【图神经网络】GNN发展与意义
引言
想象一下。早晨,你在社交媒体上刷到朋友分享的聚会照片,应用立刻为你推荐了几个“你可能认识的人”,而他们中的一些确实是你朋友的朋友。出门时,地图应用为你规划出避开拥堵的最佳路线。晚上休息时,视频网站精准地推送了一部你期待已久的电影。
这些看似毫不相关的体验,背后都有一个共同的线索:网络,一个由无数节点和它们之间无形关系构成的世界。在数学和计算机科学中,我们称这种网络结构为“图”(Graph)。而正是这种无处不在的“图”结构,催生了人工智能领域的分支之一:图神经网络(Graph Neural Networks, GNN)。
在深入GNN之前,我们首先要理解什么是“图”。它并非指柱状图或折线图,而是一种由“节点”(Nodes/Vertices)和连接节点的“边”(Edges)组成的数学结构。这就像夜空中的星座,星星是节点,连接它们的想象线就是边。一个简单的“节点-边”结构,却足以描绘我们现实世界中无数复杂的系统:
- 社交网络:每个人是节点,好友关系是边。
- 分子结构:原子是节点,化学键是边。
- 交通网络:城市或交叉路口是节点,公路、铁路或航线是边。
- 知识图谱:维基百科中的词条是节点,它们之间的超链接是边。
传统的深度学习模型,如卷积神经网络(CNN)和循环神经网络(RNN),在处理图像(规则的像素网格)和文本(线性的单词序列)这类“欧几里得空间”数据时取得了巨大成功。然而,当面对“图”这种结构时,它们却显得力不从心。原因在于图数据具有几个独特的挑战:
- 结构不规则:图中的节点没有固定的邻居数量。你的社交网络里,有的朋友可能只有寥寥数个好友,而有的则是社交达人,拥有成百上千的连接。
- 顺序无关性:一张图片里的像素可以从左到右、从上到下排列,但图中的节点没有天然的顺序。将一张图的节点随机打乱编号,它仍然是同一张图。
- 关系的重要性:在图数据中,节点之间的连接关系本身就蕴含着至关重要的信息。你是谁,不仅取决于你自身的属性,更取决于你和谁相连。
为了解决这些挑战,图神经网络应运而生。它是一种专为图结构数据设计的神经网络,其核心能力就是从关系中学习。本文带你从GMAT的基础概念出发,深入探索它的核心思想、发展脉络、应用场景,并最终通过一个完整的实战案例,让你亲手搭建并训练你的第一个GNN模型。
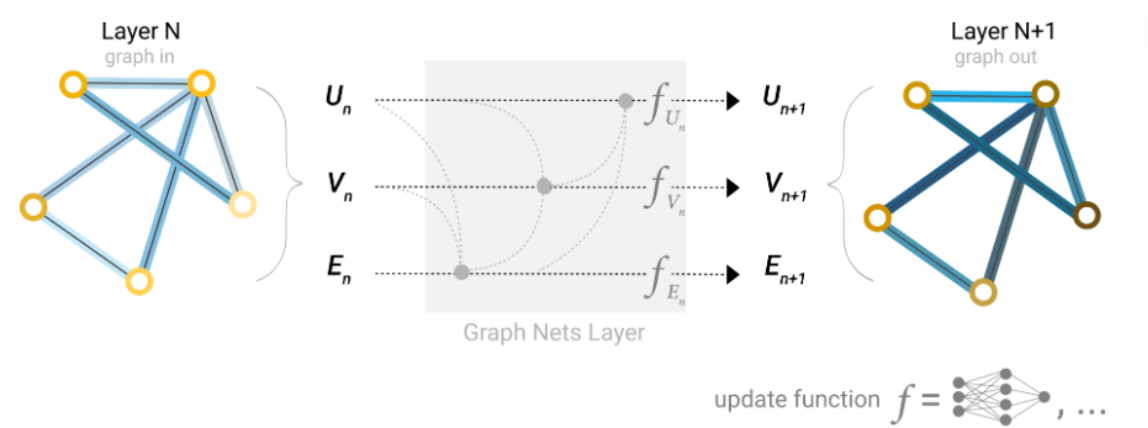
第一部分:GNN是什么?
要真正理解GNN,我们需要回到它的起点,看看最初的研究者们是如何构想出这样一个能在图结构上传播和学习信息的模型的。GNN的发展并非一蹴而就,而是经历了一个从理论到实践、从复杂到简洁的演化过程。
1.1 初代图神经网络 (GNN)
图神经网络的概念最早可以追溯到2005年,但其理论基础则是由Franco Scarselli等人在2009年的论文《The Graph Neural Network Model》中正式奠定的。这个初代的GNN模型,其核心思想既优雅又深刻:通过节点间的信息传递,让整个图系统达到一个稳定的平衡状态,而这个稳定状态下的节点表示(Embedding)就蕴含了丰富的结构信息。
这个过程可以想象成在一个平静的湖水中投入一颗石子,涟漪会从中心向四周扩散,直到整个湖面再次恢复平静,但此时湖水的状态已经记录了“石子投入”这个事件的信息。
状态更新与输出:GNN的两大核心函数
初代GNN通过一个迭代的过程,不断更新每个节点的状态,直到收敛。这个过程由两个关键函数驱动:
-
局部转移函数 (local transition function),记作
f:这个函数定义了每个节点如何根据其自身特征、邻居节点的特征以及邻居节点的上一时刻状态来更新自己当前时刻的状态。其数学表达式可以写成: hvt+1=f(xv,xco[v],hne[v]t,xne[v])hvt+1=f(xv,xco[v],hne[v]t,xne[v])
让我们来拆解一下这个公式:
- hvt+1hvt+1:节点
v在t+1时刻的隐藏状态(或称为状态向量)。这是我们想要计算的目标。 - xvxv:节点
v自身的特征向量。 - xco[v]xco[v]:与节点
v相连的边的特征向量集合。 - hne[v]thne[v]t:节点
v的所有邻居节点在t时刻的隐藏状态集合。这是信息传递的关键! - xne[v]xne[v]:节点
v的所有邻居节点的特征向量集合。
最重要的一点是,函数
f是全局共享的,意味着图上所有节点都使用同一个更新规则。在深度学习的框架下,这个f通常就是一个前馈神经网络(FNN)。它接收来自邻居的、不定长的信息,通过一个聚合操作(如求和)将其整合,然后更新中心节点的状态。 - hvt+1hvt+1:节点
-
局部输出函数 (local output function),记作
g:当节点的隐藏状态经过多轮迭代并最终收敛后,这个函数负责根据节点最终的稳定状态和自身特征,生成面向特定任务的输出。其数学表达式为: ov=g(hv,xv)ov=g(hv,xv)
- ovov:节点
v的最终输出。例如,在社交网络中预测一个用户是否是水军账号,这个输出可以是一个二分类的概率值。 - hvhv:节点
v收敛后的最终隐藏状态。 - 同样,
g也是一个全局共享的函数,通常也由一个神经网络来实现。
- ovov:节点
整个流程就像下图所示,信息在图的结构上流动,经过T个时间步后,每个节点的状态趋于稳定,此时再通过输出函数 g 得到每个节点的预测结果。
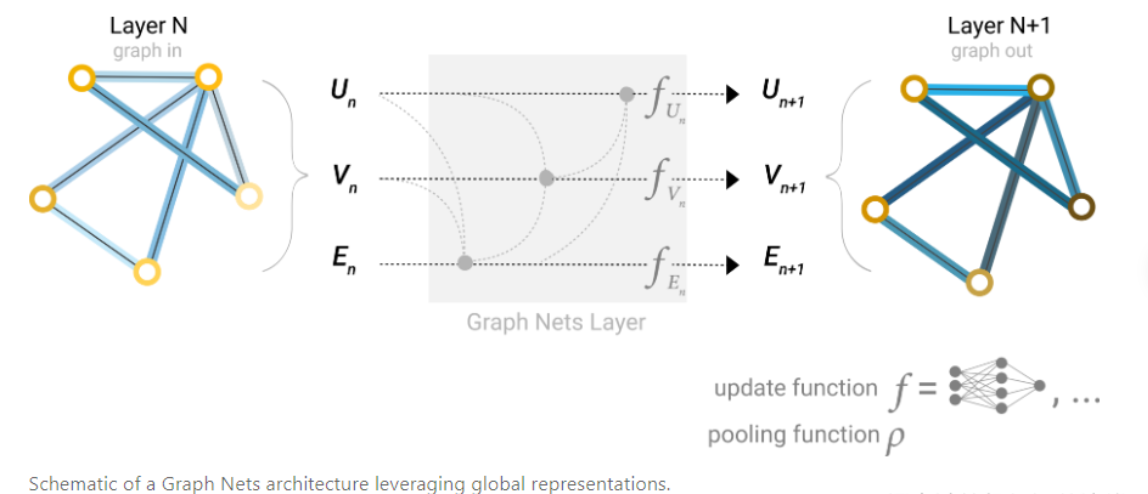
理论基石:巴拿赫不动点定理
你可能会问:我们怎么能保证这个迭代过程一定会停止,而不是永无休止地更新下去呢?这正是初代GNN理论的精妙之处,它巧妙地借用了数学中的巴拿赫不动点定理。
该定理指出,在一个完备的度量空间中,如果一个函数是“压缩映射”(Contraction Mapping),那么无论从哪个点开始,反复应用这个函数,最终都会收敛到唯一的一个“不动点”。
什么是压缩映射?想象一下,你有一张地图,你将这张地图缩小后放在它所描绘的真实土地上。根据不动点定理,地图上必然有且仅有一个点,它所在的位置恰好就是它所代表的真实地点。这个点就是不动点。压缩映射就是指,经过函数变换后,空间中任意两点间的距离都会变小。
在GNN中,只要我们设计的状态更新函数 f(或者说由所有 f 组成的全局更新函数 F)是一个压缩映射,那么无论节点的初始状态 H0H0 是什么,经过反复迭代 Ht+1=F(Ht,X)Ht+1=F(Ht,X),最终都会收敛到一个唯一的、稳定的状态 H。
为了保证 f 是一个压缩映射,研究者在模型的损失函数中加入了一个对 f 的雅可比矩阵的惩罚项,从而在训练过程中约束它的“压缩”性质。
初代GNN的局限性
尽管初代GNN在理论上非常完备,但它的核心——不动点理论,既是其优势,也带来了难以克服的局限:
- 计算效率低下:为了达到收敛,模型需要进行不确定次数的迭代,这在大型图上可能非常耗时。
- 过度平滑 (Over-smoothing):当信息在图上传播很多轮次后,每个节点的表示会变得越来越相似,因为它们都融合了大量来自远处邻居的信息。最终,所有节点的表示可能趋于一致,从而失去了区分度,这使得节点级别的任务变得困难。想象一下,将红、黄、蓝三种颜色的墨水滴入水中,一开始颜色分明,但随着时间推移和扩散,最终整杯水都会变成一种难以分辨的浑浊颜色。
- 特征利用不充分:模型将边仅仅看作信息传递的通道,而没有为边的类型或属性设置独立的、可学习的参数,限制了模型在异构图(包含多种类型节点和边)上的表达能力。
1.2 门控图神经网络 (GGNN)
为了克服初代GNN的局限,特别是其对不动点理论的依赖和计算效率问题,研究者们从当时已经非常成熟的循环神经网络(RNN)领域汲取灵感,提出了门控图神经网络(Gated Graph Neural Network, GGNN)。
GGNN做出了几个关键的改变,使其更符合现代深度学习的范式:
- 告别不动点:GGNN不再追求状态收敛。它将信息传递的过程视为一个固定步数的循环过程,就像RNN处理一个固定长度的序列一样。这大大提高了计算效率。
- 引入门控机制:GGNN借鉴了GRU(门控循环单元)的设计,引入了门控机制来控制信息的流动和更新。这使得模型能更好地捕捉长距离依赖,并缓解梯度消失/爆炸问题。
- 采用BPTT算法: 它在结构上更像RNN,GGNN可以直接使用时间反向传播算法(Backpropagation Through Time, BPTT)进行端到端的训练,而不再需要复杂的Almeida-Pineda算法。
GGNN的状态更新公式变得更加现代: hvt+1=GRU(hvt,∑u∈ne[v]Wedgehut)hvt+1=GRU(hvt,∑u∈ne[v]Wedgehut) 这里,hvthvt 是节点 v 在 t 时刻的状态,GRU单元接收上一时刻自身的状态和当前时刻聚合到的邻居信息作为输入,来计算新的状态。值得注意的是,公式中的 WedgeWedge 是一个与边的类型相关的可学习权重矩阵,这使得GGNN能够自然地处理异构图,学习不同关系的不同语义。
此外,GGNN通常将节点的初始特征 xvxv 直接用作其隐藏状态的初始值 hv0hv0,这使得节点的自身属性从一开始就参与到信息传递中。
1.3 消息传递范式 (Message Passing)
无论是初代GNN的迭代收敛,还是GGNN的固定步数循环,它们的本质都可以被一个更通用、更简洁的框架所概括,这就是消息传递神经网络(Message Passing Neural Network, MPNN)范式。
这个范式将GNN的一层(或一次迭代)操作分解为三个核心步骤:
- 消息计算 (Message Calculation):每个节点
u根据自身的状态 huhu 和它与邻居v连接的边的特征 x(u,v)x(u,v),为邻居v生成一条“消息” mu→vmu→v。 mu→v=Message(hu,hv,x(u,v))mu→v=Message(hu,hv,x(u,v)) - 消息聚合 (Message Aggregation):每个节点
v收集所有来自其邻居的消息,并通过一个置换不变的聚合函数(如求和、均值、最大值)将它们整合成一条总信息 mvmv。 mv=Aggregate({mu→v∣u∈ne[v]})mv=Aggregate({mu→v∣u∈ne[v]}) - 状态更新 (State Update):每个节点
v结合自己当前的状态 hvhv 和聚合到的总信息 mvmv,通过一个更新函数来计算自己的新状态 hv′hv′。 hv′=Update(hv,mv)hv′=Update(hv,mv)
这个“消息传递”的视角极大地统一了GNN的世界。不同的GNN模型,如GCN、GAT、GraphSAGE等,都可以看作是在这个框架下,对Message、Aggregate和Update函数采用了不同的设计。它清晰地揭示了GNN的核心机制:每个节点通过不断地与邻居交换信息,来丰富和更新自身的表示,使其从一个孤立的实体,变成一个感知了周围网络结构和邻居属性的、上下文感知的实体。
第二部分:GNN能做什么用?—— 跨越领域的应用场景
GNN的强大之处在于其普适性。只要一个问题可以被建模成“图”结构,GNN就有可能在其中发挥作用。这使得GNN的应用遍地开花,从前沿科学到日常生活,都能看到它的身影。
2.1 药物研发与生命科学
- 分子性质预测:一个分子可以被天然地看作一张图,其中原子是节点,化学键是边。GNN可以学习分子的图表示,并用于预测其化学性质,如溶解度、毒性、活性等。这极大地加速了新药筛选的过程,降低了研发成本。Atomwise等公司正在利用GNN从数百万种化合物中快速筛选潜在的候选药物。
- 蛋白质工程:蛋白质是执行生命功能的复杂大分子,其功能由其三维结构决定。蛋白质同样可以被建模为图。DeepMind的AlphaFold2虽然是一个复杂的系统,但也融入了基于图的推理思想,在蛋白质结构预测方面取得了革命性突破,这对理解疾病机理和设计靶向药物至关重要。
2.2 推荐系统
点击链接【图神经网络】GNN发展与意义阅读原文

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)