神经网络学习(一)前馈神经网络
本文介绍了前馈神经网络的基本原理。神经网络通过线性变换(Wx+b)与非线性激活函数(如ReLU、Sigmoid)的组合来逼近复杂关系。输入层接收数据,隐藏层进行特征变换,输出层根据任务类型设计。损失函数(如MSE、MAE)衡量预测误差,梯度下降算法通过计算参数梯度并反向传播来优化网络权重。整个过程体现了"线性组合+非线性激活"的通用逼近能力,通过迭代训练使预测值逐步接近真实值。
·
前馈神经网络
1. 引言:神经网络的本质
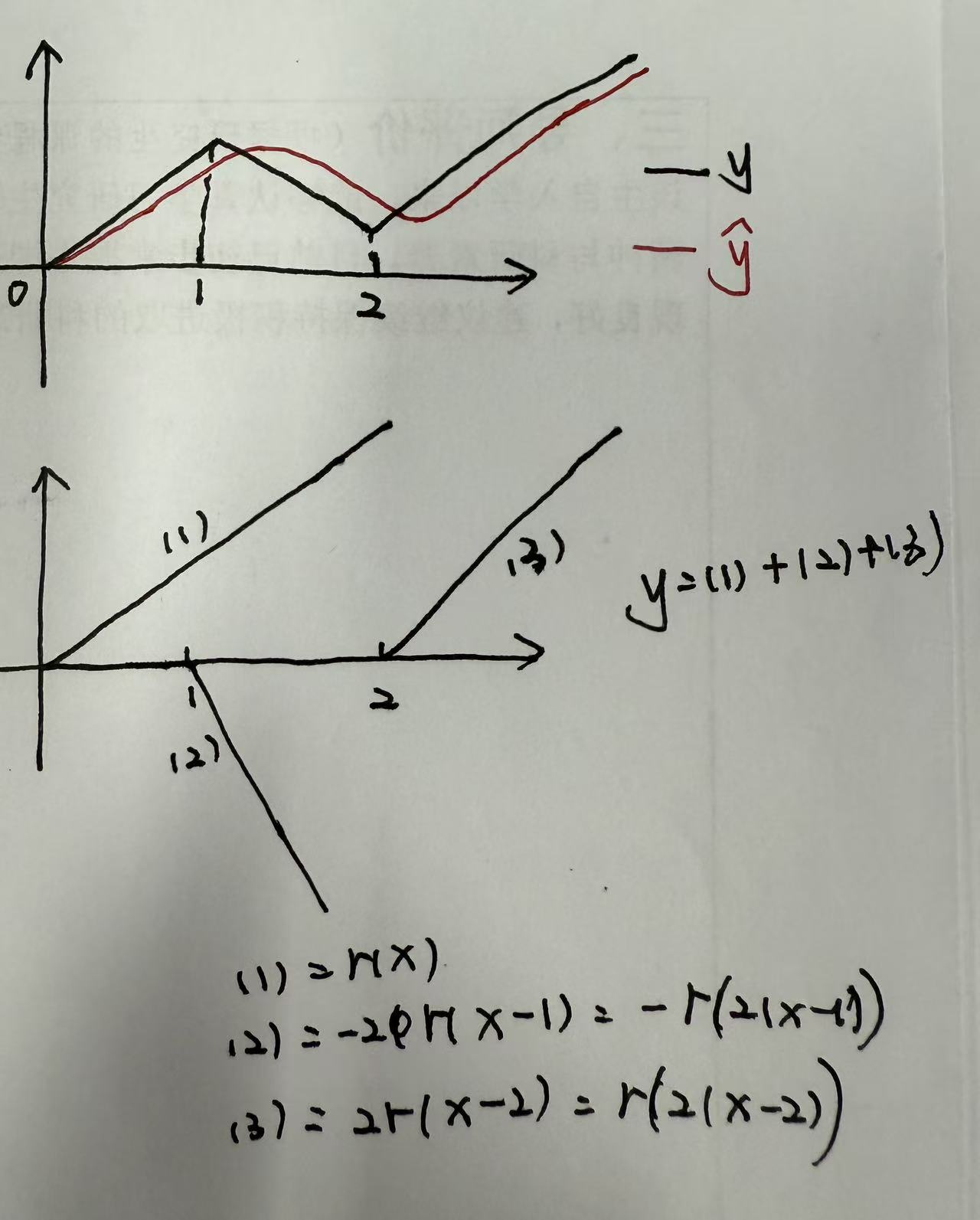
- 神经网络的核心目标:通过线性变换的组合逼近非线性关系。
- 如上图的一条非线性曲线,可以通过(1)、(2)、(3)三条线性曲线的组合形成
2. 神经网络基础结构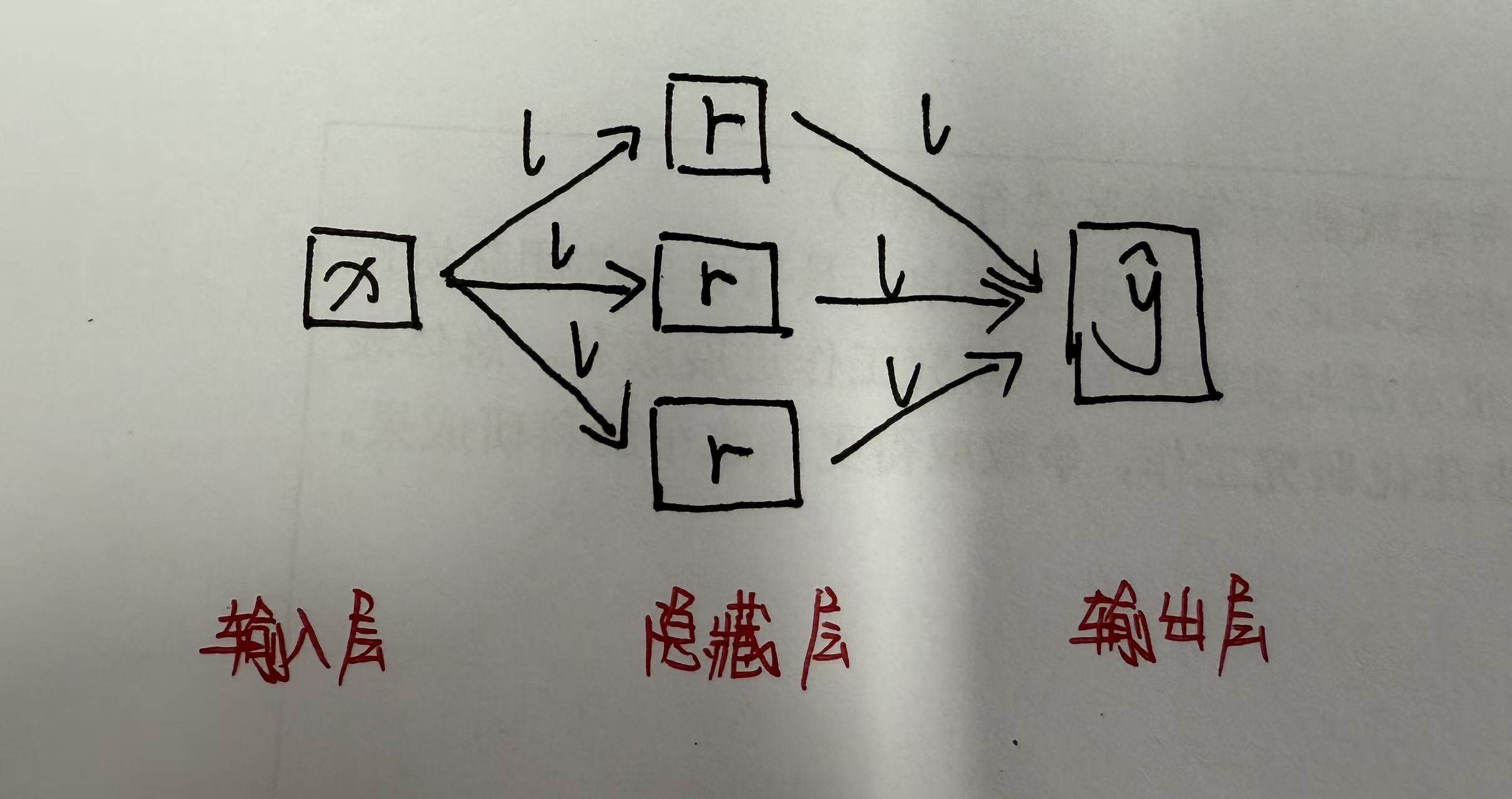
- 输入层:原始数据的向量化表示(如像素值、文本编码)。
- 隐藏层:通过权重矩阵实现线性变换(Wx + b),叠加激活函数引入非线性。
- 输出层:根据任务类型设计(如分类用Softmax,回归用线性输出)。
- 权重:就是线性变换中的参数W,可用于调整。
- bios偏置:线性变换中的参数b。
3. 激活函数:非线性的关键
- 作用:打破线性叠加的局限性(如ReLU、Sigmoid、Tanh)。
- 示例:$ReLU(x) = \max(0, x)$,解决梯度消失问题。
- $Sigmoid(x) = 1/(1+math.exp(-x))$
4. 损失函数:模型的“错误度量”
- 定义:对于每个点都可以得到神经网络的输出和真实值的误差,损失函数是用于描述这个差距的,通常用差值平方或差值绝对值取平均得到。
- 公式示例:
- $ \text{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i| $
MAE表示平均绝对误差(Mean Absolute Error)。y_i是第i个观测的真实值。ŷ_i是第i个观测的预测值或拟合值。n是观测的总数。
- $ \text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 $
- MSE 表示均方误差(Mean Squared Error)。
- y_i 是第 i 个观测的真实值。
- ŷ_i 是第 i 个观测的预测值或拟合值。
- n 是观测的总数。
5. 梯度与梯度下降:优化原理
- 梯度:损失函数对各参数的偏导数。梯度是由损失函数对每个权重的偏导数组成的向量。在每个权重的方向上是损失函数变化最快的方向。
- 梯度下降:沿负梯度方向更新参数。
以下图为例取输入x1=100(房子面积),x2=3(卧室数量),x3=5(房龄),y的真实值y_true为300(真实房价),这时候每个输入都有一个权重w,然后b为偏置(基础房价),我们通过计算得到y的预测值y_pred=180(预测房价),离真实的房价很远。
计算出损失函数lose_function,对每个参数求偏导可以得到梯度。
代入学习率lr=0.00001(因为梯度过大),可以得到每个权重的新值,重新计算预测值就会发现等于204.084,离真实值更加近了,这样的过程也就是神经网络训练中的一轮训练。
这样做的好处是什么呢,远离目标值的时候,学习率*梯度的值很大,快速接近。而近的时候值就很小,慢慢靠近,不会错过目标。
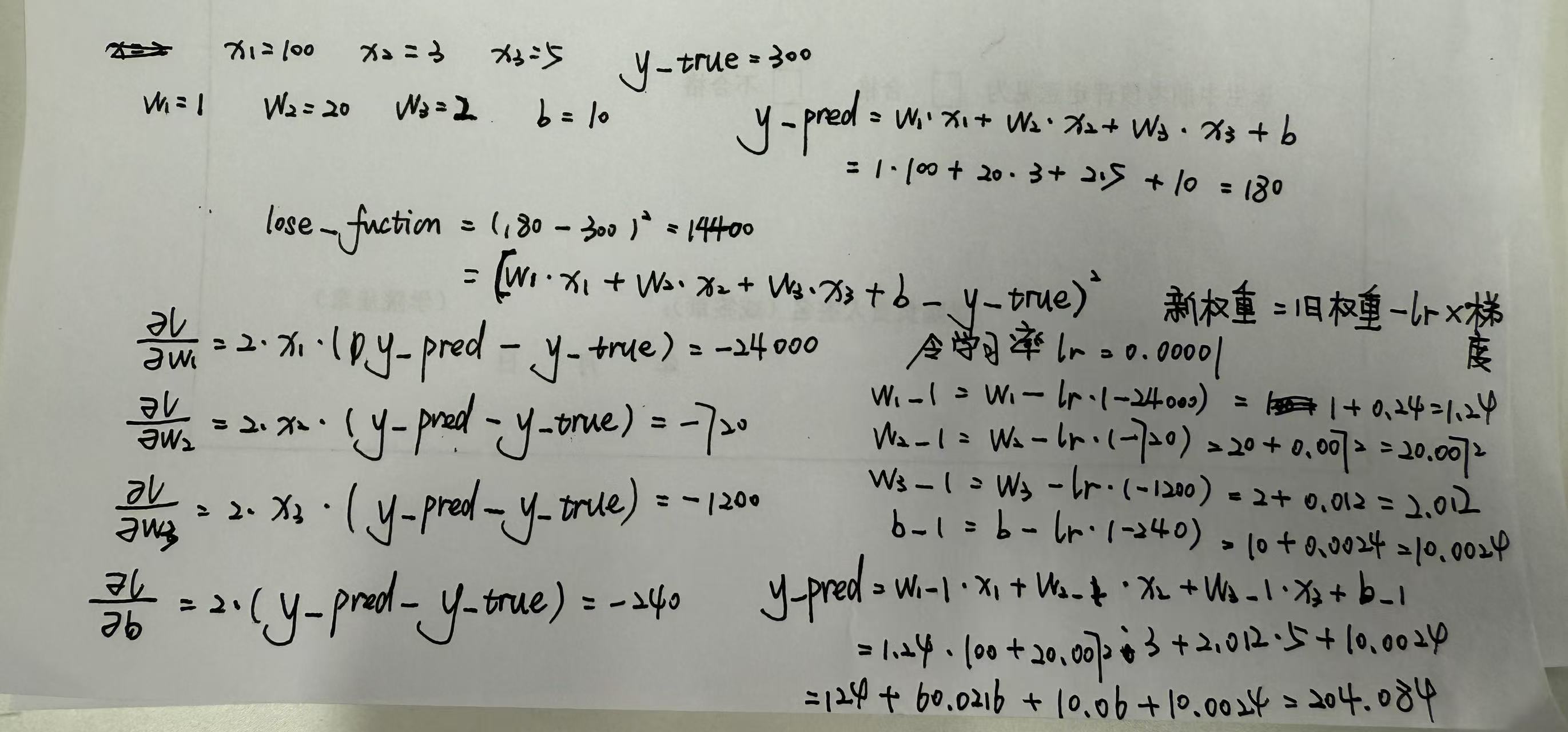
6. 总结:从理论到实践的闭环
- 强调“线性组合+非线性激活”的通用逼近能力。
- 简要提及反向传播的链式法则实现自动求导。
此大纲避免步骤词汇,以概念关联性推进,适合技术文章写作。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)