移动边缘计算中的卸载与资源分配
本文研究移动边缘计算中的计算卸载与资源分配问题,提出一种基于处理延迟和能耗的任务权重成本模型,并采用遗传算法优化卸载决策。同时设计基于效用最大化的双重拍卖资源分配方案,考虑用户偏好与动态出价策略,通过贪婪机制提升系统效用。实验表明,所提方法能有效降低延迟与能耗,提高资源利用率和拍卖成功率。
移动边缘计算中的计算卸载与服务分配
1 引言
近年来,各种移动智能设备为人们的生活提供了便利。涌现出了大量计算密集型应用,例如虚拟现实(VR)、增强现实(AR)、移动支付、互动游戏和智能监控。因此,用户对移动设备性能的期望越来越高[1, 2]。然而,移动设备需要将数据发送到远离终端的服务器,这会给移动网络的无线链路和回传链路带来大量额外负载,导致网络负载加重和频谱占用过高。高延迟严重影响了用户的满意度,同时也增加了对大带宽和延迟敏感型应用的需求。
为了解决传统云计算带来的问题,移动边缘计算(MEC)逐渐受到广泛关注。移动边缘计算将智能计算和计算单元置于网络边缘,增强了无线网络侧的处理、存储和计算功能。换句话说,在移动网络边缘提供计算服务,使得服务能够本地化并近距离部署,从而更好地支持对低延迟和高服务质量有需求的各种服务[3]。然而,边缘计算的研究过程中仍存在许多问题。例如,当任务卸载到边缘服务器时,如何卸载、何时卸载以及卸载到何处,都是亟需解决的关键问题。当任务成功卸载到边缘服务器后,下一步需要处理的是在边缘服务器上的资源分配问题。
移动边缘计算中的计算卸载技术是指将计算密集型任务完全或部分卸载到资源充足的边缘服务器。它主要解决了移动设备在存储、能耗、计算和传输方面的不足。在边缘云环境中进行计算卸载可以减轻核心网络的压力以及传输带来的延迟[4]。建立计算卸载模型,进而研究向移动边缘计算服务器进行计算卸载的决策策略,并有效提高系统服务效率和用户服务质量,是边缘计算任务卸载策略研究中的关键点之一。计算卸载有三种情况:(1)本地执行:全部计算由移动终端用户在本地完成;(2)部分卸载:部分计算由移动终端用户在本地处理,其余部分卸载至移动边缘计算服务器进行计算;(3)全部卸载:所有计算均卸载至移动边缘计算服务器执行。计算卸载研究通常关注三个优化目标:(1)最小化执行延迟;(2)在延迟约束下最小化移动边缘计算系统或移动终端用户的能耗;(3)寻找延迟与能耗之间的权衡。
在实际应用场景中,由于边缘服务器的有限计算资源,需要根据不同场景和不同用户以获得更高的计算资源利用率[5]。边缘计算中的资源分配优化是指在资源受限的情况下,根据能效、吞吐量、公平性、优先级等性能指标,灵活地将系统中的带宽、中央处理器资源等分配给各项任务。同时,应满足降低网络拥塞、提高边缘计算网络中系统资源利用率的需求。在边缘计算环境中,多用户与多个边缘节点共同参与资源分配过程,但作为买方的移动用户与作为服务提供方的边缘节点具有不同的利益诉求:用户希望最小化成本,而边缘节点则希望最大化收益。如何为用户和边缘节点动态生成竞价,并最大化系统效用,是边缘计算环境下的资源分配研究的关键问题。
通过在边缘云计算中进行计算卸载,可以降低移动设备和应用的能耗与处理延迟。然而,计算卸载的决策是一个NP难问题。为解决此问题,本文建立了基于处理延迟和能耗的任务权重成本模型,并将任务权重成本作为优化目标,采用遗传算法寻找计算卸载的最优决策方案。由于边缘服务器的计算资源有限,为了根据不同应用场景和不同用户合理分配计算资源,本文提出了一种基于效用最大化的资源分配算法。考虑到用户对不同边缘节点具有不同的偏好,讨论了用户与边缘节点的出价策略。最后,基于贪婪策略将资源分配给高单价出价用户,以最大化系统效用。主要贡献如下:
(1) 为了降低边缘计算环境中的任务执行延迟和能耗,提出了一种动态计算卸载方案。在该策略中,建立了基于处理延迟和能耗的任务权重成本模型。为了避免基于遗传算法的计算卸载方案陷入局部最优,定义了动态变化的交叉概率和变异概率。
(2) 本文提出了一种基于效用最大化的资源分配方案。该模型考虑了用户对不同边缘节点的偏好、边缘节点的资源总量以及用户和边缘节点的竞价策略。最后,在双重拍卖过程中,根据贪婪策略将资源分配给高单价出价用户,以最大化系统效用。
(3) 通过在真实数据集上进行的一系列对比实验,验证了本文所提出的移动边缘计算中协同卸载与资源分配优化的有效性。所提出的计算卸载算法能够有效降低任务执行延迟以及能耗,所提出的资源分配算法能够促进成功拍卖用户数量的增长,并最大化系统效用。
本文的其余部分安排如下:第2节讨论了关于计算卸载和资源分配的相关工作。第3节介绍了移动边缘计算中协同卸载与资源分配优化的模型与解决方案。第4节给出了算法的流程、伪代码及复杂度分析。第5节介绍了实验环境以及实验结果的分析。最后,第6节讨论了结论。
2 相关工作
2.1 计算卸载
移动边缘计算中的计算卸载是指移动设备将计算密集型任务卸载到靠近用户的移动边缘计算服务器进行处理。为了降低由于在资源受限的移动设备上执行任务计算所带来的能耗和任务延迟,移动边缘计算中的计算卸载变得越来越重要。
Chouhan 等人 [6]提出了一种能耗感知的计算卸载框架。该框架专注于部分计算卸载,并致力于在数据传输过程中降低压缩‐解压缩能耗。为了促进实时医疗数据处理,Li 等人 [7]提出了一种边缘计算环境中的计算卸载模型,并通过心率检测应用验证了该模型的有效性 [8]。Wan 等人 [9]在支持5G的 EC‐IoV系统中提出了一种计算卸载算法,该算法尤其能够减少延迟并提高系统效率。Silva 等人 [10]在混合云环境中提出了一种任务卸载方案,可缓解由计算资源拥塞引起的计算性能瓶颈。Maleki 等人 [11]在移动边缘计算中建立了位置感知计算卸载和任务预测模型,该模型考虑了任务执行时间和移动应用位置变化的影响。Hmimz 等人 [12]提出了一种基于多目标优化的任务卸载模型,并采用启发式算法求解问题,以实现能耗与用户满意度之间的平衡。
Nowak 等人 [13]考虑了用户组和边缘云服务器的应用场景,其计算任务可以被拆分,并提出了一种基于纳什博弈的计算卸载算法,以实现卸载的合理性。
在边缘计算环境中,Hossain 等人 [14]提出了一种协同计算卸载模型,用于处理延迟敏感型任务并提高成功任务卸载的平均数量。Singh 等人 [15]在多接入边缘计算环境中提出了一种基于计算复杂度的任务卸载算法。在该算法中,当连接接入延迟较大时,优先卸载复杂度较高的应用,以最小化任务完成时间。结合第五代移动通信技术中的异构网络与移动边缘计算,Guo 等人[16]提出了一种基于博弈论的任务卸载方法,以降低计算消耗并提高系统吞吐量。为了降低智能物联网设备的能耗,Mavromoustakis 等人[17]提出了一种计算卸载模型,该模型可为智能设备动态提供卸载策略。Wei 等人[18]提出了一种基于马尔可夫决策的任务卸载方案,并利用深度强化学习获得最优卸载策略。
计算卸载的优化目标主要集中在减少任务处理延迟和能耗。然而,目前很少有研究关注任务延迟和终端能耗的综合优化。此外,上述大多数算法的迭代速度相对较慢,难以同时保证较低的计算卸载成本以及算法对变化的计算卸载环境的动态适应性。本文设计的计算卸载算法能够降低执行能耗和时间延迟,并对变化的环境具有动态适应性。
2.2 资源分配
与云服务相比,边缘服务器上的频谱和计算资源仍然有限,密集任务卸载可能导致边缘服务资源短缺和网络拥塞等问题。因此,在确保应用需求的前提下,如何在卸载过程中找到最优移动边缘计算资源分配策略具有重要的研究价值 [16,19–21]。
在边缘计算环境中,Meskar 等人 [17]提出了一种基于公平性的资源分配方案,以合理分配计算资源和通信链路带宽,并提高资源利用率。李等人 [18]提出了一种资源分配算法,在满足边缘服务器工作负载约束的前提下,最小化租用节点成本和SLA违约率。Din 等人 [22]提出了一种基于移动性的资源分配策略,以降低边缘服务器的负载和工作成本,并采用深度强化学习来解决该问题。在雾计算中,Birhanie 等人 [19]提出了一种在延迟和QoS约束下的资源分配算法,该算法通过博弈论求解,并应用于车辆场景。在地理分布云中,李等人 [23]提出了一种基于超图划分的任务调度算法,考虑了云服务器的负载,可有效减少任务执行时间并实现系统的负载均衡。Khanfor 等人 [24]提出了一种针对执行任务总时间的预测模型,能够为物联网中的各种智能设备动态分配计算资源。Jošilo 等人 [25]在移动边缘计算环境中提出了一种基于去中心化斯塔克尔伯格博弈的资源分配算法,与普通资源分配算法相比,显著降低了资源分配完成时间。Habiba 等人 [20]设计了一种基于逆向拍卖的位置感知资源分配策略,并采用贪心算法求解该问题最大化社会效益的问题。在边缘计算中,ATasiopoulos 等人[26]提出了一种基于拍卖的资源分配与供应机制,该机制将用户满意度和任务执行时间作为评价指标。Bahreini 等人[27]提出了一种基于双重拍卖的资源分配策略,能够有效对边缘云资源进行定价,并鼓励越来越多的用户参与资源拍卖过程。为了实现边缘云环境中资源分配的动态定价,Baek 等人[28]引入并比较了不同的资源定价机制,这些机制能够有效解决资源拍卖中的公平性问题。在边缘计算环境中,Nguyen 等人[29]提出了一种基于效用的资源分配算法,该算法引入了一种新颖的资源定价机制和共享激励机制。
尽管上述关于边缘计算资源分配的研究具有独特的解决方案,但仍存在一定的局限性。部分研究未考虑无线资源的分配,且基于双重拍卖机制的资源分配算法未考虑每轮拍卖中用户或边缘节点的出价策略。因此,提出了一种基于双重拍卖的移动边缘计算资源分配策略,以最大化用户和边缘节点的效用。
3 系统模型
在移动边缘计算环境中,计算卸载分为本地执行和卸载到边缘服务器执行。当任务成功卸载到边缘服务器后,下一步需要处理的是将有限的MEC计算资源分配给一个或多个终端用户应用的问题。然而,密集的移动数据流量对能量受限的移动设备带来了巨大挑战[8]。通过资源分配,可以有效降低任务的执行延迟和能耗,提高系统吞吐量以及计算资源利用率。综合考虑上述因素,本文提出了一种基于处理延迟和能耗的动态计算卸载方案,以及一种基于效用最大化的资源分配方案。本节中主要符号的含义如表1所示。
3.1 基于处理延迟和能耗的动态计算卸载
在本节中,为了降低移动设备的执行能耗和处理延迟,本文提出了一种边缘计算环境下的动态卸载方案。并引入了全局处理延迟模型、执行能耗模型和加权成本模型。基于处理延迟和能耗的动态计算卸载模型的系统模型如图1所示,且边缘节点的服务器是具有异构处理能力的资源提供者。
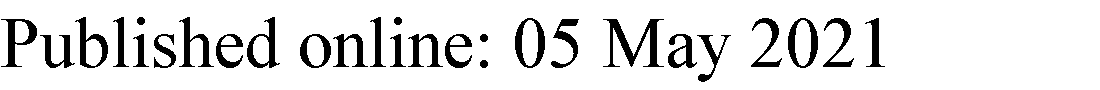
Table 1 The description of major symbols
| Symbol | Explanation | Symbol | Explanation |
|---|---|---|---|
| V | The set of tasks of the application | E | The set of links and weight between different tasks |
| N | The number of edge servers | S0 | The local mobile device |
| Tl i | The processing delay of the task i on the local device | Te i | The processing delay of the task i on the edge cloud server |
| f l i | The local computing capability | f e i | The computing capability of the edge node |
| li | The CPU cycle required to complete the computation task | bwx,y | The transmission bandwidth between the edge server x and y |
| T(task) | The processing delay of the task | tx,y i,j | The communication delay between the two tasks |
| s i | A differentiating factor for tasks executed on local or edge cloud servers | xy | The communication delay factor between two tasks |
| Pl i | The execution energy consumption of the task on the local device | Pe i | The energy consumption on local device when tasks executed on the edge server |
| px,y i,j | The communication energy consumption between the two tasks | P(task) | The energy consumption of the task |
| W(task) | The task weight cost | TSi | The size of task data(KB) |
| DLi | The task deadline(s) | RTransi | The communication resource demand of the user |
| RCpui | The computing resource demand of the user | SCpuj | the computing speed of node j |
| CCpuj | The total computing resources of node j | CTransj | the total communication resources of node j |
| ai,j | Indicate whether user i migrates the task to node j for processing | Preferencei,j | The preference of user i for edge node j |
| di,j | The distance between the user and the edge node | Ttotali,j | The task completion time |
| TExei | The execution time for the task user i | TTransi | The transmission time for the task user i |
| Ubidmax | The highest unit bid allowed in the market | Ubidmin | The lowest unit bid allowed in the market |
| UValvei | The unit resource valuation of user i | UCostj | The unit resource cost price of node j |
| UBidi | The unit bidding price of user i | UAskj | The unit asking price of edge node j |
| UtilityUser i | The utility of user i | UtilityNode j | The utility of edge node j |
| B(t) | The resource payment price sequence up to round t | UtilitySystem | The utility of the system |
3.1.1 计算卸载模型
假设计算密集型应用在终端设备上执行。每个组件可以在本地计算,或卸载到移动边缘计算服务器进行计算。任务 i 表示为 {si,li,ri} ,其中 si表示任务在终端设备上计算过程中需要输入的数据量。无论任务是在本地计算还是被卸载到移动边缘计算服务器,si均视为保持不变。li表示完成该计算任务所需的 CPU 周期。ri是当前计算任务得到的结果。本文使用图 G(V, E)来表示具有不同权重的不同任务之间的关系。其中,节点 V 和有向边 E 分别表示应用的任务以及不同任务之间的连接和权重。假设有 N 个边缘服务器组成的集合,集合 S ={S0, S1,…, SN}表示可用服务的集合。S0表示本地移动设备,意味着应用任务可以在本地移动设备上执行。V 中的每个任务表示任务 i 在节点 Sa上的处理延迟。每条有向边 e =(x, y)表示在服务器 Sa上运行的任务 x 与在服务器 Sb上运行的任务 y 之间的数据传输时间。
3.1.1.1 处理延迟和执行能耗
应用的处理延迟主要由每个任务的处理时间以及不同任务之间的通信延迟组成。每个任务的处理时间分为在本地移动设备上执行任务的处理延迟 T l i 和在移动边缘服务器上执行任务的边缘云处理延迟 T e i。通信延迟是不同任务之间有向边的权重。当用户选择在本地执行任务时,设 S 0 , let f l i 表示用户 i 的本地计算能力(CPU 周期数),li 表示完成计算任务所需的 CPU 周期,本地计算任务的处理延迟 T l i 为:
$$
Tl_i = \frac{l_i}{f_l^i}, i = S_0
$$
$$
Te_i = \frac{l_i}{f_e^i}, i \in {S_1, S_2, …, S_N}
$$
$$
t_{x,y}^{i,j} = \frac{Volume_{ij}}{bw_{x,y}}
$$
$$
T(task) = \sum_{i=1}^{n} \sum_{j=1}^{n} \lambda_{xy} \times t_{x,y}^{i,j} + \sum_{i=1}^{n} ((1-\mu_s^i) \times Tl_i + \mu_s^i \times Te_i)
$$
$$
\mu_s^i = 0, s = S_0; \mu_s^i = 1, s \in {S_1, S_2, …, S_N}
$$
$$
\lambda_{xy} = 0, \mu_s^i \oplus \mu_s^j = 0; \lambda_{xy} = 1, \mu_s^i \oplus \mu_s^j = 1
$$
$$
\sum_{s=0}^{N} \mu_s^i = 1 \quad \forall i \in V
$$
其中 Tei 表示在移动边缘服务器上执行任务的处理延迟,f ei 表示边缘节点 i 的计算能力。不同边缘服务器上两个任务之间的通信延迟表示如下:
其中:通信延迟 $t_{x,y}^{i,j}$ 由任务间的数据传输量 $Volume_{ij}$ 和传输带宽 $bw_{x,y}$ 决定。任务的处理延迟模型 T(task) 定义为:
其中: n 表示任务数量,且上述约束表明,如果任务被分配给边缘服务器,$\mu_s^i = 1$ ;如果任务被分配给本地设备,则 $\mu_s^i = 0$ 。因此, $\mu_s^i$ 可被视为在本地设备或边缘服务器上执行任务的区分因子。$\lambda_{xy}$ 表示两个任务之间的通信延迟因子。一方面,如果任务被分配到同一边缘服务器上, $\lambda_{xy} = 0$ ;另一方面,如果两个任务在同一移动设备上运行,$\lambda_{xy} = 0$ 。此外,公式(4) 还包含每个任务只能被分配到一个边缘服务器的约束。
执行能耗主要由每个任务的执行能耗以及不同任务之间的通信能耗组成。每个任务的能耗包括任务在本地移动设备上执行时的能耗P l i,以及任务在边缘服务器上执行时在空闲本地设备上的能耗P e i。任务 i 在本地设备上的执行能耗Pl i 和任务 i 在边缘服务器上的能耗Pe i 分别定义为:
$$
Pl_i = Tl_i \times p_c
$$
$$
Pe_i = Te_i \times p_{idle}
$$
$$
P_{x,y}^{i,j} = t_{x,y}^{i,j} \times p_{trans}
$$
$$
P(task) = \sum_{i=1}^{n} \sum_{j=1}^{n} \lambda_{xy} \times P_{x,y}^{i,j} + \sum_{i=1}^{n} ((1-\mu_s^i) \times Pl_i + \mu_s^i \times Pe_i)
$$
其中 pc表示中央处理器的工作功率,pidle表示终端设备在空闲状态下的功率,该功率远小于终端设备进行计算时的工作功率。其中Px ,y i,j 是两个任务之间的通信能耗,ptrans 表示终端设备传输数据时的功率。执行能耗模型 P(task)定义如下:
3.1.1.2 任务权重成本模型
计算卸载的主要优化目标是最小化任务的成本函数。根据上述讨论,建立了一个权重优化模型,并搜索任务的成本函数最优值任务 ′的任务,任务= min(W(任务)) 。任务权重成本W(任务)表达如下:
$$
W(task) = \alpha_k \times \frac{T(task)}{T_{loc}} + (1 - \alpha_k) \times \frac{P(task)}{P_{loc}}
$$
$$
\min {W(task)}
$$
$$
s.t. \alpha_k \in [0, 1]
$$
$$
s.t. T(task) \leq MCT_n
$$
其中 Tloc和 Ploc分别表示任务在本地终端设备上的处理延迟和执行能耗。 αk 和 1− k 分别表示处理时延权重和执行能耗权重。 αk 的大小主要取决于不同用户的服务需求。当 αk = 1时,表示用户主要关注任务的处理延迟,适用于时间受限场景。相反,当 αk = 0时,表示用户主要关注任务的执行能耗,适用于能量受限场景。 MCT n 是所有任务的最大允许处理时延,公式(15) 表示所有任务的处理延迟应小于或等于最大允许处理时延。
3.1.2 基于遗传算法的动态计算卸载解决方案
基于处理延迟和能耗的动态计算卸载问题是非确定性多项式完全(NPC)问题,难以在多项式时间内找到其最优解。遗传算法通过模拟生物进化机制在全局范围内搜索最优解,是求解NP问题的常用技术之一。遗传算法利用交叉和变异策略,在不了解问题域先验知识的情况下使种群保持在最优解区域附近。因此,本文设计了一种基于遗传算法的动态计算卸载方法(DCOGA)。在该方法中,每条染色体代表一个应用的计算卸载决策,解中的每个基因被赋予一个值,表示边缘云服务器或本地执行。DCOGA算法的目标是为每个应用组件获得最佳的计算卸载决策 task′ ,从而得到最小的全局代价函数。DCOGA算法的过程主要包括种群初始化、种群繁殖、选择、交叉、变异、适应度函数设计以及迭代终止条件。具体过程如下。
3.1.2.1 种群初始化和适应度函数
在此步骤中初始化DCOGA算法的相关参数,包括最大迭代次数 周期、交叉概率 p1、变异概率 p2、种群大小 popsize 以及初始种群。采用自然数编码方案解决计算卸载中的染色体编码问题。使用0表示本地设备,[1,N]表示边缘节点。当应用被划分为 n 个任务时,任务被随机卸载到不同的节点。为了更好地初始化种群,由于在边缘云环境中任务卸载的性能通常优于本地执行,且边缘云服务器数量为 N,因此将所有染色体的基因分配给同一个边缘服务器,并生成 N 个染色体。其余染色体随机生成,以保持种群的随机性。
传统的遗传算法是选择适应度值较高的个体并将其传递给下一代。因此,在DCOGA算法中,初始种群的适应度函数f init定义为公式(16),它表示公式 (12)中目标函数的倒数。因此,在每次迭代中,算法将尝试找到比上一次迭代具有更高适应度值的任务分割方案。
$$
f_{init} = \frac{1}{\alpha_t \times \frac{T(task)}{T_{loc}} + \alpha_p \times \frac{P(task)}{P_{loc}}}
$$
3.1.2.2 种群选择、交叉和变异
选择算子能够从种群中选择高质量的染色体进行交叉变异操作,实现优胜劣汰,并控制种群的进化方向。在本文中,为了根据适应度函数评估初始种群和保留种群中的染色体,选择算子采用了轮盘赌算法。轮盘赌算法的基本思想是每个染色体占据轮盘的一部分区域,适应度函数值越大,所占区域越大,被选为父代染色体的概率也越大。
交叉操作是将父代染色体结合以生成下一代染色体;通常,下一代染色体质量更高。标准的单点交叉通过交换两个染色体片段来生成子代染色体。变异操作是指染色体中的某个基因以一定概率被更改为另一个值,以避免算法出现早熟收敛。为了避免基于遗传算法的计算卸载方案陷入局部最优,动态调整交叉概率p1和变异概率p2定义如下:
$$
P_1 =
\begin{cases}
\beta_1 \frac{f_{max} - f_{crossover}}{f_{max} - f_{avg}}, & f_{crossover} \geq f_{avg} \
\beta_2, & f_{crossover} < f_{avg}
\end{cases}
$$
$$
P_2 =
\begin{cases}
\beta_3 \frac{f_{max} - f_{mutation}}{f_{max} - f_{avg}}, & f_{mutation} \geq f_{avg} \
\beta_4, & f_{mutation} < f_{avg}
\end{cases}
$$
其中, β1, β2, β3, β4为常数。f max表示当前代种群中的最大适应度值;f avg 表示整个种群的平均适应度值;f crossover表示在交叉操作中被选中的两个个体中较大的适应度值;f mutation是在变异操作中被选中的个体的适应度值。
通过上述遗传操作,可以获得新一代的种群。然后根据公式(16)计算新一代种群个体的适应度值。如果种群的最大适应度值与平均适应度值相差不大,或者已达到预设的最大迭代次数,则算法停止,并输出最优适应度值及相应的计算卸载决策。否则,算法将继续执行,直到满足停止条件为止。
3.2 基于效用最大化的资源分配
将任务迁移到边缘节点的过程需要利用通信资源上传任务,然后利用边缘节点的计算资源完成任务处理。因此,移动边缘计算资源分配需要同时分配通信资源和计算资源。为了解决联合资源分配问题,本文以最大化社会效用为优化目标,采用双重拍卖来解决
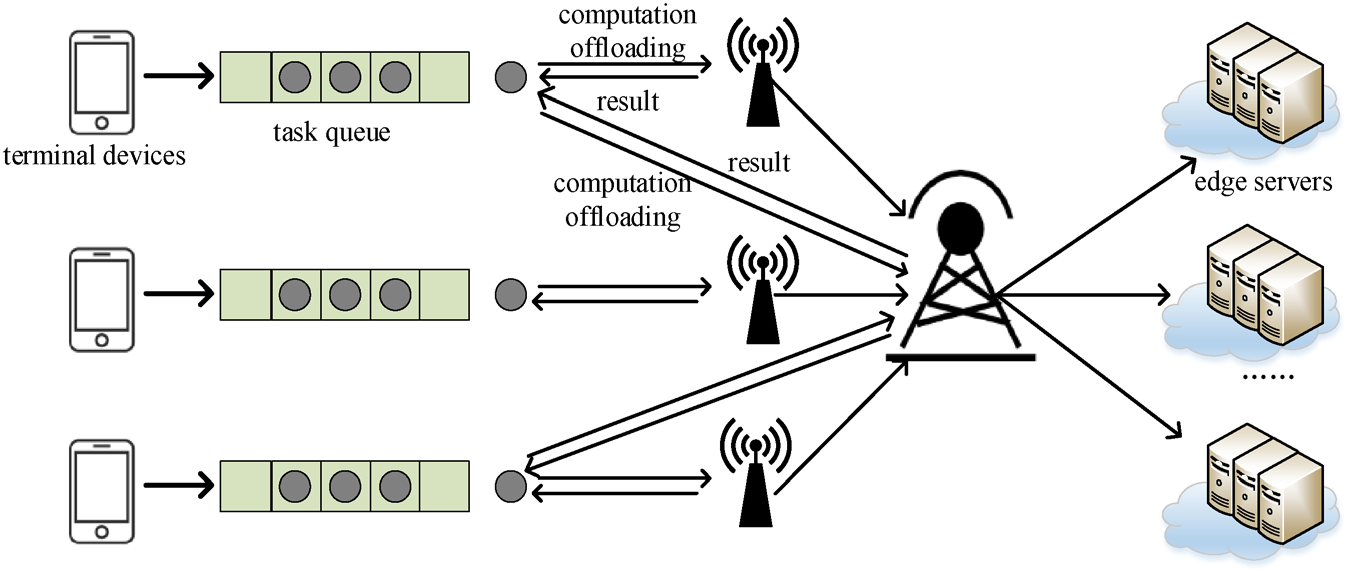
资源分配问题。在资源分配模型中,存在三个角色:用户、拍卖代理和边缘节点。其中,用户向拍卖代理提交资源需求和出价,边缘节点提交可租用资源和要价。拍卖代理负责资源拍卖,并反馈每轮拍卖结果。具体过程如图2所示。
3.2.1 资源分配模型
移动边缘计算系统由多用户和多移动边缘计算节点组成。用户可以将任务迁移到边缘节点进行处理,但需要计算任务的截止时间和迁移任务到边缘服务器处理的完成时间。只有当迁移任务的完成时间不超过截止时间时,任务才能被迁移。在资源分配模型中,Taski=(TSi、DLi、RTransi、RCpui)表示用户i的任务信息,其中i = 1, 2,…, M;TSi表示任务数据的大小(KB),DLi表示任务截止时间(秒),RTransi和RCpui分别表示用户的通信资源需求和计算资源需求。用户i的本地CPU频率用Freq i,local表示,假设每个移动终端的传输功率相同,用Plocal表示。Nodej =(SCpuj、CCpuj、CTransj)表示边缘节点j的信息,其中j = 1, 2,…, N;SCpuj表示节点j的计算速度,CCpuj和CTransj分别表示总计算资源和通信资源。
假设每个任务只能迁移到一个边缘节点进行处理,ai,j = 1表示用户 i 将任务迁移到节点 j 进行处理,而 ai,j = 0表示该任务未迁移到节点 j 进行处理:
$$
\sum_{j=1}^{N} a_{i,j} \leq 1, 1 \leq i \leq M, 1 \leq j \leq N
$$
在任务迁移过程中,用户对边缘节点有不同的偏好,并向偏好度最高的节点发起资源请求。偏好计算公式如下所示:
$$
Preference_{i,j} = \omega_1 \times \frac{1}{d_{i,j}} + \omega_2 \times CCpu_j + \omega_3 \times SCpu_j + \omega_4 \times CTrans_j
$$
在该方程中,Preferencei,j表示用户i对边缘节点j的偏好,其中 1+ω2+ω3+ω4= 1 。显然,不同类型的任务具有不同的值。例如,计算密集型应用需要更多的计算资源,因此权重因子ω2更大;而延迟敏感型应用对计算速度要求更高,因此权重因子ω3更大。di,j表示用户与边缘节点之间的距离,用户离边缘节点越远,其对该边缘节点的偏好越低。在根据用户i的偏好选择边缘节点j后,计算任务完成时间Ttotali,j :
$$
Ttotal_{i,j} = TExe_i + TTrans_i
$$
$$
\begin{cases}
TTrans_i = \frac{TS_i}{RTrans_i \times \log_2 \left(1 + \frac{P_{local} \times d^{-a}_{i,j}}{N_0}\right)} \
TExe_i = \frac{RCpu_i}{SCpu_j}
\end{cases}
$$
其中 TExei和 TTransi分别表示用户 i 将任务迁移到边缘节点 j进行处理所需的执行时间和传输时间。在上述公式中,d− i,j是距离的函数,a的值为4。在边缘节点上处理的任务数据量较小,因此返回时间对任务完成时间的影响可以忽略。资源分配应满足式(23)的截止时间约束。迁移到移动边缘计算节点进行处理时的任务完成时间不超过本地处理的任务完成时间,因此截止时间i 如下:
$$
Ttotal_{i,j} \leq DL_i
$$
$$
DL_i = \frac{RCpu_i}{Freq_{i,local}}
$$
3.2.2 基于双重拍卖的资源分配方案
在移动边缘计算中,双重拍卖交易的物品是边缘节点的通信资源和计算资源。失败用户或具有剩余资源的边缘节点可以继续调整出价以参与下一轮拍卖。由于拍卖持续多轮,为了便于用户和边缘节点出价,本文采用代理机制来完成资源出价。基于双重拍卖的资源分配算法有四个终止条件:(1)系统中没有失败用户;(2)失败用户的出价策略无法再调整;(3)拍卖轮次达到预设的最大拍卖轮数;(4)边缘节点无剩余资源。
3.2.2.1 双重拍卖过程
在资源拍卖过程中,用户 i 通过用户代理提交计算资源需求 RCpui 、通信资源需求 RTrans i 以及单位资源出价 UBidi(UBid i < UValve i )。同时,边缘节点 j 通过节点代理提交总计算资源 CCpuj 、总通信资源 CTrans j 以及单位资源要价 UAsk j (UAskj > UCost j )。在用户代理和边缘节点代理将信息提交给拍卖代理后,拍卖代理根据出价信息确定候选用户和候选边缘节点,并基于贪心方法从候选用户和候选边缘节点中确定获胜用户和获胜边缘节点,并确定资源支付价格。假设用户单位支付的价格与边缘节点的单位奖励相等,即为出价。用户i和边缘节点j的效用如下:
$$
UtilityUser_i = \sum_{j=1}^{N} [a_{i,j} \cdot (UValve_i - Bid) \cdot (RCpu_i + RTrans_i)]
$$
$$
UtilityNode_j = \sum_{i=1}^{M} a_{i,j}[(Bid - UCost_j) \cdot (RCpu_i + RTrans_i)]
$$
$$
\sum_{j=1}^{N} a_{i,j} \leq 1, a_{i,j} \in {0, 1}, 1 \leq i \leq M, 1 \leq j \leq N
$$
3.2.2.2 出价策略
为了最大化用户和边缘节点的效用,本文提出了一种优化的投标策略。在第一轮拍卖中,用户 i 和边缘节点 j 相对乐观,因此用户的初始投标价格较低,而边缘节点的初始要价较高。因此,用户初始单位投标价格设为 0.5UValvei ,边缘节点的初始单位报价设为 2UCostj 。并且 B(t) 表示截至第 t 轮的资源支付价格序列:
$$
B(t) = {[Bid_1(1), Bid_2(1), …, Bid_k(1)], [Bid_1(2), Bid_2(2), …, Bid_p(2)], …, [Bid_1(t), Bid_2(t), …, Bid_q(t)]}
$$
随着拍卖的进行,B(t)的长度也随之增加,出价k(t)表示第k个资源在第t轮拍卖中的支付。如果系统中没有资源支付的历史信息,为了使尽可能多的用户成功参与交易,当前拍卖轮次中未成功的用户将根据具有固定价格调整比率的投标策略调整其出价,并继续参与下一轮拍卖。具有固定价格调整比率的投标策略如下:
$$
UBid_i(t+1) = UBid_i(t) \cdot (1+\omega)
$$
其中 ω表示投标调整比率,设定为10%。如果价格序列B(t)中存在资源支付历史信息,则从B(t)中提取每个拍卖轮次对应的资源支付序列的最大值,形成最高支付序列Bmax(t) ,序列中的最小值构成最低支付序列Bmin(t) 。随着拍卖轮次的增加,由于出价较低而未能成功获取资源的用户以及具有剩余资源的边缘节点将变得越来越悲观。因此,用户i和边缘节点j的乐观系数序列为 λi 和 δj ,且0< λi , δj < 1 。因此,用户i和边缘节点j在第t+ 1拍卖轮次中继续参与拍卖的出价策略如下:
$$
UBid_i(t+1) = \min{\lambda_i(t) \cdot \min[B_{min}(t)] + (1 - \lambda_i(t)) \cdot \max[B_{max}(t)], UValve_i}
$$
$$
UAsk_j(t+1) = \max{\delta_j(t) \cdot \max[B_{max}(t)] + (1 - \delta_j(t)) \cdot \min[B_{min}(t)], UCost_j}
$$
在基于双向拍卖的通信与计算资源分配中,根据贪婪策略将资源分配给出价较高的用户,以最大化系统福利。此外,用户和边缘节点会获知资源分配的结果。系统的总效用是用户和边缘节点效用的总和。系统的效用越大,资源拍卖市场中的资源分配效率就越高。最大化系统总效用的问题可以被定义为一个 0–1整数规划问题。
$$
UtilitySystem = \sum_{i=1}^{M} UtilityUser_i + \sum_{j=1}^{N} UtilityNode_j
$$
$$
s.t. \sum_{j=1}^{N} a_{i,j} \leq 1, 1 \leq j \leq N
$$
$$
s.t. \sum_{i=1}^{M} (a_{i,j} \times RCpu_i) \leq CCpu_j , \sum_{i=1}^{M} (a_{i,j} \times RTrans_i) \leq CTrans_j , 1 \leq i \leq M
$$
$$
s.t. Ttotal_{i,j} \leq DL_i, 1 \leq i \leq M, 1 \leq j \leq N
$$
4 算法描述
4.1 基于遗传算法的计算卸载
算法1中的伪代码介绍了基于遗传算法的动态计算卸载的实现步骤。首先,根据边缘节点数量N和任务n的数量生成初始种群,并分别计算其适应度函数值。然后,按照适应度函数对初始种群进行排序。并根据适应度函数值,通过轮盘赌算法生成下一代种群。最后,根据动态变化的交叉概率p1和变异概率p2执行交叉操作和变异操作。该操作重复进行,直到种群的最大适应度值和平均适应度值变化很小,或已达到最大迭代次数。
在所提出的动态计算卸载算法中,假设遗传算法的迭代次数为period。边缘节点数量记为N。每次迭代中进行选择、交叉和变异操作的次数为k次。因此,该算法的时间复杂度为O(period ×N ×k)。
4.2 基于双重拍卖的资源分配
本文所提出的基于双重拍卖的资源分配算法的实现步骤如下:(1)用户计算对边缘节点的偏好;(2)用户选择偏好最高的边缘节点,并提交初始单位投标价格和资源需求。同时,边缘节点提交初始单位报价并计算计算和通信资源的总量;(3)拍卖代理根据出价确定候选用户和候选边缘节点;(4)基于贪婪策略向单位出价较高的用户分配资源;(5)判断拍卖是否结束。若否,则继续进行拍卖,用户和边缘节点可在下一轮拍卖前调整其出价;若满足拍卖结束条件,则直接终止拍卖,并返回最优资源分配方案和系统效用。
在所提出的基于双重拍卖的资源分配算法中,假设拍卖已进行了t轮。每次迭代的过程可分为三个步骤。首先,根据M个用户的出价和N个边缘节点的要价,生成候选用户和候选节点。然后,在候选用户与候选节点之间进行资源分配。最后,计算在本轮拍卖中失败但仍参与下一轮拍卖的用户和边缘节点的出价策略。因此,算法复杂度为O(M ×N × t)。
5 性能评估
5.1 实验环境
5.1.1 实验设置
本文的实验环境由远程云服务器、边缘节点服务器和用户组成。如图 3 所示,主要设备如下:(1)租用腾讯云主机作为远程云服务器。处理器为 Intel Xeon E5‐2667v4,操作系统为 Ubuntu,系统内核版本为 16.04。(2)共有四个边缘服务器,为用户提供强大的边缘计算和存储能力。具体配置如表 2 所示。(3)移动终端包括不同类型的智能手机和笔记本电脑。终端设备可通过无线接入点访问边缘节点。
表2 边缘节点的配置信息
| 边缘服务器 | 内存 | Disk | CPU |
|---|---|---|---|
| 节点1 | 64 GB | 500 GB | Intel Xeon E5‐2680 v4 @ 2.40 GHz |
| 节点 2 | 64 GB | 1 TB | Intel Xeon Gold 6126 @ 2.60 GHz |
| 节点 3 | 128 GB | 2 TB | Intel Xeon E5‐1680 v2 @ 3.00 GHz |
| 节点 4 | 220 GB | 2 TB | Intel Xeon E5‐2673 v2 @ 3.30 GHz |
5.1.2 测试用例
为了在移动边缘计算环境中测试所提出的动态计算卸载算法,使用 UA‐DETRAC [30] 视频数据集辅助实验。该数据集主要拍摄于中国北京和天津的道路交叉口,视角与交通监控视频类似,由佳能EOS550D相机拍摄。视频帧率为每秒25帧。每帧格式为 JPEG,尺寸为 960 × 540。道路场景包含不同时段和天气条件(图 4)。
对于基于效用的资源分配算法的实验,使用车辆移动轨迹(VMT)数据集[31]来评估不同资源分配算法在移动边缘计算环境中的性能。该VMT数据集包含了德国科隆市一天周期内400平方公里区域的车辆交通信息。在实验中,每辆汽车被视为一个与终端设备相关的移动用户。该VMT数据集还包含车辆的位置和速度等信息。
5.1.3 基准算法和评价指标
为了验证所提出的动态计算卸载模型的性能,将本地计算算法(LC)、移动边缘云环境中的基于粒子群优化的计算卸载算法(COPSO)[32],以及边缘计算环境中的具有延迟和能耗约束的计算卸载算法(CODEC)[33]与本文提出的基于处理延迟和能耗的计算卸载算法进行了比较。LC算法将所有任务放在本地设备上执行,不使用边缘服务器。因此,当计算资源有限时,会对终端设备造成较大的负载。COPSO算法是一种基于多目标优化的计算卸载算法,其考虑了能耗和时间消耗。COPSO算法的优化目标与本文提出的计算卸载算法相同。在CODEC算法中,延迟和能耗被作为评估指标。此外,卸载决策与无线资源和计算资源的分配被联合优化。
为了测试所提出的基于效用的资源分配模型的有效性,本文选择基于盈亏平衡的MEC资源分配算法(SDAB)[34]和感知截止时间的资源分配算法( DORA)[35]作为基准资源分配算法。SDAB算法是一种基于单轮资源拍卖的资源分配算法。在该模型中,移动用户和服务提供商仅进行一轮出价以确定获胜用户。SDAB算法的目标函数是鼓励更多用户参与交易并实现社会效益最大化。在DORA算法中,资源分配场景由一组移动用户和一个边缘节点进行。DORA的目标函数是在任务截止时间和任务丢弃率约束下最大化社会效益。
对于所提出的动态计算卸载算法,处理延迟、能耗和任务权重成本W(任务)在公式(12)中被用作评价指标。此外,为了测试资源分配算法的性能,将系统总效用以及成功拍卖用户数量作为评价指标。
5.2 实验结果与分析
5.2.1 基于处理延迟和能耗的动态计算卸载分析
在计算卸载实验中,所有算法均执行10次,得到实验结果的95%置信区间。权重αk设置为0.5,表示任务执行对处理延迟和执行能耗具有相同的偏好。该权重值可根据不同的应用类型进行配置。在所提出的动态计算卸载算法中,种群大小popsize、最大迭代周期数period以及网络带宽bwx,y 都会影响算法性能。LC算法被用作衡量计算卸载是否能提升性能的标准算法。实验中的参数配置为popsize= 50, period= 30, ω1= 0.2, ω2= 0.4, ω3= 0.3, ω4= 0.6,且带宽为 100Mbps。
图 5a–c 分别展示了随着不同算法迭代次数的增加,处理延迟、能耗和任务权重成本 W(task)的变化趋势。如图 5a 所示,在通信带宽保持不变的情况下,除 LC 算法外,其他计算卸载算法的任务处理延迟随着迭代次数的增加逐渐下降,并最终趋于稳定;而 LC 算法的任务处理延迟一直在较小范围内波动。当算法迭代次数为 100 时,所提出的算法的处理延迟比 LC 算法低 35.80%,比 CODEC 算法低 8.47%,比 COPSO 算法低 5.14%。如图 5b 所示,能耗不同计算卸载算法的能耗随着迭代次数的增加逐渐降低。当算法迭代次数为 100时,所提出的算法的能耗比LC算法低78.74%,比CODEC算法低3.45%,比COPSO算法低6.32%。如图5c所示,除了LC算法外,其他计算卸载算法的任务权重成本W(task)随着迭代次数的增加而逐渐降低。由于LC算法是本地执行的,因此其任务权重成本一直保持为1。当算法迭代次数为100时,所提出的卸载算法在任务权重成本方面比CODEC算法低6.98%,比COPSO算法低 10.12%。
上述实验结果的原因在于,LC算法是用于衡量其他计算卸载算法是否能够提升性能的标准算法。LC算法在本地执行,而不是利用边缘服务器进行计算卸载。本地设备的计算资源有限,当任务量超过本地设备的最大承受能力时,会导致任务队列积压,从而增加算法的延迟和能耗。当任务量

保持不变时,算法的迭代次数对处理延迟、能耗和W(任务)的影响不大。COPSO算法采用粒子群优化来解决计算卸载问题,但粒子群算法存在收敛速度慢的问题。此外,粒子在搜索空间中的种群多样性容易丧失,易陷入局部最优,且难以保证粒子位置的随机性。因此,当迭代次数缓慢增加时, COPSO算法在能耗和W(任务)方面的表现不如CODEC算法。本文所提出的算法综合考虑了任务处理延迟和能耗对计算卸载的影响,为避免遗传算法陷入局部最优,采用了动态变化的交叉概率和变异概率。因此,所提出的计算卸载算法优于LC算法、CODEC算法和COPSO算法。
图 6a–c 显示了处理延迟、能耗和任务权重成本 W(task)随通信带宽变化的趋势。如图 6a 所示,随着通信带宽的增加,不同计算卸载算法的任务处理延迟逐渐降低,最终趋于收敛。当通信带宽为100Mbps时,所提出的算法的处理延迟比LC算法低 32.16%,比CODEC算法低12.78%,比COPSO算法低7.71%。如图 6b 所示,不同算法的能耗随着通信带宽的增加而下降。当通信带宽为100Mbps时,所提出的算法的能耗比LC算法低47.62%,比CODEC算法低24.87%,比 COPSO算法低14.81%。如图 6c 所示,由于LC算法在本地执行,其任务权重成本 W(task)保持为1。其他算法的任务权重成本 W(task)随着通信带宽的增加而减小,最终趋于稳定。当通信带宽为100 Mbps时,所提出的算法比 CODEC低7.71%,比COPSO低9.59%。此外,当带宽较小时,LC算法的处理延迟、能耗和任务权重成本 W(task)低于其他三种计算卸载算法,但随着带宽的增加,LC算法的性能逐渐劣于其他算法。

图6a–c中上述实验结果的原因是,LC算法在本地执行。当任务量保持不变时,通信带宽对任务的本地执行影响不大。然而,当通信带宽非常小时,数据传输能力受限,本地与边缘服务器之间的任务积压将增加,任务的处理延迟、处理能耗以及通信能耗都会增加。随着带宽的增加,边缘服务器处理任务的能力增强,处理延迟、能耗以及W(task)不同计算卸载算法的任务权重成本将降低并趋于稳定。由于COPSO算法将任务卸载分为三部分,除了卸载到边缘服务器和本地执行外,另一部分被卸载到远程云服务器。卸载到远程云服务器的延迟和能耗高于边缘服务。当任务量较大时,COPSO算法会表现出更好的效果。因此,当通信带宽增加时,COPSO算法在能耗和任务权重成本方面的表现不如其他计算卸载算法,且算法稳定性较低。本文所提出的算法能够动态分配本地执行和卸载到边缘服务器的任务比例:当带宽较小时,更多任务将在本地执行;否则将在边缘服务器上执行。因此,本文所提出的算法具有更好的性能。
5.2.2 基于效用最大化的资源分配分析
在移动边缘环境中基于效用最大化的资源分配场景包括部署在基站附近的4个边缘节点,以及数量从10到100不等的用户,这些用户随机分布在边缘节点附近。用户终端设备的本地计算能力在1.5至2.5 GHz之间随机生成,任务数据大小在1000 和 5000 KB。用户所需的资源在 0.2 到 1 GHz 之间随机生成。 Ubidmax和 Ubidmin的值分别为 6.6 和 0.6。
为了验证所提出的资源分配算法的收敛性,当用户数量为20、50和100时,本实验记录了随着拍卖轮次迭代次数增加,效用的变化情况。如图7所示,当用户数量和边缘节点数量保持不变时,随着执行的拍卖轮次增加,移动用户和边缘节点的效用也随之增加。当执行的拍卖轮次较大时,增量速率变小,并最终快速收敛。从图中可以看出,当拍卖算法的迭代次数大于5时,效用基本不再变化,这证明了所提出的资源分配算法具有良好的收敛性,因为效用能够快速收敛到最大值。
图 8 显示了系统总效用随用户数量变化的情况。从图中可以看出,不同资源分配算法所获得的系统总效用随着用户数量的增加而显著上升。其中,所提出的资源分配算法能够获得更高的系统总效用。当用户数量为100时,本文所提出的算法在系统总效用方面比SDAB算法高出14.67%,比DORA算法高出 8.62%。这是因为在所提出的资源分配算法中,用户和移动边缘计算节点在调整下一轮拍卖的出价时,会参考资源拍卖市场中的历史支付信息,并同时考虑移动边缘计算节点出价的变化。因此,在拍卖轮次有限的情况下,出价更加合理,使得更多的用户和移动边缘计算节点能够成功进行资源交易,从而获得更高的系统总效用。
图 9 显示了成功拍卖用户随用户数量变化的趋势。当用户数量为20时, SDAB算法、DORA算法和所提出的资源分配算法获得的平均成功拍卖用户数量分别为20、17和18;当用户数量为100时,成功拍卖用户数量分别为60、65和72。从图中可以看出,各种资源分配算法的成功拍卖用户数量随着用户数量的增加而急剧上升。当用户数量较小时,SDAB算法可以获得较高的成功拍卖用户数量,但随着拍卖参与者数量的增加,基于单轮拍卖的SDAB算法的拍卖交易机制难以反映资源数量与价格波动之间的关系,也无法满足交易个体最大化自身效用的需求
通过价格和数量的结合,在所提出的资源分配算法中,用户和边缘节点根据资源的历史支付信息调整其出价,从而使出价更符合市场规则。因此,在所提出的资源分配算法中,更多用户能够成功获得资源。
6 结论
本文中,首先构建了一种基于处理延迟和能耗的任务权重成本模型,并将任务权重成本作为优化目标,采用遗传算法求解该问题。通过对真实数据集进行一系列对比实验,所提出的计算卸载策略能够有效降低任务执行延迟和能耗。例如,所提出的卸载算法的处理延迟分别比LC算法、CODEC算法和COPSO算法低32.16%、12.78%和7.71%。其次,为了合理分配计算资源并提高边缘服务器的资源利用率,提出了一种基于效用最大化的资源分配策略。在该模型中,为用户和边缘计算节点制定了出价策略,并基于贪婪策略将资源分配给高单价出价用户。通过实验可以看出,所提出的资源分配算法能够提升成功拍卖用户数量并最大化系统效用。例如,与SDAB算法和DORA算法相比,所提出的分配算法可使系统效用分别提升14.67%和8.62%。在未来的工作中,将进一步优化计算卸载中的任务权重成本模型以及资源分配中用户和边缘节点的出价策略。此外,本文所提出的算法还需要在更多应用场景中进行测试。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)