Oracle AI Database 26ai 与开发相关的15个新特性

作者 | JiekeXu
来源 |公众号 JiekeXu DBA之路(ID: JiekeXu_IT)
如需转载请联系授权 | (个人微信 ID:JiekeXu_DBA)
大家好,我是JiekeXu,江湖人称“强哥”,青学会MOP技术社区主席,荣获Oracle ACE Pro称号,金仓最具价值倡导者KVA,崖山最具价值专家YVP,IvorySQL开源社区专家顾问委员会成员,墨天轮MVP,墨天轮年度“墨力之星”,拥有 Oracle OCP/OCM 认证,MySQL 5.7/8.0 OCP 认证以及金仓KCM、KCSM证书,PCA、PCTA、OBCA、OGCA等众多国产数据库认证证书,欢迎关注我的微信公众号“JiekeXu DBA之路”,然后点击右上方三个点“设为星标”置顶,更多干货文章才能第一时间推送,谢谢!后台回复【加群】,添加我个人微信拉你进群一起交流学习。

前 言
在 Oracle 官方新特性网站上 Oracle AI Database 26ai 有 434 项新特性,地址如下 https://apex.oracle.com/database-features。

Oracle AI Database 26ai 可在 Oracle Database Appliance、Oracle Exadata Database Machine、Autonomous Database、Exadata Database Service、Exascale Infrastructure 上的 Exadata Database Service、Exadata Cloud@Customer 和 Base Database Service 上使用。Oracle Exadata Database Service 和 Autonomous Database 可在 OCI、Azure、Google Cloud 和 AWS 上使用。

最近两年说的最多的,就是 AI、向量数据库,向量数据类型、向量索引、向量距离函数、支持 ONNX 格式模型、向量函数、向量内存等等,之前翻译过官方文档,也写过一点《Oracle 23ai 新特性:AI Vector Search》,不过现在估计有更新了,有些内容有出入,这里先跳过这些内容,可以先看看《聊聊 Oracle 23 ai 新特性、相关更改和停用功能》,下面挑选了一些与开发人员相关的 SQL 层面的新特性,希望对国产数据库以及其他数据库从业人员有借鉴意义。
Oracle Linux8 安装 26ai FREE 版本
下面是 26ai 最新的体系结构图,和之前看到的版本都不一样,值得多研究研究。

在 Oracle Linux8 上安装 26ai 非常简单,如果你的虚拟机能联网,可以在线下载,那么就更简单了,只需三步就可以。
--第一步 下载对应系统版本的 preinstall 和 ai-database-free-26ai rpm 包
wget https://yum.oracle.com/repo/OracleLinux/OL8/appstream/x86_64/getPackage/oracle-ai-database-preinstall-26ai-1.0-1.el8.x86_64.rpm
wget https://download.oracle.com/otn-pub/otn_software/db-free/oracle-ai-database-free-26ai-23.26.0-1.el8.x86_64.rpm
--第二步 安装 preinstall 和 ai-database-free-26ai rpm 包
dnf install oracle-ai-database-preinstall-26ai-1.0-1.el8.x86_64.rpm
dnf install oracle-ai-database-free-26ai-23.26.0-1.el8.x86_64.rpm
--第三步 配置数据库
/etc/init.d/oracle-free-26ai configure
## 配置环境变量登录数据库
--临时设置环境变量,退出后不生效
[oracle@JiekeXu ~]$ export ORACLE_SID=FREE
[oracle@JiekeXu ~]$ export ORAENV_ASK=NO
[oracle@JiekeXu ~]$ . /opt/oracle/product/26ai/dbhomeFree/bin/oraenv
The Oracle base has been set to /opt/oracle
[oracle@JiekeXu ~]$ which sqlplus
/opt/oracle/product/26ai/dbhomeFree/bin/sqlplus
[oracle@JiekeXu ~]$ sqlplus / as sysdba
SQL*Plus: Release 23.26.0.0.0 - Production on Wed Oct 20 22:57:33 2025
Version 23.26.0.0.0
Copyright (c) 1982, 2025, Oracle. All rights reserved.
Connected to:
Oracle AI Database 26ai Free Release 23.26.0.0.0 - Develop, Learn, and Run for Free
Version 23.26.0.0.0
SQL> show pdbs
CON_ID CON_NAME OPEN MODE RESTRICTED
---------- ------------------------------ ---------- ----------
2 PDB$SEED READ ONLY NO
3 FREEPDB1 READ WRITE NO

下面开始介绍新特性。
1、不带 FROM 的 select 语句
现在你可以运行不带 FROM 子句的仅包含 SELECT 表达式的查询。 这一新功能提高了 SQL 代码的可移植性,方便了开发人员使用。不用多说,如下图所示。

2、IF [NOT] EXISTS 语法支持
CREATE、ALTER 和 DROP 等 DDL 命令对象的创建、修改和删除现在支持 IF EXISTS 和 IF NOT EXISTS 语法修饰符。这使您能够控制在给定对象存在或不存在时是否应引发错误,如果检查失败,命令将被忽略且不会产生错误。IF [NOT] EXISTS 语法可以简化脚本和应用程序中的错误处理。
官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/26/adfns/sql-processing-for-application-developers.html#GUID-3818B089-D99D-437C-862F-CBD276BDA3F1
DROP TABLE IF EXISTS <table_name>...如果表存在,则删除该表。如果表不存在,则忽略该语句,因此不会引发错误。创建对象时也存在相同的检查机制。 假设一种场景,即你没有 IF NOT EXISTS 支持。在执行查询之前,你期望某个表存在,但如果该表不存在,则必须创建一个新表。你可以利用 PL/SQL 或查询数据字典来确定该表是否存在。如果表不存在,你可以执行动态 SQL(EXECUTE IMMEDIATE)来创建该表。有了 IF NOT EXISTS 支持,你可以使用 CREATE TABLE IF NOT EXISTS <表名>... 命令在表不存在时创建表。如果具有此名称的表已经存在,无论该表的结构如何,该语句都会被忽略,不会产生错误。
CREATE <object type> [IF NOT EXISTS] <rest of syntax>
-- create table if not exists
CREATE TABLE IF NOT EXISTS t1 (c1 number);
-- alter table if exists
ALTER TABLE IF EXISTS t1 ADD c2 number;
-- drop table if exists
DROP TABLE IF EXISTS t1;
CREATE OR REPLACE语法中不允许使用 IF NOT EXISTS 子句。
以下是一些示例,说明 CREATE OR REPLACE 语句和 CREATE 语句如何与 IF NOT EXISTS 子句一起使用或不能一起使用:
-- not allowed, REPLACE cannot coexists with IF NOT EXISTS
CREATE OR REPLACE SYNONYM IF NOT EXISTS t1_syn FOR t1;
-- allowed
CREATE SYNONYM IF NOT EXISTS t1_syn FOR t1;
-- allowed
CREATE OR REPLACE SYNONYM t1_syn FOR t1;3、应用开发人员的新数据库角色
DB_DEVELOPER_ROLE 角色为应用程序开发人员提供了在 Oracle 数据库上设计、实现、调试和部署应用程序所需的所有权限。通过使用这个角色,DBA 不再需要猜测应用程序开发可能需要哪些权限,给这么一个角色就能全部满足了,不用多说,这个之前 23c 就说过了。
官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/26/dbseg/managing-security-for-application-developers.html#GUID-DCEEC563-4F6C-4B0A-9EB2-9F88CDF351D7
GRANT DB_DEVELOPER_ROLE TO JIEKEXU;
SELECT GRANTED_ROLE FROM DBA_ROLE_PRIVS WHERE GRANTEE='JIEKEXU';
REVOKE DB_DEVELOPER_ROLE FROM JIEKEXU;
4、GROUP BY ALL
在包含聚合函数的复杂 SELECT 列表的 SQL 查询中,新的 GROUP BY ALL 子句消除了将所有非聚合列放入 GROUP BY 子句的需要。相反,新的 ALL 关键字表示结果应自动按所有非聚合列进行分组。 无需在 GROUP BY 子句中重复非聚合列,使得编写 SQL 查询更快且更不易出错。用户可以使用 GROUP BY ALL 功能来快速对 SQL 查询进行原型设计,或进行快速的临时查询。

官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/26/sqlrf/SELECT.html#SQLRF-GUID-CFA006CA-6FF1-4972-821E-6996142A51C6• ALL是一个保留字,因此它不能作为列名,也不能用作列别名。
• 不能将 ALL 与其他 GROUP BY 语法选项一起使用。如果指定了 ALL,那么 GROUP BY ALL 是唯一允许的 group_by_clause 语法。特别是,不能将 ROLLUP、CUBE 或 GROUPING SETS 与 GROUP BY ALL 一起指定。
• GROUP BY ALL 包含所有选择列表表达式,但以下表达式除外,这些表达式在 GROUP BY 子句中不是有效的 GROUP BY 表达式:◦ 分组函数或包含分组函数的表达式 ◦ 标量子查询 ◦ 窗口函数
• GROUP BY ALL 还会排除常量(包括 NULL)和绑定的选择列表表达式。跳过常量的主要原因是在启用按位置分组时避免歧义。
• GROUP BY ALL 不会提取 GROUP BY 的选择列表表达式的部分内容:整个表达式要么包含在 GROUP BY 中,要么完全不包含。
• GROUP BY ALL可用于视图和物化视图。字典中存储的这两者的定义查询将包含GROUP BY ALL,而不是转换后的GROUP BY子句。
• 支持对带有 GROUP BY ALL 的物化视图进行全文匹配重写,但不支持部分文本匹配重写。 • GROUP BY ALL 可用于 WITH 子句查询中。在允许使用 GROUP BY 子句的任何地方都支持该用法。
• HAVING条件可与GROUP BY ALL一起指定。
• GROUP BY ALL 不支持与 MODEL 子句一起使用。如果指定了它,将引发以下错误:“GROUP BY ALL 不支持与 MODEL 子句一起使用”。
• GROUP BY表达式限制(1000或4k)适用于GROUP BY ALL。如果超过限制,将引发错误。
• 在定义子查询的 CREATE MATERIALIZED ZONE MAP DDL 中不支持 GROUP BY ALL。如果指定了该子句,将引发以下错误:“分区映射不允许使用构造或对象 GROUP BY ALL 子句”。
示例:

5、GROUP BY 按列别名或位置分组
现在 26ai 中,您可以在 GROUP BY、GROUP BY CUBE、GROUP BY ROLLUP 和 GROUP BY GROUPING SETS 子句中使用列别名或 SELECT 项位置。此外,HAVING 子句支持列别名。 这些改进使得编写 GROUP BY 和 HAVING 子句更加容易。它可以让 SQL 查询更具可读性和可维护性,同时提供更好的 SQL 代码可移植性。
官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/26/sqlrf/SELECT.html#GUID-CFA006CA-6FF1-4972-821E-6996142A51C6__I2066419GROUP BY 子句的限制,本条款受以下限制约束:
• 您不能将 LOB 列、嵌套表或可变数组指定为 expr 的一部分。
• 表达式可以是任何形式,但标量子查询表达式除外。
• 如果分组子句引用了任何对象类型的列,则查询将不会被并行化。
• 若要按位置分组,则必须将参数 group_by_position_enabled 设置为 true,该参数默认值为 false
示例:
SQL> select job,deptno,sum(sal) from emp group by1 ,2;
select job,deptno,sum(sal) from emp group by 1,2
*
ERROR at line 1:
ORA-03162: "JOB": must appear in the GROUPBY clause or be used in an aggregate functionas'group_by_position_enabled'isFALSE
Help: https://docs.oracle.com/error-help/db/ora-03162/
--修改参数
alter system set group_by_position_enabled=true;
select job God_job,deptno,sum(sal) from emp group by God_job,2;
SELECT manager_id, EXTRACT(YEARFROM hire_date) AS hired_year, COUNT(*)
FROM employees GROUP BY 1, 2;
SELECT DECODE(GROUPING(department_name), 1, 'All Departments',
department_name) AS department_name,
DECODE(GROUPING(job_id), 1, 'All Jobs', job_id) AS job_id,
COUNT(*) "Total Empl", AVG(salary) *12 "Average Sal"
FROM employees e, departments d
WHERE d.department_id = e.department_id
GROUP BY CUBE (department_name, job_id)
ORDERBY department_name, job_id;
SELECT department_id, manager_id
FROM employees
GROUP BY department_id, manager_id HAVING (department_id, manager_id) IN
(SELECT department_id, manager_id FROM employees x
WHERE x.department_id = employees.department_id)
ORDERBY department_id;
6、SQL非定位插入子句
Oracle 26 AI 数据库新增了 INSERT INTO SET 子句,这是一种更简单、自解释的 INSERT INTO 语句语法。INSERT INTO 语句的 SET 子句与 UPDATE 语句中已有的 SET 子句相同。在插入子查询结果时,它还新增了 BY NAME 子句。该子句通过列名而非 INSERT 和 SELECT 列表中的位置来匹配源列和目标列。SET 子句的好处在于,它能让 INSERT INTO 语句中的每个值对应哪一列一目了然,而对于当前有数百列的 INSERT INTO 语句来说,要弄清楚这一点既不明显又很麻烦。同样,在加载子查询时,让 INSERT 和 SELECT 列表中数百列的顺序相匹配也很笨拙。使用 BY NAME 子句可以让这些列表的顺序不同,从而简化了编写语句的过程。

官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/26/sqlrf/INSERT.html#GUID-903F8043-0254-4EE9-ACC1-CB8AC0AF3423__I2125362
示例1:不带括号的单行插入
INSERT INTO employees SET
employee_id =210, last_name ='Smith', email ='ASMITH', hire_date = SYSDATE, job_id ='AD_ASST';
示例2:带括号的单行插入
INSERT INTO employees SET
(employee_id =211, last_name ='SmithS', email ='ASMITHS', hire_date = SYSDATE, job_id ='AD_ASST');
示例3:多行插入
INSERT INTO employees SET
(employee_id =212, last_name ='SmithE', email ='ASMITHE', hire_date = SYSDATE, job_id ='AD_ASST'),
(employee_id =213, last_name ='Roddick', email ='ARODDICK', hire_date = SYSDATE, job_id ='IT_PROG');
Insert into ... by_name_position_clause 支持使用子查询进行非位置插入,其中子查询的选择列表中暴露的列名(别名或简单列名,如果没有别名)会与目标表的列名进行匹配,以确定值应插入表中的顺序。作为子查询的修饰符,by_name_position_clause 可以选择性地出现在子查询之前的任何位置。
以下两条插入语句在语义上是等价的:
INSERT INTO job_history
BY NAME
SELECT employee_id, hire_date AS start_date, SYSDATE -1AS end_date, department_id, job_id FROM employees
WHERE employee_id =206;
INSERT INTO job_history (employee_id, start_date, end_date, department_id, job_id)
SELECT employee_id, hire_date, SYSDATE -1, department_id, job_id FROM employees
WHERE employee_id =206;
以下非 11g--26ai 新特性,接下来的示例将数据插入多个表中。假设你想为销售代表提供有关各种规模订单的一些信息。以下示例将为小、中、大及特殊订单创建表,并使用示例表 orders 中的数据填充这些表:
CREATE TABLE small_orders
(order_id NUMBER(12) NOTNULL,
customer_id NUMBER(6) NOTNULL,
order_total NUMBER(8,2),
sales_rep_id NUMBER(6)
);
CREATE TABLE medium_orders AS SELECT * FROM small_orders;
CREATE TABLE large_orders AS SELECT * FROM small_orders;
CREATE TABLE special_orders
(order_id NUMBER(12) NOTNULL,
customer_id NUMBER(6) NOTNULL,
order_total NUMBER(8,2),
sales_rep_id NUMBER(6),
credit_limit NUMBER(9,2),
cust_email VARCHAR2(40)
);
--INSERT ALL 多表插入操作订单表:
INSERT ALL
WHEN order_total <=100000THEN
INTO small_orders
WHEN order_total >1000000AND order_total <=200000THEN
INTO medium_orders
WHEN order_total >200000THEN
INTO large_orders
SELECT order_id, order_total, sales_rep_id, customer_id
FROM orders;7、SQL时间分桶
时间分桶是处理时间序列或事件流数据时的常见操作,在这种操作中,任意定义的时间窗口内的一系列数据点需要映射到特定的固定时间间隔(桶),以便进行聚合分析。借助新的 SQL 运算符 TIME_BUCKET,Oracle 为 DATETIMES 基于时间的数据提供了原生且高效的时间分桶支持。为时间序列数据的常见固定时间间隔分桶提供原生 SQL 运算符,可显著简化此类信息的应用开发和数据分析。除了使代码更简单、更不易出错外,原生运算符还能提高时间序列分析的性能。
官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/26/dwhsg/sql-analysis-reporting-data-warehouses.html#GUID-91A27A23-A5E0-4CF7-8669-019146D22A4DTIME_BUCKET 函数支持将输入的 DATETIMES 按指定间隔进行分桶,该间隔与特定原点对齐,并返回时间所在桶的起始点。 TIME_BUCKET 直接支持以下输入的 DATETIMES:
• 日期 DATE
• 时间戳 TIMESTAMP
• 带时区的时间戳 TIMESTAMP WITH TIME ZONE
• 带本地时区的时间戳 TIMESTAMP WITH LOCAL TIME ZONE
• 数字(纪元时间) NUMBER(EPOCH TIME)
--本集中的三个示例使用了数据类型 DATE。我们先用 Oracle INTERVAL 语法,再用 ISO 8601 语法选择一个五年的时间窗口。前两个示例使用 START 参数,该参数将窗口的起点定义为返回值。第三个示例使用相同的语句,但使用 END 参数,该参数返回窗口的终点。
SQL>select time_bucket(DATE'2022-06-29', 'P5Y', DATE'2000-01-01', START) ;
TIME_BUCKET(DATE'20
-------------------
2020-01-01 00:00:00
SQL> select time_bucket(DATE '2022-06-29', INTERVAL '5' YEAR, DATE '2000-01-01', START) ;
TIME_BUCKET(DATE'20
-------------------
2020-01-0100:00:00
SQL>select time_bucket(DATE'2022-06-29', INTERVAL'5'YEAR, DATE'2000-01-01', END) ;
TIME_BUCKET(DATE'20
-------------------
2025-01-01 00:00:00
SQL> alter session set nls_date_format='dd mon syyyy hh24:mi:ss';
Session altered.
SQL> select time_bucket(TIMESTAMP '2022-06-2912:34:56', INTERVAL '5' HOUR, TIMESTAMP '2022-06-2900:00:00', END);
TIME_BUCKET(TIMESTAMP'2022-06-2912:34:56',INTERVAL'5'HOUR,TIMESTAMP'2022-06
---------------------------------------------------------------------------
29-JUN-2203.00.00 PM
--这是一个CHAR数据类型的示例。请注意,输入是NLS_TIMESTAMP_FORMAT中的一个字符,并会自动转换为TIMESTAMP。这就是为什么第二个参数ORIGIN可以是一个时间戳的原因。
SQL>alter session set nls_timestamp_format='yyyy-mm-dd hh24:mi:ss';
SQL>select time_bucket('2022-06-27 12:34:56', 'P5D', TIMESTAMP'2022-06-29 12:14:56');
TIME_BUCKET('2022-06-2712:34:56','P5D',TIMESTAMP'2022-06-2912:14:56')
---------------------------------------------------------------------------
2022-06-2412:14:56
8、SQL 生成 128 位 UUID
UUID 是一种128位的通用唯一标识符,被应用程序广泛用于生成不可预测的随机值,该值可用作表中的主键、事务ID或任何形式的唯一标识符。在Oracle AI数据库26ai中,SQL函数UUID()根据 UUID RFC 9562 在数据库中生成版本4变体1的UUID。UUID生成和操作函数提供了一种合规的方式来生成随机、唯一且不可预测的标识符,该标识符可用于填充数据库表中的主键列、唯一标识事务ID(例如,用于Oracle AI数据库26ai中的无会话事务功能)以及其他许多用途。现代应用程序期望能够生成不可预测且随机的 UUID。所有主要的数据库和数据管理系统都支持某种形式的 UUID 生成和操作。当前的 Oracle SQL 运算符 SYS_GUID() 总是生成一个可预测的唯一标识符序列,这并非最优方案。
官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/26/sqlrf/uuid.html#SQLRF-GUID-2A0ECCC2-3DA1-442F-AC9D-A6FE643F381DUUID 以 RAW(16) 值的形式返回版本4变体1的 UUID,格式如下: xxxxxxxx-xxxx-4xxx-Bxxx-xxxxxxxxxxxx,其中 x 为十六进制数字。 UUID可以选择接受一个NUMBER类型的版本说明符作为输入。UUID(0) 和 UUID(4) 等同于 UUID(),因为在这两种情况下都会返回版本4、变体1的 UUID。 除4和0之外的版本会返回错误。
SELECT UUID();
UUID()
--------------------------------
4EC3D31B77224FEABF38456CE010BD90
select SYS_GUID();
SYS_GUID()
--------------------------------
41A302077A294D19E0638ED8000C623C
--注意:RAW(16)已转换为可打印形式
SQL>ALTER TABLE locations ADD (uid_col RAW(16));
SQL>UPDATE locations SET uid_col = UUID();
23rows updated.
SQL>SELECT location_id, uid_col FROM locations
2 ORDERBY location_id, uid_col;
LOCATION_ID UID_COL
----------- --------------------------------
10003E74D833847A4F7EBF56CEFD3936BCF8
11005F62472A5A414FBCBFB81298098E9BE9
12000768F8460D324F3ABF551C0728E27A96
13006499D717251C4F14BF34E3E038186A3E
9、支持布尔数据类型
Oracle 23c 引入了 SQL 布尔数据类型,这个 23c 发布之前也已经介绍过了,这里大概说一说。布尔数据类型具有真值 TRUE(真)和 FALSE(假)。如果没有 NOT NULL 约束,布尔数据类型还支持真值 UNKNOWN(未知)作为空值。在 SQL 语法中,只要出现数据类型的地方,都可以使用布尔数据类型。
官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/26/sqlrf/Data-Types.html#GUID-285FFCA8-390D-4FA9-9A51-47B84EF5F83A例如,在 CREATE TABLE 语句中,可以使用关键字 BOOLEAN 或 BOOL 来指定布尔列:
CREATE TABLE example (id NUMBER, c1 BOOLEAN, c2 BOOL);
--可以使用 SQL 关键字 TRUE、FALSE 和 NULL 分别表示状态 “TRUE”、“FALSE” 和 “NULL”。例如,使用上面创建的表示例,
INSERT INTO example VALUES (1, TRUE, NULL);
INSERT INTO example VALUES (2, FALSE, true);
INSERT INTO example VALUES (3, 0, 'off');
INSERT INTO example VALUES (4, 'no', 'yes');
INSERT INTO example VALUES (5, 'f', 't' );
INSERT INTO example VALUES (6, false, true);
INSERT INTO example VALUES (7, 'on', 'off');
INSERT INTO example VALUES (8, -3.14, 1);
--请注意,数字按如下方式转换为布尔值: • 0 转换为 FALSE。 • 非零值,如42或-3.14,会转换为TRUE。
请注意,支持比较运算符来比较布尔值
SELECT * FROM example WHERE c1 = c2;
SELECT * FROM example e1
WHERE c1 >=ALL (SELECT c2 FROM example e2 WHERE e2.id > e1.id);
SELECT * FROM example WHERE NOT c2;
SELECT * FROM example WHERE c1 AND c2;
SELECT * FROM example WHERE c1 AND TRUE;
SELECT * FROM example WHERE c1 OR c2;
10、UPDATE语句的空值默认处理
您可以将列定义为在更新操作中使用 DEFAULT ON NULL,而此前这仅在插入操作中可行。当更新操作尝试将值更新为 NULL 时,指定为 DEFAULT ON NULL 的列会自动更新为特定的默认值。此功能简化了应用程序开发,无需使用复杂的应用程序代码或数据库触发器即可实现所需的行为。开发效率得以提高,代码也更不容易出错。

官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/26/sqlrf/CREATE-TABLE.html#GUID-F9CE0CC3-13AE-4744-A43C-EAC7A71AAAB6__CJAIGEJE示例:
以下语句创建了一个名为 myemp 的表,该表可用于存储员工数据。 department_id 列被定义为具有默认值 50(当值为NULL时)。因此,如果后续的 INSERT 语句试图将 NULL 值赋给 department_id,则会改为赋值 50。
SQL> conn jiekexu/Pass_word123@FREEPDB1
CREATE TABLE myemp (employee_id number, last_name varchar2(25),department_id NUMBER DEFAULT ON NULL 50 NOT NULL);
--在员工表中,员工编号 178 的部门编号值为 NULL:
SELECT employee_id, last_name, department_id
FROM employees
WHERE department_id IS NULL;
EMPLOYEE_ID LAST_NAME DEPARTMENT_ID
----------- ------------------------- -------------
178 Grant
-- 用员工表中的 employee_id、last_name 和 department_id 列数据填充 myemp 表:
INSERT INTO myemp (employee_id, last_name)
values(178,'Grant');
-- 在 myemp 表中,employee_id 为 178 的员工对应的 department_id 值为 50:
SELECT employee_id, last_name, department_id
FROM myemp
WHERE employee_id =178;
EMPLOYEE_ID LAST_NAME DEPARTMENT_ID
----------- ------------------------- -------------
178 Grant 50
--最后这里的更新居然失败了
SQL>update myemp set department_id=nullwhere EMPLOYEE_ID=178;
update myemp set department_id=nullwhere EMPLOYEE_ID=178
*
ERROR at line 1:
ORA-01407: cannot update ("JIEKEXU"."MYEMP"."DEPARTMENT_ID") toNULL
Help: https://docs.oracle.com/error-help/db/ora-01407/
这里 update 却报错了,不知道是我理解的不对,还是 FREE 版本本身就不支持 update 的时候设置为默认值呢?这点只能后面有新环境在研究了。欢迎关注我的视频号,学习了解更多新知识。
以上算是十个与开发相关的新特性吧,不过好像还有一些与开发相关的新特性,去年已经提过了。比如:
11、schema 级别权限
直接授予用户 schema 级别的查询权限,省的新建表的时候还得一个个单独授予,目前 26ai 之前的版本均会被困扰,实在麻烦,这点后面有时间再细说。
官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/26/dbseg/configuring-privilege-and-role-authorization.html#GUID-EEE53C39-D610-4792-82EA-6F49B880B036
GRANT SELECT ANY TABLE ON SCHEMA HR TO JiekeXu;
REVOKE SELECT ANY TABLE ON SCHEMA HR FROM JiekeXu;12、大宽表最多支持 4096 列
数据库表或视图中允许的最大列数已增至 4096 列。此功能允许您构建可在单个表中存储属性的应用程序,其列数超过了之前的 1000 列限制。某些应用(如机器学习和流式物联网应用工作负载)可能需要使用超过 1000 列的去规范化表。
官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/26/refrn/MAX_COLUMNS.html#REFRN-GUID-916B35D1-364E-41C6-A025-E2D32533D08E
ORA-01792: maximum number of columns in a table or view is 1000
alter system set MAX_COLUMNS = 'EXTENDED' scope=spfile;注意:要启用宽表功能,需要将 MAX_COLUMNS 参数设置为EXTENDED。使用此设置时,数据库表或视图允许的最大列数为4096。要设置MAX_COLUMNS = EXTENDED,COMPATIBLE初始化参数必须设置为23.0.0.0或更高版本。
• 要禁用宽表功能,请将此参数设置为STANDARD。使用此设置时,数据库表或视图允许的最大列数为1000。这与Oracle AI Database 26ai之前的版本的行为一致。
另外注意的就是您可以随时将 MAX_COLUMNS 的值从 STANDARD 更改为 EXTENDED。但是,只有当数据库中的所有表和视图都包含 1000 列或更少时,您才能将 MAX_COLUMNS 的值从 EXTENDED 更改为 STANDARD。Oracle AI Database 26ai 客户端(如 SQLPlus、OCI、JDBC-OCI、非托管 ODP.NET 以及开源驱动程序)支持增加的列限制 4096。旧版客户端(Oracle AI Database 26ai 之前的版本)不支持增加的列限制,无法访问表或视图中的超过 1000 列。
13、不受限制的并行 DML
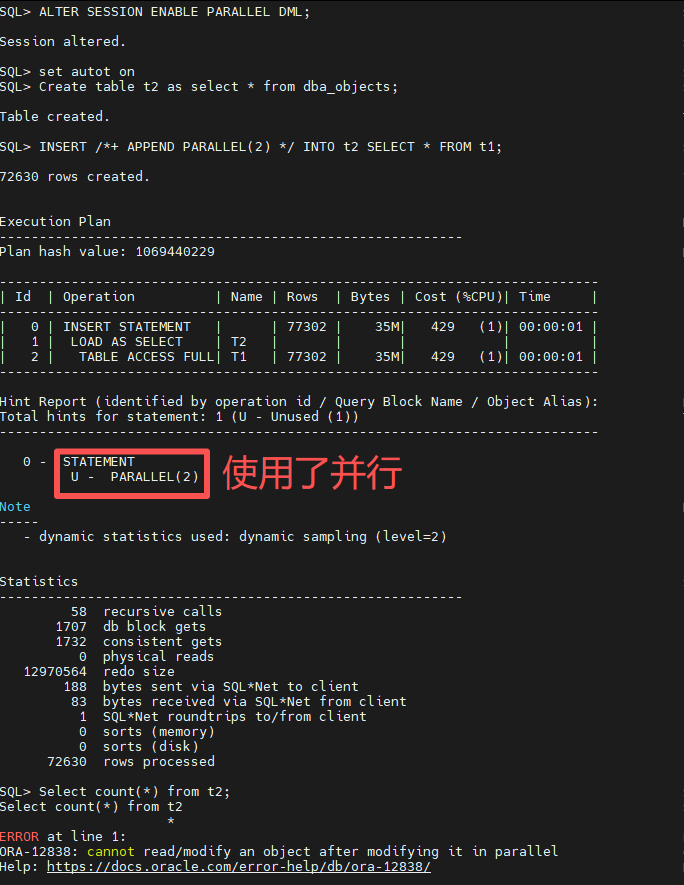
Oracle 数据库允许并行执行 DML 语句(INSERT、UPDATE、DELETE 和 MERGE),方法是将 DML 语句分解为相互排斥的较小任务。并行执行 DML 语句可使 DSS 查询、批量 OLTP 作业或任何较大的 DML 操作更快。不过,并行 DML 操作有一些事务限制。其中包括限制每个表使用多个并行 DML 的事务。这意味着,一旦并行 DML 语句修改了对象,同一事务的后续语句就无法读取或修改该对象。该增强功能消除了这一限制,使用户可以在同一事务中运行并行 DML 以及查询、串行 DML 和并行 DML 等语句的任意组合。对用户来说,这可以充分利用 Oracle 数据库的并行执行和并行查询功能,从而简化和加快数据加载和分析处理。
官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/26/vldbg/using-parallel.html#GUID-1D5C8D6C-0A0E-4CDB-8B32-16EC3C856ACC
ALTER SESSION FORCE PARALLEL DML;
ALTER SESSION ENABLE PARALLEL DML;
Create table t3 as select * from dba_objects;
INSERT /*+ APPEND PARALLEL(t3,2) */ INTO t3 SELECT * FROM t3;
Select count(*) from t3;实际上我在 Oracle AI Database 26ai FREE 版本测试中还是和以前的版本一样会报错 ORA-12838: cannot read/modify an object after modifying it in parallel,估计此特性 FREE 版本暂时还没有吧。
14、将内联 LOB 的最大大小增加到 8000 字节
如果设置了 ENABLE STORAGE IN ROW(启用行存储),内联 LOB 大小最小为 4000,最大为 8000。这包括控制信息和 LOB 值。LOB 的默认内联大小为 4000。
官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/26/adlob/creating-new-LOB-column.html#GUID-6378560B-4305-496A-95A7-1FDFB6719FDC
SQL>CREATE TABLE t_lobtab1 (id NUMBER, blog CLOB)
2 lob (blog) STORE AS SECUREFILE jiekexusegname
3 (TABLESPACE users
4 ENABLE STORAGE IN ROW
5 CACHE LOGGING
6 RETENTION AUTO
7 COMPRESS);
Table created.15、增加 Oracle AI 数据库密码长度至 1024 字节
Oracle AI 数据库现在支持长达 1024 字节的密码。在之前的版本中,密码长度和安全角色密码长度最多为 30 字节。增加密码长度符合行业对更强身份验证的普遍趋势。在必须使用密码的情况下,更长的密码长度允许创建更难猜测的密码。
Oracle 为密码设置了一套最低要求。密码长度至少需为 12 字节(最长 1024 字节)。您可通过多种方式增强密码安全性,例如要求密码达到合理长度,或创建自定义密码复杂度验证脚本,以强制执行适用于您所在站点的密码复杂度策略要求。
官方文档:https://docs.oracle.com/en/database/oracle/oracle-database/26/dbseg/configuring-authentication.html#GUID-AA1AA635-1CD5-422E-B8CA-681ED7C253CA
create tablespace JIEKEXU datafile '/opt/oracle/oradata/FREE/FREEPDB1/jiekexu01.dbf' size 30m;
create user JiekeXu identified by Oracle_26_Ai default tablespace JiekeXu;
grant connect,resource,unlimited tablespace to JiekeXu;
create user JiekeXu_ReadOnly identified by Oracle_26_AiOracle_26_AiOracle_26_AiOracle_26_Ai default tablespace JiekeXu; --大于 30 字节的密码
grant connect,resource,unlimited tablespace to JiekeXu_ReadOnly;
select tablespace_name,bigfile from dba_tablespaces;
Oracle 26ai 有 434 项新特性,除此之外,还有很多比较实用的和借鉴的特性,AI 向量不用多说,机器学习、SQL 图、JSON、微服务、JavaScript、JDBC 应用连续性、安全、审计、高可用、云服务、大数据等多方面有重大更新,因未发布本地版本,很多特性也无法测试,目前只能去看官方文档学习了解了,那么今天就先到这里咯。
参考链接
https://apex.oracle.com/database-features
https://www.oracle.com/database/26ai/
https://docs.oracle.com/en/database/oracle/oracle-database/26/nfcoa/
https://docs.oracle.com/en/database/oracle/oracle-database/26/dbseg/configuring-authentication.html#GUID-AA1AA635-1CD5-422E-B8CA-681ED7C253CA全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步
——————————————————————————
公众号:JiekeXu DBA之路
墨天轮:https://www.modb.pro/u/4347
CSDN :https://blog.csdn.net/JiekeXu
ITPUB:https://blog.itpub.net/69968215
IFCLUB:https://ifclub.com.cn/user?type=1
腾讯云:https://cloud.tencent.com/developer/user/5645107 ——————————————————————————

第三批国测公布:国产数据库新势力的破局与价值
2024 年公众号 JiekeXu DBA之路历史文章合集
2023 年公众号 JiekeXu DBA之路历史文章合集
2022 年公众号 JiekeXu DBA之路历史文章合集
2021 年公众号历史文章合集


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)