【MySQL】数据库——超详细
一、什么是MySQL
MySQL是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的RDBMS (Relational Database Management System,关系数据库管理系统)应用软件之一。
MySQL是一种关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
MySQL所使用的 SQL 语言是用于访问数据库的最常用标准化语言。MySQL 软件采用了双授权政策,分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型和大型网站的开发都选择 MySQL作为网站数据库。
二、下载与安装
MySQL官网下载地址:
https://www.mysql.com/cn/![]() https://www.mysql.com/cn/
https://www.mysql.com/cn/
MySQL 安装程序指南
摘要
本文档介绍了 MySQL 安装程序,这是一个简化了各种 MySQL 产品的安装和更新过程的应用程序,包括 和 。
有关详细说明每个 MySQL 安装程序版本中更改的说明,请参阅 。
有关法律信息,请参阅法律声明。
如需有关使用 MySQL 的帮助,请访问MySQL 论坛,您可以在其中与其他 MySQL 用户讨论您的问题。
文档生成时间:2024-07-17(修订版:79056)
目录
三、SQL语句的分类
数据库基础概念
数据库定义:数据库是一个有组织的集合,用于存储和管理数据的系统。它提供数据的快速访问和处理,并支持数据的增加、修改、删除和查询。
数据库管理系统(DBMS):数据库管理系统是数据库的核心组成部分,用于管理数据库的创建、维护、访问和操作。常见的DBMS包括MySQL、Oracle、SQL Server等。
数据模型:不同的DBMS可能支持不同的数据模型,如关系型、文档型、图形型等。MySQL主要支持关系型数据模型。
常见的 SQL 语句分为以下几类:
- DDL(数据定义语言):用于创建、修改和删除数据库对象(如表、视图、索引)。
- create:创建数据库对象
- alert:修改数据库对象的结构
- drop:删除数据库对象
- DML(数据操作语言):用于插入、更新和删除数据。
- select:查询数据
- insert:插入数据
- update:更新数据
- delete:删除数据
- DQL(数据查询语言):用于查询数据。
- DCL(数据控制语言):用于权限管理。
- grant:授予用户权限
- revoke:撤销用户权限
- TCL(事务控制语言):用于管理事务。
- commit:提交事务
- rollback:回滚事务
- savepoint:设置保存点
四、Mysql支持的数据类型
1.数值类型
整数类型
- TINYINT: 一个非常小的整数。存储范围为 -128 到 127,或者 0 到 255(无符号)。
- SMALLINT: 一个小整数。存储范围为 -32768 到 32767,或者 0 到 65535(无符号)。
- MEDIUMINT: 一个中等大小的整数。存储范围为 -8388608 到 8388607,或者 0 到 16777215(无符号)。
- INT 或者 INTEGER: 一个标准整数。存储范围为 -2147483648 到 2147483647,或者 0 到 4294967295(无符号)。
- BIGINT: 一个大的整数。存储范围为 -9223372036854775808 到 9223372036854775807,或者 0 到 18446744073709551615(无符号)。
浮点数类型
- FLOAT: 单精度浮点数。
- DOUBLE: 双精度浮点数。
- DECIMAL 或者 NUMERIC: 用于存储精确的小数。
2.日期和时间类型
- DATE: 日期,格式为 ‘YYYY-MM-DD’。范围从 ‘1000-01-01’ 到 ‘9999-12-31’。
- TIME: 时间,格式为 ‘HH:MM:SS’。范围从 ‘-838:59:59’ 到 ‘838:59:59’。
- DATETIME: 日期和时间,格式为 ‘YYYY-MM-DD HH:MM:SS’。范围从 ‘1000-01-01 00:00:00’ 到 ‘9999-12-31 23:59:59’。
- TIMESTAMP: 时间戳,格式为 ‘YYYY-MM-DD HH:MM:SS’。范围从 ‘1970-01-01 00:00:01’ UTC 到 ‘2038-01-19 03:14:07’ UTC。
- YEAR: 年份,格式为 YYYY。范围从 ‘1901’ 到 ‘2155’。
3.字符串类型
- CHAR: 固定长度字符串。长度从 0 到 255 字节。
- VARCHAR: 可变长度字符串。长度从 0 到 65535 字节。
- TINYBLOB 和 TINYTEXT: 特别小的BLOB(Binary Large Object)和文本数据。最大长度 255 字节。
- BLOB 和 TEXT: BLOB和文本数据。最大长度 65535 字节。
- MEDIUMBLOB 和 MEDIUMTEXT: 中等大小的BLOB和文本数据。最大长度 16777215 字节。
- LONGBLOB 和 LONGTEXT: 特别大的BLOB和文本数据。最大长度 4294967295 字节。
- ENUM: 枚举类型。字符串对象可从特定的集合中选择一个值。
- SET: 一个字符串对象,可以有零个或多个值,每个值必须来自特定的集合。
4.JSON 类型
JSON: 用于存储 JSON (JavaScript Object Notation) 文档。
示例代码
CREATE TABLE json_types_example (
json_col JSON
);5.位类型
BIT: 位字段类型。可用于存储位字段值。
示例代码
CREATE TABLE bit_types_example (
bit_col BIT(8)
);6.空间数据类型
MySQL 还支持用于存储空间数据的类型:
- GEOMETRY: 一种空间数据类型,可以存储任何类型的几何数据。
- POINT: 表示地理空间数据的 x 和 y 坐标。
- LINESTRING: 表示线的一系列点。
- POLYGON: 表示多边形的集合。
示例代码
CREATE TABLE spatial_types_example (
geometry_col GEOMETRY,
point_col POINT,
linestring_col LINESTRING,
polygon_col POLYGON
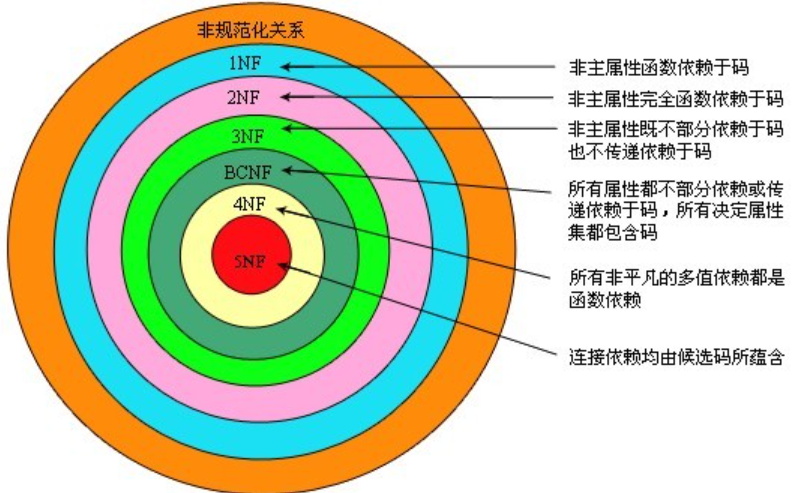
);五、MySQL设计的三大范式
数据库设计中的三个范式,通常称为关系数据库的三个范式,用于规范化数据库模式以减少冗余和数据异常。
第一范式(1NF):确保每个列都具有原子性值,不可再分割。
每个表中的每个字段都包含一个原子值,不可再分割成更小的部分。
避免在同一列中存储多个值,使用多个字段或新表来分隔重复的数据。
第二范式(2NF):确保非主键列完全依赖于主键而不是部分依赖。
数据库表必须符合第一范式。
非主键列必须完全依赖于主键,而不是仅依赖于主键的部分。
如果一个表中存在组合主键,那么非主键列必须依赖于全部组合主键,而不仅仅是其中的一部分。
第三范式(3NF):确保非主键列之间没有传递依赖关系。
数据库表必须符合第二范式。
非主键列之间不能存在传递依赖关系,即不能通过其他非主键列推导出某个非主键列的值。
如果存在传递依赖关系,应该将其移到单独的表中。
六、索引
定义
索引是数据库表中一列或多列的值进行排序的一种结构,可以加快查询速度。
常见索引类型
包括:
普通索引: 是最基本的索引,它没有任何限制
唯一索引: 索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一
主键索引: 是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。
组合索引: 一个索引包含多个列,实际开发中推荐使用组合索引。
全文索引: 全文搜索的索引。FULLTEXT 用于搜索很长一篇文章的时候,效果最好。只能用于InnoDB或MyISAM表,只能为CHAR、VARCHAR、TEXT列创建。
索引的设计原则
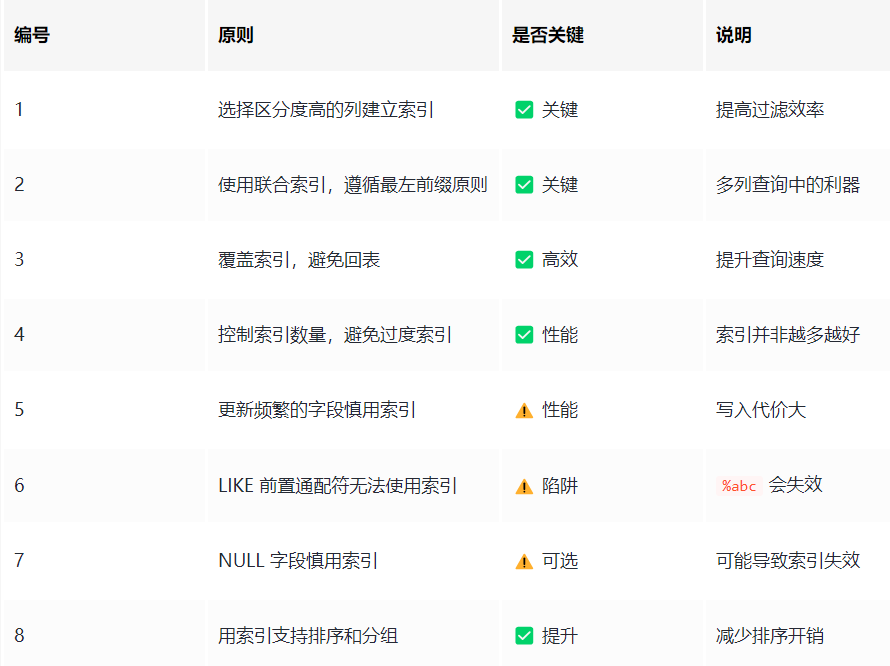
1. 唯一特性的字段,适合创建索引
业务上具有唯一特性(例如唯一约束、主键约束)的字段,即使是组合字段,也必须建成唯一索引。
说明:不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的。
2. 频繁作为where条件的字段,适合创建索引
某个字段在SELECT语句的 WHERE 条件中经常被使用到,那么就需要给这个字段创建索引了。尤其是在数据量大的情况下,创建普通索引就可以大幅提升数据查询的效率。
3. 经常分组或排序查询的字段,适合创建索引
本身索引就已经排好序了,而且B+树叶节点一起组成双向链表,很适合范围查询。很适合建立索引。
索引就是让数据按照某种顺序进行存储或检索,因此当我们使用 GROUP BY 对数据进行分组查询,或者使用 ORDER BY 对数据进行排序的时候,就需要对分组或者排序的字段进行索引。
如果待排序的列有多个,那么可以在这些列上建立联合索引。
4. 增改语句的查询条件字段,适合创建索引
UPDATE、DELETE 的 WHERE 条件列。对数据按照某个条件进行查询后再进行 UPDATE 或 DELETE 的操作,如果对 WHERE 字段创建了索引,就能大幅提升效率。原理是因为我们需要先根据 WHERE 条件列检索出来这条记录,然后再对它进行更新或删除。如果进行更新的时候,更新的字段是非索引字段,提升的效率会更明显,这是因为非索引字段更新不需要对索引进行维护。
5.DISTINCT字段,适合创建索引
有时候我们需要对某个字段进行去重,使用 DISTINCT,那么对这个字段创建索引,也会提升查询效率。因为索引会对数据按照某种顺序进行排序,排序后再去重会快很多。
SELECT DISTINCT 字段列表 FROM 表名;6. 多表连接时,连接表数量别超过3张,where字段和连接字段适合创建索引
首先, 连接表的数量尽量不要超过 3 张,因为每增加一张表就相当于增加了一次嵌套的循环,数量级增长会非常快,严重影响查询的效率。
其次, 对 WHERE 条件创建索引,因为 WHERE 才是对数据条件的过滤。如果在数据量非常大的情况下,没有 WHERE 条件过滤是非常可怕的。
最后, 对用于连接的字段创建索引,并且该字段在多张表中的类型必须一致。比如 course_id 在student_info 表和 course 表中都为 int(11) 类型,而不能一个为 int 另一个为 varchar 类型。
7. 数据范围越小的字段,越适合创建索引
我们这里所说的类型大小指的就是该类型表示的数据范围的大小。
我们在定义表结构的时候要显式的指定列的类型,以整数类型为例,有TINYINT、MEDIUMINT、INT、BIGINT等,它们占用的存储空间依次递增,能表示的整数范围当然也是依次递增。如果我们想要对某个整数列建立索引的话,在表示的整数范围允许的情况下,尽量让索引列使用较小的类型,比如我们能使用INT就不要使用BIGINT,能使用MEDIUMINT就不要使用INT。这是因为:
数据类型越小,在查询时进行的比较操作越快
数据类型越小,索引占用的存储空间就越少,在一个数据页内就可以放下更多的记录,从而减少磁盘I/0带来的性能损耗,也就意味着可以把更多的数据页缓存在内存中,从而加快读写效率。
这个建议对于表的主键来说更加适用,因为不仅是聚簇索引中会存储主键值,其他所有的二级索引的节点处都会存储一份记录的主键值,如果主键使用更小的数据类型,也就意味着节省更多的存储空间和更高效的I/0。
8. 很长的varchar字段,适合创建前缀索引
假设我们的字符串很长,那存储一个字符串就需要占用很大的存储空间。在我们需要为这个字符串列建立索引时,那就意味着在对应的B+树中有这么两个问题:
B+树索引中的记录需要把该列的完整字符串存储起来,更费时。而且字符串越长,在索引中占用的存储空间越大;
如果B+树索引中索引列存储的字符串很长,那在做字符串比较时会占用更多的时间。我们可以通过截取字符串区分度高的前缀子串建立索引,这个就叫前缀索引。这样在查找记录时虽然不能精确的定位到记录的位置,但是能定位到相应前缀所在的位置,然后根据前缀相同的记录的主键值回表查询完整的字符串值。既节约空间,又减少了符串的比较时间,还大体能解决排序的问题。
left()函数用于取字符串前缀。
create table shop(address varchar(120) not null);
alter table shop add index(address(12));完整字段在全部数据中的选择度:
select count(distinct address) / count(*) from shop;通过不同长度去计算,与全表的选择性对比:
count(distinct left(列名, 索引长度))/count(*)【强制】在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度。
说明:索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为 20 的索引,区分度会高达90% 以上,可以使用 count(distinct left(列名, 索引长度))/count(*)的区分度来确定。
9. 区分度高的字段,适合作为索引
10. 联合索引,将频繁查询的列放到左侧
这样也可以较少的建立一些索引。同时,由于"最左前缀原则",可以增加联合索引的使用率。
11. 多个字段都要创建索引时,联合索引优于单值索引
12.单张表索引数建议别超过6个
在实际工作中,我们也需要注意平衡,索引的数目不是越多越好。我们需要限制每张表上的索引数量,建议单张表索引数量不超过6个。原因:
每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大
索引会影响INSERT、DELETE、UPDATE等语句的性能,因为表中的数据更改的同时,索引也会进行调整和更新,会造成负担。
优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,会增加MySQL优化器生成执行计划时间,降低查询性能.
不适合创建索引的情况
1. 在where中使用不到的字段,不要设置索引
2. 数据量小的表,不要设置索引
在数据表中的数据行数比较少的情况下,比如不到 1000 行,是不需要创建索引的。
3. 有大量重复数据的列上,不要设置索引
当数据重复度大,比如高于 10% 的时候,也不需要对这个字段使用索引。
例如100万数据量的学生表,只有10个男生,其他都是女生,性别字段就别设置索引。
4. 经常更新的表,不要创建过多索引
第一层含义:频繁更新的字段不一定要创建索引。因为更新数据的时候,也需要更新索引,如果索引太多,在更新索引的时候也会造成负担,从而影响效率。
第二层含义:避免对经常更新的表创建过多的索引,并且索引中的列尽可能少。此时,虽然提高了查询速度,同时却会降低更新表的速度。
5. 不建议用无序的值作为索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。
6. 删除很少使用的索引
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
7. 不要定义冗余或重复的索引
冗余索引示例:个人信息表,联合索引最左边字段不需再创建索引
CREATE TABLE person_info(
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
birthday DATE NOT NULL,
phone_number CHAR(11) NOT NULL,
country varchar(100) NOT NULL,
PRIMARY KEY (id),
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number),
KEY idx_name (name(10))
);我们知道,通过idx_name_birthday_phone_number 联合索引就可以对name 列进行快速搜索,再创建一个专门针对name 列的索引就算是一个冗余索引,维护这个索引只会增加维护的成本,并不会对搜索有什么好处。
重复索引示例:
CREATE TABLE repeat_index_demo (
col1 INT PRIMARY KEY,
col2 INT,
UNIQUE uk_idx_c1 (col1),
INDEX idx_c1 (col1)
);col1 既是主键、又给它定义为一个唯一索引,还给它定义了一个普通索引,可是主键本身就会生成聚簇索引,所以定义的唯一索引和普通索引是重复的,这种情况要避免。
索引失效
在 MySQL 中,索引有时可能会失效,导致查询性能下降。以下是常见的 14 种场景,在这些场景下,索引可能会失效
1.使用 OR 连接多个条件
场景: 当查询中包含 OR 时,如果 OR 连接的多个条件中有一个没有使用索引,可能会导致索引失效。例:
SELECT * FROM employees WHERE age = 30 OR name = 'John';这个查询中,age = 30可能使用索引,但 name = 'John'没有索引时,MySQL 会放弃使用索引。
2.在查询中使用函数
场景: 如果查询中在索引列上应用了函数,索引可能失效。例:
SELECT * FROM employees WHERE YEAR(birthdate) = 1990;这里对birthdate使用了YEAR()函数,导致索引失效。
3.使用 LIKE 开头的模糊匹配
场景: 当 LIKE 操作符以通配符 % 开头时,索引会失效。例:
SELECT * FROM employees WHERE name LIKE '%John';由于 %位于开头,MySQL 无法使用索引优化查询。
4.在查询条件中使用 NOT
场景: 使用 NOT 操作符时,索引可能会失效,尤其是与 IN 或 LIKE 一起使用时。例:
SELECT * FROM employees WHERE NOT age = 30;NOT会导致索引失效,MySQL 可能会选择全表扫描。
5.使用 IS NULL 或 IS NOT NULL
场景: 当查询条件使用 IS NULL 或 IS NOT NULL 时,索引可能不会被使用。例:
SELECT * FROM employees WHERE salary IS NULL;使用IS NULL时,索引可能不会被有效利用。
6.范围查询后再进行其他条件筛选
场景: 使用范围查询(BETWEEN、<、> 等)后,再添加其他条件,索引可能失效。例:
SELECT * FROM employees WHERE age BETWEEN 30 AND 40 AND name = 'John';这里,age使用了范围查询,name的条件可能无法使用索引。
7.联合索引的列顺序不匹配
场景: 使用联合索引时,如果查询的列顺序与索引创建时的顺序不匹配,索引可能会失效。例:
CREATE INDEX idx_name_age ON employees (name, age);
SELECT * FROM employees WHERE age = 30 AND name = 'John';如果age在联合索引中排在name后面,这种查询会导致索引失效。
8.使用 DISTINCT 或 GROUP BY
场景: 如果查询中使用了 DISTINCT 或 GROUP BY,索引可能无法被完全利用。例:
SELECT DISTINCT name FROM employees WHERE age = 30;DISTINCT 和 GROUP BY可能导致索引不完全被利用。
9.在查询中使用 LIMIT
场景: 当查询包含 LIMIT 子句时,如果没有明确的排序索引,MySQL 可能无法使用索引。例:
SELECT * FROM employees WHERE age = 30 LIMIT 10;如果没有ORDER BY,MySQL 可能不会使用索引来限制结果数量。
10.数据类型不匹配
场景: 如果查询中使用的列的数据类型与索引列的数据类型不匹配,可能导致索引失效。例:
SELECT * FROM employees WHERE salary = '30000';如果salary是INT类型,而查询中使用了字符串类型的30000,索引可能失效。
11.使用 JOIN 时连接条件没有使用索引
场景: 当连接条件(ON 子句)没有涉及索引时,索引会失效。例:
SELECT * FROM employees e JOIN departments d ON e.department_id = d.id;如果department_id没有索引,查询可能会进行全表扫描。
12. 使用 OR 和不等于条件(<>)
场景: 使用 OR 连接时,如果条件中有不等于(<>)操作符,索引可能失效。例:
SELECT * FROM employees WHERE department_id = 1 OR department_id <> 2;这种情况下,索引可能无法完全利用。
13.字符串拼接或连接运算
场景: 当查询条件中对列进行拼接或连接运算时,索引会失效。例:
SELECT * FROM employees WHERE CONCAT(first_name, ' ', last_name) = 'John Doe';这种字符串连接操作会导致索引无法使用。
14.隐式类型转换
场景: 如果查询中对列进行隐式类型转换,索引可能无法使用。例:
SELECT * FROM employees WHERE salary = '30000.00';如果salary列是FLOAT类型,而查询使用了字符串'30000.00',这可能导致隐式类型转换,从而使索引失效。
七、MySQL常用命令
-
查看mysql数据库的版本号:
select version();-
启动MySQL服务:(基于Windows)
net start mysql-
停止MySQL服务:
net stop mysql-
登录MySQL数据库:
mysql -u 用户名 -p 其中,用户名是MySQL用户名,接着根据系统提示输入密码即可
-
如果安装MySQL时没有设置root密码,可以使用以下命令登录:
mysql -u root-
退出 MySQL 命令行界面:
exit或者quit-
显示所有的数据库名:
show databases;-
创建数据库:
create database 数据库名;-
切换到特定的数据库:
use 数据库名;-
查看当前使用的数据库名:
select database();-
删除数据库:
drop database 数据库名;-
显示数据库中的表:
show tables;-
创建表:
create table 表名 (
列名1 数据类型,
列名2 数据类型,
...
);-
删除表:
drop table 表名;-
向表中插入数据:
insert into 表名(列名1, 列名2, ...)
VALUES (具体值1, 具体值2, ...);-
在表中查询特定的数据:
select 列名1, 列名2, ...
from 表名
where 查询条件;- 不需要查询条件时:
select 列名1, 列名2, ...
from 表名;-
获取某表的所有数据:
select * from 表名-
获取某表的结构:
desc 表名;
也可使用
describe 表名;-
更改表中某列的名字:
alert table 表名 rename column 原始列名 to 新列名;-
为表中某列指定一个别名(并不改变表结构中列的名称)
select 原始列名 as 新列名 from 表名;八、MySQL数据处理函数
(1)单行处理函数:指在SQL中用于处理单个值的函数。它们接受一个或多个输入参数,并返回一个单一的结果。
以下是一些常见的 SQL 单行处理函数:
UPPER():将字符串转换为大写。例如:SELECT UPPER('hello')将返回'HELLO'。
LOWER():将字符串转换为小写。例如:SELECT LOWER('WORLD')将返回'world'。
LENGTH():返回字符串的长度。例如:SELECT LENGTH('abcde')将返回5。
SUBSTRING():提取字符串的一个子串。例如:SELECT SUBSTRING('Hello,World!', 1, 5)将返回'Hello'。如果我们将参数 1 改为 7,即 SELECT SUBSTRING(‘Hello, World!’, 7, 5),结果将返回子串 ‘World’,因为它从第 7 个字符开始提取,长度为 5 个字符。
CONCAT():将多个字符串连接起来。例如:SELECT CONCAT('Hello', ' ', 'World')将返回'Hello World'。
TRIM():去除字符串前后的空格。例如:SELECT TRIM(' hello ')将返回'hello'。
ROUND():对数值进行四舍五入。例如:SELECT ROUND(3.14159, 2)将返回3.14。
ABS():返回数值的绝对值。例如:SELECT ABS(-10)将返回10。
COALESCE():返回参数列表中第一个非空的值。例如:SELECT COALESCE(NULL, 'default')将返回'default'。
NOW():返回当前日期和时间。例如:SELECT NOW()将返回当前的日期和时间。
(2)多行处理函数:指在 SQL 中用于处理多个值的函数。它们接受多个输入参数,并返回一个结果集,可以包含多行和多列。
以下是一些常见的 SQL 多行处理函数:
COUNT():计算满足条件的行数。例如:SELECT COUNT(*) FROM employees将返回employees表中的行数。对于查询
SELECT COUNT(employee_id) FROM employees,它将返回 employees 表中 employee_id 列中非空值的行数。
SUM():计算数值列的总和。例如:SELECT SUM(salary) FROM employees将返回employees表中所有员工的薪资总和。
AVG():计算数值列的平均值。例如:SELECT AVG(salary) FROM employees将返回employees表中所有员工的薪资平均值。
MIN()和MAX():分别返回数值列的最小值和最大值。例如:SELECT MIN(salary), MAX(salary) FROM employees将返回employees表中员工的最低和最高薪资。
GROUP_CONCAT():将多行值连接为一个字符串。例如:SELECT GROUP_CONCAT(name) FROM employees将返回employees表中所有员工姓名的逗号分隔列表。
GROUP BY子句:按照指定的列对结果进行分组。例如:SELECT department, AVG(salary) FROM employees GROUP BY department将按部门计算员工薪资的平均值,并对结果进行分组。
HAVING子句:在GROUP BY分组结果上进行过滤。例如:SELECT department, AVG(salary) FROM employees GROUP BY department HAVING AVG(salary) > 5000将返回薪资平均值大于 5000 的部门。
九、MySQL连接查询
连接查询用于在多个表之间建立关系,并检索满足特定条件的数据。
常见的连接类型如下:
内连接
1.内连接(INNER JOIN):返回两个表中满足连接条件的匹配行。只有在两个表中都存在匹配的值时,才会返回结果。
SELECT *
FROM table1
INNER JOIN table2 ON table1.column = table2.column;2.等值连接(Equi Join):一种基于相等条件进行连接的连接类型。在等值连接中,两个表通过一个或多个列的值相等来建立连接。
假设我们有两个表:employees 和 departments,它们分别包含员工的信息和部门的信息。这两个表中都有一个共同的列 department_id,我们可以使用该列来进行等值连接,以获取每个员工所在的部门。
SELECT *
FROM employees
INNER JOIN departments ON employees.department_id = departments.department_id;在这个查询中,我们使用了 INNER JOIN 进行连接,连接条件是 employees.department_id = departments.department_id。这意味着只有在 employees 表中的 department_id 值等于 departments 表中的 department_id 值时,才会返回匹配的行。
3.非等值连接(Non-Equi Join):一种基于不相等条件进行连接的连接类型。在非等值连接中,两个表根据不相等的条件来建立连接。
假设我们有两个表:orders 和 discounts,分别包含订单信息和折扣信息。我们想要找出订单总额大于折扣金额的订单。
SELECT orders.order_id, orders.total_amount, discounts.discount_amount
FROM orders, discounts
WHERE orders.total_amount > discounts.discount_amount;在这个查询中,使用了 WHERE 子句来指定连接条件,即 orders.total_amount > discounts.discount_amount。这表示只有在 orders 表中的 total_amount 值大于 discounts 表中的 discount_amount 值时,才会返回匹配的行。
4.自连接(Self Join):指在同一个表内进行连接操作。在自连接中,我们将表视为两个不同的实体,并使用相同表的别名来建立连接关系。
假设我们有一个表 employees,其中包括员工的姓名和直接上级的员工ID。我们想要获取每个员工及其直接上级的姓名。
SELECT e.employee_name, m.employee_name AS manager_name
FROM employees e
INNER JOIN employees m ON e.manager_id = m.employee_id;在这个查询中,我们使用了别名 e 和 m 来表示同一个表 employees 的两个实体。我们通过连接条件 e.manager_id = m.employee_id 来建立员工与其直接上级员工的连接关系。
外连接
1.左连接(LEFT JOIN):返回左表的所有行,以及与右表满足连接条件的匹配行。如果右表中没有与左表匹配的行,则对应的右表列将显示为 NULL。
SELECT *
FROM table1
LEFT JOIN table2 ON table1.column = table2.column;2.右连接(RIGHT JOIN):返回右表的所有行,以及与左表满足连接条件的匹配行。如果左表中没有与右表匹配的行,则对应的左表列将显示为 NULL。
SELECT *
FROM table1
RIGHT JOIN table2 ON table1.column = table2.column;3.全连接(FULL JOIN):返回左表和右表的所有行,并将它们组合在一起。如果某行在其中一个表中有匹配,而在另一个表中没有匹配,对应的列将显示为 NULL。
SELECT *
FROM table1
FULL JOIN table2 ON table1.column = table2.column;十、MySQL约束
在MySQL中,约束(Constraints)是用来确保数据库表中数据的准确性和可靠性的规则。它们限制了可以插入表中的数据类型,从而保证了数据的完整性。如果数据操作违反了约束,该操作将被终止。
创建约束: 约束可以在使用CREATE TABLE语句创建表时指定,也可以在表创建后使用ALTER TABLE语句添加。例如,创建一个带有约束的表的语法如下:
CREATE TABLE table_name (
column1 datatype constraint,
column2 datatype constraint,
column3 datatype constraint,
);常见的MySQL约束包括:
NOT NULL:确保列不可以有NULL值。
UNIQUE:确保列中的所有值都是不同的。
PRIMARY KEY:是NOT NULL和UNIQUE的组合,唯一标识表中的每一行。
FOREIGN KEY:防止破坏表之间的链接。
CHECK:确保列中的值满足特定条件。
DEFAULT:为列设置默认值,如果未指定值则使用此默认值。
约束的分类:
列级约束:直接应用于列。
表级约束:应用于整个表。
示例: 创建带有列级约束的表:
CREATE TABLE teachers(
id INT PRIMARY KEY,
stuName VARCHAR(20) NOT NULL UNIQUE,
gender CHAR(1) CHECK(gender='W' OR gender='M'),
seat INT UNIQUE,
age INT DEFAULT 18
);创建带有表级约束的表:
CREATE TABLE students (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
age INT NOT NULL DEFAULT 18,
gender CHAR CHECK(gender IN ('W','M')),
tid INT,
CONSTRAINT fk FOREIGN KEY(tid) REFERENCES teachers(id)
);修改表时添加或删除约束: 可以使用ALTER TABLE语句修改表的约束。例如,添加一个新的列级约束或删除一个现有的表级约束。
主键与唯一约束的区别:
主键(PRIMARY KEY):保证唯一性,不允许为空,一个表中最多只能有一个,允许组合但不推荐。
唯一(UNIQUE):保证唯一性,允许为空,一个表中可以有多个,允许组合但不推荐。
十一、MySQL事务
事务 是指在数据库中执行的一组操作,这些操作要么全部成功,要么全部失败。事务的主要目的是确保数据的一致性和完整性。事务具有四个重要特性,简称为 ACID:原子性、一致性、隔离性和持久性。
事务的特性
原子性(Atomicity):事务中的所有操作要么全部完成,要么全部不完成。如果事务中的某个操作失败,整个事务将被回滚到开始状态。
一致性(Consistency):事务必须使数据库从一个一致性状态变换到另一个一致性状态。事务完成后,数据必须符合所有的预设规则。
隔离性(Isolation):一个事务的执行不能被其他事务干扰。并发执行的事务之间不能互相影响。
持久性(Durability):一旦事务提交,对数据库的修改将永久保存,即使系统故障也不会丢失。
MySQL 中的事务操作
在 MySQL 中,事务可以分为隐式事务和显式事务。隐式事务是指 MySQL 自动管理事务的开启和提交,而显式事务则需要开发者手动控制。
隐式事务
隐式事务在执行 INSERT、UPDATE、DELETE 等操作时,MySQL 会自动开启和提交事务。是否开启隐式事务由变量 autocommit 控制。
-- 查看 autocommit 变量
SHOW VARIABLES LIKE 'autocommit';显式事务
显式事务需要手动开启、提交或回滚。可以使用以下两种方式:
-
使用 SET 命令:
SET autocommit=0; -- 关闭自动提交
-- 执行事务操作
COMMIT; -- 提交事务
ROLLBACK; -- 回滚事务-
使用 START TRANSACTION 命令:
START TRANSACTION; -- 开启事务
-- 执行事务操作
COMMIT; -- 提交事务
ROLLBACK; -- 回滚事务事务的隔离级别
事务的隔离级别决定了在并发环境下,事务之间的隔离程度。MySQL 提供了四种隔离级别:
读未提交(READ UNCOMMITTED):最低的隔离级别,可能导致脏读、不可重复读和幻读。
读已提交(READ COMMITTED):避免脏读,但可能导致不可重复读和幻读。
可重复读(REPEATABLE READ):避免脏读和不可重复读,但可能导致幻读。MySQL 默认的隔离级别。
串行化(SERIALIZABLE):最高的隔离级别,避免所有并发问题,但性能较差。
可以使用以下命令查看和设置隔离级别:
-- 查看当前隔离级别
SHOW VARIABLES LIKE 'transaction_isolation';
-- 设置隔离级别
SET GLOBAL transaction_isolation = 'READ-COMMITTED';示例
以下是一个简单的事务示例:
-- 开始事务
START TRANSACTION;
-- 执行一些SQL语句
UPDATE accounts SET balance = balance - 100 WHERE user_id = 1;
UPDATE accounts SET balance = balance + 100 WHERE user_id = 2;
-- 提交事务
COMMIT;
腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 42
42 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)