深度学习笔记4:Pytorch实现反向传播及走出梯度下降第一步
反向传播
目的
反向传播(Backpropagation)是深度学习中训练神经网络的核心算法,其核心意义在于:高效计算神经网络中所有参数(权重和偏置)对损失函数的梯度,为参数更新提供依据,从而让神经网络能够 “学习” 数据中的规律。
在梯度下降的最初,我们需要先找出坐标点所对应的梯度向量。梯度向量,是各个自变量求偏导后的表达式,接着再代入坐标点计算出来的,在这一步骤中,最大的难点在于:如何获得梯度向量的表达式——也就是损失函数对各个自变量求偏导后的表达式。而在神经网络中,就可以使用反向传播达到目的。反向传播为了找出距离和方向。
Pytorch实现反向传播
在实现反向传播之前,首先必须要完成模型的正向传播,并且要定义好损失函数,在此借助之前 的实验中完成的三层神经网络的类和数据(500行,20个特征的随机数据)来进行正向传播,具体结构参照笔记1。
数据准备
import torch
import torch.nn as nn
from torch.nn import functional as F
torch.manual_seed(420)
X = torch.rand((500,20),dtype=torch.float32) * 100
y = torch.randint(low=0,high=3,size=(500,1),dtype=torch.float32)
设计神经网络
class Model(nn.Module):
def __init__(self,in_features=10,out_features=2):
super().__init__()
self.linear1=nn.Linear(in_features,13,bias=True)
self.linear2=nn.Linear(13,8,bias=True)
self.linear1=nn.Linear(8,out_features,bias=True)
def forward(self,x):
sigma1=torch.relu(nn.linear1(x))
sigma2=torch.sigmoid(nn.linear2(sigma1))
zhat=self.output(sigma2)
return zhat
注意:这是一个三分类的神经网络,因此需要调用的损失函数应是:多分类交叉熵函数CEL。CEL类中已经内置了softmax功能,因此需要修改一下网络架构,删除forward前向传播函数中输出层上的softmax函数,并将最终的输出修改为zhat。
input_ = X.shape[1] #特征的数目
output_ = len(y.unique()) #分类的数目
#实例化神经网络类
torch.manual_seed(420)
net = Model(in_features=input_, out_features=output_)
#前向传播
zhat = net.forward(X)
#定义损失函数
criterion = nn.CrossEntropyLoss()
#对打包好的CorssEnrtopyLoss而言,只需要输入zhat
loss = criterion(zhat,y.reshape(500).long())
#此时输出loss可查看损失

net.linear1.weight.grad
#此时查看第一个隐藏层的权重矩阵,不会返回任何值反向传播
backward是任意损失函数类都可以调用的方法,对任意损失函数,backward都会求解其中全部 w的梯度 loss.backward()
loss.backward()net.linear1.weight.grad #返回相应层的权重参数的梯度信息
#梯度是反向传播的核心输出,用于指示 “每个参数需要调整多少才能减少损失”
net.linear1.weight.grad.shape #shape方法查看梯度向量形状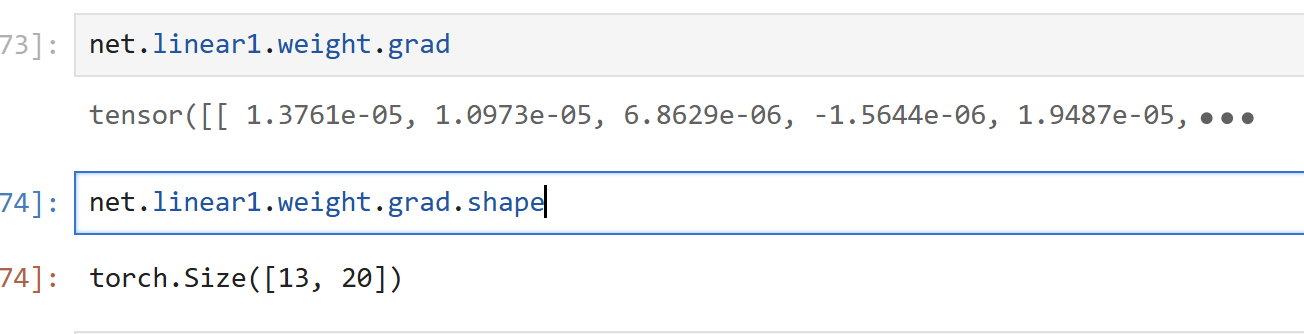
ps:此时也可以查看第二隐藏层和输出层的梯度信息
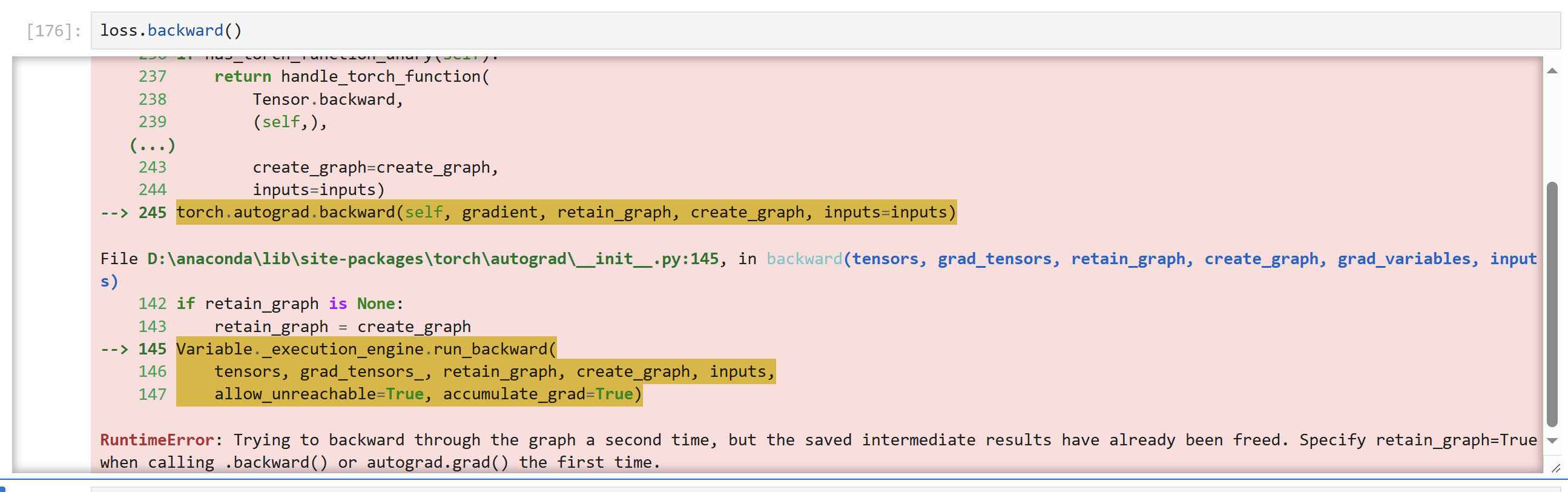
神经网络的反向传播只能进行一次,如果需要再次进行反向传播,则需要重新进行一次正向传播,或在反向传播时设置参数:
loss.backward(retain_graph=True)注意点
当使用nn.Module继承后的类进行正向传播时,我们的权重是自动生成的,在生成时就被自动设置 为允许计算梯度(requires_grad=True),所以不需要自己去设置。
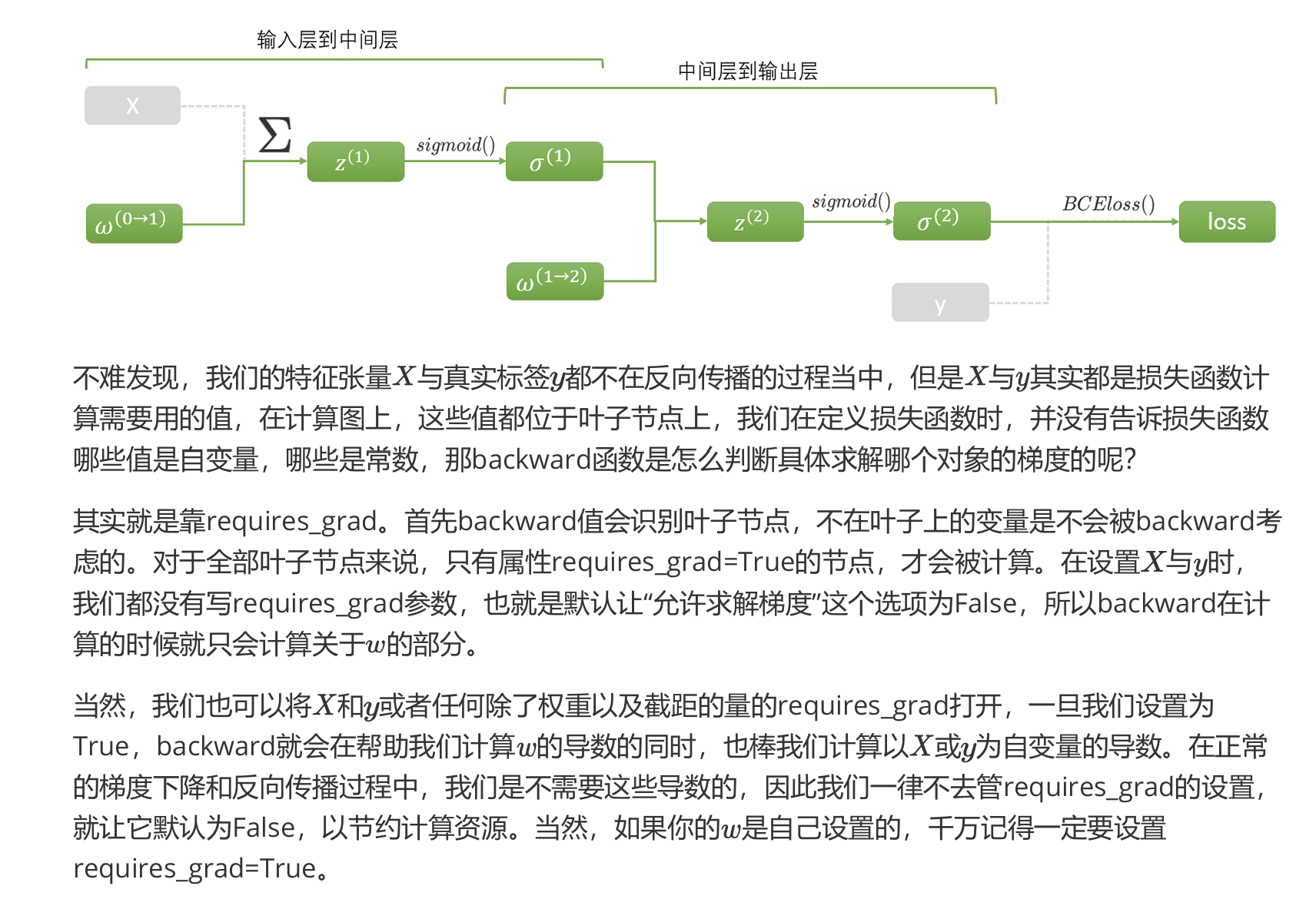
走出梯度下降第一步
权重的迭代公式
:偏导数部分,已经计算出来了,就是使用backward求解出的结果,也就是隐藏层的梯度信息
:学习率,也就是步长,常被写为lr,是迭代开始前人为设置的。
已经有了所有值,可以进行迭代
操作
#w(t+1)=w(t)- 步长* grad
lr =10 #learning_rate 学习率,步长
w = net.linear1.weight.data #.data只取出权重数据,原始权重
dw = net.linear1.weight.grad #梯度
w = w-lr*dw #迭代具体过程
#另一种写法: w -= lr*dw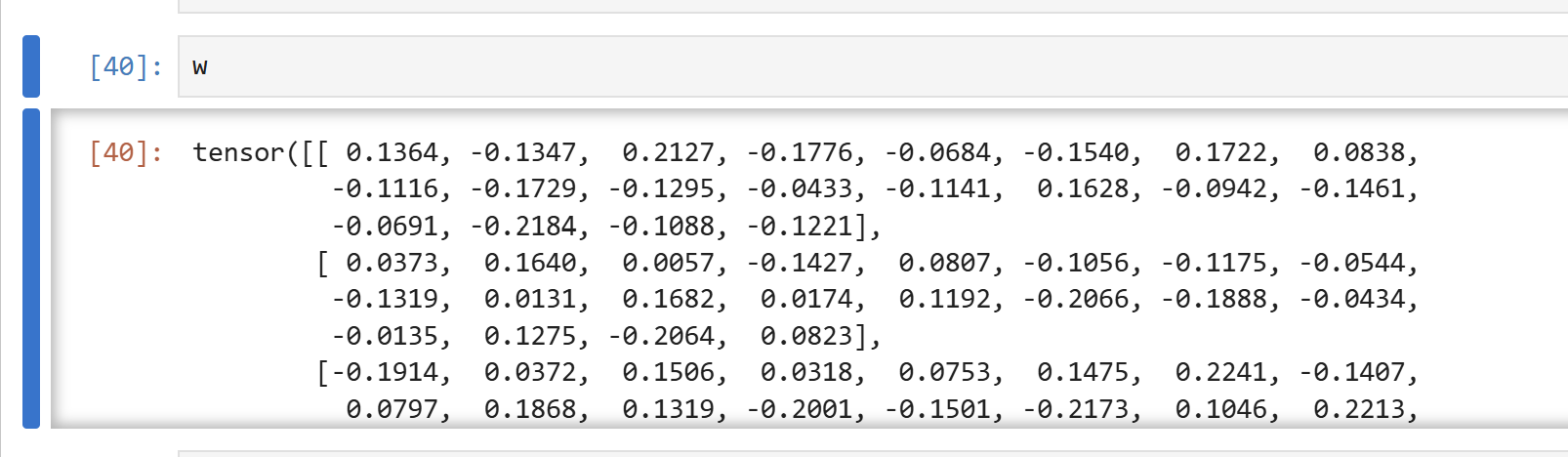
重复执行:w = w-lr*dw,进行手动迭代权重,观察权重变化,下图手动迭代10次后结果图。
普通梯度下降就是在重复: 正向传播->计算梯度->更新权重的过程,但这个过程往往非常漫长。当步长设置为0.001时,几乎看不到w任何的变化,只有当步长设置得非常巨大时,才能够看到一些 改变,但设置巨大的步长可能会跳过真正的最小值,所以也无法将步长设置得很大。无论如何,梯度下降都是一个缓慢的过程。在这个基础上,提出了加速迭代的数个方法,其中一个很关键的方法,就是使用动量Momentum。下一个笔记更新动量法。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 31
31 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)