笔记:对yolov8网络代码的学习
先对代码进行学习,方便日后的改写,比如添加p2层等。
目录
2.4.Neck —— 特征融合层(PAN + FPN 结构)
2.5.Head —— 检测头(Decoupled Head)
1.获取yolov8模型网络的yaml
方法一:全部下载(包括其他初始设置如残差网络,卷积基本参数等)
进入ultralytics的github官网,下载yolo的相关文件:https://github.com/ultralytics/ultralytics
下载后解压打开,找到路径:ultralytics/cfg/models/v8这个相对路径。
方法二:只下载yaml或者直接复制
选择只下载yaml文件:https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/v8
2.查看代码和结构
2.1.实例查看
源文件:yolov8.yaml
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLOv8 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolov8
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 129 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPS
s: [0.33, 0.50, 1024] # YOLOv8s summary: 129 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPS
m: [0.67, 0.75, 768] # YOLOv8m summary: 169 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPS
l: [1.00, 1.00, 512] # YOLOv8l summary: 209 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPS
x: [1.00, 1.25, 512] # YOLOv8x summary: 209 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPS
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
我们可以结合yolo结构图片来观察和思考:
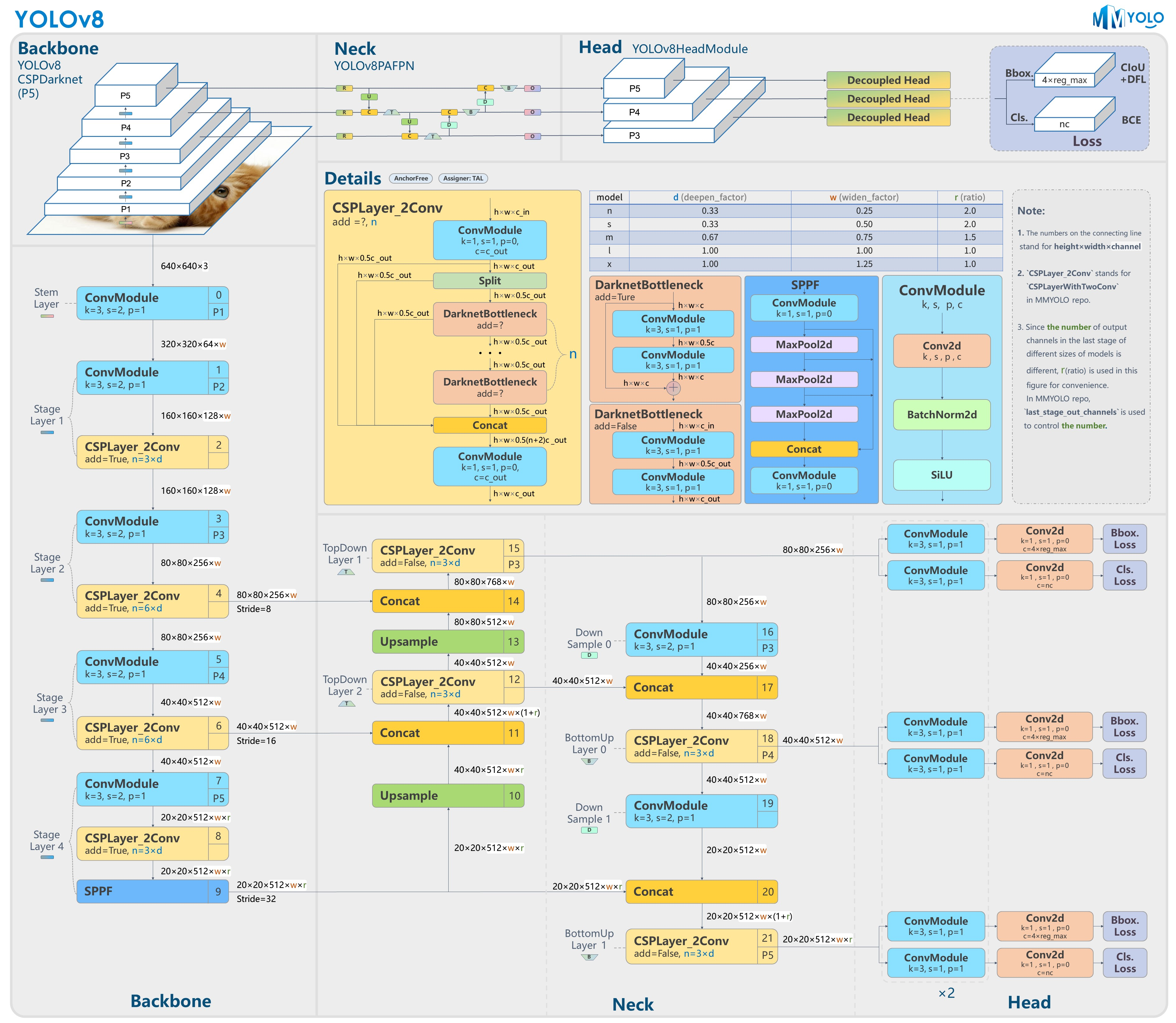
2.2.结构总览
YOLOv8 是一种 端到端目标检测/分割框架,由三个主要部分构成:
| 模块 | 名称 | 功能 |
|---|---|---|
| Backbone | YOLOv8-CSPDarknet (P5) | 提取多尺度特征 |
| Neck | YOLOv8-PAN-FPN | 融合特征金字塔,增强跨层信息 |
| Head | YOLOv8-Head-Module | 解耦检测头,预测类别与边界框 |
数据流动顺序是:
输入图像 → Backbone → Neck → Head → Detect → Loss
在 yaml中的格式定义为:
backbone:
- ...
head:
- ...
其中的每一行结构格式为:
[from, repeats, module, args]
表示输入索引、重复次数、模块类型、参数。
如
[-1, 1, Conv, [64, 3, 2]]表示从上一个输出开始,执行 1 次卷积(3×3 核,stride=2,输出64通道)
如果把第一个参数改成2会发生什么?
-1表示使用上一层的输出作为输入。
2表示使用索引为 2 的层输出(即第三层的输出)作为输入。
写法 实际输入来源 意义 -1紧邻的上一层(index = 当前层 - 1) 连续计算,默认正常链式结构 2第三层(index = 2) 跳过前面几层,重新取某个早期输出 YOLO 系列中,所有线性串接层都默认使用
-1,表示:“以上一层的输出作为输入”。因此变成2意义不大,甚至还有越界的风险。
如果把第二个参数改成2会发生什么?
连续执行 2 次 Conv 模块,每次使用相同的参数。
相当于这里修改网络为:
[-1, 1, Conv, [64, 3, 2]] [-1, 1, Conv, [64, 3, 1]] # 相当于又加了一层同参数卷积
那这里的stride怎么变成1了呢?
在
ultralytics/nn/tasks.py(或早期版本的models/yolo.py)中,有如下逻辑(伪代码):# pseudo-code for i, (f, n, m, args) in enumerate(model_def): module = eval(m) # 模块类(如 Conv, C2f, etc.) if n > 1: # 当 repeats > 1 时,生成一个 Sequential 容器 layers = [module(c_in, *args)] args[1] = 1 # <-- 关键:后续重复的 stride 全部强制设为1 for _ in range(n - 1): layers.append(module(layers[-1].ch_out, *args)) module = nn.Sequential(*layers) else: module = module(c_in, *args)当某层
repeats = n > 1时,框架会自动生成 n 个连续的相同模块,但只有第一个保持原始 stride,其余的 stride 都强制改为 1。这是为了保证 空间尺寸不会被重复下采样。
重复次数 stride 执行效果 输出尺寸 1 次 640 → 320 ✅ 正常 2 次(不改 stride) 640 → 160 ❌ 错误,下采样太多 2 次(第二次 stride=1) 640 → 320 ✅ 正确逻辑
上面提到的640和320都是啥?
表格里提到的 “640 → 320” 并不是随意写的,而是根据 输入图像尺寸(通常 640×640)与每层卷积的 stride 参数 计算出来的结果。
当不进行图片大小的超参设置时YOLOv8以640为默认,即
imgsz = 640这表示输入图像经过预处理(
letterbox)后,会变成 640×640×3。在 YOLO 默认的 padding 规则下:
对于 stride=2 且 kernel=3, padding=1 的卷积,输出尺寸恰好是输入尺寸的一半。
I:输入尺寸;
P:padding;
K:kernel size;
S:stride。
如果对卷积神经网络运算不懂的参见:笔记:卷积神经网络(CNN)-CSDN博客
2.3.Backbone —— 特征提取主干网络
backbone:
- [-1, 1, Conv, [64, 3, 2]] # Stem 层:640→320
- [-1, 1, Conv, [128, 3, 2]] # Stage1:320→160
- [-1, 3, C2f, [128, True]] # CSP块,保持尺寸
- [-1, 1, Conv, [256, 3, 2]] # Stage2:160→80
- [-1, 6, C2f, [256, True]] # 更深层特征
- [-1, 1, Conv, [512, 3, 2]] # Stage3:80→40
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # Stage4:40→20
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 多尺度汇聚
Conv 模块:用于降采样 + 通道扩展;
C2f(Cross-Stage Partial Fusion):YOLOv8 核心替代 CSP 模块的改进结构,增强梯度流;
SPPF:多感受野池化,提升上下文感知。
经过如上backbone网络中,输出的特征为:
P3 (80×80×256), P4 (40×40×512), P5 (20×20×1024)
为什么特征图在backbone中逐渐变小而通道却逐渐变多?
首先我们应该明确什么是通道(channel),假设输入一张标准RGB图片(640×640×3)
3就是通道数(channel number)代表的是 R,G,B三个通道。也可以理解为,这个图片是由R图,G图,B图三张图片融合而成。
在卷积层中,每个卷积核(filter)会扫描整张图像并提取一种特定特征:
例如:
Conv(in_channels=3, out_channels=64, kernel=3x3)表示就是,我输入是3通道的,用64个大小3×3的卷积核(每个卷积核都从3通道输入中学一个特征),输出变成了64通道的。
那么一个卷积核是如何将3通道的特征图变成一个特征图的呢?
这个问题就比较简单了,如果想让640×640×3的图变成输出通道为64,那么我们用64个3×3×3的卷积核就可以了。每个卷积核会覆盖输入的所有通道,但只产生 一个 输出特征图(feature map)。
为什么 C2f 在不同层的重复次数不同?
在
yolov8.yaml的 官方backbone 中,C2f 的定义如下:- [-1, 3, C2f, [128, True]] # 层 2 - [-1, 6, C2f, [256, True]] # 层 4 - [-1, 6, C2f, [512, True]] # 层 6 - [-1, 3, C2f, [1024, True]] # 层 8可以看到:
浅层(低通道) → repeats 比较少;
中层 → repeats 增加;
深层(高通道) → repeats 减少。
实际上:YOLOv8 的 C2f repeats 是根据层的特征复杂度与分辨率动态配置的:
网络深度 特征图尺寸 通道数 C2f repeats 原因 浅层 (P2/4) 分辨率大 (160×160) 通道较少 (128) 3 捕捉低级特征(边缘、纹理)即可 中层 (P3/8, P4/16) 分辨率中等 (80~40) 通道增多 (256~512) 6 信息密集,需要更深的融合 深层 (P5/32) 分辨率小 (20×20) 通道很高 (1024) 3 语义强但空间小,过深反而浪费
“分辨率越小,通道越多 → 重复次数反而减少”
C2f 的两个参数含义是什么?
C2f(c, shortcut=True) [-1, 3, C2f, [128, True]]
参数 类型 作用 第一个参数 (c) int 输出通道数(例如 128、256、512 等) 第二个参数 (shortcut) bool 是否启用残差连接(Residual Connection) 第一个参数不过多赘述。
shorcut=True/False表示是否在每个 bottleneck 中启用“捷径连接(Residual Connection)”。其结构为:
y = x + F(x)若为 False,则只用 F(x)。
浅层 shortcut=True,保证梯度传递稳定;
深层 shortcut=False,防止重复通道干扰。
x+F(x) 里的 “x” 到底是谁?
- x 是输入特征(直接来自上一个模块);
- F(x) 是该模块(例如几层卷积 + BN + 激活)提取的特征;
- y 是输出(融合后的特征)。
如果不用残差,网络要学习从零开始重建所有信息。但有了残差,网络只需要学习“差异”,即哪些地方需要修正。
C2f内部如何实现此运算?
在 YOLOv8 源码中(
ultralytics/nn/modules.py)的C2f结构可以展开成:# 伪代码简化版 class C2f(nn.Module): def __init__(self, c1, c2, shortcut=True, n=1): super().__init__() self.cv1 = Conv(c1, c2 // 2, 1, 1) self.cv2 = Conv(c2 * 2, c2, 1, 1) self.m = nn.ModuleList(Bottleneck(c2 // 2, c2 // 2, shortcut) for _ in range(n)) self.shortcut = shortcut def forward(self, x): y = [] x = self.cv1(x) for m in self.m: x = m(x) y.append(x) out = torch.cat(y, dim=1) return self.cv2(out)每个
Bottleneck内部结构是:def forward(self, x): y = self.cv2(self.cv1(x)) return x + y if self.shortcut else y这个
x就是上一次迭代输入到当前 bottleneck 的特征;如果 shortcut=True,就执行
x + F(x);如果 False,就只输出
F(x)。
而整个残差的计算过程如下:
- 输入通道 c1 被分成两部分。一部分直接保留(shortcut path),一部分进入主分支(main path)进行卷积处理。
- 堆叠多个 Bottleneck 模块(深度 n)。每个 Bottleneck 内部包含:两个卷积(Conv-BN-SiLU);一个短残差连接(内部 shortcut);用来在主支内部形成局部残差流,增强特征重用。
- 跨阶段融合(第 1 次融合)。当主分支通过多层 Bottleneck 后,会产生多个中间输出;这些输出会被 逐级收集(concatenate);与之前未经过卷积的那部分 shortcut path 汇合,得到一个融合特征。
- 整合卷积(第 2 次融合)。将上一步融合的结果(concat 后的多分支特征)通过一个
1×1卷积;作用:压缩通道;再次融合信息;输出与输入尺寸保持一致。
为什么官方默认所有 C2f 都是 shortcut=True?
YOLOv8 的 backbone 是非常深的结构:
多层 Conv + 多层 C2f;
如果不加 shortcut,梯度在深层传播会逐渐衰减;
shortcut=True 让梯度能“绕过”卷积直接传回浅层,保证训练稳定。
残差链接的好处:
Ultralytics 官方在 2023 年 YOLOv8 的 ablation study(消融实验)中发现:
效果 原因 更快收敛 梯度能直达浅层 防止梯度消失 有直连路径 防止特征丢失 输入特征保留 精度提升 低层与高层信息结合更丰富
模型 shortcut=True shortcut=False mAP@50 YOLOv8n ✅ ❌ +1.1% YOLOv8s ✅ ❌ +0.8% YOLOv8m/l ✅ ❌ +0.5%
2.4.Neck —— 特征融合层(PAN + FPN 结构)
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 20→40
- [[-1, 6], 1, Concat, [1]] # 与 P4 拼接
- [-1, 3, C2f, [512]] # 输出 40×40×512
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 40→80
- [[-1, 4], 1, Concat, [1]] # 与 P3 拼接
- [-1, 3, C2f, [256]] # 输出 80×80×256 (P3)
- [-1, 1, Conv, [256, 3, 2]] # 80→40
- [[-1, 12], 1, Concat, [1]] # 与 P4 融合
- [-1, 3, C2f, [512]] # 输出 P4
- [-1, 1, Conv, [512, 3, 2]] # 40→20
- [[-1, 9], 1, Concat, [1]] # 与 P5 融合
- [-1, 3, C2f, [1024]] # 输出 P5-
上采样 + 拼接:自上而下的 FPN 路径;
-
再通过下采样 + 拼接:形成 PAN 路径;
-
目的是将高语义(P5)与低层细节(P3)结合,形成平衡的特征金字塔。
问题
自动/备用措施
拼接通道不一致
插入 1×1 Conv 自动对齐
Upsample 抖动
改用
bilinear模式Neck 梯度过大
层冻结或降低
depth_multiple
为什么yolov8的官方yaml中neck被放在了head中统称head?
在 架构定义 YAML 文件(如 yolov8.yaml) 中,Neck 被并入 Head 区块 的原因既是实现简化、也是框架演进结果。
在 YOLOv8 官方
yolov8.yaml中,大体分为两部分:backbone: - [模块定义...] head: - [模块定义...]没有再单独列出 “neck”。但注意:head 部分的前几层(例如 C2f + upsample + concat 结构)实际上就是原本 FPN/PAN 的 neck。
上采样和下采样融合的优势是什么?
下采样:将特征图的空间分辨率降低(宽高变小),同时增加通道数(特征维度)。
上采样:将特征图的空间分辨率提高(宽高变大),以便和浅层特征对齐融合。
对于不同层级的特点,我们可以理解为:
浅层(高分辨率):细节多,纹理、边缘清晰;
深层(低分辨率):语义强,能识别“是什么”;
中层:介于两者之间,表示物体的部分结构。
特征层 优点 缺点 浅层特征 精细、定位准 不理解语义(容易误检) 深层特征 语义强、识别准 空间分辨率低、定位模糊 上下采样融合的核心优势在于:
- 不同大小的目标(小/中/大)在不同尺度特征图中表现不同;
- 通过上采样融合后,模型可以同时利用多个尺度的特征;
- 检测头可以在 P3(小目标)、P4(中目标)、P5(大目标)上预测。
这正是 YOLOv8 多输出 Head 的基础:
Detect([P3, P4, P5]) # 三个尺度检测头
残差规定了一半留下一半送入bottleneck,上下采样融合这一块,是怎么规定这个“量”的?
上采样–下采样融合属于特征拼接(feature fusion),
此时不是“分流一半”,而是全量特征拼接。举例:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 上采样 ×2 - [[-1, 6], 1, Concat, [1]] # 与浅层特征拼接 - [-1, 3, C2f, [256, False]] # 融合卷积
- 深层特征
x_deep(低分辨率) → 上采样 ×2- 与浅层特征
x_shallow(高分辨率)在通道维度拼接- 此时通道数翻倍(例如 256 + 256 = 512)。
- 融合卷积(例如 C2f)对拼接后的 512 通道特征再进行“压缩”和“融合”
Conv(512, 256, 1, 1)这样恢复目标通道数。
Concat层的第一个参数为什么有两个?- [[-1, 6], 1, Concat, [1]]这行在 YOLOv8 的结构定义中非常典型,出现在 上采样–融合部分(Neck)。
位置 含义 [-1, 6]输入来源(可以有多个) 1重复次数(这里只执行一次) Concat模块类型 [1]模块参数 因为 Concat 需要两个输入特征图:
-1表示上一层的输出(深层上采样特征);6表示来自 backbone 第 6 层的输出(浅层高分辨率特征)。因此这些参数也可以改成别的,但是前提是:
- 空间尺寸(H×W)必须一样;
- 拼接方向必须正确;
- 通道数拼接后不要太大。
- [[-1, 4], 1, Concat, [1]] ✅ 允许,只要第4层特征和当前上采样输出尺寸相同 - [[-1, 8], 1, Concat, [1]] ⚠️ 可能不匹配(如果第8层特征尺寸不同)
上采样的最后一个参数里面都是什么?
举例:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
参数位置 含义 默认值 [0]输出尺寸(可为 None) None [1]缩放因子(scale_factor) 2 [2]上采样模式(插值方式) 'nearest' ①
None→ 指定目标尺寸(size)如果想让上采样到特定大小,可以手动写:[640] ,但 YOLO 中使用
None,表示不固定输出大小,而是依靠缩放倍数(scale_factor)。②
2→ 缩放倍数(scale_factor)
- 表示在空间维度上放大 2 倍;
- 例如 40×40 → 80×80;
- 可以改成 4、1.5 等浮点数,但必须保持后续层尺寸匹配。
③
'nearest'→ 上采样模式上采样时的插值方式,有几种可选:
YOLOv8 默认
模式 说明 特点 'nearest'最近邻插值 快速,YOLO 默认 'bilinear'双线性插值 平滑但稍慢 'bicubic'三次插值 视觉更柔和 'trilinear'3D 插值 用于体数据,不适用YOLO 'nearest'是为了:
加速;
避免在边界引入模糊;
保持与训练一致性。
2.5.Head —— 检测头(Decoupled Head)
最后的 Detect 模块对应解耦头(Decoupled Head):
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 10
- [[-1, 6], 1, Concat, [1]] # 11
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 13
- [[-1, 4], 1, Concat, [1]] # 14
- [-1, 3, C2f, [256]] # 15
- [-1, 1, Conv, [256, 3, 2]] # 16
- [[-1, 12], 1, Concat, [1]] # 17
- [-1, 3, C2f, [512]] # 18
- [-1, 1, Conv, [512, 3, 2]] # 19
- [[-1, 9], 1, Concat, [1]] # 20
- [-1, 3, C2f, [1024]] # 21
- [[15, 18, 21], 1, Detect, [nc]] # 22- [[15, 18, 21], 1, Detect, [nc]] # 三尺度检测头| 项 | 含义 |
|---|---|
[[15, 18, 21]] |
输入来源层索引(from) |
1 |
重复次数(repeats) |
Detect |
模块类型(module) |
[nc] |
模块参数(args) |
| 层号 | 名称 | 尺寸 | 作用 |
|---|---|---|---|
| 15 | P3 特征层 | 80×80 | 小目标检测 |
| 18 | P4 特征层 | 40×40 | 中目标检测 |
| 21 | P5 特征层 | 20×20 | 大目标检测 |
其原理:
网络在完成 Backbone 特征提取和 Neck 多尺度融合后,会输出三组特征图(P3、P4、P5),分别对应小、中、大目标。Head 在每个尺度上分别建立两条并行分支——一条用于 边界框回归(预测目标位置与尺寸,即 x、y、w、h),另一条用于 分类预测(判断该区域属于哪一类)。这两条分支各自经过独立的卷积层后再融合输出,从而避免了分类与定位任务共享参数造成的梯度冲突,使得模型在高精度和高速度之间取得平衡。最终 Head 生成的每个网格单元都输出 (4 + nc) 个数值,分别对应框坐标与各类别置信度。
其中:4 是边界框坐标;nc 是类别概率;
其流程:
在推理(检测)过程中,YOLOv8 Head 会同时处理来自 P3、P4、P5 三个特征层的张量;每个特征层在空间上覆盖输入图像的不同尺度区域。模型首先通过 Head 的卷积层输出预测张量,再经过一个 Anchor-Free 解码过程:将相对坐标(中心点偏移 + 宽高比例)还原为输入图像上的绝对坐标。接着计算每个候选框的置信度(objectness × class probability),并使用 NMS(非极大值抑制) 去除重叠框。最终,网络保留下每张图上置信度最高的预测框,实现从多尺度特征图到最终检测结果的完整流程。
但是在上面我们已经提到,YoloV8的neck和head已经合并为一体了,并且一致叫head。
head:标记以下所有层(Upsample → Concat → C2f → Conv → Detect)都属于 Head。
也就是说:
backbone: → 特征提取
head: → 特征融合 + 检测输出(官方统称 head)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)