深度学习进阶(五)——强化学习与决策智能:让模型学会行动
一、前言:从“预测”到“决策”的跃迁
在深度学习的发展历程中,卷积网络学会了「看」,Transformer 学会了「读」,而生成模型学会了「写」。
但智能的终极形态,不仅是理解与表达,还包括「行动」。
强化学习(Reinforcement Learning, RL)正是让机器从经验中学习决策策略的核心方法。
如果说监督学习是在教模型“该输出什么”,
那么强化学习是在教模型“该做什么”。
与分类、回归等任务不同,强化学习不依赖大量标注样本。
它关注的是一个更真实的问题:
当模型身处一个动态环境时,如何通过试错获得最大奖励?
这是自动驾驶、机器人控制、游戏 AI、智能推荐系统乃至 ChatGPT 的「RLHF(强化学习人类反馈)」的基础。
本篇文章将从直觉到数学推导,再到算法实现,完整梳理强化学习的核心框架:
-
强化学习的基本概念;
-
马尔可夫决策过程(MDP);
-
价值函数与策略;
-
动态规划与 Q-learning;
-
策略梯度与 Actor-Critic;
-
现代算法:PPO、SAC;
-
RLHF 在大模型中的应用。
二、直觉理解:机器如何“试着去做”
强化学习的核心思想可以用一句话概括:
「做 → 看结果 → 学会下次该怎么做得更好。」
它与人类的经验学习非常接近。
小孩第一次学走路,会摔倒无数次,但每次摔倒后会调整重心——这就是「反馈信号」。
强化学习正是模拟这种机制:
模型不断与环境交互,观察状态、采取动作、获得奖励,并更新策略。
整个过程是闭环的:
状态(state) → 动作(action) → 奖励(reward) → 新状态(state') → ...
模型目标是找到一个最优策略(policy),在长期累计奖励最大化的前提下,做出正确的决策。
三、形式化定义:马尔可夫决策过程(MDP)
强化学习问题通常用 马尔可夫决策过程(Markov Decision Process, MDP) 表示。
一个 MDP 可以定义为一个五元组:

其中:
-
SSS:状态集合(state space)
-
AAA:动作集合(action space)
-
P(s′∣s,a)P(s'|s,a)P(s′∣s,a):状态转移概率(state transition)
-
R(s,a)R(s,a)R(s,a):奖励函数(reward function)
-
γ∈[0,1]\gamma \in [0,1]γ∈[0,1]:折扣因子(discount factor)
折扣因子的意义在于,未来的奖励权重会逐渐降低,防止模型“过于贪心未来”。
目标是最大化期望累计奖励:
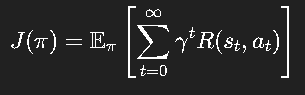
其中 π(a∣s)\pi(a|s)π(a∣s) 是策略,即在状态 s 下采取动作 a 的概率。
四、价值函数:衡量“好不好”的核心
强化学习中最核心的思想是“值”(Value):
值函数告诉我们,在当前状态下,如果遵循某个策略,长期来看到底有多好。
常见的两个函数:
-
状态价值函数:
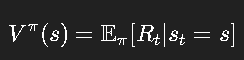
-
动作价值函数(Q 值):
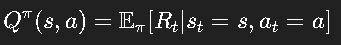
两者关系:
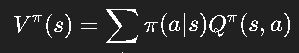
如果我们能准确估计 Q(s,a)Q(s,a)Q(s,a),就能直接找到最优动作:
![]()
五、动态规划与 Bellman 方程
强化学习的数学基础是 Bellman 方程,它揭示了“当前价值”和“下一步价值”的递推关系。
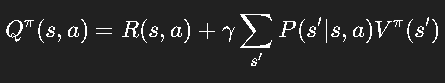
或在最优情况下:
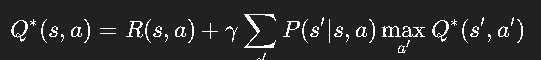
这就是 Bellman 最优方程。
它意味着:
当前的最优值 = 立即奖励 + 折扣后的未来最优值。
这种递推关系构成了所有 RL 算法的理论基石。
六、值迭代与 Q-learning
(1)值迭代
值迭代(Value Iteration)直接利用 Bellman 方程进行迭代更新,直到收敛:
V[s] = max_a (R(s, a) + gamma * sum(P(s'|s, a) * V[s']))
当状态空间较小时,这种算法简单且有效。
(2)Q-learning
Q-learning 是一种无模型(model-free)算法,不需要知道环境转移概率,只通过经验样本更新:
![]()
伪代码:
for each episode:
s = env.reset()
while not done:
a = epsilon_greedy(Q, s)
s_next, r, done = env.step(a)
Q[s,a] = Q[s,a] + alpha * (r + gamma * max(Q[s_next]) - Q[s,a])
s = s_next
核心机制:
-
探索与利用(Exploration vs. Exploitation)
-
探索:尝试新的动作(可能获得更好奖励);
-
利用:选择当前最优动作;
-
-
ε-greedy 策略:以 ε 的概率随机探索,以 1-ε 的概率选择最优动作。
Q-learning 让智能体能通过反复试错,不依赖模型结构,学习出近似最优策略。
七、从 Q-learning 到深度 Q 网络(DQN)
当状态空间巨大(如 Atari 游戏)时,传统 Q-table 无法存储所有状态。
于是 DeepMind 在 2015 年提出 DQN(Deep Q-Network),用神经网络来近似 Q 函数。
核心思路:
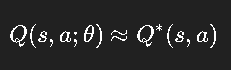
算法引入两大关键技术:
-
经验回放(Experience Replay)
-
将交互经验存入缓冲区;
-
训练时随机采样,打破时间相关性。
-
-
目标网络(Target Network)
-
复制一个延迟更新的网络,用于计算目标 Q 值,避免震荡。
-
伪代码:
replay_buffer = []
for each step:
replay_buffer.append((s,a,r,s_next))
batch = random_sample(replay_buffer)
target = r + gamma * max(Q_target(s_next))
loss = mse(Q_main(s,a), target)
update(Q_main)
DQN 的成功(Atari 游戏超越人类)标志着深度学习与强化学习的第一次完美结合。
八、策略梯度与 Actor-Critic 框架
Q-learning 适用于离散动作空间,而在连续控制任务(如机械臂)中就不再适用。
此时我们引入另一类算法:策略梯度(Policy Gradient)。
策略梯度的目标是直接优化策略参数 θ\thetaθ,最大化期望奖励:
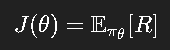
其梯度为:
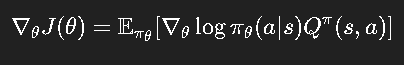
这就是著名的 REINFORCE 算法。
伪代码:
for each episode:
collect (s,a,r)
G = discounted_reward()
theta += alpha * grad(log(pi(a|s))) * G
Actor-Critic 框架
为降低方差,引入 价值函数基线(baseline),同时维护两个网络:
-
Actor:生成动作;
-
Critic:评估动作价值。
梯度更新:
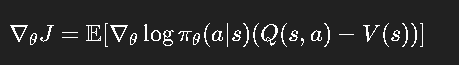
这样既保留策略优化的灵活性,又具备值函数的稳定性。
代表算法包括:
-
A2C / A3C(同步与异步版本);
-
DDPG(确定性策略梯度,适用于连续动作);
-
SAC(Soft Actor-Critic,熵正则化策略,提高探索性);
-
PPO(Proximal Policy Optimization,最流行的稳定算法)。
九、现代强化学习的核心算法:PPO 概览
PPO(Proximal Policy Optimization)通过限制策略更新幅度,避免了梯度爆炸与性能退化。
它的核心思想是:
不让新策略离旧策略太远。
关键目标函数:
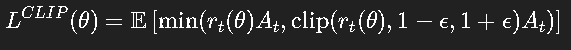
其中:
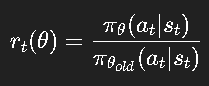
实现时简单高效,是当前主流 RL 与 RLHF 的基础。
十、RLHF:从强化学习到 ChatGPT
RLHF(Reinforcement Learning from Human Feedback)是强化学习在大语言模型中的关键应用。
过程如下:
-
监督微调(SFT):
用人工标注数据微调模型,使其生成高质量回答。 -
奖励模型(Reward Model):
人类对多条回答进行排序,训练一个模型预测“哪条更好”。 -
强化学习优化(PPO):
使用奖励模型作为环境,模型通过 PPO 优化生成策略。
伪代码简化:
for each prompt:
outputs = policy.generate(prompt)
reward = reward_model(outputs)
loss = PPO_clip(policy, old_policy, reward)
RLHF 的目标不是获得最大奖励,而是让模型对齐人类偏好,从而输出符合人类价值的内容。
这也是 ChatGPT、Claude、Gemini 等系统具备“温度感”的核心。
十一、现实挑战与展望
强化学习虽强大,但仍存在难点:
-
奖励设计困难(Reward Engineering);
-
样本效率低;
-
训练过程不稳定;
-
泛化性差。
未来方向:
-
基于模型的强化学习(Model-based RL):让智能体学习环境动态,提升样本利用率。
-
分层强化学习(Hierarchical RL):拆分复杂任务为子目标。
-
结合大模型的决策智能:让语言模型成为策略生成器,强化学习负责行动执行。
-
世界模型(World Model):融合感知、记忆与推理,模拟现实世界的学习过程。
十二、结语:智能的下一步,是“会行动”
强化学习让机器从被动的“模式匹配”者,变成主动的“策略制定者”。
它不再依赖人类告诉它“正确答案”,而是自己去探索“什么是对的”。
正如 DeepMind 的 AlphaGo 改变了围棋,ChatGPT 改变了语言交互,未来的强化学习将改变「决策」。
无论是在无人驾驶、智能机器人还是通用人工智能中,RL 都是连接“理解”与“行动”的关键桥梁。
看得懂世界,是理解;
动得起世界,才是智能。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)