基于线性回归模型的数据分析与预测实践
1.数据预处理的重要性:无论是归一化还是特征工程,都对模型性能有重要影响。合理的特征构造能显著提升模型的预测能力。2.模型选择:SGDRegressor 适合大规模数据,而 LinearRegression 适合一般场景。根据实际数据情况选择合适的模型很关键。3.模型评估:除了 R² 得分,MSE 等指标也能帮助我们全面了解模型性能。可视化则能更直观地展示预测效果。通过以上两个案例,我们展示了线性
基于线性回归模型的数据分析与预测实践
在数据分析与机器学习领域,线性回归是一种经典且常用的方法。本文将通过两个实际案例,分享如何使用线性回归模型进行数据处理、模型训练与预测分析,包括二手车价格预测和保险费用相关分析。相关数据和资料下载链接(0积分):【免费】基于线性回归模型的数据分析与预测实践数据-二手车与医疗数据资源-CSDN下载
一、二手车价格预测实践
1. 数据加载与预处理
首先,我们需要加载二手车数据集并进行必要的预处理:
import numpy as np
import pandas as pd
# 加载数据并选择需要的特征列
df = pd.read_csv('./used_cars.csv', sep=',', header=0)
columns = ['brand','bodyType','fuelType','gearbox','power','kilometer','notRepairedDamage','days','v_0','v_1','price']
df = df[columns]
# 数据归一化处理
df = (df - df.min()) / (df.max() - df.min())
这里我们选择了与二手车价格相关的多个特征,并使用 min-max 归一化将数据缩放到 [0,1] 区间,这有助于提高模型的训练效果。
2. 数据集划分
将数据集分为训练集和测试集,通常采用 8:2 的比例:
# 划分训练集和测试集
train_data = df.sample(frac=0.8, replace=False)
test_data = df.drop(train_data.index)
# 提取特征和目标变量
x_train = train_data.iloc[:, 0:10].values
y_train = train_data['price'].values
x_test = test_data.iloc[:, 0:10].values
y_test = test_data['price'].values
3. 模型训练与保存
使用 SGDRegressor(随机梯度下降回归器)进行模型训练:
from sklearn.linear_model import SGDRegressor
import joblib
import os
# 初始化并训练模型
model = SGDRegressor(
max_iter=1000,
learning_rate='adaptive',
eta0=0.01,
loss='huber'
)
model.fit(x_train, y_train)
# 计算训练集得分
pre_score = model.score(x_train, y_train)
print('训练集得分=', pre_score)
print('模型系数=', model.coef_, '截距=', model.intercept_)
# 保存模型
if not os.path.exists('./save_model'):
os.makedirs('./save_model')
joblib.dump(model, './save_model/SGDRegressor.model')
SGDRegressor 适合处理大规模数据集,这里使用了 huber 损失函数,对异常值具有较好的鲁棒性。
4. 模型评估与可视化
加载保存的模型,在测试集上进行评估并可视化结果:
# 加载模型并预测
model = joblib.load('./save_model/SGDRegressor.model')
y_pred = model.predict(x_test)
# 评估模型
print('测试集准确性得分=%.5f' % model.score(x_test, y_test))
MSE = np.mean((y_test - y_pred) **2)
print('损失MSE={:.5f}'.format(MSE))
# 可视化预测结果
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(9, 3))
ax1 = plt.subplot(111)
x = range(0, len(y_test))
plt.plot(x, y_test, 'g', label='真实值', marker='*', linewidth=0.5)
plt.plot(x, y_pred, 'b', label='预测值', marker='.', linewidth=0.5)
ax1.set_xlabel('样本序号')
ax1.set_ylabel('价格')
plt.legend(loc='upper right')
plt.show()
通过 MSE(均方误差)和 R² 得分评估模型性能,并绘制真实值与预测值的对比图,直观展示模型的预测效果。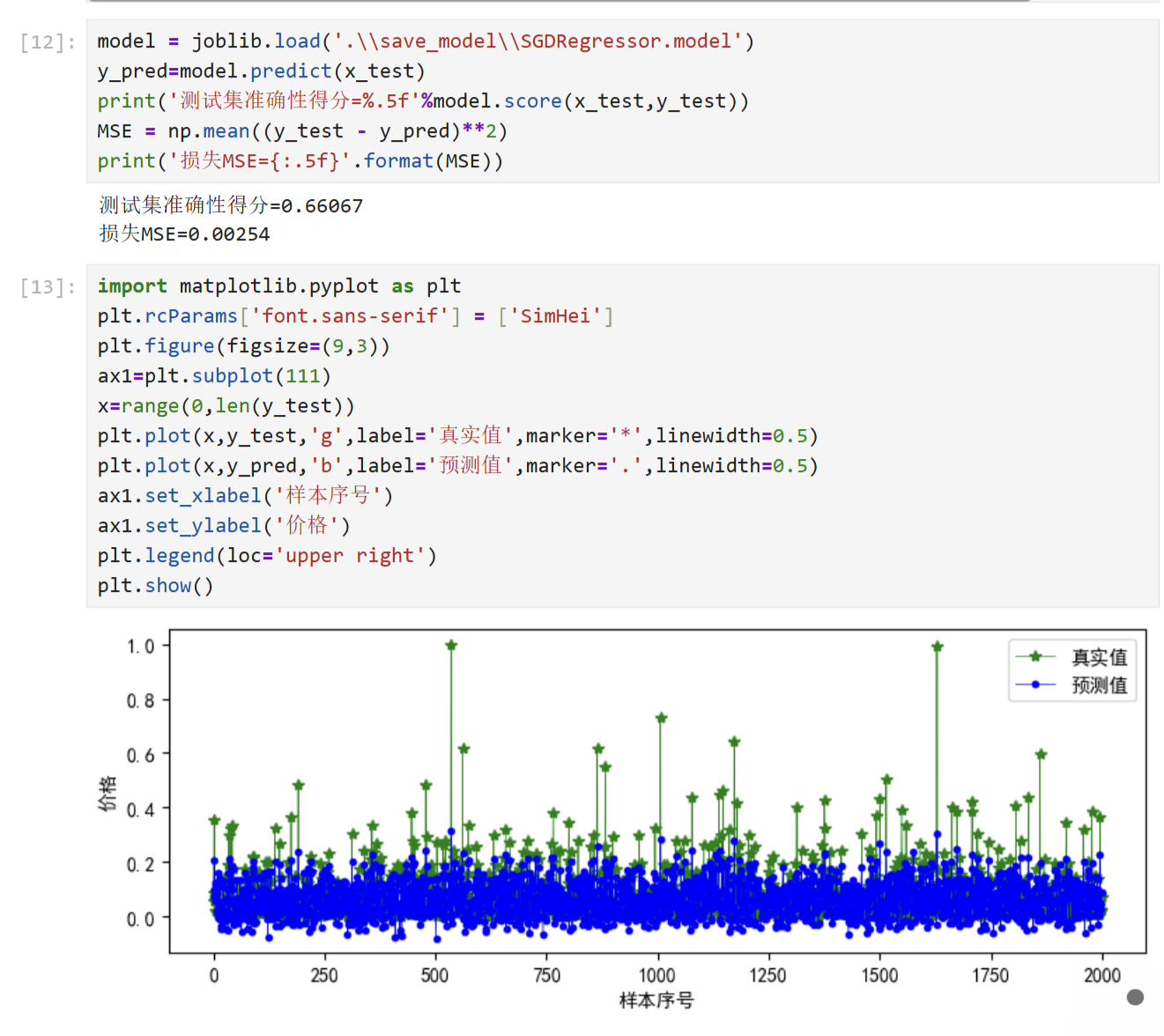
二、保险费用数据分析
1. 数据预处理与特征工程
处理保险数据集,包括类别变量转换和特征构造:
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
# 加载数据
df = pd.read_csv('.\insurance.csv', header=0)
# 类别变量转换为数值
df.loc[df['sex'] == 'female', 'sex'] = 0
df.loc[df['sex'] == 'male', 'sex'] = 1
df.loc[df['smoker'] == 'yes', 'smoker'] = 1
df.loc[df['smoker'] == 'no', 'smoker'] = 0
df.loc[df['region'] == 'southwest', 'region'] = 1
df.loc[df['region'] == 'southeast', 'region'] = 2
df.loc[df['region'] == 'northwest', 'region'] = 3
df.loc[df['region'] == 'northeast', 'region'] = 4
# 构造交互特征:吸烟且BMI>30的人群
def bmi(x):
if x >= 30:
return 1
else:
return 0
df.insert(6, 'bmi_smoker', df['smoker'] * df['bmi'].apply(lambda x: bmi(x)))
# 数据归一化
scaler = MinMaxScaler()
df1 = scaler.fit_transform(df)
# 划分特征和目标变量
train_data = df1[:, [0, 1, 2, 3, 4, 5, 6]]
train_target = df1[:, [7]]
x_train, x_test, y_train, y_test = train_test_split(train_data, train_target, test_size=0.3)
这里我们构造了一个有意义的交互特征bmi_smoker,因为吸烟且肥胖的人群医疗费用可能远高于单独吸烟或单独肥胖的人群。
2. 线性回归模型训练与评估
使用普通线性回归模型进行训练和评估:
from sklearn.linear_model import LinearRegression
# 训练模型
model = LinearRegression()
model.fit(x_train, y_train)
# 评估模型
score = model.score(x_test, y_test)
intercept = model.intercept_
coef = model.coef_
print(f'模型准确性得分{score:.3f}')
# 构建回归方程
func_LR = f'y={intercept[0]:.6f}'
for i in range(0, coef.size):
func_LR += (f'{coef[0][i]:+.6f}x{i}')
print(func_LR)
# 可视化预测结果
plt.rcParams['font.sans-serif'] = ['SimHei']
y_pred = model.predict(x_test)
plt.figure(figsize=(8, 8))
plt.scatter(y_test, y_pred, label='测试集目标值')
plt.plot(y_pred, y_pred, 'r', label='模型预测值') # y=x参考线
plt.legend(loc='upper left')
plt.savefig('保险费用预测.png')
通过打印回归方程,我们可以直观了解各个特征对目标变量的影响程度和方向。散点图则展示了预测值与真实值的偏差程度。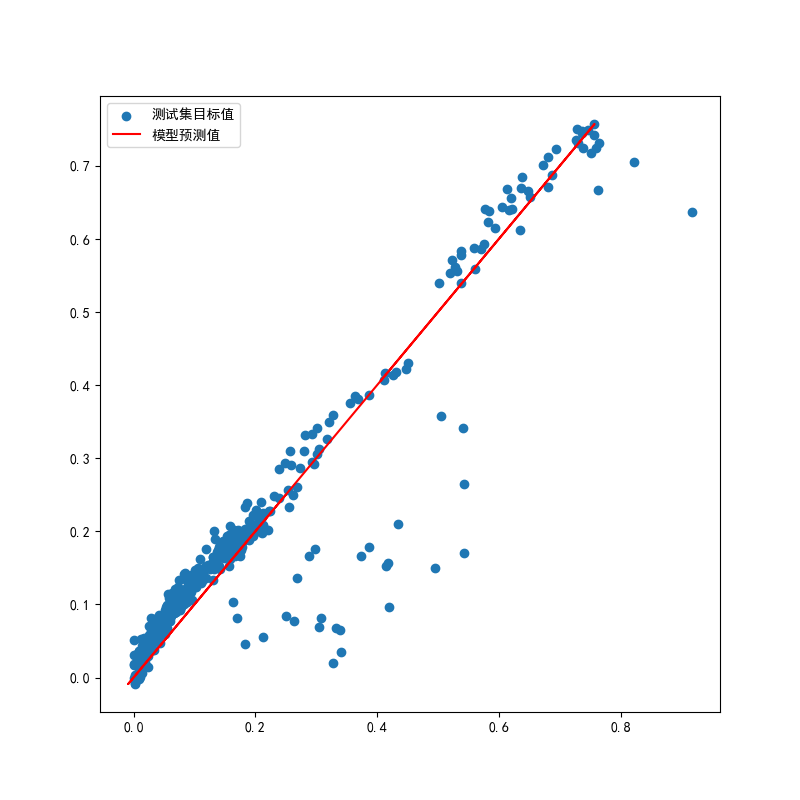
三、总结与思考
1.数据预处理的重要性:无论是归一化还是特征工程,都对模型性能有重要影响。合理的特征构造能显著提升模型的预测能力。
2.模型选择:SGDRegressor 适合大规模数据,而 LinearRegression 适合一般场景。根据实际数据情况选择合适的模型很关键。
3.模型评估:除了 R² 得分,MSE 等指标也能帮助我们全面了解模型性能。可视化则能更直观地展示预测效果。
通过以上两个案例,我们展示了线性回归模型在实际数据分析中的应用流程,从数据加载、预处理、模型训练到评估可视化的完整过程。希望能为大家提供一些实践参考。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)