【数据库原理笔记】1 关系模型,关系代数——超详细+具体例题
🎯 一、关系模型
关系数据模型(Relational Data Model)是数据库领域最核心的理论基础之一,由 E.F. Codd 在 1970 年提出,现已成为现代数据库系统(如 MySQL、Oracle、PostgreSQL)的标准模型。其核心思想是用 二维表(关系) 组织数据,并通过数学理论(集合论、谓词逻辑)保证数据的一致性和完整性。
1. 核心概念
(1)关系(Relation)
-
定义:一张二维表,由行(元组)和列(属性)组成。
-
示例:
学号(SNO) 姓名(SNAME) 性别(SEX) 001 张三 男 002 李四 女
(2)属性(Attribute)
-
表的列,表示数据的某一特征(如“姓名”)。
-
域(Domain):属性的取值范围(如“性别”的域是
{男, 女}
(3)元组(Tuple)
-
表的行,表示一个实体的完整信息(如学生“张三”的记录)。
(4)键(Key)
-
主键(Primary Key):唯一标识元组的属性(如“学号”)。
-
外键(Foreign Key):引用其他表主键的属性(如“选课表”中的“学号”引用“学生表”)。
2. 关系模型的数学基础
关系模型基于 集合论 和 一阶谓词逻辑:
-
关系是元组的集合,因此支持集合操作(并、差、交、笛卡尔积)。
-
关系代数 提供操作符(如选择
σ、投影Π、连接⋈)来查询数据。
🎯 二、关系模式
关系模式是关系数据库设计的核心概念,定义了关系的逻辑结构及约束规则。它是关系模型的静态描述,决定了数据如何被组织和约束。
1. 关系模式的定义
关系模式是关系的型(Type)的描述,包含:
-
关系名:表的唯一标识(如
STUDENT)。 -
属性集:表的列及其数据类型(如
学号 CHAR(7))。 -
完整性约束:主键、外键、域约束等。
形式化表示:R(U, D, DOM, F, PK)
-
U:属性集合(如
{SNO, SNAME, SEX})。 -
D:属性对应的域(如
SNO的域是7位数字)。 -
DOM:属性到域的映射(如
DOM(SNO) = D_SNO)。 -
F:属性间的函数依赖(如
SNO → SNAME)。 -
PK:主键(如
SNO)。
2. 关系模式 vs. 关系实例
| 对比项 | 关系模式(Schema) | 关系实例(Instance) |
|---|---|---|
| 定义 | 关系的逻辑结构(表头) | 关系的具体数据(表内容) |
| 稳定性 | 相对稳定(设计阶段确定) | 动态变化(随数据增删改查变化) |
| 示例 | STUDENT(SNO, SNAME, SEX) |
('001', '张三', '男') |
3. 关系模式的核心要素
(1)属性(Attribute)
-
表的列,表示实体的特征。
-
原子性:属性不可再分(满足第一范式,1NF)。
-
✅ 合法:
年龄 INT -
❌ 非法:
联系方式(电话, 地址)(需拆分为两列)。
-
(2)域(Domain)
-
属性的取值范围(如 性别的域为 {'男', '女'})
(3)键(Key)
-
候选键(Candidate Key):能唯一标识元组的最小属性集。
-
主键(Primary Key):从候选键中选定的唯一标识符。一个表只能有一个主键。
(4)外键(Foreign Key)
-
引用其他表主键的属性,维护参照完整性。
🎯 三、键(超键),候选键,主键
为了清晰理解这些概念,我们以一个 学生信息表(STUDENT) 为例,逐步分析不同类型的键。
假设 STUDENT 表包含以下字段:
| 字段名 | 说明 | 特性 |
|---|---|---|
学号(SNO) |
唯一标识学生 | 无重复,非空 |
身份证号(ID) |
学生身份证号 | 无重复,非空 |
姓名(SNAME) |
学生姓名 | 可能重复(如“张三”) |
手机号(PHONE) |
学生联系方式 | 可能为空(新生未登记) |
1. 超键(Superkey)
定义:能唯一标识表中每一行的 属性或属性组合(可能包含冗余属性)。
示例:以下组合均为 STUDENT 表的超键:
-
{SNO} 学号本身可唯一标识学生。 -
{ID} 身份证号也可唯一标识学生。 -
{SNO, SNAME} 学号已能唯一标识,SNAME是冗余的。 -
{ID, PHONE} 身份证号已足够,其他属性冗余。
关键点:
-
超键的唯一性由 所有属性的组合 决定,而非单个属性。
-
超键可能包含不必要的属性(如
{SNO, SNAME}中的SNAME)。
2. 候选键(Candidate Key)
定义:最小的超键(即不含冗余属性),表中可能有多个候选键。
示例:STUDENT 表的候选键:
-
{SNO} 学号是最小唯一标识符。 -
{ID} 身份证号也是最小唯一标识符。
排除的非候选键:
-
{SNO, SNAME}:SNAME冗余,不是最小超键。 -
{ID, PHONE}:PHONE冗余。
关键点:
-
候选键是超键的子集,且不能再减少属性(最小性)。
-
一个表可能有多个候选键(如
SNO和ID)。
3. 主键(Primary Key)
定义:从候选键中 选定一个 作为表的唯一标识符,需满足:
-
唯一性:主键值不能重复。
-
非空性:主键值不能为
NULL。 -
不可变性:主键值通常不修改。
示例:从候选键 {SNO}、{ID}中,选择 SNO 作为主键:
4. 对比总结
| 键类型 | 定义 | 示例(STUDENT表) | 特点 |
|---|---|---|---|
| 超键 | 能唯一标识行的属性组合(含冗余) | {SNO}, {ID}, {SNO, SNAME} |
不要求最小性 |
| 候选键 | 最小的超键(无冗余属性) | {SNO}, {ID} |
表中可能有多个候选键 |
| 主键 | 从候选键中选定的唯一标识符 | SNO(被选为主键) |
唯一、非空、不可变 |
符号表述:
关系模型,
- 超键:
(K函数决定R)
- 候选键:
,不存在
,使得
- 关系R选定候选键K时,K是主键
- 外键
,
, K是R的外键,K是R'的外键
再举例:有以下关系:
id name street 约束:同一个street的name不同。则:
键:{id}, {id, name}, {id, street}, {id, name, street}, {name, street}
候选键:{id}, {name, street}
🎯 四、关系代数及其运算
关系代数是数据库理论中用于表达数据库查询操作的数学理论。
它提供了一组操作符,用于对关系(即表)进行操作。以下是一些基本的关系代数运算:
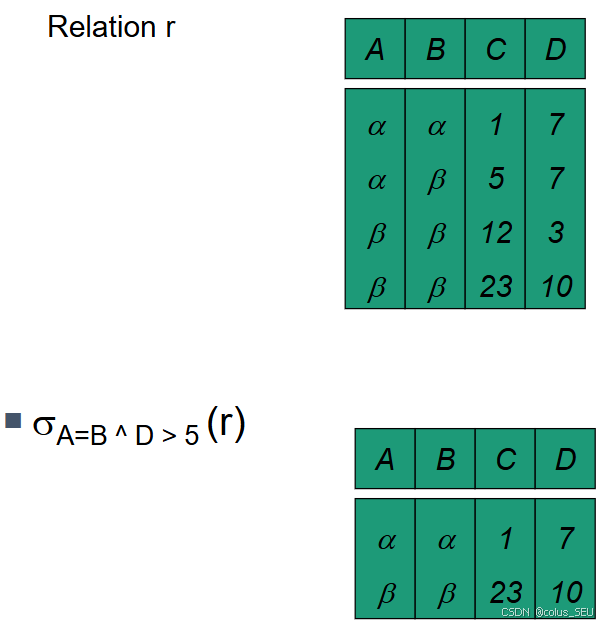
选择(Selection) 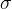
-
从关系中选择满足特定条件的元组(行)。
-
格式:
-
举例:
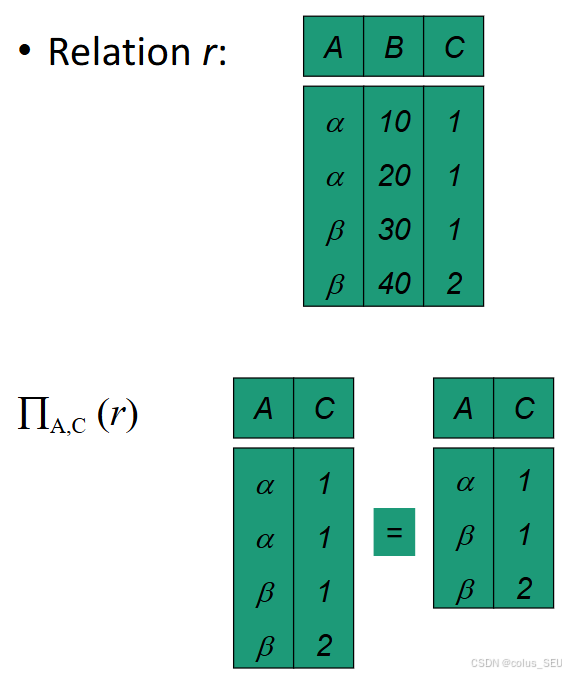
投影(Projection) 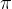
-
从关系中选择特定的属性(列)。
-
格式:
-
举例:
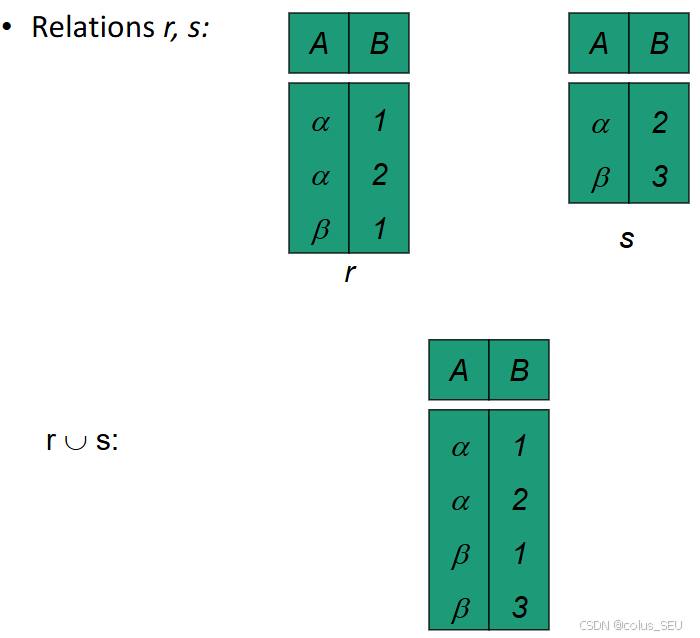
并(Union) 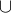
-
合并两个关系中的所有元组,去除重复的元组。
-
格式:{关系1}
-
举例:
交(Intersection) 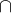
-
找出两个关系中共有的元组。
-
格式:{关系1}
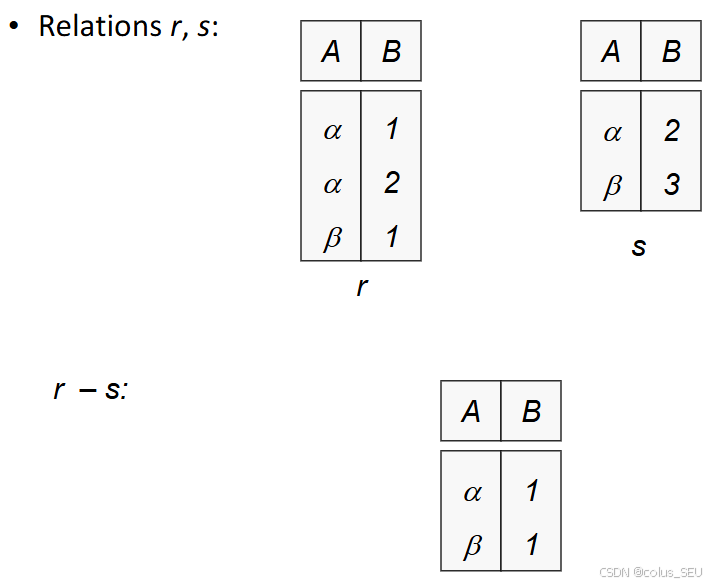
差(Difference) -
-
找出在一个关系中但不在另一个关系中的元组。
-
格式:{关系1} - {关系2}
-
举例:
重命名 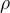
-
更改关系中属性(列)的名称,而不改变其数据。
-
格式:
连接 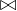
-
自然连接会自动找出两个关系中具有相同属性名的列,并基于这些列的值进行匹配。
-
格式:关系1
-
举例:假设我们有两个关系(表):
-
学生选课表(Enrollments)
属性:学生ID(StudentID),课程ID(CourseID),成绩(Grade)StudentID CourseID Grade 101 C101 85 101 C102 90 102 C101 78 103 C103 88 -
课程信息表(Courses)
属性:课程ID(CourseID),课程名称(CourseName),学分(Credits)CourseID CourseName Credits C101 计算机科学 4 C102 数学 3 C103 物理 3
我们的目标是获取每个学生的课程名称和成绩,但原始的两个表中没有直接的“学生姓名”属性。我们需要通过CourseID来连接这两个表。
使用关系代数表示为:
结果
| StudentID | CourseID | Grade | CourseID_Courses | CourseName | Credits |
|---|---|---|---|---|---|
| 101 | C101 | 85 | C101 | 计算机科学 | 4 |
| 101 | C102 | 90 | C102 | 数学 | 3 |
| 102 | C101 | 78 | C101 | 计算机科学 | 4 |
| 103 | C103 | 88 | C103 | 物理 | 3 |
在这个结果中,我们可以看到每个学生的课程名称和成绩,这是通过自然连接实现的。这种操作在数据库查询中非常常见,尤其是在需要从多个表中提取信息时。
笛卡尔积(Cartesian Product) 
-
将两个关系的元组合并成所有可能的组合。
-
例如:关系1
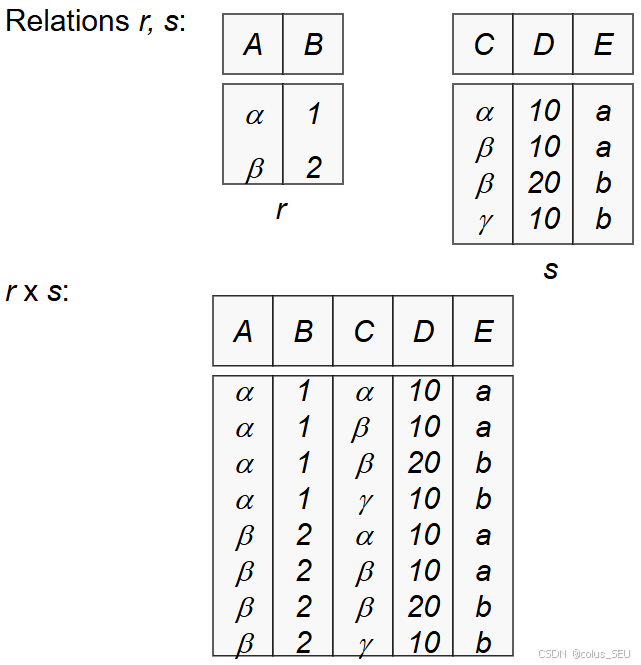
组合运算
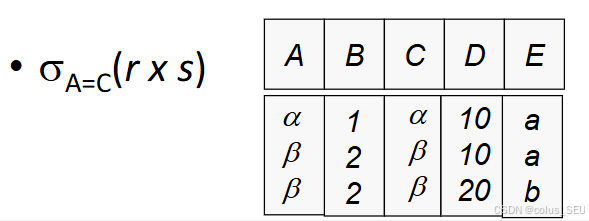
例题分析
题1
有以下两个关系:
C(课程关系)
| CN | type |
|---|---|
CN为课程名称,为该关系的主键
type为课程类型,其域为:{选修,必修}
S_C(学生选课关系)
| SN | CN |
|---|---|
SN为学生名称
CN为课程名称
主键为{SN, CN}
求以下关系:
(1)所有必修课
$$
\pi_{CN}(\sigma_{type=\text{必修}}(C))
$$
(2)至少选一门必修课的所有学生
$$
\pi_{SN}({{(S\_C \bowtie \pi_{CN}(\sigma_{type = \text{必修}}(C)}})))
$$
当然也可以直接写成:
$$
\pi_{SN}({{(S\_C \bowtie \sigma_{type = \text{必修}}(C)}}))
$$
(3)至少选两门必修课的所有学生
先得到每个学生选的必修课的数目。可以先得到 学生-必修课 的关系:
$$
T = S\_C \bowtie \sigma_{type = \text{必修}}(C)
$$
即 T(SN,CN,type),这里 CN 是必修课的 CN。
然后按 SN 分组,统计每个学生的必修课数量。但关系代数没有直接的分组运算,因此需要用自连接的方法。
T 中同一个 SN 对应不同的 CN 就是不同的必修课。要找至少两门不同的必修课,就是找存在两门不同的 CN 对应同一个 SN。
可以这样:
$$
\rho_{T1(SN,CN1)}(\pi_{SN,CN}(T)) \\ \rho_{T2(SN,CN2)}(\pi_{SN,CN}(T))
$$
然后:
$$
\pi_{SN}(\sigma_{T1.SN = T2.SN \and T1.CN \neq T2.CN}(T1 \times T2))
$$
(4)刚好选两门必修课的所有学生
思路:设 Two = 至少两门必修的学生(上题结果);设 Three = 至少三门必修的学生
则刚好两门 = Two - Three。
至少三门的学生可以用类似至少两门的方法:T 同上,自连接三次:
$$
T1 = \rho_{T1(SN, CN1)}(\pi_{SN,CN}(T)) \\ T2 = \rho_{T2(SN, CN2)}(\pi_{SN,CN}(T)) \\ T3 = \rho_{T3(SN, CN3)}(\pi_{SN,CN}(T))
$$
然后选择 T1.SN = T2.SN = T3.SN 且 CN1, CN2, CN3 两两不等,投影 SN,得到至少三门的学生:
$$
Two = \pi_{SN}(\sigma_{T1.SN = T2.SN \land T1.CN \neq T2.CN}(T1 \times T2))
$$
$$
Three = \pi_{SN}(\sigma_{T1.SN = T2.SN = T3.SN \land T1.CN \neq T2.CN \land T2.CN \neq T3.CN \land T1.CN \neq T3.CN}(T1 \times T2 \times T3))
$$
$$
Ans = Two - Three
$$
(5)🌟 修所有必修课的学生
思路:先得到所有学生与所有必修课的笛卡尔积,减去他已经选的,得到他没选的必修课,再投影 SN 得到有没修必修课的学生,最后从全体学生中减去这些学生。
所有必修课:
$$
B = \sigma_{type = \text{必修}}(CN)
$$
则修所有必修课的学生:
$$
\pi_{SN}(S\_C) - \pi_{SN}((\pi_{SN}(S\_C) \times B) - S\_C)
$$
题2
1. 银行数据库关系模型表格
(1) branch 分行表
| branch_name | branch_city | assets |
|---|---|---|
| Downtown | Brooklyn | 9000000 |
| Perryridge | Harrison | 1700000 |
| Brighton | Brooklyn | 7100000 |
| Redwood | Palo Alto | 2100000 |
| Uptown | Rye | 3500000 |
(2) account 账户表
| account_number | branch_name | balance |
|---|---|---|
| A-101 | Downtown | 500 |
| A-102 | Perryridge | 400 |
| A-201 | Brighton | 900 |
| A-215 | Mianus | 700 |
| A-217 | Brighton | 750 |
| A-222 | Redwood | 700 |
| A-305 | Round Hill | 350 |
(3) customer 客户表
| customer_name | customer_street | customer_city |
|---|---|---|
| Jones | Main | Harrison |
| Smith | North | Rye |
| Hayes | Main | Harrison |
| Curry | North | Rye |
| Lindsay | Park | Pittsfield |
| Turner | Putnam | Stamford |
| Adams | Spring | Pittsfield |
(4) depositor 存款人表
| customer_name | account_number |
|---|---|
| Hayes | A-102 |
| Johnson | A-101 |
| Johnson | A-201 |
| Jones | A-217 |
| Lindsay | A-222 |
| Smith | A-215 |
| Turner | A-305 |
(5) loan 贷款表
| loan_number | branch_name | amount |
|---|---|---|
| L-170 | Downtown | 3000 |
| L-230 | Redwood | 4000 |
| L-155 | Perryridge | 1500 |
| L-260 | Perryridge | 1700 |
(6) borrower 借款人表
| customer_name | loan_number |
|---|---|
| Jones | L-170 |
| Smith | L-230 |
| Hayes | L-155 |
| Curry | L-260 |
-
主键与外键:
-
account表的account_number、loan表的loan_number是主键。 -
depositor和borrower中的account_number、loan_number是外键。
-
-
查找所有在Perryridge分行有贷款的客户姓名
$$
\pi_{customer\_name}(\sigma_{branch\_name=Perryridge}(borrower \bowtie loan))
$$ -
查找在银行既有贷款又有账户的客户姓名
$$
\pi_{customer\_name}(depositor) \cap \pi_{customer\_name}(borrower)
$$ -
查找在Perryridge分行有贷款但没有在任何分行有账户的客户
$$
\pi_{customer\_name}(\sigma_{branch\_name = Perryridge}(borrow \bowtie loan)) - \pi_{customer\_name}(depositor)
$$
-
查找所有在"Downtown"和"Uptown"分行都有账户的客户
$$
\pi_{customer\_name}(\sigma_{branch\_name = Downtown}(depositor \bowtie account)) \cap \pi_{customer\_name}(\sigma_{branch\_name = Uptown}(depositor \bowtie account))
$$ -
🌟 查找在Brooklyn市所有分行都有账户的客户
-
Brooklyn的所有分行:
$$
B = \pi_{branch\_name}(\sigma_{branch\_city=Brooklyn}(branch))
$$-
所有客户在Brooklyn分行的账户分布:
$$
C = \pi_{customer\_name, branch\_name}(depositor \bowtie account \bowtie branch)
$$-
未在某个Brooklyn分行开户的客户:
-
对每个Brooklyn分行,找出没有在该分行开户的客户:
$$
D = \pi_{customer\_name}(C) \times B - C
$$ -
这里 \pi_{customer\_name}(C) \times B 生成所有客户与Brooklyn分行的可能组合,然后使用差集 - 排除实际存在的账户关系,得到缺失的客户-分行对。
-
-
最终结果:
-
所有客户减去未完全覆盖Brooklyn分行的客户:
$$
\text{Result} = \pi_{customer\_name}(depositor) - \pi_{customer\_name}(D)
$$
-
-
-
🌟 查找最大的账户余额
-
自连接比较:将 account 表与自身的重命名副本(记为 d)进行笛卡尔积,比较每一对余额。
-
筛选非最大值:找出所有 存在比它更大余额 的 balance 值(即非最大值)。
-
差集求最大值:用所有余额减去非最大值,得到真正的最大值。
$$
\text{MaxBalance} = \pi_{\text{balance}}(\text{account}) - \pi_{\text{account.balance}} \left( \sigma_{\text{account.balance} < d.\text{balance}} \left( \text{account} \times \rho_d(\text{account}) \right) \right)
$$ -
题3
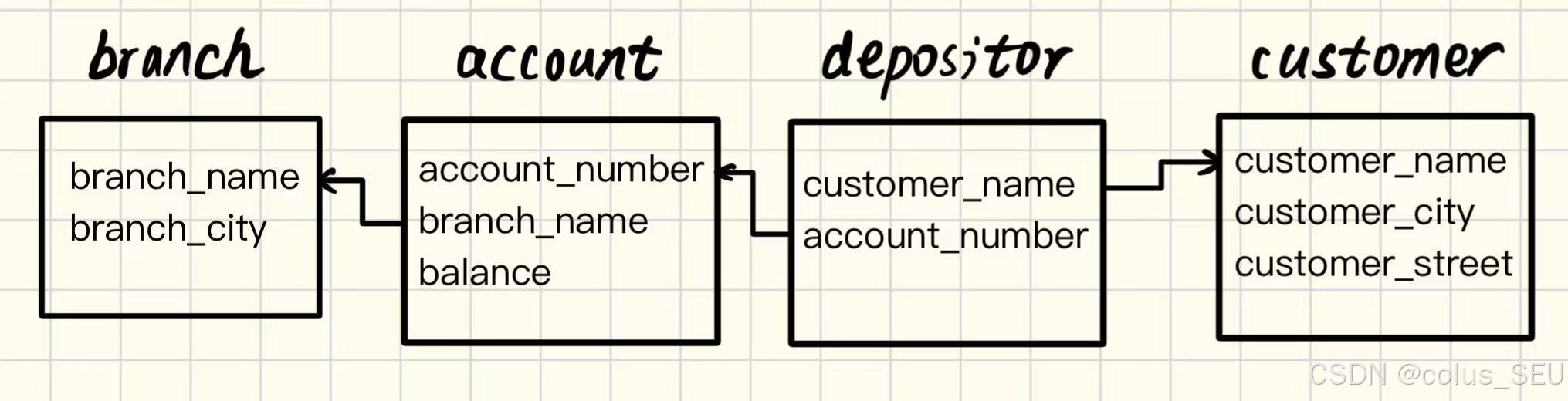
根据上图关系模型,使用关系代数计算在所有银行都有存款且存款都至少有10000元的客户及其住址。
(1)可以使用连接操作
步骤 1:所有客户和所有银行的组合
$$
All\_customer\_branch \leftarrow \pi_{branch\_name}(branch) \times \pi_{customer\_name}(customer)
$$
步骤 2:实际有高额存款的(客户,银行)对
$$
Actual\_customer\_branch \leftarrow \pi_{customer\_name,account\_number}(depositor \bowtie \sigma_{balance \geq 10000}(account))
$$
步骤 3:找出缺少某家银行或者存款额度不够的客户,称为坏客户
$$
Bad\_customers \leftarrow \pi_{customer\_name}(All\_customer\_branch - Actual\_customer\_branch)
$$
步骤 4:好客户 = 所有客户 - 坏客户
$$
Good\_customers = \pi_{customer\_name}(customer) - Bad\_customers
$$
步骤 5:带上地址
$$
Result \leftarrow Good\_customers \bowtie customer
$$
(2)不能使用连接操作,使用笛卡尔积加选择操作代替(考试要求)
步骤 1:所有客户和所有银行的组合
$$
All\_customer\_branch \leftarrow \pi_{branch\_name}(branch) \times \pi_{customer\_name}(customer)
$$
步骤 2:实际有高额存款的(客户,银行)对
$$
Actual\_customer\_branch \leftarrow \pi_{customer\_name,account\_number}(\sigma_{depositor.account\_name = account.account\_name \and account.balance \geq 10000}(depositor \times account))
$$
步骤 3:找出缺少某家银行或者存款额度不够的客户,称为坏客户
$$
Bad\_customers \leftarrow \pi_{customer\_name}(All\_customer\_branch - Actual\_customer\_branch)
$$
步骤 4:好客户 = 所有客户 - 坏客户
$$
Good\_customers = \pi_{customer\_name}(customer) - Bad\_customers
$$
步骤 5:带上地址
$$
Result \leftarrow \pi_{customer.customer\_name,customer\_street,customer\_city} ( \sigma_{Good\_customers.customer\_name = customer.customer\_name}(Good\_customers \times customer))
$$
题4
现有以下关系模型:
老师授课(t)
| T(teacher) | C(class) |
|---|---|
学生选课(s)
| S(student) | C(class) |
|---|---|
使用关系代数计算以下问题:
1、找出 (学生, 老师) 对,使得该学生选修了该老师的至少两门不同的课。
-
先通过自然连接得到 学生-老师-课程 关系 STC:
-
然后计算如果学生选修了该老师,那必然选修了该老师至少两门课程的师生关系
$$
\pi_{S,T}(\sigma_{STC1.S=STC2.S \and STC1.T=STC2.T \and STC1.C \neq STC2.C}(\rho_{STC1}(STC) \times \rho_{STC2}(STC)))
$$
2、选修所有课程的学生
-
先计算所有学生和所有课程的可能组合:
$$
\pi_{C}(t) \times \pi_{S}(s)
$$
-
然后计算没选的学生课程组合:
$$
\pi_{C}(t) \times \pi_{S}(s) - s
$$
-
则选修所有课程的学生为所有学生减去有没选课程的学生:
$$
\pi_{S}(s) - \pi_{S}(\pi_{C}(t) \times \pi_{S}(s) - s)
$$
3、选修每位老师所有课程的学生
即对每个老师 T,该学生选修了该老师的所有课程。
-
先计算每个学生与每个老师的组合:
$$
\pi_{T}(t) \times \pi_{S}(s)
$$
-
然后找出“某个老师有某门课,但学生没选”的情况:
-
先计算学生选择该老师开设的所有课程的情况:
$$
(\pi_{T}(t) \times \pi_{S}(s)) \times t
$$-
然后通过自然连接得到 学生-老师-课程 关系,表示学生已经选择该老师的课程的情况:
$$
\sigma_{t.C=s.C}(t \times s) = t \bowtie s
$$-
最后二者相减得到“某个老师有某门课,但学生没选”的情况:
-
$$
(\pi_{T}(t) \times \pi_{S}(s)) \times t - \sigma_{t.C=s.C}(t \times s)
$$
-
则选修每位老师所有课程的学生为所有学生减去没有选择每位老师所有课程的学生
$$
\pi_{S}(s) - \pi_{S}[(\pi_{T}(t) \times \pi_{S}(s)) \times t - \sigma_{t.C=s.C}(t \times s)]
$$

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 30
30 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)