(五)DQN——开启深度强化学习
之前所讲的各种强化学习算法,如 Q-learning 等,大多是以矩阵的方式建立了一张存储每个状态下所有动作QQQ值的表格(一般叫 Q table),但用表格存储动作价值只适用于:环境的状态和动作均离散,且空间较小时,试想一下:当状态 or 动作连续,或者空间大,此时表格记录显得捉襟见肘。但聪明的你想到:函数拟合(function approximation)!即将这个复杂的Q table视作数据
目录
DQN 算法
在 2013 年的 NIPS 深度学习研讨会上,DeepMind 公司的研究团队发表了 DQN 论文,首次展示了这一直接通过卷积神经网络接受像素输入来玩转各种雅达利(Atari)游戏的强化学习算法,由此拉开了深度强化学习的序幕。
前言
之前所讲的各种强化学习算法,如 Q-learning 等,大多是以矩阵的方式建立了一张存储每个状态下所有动作 Q Q Q 值的表格(一般叫 Q table),但用表格存储动作价值只适用于:环境的状态和动作均离散,且空间较小时,试想一下:当状态 or 动作连续,或者空间大,此时表格记录显得捉襟见肘。
但聪明的你想到:函数拟合(function approximation)!
即将这个复杂的Q table视作数据,使用一个参数化的函数 Q θ Q_\theta Qθ 来拟合这些数据。很显然这是一种近似方式。但是该怎么做拟合比较有效?
聪明的你又想到:神经网络
神经网络具有强大的表达能力,因此我们可以用一个神经网络来表示函数 Q——我们称之为 Q 网络,如下图是工作在CartPole环境中的Q网络示意图:
值得一提的是,通常 DQN(以及 Q-learning)只能处理动作离散的情况,因为在函数 Q Q Q 的更新过程中有 m a x a \mathbf{max}_{a} maxa 这一操作。总之,DQN 主要用来解决连续状态下离散动作的问题。
那么 Q 网络的损失函数是什么呢?
还记得之前 Q-learning 的更新规则吗?该算法是用 TD目标 来增量更新 Q Q Q函数,也即要使 Q ( s , a ) Q(s, a) Q(s,a) 和 TD 目标 r + γ max a ′ ∈ A Q ( s ′ , a ′ ) \boldsymbol{r+\gamma\max_{a^{\prime}\in\mathcal{A}}Q(s^{\prime},a^{\prime})} r+γmaxa′∈AQ(s′,a′) 靠近。
于是,聪明的你再次想到构造均方误差形式的损失函数:
ω ∗ = arg min ω 1 2 N ∑ i = 1 N [ Q ω ( s i , a i ) − ( r i + γ max a ′ Q ω ( s i ′ , a ′ ) ) ] 2 \omega^{*}=\arg\min_{\omega}\frac{1}{2N}\sum_{i=1}^{N}\left[Q_{\omega}\left(s_ {i},a_{i}\right)-\left(r_{i}+\gamma\max_{a^{\prime}}Q_{\omega}\left(s_{i}^{ \prime},a^{\prime}\right)\right)\right]^{2} ω∗=argωmin2N1i=1∑N[Qω(si,ai)−(ri+γa′maxQω(si′,a′))]2
ω \omega ω:神经网络用来拟合函数的参数 ,即每一个状态下所有可能动作的值我们都能表示为 Q ω ( s , a ) Q_{\omega}\left(s,a\right) Qω(s,a)
至此,我们就可以将 Q-learning 扩展到神经网络形式——深度 Q 网络(deep Q network,DQN)算法。
两大模块
经验回放(Experience Replay)
- 为什么需要这个东西?
去除数据相关性,使数据独立;提高样本使用效率 - 这个东西是什么样的?
经验回放机制将历史转移样本存入回放缓冲区,随机小批量采样打破时序相关性,提高样本效率并减少方差。 - 为什么经验回放有如此功效?
一是因为在 MDP 环境中交互采样得到的数据并不满足独立性假设,因为这一时刻的状态和上一时刻的状态有关。非独立同分布的数据很影响神经网络的训练,会使其拟合到最近训练的数据上。采用经验回放可以打破样本之间的相关性,让其满足独立假设。
二是每一个样本可以被使用多次,十分适合深度神经网络的梯度学习。
目标网络(Target Network)
-
为什么需要这个东西?
DQN 算法最终更新的目标是让 Q ω ( s , a ) Q_{ \omega} \left( s,a \right) Qω(s,a) 逼近 r + γ max a ′ Q ω ( s ′ , a ′ ) r+ \gamma \max_{a^{ \prime}}Q_{ \omega} \left( s^{ \prime},a^{ \prime} \right) r+γmaxa′Qω(s′,a′)。由于TD 目标本身就包含神经网络的输出,因此在更新网络参数的同时TD 目标也不断改变,易造成神经网络训练的不稳定性。 -
这个东西是什么样的?
目标网络冻结旧参数用于计算目标 Q值,避免目标随训练网络同步抖动,缓解自举带来的发散风险。通过固定参数,稳定了训练目标。- 训练网络: Q ω ( s , a ) Q_{ \omega} \left( s,a \right) Qω(s,a),用于计算损失函数中的 Q ω ( s , a ) Q_{ \omega} \left( s,a \right) Qω(s,a) 项;
- 目标网络: Q w − ( s , a ) Q_{w^{-}} \left( s,a \right) Qw−(s,a),用于计算原来损失函数中的 ( r + γ max a ′ Q w − ( s ′ , a ′ ) ) \left( r+ \gamma \max_{a^{ \prime}}Q_{w^{-}} \left( s^{ \prime},a^{ \prime} \right) \right) (r+γmaxa′Qw−(s′,a′))
想象你在打靶,如果靶子一直移动,你估计很难打中,训练效果欠佳,但如果我固定靶子,你就能很好地学习打靶了
DQN 算法流程

两种改进方式
但普通的 DQN 存在一定的局限性:
- 过高估计问题:Q值被系统性高估,影响策略质量
- 目标Q值更新不稳定:目标网络更新延迟导致训练振荡
因此,下面介绍两种 DQN 的改进算法:
Double DQN
背景:DQN 对Q值过高估计(overestimation)——源于目标Q值计算中的最大化操作偏差。
解决方案:Double DQN通过将动作选择与评估解耦,解决了DQN的过估计问题。
先把 TD目标的动作价值求解拆解为两部分:选当前状态的最优动作+计算该动作的价值,也即:
Q ω − ( s ′ , arg max a ′ Q ω − ( s ′ , a ′ ) ) \boldsymbol{Q_{\omega^{-}}\left(s^{\prime},\arg\max_{a^{\prime}}Q_{\omega^{-}} \left(s^{\prime},a^{\prime}\right)\right)} Qω−(s′,arga′maxQω−(s′,a′))
当这两部分都用同一套 Q 网络进行计算时,每次得到的都是神经网络当前估算的所有动作价值中的最大值。考虑到通过神经网络估算的 Q 值本身在某些时候会产生正向或负向的误差,在 DQN 的更新方式下神经网络会将正向误差累积。最终会让 Q 值过高估计。
所以,Double DQN 提出用两个独立训练的神经网络来对上面提到的两部分分别进行操作,也即一个网络用于决定选动作,一个用于计算相应动作的价值。具体如下:
r + γ Q ω − ( s ′ , a r g max a ′ Q ω ( s ′ , a ′ ) ) r+ \gamma Q_{ \textcolor{blue}{\omega^{-}}} \left( s^{ \prime}, \underset{a^{ \prime}}{arg \max}Q_{ \textcolor{red}\omega} \left( s^{ \prime},a^{ \prime} \right) \right) r+γQω−(s′,a′argmaxQω(s′,a′))
对比:
| DQN | Double DQN | |
|---|---|---|
| 优化目标 | r + γ Q ω − ( s ′ , a r g max a ′ Q ω − ( s ′ , a ′ ) ) r+ \gamma Q_{ \textcolor{blue}{\omega^{-}}} \left( s^{ \prime}, \underset{a^{ \prime}}{arg \max}Q_{ \textcolor{blue}\omega^{-}} \left( s^{ \prime},a^{ \prime} \right) \right) r+γQω−(s′,a′argmaxQω−(s′,a′)) | r + γ Q ω − ( s ′ , a r g max a ′ Q ω ( s ′ , a ′ ) ) r+ \gamma Q_{ \textcolor{blue}{\omega^{-}}} \left( s^{ \prime}, \underset{a^{ \prime}}{arg \max}Q_{ \textcolor{red}\omega} \left( s^{ \prime},a^{ \prime} \right) \right) r+γQω−(s′,a′argmaxQω(s′,a′)) |
| 动作选取 | 依靠目标网络 Q ω − Q_{ \textcolor{blue}\omega^{-}} Qω− | 依靠训练网络 Q ω Q_{ \textcolor{red}\omega} Qω |
Dueling DQN
Dueling DQN 将 Q 网络建模成:
Q η , α , β ( s , a ) = V η , α ( s ) + A η , β ( s , a ) Q_{ \eta, \alpha, \beta} \left( s,a \right)=V_{ \eta, \alpha} \left( s \right)+A_{ \eta, \beta} \left( s,a \right) Qη,α,β(s,a)=Vη,α(s)+Aη,β(s,a)
A A A 是优势函数,简单说满足等式: A = Q − V A = Q - V A=Q−V,代表该状态下采取不同动作的优势函数,表示采取不同动作的差异性;
η \eta η 是状态价值函数和优势函数共享的网络参数,一般用在神经网络中,用来提取特征的前几层;
α \alpha α 和 β \beta β 分别为状态价值函数和优势函数的参数
也即,Dueling DQN 是对网络结构创新——将卷积特征分流为状态价值函数 V(s) 和动作优势函数 A(s, a) 两个支路,通过聚合层得到 Q(s, a) 。
此时,变成训练神经网络的最后几层的两个分支,分别输出状态价值函数和优势函数,再求和得到 Q Q Q 值,如下图:
为什么要分离出V和A后分别建模?看下面例子:
橙色是智能体注意力集中部位,当智能体前面没车时,车辆自身动作差异不大,此时智能体更关注状态价值,而当其前面有车时(需要超车),智能体开始关注不同动作优势值的差异。
也即某些情境下智能体只会关注状态的价值,而并不关心不同动作导致的差异,此时将二者分开建模能够使智能体更好地处理与动作关联较小的状态。
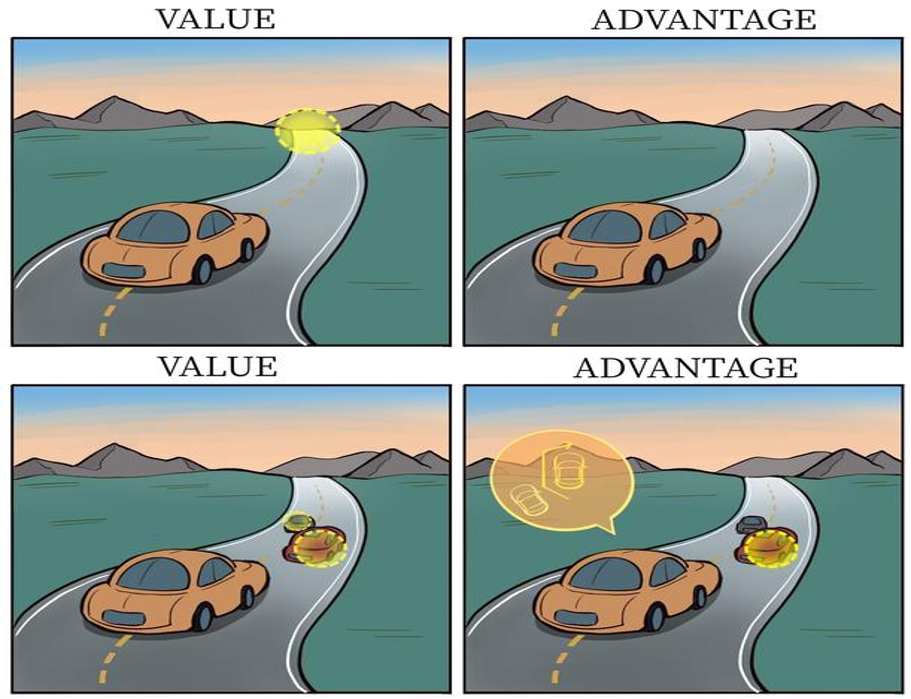
然后来看实现,上文提到Dueling DQN 对 Q 网络建模的公式,其存在对 V V V 和 A A A 值建模不唯一性的问题。如:同样的 Q Q Q 值,如果 V V V 加个任意大小常数 C C C,然后所有 A A A 又减去这个 C C C, Q Q Q 值肯定不变,但是这样关于 V V V 和 A A A 值的建模就可能八仙过海各显神通了,明显不合理。
基于此,Dueling DQN 强制最优动作的优势函数的实际输出为 0,即:
Q η , α , β ( s , a ) = V η , α ( s ) + A η , β ( s , a ) − max a ′ A η , β ( s , a ′ ) Q_{\eta,\alpha,\beta}(\boldsymbol{s,a})=V_{\eta,\alpha}(\boldsymbol{s})+A_{ \eta,\beta}(\boldsymbol{s,a})-\max_{a^{\prime}}A_{\eta,\beta}\left(\boldsymbol {s,a^{\prime}}\right) Qη,α,β(s,a)=Vη,α(s)+Aη,β(s,a)−a′maxAη,β(s,a′)
看上式,如果当前状态选择了最优动作,刚好两个 A A A 互相抵消了,也即: V ( s ) = max a Q ( s , a ) V \left( s \right)= \max_{a}Q \left( s,a \right) V(s)=maxaQ(s,a),这样通过强制最优优势函数为0,也限制出了状态价值函数的建模,确保了两者的唯一性。
在具体实现中,还可以用平均代替最大化操作,即:
Q η , α , β ( s , a ) = V η , α ( s ) + A η , β ( s , a ) − 1 ∣ A ∣ ∑ a ′ A η , β ( s , a ′ ) Q_{\eta,\alpha,\beta}(s,a)=V_{\eta,\alpha}(s)+A_{\eta,\beta}(s,a)-\frac{1}{| \mathcal{A}|}\sum_{a^{\prime}}A_{\eta,\beta}\left(s,a^{\prime}\right) Qη,α,β(s,a)=Vη,α(s)+Aη,β(s,a)−∣A∣1a′∑Aη,β(s,a′)
这里感觉平均操作更多是在做标准化其优势函数值
最后可能有此问题——为什么 Dueling DQN 会比 DQN 好?
部分原因在于 Dueling DQN 能更高效学习状态价值函数。每一次更新时,函数 V V V 都会被更新,这也会影响到其他动作的 Q Q Q 值。而传统的 DQN 只会更新某个动作的 Q Q Q 值,其他动作的 Q Q Q 值就不会更新。因此,Dueling DQN 能够更加频繁、准确地学习状态价值函数。
总结
- DQN 主要思想:基于函数拟合思想,使用神经网络拟合动作价值函数 Q Q Q
- DQN 主要解决连续状态下离散动作的问题
- DQN 两大主要模块:经验回放和目标网络
- DQN 两种经典改进方式:
- Double DQN:解耦动作选择与价值评估,解决了 DQN 中对值的过高估计。
- Dueling DQN:分离状态价值函数和优势函数,能够很好地学习到不同动作的差异性,在动作空间较大的环境下非常有效。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)