
anaconda-ks.cfg Desktop Documents Downloads Music nginx.tar.gz Pictures Public Templates Videos
还原数据卷
[root@docker-node2 ~]# docker run -it --name test -v `pwd`:/backup busybox:latest sh -c "tar zxf /backup/nginx.tar.gz;sh"
/ # ls
backup bin dev etc home lib lib64 proc root sys tmp usr var
/ # cd etc/nginx/
/etc/nginx # cd /usr/share/nginx/html/
/usr/share/nginx/html # ls
50x.html index.html
八 Docker的安全优化
8.1 Docker安全性介绍
Docker容器的安全性,很大程度上依赖于Linux系统自身
评估Docker的安全性时,主要考虑以下几个方面:
- Linux内核的命名空间机制提供的容器隔离安全
- Linux控制组机制对容器资源的控制能力安全。
- Linux内核的能力机制所带来的操作权限安全
- Docker程序(特别是服务端)本身的抗攻击性。
- 其他安全增强机制对容器安全性的影响
1 命名空间隔离的安全namespace
- 当docker run启动一个容器时,Docker将在后台为容器创建一个独立的命名空间。命名空间提供了最基础也最直接的隔离。
- 与虚拟机方式相比,通过Linux namespace来实现的隔离不是那么彻底。
- 容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。
- 在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,比如:磁盘等等
以下的都是被命名空间隔离的参数
[root@docker-node2 ~]# docker inspect web | grep Pid
"Pid": 4338,
"PidMode": "",
"PidsLimit": null,
[root@docker-node2 ~]# cd /proc/4338/ns/ #进程的namespace
[root@docker-node2 ns]# ls
cgroup ipc mnt net pid pid_for_children time time_for_children user uts
#被隔离的参数
2 控制组资源控制的安全cgroup
-
当docker run启动一个容器时,Docker将在后台为容器创建一个独立的控制组策略集合。
-
Linux Cgroups提供了很多有用的特性,确保各容器可以公平地分享主机的内存、CPU、磁盘IO等资源。
-
确保当发生在容器内的资源压力不会影响到本地主机系统和其他容器,它在防止拒绝服务攻击(DDoS)方面必不可少
以下的资源和对象不能被namespace化,资源的使用无瓶颈会导致宿主机的内存溢出
需使用cgroup工具对其进行限制
[root@docker-node2 ns]# cd /sys/fs/cgroup/
[root@docker-node2 cgroup]# ls
cgroup.controllers cgroup.threads dev-mqueue.mount misc.capacity system.slice
cgroup.max.depth cpuset.cpus.effective init.scope misc.current user.slice
cgroup.max.descendants cpuset.cpus.isolated io.stat sys-fs-fuse-connections.mount
cgroup.procs cpuset.mems.effective memory.numa_stat sys-kernel-config.mount
cgroup.stat cpu.stat memory.reclaim sys-kernel-debug.mount
cgroup.subtree_control dev-hugepages.mount memory.stat sys-kernel-tracing.mount
[root@docker-node2 cgroup]#
#内存资源默认没有被隔离
[root@docker-node2 ~]# docker run -it --name test --rm busybox:latest
/ # free -m
total used free shared buff/cache available
Mem: 1743 492 582 7 669 1084
Swap: 512 0 512
/ #
[root@docker-node2 ~]# free -m
total used free shared buff/cache available
Mem: 1743 625 617 6 668 1118
Swap: 511 0 511
[root@docker-node2 ~]#
对docker的资源进行限制使用cgroup来进行控制
3 内核能力机制
- 能力机制(Capability)是Linux内核一个强大的特性,可以提供细粒度的权限访问控制。
- 大部分情况下,容器并不需要“真正的”root权限,容器只需要少数的能力即可。
- 默认情况下,Docker采用“白名单”机制,禁用“必需功能”之外的其他权限。
4 Docker服务端防护
- 使用Docker容器的核心是Docker服务端,确保只有可信的用户才能访问到Docker服务。
- 将容器的root用户映射到本地主机上的非root用户,减轻容器和主机之间因权限提升而引起的安全问题。
- 允许Docker 服务端在非root权限下运行,利用安全可靠的子进程来代理执行需要特权权限的操作。这些子进程只允许在特定范围内进行操作。
[root@docker ~]# ls -ld /var/lib/docker/ #默认docker是用root用户控制资源的
drwx--x--- 12 root root 171 8月 20 13:21 /var/lib/docker/
8.2 Docker的资源限制
Linux Cgroups 的全称是 Linux Control Group。
- 是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
- 对进程进行优先级设置、审计,以及将进程挂起和恢复等操作。
Linux Cgroups 给用户暴露出来的操作接口是文件系统
- 它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。
- 执行此命令查看:mount -t cgroup
#在rhel9中默认使用cgroup-v2 但是cgroup-v2中不利于观察docker的资源限制情况,所以推荐使用
cgroup-v1
[root@docker ~]# grubby --update-kernel=/boot/vmlinuz-$(uname -r) \
--args="systemd.unified_cgroup_hierarchy=0 systemd.legacy_systemd_cgroup_controller"
[root@docker ~]# reboot #设置后要重启
#设置后有输出就是开了对应的cgroup,没有就是没开
[root@docker-node2 ~]# mount -t cgroup2
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot)
#重启后查看
[root@docker-node2 ~]# mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/misc type cgroup (rw,nosuid,nodev,noexec,relatime,misc)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
[root@docker-node2 ~]# mount -t cgroup2
#不同cgroup管理的精细程度不同,cgroup2管理的更细致,cgroup更容易看出资源的限制
[root@docker-node2 ~]# cd /sys/fs/cgroup/
[root@docker-node2 cgroup]# ls
blkio cpuacct cpuset freezer memory net_cls net_prio pids systemd
cpu cpu,cpuacct devices hugetlb misc net_cls,net_prio perf_event rdma
[root@docker-node2 ns]# cd /sys/fs/cgroup/
[root@docker-node2 cgroup]# ls
cgroup.controllers cgroup.threads dev-mqueue.mount misc.capacity system.slice
cgroup.max.depth cpuset.cpus.effective init.scope misc.current user.slice
cgroup.max.descendants cpuset.cpus.isolated io.stat sys-fs-fuse-connections.mount
cgroup.procs cpuset.mems.effective memory.numa_stat sys-kernel-config.mount
cgroup.stat cpu.stat memory.reclaim sys-kernel-debug.mount
cgroup.subtree_control dev-hugepages.mount memory.stat sys-kernel-tracing.mount
8.2.1 限制cpu使用
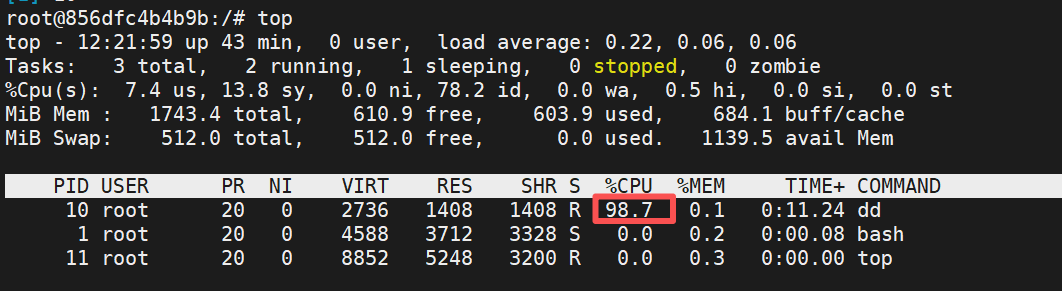
如果不限制cpu,会出现一个容器的cpu爆满使得宿主机宕机
[root@docker-node2 ~]# docker run -it --rm --name test ubuntu:latest
root@856dfc4b4b9b:/# dd if=/dev/zero of=/dev/null &
#of=/dev/null 把空设备以字符形式输出到垃圾箱上,使其干磨cpu不占用磁盘导致虚拟机宕机
#of=file 不仅耗cpu还占用磁盘
1.限制cpu的使用量
[root@docker-node2 ~]# docker run -it --rm --name test --cpu-period 100000 --cpu-quota 20000 ubuntu:latest
#--cpu-period 100000 设置 CPU 周期的长度,单位为微秒(通常为 100000,即 100 毫秒)时间分片
--cpu-quota 20000 ubuntu #设置容器在一个周期内可以使用的 CPU 时间,单位也是微秒。
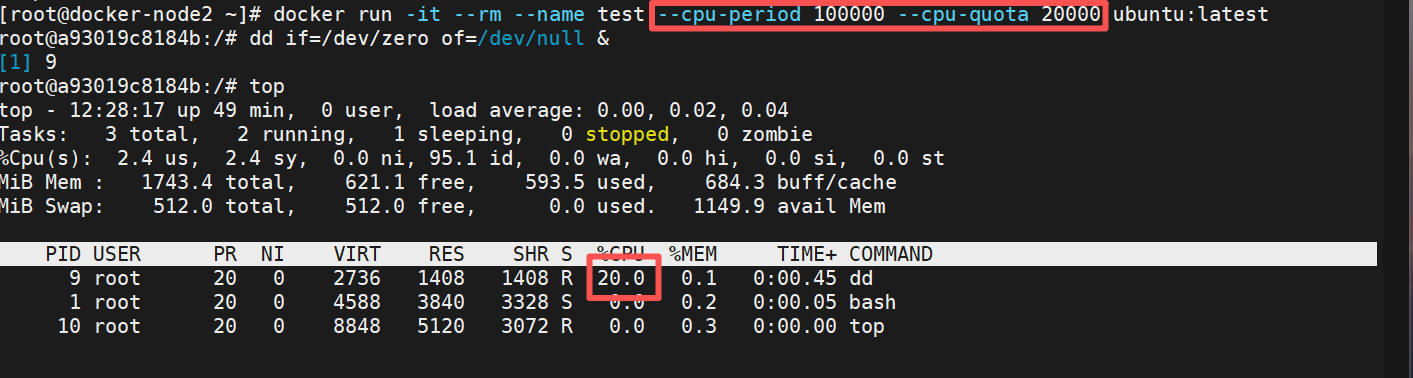
最多只能使用总量的20%
[root@docker-node2 a93019c8184b106fc0042293fa2b1f595f9fce1fbe15c1a1891daea8ad643835]# cat cpu.cfs_quota_us
20000 #可以更改文件的参数来热处理更改cpu的使用量
[root@docker-node2 a93019c8184b106fc0042293fa2b1f595f9fce1fbe15c1a1891daea8ad643835]# pwd
/sys/fs/cgroup/cpu/docker/a93019c8184b106fc0042293fa2b1f595f9fce1fbe15c1a1891daea8ad643835
2.限制cpu的优先级
[root@docker-node2 ~]# cat /proc/cpuinfo
......
processor : 3
vendor_id : GenuineIntel
cpu family : 6
model : 183
model name : 13th Gen Intel(R) Core(TM) i9-13900HX
stepping : 1
microcode : 0x113
cpu MHz : 2419.202
cache size : 36864 KB
physical id : 0
siblings : 4
core id : 3
cpu cores : 4 #cpu核心数为4
apicid : 3
initial apicid : 3
fpu : yes
fpu_exception : yes
cpuid level : 32
#可以关闭cpu的核心,当cpu都不空闲下才会出现争抢的情况,为了实验效果我们可以关闭只剩一个cpu核心
[root@docker-node2 ~]# cd /sys/devices/system/cpu/
[root@docker-node2 cpu]# ls #有四个cpu从cpu0开始到cpu3
cpu0 cpu2 cpufreq hotplug kernel_max nohz_full online power smt vulnerabilities
cpu1 cpu3 cpuidle isolated modalias offline possible present uevent
[root@docker-node2 ~]# echo 0 > /sys/devices/system/cpu/cpu1/online
[root@docker-node2 ~]# echo 0 > /sys/devices/system/cpu/cpu2/online
[root@docker-node2 ~]# echo 0 > /sys/devices/system/cpu/cpu3/online
#把参数改为0就是下线cpu
#开启容器通过优先级限制资源
#设定cpu优先级,最大为1024,值越大优先级越高
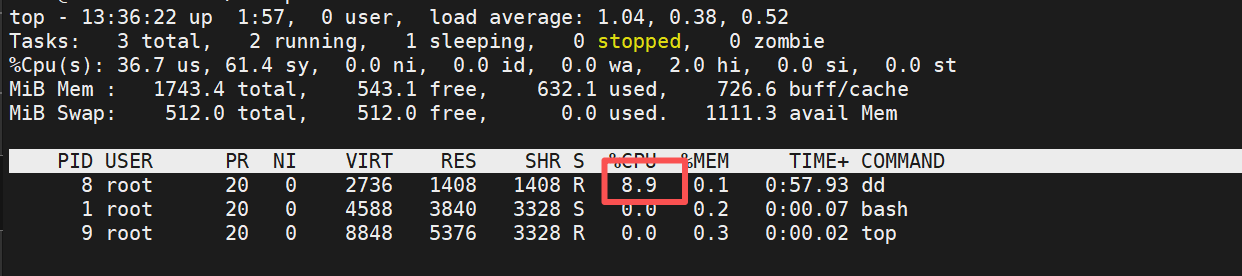
[root@docker-node2 ~]# docker run -it --rm --cpu-shares 100 --name test1 ubuntu:latest
root@4c9c8107b166:/# dd if=/dev/zero of=/dev/null &
[1] 10
root@dc066aa1a1f0:/# top
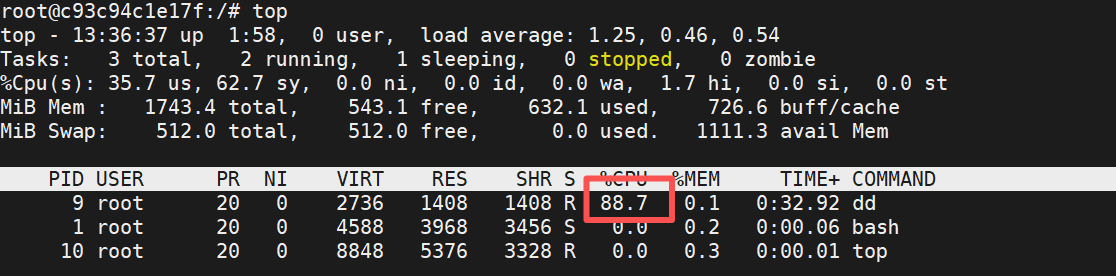
#开启另外一个容器不限制cpu的优先级
oot@docker-node2 cpu]# docker run -it --rm --name test2 ubuntu:latest
root@c93c94c1e17f:/# dd if=/dev/zero of=/dev/null &
#对比可以看出cpu使用量是9:1

8.2.2 限制内存使用
#开启容器并限制容器使用内存大小
[root@docker system.slice]# docker run -d --name test --memory 200M --memory-swap 200M nginx
#查看容器内存使用限制
[root@docker ~]# cd /sys/fs/cgroup/memory/docker/d09100472de41824bf0省略部分id96b977369dad843740a1e8e599f430/
[root@docker d091004723d4de41824f6b38a7be9b77369dad843740a1e8e599f430]# cat memory.limit_in_bytes
209715200
#测试容器内存限制,在容器中我们测试内存限制效果不是很明显,可以利用工具模拟容器在内存中写入数据
#在系统中/dev/shm这个目录被挂在到内存中
#下载工具
[root@docker-node2 rpm]# dnf install libcgroup-tools-0.41-19.el8.x86_64.rpm libcgroup-0.41-19.el8.x86_64.rpm -y
[root@docker cgroup]# docker run -d --name test --rm --memory 200M --memory-swap 200M nginx f5017485d69b50cf2e294bf6c65fcd5e679002e25bd9b0eaf9149eee2e379eec
[root@docker cgroup]# cgexec -g memory:docker/f5017485d69b50cf2e294bf6c65fcd5e679002e25bd9b0eaf9149eee2e379eec dd if=/dev/zero of=/dev/shm/bigfile bs=1M count=150
记录了150+0 的读入
记录了150+0 的写出
157286400字节(157 MB,150 MiB)已复制,0.0543126 s,2.9 GB/s
[root@docker cgroup]# cgexec -g memory:docker/f5017485d69b50cf2e294bf6c65fcd5e679002e25bd9b0eaf9149eee2e379eec dd if=/dev/zero of=/dev/shm/bigfile bs=1M count=180
记录了180+0 的读入
记录了180+0 的写出
188743680字节(189 MB,180 MiB)已复制,0.0650658 s,2.9 GB/s
[root@docker cgroup]# cgexec -g memory:docker/f5017485d69b50cf2e294bf6c65fcd5e679002e25bd9b0eaf9149eee2e379eec dd if=/dev/zero of=/dev/shm/bigfile bs=1M count=120
记录了120+0 的读入
记录了120+0 的写出
125829120字节(126 MB,120 MiB)已复制,0.044017 s,2.9 GB/s
[root@docker cgroup]# cgexec -g memory:docker/f5017485d69b50cf2e294bf6c65fcd5e679002e25bd9b0eaf9149eee2e379eec dd if=/dev/zero of=/dev/shm/bigfile bs=1M count=200
已杀死
#也可以自建控制器
[root@docker ~]# mkdir -p /sys/fs/cgroup/memory/x1/
[root@docker ~]# ls /sys/fs/cgroup/memory/x1/
cgroup.clone_children memory.kmem.tcp.max_usage_in_bytes memory.oom_control
cgroup.event_control memory.kmem.tcp.usage_in_bytes memory.pressure_level
cgroup.procs memory.kmem.usage_in_bytes memory.soft_limit_in_bytes
memory.failcnt memory.limit_in_bytes memory.stat
memory.force_empty memory.max_usage_in_bytes memory.swappiness
memory.kmem.failcnt memory.memsw.failcnt memory.usage_in_bytes
memory.kmem.limit_in_bytes memory.memsw.limit_in_bytes memory.use_hierarchy
memory.kmem.max_usage_in_bytes memory.memsw.max_usage_in_bytes notify_on_release
memory.kmem.slabinfo memory.memsw.usage_in_bytes tasks
memory.kmem.tcp.failcnt memory.move_charge_at_immigrate
memory.kmem.tcp.limit_in_bytes memory.numa_stat
[root@docker ~]# echo 209715200 > /sys/fs/cgroup/memory/x1/memory.limit_in_bytes #内存可用大小限制
[root@docker ~]# cat /sys/fs/cgroup/memory/x1/tasks #此控制器被那个进程调用
[root@docker ~]# cgexec -g memory:x1 dd if=/dev/zero of=/dev/shm/bigfile bs=1M count=100
记录了100+0 的读入
记录了100+0 的写出
104857600字节(105 MB,100 MiB)已复制,0.0388935 s,2.7 GB/s
[root@docker ~]# free -m
total used free shared buff/cache available
Mem: 3627 1038 1813 109 1131 2589
Swap: 2062 0 2062
[root@docker ~]# cgexec -g memory:x1 dd if=/dev/zero of=/dev/shm/bigfile bs=1M count=300
记录了300+0 的读入
记录了300+0 的写出
314572800字节(315 MB,300 MiB)已复制,0.241256 s,1.3 GB/s
[root@docker ~]# free -m
total used free shared buff/cache available
Mem: 3627 1125 1725 181 1203 2501
Swap: 2062 129 1933 #内存溢出部分被写入swap交换分区
[root@docker ~]# rm -fr /dev/shm/bigfile
[root@docker ~]# echo 209715200 > /sys/fs/cgroup/memory/x1/memory.memsw.limit_in_bytes #内存+swap控制
[root@docker ~]# cgexec -g memory:x1 dd if=/dev/zero of=/dev/shm/bigfile bs=1M count=200
已杀死
[root@docker ~]# cgexec -g memory:x1 dd if=/dev/zero of=/dev/shm/bigfile bs=1M count=199
已杀死
[root@docker ~]# rm -fr /dev/shm/bigfile
[root@docker ~]#
[root@docker ~]# rm -fr /dev/shm/bigfile
[root@docker ~]# cgexec -g memory:x1 dd if=/dev/zero of=/dev/shm/bigfile bs=1M count=180
记录了180+0 的读入
记录了180+0 的写出
188743680字节(189 MB,180 MiB)已复制,0.0660052 s,2.9 GB/s
[root@docker ~]# cgexec -g memory:x1 dd if=/dev/zero of=/dev/shm/bigfile bs=1M count=190
记录了190+0 的读入
记录了190+0 的写出
199229440字节(199 MB,190 MiB)已复制,0.0682285 s,2.9 GB/s
[root@docker ~]# cgexec -g memory:x1 dd if=/dev/zero of=/dev/shm/bigfile bs=1M count=200
已杀死
[!NOTE]
cgexec -g memory:doceker/容器id -g表示使用指定控制器类型
8.2.3 限制磁盘io
现象

解决示例
[root@docker-node2 memory]# docker run -it --rm --name test \
> --device-write-bps \ #指定容器使用磁盘io的速率
> /dev/nvme0n1:30M ubuntu #/dev/nvme0n1是指定系统的磁盘,30M即每秒30M数据
root@a4e9567a666d:/# dd if=/dev/zero of=bigfile #开启容器后会发现速度和设定不匹配,是因为系统的缓存机制
^C592896+0 records in
592895+0 records out
303562240 bytes (304 MB, 289 MiB) copied, 2.91061 s, 104 MB/s
root@a4e9567a666d:/# dd if=/dev/zero of=bigfile bs=1M count=100
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 0.0515779 s, 2.0 GB/s
root@a4e9567a666d:/# dd if=/dev/zero of=bigfile bs=1M count=100 oflag=direct #设定dd命令直接写入磁盘
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 3.33545 s, 31.4 MB/s
8.3 Docker的安全加固
8.3.1 Docker的默认隔离性
在系统中运行容器,我们会发现资源并没有完全隔离开
例如内存,cpu,磁盘io
[root@docker ~]# free -m #系统内存使用情况
total used free shared buff/cache available
Mem: 3627 1128 1714 207 1238 2498
Swap: 2062 0 2062
[root@docker ~]# docker run --rm --memory 200M -it ubuntu
root@e06bdc13b764:/# free -m #容器中内存使用情况
total used free shared buff/cache available
Mem: 3627 1211 1630 207 1239 2415
Swap: 2062
#我们可以使用cgroup来进行资源的限制
#虽然我们限制了容器的内容使用情况,但是查看到的信息依然是系统中内存的使用信息,并没有隔离开
8.3.2 解决Docker的默认隔离性
LXCFS 是一个为 LXC(Linux Containers)容器提供增强文件系统功能的工具。
主要功能
-
资源可见性:
- LXCFS 可以使容器内的进程看到准确的 CPU、内存和磁盘 I/O 等资源使用信息。在没有 LXCFS 时,容器内看到的资源信息可能不准确,这会影响到在容器内运行的应用程序对资源的评估和管理。
-
性能监控:
- 方便对容器内的资源使用情况进行监控和性能分析。通过提供准确的资源信息,管理员和开发人员可以更好地了解容器化应用的性能瓶颈,并进行相应的优化。
安装lxcfs
#在rhel9中lxcfs是被包含在epel源中,我们可以直接下载安装包进行安装
[root@docker ~]# ls lxcfs
lxcfs-5.0.4-1.el9.x86_64.rpm lxc-libs-4.0.12-1.el9.x86_64.rpm lxc-templates-4.0.12-1.el9.x86_64.rpm
[root@docker ~]# dnf install lxcfs/*.rpm
运行lxcfs并解决容器隔离性
[root@docker ~]# lxcfs /var/lib/lxcfs & #后台启动lxfs进程
[root@docker ~]# docker run -it -m 256m --name test \ #-m 设置容器的内存
-v /var/lib/lxcfs/proc/cpuinfo:/proc/cpuinfo:rw \
-v /var/lib/lxcfs/proc/diskstats:/proc/diskstats:rw \
-v /var/lib/lxcfs/proc/meminfo:/proc/meminfo:rw \
-v /var/lib/lxcfs/proc/stat:/proc/stat:rw \
-v /var/lib/lxcfs/proc/swaps:/proc/swaps:rw \
-v /var/lib/lxcfs/proc/uptime:/proc/uptime:rw \
ubuntu
root@69ec0c67ff04:/# free -m
total used free shared buff/cache available
Mem: 256 1 254 0 0 254
Swap: 512 0 512
8.3.3 容器特权
在容器中默认情况下即使我是容器的超级用户也无法修改某些系统设定,比如网络
[root@docker ~]# docker run --rm -it busybox
/ # whoami
root
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
27: eth0@if28: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
/ # ip a a 192.168.0.100/24 dev eth0
ip: RTNETLINK answers: Operation not permitted
这是因为容器使用的很多资源都是和系统真实主机公用的,如果允许容器修改这些重要资源,系统的稳定性会变的非常差
但是由于某些需要求,容器需要控制一些默认控制不了的资源,如何解决此问题,这时我们就要设置容器特权
[root@docker ~]# docker run --rm -it --privileged busybox
/ # id root
uid=0(root) gid=0(root) groups=0(root),10(wheel)
/ # ip a a 192.168.0.100/24 dev eth0
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
29: eth0@if30: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet 192.168.0.100/24 scope global eth0
valid_lft forever preferred_lft forever
/ # fdisk -l
Disk /dev/nvme0n1: 100 GB, 107374182400 bytes, 209715200 sectors
13003 cylinders, 256 heads, 63 sectors/track
Units: sectors of 1 * 512 = 512 bytes
Device Boot StartCHS EndCHS StartLBA EndLBA Sectors Size Id Type
/dev/nvme0n1p1 0,0,2 1023,255,63 1 209715199 209715199 99.9G ee EFI GPT
#如果添加了--privileged 参数开启容器,容器获得权限近乎于宿主机的root用户
8.3.4 容器特权的白名单
–privileged=true 的权限非常大,接近于宿主机的权限,为了防止用户的滥用,需要增加限制,只提供给容器必须的权限。此时Docker 提供了权限白名单的机制,使用–cap-add添加必要的权限
capabilities手册地址:http://man7.org/linux/man-pages/man7/capabilities.7.html
#限制容器对网络有root权限
[root@docker ~]# docker run --rm -it --cap-add NET_ADMIN busybox
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
31: eth0@if32: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
/ # ip a a 192.168.0.100/24 dev eth0 #网络可以设定
/ # fdisk -l #无法管理磁盘
/
九 容器编排工具Docker Compose
9.1 Docker Compose概述

Docker Compose 是一个用于定义和运行多容器 Docker 应用程序的工具。
其是官方的一个开源项目,托管到github上
https://github.com/docker/compose
网址:
主要功能
- 定义服务:
- 使用 YAML 格式的配置文件来定义一组相关的容器服务。每个服务可以指定镜像、端口映射、环境变量、存储卷等参数。
- 例如,可以在配置文件中定义一个 Web 服务和一个数据库服务,以及它们之间的连接关系。
- 一键启动和停止:
- 通过一个简单的命令,可以启动或停止整个应用程序所包含的所有容器。这大大简化了多容器应用的部署和管理过程。
- 例如,使用
docker-compose up命令可以启动配置文件中定义的所有服务,使用docker-compose down命令可以停止并删除这些服务。
- 服务编排:
- 可以定义容器之间的依赖关系,确保服务按照正确的顺序启动和停止。例如,可以指定数据库服务必须在 Web 服务之前启动。
- 支持网络配置,使不同服务的容器可以相互通信。可以定义一个自定义的网络,将所有相关的容器连接到这个网络上。
- 环境变量管理:
- 可以在配置文件中定义环境变量,并在容器启动时传递给容器。这使得在不同环境(如开发、测试和生产环境)中使用不同的配置变得更加容易。
- 例如,可以定义一个数据库连接字符串的环境变量,在不同环境中可以设置不同的值。
工作原理
- 读取配置文件:
- Docker Compose 读取 YAML 配置文件,解析其中定义的服务和参数。
- 创建容器:
- 根据配置文件中的定义,Docker Compose 调用 Docker 引擎创建相应的容器。它会下载所需的镜像(如果本地没有),并设置容器的各种参数。
- 管理容器生命周期:
- Docker Compose 监控容器的状态,并在需要时启动、停止、重启容器。
- 它还可以处理容器的故障恢复,例如自动重启失败的容器。
Docker Compose 中的管理层
- 服务 (service) 一个应用的容器,实际上可以包括若干运行相同镜像的容器实例
- 项目 (project) 由一组关联的应用容器组成的一个完整业务单元,在 docker-compose.yml 文件中定义
- 容器(container)容器是服务的具体实例,每个服务可以有一个或多个容器。容器是基于服务定义的镜像创建的运行实例
[!NOTE]
Docker Compose只能在同一主机开启多个容器,做不到在多个主机之前进行容器的编排;需要用到k8s
9.2 Docker Compose 的常用命令参数
以下是一些 Docker Compose 常用命令:
一、服务管理
-
docker-compose up:-
启动配置文件中定义的所有服务。
-
可以使用
-d参数在后台启动服务。 -
可以使用-f 来指定yml文件
-
例如:
docker-compose up -d。[root@docker test]# docker compose up -d [+] Running 2/2 ✔ Container test-db-1 Started 0.9s ✔ Container test-web-1 Started 0.9s [root@docker ~]# docker compose -f test/docker-compose.yml up -d [+] Running 3/3 ✔ Network test_default Created 0.1s ✔ Container test-web-1 Started 0.9s ✔ Container test-db-1 Started
-
-
docker-compose down:-
停止并删除配置文件中定义的所有服务以及相关的网络和存储卷。
[root@docker test]# docker compose down [+] Running 3/3 ✔ Container test-db-1 Removed 1.7s ✔ Container test-web-1 Removed 0.3s ✔ Network test_default Removed 0.1s
-
-
docker-compose start:-
启动已经存在的服务,但不会创建新的服务。
[root@docker test]# docker compose start [+] Running 2/2 ✔ Container test-db-1 Started ✔ Container test-web-1 Started
-
-
docker-compose stop:-
停止正在运行的服务
[root@docker test]# docker compose stop [+] Stopping 2/2 ✔ Container test-web-1 Stopped 0.4s ✔ Container test-db-1 Stopped 10.3s
-
-
docker-compose restart:-
重启服务。
[root@docker test]# docker compose restart [+] Restarting 2/2 ✔ Container test-web-1 Started ✔ Container test-db-1 Started
-
二、服务状态查看
-
docker-compose ps:-
列出正在运行的服务以及它们的状态,包括容器 ID、名称、端口映射等信息。
[root@docker test]# docker compose ps NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS test-db-1 mysql:5.7 "docker-entrypoint.s…" db 2 minutes ago Up 48 seconds 3306/tcp, 33060/tcp test-web-1 nginx "/docker-entrypoint.…" web 2 minutes ago Up 50 seconds 0.0.0.0:80->80/tcp, :::80->80/tcp
-
-
docker-compose logs:-
查看服务的日志输出。可以指定服务名称来查看特定服务的日志。
[root@docker test]# docker compose logs db
-
三、构建和重新构建服务(了解)
-
docker-compose build:-
构建配置文件中定义的服务的镜像。可以指定服务名称来只构建特定的服务。
[root@docker test]# cat Dockerfile FROM busybox:latest RUN touch /leefile1 [root@docker test]# cat lee.Dockerfile services: test1: image: test1 #生成镜像名称 build: context: /root/test #指定Dockerfile位置 dockerfile: fjw.Dockerfile #指定Dockerfile名字 command: ["/bin/sh","-c","sleep 3000"] restart: always container_name: busybox1 test2: image: test2 build: context: /root/test dockerfile: Dockerfile command: ["/bin/sh","-c","sleep 3000"] restart: always container_name: busybox2 [root@docker test]# docker compose -f test.yml build #构建services中的所有 [root@docker test]# docker compose -f test.yml build test1 #构建services中的test1
-
-
docker-compose up --build:- 启动服务并在启动前重新构建镜像。
[root@docker test]# docker compose -f test.yml up -d #会去仓库拉去镜像 [+] Running 1/1 ! test1 Warning pull access denied for test1, repository does not exist or may require 'docker login': denied: requested acces... [root@docker test]# docker compose -f test.yml up --build #会先构建镜像后启动容器
四、其他操作
-
docker-compose exec:-
在正在运行的服务容器中执行命令。
services: test: image: busybox command: ["/bin/sh","-c","sleep 3000"] restart: always container_name: busybox1 [root@docker test]# docker compose -f test.yml up -d [root@docker test]# docker compose -f test.yml exec test sh / #
-
-
docker-compose pull:- 拉取配置文件中定义的服务所使用的镜像。
[root@docker test]# docker compose -f test.yml pull [+] Pulling 2/2 ✔ test Pulled ✔ ec562eabd705 Pull complete -
docker-compose config:-
验证并查看解析后的 Compose 文件内容
[root@docker test]# docker compose -f test.yml config name: test services: test: command: - /bin/sh - -c - sleep 3000 container_name: busybox1 image: busybox networks: default: null restart: always networks: default: name: test_default [root@docker test]# docker compose -f test.yml config -q
-
9.3 Docker Compose 的yml文件
Docker Compose 的 YAML 文件用于定义和配置多容器应用程序的各个服务。以下是一个基本的 Docker Compose YAML 文件结构及内容解释:
一、服务(services)
-
服务名称(service1_name/service2_name 等):
-
每个服务在配置文件中都有一个唯一的名称,用于在命令行和其他部分引用该服务。
services: web: # 服务1的配置 mysql: # 服务2的配置
-
-
镜像(image):
-
指定服务所使用的 Docker 镜像名称和标签。例如,
image: nginx:latest表示使用nginx镜像的最新版本services: web: images:nginx mysql: images:mysql:5.7
-
-
端口映射(ports):
-
将容器内部的端口映射到主机的端口,以便外部可以访问容器内的服务。例如,
- "8080:80"表示将主机的 8080 端口映射到容器内部的 80 端口。services: web: image: timinglee/mario container_name: game #指定容器名称 restart: always #docekr容器自动启动 expose: - 1234 #指定容器暴露那些端口,些端口仅对链接的服务可见,不会映射到主机的端口 ports: - "80:8080"
-
-
环境变量(environment):
-
为容器设置环境变量,可以在容器内部的应用程序中使用。例如,
VAR1: value1设置环境变量VAR1的值为value1services: web: images:mysql:5.7 environment: MYSQL_ROOT_PASSWORD: fjw
-
-
存储卷(volumes):
-
将主机上的目录或文件挂载到容器中,以实现数据持久化或共享。例如,
- /host/data:/container/data将主机上的/host/data目录挂载到容器内的/container/data路径。services: test: image: busybox command: ["/bin/sh","-c","sleep 3000"] restart: always container_name: busybox1 volumes: - /etc/passwd:/tmp/passwd:ro #只读挂在本地文件到指定位置
-
-
网络(networks):
-
将服务连接到特定的网络,以便不同服务的容器可以相互通信
services: web: image: nginx container_name: webserver network_mode: bridge #使用本机自带bridge网络services: test: image: busybox container_name: webserver command: ["/bin/sh","-c","sleep10000000"] #network_mode: mynet2 networks: - mynet1 - mynet2 networks: mynet1: driver: bridge mynet2: driver: bridge
-
-
命令(command):
-
覆盖容器启动时默认执行的命令。例如,
command: python app.py指定容器启动时运行python app.py命令[root@docker test]# vim busybox.yml services: web: image: busybox container_name: busybox #network_mode: mynet2 command: ["/bin/sh","-c","sleep10000000"]
-
二、网络(networks)
-
定义 Docker Compose 应用程序中使用的网络。可以自定义网络名称和驱动程序等属性。
-
默认情况下docker compose 在执行时会自动建立网路
services: test: image: busybox1 command: ["/bin/sh","-c","sleep 3000"] restart: always network_mode: default container_name: busybox test1: image: busybox2 command: ["/bin/sh","-c","sleep 3000"] restart: always container_name: busybox1 networks: - mynet1 test3: image: busybox3 command: ["/bin/sh","-c","sleep 3000"] restart: always container_name: busybox1 networks: - mynet1 networks: mynet1: driver: bridge #使用桥接驱动,也可以使用macvlan用于跨主机连接 default: external: true #不建立新的网络而使用外部资源 name: bridge #指定外部资源网络名字 mynet2: ipam: driver: default config: - subnet: 172.28.0.0/16 gateway: 172.28.0.254
三、存储卷(volumes)
-
定义 Docker Compose 应用程序中使用的存储卷。可以自定义卷名称和存储位置等属性。
services: test: image: busybox command: ["/bin/sh","-c","sleep 3000"] restart: always container_name: busybox1 volumes: - data:/test #挂在data卷 - /etc/passwd:/tmp/passwd:ro #只读挂在本地文件到指定位置 volumes: data: name: fjwyyy #指定建立卷的名字
9.4 企业示例
利用容器编排完成haproxy和nginx负载均衡架构实施
```
services:
web1:
image: nginx:latest
container_name: web1
restart: always
networks:
- mynet1
expose:
- 80
volumes:
- /docker/web/html1:/usr/share/nginx/html
web2:
image: nginx:latest
container_name: web2
restart: always
networks:
- mynet1
expose:
- 80
volumes:
- /docker/web/html2:/usr/share/nginx/html
haproxy:
image: haproxy:2.3
container_name: haproxy
restart: always
networks:
- mynet1
- mynet2
volumes:
- /docker/conf/haproxy/haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg
ports:
- 80:80
networks:
mynet1:
driver: bridge
mynet2:
driver: bridge

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)