高并发系统下的数据库优化:索引设计、SQL 优化、连接池配置(HikariCP)
高并发系统下的数据库优化:索引设计、SQL 优化、连接池配置(HikariCP)
在高并发系统中,数据库往往是性能瓶颈的 “重灾区”—— 当并发请求量突破万级、十万级,原本 “够用” 的数据库会出现查询延迟飙升、连接耗尽、甚至宕机的情况。作为架构师,数据库优化是保障系统稳定性的核心能力,而索引设计、SQL 优化、连接池配置则是高并发场景下数据库优化的 “三驾马车”。本文将从实战角度出发,拆解这三大优化方向的核心逻辑、操作方法及落地案例,并搭配插图辅助理解,为高并发系统数据库优化提供可落地的方案。
一、引言:为什么高并发下数据库必须优化?
在中小并发场景(如日均请求 10 万以下),简单的数据库设计或许能满足需求;但当并发量突破 10 万、100 万(如电商大促、秒杀活动),数据库的性能短板会被无限放大:
-
查询延迟:未优化的 SQL 查询可能从 “毫秒级” 变为 “秒级”,直接导致用户页面加载卡顿、订单提交超时;
-
连接耗尽:每个请求都创建新数据库连接,而数据库默认连接数有限(如 MySQL 默认 151 个),高并发下会出现 “连接超时” 错误;
-
资源过载:频繁的全表扫描、无效索引会导致数据库 CPU、磁盘 IO 飙升,甚至引发数据库宕机,影响整个业务链路。
因此,高并发系统的数据库优化不是 “可选项”,而是 “必选项”—— 优化的目标是:在保证数据一致性的前提下,将数据库查询延迟控制在毫秒级,连接利用率最大化,资源消耗最小化。
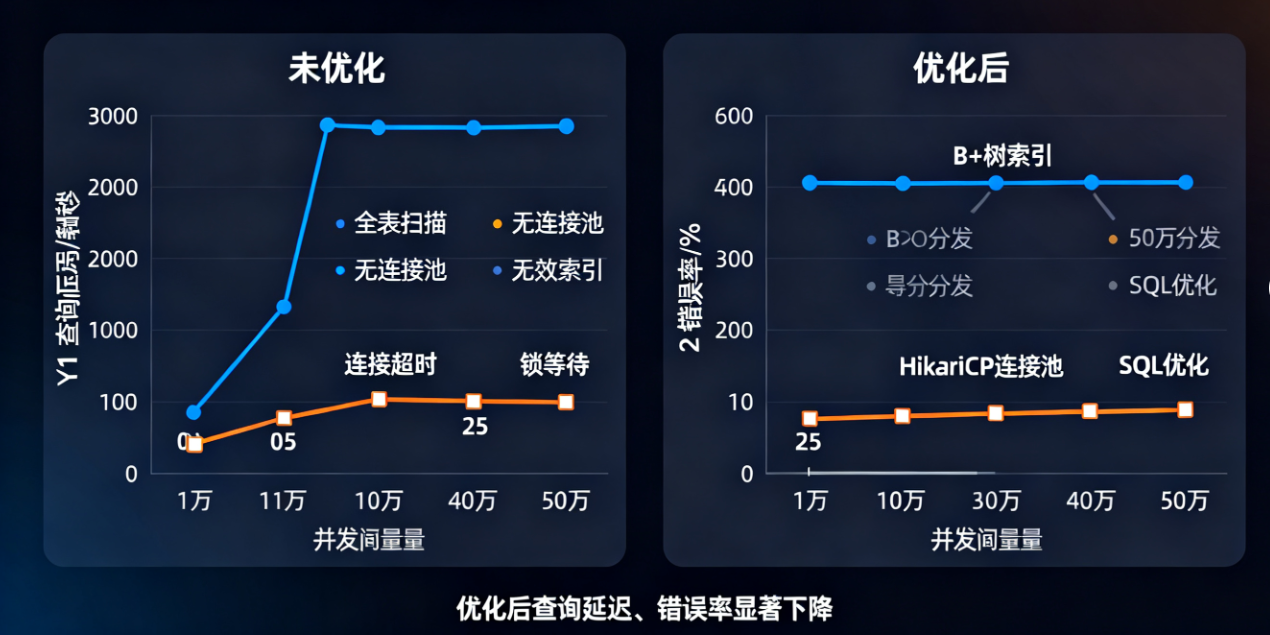
(图 1:高并发场景下未优化与优化后的数据库性能对比,优化后查询延迟、错误率显著下降)
二、高并发系统下的数据库挑战:先明确 “痛点” 在哪
在动手优化前,需先理清高并发场景下数据库面临的核心挑战,避免 “盲目优化”。
1. 高并发带来的 3 大核心问题
-
请求量突增:秒杀活动开始时,订单查询、库存扣减请求瞬间从日常 100 QPS 飙升至 10 万 QPS,数据库处理能力不足会导致请求堆积;
-
资源竞争激烈:多线程同时操作同一张表(如库存表),会出现行锁、表锁等待,甚至死锁,导致事务执行超时;
-
数据读取压力大:高并发下 80% 的请求是 “读操作”(如商品详情查询),频繁读取会占用大量数据库 IO 资源,挤压 “写操作”(如下单、支付)的资源空间。
2. 数据库性能瓶颈的 4 个关键环节
高并发下数据库的性能瓶颈,本质是 “资源供需不匹配”,主要集中在 4 个环节:
| 瓶颈环节 | 表现形式 | 高并发下的影响 |
|---|---|---|
| CPU | SQL 执行时 CPU 使用率超 80%,复杂计算(如聚合函数、子查询)占用大量 CPU | 查询延迟延长,无法处理更多请求 |
| 内存 | 数据库缓存(如 MySQL Buffer Pool)不足,频繁从磁盘读取数据 | 磁盘 IO 飙升,查询速度下降 |
| 磁盘 IO | 全表扫描、无索引查询导致磁盘读写频繁,IO 等待时间超 200ms | 单条查询耗时增加,并发处理能力下降 |
| 网络 | 数据库与应用服务器之间网络带宽不足,或连接数超限 | 连接超时,请求无法到达数据库 |
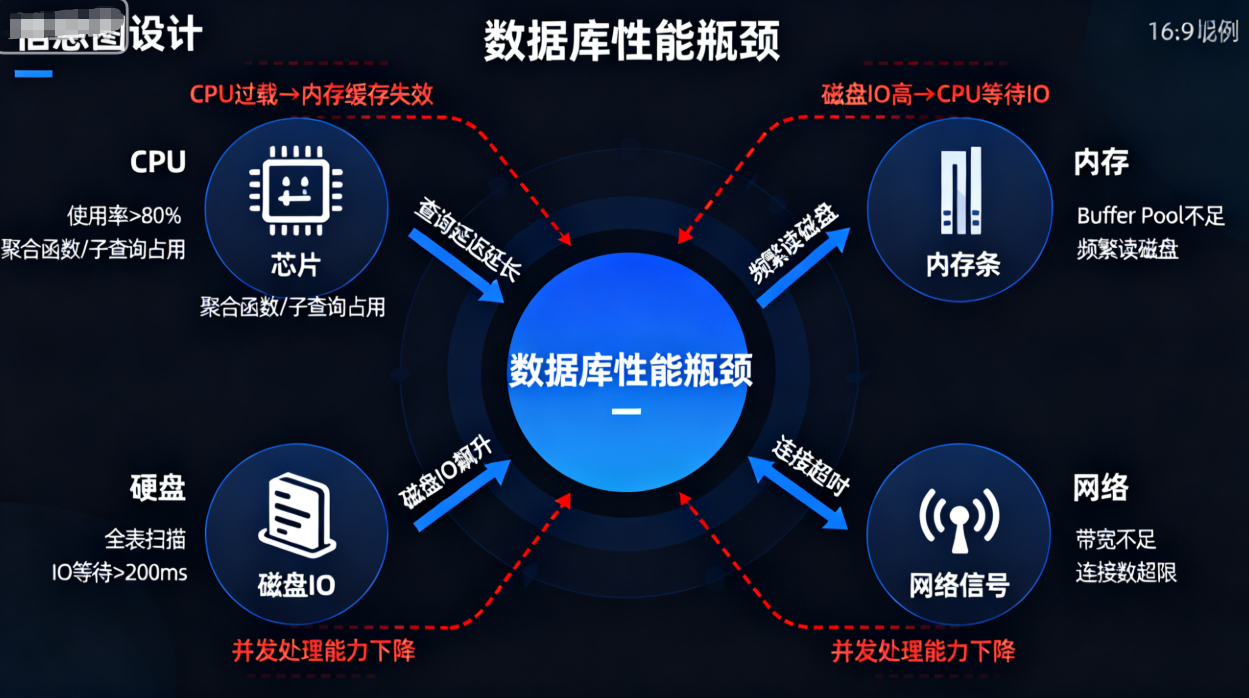
(图 2:高并发下数据库性能瓶颈的 4 个关键环节及相互影响关系)
三、索引设计优化:让查询 “快” 起来的核心
索引是数据库查询的 “加速器”—— 在高并发场景下,合理的索引能将查询时间从 “秒级” 压缩到 “毫秒级”;反之,无效索引、过度索引会拖慢写操作(如插入、更新),甚至引发性能反跳。
1. 索引基础:先搞懂 “索引是什么”
索引本质是数据库表中数据的 “排序目录”,类似书籍的目录:通过目录能快速找到对应章节,而无需逐页翻阅;通过索引,数据库能快速定位到目标数据,避免全表扫描。
常见的索引类型及适用场景:
-
B + 树索引:MySQL 默认索引类型,适用于范围查询(如
where price between 100 and 200)、等值查询(如where id=100),支持排序和分页; -
哈希索引:适用于精确等值查询(如
where user_id='12345'),查询速度快,但不支持范围查询和排序; -
联合索引:多字段组合的索引(如
index (user_id, order_time)),需遵循 “最左前缀原则”,适用于多条件查询。
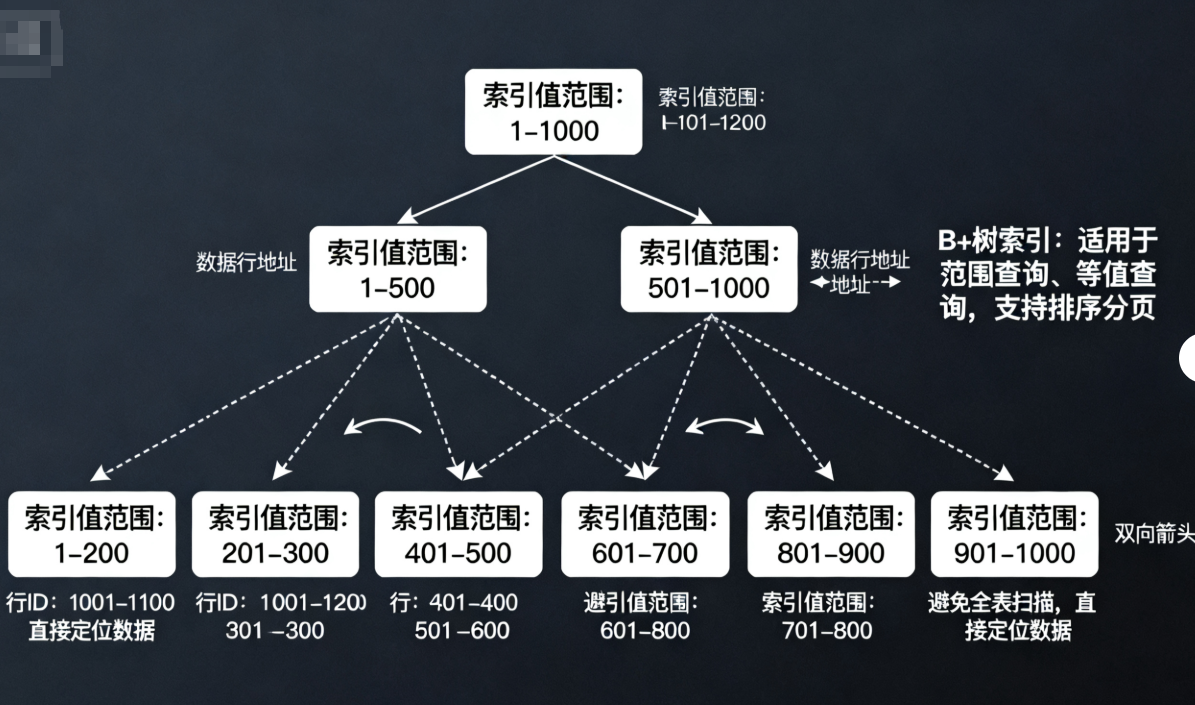
(图 3:B + 树索引结构示意图,通过层级索引快速定位数据,避免全表扫描)
2. 高并发场景下的索引设计策略:3 个核心原则
高并发场景下的索引设计,需平衡 “读性能” 和 “写性能”,核心遵循 3 个原则:
(1)“高频查询优先”:优先为高频查询字段建索引
高并发下,80% 的查询集中在 20% 的高频字段上(如商品 ID、用户 ID)。例如:
-
电商商品详情页查询:
select * from product where product_id=?,需为product_id建主键索引; -
订单列表查询:
select * from order where user_id=? order by create_time desc,需为user_id和create_time建联合索引(index (user_id, create_time))。
反例:为低频查询字段(如where is_delete=0)建索引,不仅无法提升查询性能,还会增加插入 / 更新时的索引维护成本。
(2)“避免过度索引”:单表索引数量不超过 5 个
索引并非越多越好 —— 每新增一条数据,数据库需同步更新所有相关索引,过度索引会导致写操作(插入、更新、删除)性能下降。高并发场景下,单表索引数量建议控制在 5 个以内,优先保留高频查询、高区分度的索引。
(3)“遵循最左前缀”:联合索引字段顺序有讲究
联合索引的生效规则是 “最左前缀匹配”—— 查询条件需包含联合索引的最左字段,否则索引无法生效。例如:
-
联合索引
index (user_id, order_time):-
生效查询:
where user_id=?(匹配最左字段)、where user_id=? and order_time>?'(匹配全部字段); -
失效查询:
where order_time>?'(未匹配最左字段)。
-
技巧:将区分度高、查询频率高的字段放在联合索引的左侧。
3. 索引优化实战案例:从 “全表扫描” 到 “毫秒级查询”
场景:电商订单查询接口,高并发下查询延迟超 3 秒,SQL 如下:
select order\_id, user\_id, order\_amount from order 
where user\_id='12345' and create\_time > '2025-01-01' 
order by create\_time desc limit 10;
问题定位:用EXPLAIN分析 SQL 执行计划,发现type=ALL(全表扫描),rows=100000(扫描 10 万行数据),无有效索引。
优化方案:为user_id和create_time建联合索引:
create index idx\_user\_create on order (user\_id, create\_time);
优化效果:EXPLAIN分析显示type=range(范围查询),rows=100(仅扫描 100 行数据),查询延迟从 3 秒降至 50 毫秒。

(图 4:左为优化前全表扫描执行计划,右为优化后索引查询执行计划,扫描行数大幅减少)
四、SQL 优化:让每一条 SQL “高效执行”
在高并发场景下,一条低效 SQL 可能拖垮整个数据库 —— 例如,全表扫描的 SQL 在并发 1 万时,会导致数据库 CPU、IO 飙升。SQL 优化的核心是:让 SQL 尽可能使用索引,减少数据扫描量,避免无效计算。
1. SQL 优化基础:3 个 “避坑” 技巧
(1)避免 “SELECT *”:只查询需要的字段
“SELECT *” 会导致数据库读取所有字段数据,增加磁盘 IO 和网络传输开销,尤其在表字段较多(如包含大文本字段)时,性能影响显著。高并发场景下,需明确查询字段:
优化前:
select \* from product where product\_id=?; -- 读取所有字段
优化后:
select product\_id, product\_name, price from product where product\_id=?; -- 只查必要字段
(2)避免 “函数操作索引字段”:导致索引失效
在索引字段上使用函数(如substr()、date()),会导致数据库无法使用索引,触发全表扫描:
优化前:
select \* from order where date(create\_time) = '2025-01-01'; -- create\_time是索引字段,用函数后索引失效
优化后:
select \* from order where create\_time between '2025-01-01 00:00:00' and '2025-01-01 23:59:59'; -- 不操作索引字段,索引生效
(3)避免 “隐式类型转换”:索引字段类型与查询值类型需一致
若索引字段类型为varchar,查询时用数值类型(如where user_id=12345),会触发隐式类型转换,导致索引失效:
优化前:
select \* from user where user\_id=12345; -- user\_id是varchar类型,查询值是数值,隐式转换
优化后:
select \* from user where user\_id='12345'; -- 查询值与字段类型一致,索引生效
2. 高并发下的 SQL 性能分析:用好 “EXPLAIN” 工具
EXPLAIN是 MySQL 自带的 SQL 性能分析工具,能清晰展示 SQL 的执行计划(如是否使用索引、扫描行数、连接方式),是高并发场景下定位低效 SQL 的核心工具。
EXPLAIN输出结果中需重点关注的 3 个字段:
-
type:查询类型,从优到差为
system > const > eq_ref > ref > range > index > ALL,高并发场景下需保证type至少为range(范围查询),避免ALL(全表扫描); -
key:实际使用的索引,若为
NULL,表示未使用索引; -
rows:预估扫描行数,数值越小越好,高并发下需控制在 1000 行以内。

(图 5:EXPLAIN 分析 SQL 执行计划示例,红框标注 type、key、rows 核心字段,显示使用索引且扫描行数少)
3. 高并发 SQL 优化实战:批量操作替代循环操作
高并发场景下,频繁的单条 SQL 操作(如循环插入 1000 条数据)会导致数据库连接频繁切换,性能低下。此时需用 “批量操作” 替代 “循环操作”:
优化前(循环插入):
// 循环插入1000条订单,每次创建新连接,性能差
for (Order order : orderList) {
  String sql = "insert into order (order\_id, user\_id) values (?, ?)";
  jdbcTemplate.update(sql, order.getOrderId(), order.getUserId());
}
优化后(批量插入):
// 批量插入1000条订单,一次连接完成,性能提升5-10倍
String sql = "insert into order (order\_id, user\_id) values (?, ?)";
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
  @Override
  public void setValues(PreparedStatement ps, int i) throws SQLException {
  Order order = orderList.get(i);
  ps.setString(1, order.getOrderId());
  ps.setString(2, order.getUserId());
  }
  @Override
  public int getBatchSize() {
  return orderList.size();
  }
});
优化效果:批量操作减少了数据库连接次数和网络交互次数,插入 1000 条数据的时间从 5 秒降至 0.5 秒,并发处理能力显著提升。
五、连接池配置(HikariCP):让数据库连接 “高效复用”
在高并发场景下,“每次请求创建新数据库连接” 是致命问题 —— 数据库连接的创建和销毁成本高(需 TCP 三次握手、身份认证),且数据库默认连接数有限(如 MySQL 默认 151 个)。此时,数据库连接池成为解决问题的关键,而 HikariCP 则是目前性能最优的 Java 数据库连接池(Spring Boot 默认集成)。
1. 连接池核心原理:“复用连接,减少开销”
数据库连接池的核心逻辑是:提前创建一定数量的数据库连接,存储在 “连接池” 中;请求到来时,从连接池获取连接,使用后归还连接,避免重复创建和销毁。
连接池的核心优势:
-
减少连接开销:连接复用,避免频繁创建 / 销毁连接的性能损耗;
-
控制连接数量:限制最大连接数,避免数据库因连接过多而宕机;
-
提升响应速度:请求无需等待连接创建,直接从池获取,响应更快。
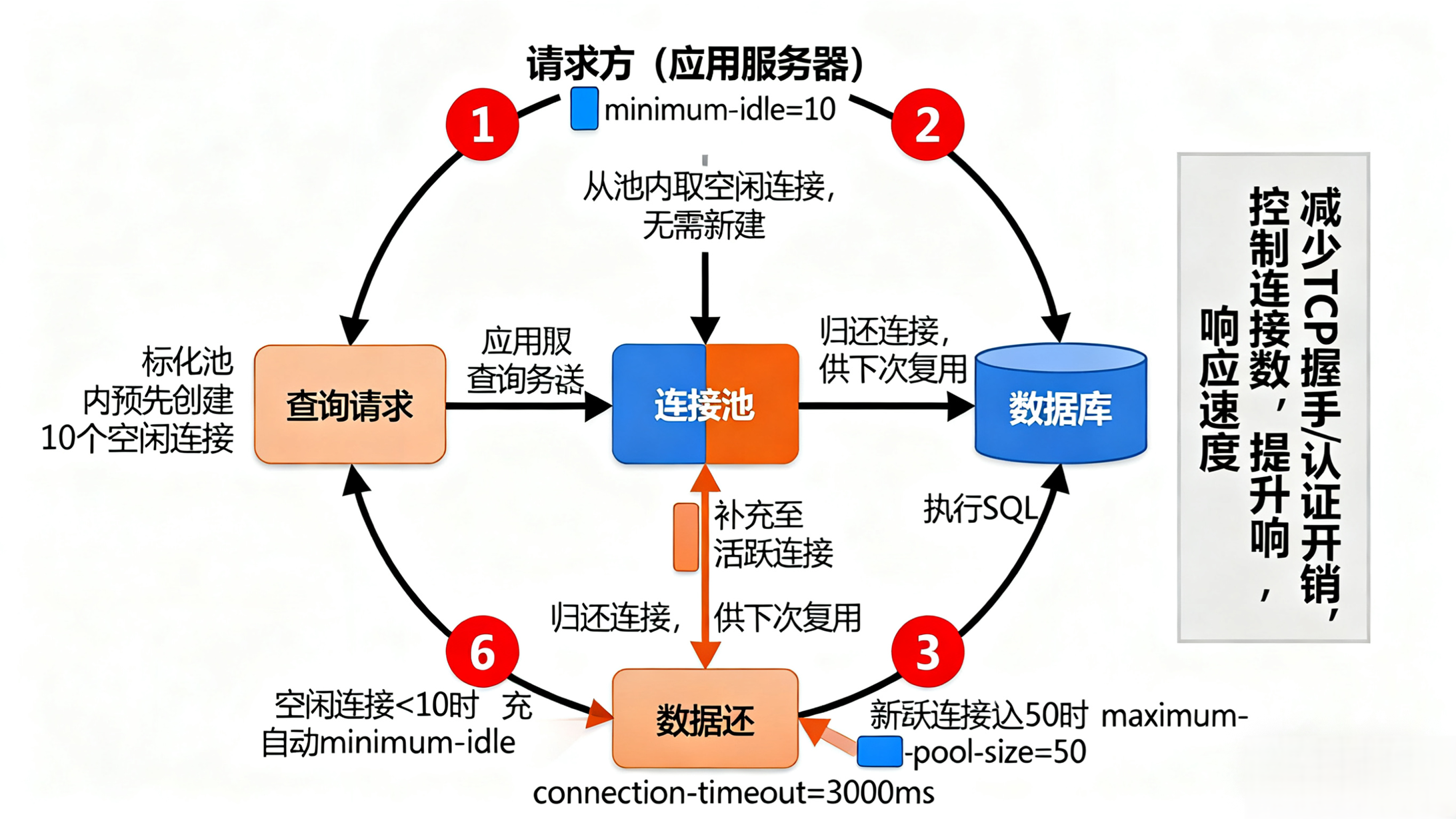
(图 6:HikariCP 连接池工作流程,请求从池获取连接,使用后归还,避免重复创建)
2. HikariCP 核心特性:为什么高并发场景选它?
相比 C3P0、DBCP 等传统连接池,HikariCP 在高并发场景下的优势显著:
-
性能最优:采用 “无锁设计”“快速列表” 等优化,连接获取和归还速度比其他连接池快 2-3 倍;
-
配置极简:默认配置已适配高并发场景,无需过多自定义;
-
监控完善:支持 JMX 监控,可实时查看连接池状态(如活跃连接数、空闲连接数);
-
稳定性强:低延迟、低内存占用,在高并发下不易出现连接泄漏、死锁问题。
3. 高并发场景下的 HikariCP 配置优化:6 个核心参数
HikariCP 的配置需结合业务并发量和数据库性能,核心优化 6 个参数(Spring Boot 配置示例):
spring:
  datasource:
  type: com.zaxxer.hikari.HikariDataSource
  hikari:
  # 1. 连接池名称(用于监控)
  pool-name: order-db-pool
  # 2. 最小空闲连接数:高并发下避免空闲连接过少,需频繁创建连接
  minimum-idle: 10
  # 3. 最大连接数:根据数据库性能和业务并发量设置,MySQL默认151,建议不超过200
  maximum-pool-size: 50
  # 4. 连接超时时间:请求获取连接的超时时间,避免无限等待,建议3000ms
  connection-timeout: 3000
  # 5. 连接存活时间:连接在池中的最大存活时间,避免使用过期连接,建议300000ms(5分钟)
  max-lifetime: 300000
  # 6. 空闲连接超时时间:空闲连接在池中的最大保留时间,建议600000ms(10分钟)
  idle-timeout: 600000
参数配置原则:
-
最大连接数(
maximum-pool-size):需小于数据库最大连接数(如 MySQL 通过show variables like 'max_connections'查看,默认 151),建议设置为 “业务并发量的 1.2-1.5 倍”(如并发 100,设置 150); -
最小空闲连接数(
minimum-idle):高

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)