【Python深度学习系列】深入了解Hydra框架与PyTorch的结合(案例分析)
深入了解Hydra框架与PyTorch的结合(案例分析)
·
这是我的第432篇原创文章。
一、引言
在深度学习的世界中,模型训练与超参数管理是实施成功的关键因素。近年来,Hydra框架因其灵活的配置管理和易于集成的特性而受到越来越多的关注。在本篇文章中,我们将探讨Hydra框架如何与PyTorch结合,并展示其在实际项目中的应用。通过一个简单的代码示例来看看Hydra是如何工作的。我们将创建一个简单的PyTorch模型,并使用Hydra管理其超参数。
二、实现过程
2.1 安装Hydra
Hydra是一个用于简化复杂应用程序配置的框架。它允许用户以层次化的方式组织配置文件,支持动态配置、命令行覆盖以及多种配置模式。使用Hydra,开发者可以更轻松地管理深度学习实验中的超参数,同时保持代码的整洁性。
pip install hydra-core2.2 基本的配置示例
首先,创建一个名为config.yaml的文件,配置我们模型的超参数:
model:
name: SimpleNet
layers: 3
units: 64
train:
epochs: 10
batch_size: 32
learning_rate: 0.0012.3 PyTorch模型与Hydra集成
然后,我们可以创建一个train.py文件,读取配置并训练模型:
import hydra
from omegaconf import DictConfig
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
class SimpleNet(nn.Module):
def __init__(self, layers, units):
super(SimpleNet, self).__init__()
self.fc = nn.Sequential(
*[nn.Linear(units, units) for _ in range(layers)] + [nn.ReLU()]
)
def forward(self, x):
return self.fc(x)
@hydra.main(version_base=None, config_path=".", config_name="config")
def main(cfg: DictConfig):
model = SimpleNet(cfg.model.layers, cfg.model.units)
optimizer = optim.Adam(model.parameters(), lr=cfg.train.learning_rate)
# Dummy dataset
data = torch.randn((100, cfg.model.units))
target = torch.randint(0, 2, (100,))
dataset = Data.TensorDataset(data, target)
train_loader = Data.DataLoader(dataset, batch_size=cfg.train.batch_size)
for epoch in range(cfg.train.epochs):
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = nn.CrossEntropyLoss()(outputs, labels)
loss.backward()
optimizer.step()
if __name__ == "__main__":
main()在上面的代码中,我们首先定义了一个简单的神经网络SimpleNet。然后,@hydra.main装饰器用于将main函数转换为Hydra应用程序。这使得我们能够通过命令行或配置文件灵活配置模型的超参数。我们可以用Mermaid绘制一个流程图,展示运行流程:
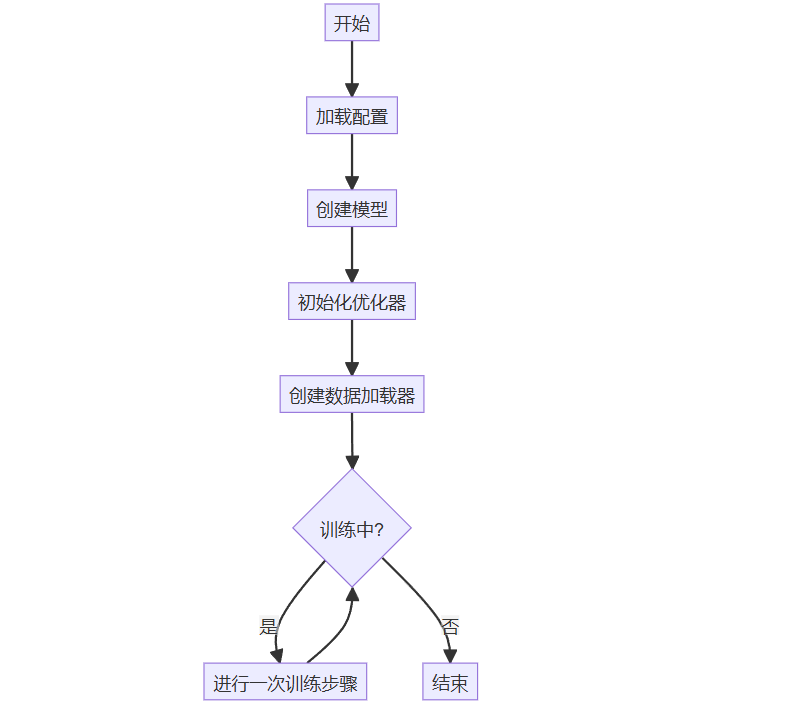
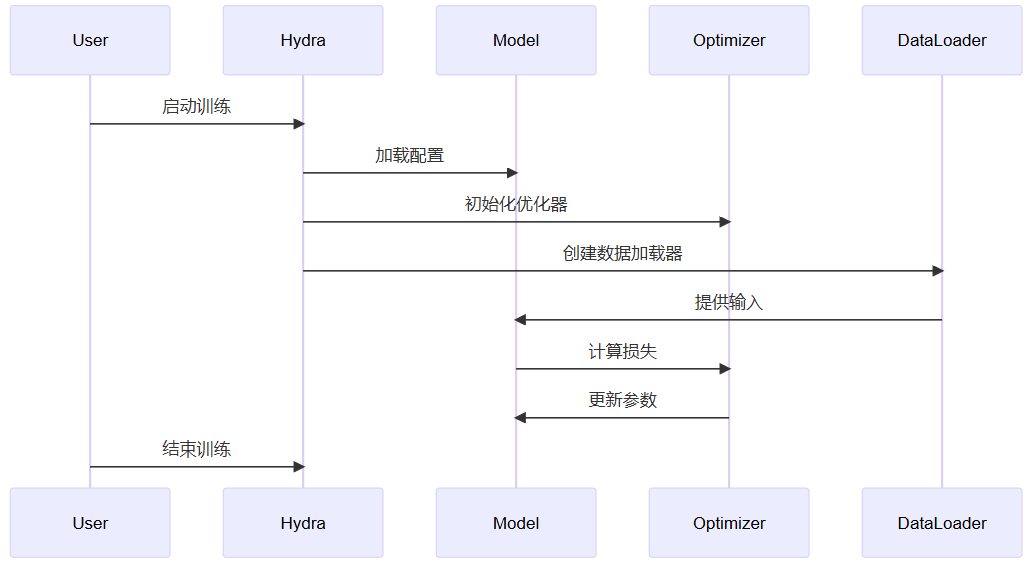
训练过程的交互也可以用序列图表示:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)