基于大数据的网约车平台运营数据分析系统
本文介绍了一套基于Hadoop+Spark架构的网约车运营数据分析系统。该系统采用Django/SpringBoot后端和Vue+Echarts前端,支持多维度分析包括时间分布、地域对比、运营效率和司机行为等。通过SparkSQL和Pandas进行数据处理,MySQL存储数据,为网约车平台提供精细化运营决策支持。系统具备双版本(Python/Java)和定制化功能,实现从数据采集到可视化的完整分析
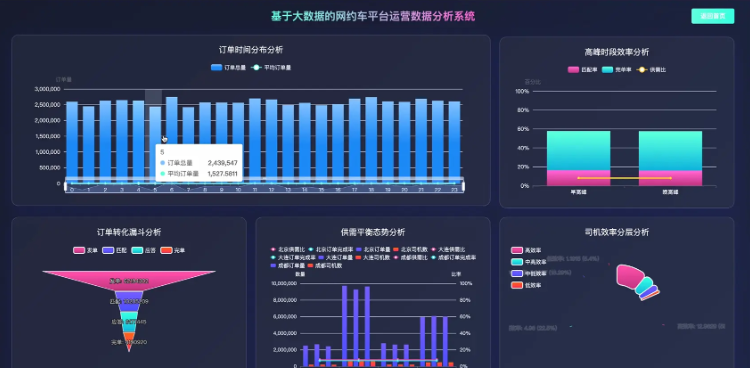
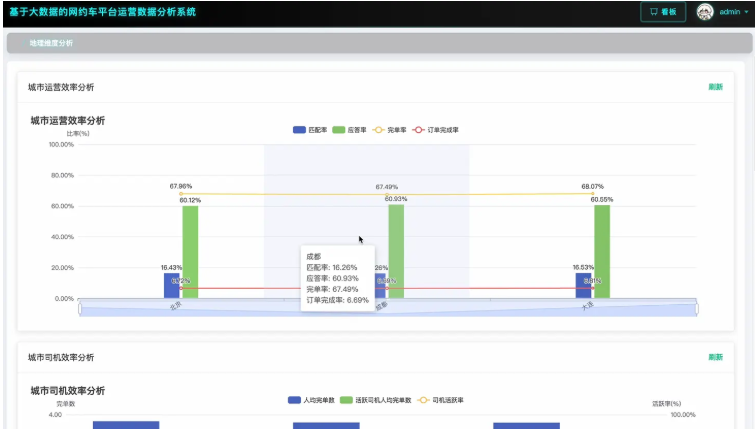
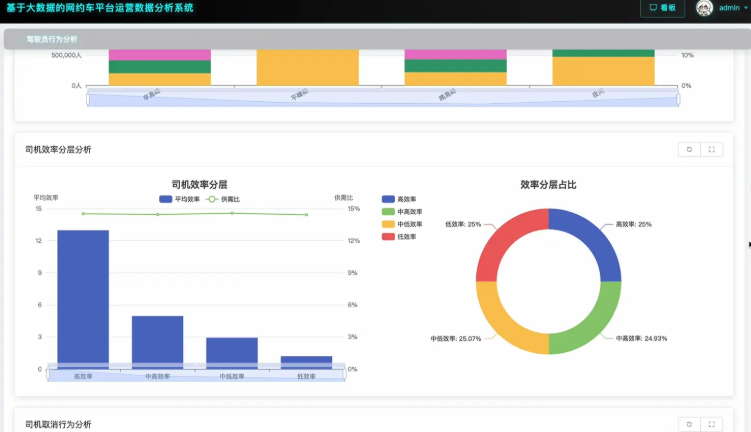
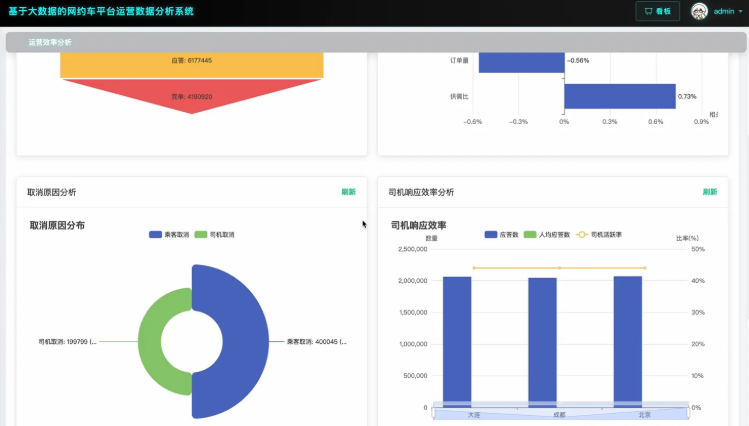
基于大数据的网约车平台运营数据分析系统是一套专门针对网约车行业运营数据进行深度分析的综合性平台,采用Hadoop分布式存储架构和Spark大数据计算引擎作为核心技术栈,能够高效处理海量的网约车运营数据。系统通过Django后端框架构建稳定的数据处理服务,结合Vue+ElementUI+Echarts前端技术实现直观的数据可视化展示,支持对网约车平台的订单量分布、匹配效率、司机行为、城市运营等多个维度进行全面分析。系统具备时间维度分析功能,能够统计不同时间点的订单量分布和高峰时段运营效率;地域维度分析功能可以对比不同城市间的运营效率和司机工作表现;运营效率维度通过构建订单转化漏斗和匹配率分析,帮助平台识别运营瓶颈;司机行为维度则通过活跃度分析和效率分层,为司机管理提供数据支撑。整个系统基于MySQL数据库存储,利用Spark SQL进行复杂查询,通过Pandas和NumPy进行数据预处理和统计分析,为网约车平台的精细化运营决策提供可靠的数据支持。
大数据框架:Hadoop+Spark(本次没用Hive,支持定制) 开发语言:Python+Java(两个版本都支持) 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持) 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy 数据库:MySQL


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)