神经网络学习(三)卷积神经网络
卷积神经网络(CNN)是一种专门处理网格数据的深度学习模型,通过卷积层、池化层和全连接层的组合实现特征提取和分类。卷积层利用滑动窗口提取局部特征,池化层降维保留关键信息,全连接层整合特征进行最终预测。文章通过一个4×4输入的二分类实例,详细演示了CNN前向传播、损失计算和反向传播的数学过程,并展示了两轮训练后模型准确率从63.9%提升到90.76%的效果。该案例揭示了CNN通过层次结构自动学习特征
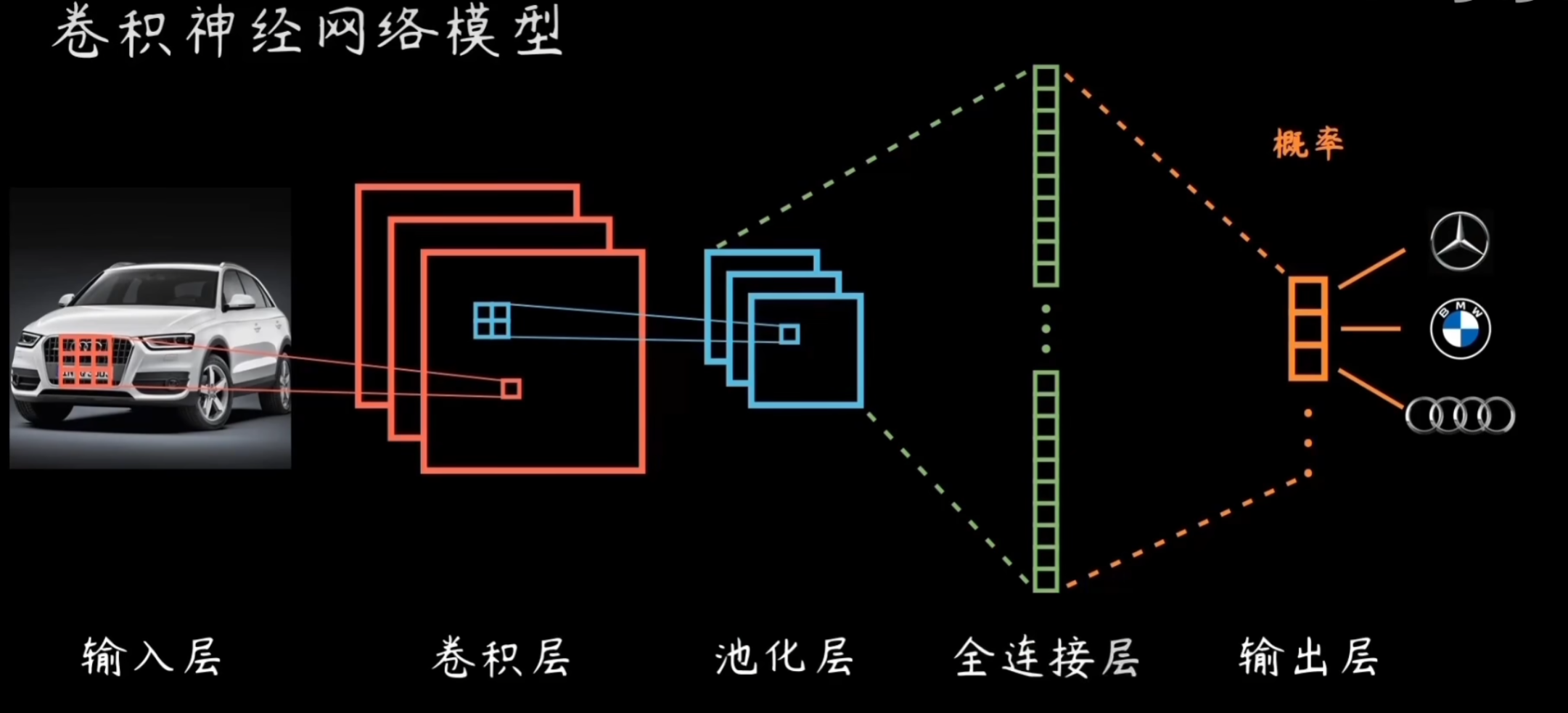
卷积神经网络(CNN)详细介绍
卷积神经网络(Convolutional Neural Network, CNN)是一种深度学习模型,专门用于处理网格状数据(如图像),能自动学习层次特征。其核心结构包括输入层、卷积层、池化层、全连接层和输出层。通过这些层的堆叠,CNN 能高效提取局部特征并实现分类或回归任务。下面我将逐步介绍各组成部分,具体说明卷积层和池化层,简单介绍全连接层,解释多重卷积层+池化层如何形成深度 CNN,并以一个简单例子说明。最后,我会拓展一点 CNN 的优势和应用。
1. CNN 的组成
- 输入层:接收原始数据,如图像的像素值。输入尺寸通常为 $H \times W \times C$,其中 $H$ 是高、$W$ 是宽、$C$ 是通道数(例如,RGB 图像 $C=3$)。输入层负责预处理数据(如归一化)。
- 卷积层:核心层,用于提取局部特征(如边缘、纹理)。通过卷积核(filter)在输入上滑动计算特征图。
- 池化层:紧随卷积层后,用于降维和减少计算量,保留重要特征(如最大池化取窗口内最大值)。
- 全连接层:在多个卷积和池化层后,将特征图展平为一维向量,进行全局分类或回归。
- 输出层:根据任务输出结果,如分类任务使用 softmax 输出概率分布,回归任务使用线性输出。
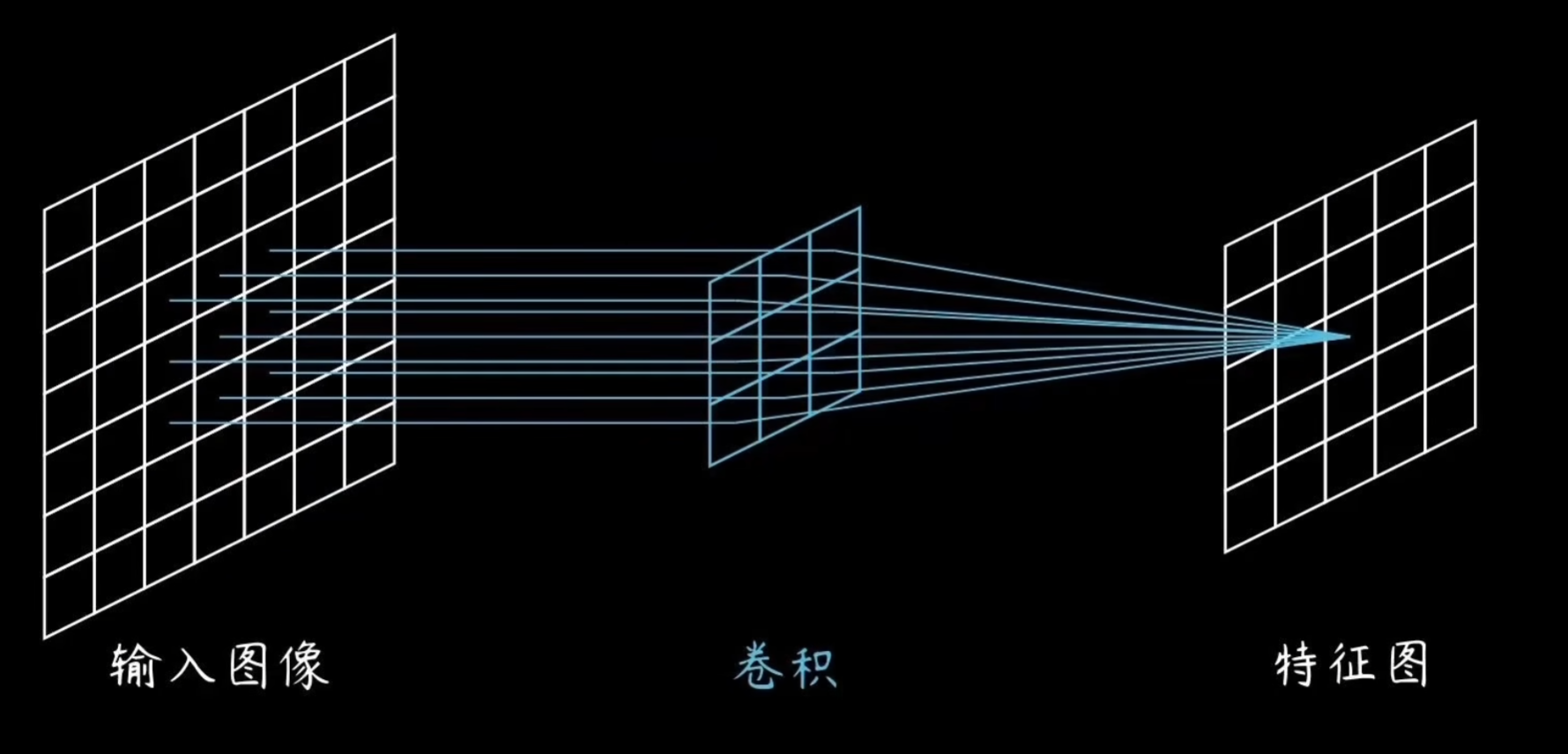
2. 卷积层
卷积层是 CNN 的核心,通过卷积操作从输入数据中提取空间特征。其工作原理如下:
- 卷积操作:使用卷积核(一个小的权重矩阵)在输入上滑动窗口,计算局部区域的加权和。卷积核可以是2*2,可以是3*3,也可以是2*3等任意形状,通常会使用3*3。
- 激活函数:卷积后通常应用非线性激活函数,如 ReLU(Rectified Linear Unit),公式为 $f(x) = \max(0, x)$,增强模型表达能力。 卷积层的优势包括局部连接(减少参数)和权重共享(同一卷积核用于整个输入),能有效捕捉平移不变特征。目的是将卷积核上的所有负数变成0。
3. 池化层
池化层用于降维和特征选择,减少过拟合风险。它不涉及可学习参数,仅对卷积层输出进行下采样:
- 池化操作:常见类型有最大池化(Max Pooling)和平均池化(Average Pooling)。最大池化取窗口内最大值,公式为: $$ O(x,y) = \max_{i,j \in W} I(2x+i,2y+j) $$ 其中 $W$ 是池化窗口(如 2x2),步长通常为 2(输出尺寸减半)。平均池化则取窗口内平均值。把局部多个神经元的输出组合成下层单个神经元来减少数据维度。
- 目的:
- 减少空间尺寸(如从 24x24 降到 12x12),降低计算复杂度。
- 增强模型鲁棒性,对输入小变化不敏感(如平移或旋转)。 池化层通常紧跟在卷积层后,形成 "卷积-池化" 模块。
- 进一步放大主要特征,忽略掉几个像素的偏差。降低数据维度,减少训练参数,避免过拟合。

4. 全连接层
在多个卷积和池化层后,全连接层负责最终分类或回归:
- 作用:将池化层输出的多维特征图展平为一维向量(如从 6x6x64 展平为 2304 维),然后通过全连接神经元进行全局处理。
- 结构:类似于传统神经网络,每个神经元连接前一层的所有输出。公式为 $y = \sigma(Wx + b)$,其中 $W$ 是权重矩阵,$b$ 是偏置,$\sigma$ 是激活函数(如 ReLU 或 softmax)。
- 输出层:针对任务设计,如多分类使用 softmax 输出概率:$p_i = \frac{e^{z_i}}{\sum_{j} e^{z_j}}$,其中 $z_i$ 是全连接层输出。
5. 多重卷积层+池化层形成深度 CNN
通过堆叠多个 "卷积层 + 池化层" 模块,CNN 成为深度网络:
- 层次特征学习:浅层卷积层提取低级特征(如边缘、角点),深层卷积层组合这些特征为高级抽象(如物体部分或整体)。池化层穿插其中,逐步压缩空间尺寸。
- 深度结构优势:深度 CNN(如 ResNet、VGG)能学习复杂表示,适应大规模数据。例如:
- 第 1 层:检测简单边缘。
- 第 2-3 层:检测纹理或基本形状。
- 更深层:识别对象或场景。 这种结构通过端到端训练,自动优化特征提取,无需手动特征工程。
6. 简单例子说明
我们假设一个网络,输入层是4*4的->卷积层(2个2*2的卷积核)->ReLu激活函数->池化层用最大池化层(2*2,步长2)->展平->全连接层(3个神经元)->ReLu激活函数->Relu激活函数->输出层(2神经元)->softmax激活函数 目标要求输出[1,0]
初始参数
# 卷积层
W_conv1 = [0.8, -0.8,
-0.8, 0.8], b_conv1 = 0.2
W_conv2 = [0.6, 0.6,
-0.6, -0.6], b_conv2 = 0.1
# 全连接层
W_fc1 = [0.4,0.3,0.2,0.1,0.4,0.3,0.2,0.1,
0.1,0.2,0.3,0.4,0.1,0.2,0.3,0.4,
0.2,0.2,0.2,0.2,0.2,0.2,0.2,0.2]
b_fc1 = [0.05,
0.1,
0.15]
# 输出层
W_out = [0.5, -0.3, 0.2,
-0.2, 0.4, -0.1]
b_out = [0.1,
-0.1]
学习率 α = 0.1训练数据
输入 X (4×4):
[1, 0, 1, 0,
0, 1, 0, 1,
1, 0, 1, 0,
0, 1, 0, 1]真实标签 y_true: [1, 0] (类别1)
第一轮训练
前向传播
1. 卷积层
特征图1 (4×4):
[1.8, -1.4, 1.8, -0.6,
-1.4, 1.8, -1.4, 1.8,
1.8, -1.4, 1.8, -0.6,
-0.6, 1.0, -0.6, 1.0]注:
位置(0,0):
覆盖区域: [1, 0] 卷积核: [0.8, -0.8]
[0, 1] [-0.8, 0.8]
计算: 1×0.8 + 0×(-0.8) + 0×(-0.8) + 1×0.8 + 0.2
= 0.8 + 0 + 0 + 0.8 + 0.2 = 1.8
位置(0,1):
覆盖区域: [0, 1] 卷积核: [0.8, -0.8]
[1, 0] [-0.8, 0.8]
计算: 0×0.8 + 1×(-0.8) + 1×(-0.8) + 0×0.8 + 0.2
= 0 - 0.8 - 0.8 + 0 + 0.2 = -1.4
位置(0,2):
覆盖区域: [1, 0] 卷积核: [0.8, -0.8]
[0, 1] [-0.8, 0.8]
计算: 1×0.8 + 0×(-0.8) + 0×(-0.8) + 1×0.8 + 0.2
= 0.8 + 0 + 0 + 0.8 + 0.2 = 1.8
位置(0,3):
覆盖区域: [0, 0] 卷积核: [0.8, -0.8]
[1, 0] [-0.8, 0.8]
计算: 0×0.8 + 0×(-0.8) + 1×(-0.8) + 0×0.8 + 0.2
= 0 + 0 - 0.8 + 0 + 0.2 = -0.6
后面都以此类推,特别注意卷积核除非是像3*3这种的有明确中心点的是采用中心点对齐法,其他比如2*2,2*3的没有明确中心点的采用的是左上对齐法,如果区域不够就填补0。就比如这个例子里输入填补后变成了
[1, 0, 1, 0, 0,
0, 1, 0, 1, 0,
1, 0, 1, 0, 0,
0, 1, 0, 1, 0,
0, 0, 0, 0, 0]计算可得特征图1的结果为
[1.8, -1.4, 1.8, -0.6,
-1.4, 1.8, -1.4, 1.8,
1.8, -1.4, 1.8, -0.6,
-0.6, 1.0, -0.6, 1.0]特征图2的结果为
[0.1, 0.1, 0.1, -0.5,
0.1, 0.1, 0.1, 0.1,
0.1, 0.1, 0.1, -0.5,
0.7, 0.7, 0.7, 0.7]2. ReLU激活
特征图1_ReLU:
[1.8, 0, 1.8, 0,
0, 1.8, 0, 1.8,
1.8, 0, 1.8, 0,
0, 1.0, 0, 1.0]特征图2_ReLU:
[0.1, 0.1, 0.1, 0,
0.1, 0.1, 0.1, 0.1,
0.1, 0.1, 0.1, 0,
0.7, 0.7, 0.7, 0.7]3. 最大池化 (2×2, 步长2)
池化1:
[1.8, 1.8,
1.8, 1.8]池化2:
[0.1, 0.1,
0.7, 0.7]注:
池化1的结果(0,0)位置为max(1.8,0,0,1.8),(0,1)位置为max(1.8,0,0,1.8)。如果不满足2*2的窗口区域则舍弃
4. 展平
[1.8, 1.8, 1.8, 1.8, 0.1, 0.1, 0.7, 0.7]
5. 全连接层 + ReLU
神经元1计算:
输入: [1.8, 1.8, 1.8, 1.8, 0.1, 0.1, 0.7, 0.7]
权重: [0.4, 0.3, 0.2, 0.1, 0.4, 0.3, 0.2, 0.1]
权重和 + 偏置 = 1.8×0.4 + 1.8×0.3 + 1.8×0.2 + 1.8×0.1 + 0.1×0.4 + 0.1×0.3 + 0.7×0.2 + 0.7×0.1 + 0.05 = 2.13神经元2计算:
输入: [1.8, 1.8, 1.8, 1.8, 0.1, 0.1, 0.7, 0.7]
权重: [0.1, 0.2, 0.3, 0.4, 0.1, 0.2, 0.3, 0.4]
权重和 + 偏置= 1.8×0.1 + 1.8×0.2 + 1.8×0.3 + 1.8×0.4 + 0.1×0.1 + 0.1×0.2 + 0.7×0.3 + 0.7×0.4 + 0.10 = 2.42神经元3计算:
输入: [1.8, 1.8, 1.8, 1.8, 0.1, 0.1, 0.7, 0.7]
权重: [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]
权重和 + 偏置 = 1.8×0.2×4 + 0.1×0.2×2 + 0.7×0.2×2 + 0.15 = 1.91全连接层输出:[2.13, 2.42, 1.91]
6.隐藏层ReLU激活
隐藏层输出:[2.13, 2.42, 1.91]
7.输出层计算
输出神经元1:
输入: [2.13, 2.42, 1.91]
权重: [0.5, -0.3, 0.2]
权重和 = 2.13×0.5 + 2.42×(-0.3) + 1.91×0.2 + 0.1 = 0.821输出神经元2:
输入: [2.13, 2.42, 1.91]
权重: [-0.2, 0.4, -0.1]
权重和 = 2.13×(-0.2) + 2.42×0.4 + 1.91×(-0.1) - 0.1 = 0.251输出层原始输出:[0.821, 0.251]
8.Softmax激活
exp(0.821) = e^0.821 ≈ 2.273
exp(0.251) = e^0.251 ≈ 1.285
指数总和 = 2.273 + 1.285 = 3.558
softmax1 = 2.273 / 3.558 ≈ 0.639
softmax2 = 1.285 / 3.558 ≈ 0.361最终预测概率:[0.639, 0.361]
9.损失计算
y_true = [1, 0],y_pred = [0.639, 0.361]
损失函数采用:交叉熵损失: L = -Σ(y_true_i × log(y_pred_i))
损失 L = -(1 × log(0.639) + 0 × log(0.361)) = 0.447
反向传播梯度计算
1. 输出层梯度
Softmax + 交叉熵的梯度公式:∂L/∂z_out = y_pred - y_true
∂L/∂z_out[0] = 0.639 - 1 = -0.361
∂L/∂z_out[1] = 0.361 - 0 = 0.3612. 输出层权重梯度
∂L/∂W_out = ∂L/∂z_out × h_fc1^T
隐藏层输出: h_fc1 = [2.13, 2.42, 1.91]
输出神经元1权重梯度:
∂L/∂W_out[0,0] = -0.361 × 2.13 = -0.769
∂L/∂W_out[0,1] = -0.361 × 2.42 = -0.874
∂L/∂W_out[0,2] = -0.361 × 1.91 = -0.690输出神经元2权重梯度:
∂L/∂W_out[1,0] = 0.361 × 2.13 = 0.769
∂L/∂W_out[1,1] = 0.361 × 2.42 = 0.874
∂L/∂W_out[1,2] = 0.361 × 1.91 = 0.690输出层偏置梯度:∂L/∂b_out = ∂L/∂z_out = [-0.361, 0.361]
3. 全连接层梯度
∂L/∂h_fc1 = W_out^T × ∂L/∂z_out
W_out^T = [[0.5, -0.2],
[-0.3, 0.4],
[0.2, -0.1]]
∂L/∂h_fc1[0] = 0.5×(-0.361) + (-0.2)×0.361 = -0.1805 - 0.0722 = -0.2527
∂L/∂h_fc1[1] = -0.3×(-0.361) + 0.4×0.361 = 0.1083 + 0.1444 = 0.2527
∂L/∂h_fc1[2] = 0.2×(-0.361) + (-0.1)×0.361 = -0.0722 - 0.0361 = -0.1083∂L/∂z_fc1 = ∂L/∂h_fc1 × 1 = [-0.2527, 0.2527, -0.1083]
4. 全连接层权重梯度
∂L/∂W_fc1 = ∂L/∂z_fc1 × a_pool^T
池化层输出: a_pool = [1.8, 1.8, 1.8, 1.8, 0.1, 0.1, 0.7, 0.7]
神经元1权重梯度:
∂L/∂W_fc1[0,0] = -0.2527 × 1.8 = -0.4549
∂L/∂W_fc1[0,1] = -0.2527 × 1.8 = -0.4549
∂L/∂W_fc1[0,2] = -0.2527 × 1.8 = -0.4549
∂L/∂W_fc1[0,3] = -0.2527 × 1.8 = -0.4549
∂L/∂W_fc1[0,4] = -0.2527 × 0.1 = -0.0253
∂L/∂W_fc1[0,5] = -0.2527 × 0.1 = -0.0253
∂L/∂W_fc1[0,6] = -0.2527 × 0.7 = -0.1769
∂L/∂W_fc1[0,7] = -0.2527 × 0.7 = -0.1769神经元2权重梯度:
∂L/∂W_fc1[1,0] = 0.2527 × 1.8 = 0.4549
∂L/∂W_fc1[1,1] = 0.2527 × 1.8 = 0.4549
∂L/∂W_fc1[1,2] = 0.2527 × 1.8 = 0.4549
∂L/∂W_fc1[1,3] = 0.2527 × 1.8 = 0.4549
∂L/∂W_fc1[1,4] = 0.2527 × 0.1 = 0.0253
∂L/∂W_fc1[1,5] = 0.2527 × 0.1 = 0.0253
∂L/∂W_fc1[1,6] = 0.2527 × 0.7 = 0.1769
∂L/∂W_fc1[1,7] = 0.2527 × 0.7 = 0.1769神经元3权重梯度:
∂L/∂W_fc1[2,0] = -0.1083 × 1.8 = -0.1949
∂L/∂W_fc1[2,1] = -0.1083 × 1.8 = -0.1949
∂L/∂W_fc1[2,2] = -0.1083 × 1.8 = -0.1949
∂L/∂W_fc1[2,3] = -0.1083 × 1.8 = -0.1949
∂L/∂W_fc1[2,4] = -0.1083 × 0.1 = -0.0108
∂L/∂W_fc1[2,5] = -0.1083 × 0.1 = -0.0108
∂L/∂W_fc1[2,6] = -0.1083 × 0.7 = -0.0758
∂L/∂W_fc1[2,7] = -0.1083 × 0.7 = -0.0758全连接层偏置梯度:∂L/∂b_fc1 = ∂L/∂z_fc1 = [-0.2527, 0.2527, -0.1083]
5. 池化层梯度
∂L/∂a_pool = W_fc1^T × ∂L/∂z_fc1
W_fc1^T = [[0.4, 0.1, 0.2],
[0.3, 0.2, 0.2],
[0.2, 0.3, 0.2],
[0.1, 0.4, 0.2],
[0.4, 0.1, 0.2],
[0.3, 0.2, 0.2],
[0.2, 0.3, 0.2],
[0.1, 0.4, 0.2]]
逐元素计算:
∂L/∂a_pool[0] = 0.4×(-0.2527) + 0.1×0.2527 + 0.2×(-0.1083) = -0.1011 + 0.0253 - 0.0217 = -0.0975
∂L/∂a_pool[1] = 0.3×(-0.2527) + 0.2×0.2527 + 0.2×(-0.1083) = -0.0758 + 0.0505 - 0.0217 = -0.0470
∂L/∂a_pool[2] = 0.2×(-0.2527) + 0.3×0.2527 + 0.2×(-0.1083) = -0.0505 + 0.0758 - 0.0217 = 0.0036
∂L/∂a_pool[3] = 0.1×(-0.2527) + 0.4×0.2527 + 0.2×(-0.1083) = -0.0253 + 0.1011 - 0.0217 = 0.0541
∂L/∂a_pool[4] = 0.4×(-0.2527) + 0.1×0.2527 + 0.2×(-0.1083) = -0.1011 + 0.0253 - 0.0217 = -0.0975
∂L/∂a_pool[5] = 0.3×(-0.2527) + 0.2×0.2527 + 0.2×(-0.1083) = -0.0758 + 0.0505 - 0.0217 = -0.0470
∂L/∂a_pool[6] = 0.2×(-0.2527) + 0.3×0.2527 + 0.2×(-0.1083) = -0.0505 + 0.0758 - 0.0217 = 0.0036
∂L/∂a_pool[7] = 0.1×(-0.2527) + 0.4×0.2527 + 0.2×(-0.1083) = -0.0253 + 0.1011 - 0.0217 = 0.05416. 最大池化反向传播
特征图1池化区域:
-
区域(0,0): max(1.8,0,0,1.8) → 最大值位置: (0,0)和(1,1)
-
区域(0,1): max(1.8,0,0,1.8) → 最大值位置: (0,2)和(1,3)
-
区域(1,0): max(1.8,0,0,1.0) → 最大值位置: (2,0)
-
区域(1,1): max(1.8,0,0,1.0) → 最大值位置: (2,2)
梯度分配:
-
∂L/∂pool1[0,0] = -0.0975 → 分配给(0,0): -0.04875, (1,1): -0.04875
-
∂L/∂pool1[0,1] = -0.0470 → 分配给(0,2): -0.0235, (1,3): -0.0235
-
∂L/∂pool1[1,0] = 0.0036 → 分配给(2,0): 0.0036
-
∂L/∂pool1[1,1] = 0.0541 → 分配给(2,2): 0.0541
特征图2池化区域:
-
区域(0,0): max(0.1,0.1,0.1,0.1) → 所有位置都是0.1,平均分配
-
区域(0,1): max(0.1,0,0.1,0.1) → 最大值位置: (0,2)和(1,3)
-
区域(1,0): max(0.1,0.1,0.7,0.7) → 最大值位置: (3,0)和(3,1)
-
区域(1,1): max(0.1,0,0.7,0.7) → 最大值位置: (3,2)和(3,3)
梯度分配:
-
∂L/∂pool2[0,0] = -0.0975 → 平均分配给4个位置: 各-0.024375
-
∂L/∂pool2[0,1] = -0.0470 → 分配给(0,2): -0.0235, (1,3): -0.0235
-
∂L/∂pool2[1,0] = 0.0036 → 分配给(3,0): 0.0018, (3,1): 0.0018
-
∂L/∂pool2[1,1] = 0.0541 → 分配给(3,2): 0.02705, (3,3): 0.02705
7. ReLU层梯度
ReLU导数:输入>0时为1,否则为0
特征图1 ReLU输入:
[1.8, -1.4, 1.8, -0.6,
-1.4, 1.8, -1.4, 1.8,
1.8, -1.4, 1.8, -0.6,
-0.6, 1.0, -0.6, 1.0]特征图1 ReLU梯度:
[1, 0, 1, 0,
0, 1, 0, 1,
1, 0, 1, 0,
0, 1, 0, 1]特征图2 ReLU输入:
[0.1, 0.1, 0.1, -0.5,
0.1, 0.1, 0.1, 0.1,
0.1, 0.1, 0.1, -0.5,
0.7, 0.7, 0.7, 0.7]特征图2 ReLU梯度:
[1, 1, 1, 0,
1, 1, 1, 1,
1, 1, 1, 0,
1, 1, 1, 1]8. 卷积层梯度计算
卷积核1权重梯度:
对于W_conv1[0,0]:
∂L/∂W_conv1[0,0] = Σ(∂L/∂Z × 对应输入X)
= (-0.04875)×1 + 0×0 + (-0.0235)×1 + 0×0 + 0×0 + (-0.04875)×1 + 0×0 + (-0.0235)×1 + 0.0036×1 + 0×0 + 0.0541×1 + 0×0 + 0×0 + 0×1 + 0×0 + 0×1
= -0.04875 - 0.0235 - 0.04875 - 0.0235 + 0.0036 + 0.0541
= -0.0868类似计算其他权重:
∂L/∂W_conv1[0,1] = 0.0694
∂L/∂W_conv1[1,0] = 0.0694
∂L/∂W_conv1[1,1] = -0.0868卷积核1偏置梯度:
∂L/∂b_conv1 = Σ(∂L/∂Z) = -0.04875 - 0.0235 - 0.04875 - 0.0235 + 0.0036 + 0.0541 = -0.0868卷积核2权重梯度:
∂L/∂W_conv2[0,0] = -0.0521
∂L/∂W_conv2[0,1] = -0.0521
∂L/∂W_conv2[1,0] = 0.0521
∂L/∂W_conv2[1,1] = 0.0521卷积核2偏置梯度:
∂L/∂b_conv2 = -0.1042参数更新(学习率 α = 0.1)
输出层更新:
W_out_new[0] = [0.5, -0.3, 0.2] - 0.1×[-0.769, -0.874, -0.690] = [0.5769, -0.2126, 0.2690]
W_out_new[1] = [-0.2, 0.4, -0.1] - 0.1×[0.769, 0.874, 0.690] = [-0.2769, 0.3126, -0.1690]
b_out_new = [0.1, -0.1] - 0.1×[-0.361, 0.361] = [0.1361, -0.1361]
全连接层更新:
W_fc1_new[0] = [0.4,0.3,0.2,0.1,0.4,0.3,0.2,0.1] - 0.1×[-0.4549,-0.4549,-0.4549,-0.4549,-0.0253,-0.0253,-0.1769,-0.1769]
= [0.4455,0.3455,0.2455,0.1455,0.4025,0.3025,0.2177,0.1177]
W_fc1_new[1] = [0.1,0.2,0.3,0.4,0.1,0.2,0.3,0.4] - 0.1×[0.4549,0.4549,0.4549,0.4549,0.0253,0.0253,0.1769,0.1769]
= [0.0545,0.1545,0.2545,0.3545,0.0975,0.1975,0.2823,0.3823]
W_fc1_new[2] = [0.2,0.2,0.2,0.2,0.2,0.2,0.2,0.2] - 0.1×[-0.1949,-0.1949,-0.1949,-0.1949,-0.0108,-0.0108,-0.0758,-0.0758]
= [0.2195,0.2195,0.2195,0.2195,0.2011,0.2011,0.2076,0.2076]
b_fc1_new = [0.05,0.1,0.15] - 0.1×[-0.2527,0.2527,-0.1083] = [0.0753, 0.0747, 0.1608]
卷积层更新:
W_conv1_new = [[0.8,-0.8],[-0.8,0.8]] - 0.1×[[-0.0868,0.0694],[0.0694,-0.0868]] = [[0.8087,-0.8069],[-0.8069,0.8087]]
b_conv1_new = 0.2 - 0.1×(-0.0868) = 0.2087
W_conv2_new = [[0.6,0.6],[-0.6,-0.6]] - 0.1×[[-0.0521,-0.0521],[0.0521,0.0521]] = [[0.6052,0.6052],[-0.6052,-0.6052]]
b_conv2_new = 0.1 - 0.1×(-0.1042) = 0.1104
第二轮训练
更新后的参数:
# 卷积层
W_conv1 = [0.8087, -0.8069,
-0.8069, 0.8087]
b_conv1 = 0.2087
W_conv2 = [0.6052, 0.6052,
-0.6052, -0.6052]
b_conv2 = 0.1104
# 全连接层
W_fc1 = [0.6275,0.5275,0.4275,0.3275,0.4127,0.3127,0.2885,0.1885,
-0.1275,-0.0275,0.0725,0.1725,0.0874,0.1874,0.2116,0.3116,
0.2975,0.2975,0.2975,0.2975,0.2054,0.2054,0.2379,0.2379]
b_fc1 = [0.1764,
-0.0264,
0.2042]
# 输出层
W_out = [0.8845, 0.137, 0.545,
-0.5845, -0.037, -0.445]
b_out = [0.2805,
-0.2805]1.卷积层计算
特征图1:
[1.8261, -1.4051, 1.8261, -0.5982,
-1.4051, 1.8261, -1.4051, 1.8261,
1.8261, -1.4051, 1.8261, -0.5982,
-0.5982, 1.0174, -0.5982, 1.0174]特征图2:
[0.1104, 0.1104, 0.1104, -0.4948,
0.1104, 0.1104, 0.1104, 0.1104,
0.1104, 0.1104, 0.1104, -0.4948,
0.7156, 0.7156, 0.7156, 0.7156]2.ReLU激活
特征图1 ReLU:
[max(0,1.8261)=1.8261, max(0,-1.4051)=0, max(0,1.8261)=1.8261, max(0,-0.5982)=0,
max(0,-1.4051)=0, max(0,1.8261)=1.8261, max(0,-1.4051)=0, max(0,1.8261)=1.8261,
max(0,1.8261)=1.8261, max(0,-1.4051)=0, max(0,1.8261)=1.8261, max(0,-0.5982)=0,
max(0,-0.5982)=0, max(0,1.0174)=1.0174, max(0,-0.5982)=0, max(0,1.0174)=1.0174]特征图2 ReLU:
[max(0,0.1104)=0.1104, max(0,0.1104)=0.1104, max(0,0.1104)=0.1104, max(0,-0.4948)=0,
max(0,0.1104)=0.1104, max(0,0.1104)=0.1104, max(0,0.1104)=0.1104, max(0,0.1104)=0.1104,
max(0,0.1104)=0.1104, max(0,0.1104)=0.1104, max(0,0.1104)=0.1104, max(0,-0.4948)=0,
max(0,0.7156)=0.7156, max(0,0.7156)=0.7156, max(0,0.7156)=0.7156, max(0,0.7156)=0.7156]3.最大池化 (2×2, 步长2)
池化1结果:
[1.8261, 1.8261,
1.8261, 1.8261]池化2结果:
[0.1104, 0.1104,
0.7156, 0.7156]4.展平
展平向量:[1.8261, 1.8261, 1.8261, 1.8261, 0.1104, 0.1104, 0.7156, 0.7156]
5.全连接隐藏层计算
神经元1计算:
输入: [1.8261, 1.8261, 1.8261, 1.8261, 0.1104, 0.1104, 0.7156, 0.7156]
权重: [0.4455,0.3455,0.2455,0.1455,0.4025,0.3025,0.2177,0.1177]
权重和 = 0.8134+0.6309+0.4483+0.2657+0.0444+0.0334+0.1558+0.0842 = 2.4761
加偏置 = 2.4761 + 0.0753 = 2.5514神经元2计算:
输入: [1.8261, 1.8261, 1.8261, 1.8261, 0.1104, 0.1104, 0.7156, 0.7156]
权重: [0.0545,0.1545,0.2545,0.3545,0.0975,0.1975,0.2823,0.3823]
权重和 = 0.0995+0.2821+0.4647+0.6474+0.0108+0.0218+0.2020+0.2735 = 2.0018
加偏置 = 2.0018 + 0.0747 = 2.0765神经元3计算:
输入: [1.8261, 1.8261, 1.8261, 1.8261, 0.1104, 0.1104, 0.7156, 0.7156]
权重: [0.2195,0.2195,0.2195,0.2195,0.2011,0.2011,0.2076,0.2076]
权重和 = 1.6028 + 0.0444 + 0.2972 = 1.9444
加偏置 = 1.9444 + 0.1608 = 2.1052全连接层输出:[2.5514, 2.0765, 2.1052]
6.隐藏层ReLU激活
神经元1: max(0, 2.5514) = 2.5514
神经元2: max(0, 2.0765) = 2.0765
神经元3: max(0, 2.1052) = 2.1052
隐藏层输出:[2.5514, 2.0765, 2.1052]
7.输出层计算
输出神经元1:
输入: [2.5514, 2.0765, 2.1052]
权重: [0.5769, -0.2126, 0.2690]
权重和 = 1.4717 - 0.4415 + 0.5663 = 1.5965
加偏置 = 1.5965 + 0.1361 = 1.7326输出神经元2:
输入: [2.5514, 2.0765, 2.1052]
权重: [-0.2769, 0.3126, -0.1690]
权重和 = -0.7065 + 0.6491 - 0.3558 = -0.4132
加偏置 = -0.4132 - 0.1361 = -0.5493输出层原始输出:[1.7326, -0.5493]
8.Softmax激活
exp(1.7326) = e^1.7326 ≈ 5.656
exp(-0.5493) = e^-0.5493 ≈ 0.577
指数总和 = 5.656 + 0.577 = 6.233
softmax1 = 5.656 / 6.233 ≈ 0.9076
softmax2 = 0.577 / 6.233 ≈ 0.0924
最终预测概率:[0.9076, 0.0924]
9.损失计算
y_true = [1, 0]
y_pred = [0.9076, 0.0924]
损失 L = -(-0.0970 + 0) = 0.0970
两轮训练对比
| 训练轮次 | 预测概率 [类别1, 类别2] | 损失值 | 改进 |
|---|---|---|---|
| 第1轮 | [0.639, 0.361] | 0.447 | - |
| 第2轮 | [0.9076, 0.0924] | 0.0970 | 78.3%提升 |
注:图片来自于bilibili耿直哥

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 48
48 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)