达梦数据库到PostgreSQL数据库迁移实操
达梦的DATETIME → PostgreSQL 的TIMESTAMP;复制调整后的 DDL 脚本,在 DBeaver 中打开 PostgreSQL 目标库的对应模式,新建 SQL 编辑器并粘贴脚本,执行前核对模式名、表名是否正确,确认无误后执行,完成单表 / 批量表的结构创建(建议按模式分批次执行,每批执行后检查表是否成功创建)。右键点击选中的表,依次选择「生成 SQL」→「DDL」,DBeav
因为项目需要,要将一个达梦数据库向Postgresql数据库迁移。
一、迁移痛点与核心方案
1. 迁移背景
源库:达梦数据库(含 4 个模式、200 + 张业务表)
目标库:PostgreSQL
此前困境:尝试 Navicat、DataGrip 直接迁移失败;达梦官方 DMETL 工具已取消下载链接,迁移陷入停滞。
2. 迁移方案
最终确定以 “结构先行、数据跟进”为核心思路,借助 DBeaver 的 SQL-DDL 生成功能实现结构迁移,再通过工具完成数据导出导入,具体路径为:
PostgreSQL环境搭建(建库+建模式)→ 达梦表结构转PostgreSQL(DDL生成+调整)→ 达梦数据导出→ PostgreSQL数据导入→ 数据校验
二、 step by step 实操:从环境到迁移落地
阶段 1:环境准备(迁移前必做)
1、工具安装与配置
安装 DBeaver(Community 免费版 / Ultimate 收费版均可),分别建立达梦、PostgreSQL 的数据库连接(需提前准备两端数据库的 IP、端口、账号密码,确保网络互通)。
安装 DataGrip(用于后续数据导出导入,实测稳定性优于其他工具,也可备选 DBeaver/Navicat)。
2、 PostgreSQL 端初始化
登录 PostgreSQL,按达梦源库的 4 个模式结构,在目标库中逐一创建对应的模式(确保模式名、权限配置与源库一致,避免后续表创建时权限报错)。
阶段 2:结构迁移(核心:DDL 生成与适配)
这一步是迁移关键,需解决达梦与 PostgreSQL 的数据类型兼容性问题,具体操作:
1、生成达梦表 DDL 脚本
打开 DBeaver 并连接达梦源库,在左侧导航栏展开目标模式,选中需迁移的表(可单表选,也可按模式批量选)。
右键点击选中的表,依次选择「生成 SQL」→「DDL」,DBeaver 会自动生成包含表结构、字段类型、约束的完整 DDL 脚本(脚本会包含达梦特有的语法,需下一步调整)。
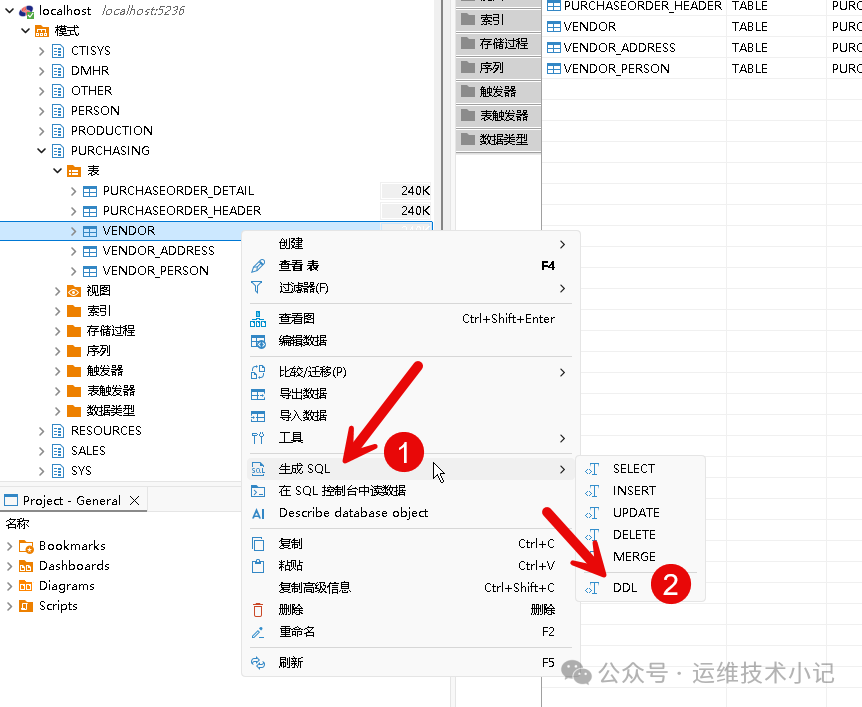
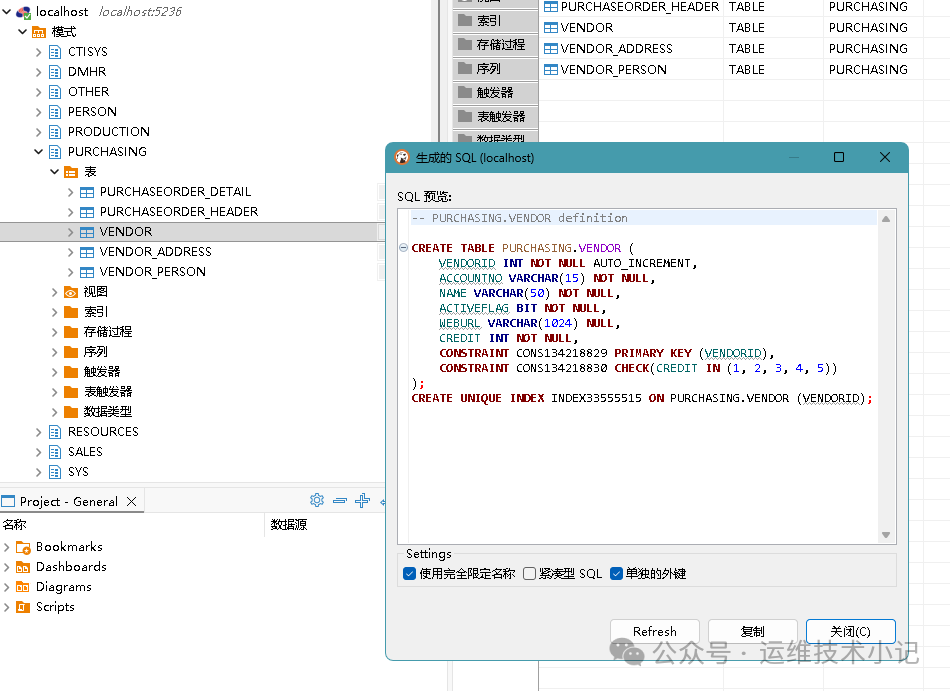
2、DDL 脚本适配调整(必改项)
字段类型替换:达梦的VARCHAR2(长度) → PostgreSQL 的VARCHAR(长度);达梦的DATETIME → PostgreSQL 的TIMESTAMP;达梦的NUMBER需根据精度改为INT/DECIMAL(例如NUMBER(10,2)→DECIMAL(10,2))。
语法清理:删除达梦特有的注释格式(如-- DM EXCLUDE)、存储过程调用语句(若脚本包含),确保仅保留建表相关语句。
3、执行 DDL 建表
复制调整后的 DDL 脚本,在 DBeaver 中打开 PostgreSQL 目标库的对应模式,新建 SQL 编辑器并粘贴脚本,执行前核对模式名、表名是否正确,确认无误后执行,完成单表 / 批量表的结构创建(建议按模式分批次执行,每批执行后检查表是否成功创建)。
阶段 3:数据迁移(导出→导入→校验)
1、达梦数据导出(以 DataGrip 为例)
打开 DataGrip 连接达梦源库,展开目标表,右键选择「Export Data」,导出格式选择「XLSX」(支持大数据量,且字段映射直观)。
导出配置:勾选 “包含表头”“保留原始数据格式”,选择本地存储路径,点击导出(200 + 张表建议按模式建立文件夹分类存储,避免文件混乱)。
2、PostgreSQL 数据导入
连接 PostgreSQL 目标库,找到需导入数据的表,右键选择「Import Data」,选择对应表的 XLSX 文件。
字段映射校验:系统会自动匹配表头与表字段,需手动核对每列映射关系(尤其日期、数值类型字段),确认无错后点击导入(导入后查看 “导入日志”,确认无数据丢失、格式错误)。
3、数据一致性校验
随机抽取 10-20 张表,对比达梦源表与 PostgreSQL 目标表的总行数(确保无数据遗漏)。
针对核心业务表(如订单表、用户表),随机查询 100 条数据,核对关键字段(如 ID、金额、时间)是否完全一致,避免数据失真。
三、迁移后:常态化数据同步方案
若迁移后需保持达梦与 PostgreSQL 的数据同步(如过渡期双库运行),推荐使用Pentaho Data Integration(原 Kettle):
支持功能:全量同步、增量同步(按时间戳 / 自增 ID 过滤)、定时任务配置。
优势:适配达梦、PostgreSQL 等多数据源,可视化流程配置,降低技术门槛,且支持异常重试、日志监控,保障同步稳定性。
四、避坑指南(5 个关键注意事项)
1、 字段类型适配:除了必改的VARCHAR2/DATETIME,达梦的CLOB需改为 PostgreSQL 的TEXT,BLOB改为BYTEA,需提前参考《达梦数据库数据类型与标准 SQL 对应表》梳理全量映射关系。
2、约束处理:若达梦表包含主键、外键、唯一约束,生成 DDL 时需确认约束名是否符合 PostgreSQL 命名规则(避免特殊字符),外键需按 “先建主表、再建从表” 的顺序执行。
3. 批量操作效率:200 + 张表不建议单张处理,可在 DBeaver 中按模式批量选中表生成 DDL,再用文本工具(如 Notepad++)批量替换字段类型,提升效率。
4、导入数据量控制:单表数据量超过 10 万行时,不建议用 XLSX 格式(易卡顿),可改为 CSV 格式导出导入,且导入时关闭目标表的索引(导入后重建),减少导入耗时。
5、备份保障:执行 DDL 前备份 PostgreSQL 目标库,数据导入前备份达梦源库数据,避免操作失误导致数据丢失。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)