深度学习5-张量运算函数-张量索引操作-形状操作-拼接操作-自动微分模块-机器学习案例:线性回归
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
1. 张量统计运算函数
常见运算函数:
sum()求和
mean()求均值
max()/min()求最大/最小值及其索引
argmax()/argmin()求最大值/最小值的索引
std()求标准差
unique()去重
sort()排序
tensor1 = torch.randint(1,10,(3,2,4))
print(tensor1)

tensor1.sum()
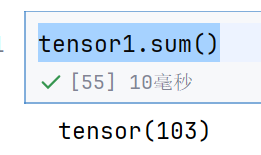
这个就是所有相加
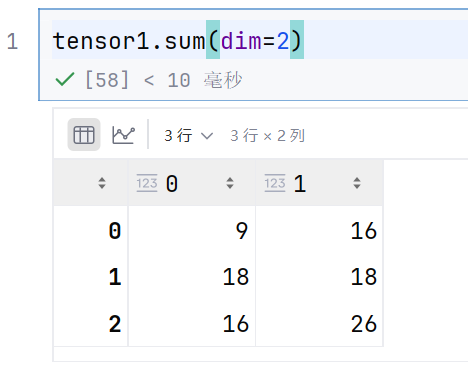
tensor1.sum(dim=0)
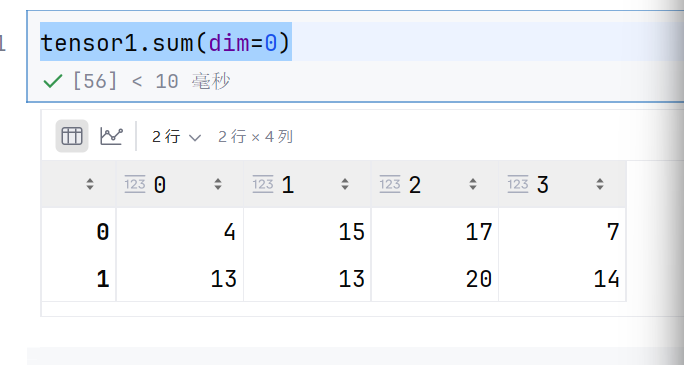
这个就是对第一维度进行求和,就是去掉3,生成2*3的矩阵
可以想象为立方体,竖着求每个单位的和
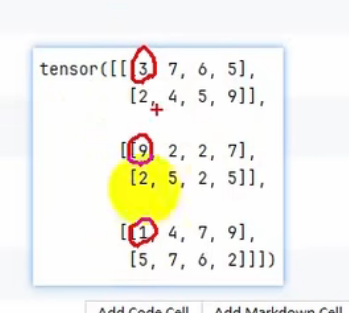
比如1+2+1=4
tensor1.sum(dim=1)
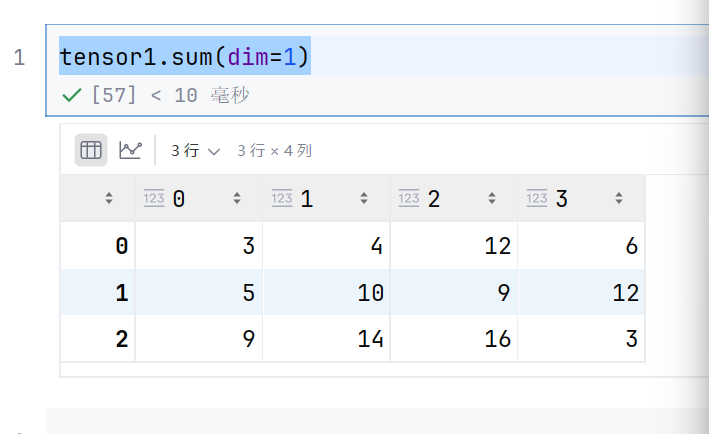
去掉第二维度,就变成3*4的矩阵了

我们来看这个,怎么变成三行四列呢------》前面两行合并,中间两行合并,最后两行合并就可以了
去掉第三维度,就变成3*2了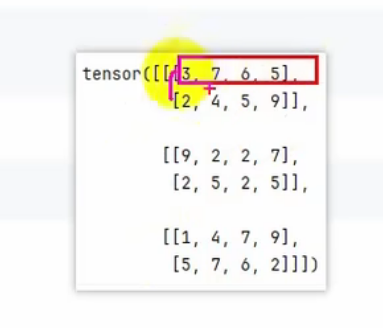
就是四合一了
也就是按行求和
就是看怎么合并,横着x,还是竖着y,还是怎么样z
tensor1 = tensor1.float()
print(tensor1.mean())
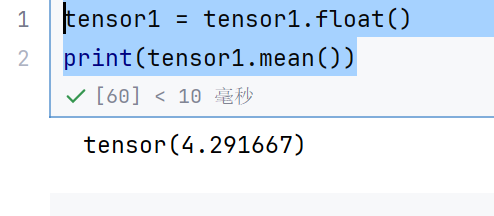
求平均值要用浮点数
print(tensor1.mean(dim=2))
还是变成3*2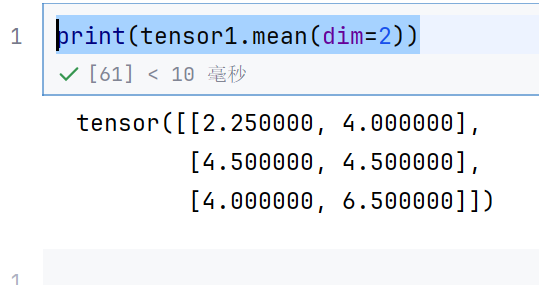
和前面求和是一样的道理
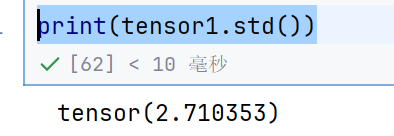
print(tensor1.std())
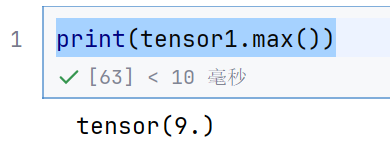
print(tensor1.max())
print(tensor1.min(dim=2))

values就是每一行的最小值
indices就是取得最小值的索引号,就是在每一行的最小值的索引
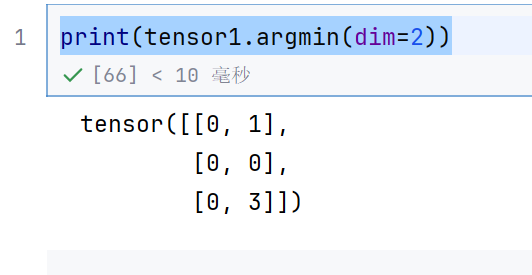
print(tensor1.argmin(dim=2))
print(tensor1.argmin())
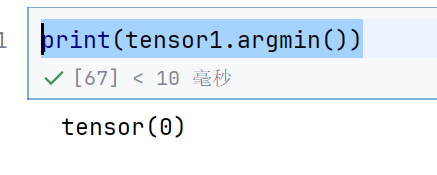
这里的索引是相当于平铺的索引
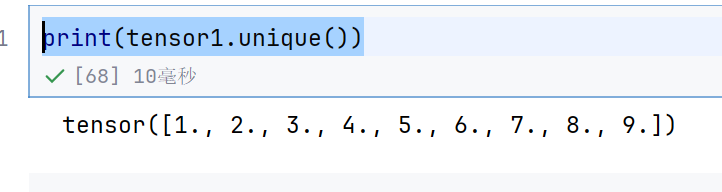
print(tensor1.unique())
print(tensor1.unique(dim=2))
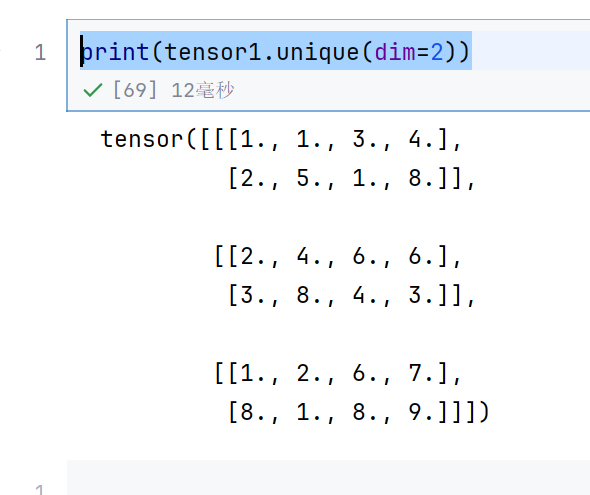
按行去重,有行相同的–》去掉
print(tensor1.sort())
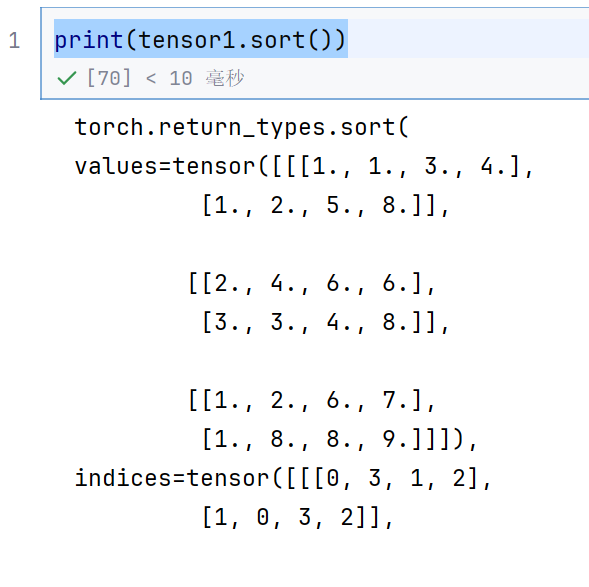
这个排序就默认就按照行进行排序了,默认dim=2
indices是在原始数组中行的索引
2. 张量索引操作
2.1 简单索引
tensor1 = torch.randint(1, 9, (3, 5, 4))
print(tensor1)


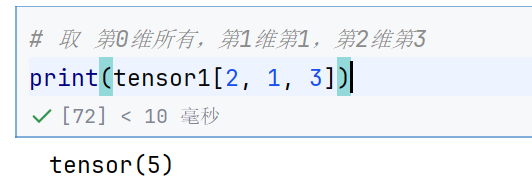
# 取 第0维所有,第1维第1,第2维第3
print(tensor1[2, 1, 3])
print(tensor1[2, 3])

这个就是直接输出一行了
# 取 第0维第0
print(tensor1[0])

# 取 第0维所有,第1维第1
print(tensor1[:, 1])

这个就是取所有的索引为1的行
# 取 第0维第1到最后
print(tensor1[1:])
print()

# 取 第0维最后,第1维1到3(包含3),第2维0到2(包含2)
print(tensor1[-1:, 1:4, 0:3])

print(tensor1[-1:, 1:4:2, 0:3])
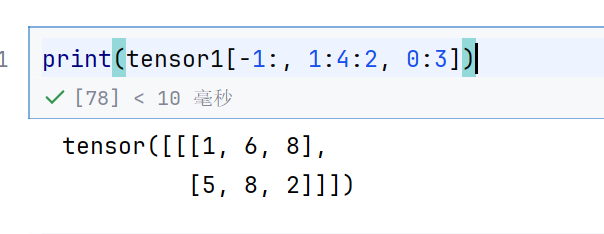
1:4:2表示步长为2,所以只取到了1和3
print(tensor1[-1:, 1:4:2, 0:3:2])
-1是最后一行,-2是导数第二行,-3是导数第三行
注意步长不能为负数
2.3 列表索引
# 取 第0维第0,第1维第1 和 第0维第1,第1维第2
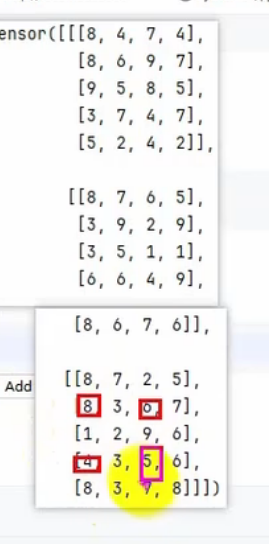
print(tensor1[[0, 1], [1, 2]])
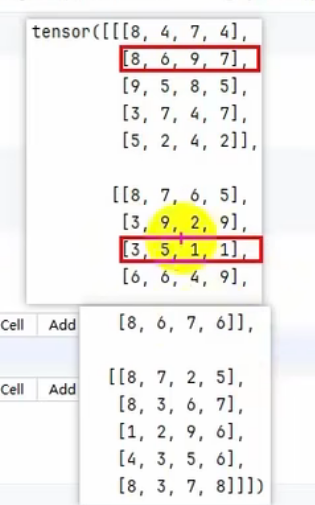

print(tensor1[[0, 1], [3, 2],[2,3]])

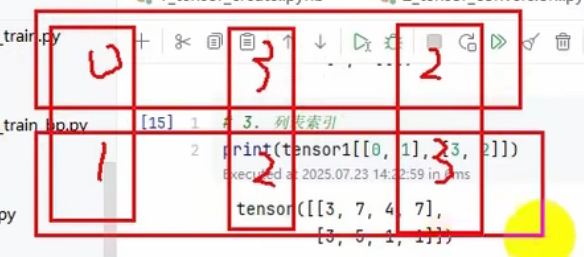
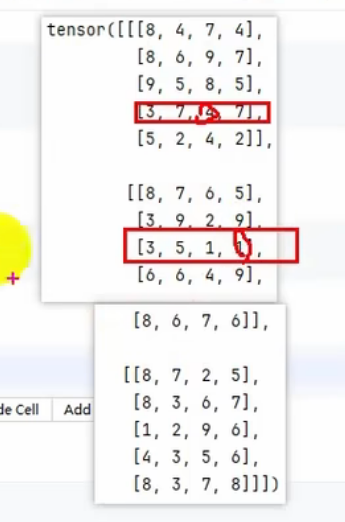
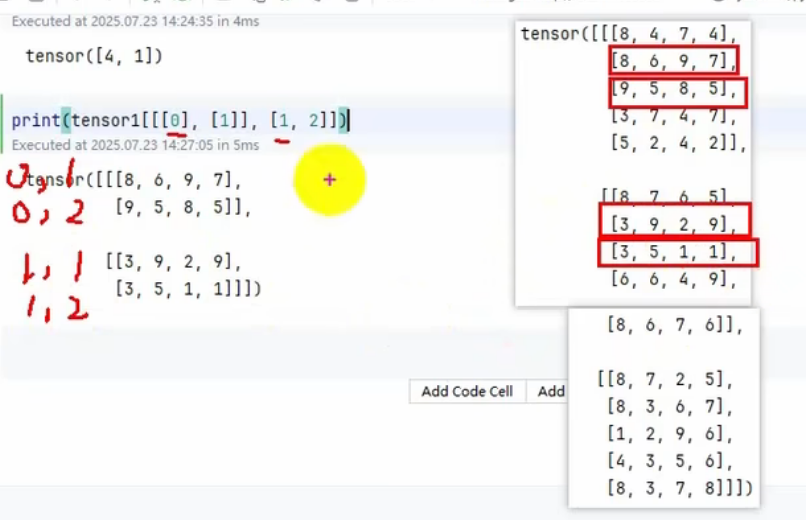
# 取 第0维第0,第1维第1、2 和 第0维第1,第1维第1、2
print(tensor1[[[0], [1]], [1, 2]])
2.3 布尔索引
# 取 第2维第0大于5的,返回(dim0,dim1)形状的索引
print(tensor1[:, :, 0] > 5)
表示每一层每一行的第一个元素,大于5
有三层,五行,所以输出3*5
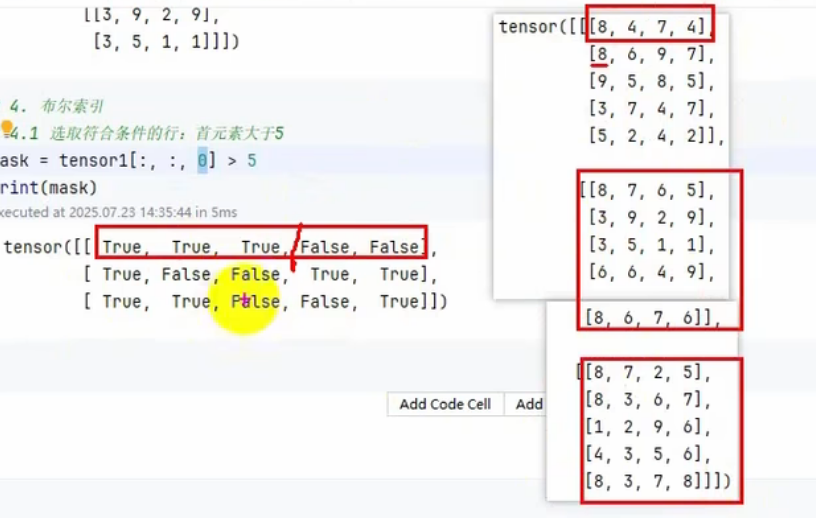
mask = tensor1[:, :, 0] > 5
print(tensor1[mask])
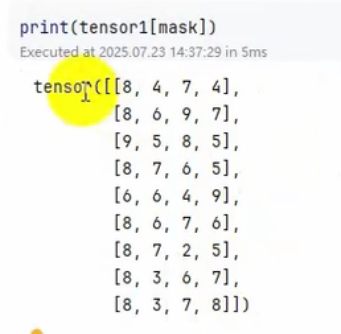
这样就选择出来了,第一个大于5的所有行了
# 取 第1维第1大于5的,返回(dim0,dim2)形状的索引
mask = tensor1[:, 1, :] > 5
这个就是判断每一层每一列中第1行大于5
所以打印出来的就是3*4
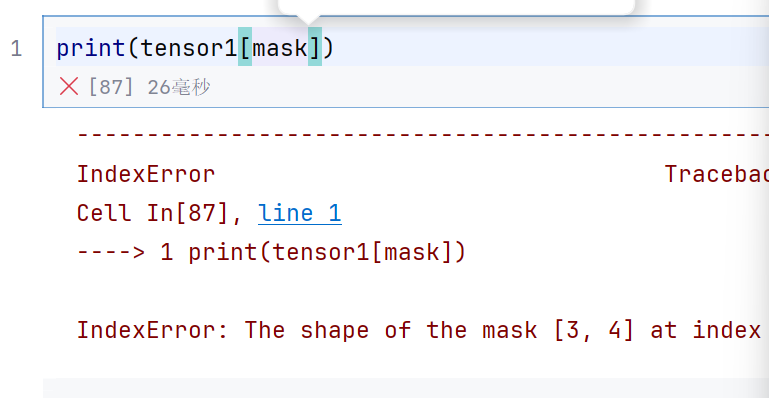
因为我们初始矩阵是354
所以不能用3*4的mask
但是把初始矩阵转置为345就可以了,最后在转置回来
# print(tensor1[mask])
tensor2 = tensor1.mT
print(tensor2.shape)

print(tensor2[mask])
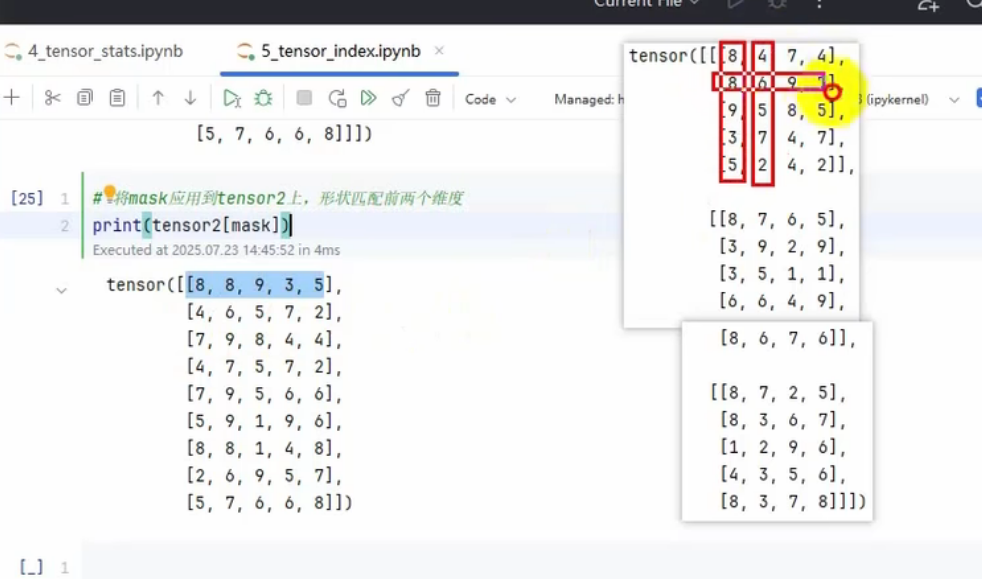
这里的每一行就是原来的每一列中第1行大于5的
#%%
print(tensor2[mask].mT)

最后在转回来
# 取 第1维第1,第2维第2大于5的,返回(dim0)形状的索引
print(tensor1[:, 1, 2] > 5)
print(tensor1[tensor1[:, 1, 2] > 5])
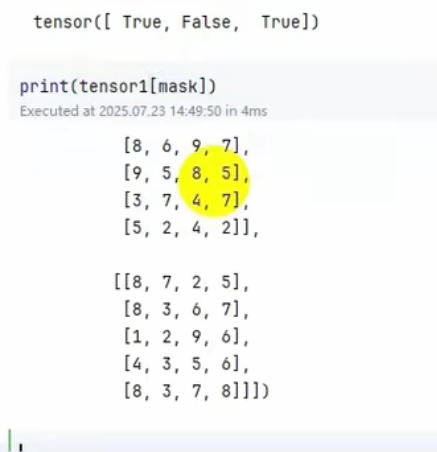
mask = tensor1 > 5
mask

print(tensor1[mask])

tensor为354
那么mask只能为3或者35或者35*4
不然就可能要转置了
3. 张量形状操作
3.1 交换维度
354,,,,如果T的话,就会变为453,T就是全部倒着翻转
最后两个元素翻转,那么就是mT
任意两个维度翻转呢
1)transpose()交换两个维度
2)permute()重新排列多个维度
tensor1 = torch.randint(1,10,(2,3,6))
print(tensor1.transpose(1,2))
这个就是交换第1和第二维度,也就是最后两个维度

print(tensor1.transpose(0,2))
初始为0,1,2的元素就会变为2,1,0
这样就可以知道元素怎么生成的了
print(tensor1.permute(0,2,1))
可以就是转置多个维度了
3.2 调整形状
比如3*2变为6,这个就是形状改变
1)reshape()调整张量的形状
tensor1 = torch.randint(1, 9, (3, 5, 4))
总个数是60
print(tensor1.reshape(6,10))
那么就可以变为数量同样为60的二维数组
数量不对应就会报错
print(tensor1.reshape(-1,10))
如果不想计算,直接给-1也是可以的
print(tensor1.reshape(-1))
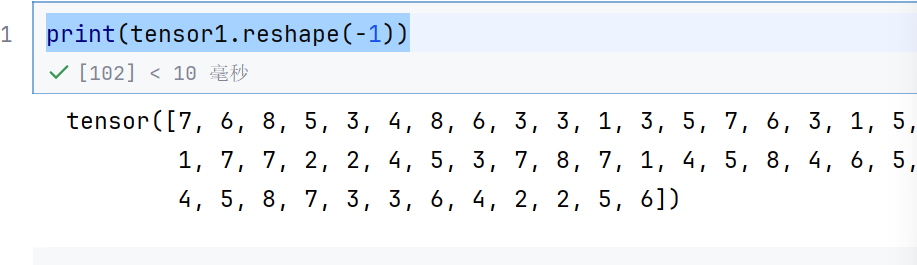
这个是变为一维
2)view()调整张量的形状,需要内存连续。共享内存
is_contiguous()判断是否内存连续
contiguous()转换为内存连续
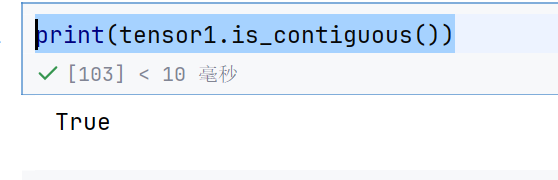
print(tensor1.is_contiguous())
print(tensor1.view(-1,10))
用法也是一样的
tensor1 = tensor1.permute(2,1,0)
print(tensor1.is_contiguous())
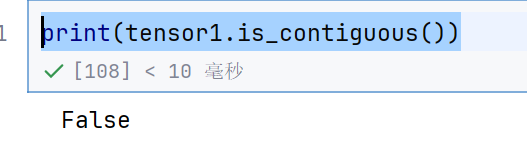
翻转之后就不连续了
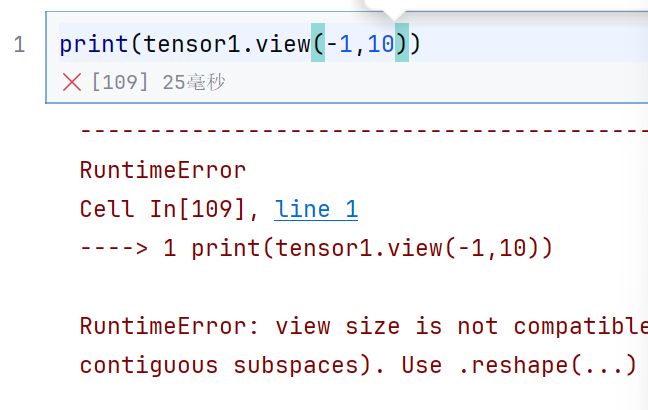
也不能view了
print(tensor1.contiguous().view(-1,10))

3.3 增加或删除维度
1)unsqueeze()在指定维度上增加1个维度
tensor1 = torch.tensor([1, 2, 3, 4, 5])
print(tensor1)
# 在0维上增加一个维度,就是增加0维,然后这一维个数为1,所以就是1*3
print(tensor1.unsqueeze(dim=0))
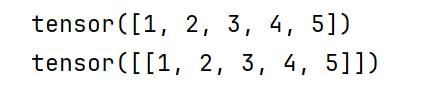
# 在1维上增加一个维度,而且数量为1,所以就是3*1
print(tensor1.unsqueeze(dim=1))

也可以把最后一个维度叫做-1维,倒数第二就是-2维,所以1维就是-1维,0维就是-2维
# 在1维上增加一个维度,而且数量为1,所以就是3*1
print(tensor1.unsqueeze(dim=-1))

效果一样
unsqueeze_就是原地操作了
2)squeeze()删除大小为1的维度
tensor1.squeeze(dim=1)

4. 张量拼接操作
1)torch.cat()张量拼接,按已有维度拼接。除拼接维度外,其他维度大小须相同
tensor1 = torch.randint(1, 9, (2, 2, 5))
tensor2 = torch.randint(1, 9, (2, 1, 5))
print(tensor1)
print(tensor2)
print(torch.cat([tensor1, tensor2], dim=1))
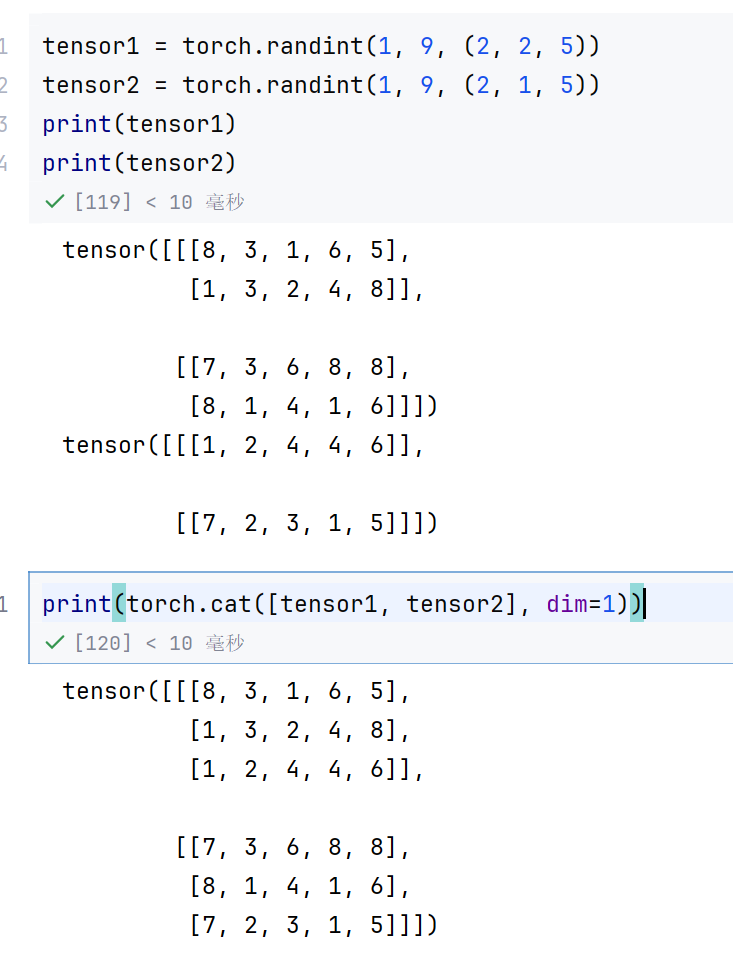
就变成了235了
2)torch.stack()张量堆叠,按新维度堆叠。所有张量形状必须一致
tensor1 = torch.randint(1, 9, (3, 1, 5))
tensor2 = torch.randint(1, 9, (3, 1, 5))
print(tensor1)
print(tensor2)
tensor3 = torch.stack([tensor1, tensor2], dim=0)
print(tensor3)
print(tensor3.shape)
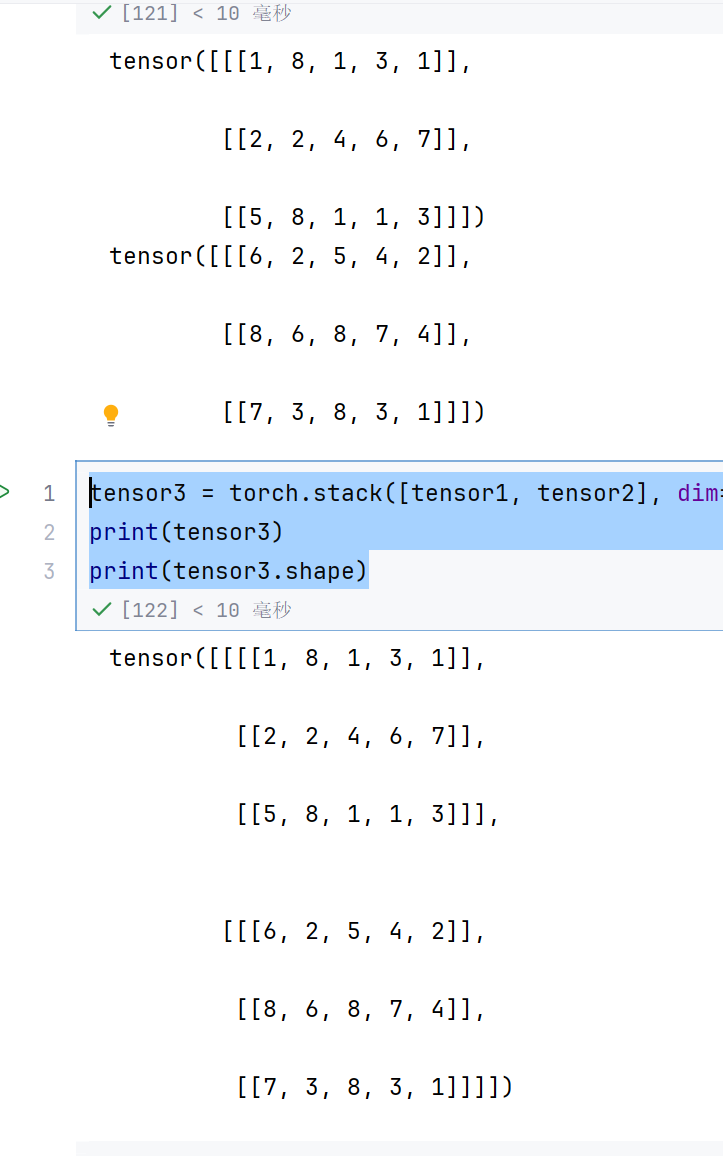
就变成了231*5
tensor3 = torch.stack([tensor1, tensor2], dim=1)
就变成了321*5
5. 自动微分模块
5.1 基本流程
训练神经网络时,框架会根据设计好的模型构建一个计算图(computational graph),来跟踪计算是哪些数据通过哪些操作组合起来产生输出,并通过反向传播算法来根据给定参数的损失函数的梯度调整参数(模型权重)。
PyTorch具有一个内置的微分引擎torch.autograd以支持计算图的梯度自动计算。
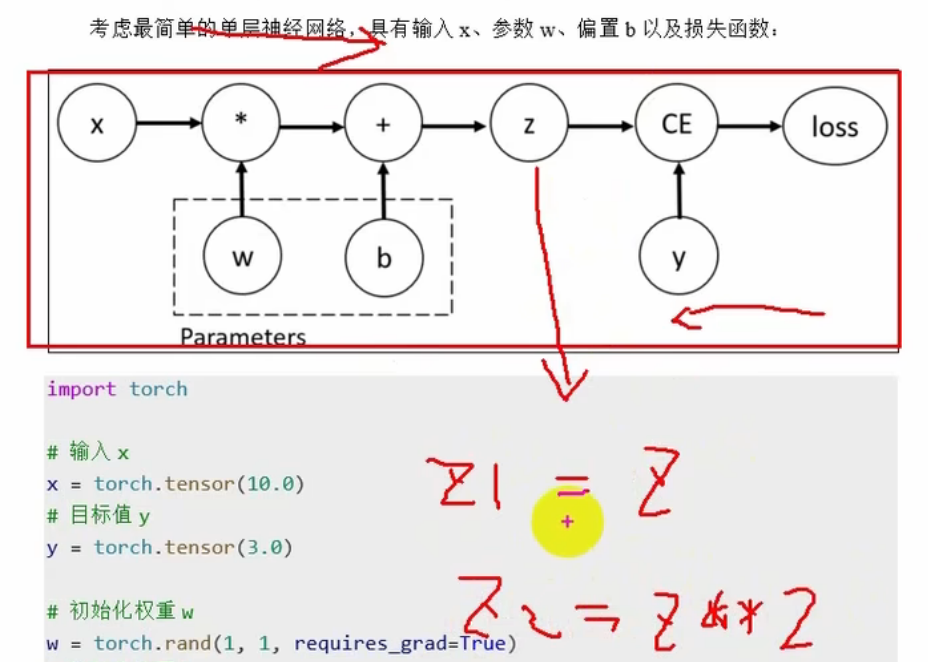
考虑最简单的单层神经网络,具有输入x、参数w、偏置b以及损失函数:
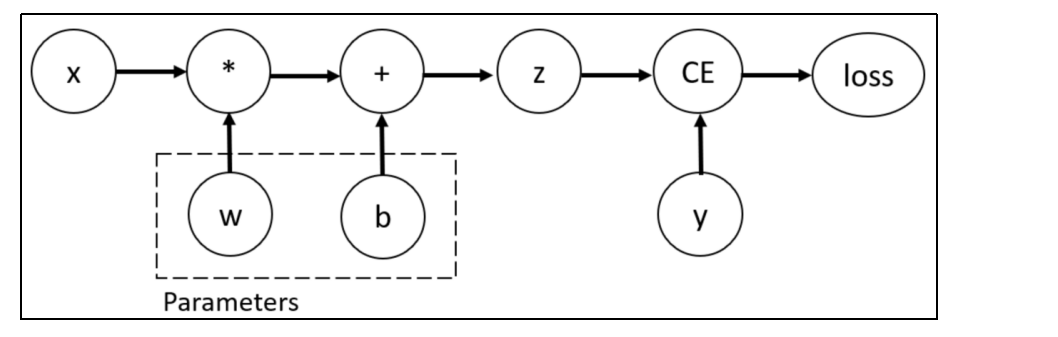
# 输入x
x = torch.tensor(10.0)
# 目标值y
y = torch.tensor(3.0)
#初始化参数,requires_grad表示会自动计算梯度
w = torch.rand(1,1,requires_grad=True)
b = torch.rand(1,1,requires_grad=True)
#前向传播,得到输出
z = w * x+b
print(z)

grad_fn=<AddBackward0>
这个指的是前向传播的过程中保存的操作的函数—》方便计算导数—》计算梯度
该计算图中x、w、b为叶子节点,即最基础的节点。叶子节点的数据并非由计算生成,因此是整个计算图的基石,叶子节点张量不可以执行in-place操作。就是原地操作,而最终的loss为根节点。
可通过is_leaf属性查看张量是否为叶子节点:
print(x.is_leaf)
print(w.is_leaf)
print(b.is_leaf)
print(y.is_leaf)
print(z.is_leaf)
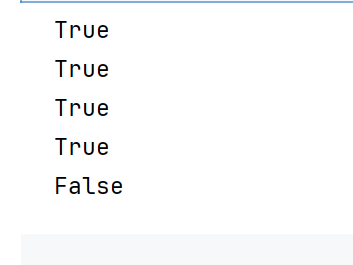
z是中间节点,叶子节点,默认梯度会一直保存,非叶子节点,用完了梯度就不要了
#设置损失函数
loss = torch.nn.MSELoss()
loss_value = loss(z,y)
print(loss_value)
print(loss_value.is_leaf)

这个是终点,不是叶子节点
这里会有点警告,主要是因为z是1*1的矩阵,而y是一个标量
# 目标值y
y = torch.tensor([[3.0]])
这样就可以了
#反向传播
loss_value.backward()
直接最后的终点损失值调用方法就可以反向传播了
#查看梯度
print(w.grad)
print(b.grad)
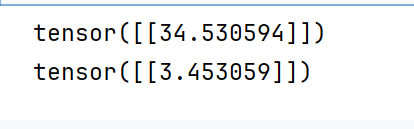
自动微分的关键就是记录节点的数据与运算。数据记录在张量的data属性中,计算记录在张量的grad_fn属性中。
计算图根据搭建方式可分为静态图和动态图,PyTorch是动态图机制,在计算的过程中逐步搭建计算图,同时对每个Tensor都存储grad_fn供自动微分使用。
若设置张量参数requires_grad=True,则PyTorch会追踪所有基于该张量的操作,并在反向传播时计算其梯度。依赖于叶子节点的节点,requires_grad默认为True。当计算到根节点后,在根节点调用backward()方法即可反向传播计算计算图中所有节点的梯度。
非叶子节点的梯度在反向传播之后会被释放掉(除非设置参数retain_grad=True)。而叶子节点的梯度在反向传播之后会保留(累积)。通常需要使用optimizer.zero_grad()清零参数的梯度。–》下一次前向传播的时候使用
5.2 分离张量
就是希望把z的张量拿出来
对z再次进行运算,z1=z*1,z2=z**2----->原始图有变化了-----》不行
有时我们希望将某些计算移动到计算图之外,可以使用Tensor.detach()返回一个新的变量,该变量与原变量具有相同的值data,但丢失计算图中如何计算原变量的信息grad_fn。-----》requesred_grad=false换句话说,梯度不会在该变量处继续向下传播。
x = torch.tensor(2.0,requires_grad=True)
y = x.detach()
print(x)
print(y)

print(x.requires_grad)
print(y.requires_grad)

print(id(x))
print(id(y))

但是它们底层的数据是共享的
print(x.untyped_storage().data_ptr())
print(y.untyped_storage().data_ptr())
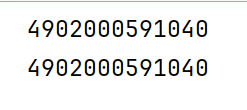
这个是打印底层数据的指针,发现是共享的
print(x)
y.zero_()
print(x)

z1 = x **2
z2 = y**2
print(z1)
print(z2)
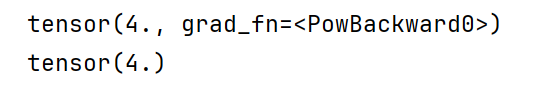
z1.sum().backward()
我们把sum当做损失函数,然后计算backward梯度
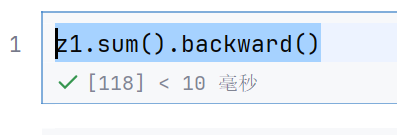
发现是可以计算的
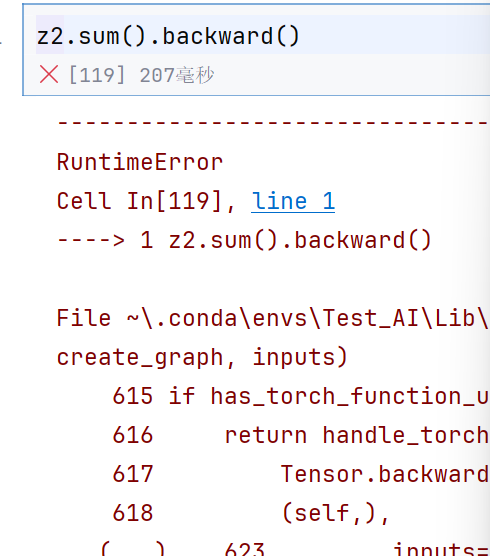
z2就不行了
这样用detach进行处理的话,就不会影响原来的z的梯度了
x = torch.ones(2,2,requires_grad=True)
y = x*x
print(x)
print(y)

u = y.detach()
print(u)

#让u参与新张量的计算,其实就是x的立方
z = u *x
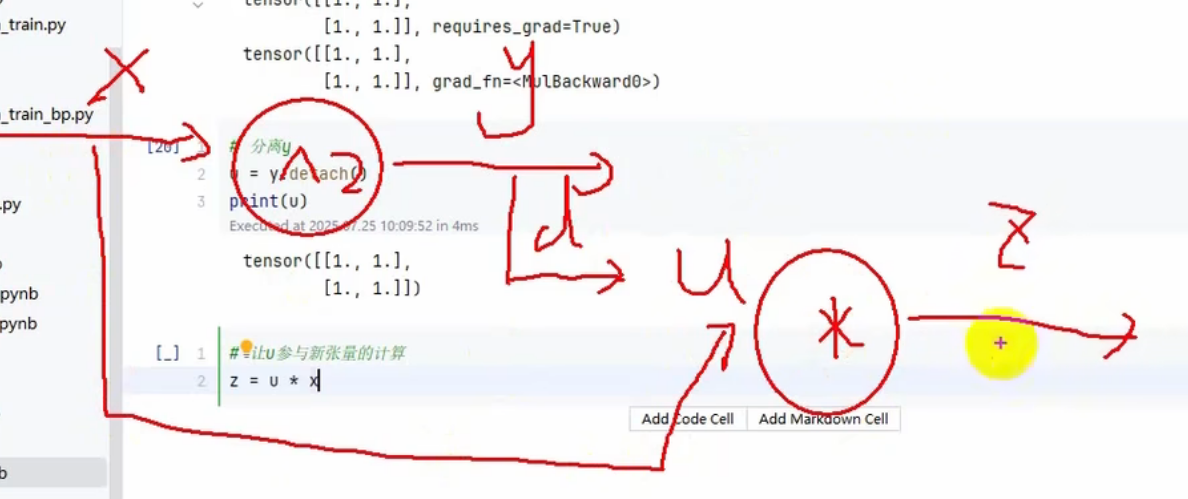
这里就把u当做常数就可以了—》求导为1
z.sum().backward()
print(x.grad)

我们看到梯度还是1,不是3—》3x的平方
.data与detach()都是返回原始数据,不返回梯度计算相关信息
区别就是data修改了—》微分引擎不会管理
detach是方法调用----》微分引擎会管理
x1 = torch.tensor([1.0,2,3],requires_grad=True)
x2 = torch.tensor([1.0,2,3],requires_grad=True)
print(x1)
print(x2)
y1 = x1.sigmoid()
y2 = x2.sigmoid()
print(y1)
print(y2)
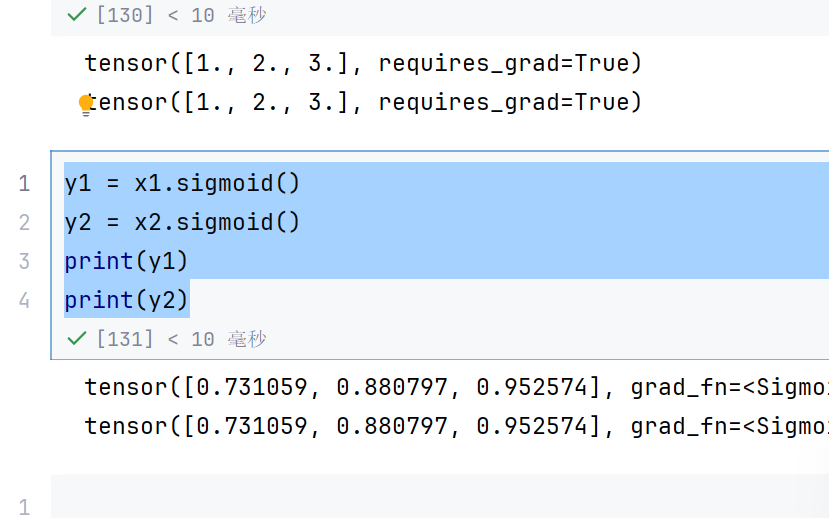
y1.sum().backward()
print(x1.grad)
y2.sum().backward()
print(x2.grad)

#%%
z1 = y1.data
z2 = y2.detach()
print(z1.requires_grad)
print(z2.requires_grad)
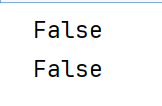
这两个都是数据共享的
z1.zero_()
z2.zero_()
print(y1)
print(y2)

但是这样会影响反向传播的结果
x1 = torch.tensor([1.0,2,3],requires_grad=True)
x2 = torch.tensor([1.0,2,3],requires_grad=True)
y1 = x1.sigmoid()
y2 = x2.sigmoid()
z1 = y1.data
z2 = y2.detach()
z1.zero_()
z2.zero_()
y1.sum().backward()
print(x1.grad)

data修改就会影响原来的梯度了—》因为微分引擎发现不了
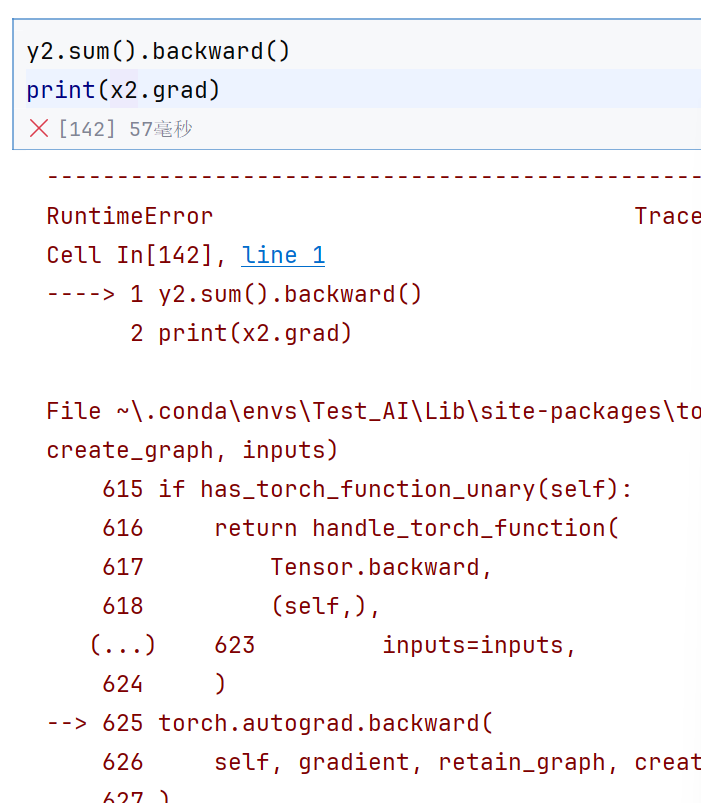
但是y2的话,就会直接报错了,因为数据修改了—》微分引擎发现了
6. 机器学习案例:线性回归
通过PyTorch训练一个模型一般分为以下4个步骤:
准备数据 → 构建模型 → 定义损失函数与优化器 → 模型训练
import torch
import matplotlib.pyplot as plt
from torch import nn, optim # 模型、损失函数和优化器
from torch.utils.data import TensorDataset, DataLoader # 数据集和数据加载器
#1.构建数据集,创建数据加载器,100*1,正态
X = torch.randn(100,1)
#预设真实系数
w = torch.tensor([2.5])
b = torch.tensor([5.2])
#定义随机噪声
noise = torch.randn(100,1)*0.1
y = w*X + b + noise
#构建数据集,X是特征,y是目标
dataset = TensorDataset(X, y)
#构建DataLoader,小批次是10,shuffle意思就是每十次小批次结束以后---》再次打乱数据--》洗牌
dataloader = DataLoader(dataset, batch_size=10,shuffle=True)
#2.构建模型,in_features和out_features表示输入神经元个数和输出神经元个数
model = nn.Linear(in_features=1,out_features=1)
#3. 定义损失函数和优化器,lr是学习率,因为优化器优化的是神经网络的,所以传入模型的参数model.parameters(),不是传入w和b
loss = nn.MSELoss()
optimizer = optim.SGD(model.parameters(),lr=0.001)
#4.模型训练,epoch_num表示训练循环次数
epoch_num = 1000
# 损失值列表
loss_list=[]
for epoch in range(epoch_num):
total_loss = 0#本轮总损失
iter_num =0#本轮迭代次数
# 取出小批次数据
for x_train,y_train in dataloader:
#4.1 前向传播
y_pred = model(x_train)
#计算损失
loss_value = loss(y_pred, y_train)
total_loss += loss_value
iter_num += 1
#反向传播
loss_value.backward()
#更新参数---》包含梯度计算
optimizer.step()
# 清除梯度--》不然下一次梯度直接累加了
optimizer.zero_grad()
#计算本轮平均损失
loss_list.append(total_loss/iter_num)
#打印模型里面的参数,weight是权重,bias是偏置
print(model.weight)
print(model.bias)
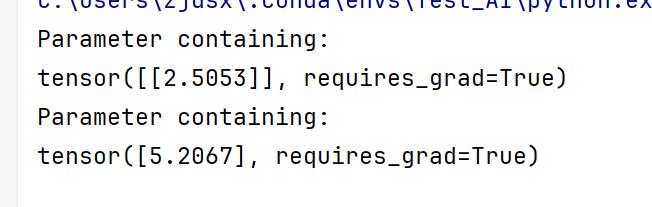
看到没和我们原来设置的2.5 和5.2 很相近了
#画图
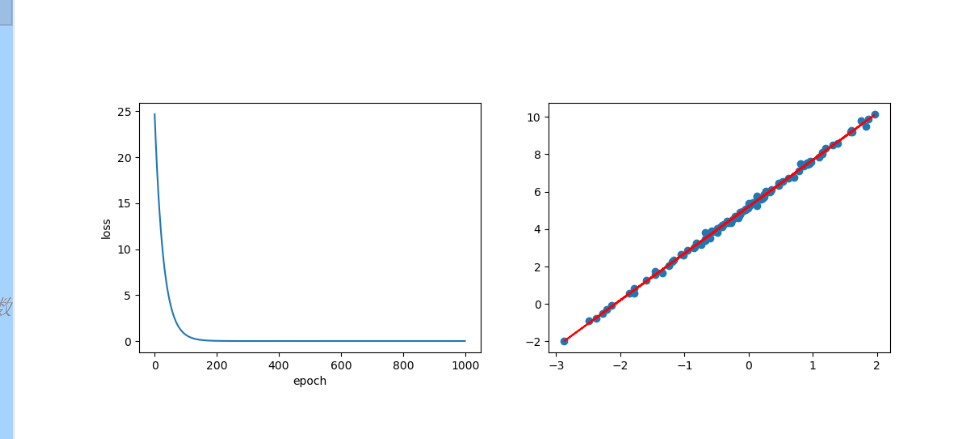
fig ,ax = plt.subplots(1,2,figsize=(12,4))
#训练损失随轮次的变化
ax[0].plot(loss_list)
ax[0].set_xlabel('epoch')
ax[0].set_ylabel('loss')
#绘制散点图和拟合直线
ax[1].scatter(X,y)
y_pred = model.weight.item() * X+model.bias.item()
ax[1].plot(X,y_pred,color='r')
plt.show()
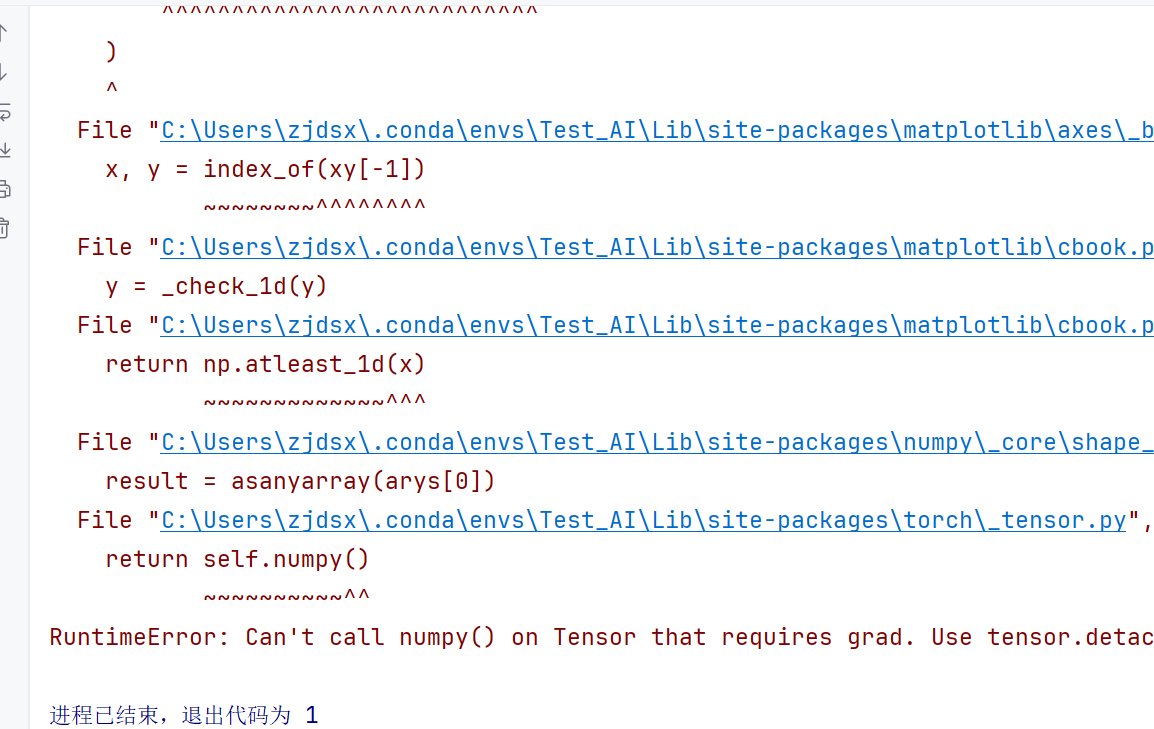
但是直接报错了,这个是怎么回事呢
loss_value = loss(y_pred, y_train)
total_loss += loss_value
是因为这个,所以total_loss 也有梯度信息----》不能画图
loss_value = loss(y_pred, y_train)
total_loss += loss_value.item()
这样的话,就可以了,因为total_loss 就只是一个标量值了
但是我们这里有点小瑕疵
batch_size就是这个,最后一个批次可能不是10,所以求平均值那里有点小误差
# 损失值列表
loss_list=[]
for epoch in range(epoch_num):
total_loss = 0#本轮总损失
iter_num =0#本轮迭代次数
# 取出小批次数据
for x_train,y_train in dataloader:
#4.1 前向传播
y_pred = model(x_train)
#计算损失
loss_value = loss(y_pred, y_train)
total_loss += loss_value.item()*x_train.shape[0]
# iter_num += 1
#反向传播
loss_value.backward()
#更新参数---》包含梯度计算
optimizer.step()
# 清除梯度--》不然下一次梯度直接累加了
optimizer.zero_grad()
#计算本轮平均损失
loss_list.append(total_loss/len(dataset))
这样就可以了,每次小批次误差,都乘以批次数量,最后总误差除以总个数,就不会有那个问题了
import torch
import matplotlib.pyplot as plt
from torch import nn, optim # 模型、损失函数和优化器
from torch.utils.data import TensorDataset, DataLoader # 数据集和数据加载器
#1.构建数据集,创建数据加载器,100*1,正态
X = torch.randn(100,1)
#预设真实系数
w = torch.tensor([2.5])
b = torch.tensor([5.2])
#定义随机噪声
noise = torch.randn(100,1)*0.1
y = w*X + b + noise
#构建数据集,X是特征,y是目标
dataset = TensorDataset(X, y)
#构建DataLoader,小批次是10,shuffle意思就是每十次小批次结束以后---》再次打乱数据--》洗牌
dataloader = DataLoader(dataset, batch_size=10,shuffle=True)
#2.构建模型,in_features和out_features表示输入神经元个数和输出神经元个数
model = nn.Linear(in_features=1,out_features=1)
#3. 定义损失函数和优化器,lr是学习率,因为优化器优化的是神经网络的,所以传入模型的参数model.parameters(),不是传入w和b
loss = nn.MSELoss()
optimizer = optim.SGD(model.parameters(),lr=0.001)
#4.模型训练,epoch_num表示训练循环次数
epoch_num = 1000
# 损失值列表
loss_list=[]
for epoch in range(epoch_num):
total_loss = 0#本轮总损失
iter_num =0#本轮迭代次数
# 取出小批次数据
for x_train,y_train in dataloader:
#4.1 前向传播
y_pred = model(x_train)
#计算损失
loss_value = loss(y_pred, y_train)
total_loss += loss_value.item()*x_train.shape[0]
# iter_num += 1
#反向传播
loss_value.backward()
#更新参数---》包含梯度计算
optimizer.step()
# 清除梯度--》不然下一次梯度直接累加了
optimizer.zero_grad()
#计算本轮平均损失
loss_list.append(total_loss/len(dataset))
#打印模型里面的参数,weight是权重,bias是偏置
print(model.weight)
print(model.bias)
#画图
fig ,ax = plt.subplots(1,2,figsize=(12,4))
#训练损失随轮次的变化
ax[0].plot(loss_list)
ax[0].set_xlabel('epoch')
ax[0].set_ylabel('loss')
#绘制散点图和拟合直线
ax[1].scatter(X,y)
y_pred = model.weight.item() * X+model.bias.item()
ax[1].plot(X,y_pred,color='r')
plt.show()
总结

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)