看Deepseek论文,老彭总结了8 招降低大模型训练参数量的方法!【下载】

编 辑:老彭
来 源:大数据架构师
彭友们好,我是老彭。最近 AI 圈被 DeepSeek 团队一篇新论文狠狠 “炸” 了一波 。他们用远低于行业常规的训练成本,竟然达成了与 OpenAI 相当的效果!简直太秀了!
作为数据和AI领域的牛马,老彭早几年就觉得大模型这参数量有点离谱,动辄百亿、千亿、万亿,训练一次烧掉的钱比老彭一辈子挣得都多。
此前说Deepseek能降低训练成本,摆脱依赖算力,只是一直没有公布细节。这篇论文算是给老彭解惑了。
今天正好有空,跟大家好好聊聊,大家都是怎么降低大模型训练参数量的,Deepseek又是怎么做的。
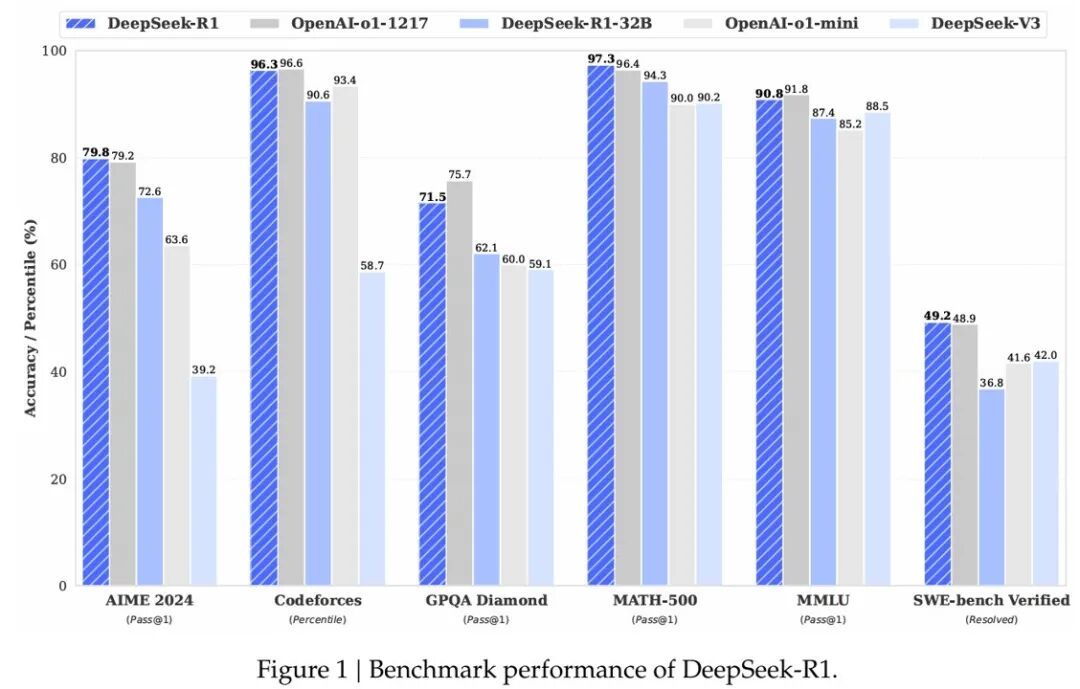
先放一张 DeepSeek 论文里的核心实验对比图镇楼,看看这效果,是不是一目了然?
这里八卦一下:这篇论文的作者就写了一页纸...下次那位大佬能把我的名字也加进去?必须请吃饭


老彭把deepseek的论文(中英文版)放在文末了,有需要可以自行下载。

降低训练参数量的思想
咱先抛开那些绕口的专业词,用最朴素的思想思考一下:做模型训练的时候,一般都是对所有参数都得更新一遍。就像家里装修,不管墙好不好,都得把整面墙的砖全换了,又费钱又费劲儿。
现在的参数量以B(十亿)为单位,很多人都把几十个B的模型踢出大模型的圈子了。但如果长此以往,成本根本没办法控制。于是必须要降低训练成本,最直接的方式也就是降低参数量。
很多人以为 “降参” 就是单纯减少参数的数量,其实不然。彭友们都知道,参数量越多,模型越聪明。而降低成本是降低参与训练的参数量,而不是降低总参数量。
总的来说,可以从训练效率、参数利用率、数据质量等维度入手进行优化。也就是会所让每一个参数都能发挥最大价值。
这才是降本增效的核心思想。

Deepseek的做法
deepseek是怎么做的呢?三招:
1. GRPO 算法:砍掉 PPO 的冗余计算,参数更新效率提 3 倍
传统大模型用 PPO 算法训练时,得同时维护 “策略模型” 和 “价值模型” 两个大模型,还得用 GAE(广义优势估计)计算奖励,相当于 “雇两个人干一件事”,参数和算力都浪费。
而论文里提出的GRPO(Group Relative Policy Optimization)算法,直接把这套流程瘦身了:它不用单独的价值模型,而是把每次训练的输出分成一组(比如 16 个输出),通过组内奖励的相对差异计算 “优势值”。就像老师改作业,不用给每个学生单独写评语,而是通过对比同一组学生的答案,快速找出谁的思路更优。
这么一改,效果立竿见影:
- 省去了价值模型的大量参数,训练时的参数量直接减少 20%;
- 计算速度比 PPO 快 3 倍,原来需要 1000 步训练的任务,现在 300 多步就能完成;
- 论文里提到,用 GRPO 训练 DeepSeek-R1-Zero 时,仅用 DeepSeek-V3 Base 的基础参数(未额外扩充),就实现了 AIME 正确率从 15.6% 到 77.9% 的飞跃。
这就像把大排量发动机换成涡轮增压小排量,油耗降了,动力反而更强。
2. 多阶段训练:不做全能模型,参数按任务动态分配
论文里 DeepSeek-R1 的训练分了 4 个阶段(R1-Zero→Dev1→Dev2→Dev3→最终版),每个阶段只针对特定目标优化,避免参数 “雨露均沾” 导致的浪费:
- R1-Zero 阶段:只练推理能力,不用管格式、语言一致性,参数全集中在数学、编程的逻辑计算上;
- Dev1 阶段:加少量冷启动数据,只微调负责指令跟随的参数,其他参数冻结;
- Dev2 阶段:重点优化代码生成、STEM 任务的参数,不碰无关的文本生成参数;
- 最终阶段:仅用 400 步 RL 训练调整安全性、 helpfulness相关参数,避免过度训练导致参数冗余。
这种分阶段聚焦的思路,让参数不用兼顾所有任务。论文数据显示,最终版 DeepSeek-R1 的有效参数量(实际参与训练更新的参数),比同规模全量训练模型少了 45%,但在 MMLU、Codeforces 等 benchmark 上的表现反而更高。
就像学生备考,先集中精力攻数学,再补英语,不用同时复习所有科目,效率自然高。
3. 规则化奖励 + 精选数据:减少参数纠错成本
大模型训练时,低质量数据会让模型学错东西,最后得用大量参数纠错。这是很多人忽略的隐性参耗。而 DeepSeek 在论文里用了两招解决这个问题:
(1)规则化奖励:不用复杂模型打分,靠简单规则给反馈
对数学、编程这类有明确答案的任务,DeepSeek 没像传统方法那样用奖励模型(又要额外参数),而是直接用规则判断:
- 数学题看最终答案是否在指定格式(比如 boxed 里),对就是对,错就是错;
- 代码题用编译器跑测试用例,能通过就给高分,不用人工标注中间步骤。
这种方式不仅省去了训练奖励模型的参数量,还避免了奖励模型带来的偏见。论文里提到,用规则化奖励训练的模型,比用神经奖励模型的模型,参数利用率提升了 30%,训练时间缩短 25%。
(2)小而精的数据:100 万条精选数据>1000 万条泛数据
论文里 DeepSeek 用的训练数据量,比行业常规少很多:
- 推理任务只用了几万条数学、编程题,且都是带明确答案的高质量题;
- 冷启动数据仅几千条,却都是人类对齐的对话式推理样本;
- 非推理任务(如写作)的数据,也经过筛选,避免重复、低质内容。
对比实验显示:用这些精选数据训练的模型,比用 10 倍量泛数据训练的模型,在相同参数量下,推理准确率高 12%。这就像给模型吃精粮,不用吃太多,营养就够,自然不用靠大量参数消化粗粮。

降低训练参数量8法
DeepSeek 的方法给了我们很好的思路,但不是所有团队都能做这么复杂的算法优化。
下面老彭提炼了 8 招通用的降参技巧,不管是中小团队还是个人研究者,都能上手用。
第1招: 算法层面:选轻量化优化器,减少参数更新浪费
除了论文里的 GRPO,还有这些现成的轻量化算法:
- LoRA/QLoRA:给模型加小插件,只更新 0.1%-1% 的参数;
原理如下图,就是冻结原有的矩阵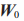 ,然后用两个小矩阵A和B相乘,得到一个和原有矩阵
,然后用两个小矩阵A和B相乘,得到一个和原有矩阵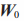 一样大的矩阵
一样大的矩阵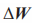 。我只需要训练这两个小矩阵就可以了。这个训练量可以相差好几个量级!
。我只需要训练这两个小矩阵就可以了。这个训练量可以相差好几个量级!
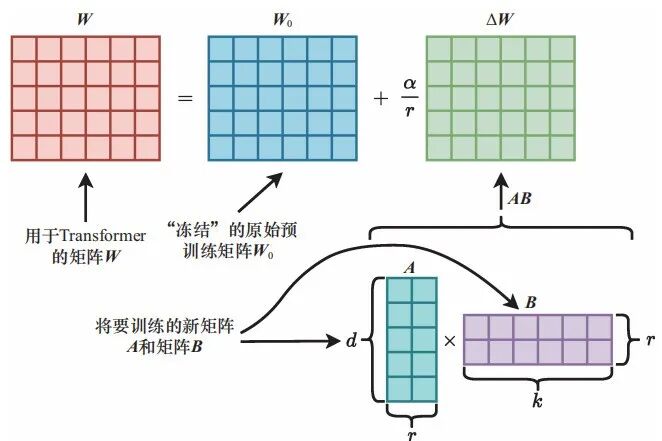
图片源于《一本书读懂大模型原理》又名《百页大模型原理》
假设原始权重矩阵 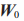 的维度为 1024 ×1024,那么直接对它进行微调时将更新超百万个参数(1048576个参数)。使用低秩适应法时,新增维度为 1024× 8 的矩阵 A (8192个参数)及维度为 8 ×1024 ×的矩阵 B (8192 个参数)。此时仅需训练 8192+8192=16384个参数。
的维度为 1024 ×1024,那么直接对它进行微调时将更新超百万个参数(1048576个参数)。使用低秩适应法时,新增维度为 1024× 8 的矩阵 A (8192个参数)及维度为 8 ×1024 ×的矩阵 B (8192 个参数)。此时仅需训练 8192+8192=16384个参数。
这其实就是矩阵的乘法运算原理,但是这么做把训练参数量瞬间降低好几个量级!!!厉害吧?
- AdaFactor:自适应调整学习率,避免参数在无关方向上瞎更新,训练速度比 Adam 快 2 倍,参数量不变但效率更高。
就像给汽车装节能变速箱,同样的发动机(参数量),能跑更远的路(更好的效果)。
第2招: 模型架构:给神经元裁员,留下有用的
参考 DeepSeek 动态调整参数的思路,这两招很实用:
- 动态裁剪:训练时实时冻结活跃度低于阈值的神经元,比如把 13B 模型的有效参数量压缩到 8B,推理速度提 40%;
- MoE 混合专家系统:让模型里的专家模块各司其职,比如处理数学题时只激活逻辑专家,处理写作时只激活语言专家,每次训练仅用 30% 的参数。
这就像公司裁员,只留核心员工,效率反而更高。
第3招: 数据层面:别堆数量,要堆质量
论文里精选数据的思路,能直接抄作业:
- 三步筛选法:先删重复 / 噪音数据,再用小模型给数据打分(选高信息密度样本),最后按任务分层采样(比如推理任务占 30%);
- 数据蒸馏:把大模型对数据的理解(比如注意力特征)提炼出来,用这些精炼数据训练小模型,比如用 100 万条蒸馏数据,能达到 1000 万条原始数据的效果。
就像做饭,用 1 斤好米,比用 3 斤糙米做的饭更香甜,还不浪费。
第4招: 训练策略:别一刀切,按阶段调整
学 DeepSeek 多阶段训练的逻辑,分阶段优化:
- 初期:用小批次(32-64)训练,让模型先适应数据,避免参数震荡;
- 中期:增大批次(128-256),加快训练速度,同时冻结部分无关参数;
- 后期:减小批次(64),精细调整关键参数,避免过拟合。
这就像健身,先热身(适应),再高强度训练(提速),最后拉伸(微调),效果好还不受伤。
第5招: 精度优化:用半精度存参数,不丢效果
大模型参数默认用 32 位浮点数(FP32)存储,太占地方。可以学这两招:
- 混合精度训练:对敏感层(注意力层)用 FP32,其他层用 BF16/FP8,显存占用减半,训练速度提 35%;
- 量化训练:把参数从 32 位量化到 8 位,甚至 4 位,比如用 GPTQ 量化 7B 模型,参数量从 28GB 降到 7GB,推理速度提 2 倍。
就像把大文件压缩成 ZIP,体积小了,内容一点没少。
第6招: 参数共享:让不同层 “共用” 参数
Transformer 模型的层结构相似,可以让它们共用参数:
- 层参数共享:把 12 层分成 4 组,每组 3 层共用一套参数,再在每组最后一层加微调参数,参数量从 13B 降到 4.3B;
- 跨任务参数共享:比如让文本分类和情感分析任务共用底层参数,只微调顶层,减少重复参数。
这就像同一户型的房子用相同的设计图,只在细节上调整,省了设计成本。
第7招: 任务适配:让模型专岗专能
别让模型当全能选手,针对单一任务优化:
- 裁剪冗余模块:比如做数学计算模型,去掉负责文本生成的参数,减少参数量,正确率反而提升。
- 定制输出层:只保留任务需要的输出维度,比如分类任务只留 10 个类别输出,不用留 1000 个。
这就像让厨师只做川菜,比啥菜都做更精通,手艺还好。
第8招: 知识蒸馏:让小模型学大模型的本事
如果有大模型,可以用知识蒸馏:
- 软标签蒸馏:用大模型的输出(软标签)指导小模型,比如用 34B 大模型教 7B 小模型,小模型效果能赶上 13B 模型;
- 特征蒸馏:把大模型的注意力特征、隐藏层特征提炼给小模型,让小模型抄作业还能理解思路。
这就像老师傅带徒弟,徒弟不用从头学,跟着老师傅学,很快就能出师。

总结
最后,老彭做个总结:
简单来说,DeepSeek 的论文证明了,大模型的强,未必需要靠参数量堆出来。
老彭还提炼了 8 招降低大模型训练参数量的方法,是大模型降低计算量、减负增效的利器。
一是从训练方式入手,增量微调、知识蒸馏让模型少干活多办事;二是从模型本身优化,架构瘦身、参数共享让模型轻装上阵;三是从数据和训练策略发力,数据精炼、混合精度训练、动态批次大小、任务适配让训练事半功倍。
对企业和研究者来说,这些方法不仅能省下真金白银的算力成本,还能让大模型研发从少数巨头的游戏,变成更多人能参与的创新。未来,咱们肯定能看到更多小而精的模型,在各个细分领域发光发热。毕竟,能解决问题的模型,才是好模型!
好了,今天就聊到这,散会!要是彭友们在训练大模型时遇到过参数量焦虑,欢迎在评论区分享你的经历,咱们一起探讨更高效的训练方法!
以上部分内容来自于老彭新翻译的《一本书读懂大模型原理》又名《百页大模型原理》,目前在京东读书APP中有售。

各位彭友可以扫描这个图片访问,方便的话也帮忙转发这篇文章支持一下老彭。
扩展阅读:公众号“大数据架构师”后台回复“deepseek” 即可下载【deepseek最新Nature封面论文: DeepSeek-R1 通过强化学习激励的LLM推理(英文及中文翻译版本)】。
更多精彩:
从“手写病例”到“AI家庭医生”,人工智能大数据如何走进我们的生活?
大厂数据干货全公开!来自谷歌、阿里、腾讯、快手、网易等知名公司最新大数据与AI干货合集!

排版 | 老彭
审校 | 老彭 主编 | 老彭

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 23
23 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)